SQL (Structured Query Language)
SQL이란?
Structured Query Language
DBMS(Database Management System)에서 데이터를 관리할 수 있게 하는 언어
- RDBMS(Relational-DBMS) - SQL Database
테이블을 분리하고 고유 ID를 연결하여 데이터를 관리한다.
데이터의 중복을 피하고 효율적으로 관리할 수 있다.
분리된 테이블을 JOIN해서 확인할 수 있다.
MySQL, Oracle, MongoDB, Cassandra, DinamoDB, Riak, Redis 등
- No-SQL Database 비관계형
명령어
SELECT
-- 모든 열 선택
SELECT * FROM Customers;
-- 원하는 열 선택
SELECT Country FROM Customers;DISTINCT
-- 뚜렷한(고유의) 값 선택 (중복되지 않은 데이터만 가져옴)
SELECT DISTINCT Country FROM Customers;WHERE
-- 원하는 행 선택
SELECT * FROM Orders
WHERE EmployeeID = 3;ORDER BY
-- 오름차순 정렬
SELECT * FROM Customers
ORDER BY ContactName (ASC);
-- 내림차순 정렬
SELECT * FROM Customers
ORDER BY ContactName DESC;LIMIT
-- 10개 데이터 가져오기
SELECT * FROM Customers
LIMIT 10;
-- 0 다음부터 10개 가져오기
SELECT * FROM Customers
LIMIT 0, 10;
-- 30 다음부터 10개 가져오기
SELECT * FROM Customers
LIMIT 30, 10;AS
SELECT
CustomerId AS '아이디',
CustomerName AS '고객명',
Address AS '주소'
FROM Customers;INSERT INTO
특정한 컬럼에 데이터를 넣을 때는 괄호 안에 컬럼명 명시
모든 컬럼에 넣을 때는 생략 가능
INSERT INTO Customers (CustomerName, City, Country)
VALUES ('Cardinal', 'Stavanger', 'Norway');UPDATE … SET
-- 해당하는 행의 데이터 값 업데이트
UPDATE Categories
SET CategoryName = 'First Category', Desciption = 'Hi'
WHERE CategoryID = 1;DELETE
-- 해당하는 행의 데이터 삭제
DELETE FROM Categories
WHERE CategoryID > 5
-- 테이블을 남기고 모든 행 삭제
DELETE FROM Customers;LIKE
WHERE 절과 함께 쓰임
-- a로 시작하는 데이터
SELECT * FROM Customers
WHERE CustomerName LIKE 'a%';
-- a로 끝나는 데이터
SELECT * FROM Customers
WHERE CustomerName LIKE '%a';
-- 두번째 글자에 r이 위치하는 데이터
SELECT * FROM Customers
WHERE CustomerName LIKE '_r%';Wildcards
WHERE 절과 함께 쓰임
| 기호 | 설명 | 예시 |
|---|---|---|
| % | 0또는 하나 이상의 문자 | bl% finds bl, black, blue, and blob |
| _ | 문자 하나 | h_t finds hot, hat, and hit |
| [] | 괄호 내의 문자 | h[oa]t finds hot and hat, but not hit |
| ^ | 괄호 내의 문자가 아닌 것 | h[^oa]t finds hit, but not hot and hat |
| - | 범위 내 문자 하나 | c[a-b]t finds cat and cbt |
IN
WHERE 절 내에서 여러개의 값을 가져올 때 씀 (여러개의 OR과 같음)
-- 괄호 안의 나라에 속하는 데이터 가져오기
SELECT * FROM Customers
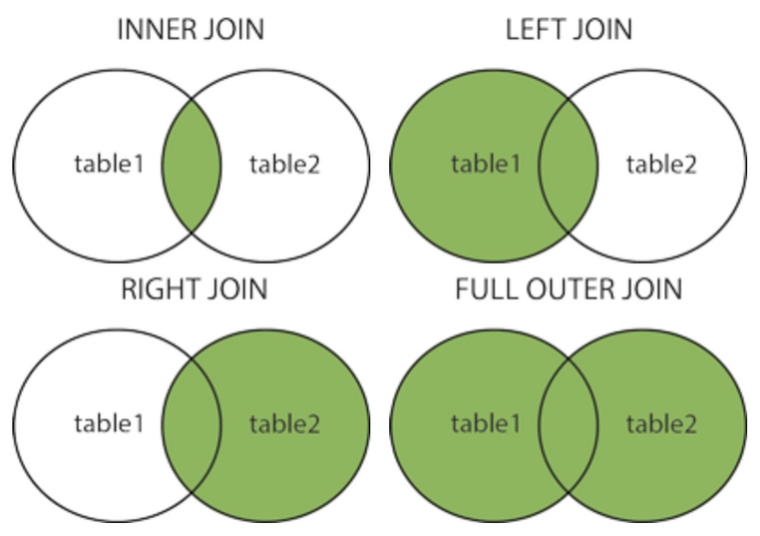
WHERE Country IN ('Germany', 'France', 'UK');JOIN
(INNER) JOIN: Returns records that have matching values in both tablesLEFT (OUTER) JOIN: Returns all records from the left table, and the matched records from the right tableRIGHT (OUTER) JOIN: Returns all records from the right table, and the matched records from the left tableFULL (OUTER) JOIN: Returns all records when there is a match in either left or right table
SELECT F.FLAVOR
FROM FIRST_HALF F
JOIN ICECREAM_INFO I
ON F.FLAVOR = I.FLAVOR
WHERE TOTAL_ORDER > 3000 AND INGREDIENT_TYPE = 'fruit_based'
ORDER BY F.TOTAL_ORDER DESC;연산자
| 연산자 | 의미 |
|---|---|
| +, -, *, / | 각각 더하기, 빼기, 곱하기, 나누기 |
| %, MOD | 나머지 |
| IS | 양쪽이 모두 TRUE 또는 FALSE |
| IS NOT | 한쪽은 TRUE, 한쪽은 FALSE |
| AND, && | 양쪽이 모두 TRUE일 때만 TRUE |
| OR, | |
| = | 양쪽 값이 같음 |
| !=, <> | 양쪽 값이 다름 |
| >, < | (왼쪽, 오른쪽) 값이 더 큼 |
| >=, <= | (왼쪽, 오른쪽) 값이 같거나 더 큼 |
| BETWEEN {MIN} AND {MAX} | 두 값 사이에 있음 |
| NOT BETWEEN {MIN} AND {MAX} | 두 값 사이가 아닌 곳에 있음 |
| IN (...) | 괄호 안의 값들 가운데 있음 |
| NOT IN (...) | 괄호 안의 값들 가운데 없음 |
| LIKE '... % ...' | 0~N개 문자를 가진 패턴 |
| LIKE '... _ ...' | _ 갯수만큼의 문자를 가진 패턴 |
사칙연산
| 연산자 | 의미 |
|---|---|
| +, -, *, / | 더하기, 빼기, 곱하기, 나누기 |
| % | 나머지 |
문자열 사칙연산
-- 사칙연산에서 문자열은 0으로 인식
SELECT 'ABC' + 3; -- 3
SELECT 'ABC' * 3; -- 0
-- 숫자로 구성된 문자열은 숫자로 인식
SELECT '1' + 3; -- 4참/거짓
- TRUE: 1
- FALSE: 0
MIN, MAX
-- 해당하는 열에서 가장 큰 값, 가장 작은 값을 가져옴
SELECT MAX(Price) AS LargestPrice, MIN(Price) AS SmallestPrice
FROM Products;COUNT, AVG, SUM
-- 데이터 개수를 가져옴
SELECT COUNT(DISTINCT Country) FROM Customers;
SELECT COUNT(*) FROM Products WHERE Price = 18;
-- 데이터 값 평균을 가져옴
SELECT AVG(Price) FROM Products WHERE CategoryID = 1;
-- 데이터 값 합을 가져옴
SELECT SUM(Price) FROM Products WHERE CategoryID = 1;숫자 관련 함수
| 함수 | 설명 |
|---|---|
| ROUND | 반올림 |
| CEIL | 올림 |
| FLOOR | 내림 |
| ABS | 절대값 |
| GREATEST | (괄호 안에서) 가장 큰 값 |
| LEAST | (괄호 안에서) 가장 작은 값 |
| 함수 | 설명 |
|---|---|
| MAX | 가장 큰 값 |
| MIN | 가장 작은 값 |
| COUNT | 갯수 (NULL값 제외) |
| SUM | 총합 |
| AVG | 평균 값 |
| POW(A, B), POWER(A, B) | A를 B만큼 제곱 |
| SQRT | 제곱근 |
| TRUNCATE(N, n) | N을 소숫점 n자리까지 선택 |
문자열 관련 함수
| 함수 | 설명 |
|---|---|
| UCASE, UPPER | 모두 대문자로 |
| LCASE, LOWER | 모두 소문자로 |
| CONCAT(...) | 괄호 안의 내용 이어붙임 |
| CONCAT_WS(S, ...) | 괄호 안의 내용 S로 이어붙임 |
| SUBSTR, SUBSTRING | 주어진 값에 따라 문자열 자름 |
| LEFT | 왼쪽부터 N글자 |
| RIGHT | 오른쪽부터 N글자 |
| LENGTH | 문자열의 바이트 길이 |
| CHAR_LENGTH, CHARACTER_LEGNTH | 문자열의 문자 길이 |
| TRIM | 양쪽 공백 제거 |
| LTRIM | 왼쪽 공백 제거 |
| RTRIM | 오른쪽 공백 제거 |
| LPAD(S, N, P) | S가 N글자가 될 때까지 P를 이어붙임 |
| RPAD(S, N, P) | S가 N글자가 될 때까지 P를 이어붙임 |
| REPLACE(S, A, B) | S중 A를 B로 변경 |
| INSTR(S, s) | S중 s의 첫 위치 반환, 없을 시 0 |
| CAST(A AS T) | A를 T 자료형으로 변환 |
| CONVERT(A, T) | A를 T 자료형으로 변환 |
시간/날짜 관련 함수
| 함수 | 설명 |
|---|---|
| CURRENT_DATE, CURDATE | 현재 날짜 반환 |
| CURRENT_TIME, CURTIME | 현재 시간 반환 |
| CURRENT_TIMESTAMP, NOW | 현재 시간과 날짜 반환 |
| DATE | 문자열에 따라 날짜 생성 |
| TIME | 문자열에 따라 시간 생성 |
| YEAR | 주어진 DATETIME값의 년도 반환 |
| MONTHNAME | 주어진 DATETIME값의 월(영문) 반환 |
| MONTH | 주어진 DATETIME값의 월 반환 |
| WEEKDAY | 주어진 DATETIME값의 요일값 반환(월요일: 0) |
| DAYNAME | 주어진 DATETIME값의 요일명 반환 |
| DAYOFMONTH, DAY | 주어진 DATETIME값의 날짜(일) 반환 |
| HOUR | 주어진 DATETIME의 시 반환 |
| MINUTE | 주어진 DATETIME의 분 반환 |
| SECOND | 주어진 DATETIME의 초 반환 |
| ADDDATE, DATE_ADD | 시간/날짜 더하기 |
| SUBDATE, DATE_SUB | 시간/날짜 빼기 |
| DATE_DIFF | 두 시간/날짜 간 일수차 |
| TIME_DIFF | 두 시간/날짜 간 시간차 |
| LAST_DAY | 해당 달의 마지막 날짜 |
| DATE_FORMAT | 시간/날짜를 지정한 형식으로 반환 |
| STR TO DATE(S, F) | S를 F형식으로 해석하여 시간/날짜 생성 |
날짜 형식
| 형식 | 설명 |
|---|---|
| %Y | 년도 4자리 |
| %y | 년도 2자리 |
| %M | 월 영문 |
| %m | 월 숫자 |
| %D | 일 영문(1st, 2nd, 3rd...) |
| %d, %e | 일 숫자 (01 ~ 31) |
| %T | hh:mm:ss |
| %r | hh:mm:ss AM/PM |
| %H, %k | 시 (~23) |
| %h, %l | 시 (~12) |
| %i | 분 |
| %S, %s | 초 |
| %p | AM/PM |
조건문 함수
| 형식 | 설명 |
|---|---|
| IF(조건, T, F) | 조건이 참이라면 T, 거짓이면 F 반환 |
| IFNULL(A, B) | A가 NULL일 시 B 출력 |

Software Engineer 🍊