Bert
Bert
사전 학습된 대용량의 레이블링 되지 않은 데이터를 이용하여 언어 모델을 학습하고 이를 토대로 자연어 처리와 관련된 작업들(문서 분류, 질의응답, 번역 등)을 수행하는 신경망을 추가한 전이 학습 방법
- 기본적으로 대량의 단어 임베딩 등에 대해 사전 학습이 되어 있는 모델을 제공하기 때문에 상대적으로 적은 자원만으로도 충분히 자연어 처리의 여러 일을 수행할 수 있음
Bert Input Representation
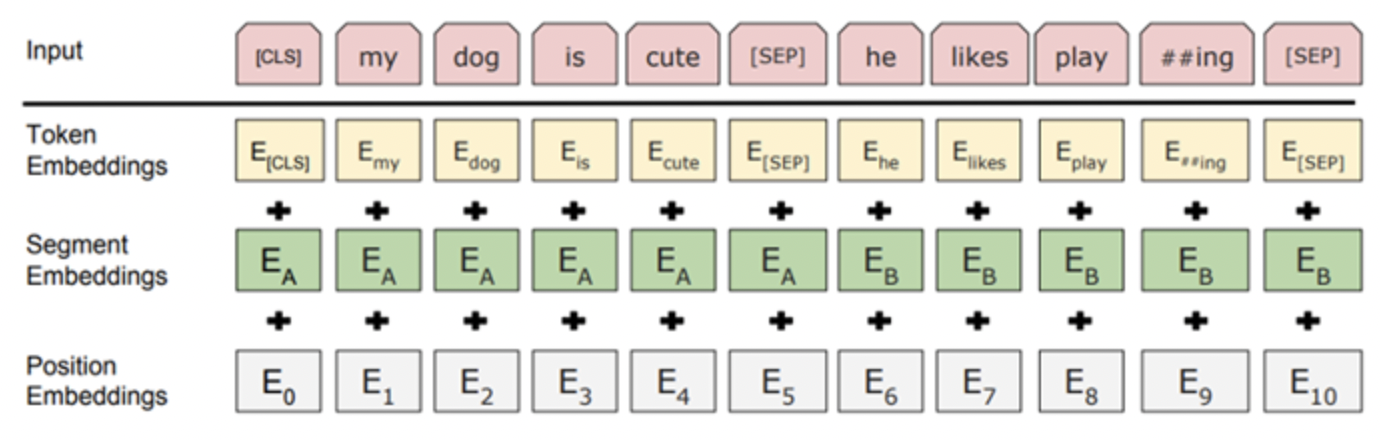
- Tocken Embeddins
: Word Piece 임베딩 방식을 사용함
- sub-word : 자주 등장하면서 가장 긴 길이의 단어 자체를 하나의 단위로 만듬
- rare-word : 자주 등장하지 않는 단어는 다시 쪼개서 sub-word로 쪼갬
- [CLS] tocken : special classification token, 입력받은 모든 문장의 시작에 쓰임
- [SEP] tocken : 문장의 구분을 위해 문장의 끝에 쓰임
자주 등장하지 않은 단어를 전부 Out-of-vocabulary(OOV)로 처리하여 모델링의 성능을 저하했던 문제를 해결할 수 있음
- Segment Embeddings
: 토큰으로 나누어진 단어들을 다시 하나의 문장으로 만들고 첫 번째 [SEP] 토큰까지는 0으로 그 이후 [SEP] 토큰까지는 1 값으로 마스크를 만들어 각 문장들을 구분함
- Position Embeddings
: 토큰의 순서를 인코딩함
BERT는 transformer의 encoder를 사용하는데 Transformer는 Self-Attention 모델을 사용하므로, Self-Attention은 입력의 위치에 대해 고려하지 못하는 문제를 입력 토큰의 위치 정보를 줌으로써 해결할 수 있음

MLOps