CountVectorizer
count_vectorizer = feature_extraction.text.CountVectorizer()CountVectorizer
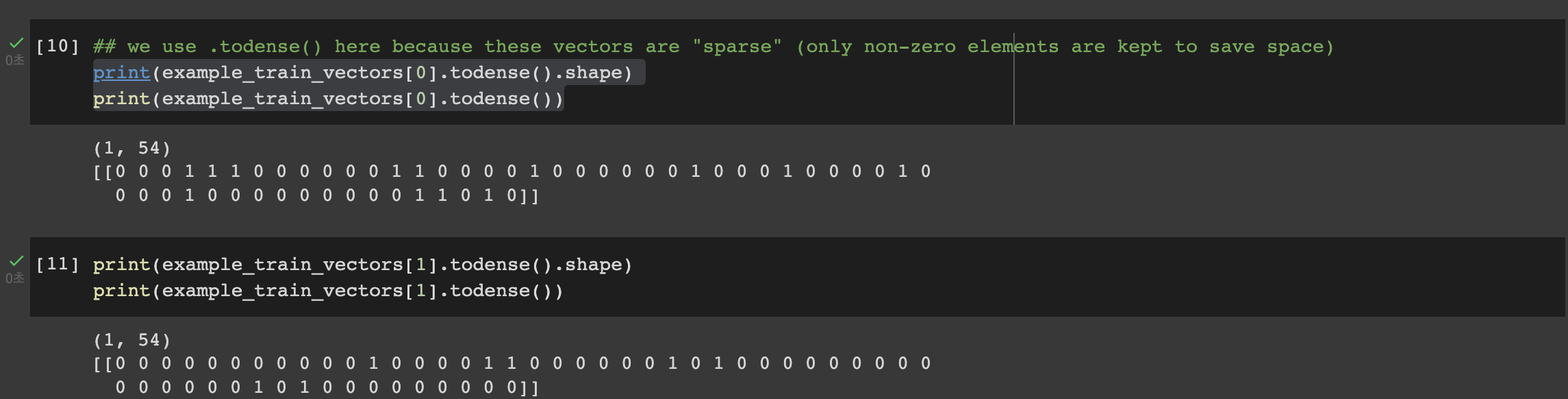
: 단어들의 출현 빈도(frequency)로 여러 문서들을 벡터화하는 것
- scikit-learn
- NLP 모델 사용시 데이터 전처리 과정에서 자주 쓰임
- 모두 소문자로 변환시키기 때문에 me 와 Me 는 모두 같은 특성이 되는 단점이 있음
Example
-> 카운팅한 전체 단어에 순서를 매긴 후, 이 문장 속 단어가 몇번쓰였는지 숫자로 나타내줌

MLOps