
_id
MongoDB 도큐먼트는 모든 도큐먼트가 _id 필드를 기본값으로 반드시 가지고 있어야 한다는 공통점이 있습니다.
이 _id 필드의 값은 각 도큐먼트를 구별하는 역할을 합니다.
도큐먼트 내부의 필드와 값이 똑같다 할지라도, _id 값이 다르면 서로 다른 도큐먼트로 간주합니다.
반면에 도큐먼트 내 필드와 값이 다르다고 하더라도, _id 값이 같다고 하면 서로 같은 도큐먼트로 여겨 에러를 발생시킵니다.
따라서 각 도큐먼트는 고유한 _id 값을 가지고 있어야 합니다.
도큐먼트를 추가할 때 _id 필드와 값을 특정하지 않았다면, 자동적으로 _id 필드가 생성되고 값에 ObjectId 타입이 할당됩니다.
insert
mongo shell을 사용하여 컬렉션에 새로운 도큐먼트를 추가해 보도록 하겠습니다.
먼저 터미널을 사용해 아틀라스 클러스터에 연결하고, MongoDB에서 제공하는 샘플 데이터를 받아옵니다.
그리고 그 데이터베이스 중 사용하려는 데이터베이스로 이동을 합니다.

이 도큐먼트를 MongoDB 샘플 데이터베이스 중 하나인 zips라고 하는 컬렉션에 삽입해 보도록 하겠습니다.
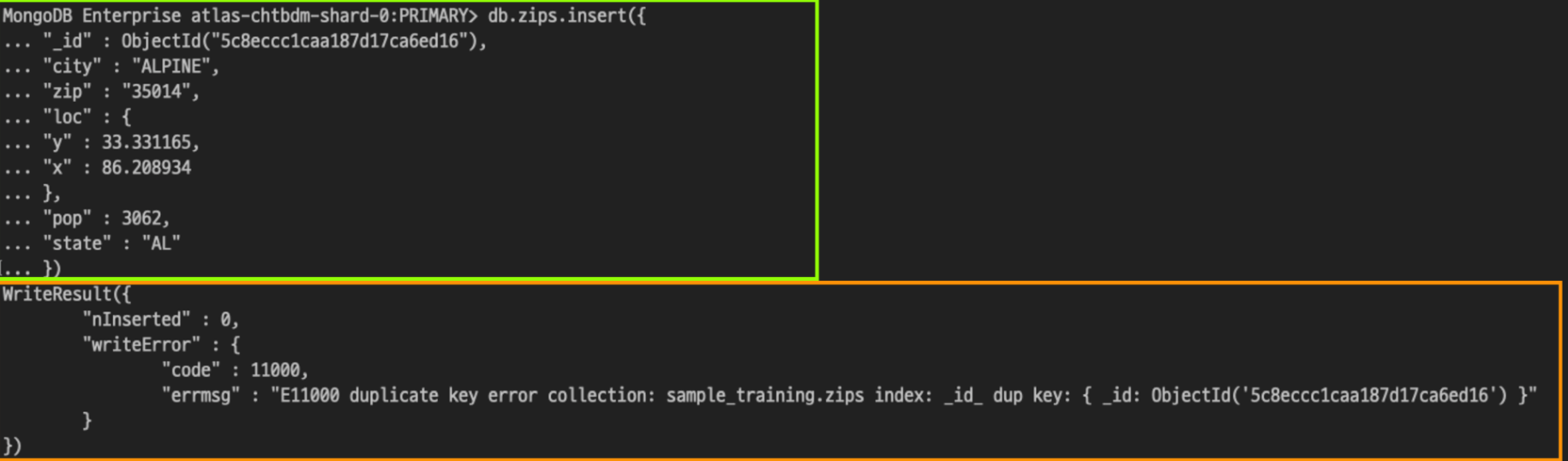
insert를 이용하여 도큐먼트를 삽입하기 위해서는 shell에 작성된 것과 같이 insert( )의 괄호 안에 삽입하고자 하는 도큐먼트를 작성합니다.
그리고 이 명령어에 따른 결과물이 하단에 WriteResult로 출력됩니다.
살펴보니 “nInserted”라는 항목이 존재합니다. 이 항목은 삽입된 도큐먼트의 수를 의미합니다.
이 부분이 0인 것으로 보아, 삽입된 도큐먼트가 없다는 뜻이므로 도큐먼트 추가에 실패했다는 것을 알 수 있습니다.
아래 writeError라는 부분을 통해, duplicate key 에러라고 하는 이유로 추가가 되지 않았음을 알 수 있습니다.
duplicate key 에러는 이미 같은 _id 값을 가지는 도큐먼트가 컬렉션 내부에 존재하기 때문에 중복된 데이터는 삽입할 수 없다는 것을 의미합니다.
그러면 이번에는 같은 데이터이지만 _id 값을 지운 도큐먼트를 zips 컬렉션에 추가해 보도록 하겠습니다.
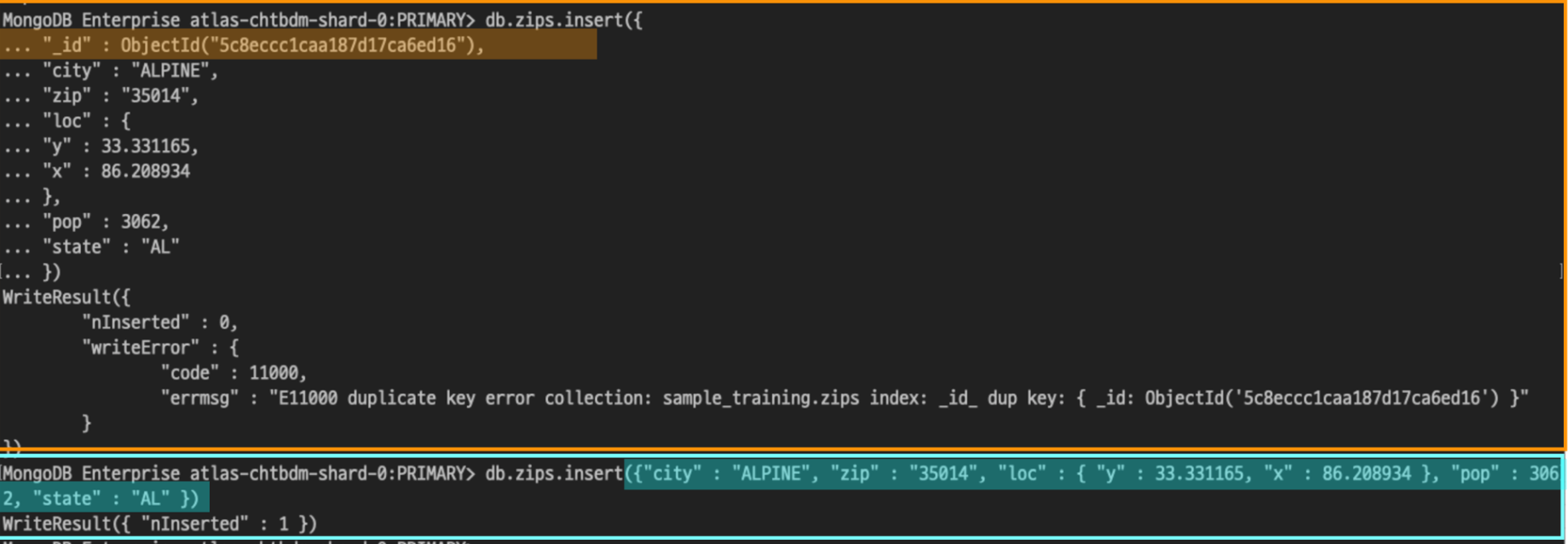
이번에도 마찬가지로 명령어에 따른 결과가 출력되었습니다.
결과를 보기 전에, 주황색 블록으로 작성된 부분에서는 _id 값을 볼 수 있습니다.
그러나 동일한 도큐먼트의 내용을 가지고 있지만, 아래 파란색 블록의 부분에서는 _id 값을 삭제한 후 삽입 작업을 실행하였습니다.
그 결과, WriteResult({“nInserted” : 1}) 로 zips 컬렉션에 우리가 작성한 1개의 도큐먼트가 삽입되었다는 것을 알 수 있습니다.
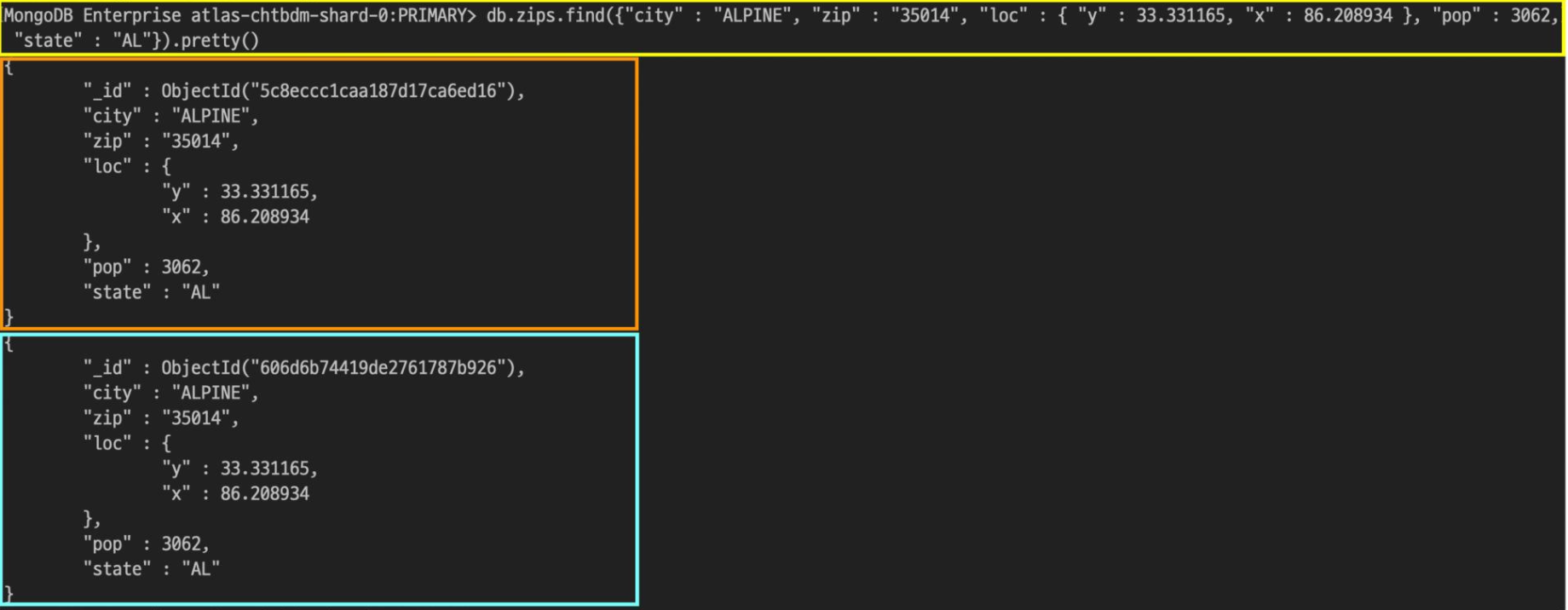
같은 필드와 값으로 find 명령어를 이용해 검색을 해보겠습니다.
검색을 해보니 2개의 결과가 출력됩니다.
하나는 기존 데이터베이스에 존재하던 도큐먼트이고, 또 다른 하나는 방금 추가한 도큐먼트입니다.
두 결과의 유일한 차이점은 _id 값이고, 두 번째로 삽입한 도큐먼트에는 _id 필드값을 추가하지 않았음에도 도큐먼트가 삽입될 때 자동적으로 해당 값이 추가되었습니다.
그리고 기본 값으로 ObjectId를 생성하여 할당하였다는 것을 알 수 있었습니다.
이처럼 _id 값에 따라 도큐먼트가 구별된다는 것을 duplicate key 에러를 통해 다시 한번 확인했습니다.
Reference
- show collections
- db.컬렉션이름.insert()
- db.컬렉션이름.find()
다수의 도큐먼트 삽입하기
db.inspections.insert([{”test1”:”1”}, {”test2”:”2”}, {”test3”:”3”}])
다량의 도큐먼트가 삽입될 때, 삽입이라는 작업을 수행하기 위한 기본 프로세스가 배열 안의 리스트 된 순서대로 진행된다. (만약 첫번째와 두번째 인덱스의 _id가 같은 값으로 지정 되면, 첫번째 값은 들어가고 두번째 값에서 에러)
그러나 { “ordered”:”false” }옵션이 추가되면 순서 상관 없이 고유한 _id 를 가진 도큐먼트는 모두 삽입된다.
존재하지 않는 컬렉션에 도큐먼트를 삽입하면, 해당 inspection이 자동으로 생성되고 데이터도 삽입된다.
READ
READ와 FIND 사용
mongo "mongodb+srv:아틀라스 클러스터 uri" --username
// 아틀라스 클러스터 접속
show dbs
// 데이터베이스 리스트 출력
// DB name - 용량
// sample_mongo - 0.001GB
use sample_training => 읽을 데이터베이스 선택
> db.zips.find({"state":"NY"})
// sample_training DB에서 zips 컬렉션 중 state가 NY인 데이터 검색 이때, find 명령어에 따른 실제 결과물은 화면에 출력된 것보다 훨씬 많지만 화면에는 랜덤하게 선택된 20개 결과물만 출력됩니다.
해당 조건에 맞는 다음 20개의 도큐먼트를 조회하기 위해서는 iterate의 줄임말인 it 명령어를 사용해야 합니다.
두 가지의 조건을 주고 싶다면, 그 조건을 find(<쿼리문1, 쿼리문2>)의 형태로 적어주면 됩니다.
두 개의 쿼리문 사용하기
> db.zips.find({“state” : “NY”, “city” : “ALBANY”})
// state가 NY이고, city가 ALBANY인 데이터 출력모든 데이터를 조회(find()) - db.zips.**find()**
결과를 읽기 쉽게 출력(pretty()) - db.zips.find().**pretty()**
결과 데이터 수 출력(count()) - db.zips.find().**count()**
한가지 결과만 출럭(findOne()) - db.zips.**findOne**({"id": ObjectId("sa89d7787dsf")}) 또는 db.zips.**findOne**()
Reference
- show dbs
- db.컬렉션이름.find().count()
- db.컬렉션이름.find()
- cursor.pretty() - cursor는 find 메소드를 실행해서 얻어낸 결과의 집합
- db.컬렉션이름.findOne()
UPDATE
updateOne - 다수의 도큐먼트 중 기준에 맞는 첫번째 도큐먼트만 업데이트
updateMany - 쿼리와 일치하는 모든 도큐먼트 업데이트
db.zips.updateMany({"city":"ALPINE"}, {"$**inc**":{"pop":10}})
// 첫 번째 인자에는 어떤 도큐먼트를 업데이트할지 결정하는 조건
// 두 번째 인자는 발생할 업데이트 내용을 특정 -> inc: 해당 필드의 값 증가
// pop 필드를 10씩 증가시키는 명령 (increse pop 10)
db.zips.updateOne({"zip":"12534"}, {"$**set**": {"pop":6235}})
// $set: 해당 필드 값 변경만약, 필드 이름을 잘못 입력 했다면 해당 필드를 추가하고 값을 할당시킨다.
$push - 배열로 이루어진 필드의 값에 요소를 추가
db.grades.updateOne({“student_id” : 250, “class_id” : 339},
{"$**push**": {"scores":{“type” : “extra credit”, “score” : 100}}})
// 연산자 | 삽입할 필드 | 추가할 서브 도큐먼트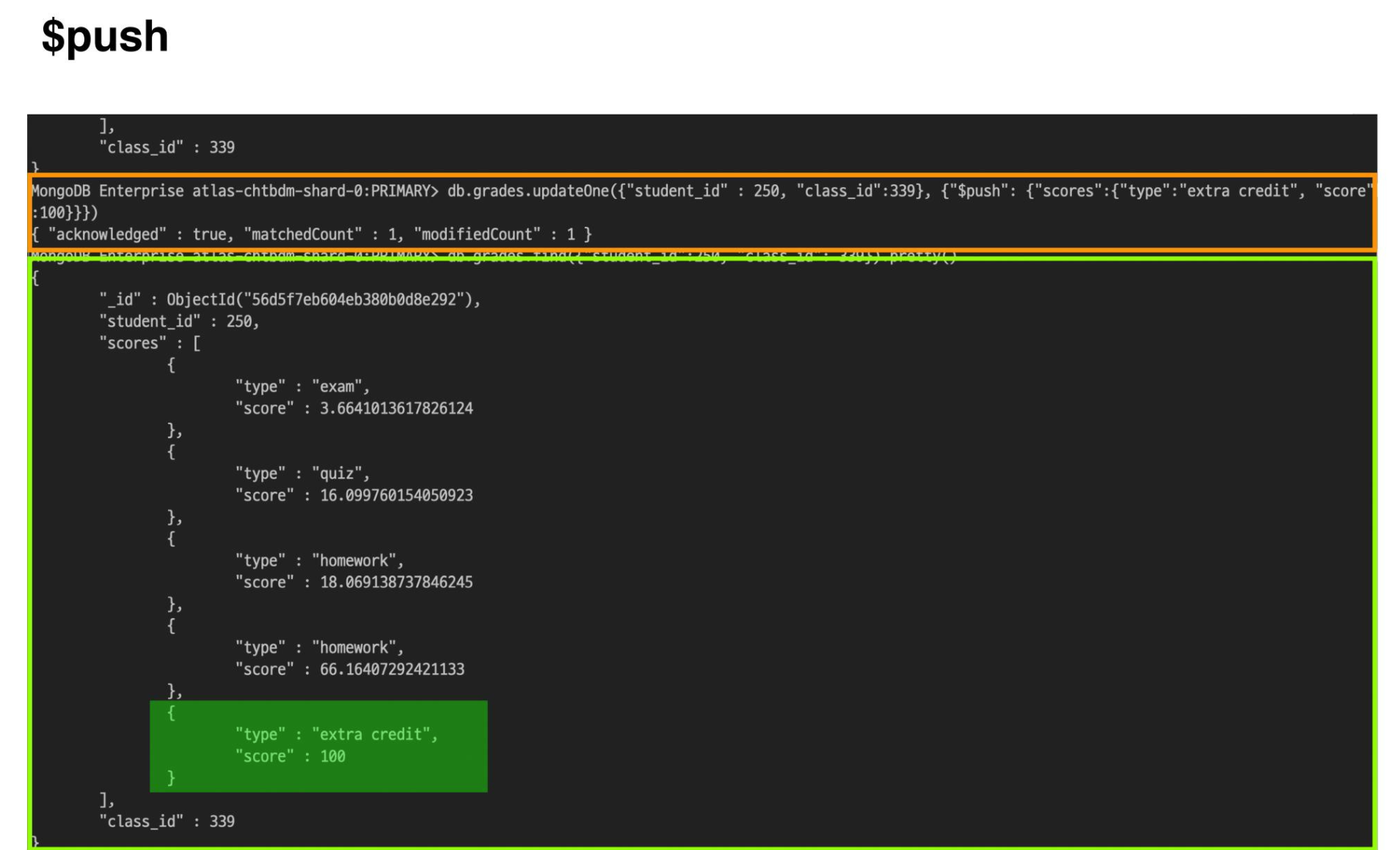
Reference
- db.컬렉션이름.updateOne()
- db.컬렉션이름.updateMany()
- 연산자
- $inc
- $set
- $push
DELETE
deleteOne - 일치하는 도큐먼트 중 첫번째 도큐먼트를 삭제
deleteMany - 일치하는 모든 도큐먼트 삭제
db.collection_name.drop() - 해당 컬렉션 삭제
컬렉션 삭제는 drop, 도큐먼트 삭제는 deleteOne, deleteMany
