https://arxiv.org/pdf/1802.05814
생성 모델은 대표적으로 학습 데이터의 분포를 기반으로 샘플링하는 Explicit density 방식과 분포를 모른 상태로 샘플링하는 Implicit density 방식으로 나뉨.
이 논문은 Explicit density 기반의 VAE를 넷플릭스가 추천시스템에서 활용한 논문.
전반적으로 VAE와 유사하나 디코더 부분에서 어느 분포를 가정하는 정도의 차이를 보임.
Abstract
본 논문은 VAEs를 implicit feedback에 기반한 협업 필터링에 확장하여 적용하였음.
implicit feedback
ex ) 좋아요 버튼을 누르지 않았지만, 여러 번 본 콘텐츠
-
기존의 협업 필터링은 선형 모델에 의존했는데, 이는 복잡한 데이터 구조를 잘 반영하지 못하는 한계가 존재. 변분 오토인코더는 비선형 모델로, 복잡한 상호작용을 잘 반영.
-
추천을 생성하는 과정에서 데이터를 다항 분포로 가정하고, 베이지안 추론을 통해
모델의 파라미터를 추정. -
목적 함수를 학습할 때, 기존 VAEs는 과도하게 정규화 되었다고 판단하고
anneling 기법을 통해 개선한 regularization parameter를 사용하였음.
Introduction
기존 추천 시스템은 평균 정밀도 (mAP) 등의 순위 기반 척도를 활용하여 평가되었음.
그러나, Top-N ranking loss는 최적화하기 어렵기 때문에 이전에는 근사치를 사용.
이후 넷플릭스 팀은 multinomial likelihood이 암시적 피드백 데이터 모델링에 적합하며 가우시안, 로지스틱보다 ranking loss를 줄이는데 효과적임을 주장.
추천 시스템은 보통 수많은 사용자와 아이템이 존재하기 때문에 big data problem으로 여겨짐.
그러나 대부분의 사용자는 전체 아이템 중 극히 일부만 상호작용하기 때문에
우리가 필요한 상호작용 데이터는 매우 적어 small-data problem으로 봐야함.
따라서, sparse signals로부터 오버피팅을 방지하고자 본 논문에서는 확률적 잠재 변수 모델
(probabilistic latent-variable)을 구축하고 베이지안 접근법을 사용.
추천시스템에서 VAEs의 SOTA 성능을 달성하기 위해서는 아래와 같음.
1. multinomial likelihood 데이터 분포 사용
2. 기존 VAEs 목적함수의 regularization term 개선
Method
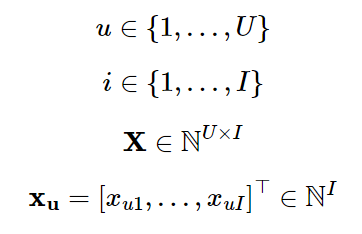
- 𝑈 : 총 사용자 수
- 𝐼 : 총 아이템 수
- 𝑢 :개별 사용자
- 𝑖 : 개별 아이템
- 𝑋 : 사용자와 아이템 간의 상호작용 행렬
행렬 𝑋는 총 𝑈 명의 사용자가 총 𝐼 개의 아이템을 클릭한 횟수를 말하며 그 크기는 𝑈×𝐼.
의 클릭 데이터 는 Bag-of-Words 방식으로 각 아이템 𝑖에 대한 클릭 횟수를 요소로 가짐.
암시적 피드백 데이터를 다루기 위해 행렬 𝑋는 이진화.
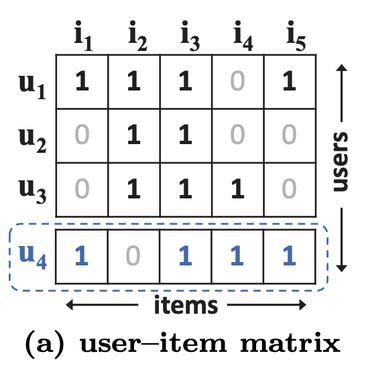 ( 이런 식으로 )
( 이런 식으로 )
Model
변분 오토 인코더를 활용한 추천 시스템에서 사용자의 클릭 데이터를 생성하는 과정
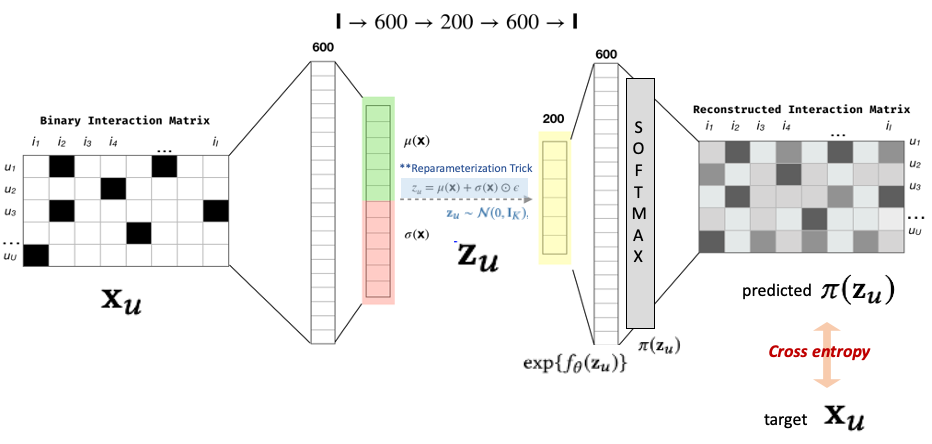
여기서 생성 과정은 사용자 에 대해 개의 차원을 가진 잠재 표현 에서 샘플링 됨.
이때 는 기존 VAE와 같이 인코더를 거쳐 표준 정규 분포 (Standard Gaussian)를 겟또.
는 디코더에 해당하는 비선형 함수 를 지나 변환되고, 이 값에 softmax를 적용하여 normalization을 진행. 이때 softmax output 값은 로 아이템 에 대한
유저 의 확률 분포가 됨.
사용자 𝑢의 아이템 총 클릭 수 가 주어졌을 때, 클릭 데이터 는 확률 를 가지는 다항 분포에서 샘플링되었다고 가정.
위 식은 잠재 요인 관점에서 유저 에 대한 log-likelihood로 다중 클래스 분류의 Cross Entopy와 동일.
우변을 보면 를 통해 0이 아닌 (실제로 클릭된 아이템)에 대해 확률 질량을 분배.
그러나 다항 분포는 softmax로 인해 의 합이 언제나 1이어야하기 때문에
모델은 상대적으로 높은 선호도를 가진 아이템에 더 많은 확률을 할당함.
: 이는 평가 지표인 Top-N Ranking Loss에서 좋은 성능을 내는 데 기여.
VAEs vs MultVAE
[ 기존 VAEs ]
- 이진 분류 : 이항분포 (Bernoulli) → Sigmoid → Binary Cross Entropy
- 회귀 : 정규분포 (Gaussian) → MSE
[ MultVAE ]
- 다중 클래스 분류 : 다항 분포 → Softmax → Cross Entropy
Variational inference
생성 모델을 학습하기 위해 MultVAE도 VAEs처럼 변분 추론를 이용하여 파라미터 를 추정.
변분 추론은 계산하기 어려운 후방 분포 를 가우시안 분포 로 근사하여 학습.
결과적으로는 KL 발산을 최소화하여 가 실제 후방 분포에 최대한 가까워지도록
를 최적화하는 것이 목표!
Amortized inference & the variational autoencoder
데이터셋에서 유저와 아이템의 수가 많을수록 최적화 해야하는 의 개수도 증가.
이는 수백만 명의 유저와 아이템이 있는 현실 세계에서 병목 현상을 초래함.
따라서 VAE에서는 개별 매개변수를 계산하는 대신 data-dependent 함수 (추론 모델) 를 사용.
이는 MultVAE의 인코더이며 posterior에 근사하는 변분 분포 는 아래와 같음.
는 유저의 클릭 데이터 를 기반으로 잠재 변수 의 가우시안 분포를 근사함.
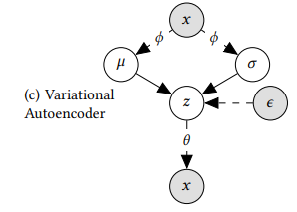
즉, 데이터를 입력하면 추론 모델이 평균 과 분산 으로 정의된 변분 분포 의
매개변수 를 출력하고 이 분포를 최적화하면 계산하기 어려운 posterior 를 근사 !
이때 와 생성 모델 를 함께 사용하면
오토인코더와 유사한 구조가 되어 변분 오토인코더 (VAE)라는 이름이 붙었음
Learning VAEs
VAE는 주변 우도 (marginal likelihood)를 통해 lower bound를 최대화하고자 함.
이때 는 베이즈 정리에서 이름이 evidence로 붙여졌기 때문에 위의 부등식의 우변을
Evidene Lower Bound, 이른바 ELBO라 함.
다시 말해, VAE는 ELBO를 최대화하는 방식으로 학습되며
우변의 KL Divergence를 최소화할 때, 를 에서 샘플링하여 파라미터를 추정해야 함.

그러나 샘플링은 에 대해 미분이 안되기 때문에 reparametrization trick을 사용.
에서 샘플링하여 로 다시 재파라미터화 시킴.
이를 통해 샘플링 과정의 확률성이 분리되어 샘플링 되어진 에 대해 역전파가 가능해짐.
Alternative interpretation of ELBO
사실 본 논문은 기존과 달리, ELBO를 아래와 같은 시각에서 해석하였음

첫번째 항은 모델이 데이터를 얼마나 잘 재구성하는지 (reconstruction error)를 나타내며
두번재 항인 KL divergence는 모델의 정규화 (regularization) 역할을 한다고 해석.
두 항은 trade-off 관계이며 정규화를 제어하는 를 도입하여 ELBO를 확장한 새로운 목적 함수를 제시.
기존 VAE는 생성 모델로서 데이터를 생성하는 데 초점을 맞추고 있지만,
추천 시스템에서는 데이터를 생성하기보다는 정확한 추천을 제공하는 것이 더 중요함.
따라서 MultVAE는 데이터 생성 능력을 너프시키더라도 추천 성능을 높이는 방향으로 를 선택.
Selecting
에서 시작하여 까지 점진적으로 증가시켜 KL을 늘리며 최적의 값을 선택.
이러한 탐색 과정을 KL annealing 이라 함.
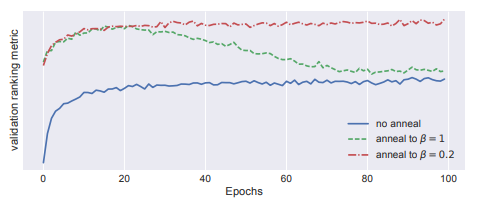
- annealing 없는 경우 성능이 낮으며 (파랑)
- 까지 annealing 하면 1에 가까워질수록 성능이 하락함 (초록)
- 최적의 지점까지 annealing을 하고 멈춘 경우에 성능이 가장 높았음 (빨강)
KL annealing은 VAE를 학슴함에 있어 추가적인 runtime을 초래하지 않기 때문에 효율적.
A taxonomy of autoencoders
변분 오토인코더 (VAE) vs 오토인코더 (AE)
AE 관점에서의 최대 우도 추정은 아래와 같고
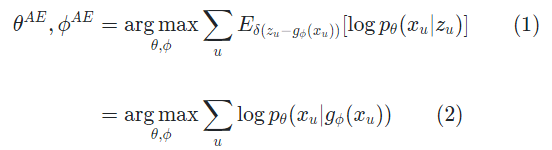
AE와 DAE는 지금까지의 VAE와는 구분되는 특징을 갖는데
AE와 DAE는 을 통해 (1)을 최적화 시킴. 즉, 생성 데이터와 원본의 차이를 줄이는 식으로 학습한다는 것. 그래서 VAE처럼 를 prior에 맞출 필요가 없음 !
그러나 0이 아닌 에만 확률을 분배하기 때문에 오버피팅 가능성이 높아진다는 문제가 존재.
따라서 DAE (Denoising AutoEncoder)는 입력 데이터에 dropout 같은 노이즈를 추가하여 이를 해결
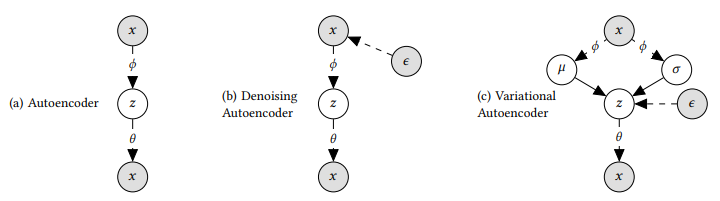
- (a) : 입력을 재구성하는 데 집중
- (b) : 입력에 노이즈 를 추가하여 학습
- (c) : VAE 묘사. 앞에서 이미 설명했으므로 pass
+) 참고로 Mult-DAE는 다항 분포 가능성을 사용하는 DAE의 변형 모델.
Prediction
훈련된 생성 모델을 바탕으로 Mult-VAE와 Mult-DAE는 동일한 매커니즘으로 예측을 수행.
유저의 과거 클릭 데이터 가 주어지면 정규화되지 않은 다항 확률 을 통해
모든 아이템을 순위화시킴.
- Mult-VAE : 변분 분포의 평균값 를 잠재 표현 로 사용
- Mult-DAE : 인코더의 출력 을 그대로 로 사용
이때 는 사용자의 클릭 데이터를 기반으로 생성된 확률을 예측하는 데 사용됨.
VAE는 평균과 분산 2개를 생성하고 DAE는 하나의 파라미터만 생성하기 때문에 실무에서 빠른 추론이 필요하다면 DAE 계열을 사용하는 것이 나을 수 있음. 그러나 두 모델의 성능 차이가 그리 큰 편은 아님 !
Related works
VAEs on sparse data
최근 연구에 의하면 VAE는 large, sparse, high-dimensional 데이터를 모델링 할 때 underfitting 됨.
해당 논문에서도 annealing을 수행하지 않거나 β = 1로 설정할 경우, 유사한 이슈 발생.
따라서 β ≤ 1 로 설정하면 collaborative filtering 관점에서 항상 유저의 click history에 기반하여 예측.
Information-theoretic connection with VAE
VAE 모델은 유저의 click history를 기반으로 최대 엔트로피를 가지는 분포를 찾는 것이며,
위에서 정의한 ELBO의 regularization term은 이 때 β를 통해 prior를 얼마나 반영할지를 조절할지를 결정하는 파라미터. 더불어 β는 모델의 discriminative와 generative의 부분을 조절하는 역할.
Neural networks for collaborative filtering
신경망 기반 협업 필터링 초기 연구는 explicit feedback와 순위를 예측하는 것에 집중,
최근 연구는 implicit feedback에 중점을 둠.
본 연구와 가장 관련이 깊은 논문은 CDAE & NCF
Empirical Study
데이터셋은 옛날 것이고 성능은 아무튼 좋을거니까 관심있는 부분만 정리.
Metrics
& 두 개의 ranking 평가 지표 사용.
두 지표 모두 유저의 테스트 아이템의 예측 순위를 실제 순위와 비교하는 방식으로 계산.
- 사용자가 관심있는 아이템 중, 추천한 아이템 K개가 얼마나 포함되는지의 비율
- 는 순위 에 있는 아이템을 나타냄
- 는 indicator 함수
- 분모는 과 사용자가 클릭한 아이템 수 중 더 작은 값을 취함
- 의 최대값은 1, 이는 관련된 모든 아이템이 상위 R개의 순위에 있는 경우를 의미
- 상위 R개의 추천에 대한 순위 품질을 평가
- 추천 항목이 얼마나 중요한 순서대로 잘 배치되었는지를 반영
- 는 순위 에 따른 가중치를 주기 위해 사용됨
- NDCG@R은 DCG@R을 이상적인 DCG 값으로 나누어 0에서 1 사이로 정규화한 값
- 사용자의 클릭 아이템들이 모두 상위에 위치할 때 최댓값 1을 가짐
Experimental setup
strong generalization 하에 모든 유저를 training / validation / test 셋으로 분할.
training
전체 클릭 기록을 기반으로 모델을 학습.
validation & test
일부 클릭 기록을 통해 모델이 user-level representation을 학습하고
사용하지 않은 나머지 클릭 기록에 대해 성능을 평가.
훈련과 평가에서 동일한 사용자가 포함될 경우 일반화 평가가 쉬워지므로,
이를 해결하기 위해 훈련에 포함되지 않은 사용자 ( held-out user )들의 클릭 기록 80%를
랜덤하게 선택하여 fold-in set을 구성해 학습하고 나머지 20%로 예측 성능 평가.
VAE & DAE에 대해
[ 공통점 ]
- input layer에 대해 dropout(p=0.5) 적용
- batch_size= 500
- opimizer = Adam
- ML-20M 데이터셋의 경우, 200 epoch 동안 train
[ 차이점 ]
- Mult-DAE : input layer에 대해 활성화 함수로 tanh을 적용하고 L2 regularization 수행
- Mult-VAE : 인코더의 output이 가우시안 분포로 사용되기 때문에 0-hidden-layer MLP 구조 사용
참고 자료
https://huidea.tistory.com/297
https://pyy0715.github.io/VAE_CF/#222-alternative-interpretation-of-elbo
