쉽게 배우는 운영체제 2판 책을 통해 내용을 정리한 글입니다!
입출력 시스템
입출력장치와 채널
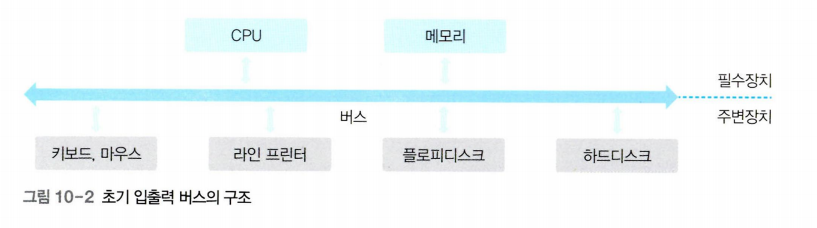
컴퓨터는 필수장치인 CPU와 메모리, 주변장치인 입출력장치와 저장장치로 구성되며, 각 장치는 메인보드에 있는 버스로 연결된다.
데이터 전송 속도에 따라 저속 주변장치와 고속 주변장치로 구분 할 수 있다.
- 저속 주변장치: 메모리와 주변장치 사이에 오고 가는 데이터 양이 적어 데이터 전송률이 낮은 장치를 말한다.
- 예) 키보드
- 고속 주변장치: 메모리와 주변장치 사이에 대용량의 데이터가 오고 가므로 데이터 전송률이 높은 저장 장치를 말한다.
- 예) 그래픽카드, 하드디스크
데이터가 지나다니는 하나의 통로를 채널이라고 부른다.

전송 속도가 비슷한 장치끼리 묶어서 장치별로 채널을 할당하면 여러 채널을 효율적으로 사용하여 전체 데이터 전송 속도를 향상할 수 있다.
입출력 버스의 구조
- 초기 구조: 모든 장치가 하나의 버스로 연결되고, CPU가 작업을 진행하다가 입출력 명령을 만나면 직접 입출력장치에서 데이터를 가져왔다. 이를 풀링(polling) 방식이라고 한다.
- 입출력 제어기를 사용한 구조: 모든 입출력 제어기(I/O controller)에 맡기는 구조
입출력 제어기(I/O controller): 입출력 제어기는 CPU와 키보드와 같은 주변 장치 간의 데이터 흐름을 관리하는 컴퓨터 시스템의 장치 또는 구성요소이다. 입출력 컨트롤러 라고도 부른다.

현대에는 고해상도의 모니터와 3D 게임이 보급되면서 그래픽 카드가 많은 양의 데이터를 전송하게 되면서 입출력 버스를 고속 입출력 버스와 저속 입출력 버스로 분리하여 운영한다.
두 버스 사이의 데이터 전송은 채널 선택기(channel selector)가 관리한다.
정리:
현대 컴퓨터는 CPU와 메모리를 연결하는 메인버스, CPU와 그래픽카드를 연결하는 그래픽 버스, 고속 주변장치를 연결하는 고속 입출력 버스, 저속 주변장치를 연결하는 저속 입출력 버스를 사용한다.
주소 버스: 데이터를 가져올 주소
데이터 버스: 실제로 송수신되는 데이터
제어 버스: 명령어의 시작과 종료, 데이터의 이동 방향, 오류 처리, 인터럽트

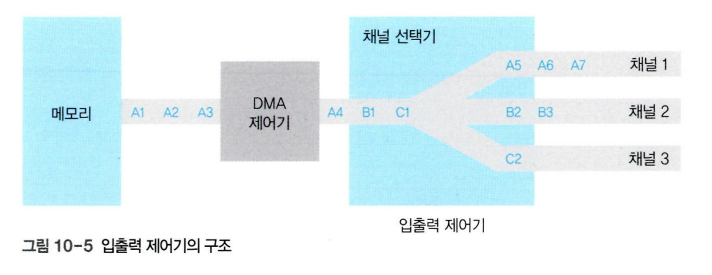
직접 메모리 접근
직접 메모리 접근(DMA)은 CPU의 도움 없이도 메모리에 접근할 수 있도록 입출력 제어기에 부여된 권한이다. 입출력 제어기에는 직접 메모리 접근을 위한 DMA 제어기가 마련되어 있다.
입출력 제어기는 여러 채널에 연결된 주변장치로부터 전송된 데이터를 적절히 배분하여 하나의 데이터 흐름을 만든다.
채널 선택기는 여러 채널에서 전송된 데이터 중 어떤 것을 메모리로 보낼지 결정한다.
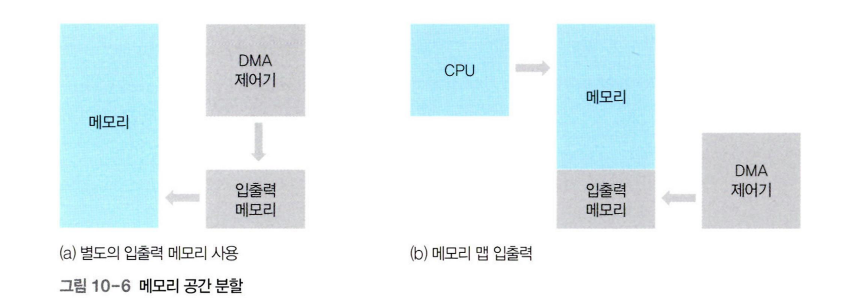
메모리 맴 입출력(MMIO):
- 메인메모리의 주소 공간 중 일부를 DMA 제어기에 할당하여 작업 공간이 겹치는 것을 막는다.
- 메모리에 접근하기 위한 주소공간과 입출력 장치에 접근하기 위한 주소 공간을 하나의 주소 공간으로 간주하는 방법
- 메모리와 입출력 장치에 같은 명령어 사용 가능
인터럽트
입출력 제어기가 DMA 제어기의 협업으로 작업이 완료되면 입출력 제어기는 CPU에 인터럽트를 보낸다. 인터럽트는 주변장치의 입출력 요구나 하드웨어의 이상 현상을 CPU에 알려주는 신호다.
외부 인터럽트:
- 입출력장치로부터 오는 인터럽트뿐 아니라 전원 이상이나 기계적인 오류로 발생하는 인터럽트
- 하드웨어 인터럽트라고도 부른다.
내부 인터럽트:
- 숫자를 0으로 나누거나 주소 공간을 벗어나서 작업하는 것과 같이 프로세스 오류와 관련된 인터럽트
- 예외 상황 인터럽트라고도 부른다.
시그널(signal):
- 사용자의 의지로 사용자가 직접 발생시키는 인터럽트
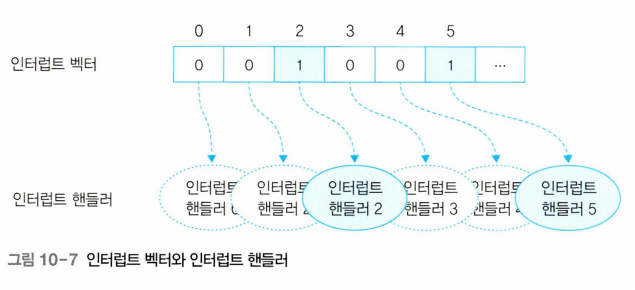
인터럽트 벡터와 인터럽트 핸들러
인터럽트 벡터:
- 여러 인터럽트 중 어떤 인터럽트가 발생했는지 파악하기 위한 자료구조
- 인터럽트벡터의 값이 1이면 인터럽트가 발생했다는 의미
인터럽트 핸들러:
- 인터럽트의 처리 방법을 함수 형태로 만들어 놓은 것
- 운영체제는 인터럽트가 발생하면 인터럽트 핸들러를 호출하여 작업한다.
- 사용자가 발생시키는 인터럽트인 시그널의 경우 자신이 만든 인터럽트 핸들러를 등록할 수도 있다.
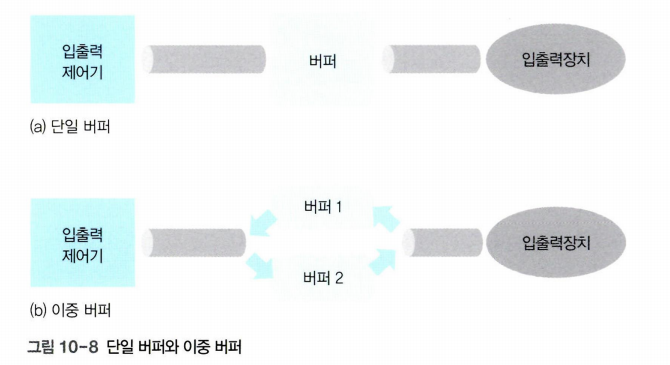
단일 버퍼와 이중 버퍼
- 버퍼는 속도가 다른 두 장치의 속도 차이를 완화하는 역활을 한다.
- 주변장치뿐 아니라 커널에서도 버퍼를 사용한다.
- 커널이 입출력장치로 보내야 할 데이터를 버퍼에 담아 놓으면 입출력 제어기가 커널 버퍼에서 입출력장치로 데이터를 보낸다.
- 스폴러를 사용하는 프린터도 버퍼를 사용한다.
단일 버퍼와 이중 버퍼의 차이
- 단일 버퍼(single buffer)보다는 이중 버퍼(double buffer)를 사용하는 것이 버퍼 운용에 유리하다.
- 단일 버퍼를 사용하면 데이터를 버퍼에 담는 작업과 버퍼에 있는 데이터를 퍼 가는 작업을 동시에 하기가 어렵다.
- 이중 버퍼를 사용하면 한 버퍼는 데이터를 담는 용도로 쓰고 다른 버퍼는 데이터를 가져가는 용도로 쓸 수 있다.
저장장치
저장장치의 종류
하드디스크
- 하드디스크의 정확한 이름은 움직이는 헤드를 가진 하드디스크 드라이브(moving-head hard disk drive)다.
- 하드디스크는 원반을 사용한 저장장치로, 맨 앞에 있는 데이터나 맨 뒤에 있는 데이터에 접근하는 속도가 거의 비슷하여 수많은 시스템에서 본격적으로 도입했다.
- 하드디스크는 메모리를 보조하는 장치라는 의미에서 제2저장장치라고도 불린다.
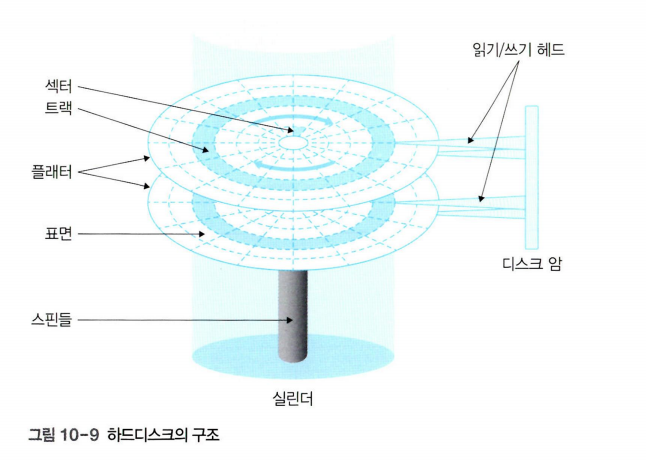
- 하드디스크는 스핀들(spindle)이라는 원통 축에 여러 개의 플래터(platter)가 달려 있다.
플래터
- 플래터는 표면에 자성체가 발려 있어 자기를 이용하여 0과 1의 데이터 저장 가능
- 플래터의 표면이 N극을 띠면 0으로, S극을 띠면 1로 인식
- 플래터의 수는 하드디스크마다 다르지만 보통 2장 이상으로 수성되며 항상 일정한 속도로 회전
- rpm(rotation per minute): 분당 회전 수
섹터와 블록
섹터:
- 하드디스크의 가장 작은 저장 단위
- 하나의 섹터에는 한 덩어리의 데이터가 저장
블록:
- 하드디스크와 컴퓨터 사이에 데이터를 전송하는 논리적인 저장 단위 중 가장 작은 단위
- 여러 개의 섹터로 구성되며, 윈도우 운영체제에서는 블록 대신 클러스터(cluster)라고 표현
하드디스크 입장에서는 섹터가 가장 작은 저장 단위이지만, 운영체제 입장에서는 하드디스크에 데이터를 보내거나 받을 때 블록이 가장 작은 단위가 된다.
트랙과 실린더
- 트랙(trak): 플래터에서 회전축을 중심으로 데이터가 기록되는 동일한 동심원상에 있는 섹터의 집합.
- 실린더(cylinder): 여러 개의 플래터에 있는 같은 트랙의 집합
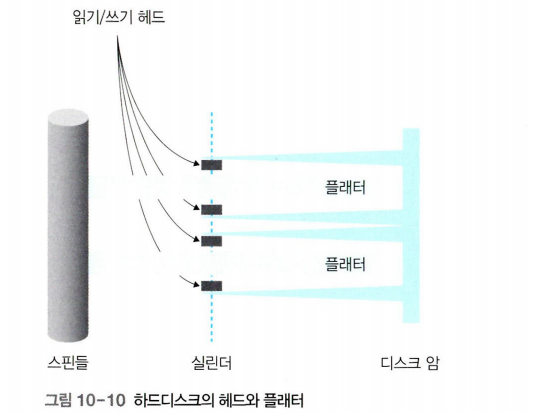
헤드와 플래터
- 하드디스크에서 데이터를 읽거나 쓸 때는 읽기/쓰기 헤드(read/write head)를 사용한다.
- 헤드의 수는 데이터가 저장되는 플래터의 표면 수와 같다.
- 플래터가 회전을 시작하면 표면에 약한 바람이 일어나는데, 헤드는 이 바람에 의해 표면에서 약간 떠 있는 형태로 작동한다.
- 만약 헤드가 프래터에 붙어버리면 고속으로 회전하는 플래터 표면에 상처가 생길 수도 있다. 이렇게 플래터 표면에 상처가 나면 데이터를 저장할 수 없는 배드 섹터(bad sertor)가 된다.
파킹(parking): 컴퓨터가 종료될 때 헤드가 플래터의 표면에 흠집을 내지 않도록, 하드디스크는 헤드를 데이터가 저장되지 않는 플래터의 맨 바깥쪽으로 이동하는데 이를 파킹(parking)이라고 한다.
SSD
SSD(Solid State Disk):
- 하드디스크의 느린 속도를 대체하기 위해 개발된 보조저장장치
- SSD는 전원이 사라져도 데이터를 보관할 수 있는 플래시 메모리로 구성된다.
- 메모리를 이용하기 때문에 속도가 빠를 뿐 아니라 모터와 같이 물리적으로 움직이는 부품이 없어서 소음을 발생 시키지 않는다.
- 크기가 작고 외부 충격에 강하며 소모되는 전력량과 발열 수준이 하드디스크보다 낮다.
- 입출력 속도가 매우 빠르다.
- 반면 같은 용량의 하드디스크에 비해 가격이 훨씬 비싸다.
하드디스크와 SSD 공통점과 차이점
공통점:
-
둘 다 단편화 현상이 발생한다.
차이점:
-
하드디스크의 경우 조각이 많이 발생하며 큰 덩어리의 데이터를 읽을 때 헤드가 여러 곳을 돌아다녀야 하므로 속도가 느려진다. 따라서 주기적으로 조각 모음을 실시해야 한다.
-
SSD는 메모리를 사용하기 때문에 데이터가 어디에 저장되어 있든 읽거나 쓰는 속도에는 차이가 거의 없다. SSD에서는 단편화가 데이터 접근 속도에 영향을 미치지 않기 때문에 조각 모음이 필요 없다.
CD
- CD는 하드디스크처럼 원반을 사용하는 저장장치로, 휴대할 수 있는 소형 원반에 데이터를 저장한다.
- 하드디스크와 마찬가지로 CD도 트랙과 섹터로 구성되어 있다.
- CD는 표면에 미세한 홈이 파여 있어 헤드에서 발사된 레이저가 홈에 들어가 반사되지 않으면0, 반사되어 있으면 1로 인식한다.
- 레이저를 쏘아 표면을 태워서 미세한 홈을 만드는 방식으로 데이터를 저장한다.
하드디스크와 CD의 비교
하드디스크:
- 하드디스크는 성능을 나타내는 단위로 rpm을 사용
- 하드디스크에서는 디스크가 작동하는 동안 플래터가 일정한 속도로 돌아간다.
- 바깥쪽에서 안쪽으로 데이터가 채워진다.
CD:
- CD는 20배속, 40배속과 같이 '배속'이라는 단위를 사용
- CD에서는 헤드 위치에 따라 디스크의 회전 속도가 변하기 때문에 표현하는 용어가 다르다.
- CD는 안쪽에서 바깥쪽으로 데이터가 채워진다.
-
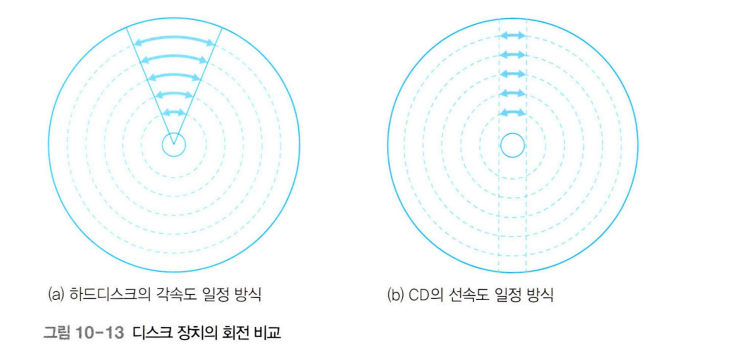
각속도 일정 방식의 회전: 하드디스크의 플래터는 항상 일정한 속도로 회전하여 바깥쪽 트랙의 속도가 안쪽 트랙의 속도보다 훨씬 빠르다. 그러므로 가장 바깥쪽에 있는 섹터가 가장 안쪽에 있는 섹터보다 더 크다. 일정한 시간 동안 이동한 각도가 같다는 의미에서 각속도 일정(constant angular velocity) 방식이라고 한다.
-
선속도 일정 방식의 회전: CD에서 사용하는 선속도 일정(constant linear velocity) 방식의 경우 어느 트랙에서나 단위 시간당 이동 거리가 같다. 이를 구현하려면 헤드가 안쪽 트랙에 있을 때는 디스크의 회전 속도를 빠르게 하고, 바깥쪽 트랙으로 이동했을 때는 디스크의 회전 속도를 느리게 해야 한다.
-
각속도 일정 방식의 섹터: 각속도 일정 방식의 하드디스크는 트랙마다 속도가 다르기 때문에 섹터의 크기도 다르다. 모드 트랙의 섹터 수가 같고 바깥쪽 섹터의 크기가 안쪽 섹터보다 크다. 안쪽 트랙에 비해 바깥쪽 트랙으로 갈수록 낭비되는 공간이 생긴다는 것이 단점이다. 디스크가 일정한 속도로 회전하기 때문에 구동 장치가 단순하고 조용하게 작동한다는 것이 장점이다.
-
선속도 일정 방식의 섹터: 선속도 일정 방식의 CD는 모든 트랙의 움직이는 속도가 같고 섹터의 크기도 같다. 안쪽 트랙보다 바깥쪽 트랙에 더 많은 섹터가 존재하므로 모든 트랙의 섹터 수가 다르다. CD는 한정된 공간에 많은 데이터를 담을 수 있고 하드디스크처럼 바깥쪽 트랙의 섹터 공간이 낭비되는 문제가 없으나 모터 제어가 복잡하고 소음이 발생한다는 단점이 있다.
디스크 장치의 데이터 전송 시간
- 하드디스크의 특정 섹터에 저장된 데이터를 읽거나 쓰려면 그 섹터가 있는 트랙까지 헤드가 이동해야 한다. 이처럼 헤드가 현재 위치에서 특정 트랙까지 이동하는데 걸리는 시간을 탐색 시간(seek time)이라고 한다.
- 특정 트랙까지 이동한 헤드는 플래터가 회전하여 원하는 섹터를 만날 때까지 기다린다. 이처럼 원하는 섹터를 만날 때까지 회전하는데 걸리는 시간을 회전 지연 시간(rotatonal latency time)이라고 한다.
- 헤드는 원하는 섹터에 있는 데이터를 읽어 전송하는데, 이때 걸리는 시간을 전송 시간(transmission time)이라고 한다.
디스크의 데이터 전송시간:
데이터 전송 시간 = 탐색 시간 + 회전 지연 시간 + 전송 시간
디스크 스케줄링
디스크 스케줄링(disk scheduling)은 트랙의 이동을 최소화하여 탐색 시간을 줄이는데 목적이 있다.

FCFS 디스크 스케줄링
FCFS(First Come First Service) 디스크 스케줄링은 요청이 들어온 트랙 순서대로 서비스 한다.
아래 그림에서 헤드가 이동한 총 거리는 7+9+6+8+20+4+5+6=65다
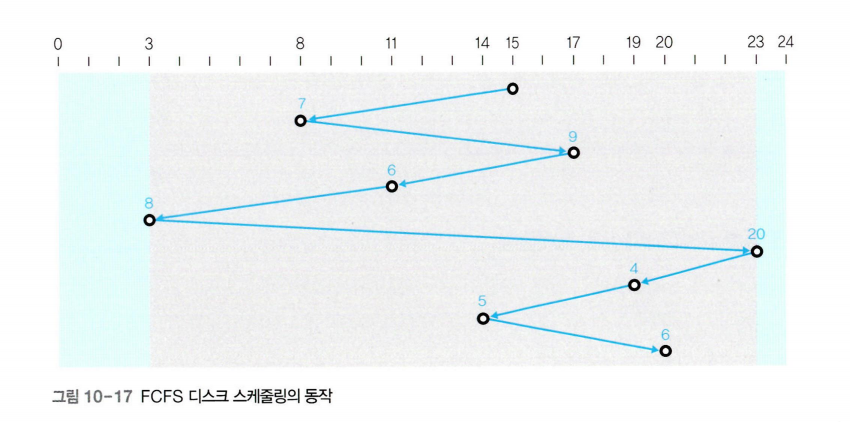
동그라미 위에 숫자는 바로 앞 트랙에서 헤드가 이동해 온 거리를 나타내고, 가운데의 회색 부분은 이동한 영역을, 바깥쪽 하늘색 부분은 헤드가 지나가지 않은 영역을 나타낸다.
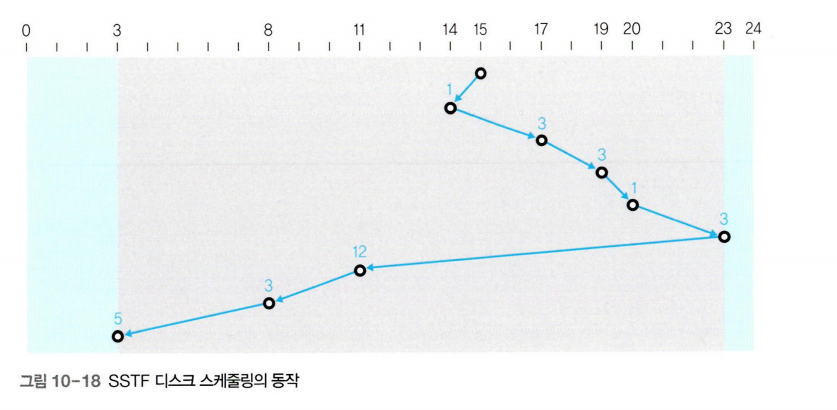
SSTF 디스크 스케줄링
SSTF(Shortest Seek Time First) 디스크 스케줄링은 현재 헤드가 있는 위치에서 가장 가까운 트랙부터 서비스 한다. 만약 다음에 서비스할 두 트랙의 거리가 같다면 먼저 요청받은 트랙을 서비스 한다. SSTF 디스크 스케줄링은 효율성이 좋지만 아사 현상을 일으킬 수 있다.
이동한 총 거리 -> 1+3+3+1+3+12+3+5=31
블록 SSTF 디스크 스케줄링
SSTF 디스크 스케줄링의 공평성 위배를 어느 정도 해결한 방법이다.
블록 SSTF 디스크 스케줄링에서는 큐에 있는 트랙 요청을 아래 그림과 같이 일정한 블록 형태로 묶는다.
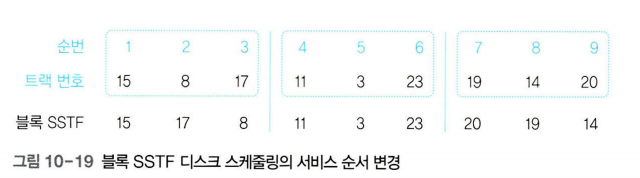
SSTF 디스크 스케줄링에서는 현재 트랙에서 가장 먼 트랙을 큐의 맨 끝으로 이동하지만 블록 SSTF 디스크 스케줄링에서는 현재 트랙에서 가장 먼 트랙을 블록의 끝으로 이동한다. 따라서 멀리 있는 트랙도 몇 번만 양보하면 서비스를 받을 수 있다. (에이징 적용)
성능은 FCFS 디스크 스케줄링 만큼 좋지 못하다.
이동한 총 거리 -> 2+9+3+8+20+3+1+5=51

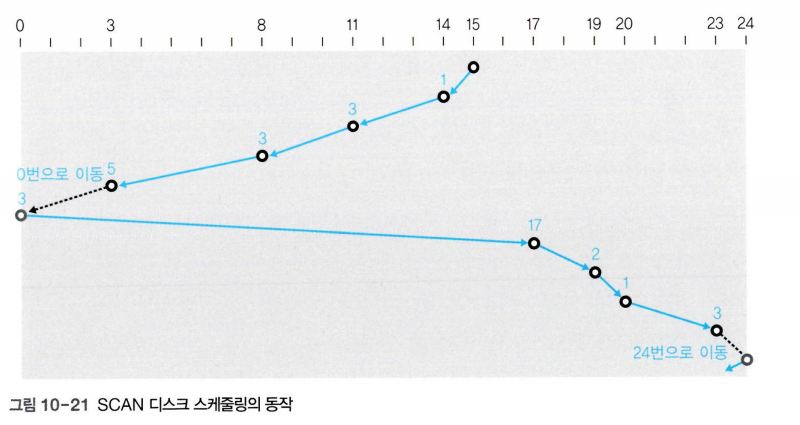
SCAN 디스크 스케줄링
SCAN 디스크 스케줄링은 SSTF 디스크 스케줄링의 공평성 위배 문제를 완화하기 위해 만들어진 기법이다. SCAN 디스크 스케줄링에서는 헤드가 한 방향으로만 움직이면서 서비스 한다. 헤드가 움직이기 시작하면 맨 마지막 트랙에 도착할 때까지 되돌아가지 않고 계속 앞으로만 전진하면서 요청받은 트랙을 서비스 한다.
이동한 총 거리 -> 1+3+3+5+3+17+2+1+3=38
C-SCAN 디스크 스케줄링
SCAN 디스크의 공평성 위배를 해결한 기법이다. SCAN 디스크 스케줄링을 변형한 것으로, 헤드가 한쪽 방향으로 움직일 때는 요청받은 트랙을 서비스 하고 반대 방향으로 돌아올 때는 서비스 하지 않고 이동만 한다.
C-SCAN은 작업 없이 헤드를 이동하기 때문에 매우 비효율적이다.
이동한 총 거리 -> 1+3+3+5+3+24+1+3+1+2=46 (SCAN 디스크 스케줄링보다는 성능이 좋지 않다.)

Look 디스크 스케줄링
Look 디스크 스케줄링은 SCAN 디스크 스케줄링의 불필요한 부분을 제거하여 효율을 높이는 기법이다. SCAN 디스크 스케줄링에서는 트랙 요청이 없어도 헤드가 맨 마지막 트랙에 도착한 후에야 방향을 바꾸지만, LOOk 디스크 스케줄링에서는 더 이상 서비스할 트랙이 없으면 헤드가 끝까지 가지 않고 중간에서 방향을 바꾼다.
이동한 총 거리 -> 1+3+3+5+17+2+1+3+=35

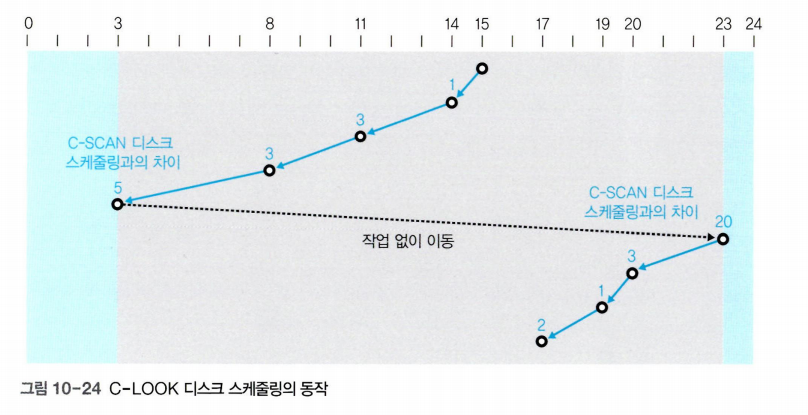
C-LOOK 디스크 스케줄링
C-LOOK (Circular LOOK) 디스크 스케줄링은 C-SCAN 디스크 스케줄링의 LOOK 버전이다. C-LOOK 디스크 스케줄링은 한쪽 방향으로만 서비스하는 C-SCAN 디스크 스케줄링과 유사하지만 더 이상 서비스할 트랙이 없으면 헤드가 중간에서 방향을 바꿀 수 있다는 점이 다르다.
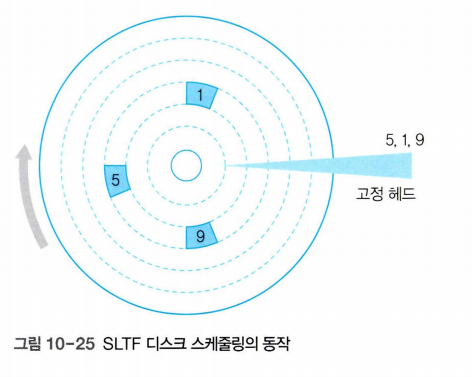
SLTF 디스크 스케줄링
SLTF(Shortest Latency Time First) 디스크 스케줄링은 헤드가 고정된 저장장치에 적용되는 스케줄링 기법이다.
SLTF 디스크 스케줄링에서는 작업 요청이 들어온 섹터의 순서를 디스크가 회전하는 방향에 맞추어 다시 정렬한다.
RAID
RAID(Redundant Array of Independent Disks)는 자동으로 백업하고 장애가 발생하면 이를 복구하는 시스템이다.
RAID는 동일한 규격의 디스크를 여러 개 모아 구성하며, 장애가 발생했을 때 데이터를 복구하는 데 사용된다.
데이터를 여러 조각으로 나누어 보내는 방식을 스트라이핑(striping)이라고 한다.
RAID 0(스트라이핑)
RAID 0은 병렬로 연결된 여러 개의 디스크에 데이터를 동시에 입출력할 수 있도록 구성된다.

- 위에 그림 처럼 4개의 디스크의 A1, A2, A3, A4를 동시에 저장한다.
- RAID 0은 장애 발생 시 복구하는 기능이 없기 때문에 장애가 발생하면 데이터를 잃는다.
RAID 1(미러링)
RAID 1에서는 하나의 데이터를 2개의 디스크에 나누어 저장하여 장애 시 백업 디스크로 활용한다.
같은 데이터를 똑같이 복사하는 것을 미러링이라고 부른다.

- RAID 1은 같은 크기의 디스크를 최소 2개 이상 필요로 하며 짝수 개의 디스크로 구성된다.
- 같은 데이터를 여러 디스크에 저장하기 때문에 장애 발생 시 미러링된 디스크를 활용하여 데이터를 복구할 수 있다.
- RAID 1의 단점은 저장하는 데이터와 같은 크기의 디스크가 하나 더 필요하기 때문에 비용이 증가한다.
- 같은 내용을 두 번 저장하기 때문에 속도가 느려질 수 있다.
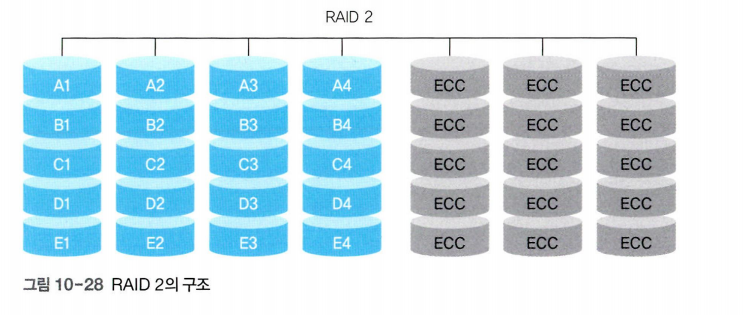
RAID 2
RAID 2에서는 오류를 검출하는 기능이 없는 디스크에 대해 오류 교정 코드(ECC)를 따로 관리하고, 오류가 발생하면 이 코드를 이용하여 디스크를 복구한다.
- RAID 2에서는 데이터가 비트 단위로 저장된다.
- 비트 단위로 저장하는 이유는 각 비트의 오류 교정 코드를 구성하여 나중에 비트 단위로 복구하기 위해서다.
- RAID 2는 n개의 디스크에 대해 오류 교정 코드를 저장하기 위해 n-1개의 추가 디스크를 필요로 하므로 RAID 1보다는 저장 공간이 적게 든다.
- 오류 교정 코드를 계산하는데 많은 시간이 소요된다.
- 오류 검출 코드: 오류가 발생했는지 확인할 수 있는 코드로, 패리티 비트(parity bit)가 대표적이다.
- 오류 교정 코드: 오류가 발생했는지 확인하는 동시에 오류를 교정할 수 있는 코드로, 해밍 코드(hamming code)가 대표적인 예다.
RAID 3
RAID 3과 RAID 4에서는 오류 검출 코드인 패리티 비트를 사용하여 데이터를 복구한다.
RAID 3은 섹터 단위로 데이터를 나누어 저장한다.
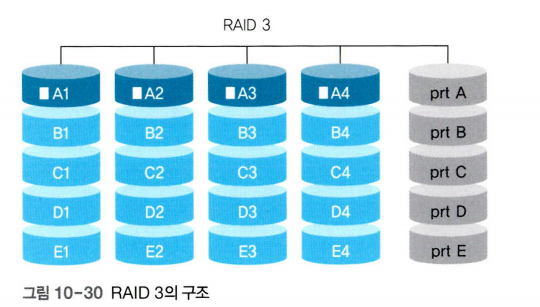
오류가 없는 섹터를 이용하여 오류가 있는 섹터의 데이터를 복원할 수 있는데 이를 'N-way 패리티 비트 방식'이라고 한다.
RAID 3에서는 N-way 패리티 비트를 구성한 후 데이터 디스크가 아닌 별도의 디스크에 보관함으로써 장애 발생 시 오류를 복구한다.
RAID 4
RAID 4는 RAID 3과 같은 방식이지만 처리하는 데이터가 블록 단위로 되어 있다.
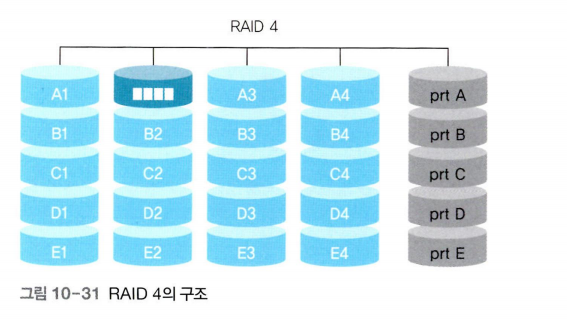
RAID 3에서는 데이터를 읽거나 쓸 때 패리티 비트를 구성하기 위해 모든 디스크가 동시에 동작해야 한다는 단점이 있지만 RAID 4에서는 데이터가 저장되는 디스크와 패리티 비트가 저장되는 디스크만 동작한다.
RAID 5
RAID 4는 병목 현상이 발생한다. 또한 패리티 비트가 저장된 디스크와 다른 디스크에서 동시에 장애가 발생할 경우 복구가 안 된다는 치명적인 단점이 있다.
RAID 5는 RAID 4와 같은 방법을 사용하지만 병목 현상을 해결한 기법이다.
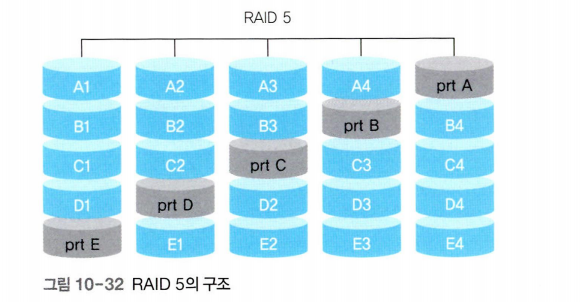
RAID 5는 패리티 비트를 여러 디스크에 분산하여 보관함으로 써 패리티 비트 디스크의 병목 현상을 완화한다. 또한 RAID 4에서 패리티 비트가 있는 디스크가 고장 나면 복구가 어렵다는 문제도 해결한다. RAID 5에서는 패리티 비트를 해당 데이터가 없는 디스크에 보관한다.
RAID 6
RAID 6은 RAID 5와 같은 방식이지만 패리티 비트가 2개다.
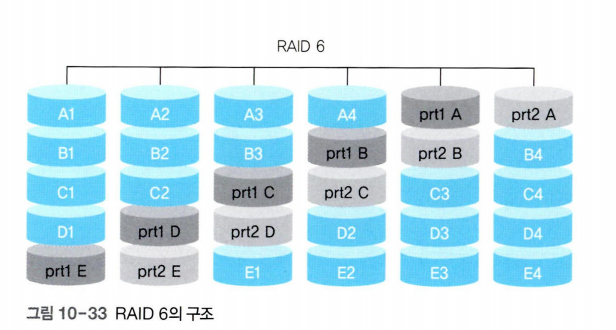
RAID 5는 한 디스크에 장애가 발생했을 때는 복구가 가능하지만 디스크 2개에 동시에 장애가 발생했을 때는 복구가 불가능하다. 디스크 2개에 동시에 장애가 발생하면 패리티 비트가 사라지기 때문이다.
RAID 6는 패리티 비트를 2개로 구성하여 분산하므로 디스크 2개의 장애를 복구할 수 있다. 하지만 RAID 6은 패리티 비트를 2개씩 운영하기 때문에 RAID 5보다 계산량이 많다는 것과 4개의 디스크당 2개의 추가 디스크가 필요하다는 단점이 있다.
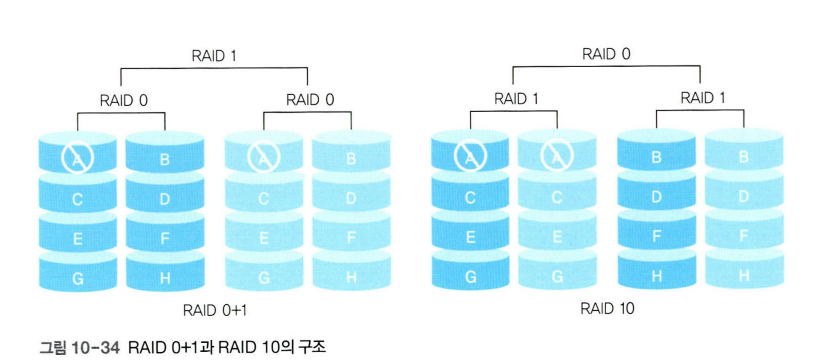
RAID 10
빠른 입출력이 장점인 RAID 0과 복구 기능이 있는 RAID 1의 결합
-
4개의 디스크를 2개씩 묶어 RAID 1로 구성하며, RAID 1로 묶인 디스크를 RAID 0으로 다시 묶는다.
-
병렬로 데이터를 처리하여 입출력 속도를 높일 수 있다.
-
장애 발생 시 미러링된 디스크로 복구가 가능하다.
-
RAID 10은 일부 디스크만 중단하여 복구할 수 있다.
RAID 50과 RAID 60
RAID 10과 마찬가지로 RAID를 0으로 묶어 성능을 높이는 방식
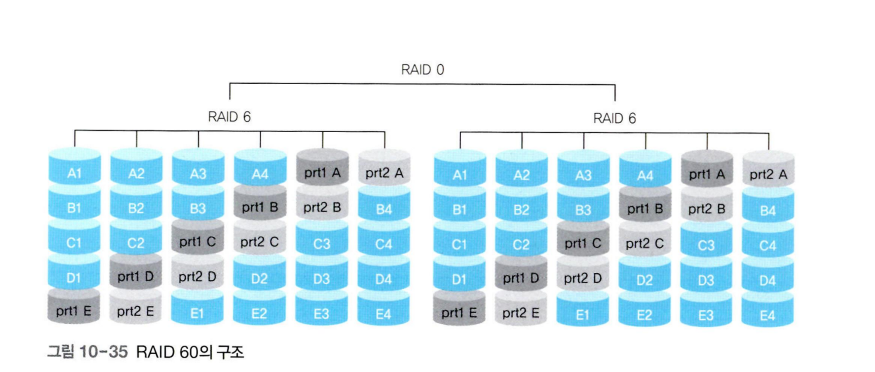
RAID 50과 RAID 60은 RAID 10에 비해 추가되는 디스크의 수가 적지만 입출력 시 계산량이 증가한다.
