
서론
팀 내부에서 그레이존 스터디를 통해 프로젝트를 진행하며 처음 접하거나, 모르는 부분을 탐구하고자 하였다. 첫번째 스터디에서는 신입으로 입사한 나를 위해 광고 도메인의 RTB를 이해하는 시간을 가졌고, 두번째 스터디에서는 스파크, 세번째는 하둡 + 스파크를 공부해보았고, 이 글은 세번째 스터디를 준비하며 공부한 내용을 기록한 글이다.
하둡을 왜사용할까
-
분산 저장이 가능하다
데이터를 한 서버에 몰아넣는 게 아니라, 수백~수천 대 서버에 쪼개서 저장한다. 한 서버가 죽어도 다른 서버에 복제본이 있으니까 데이터가 안 날라간다. -
대용량 배치 처리에 최적화됐다
MapReduce 방식으로 데이터를 병렬 처리하니까, 혼자 하면 며칠 걸릴 연산도 수백 대가 나눠서 빠르게 끝낼 수 있다. -
확장이 쉽다
서버 더 추가하면 그냥 성능이 늘어난다. 수평 확장(Scale-out)이 자연스럽게 된다. -
다양한 데이터 형식을 다 받는다
정형 데이터뿐 아니라 로그, 이미지, 텍스트 같은 비정형 데이터도 그냥 저장해두고 나중에 필요할 때 처리하면 된다.
예를들면 이해가 쉽다. 로그가 하루에 몇억건 이상 쌓이는 서비스가 있다고 가정해보자. 서버 하나에 해당 로그를 다 넣을 수도 있겠지만, 시간이 지나 로그가 쌓인다면 쿼리 성능은 처참할 것이다. 또한 DB서버가 다운될 수도 있다. 이전에 배웠던 인덱스 튜닝, 파티셔닝등을 해도 한계가 명확하다.
고성능 서버 한대로 업그레이드 하면 되지 않을까?
그래도 1년 뒤에는 데이터가 넘칠게 뻔하고, 서버 하나가 죽으면 전체적인 장애가 발생할 것이다.
그렇다면 하둡을 도입해보자. 일반 서버 20대에 하둡을 구성하면 어떻게 될까?
데이터는 20대에 나눠서 저장되고, 각 데이터는 복제된다. 서버 한두 대가 죽어도 데이터는 안전하다. 쿼리를 날리면 20대가 동시에 나눠서 처리하니까 속도도 압도적으로 빠르다. 비용도 고성능 서버 한 대보다 일반 서버 20대가 더 쌀 수 있다. 나중에 데이터가 더 늘어나면 서버 몇 대만 추가하면 그만이다.
로그뿐만 아니라 이미지, 텍스트, JSON 등 형식이 제각각인 데이터도 일단 하둡에 다 던져놓고 나중에 필요할 때 꺼내서 분석하면 된다. 기존 RDB였다면 스키마를 미리 정의해야 했겠지만, 하둡은 그런 제약이 없다.
결국 하둡은 "데이터가 너무 많아서 기존 방식으로는 감당이 안 될 때" 꺼내드는 도구다. 모든 서비스에 필요한 건 아니지만, 데이터가 폭발적으로 쌓이는 순간 하둡 같은 분산 시스템은 선택이 아니라 필수가 된다.
목표
- 하둡이 무엇인가?왜 사용하는지 알아본다.
- 하둡을 내부 HFDS에서 CSV파일을 읽는다.
- 도커를 통해 마스터1, 워커4개를 띄워 각각 Spark 설정을 한다.
- 워커 1개, 2개, 4개를 띄워서 분산처리를 하였을떄 속도 비교를 한다.
아키텍처
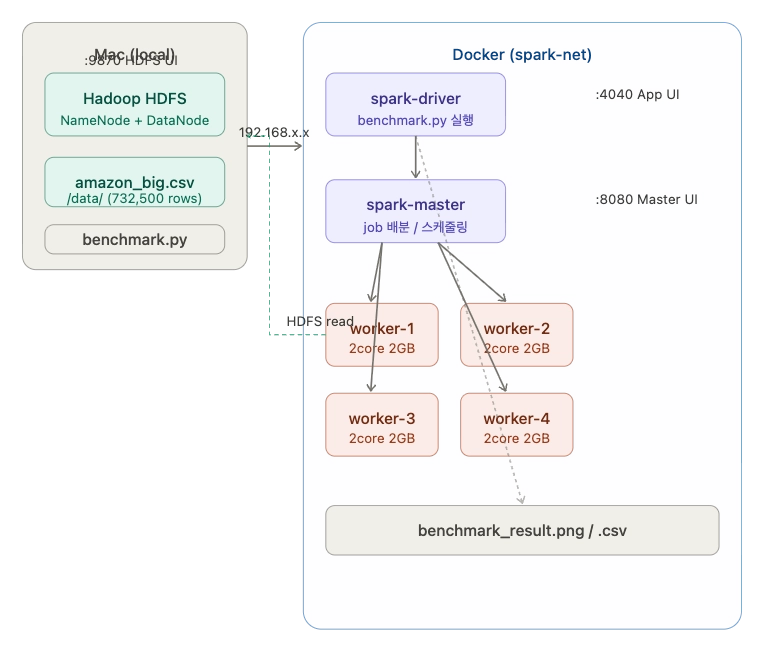
Mac (로컬) Docker (spark-net)
────────────────── ──────────────────────────────
Hadoop HDFS spark-driver
NameNode └── benchmark.py 실행
DataNode ↓ job 제출
/data/amazon_big.csv spark-master
(포트 9870, 9000) └── task 배분
spark-worker-1 (2core 2GB)
spark-worker-2 (2core 2GB)
spark-worker-3 (2core 2GB)
spark-worker-4 (2core 2GB)
↓ HDFS 읽기
192.168.x.x:9000 (Mac 로컬 IP)왜 이 구조인가
처음에는 Docker 안에 Hadoop까지 포함하려 했지만, Mac M1 (ARM64) 환경에서
Hadoop 이미지 호환 문제가 계속 발생했다. 결론적으로 Hadoop은 로컬 Mac에 직접
설치하고, Spark만 Docker로 구성하는 방식을 택했다.
Docker 컨테이너가 로컬 HDFS에 접근할 때는 localhost를 쓸 수 없다. localhost는
각 컨테이너 자신을 가리키기 때문이다. 대신 docker-compose.yml의 extra_hosts에
host.docker.internal:host-gateway를 설정하면, 컨테이너 안에서 host.docker.internal
이라는 주소로 Mac에 접근할 수 있다. Docker가 내부적으로 host-gateway를 Mac의 실제
IP로 변환해준다.
spark-dirver가 로컬의 benchmark.py를 어떻게 실행해주는 원리
docker-compose.yml에 이 설정이 있다:
spark-driver:
volumes:
- ../benchmark.py:/app/benchmark.py
이 설정이 하는 일:
로컬 Mac Docker spark-driver 컨테이너
───────────────── ──────────────────────────
~/JupyterProject/ /app/
benchmark.py ←마운트→ benchmark.py마운트는 복사가 아니라 연결이다. 로컬 파일과 컨테이너 안의 파일이 같은 파일을 가리킨다. 로컬에서 수정하면 컨테이너 안에서도 즉시 반영된다.
<실행 흐름>
```jsx
docker exec spark-driver python3 /app/benchmark.py
↓
1. spark-driver 컨테이너 안에서 python3 실행
2. /app/benchmark.py 읽음 (= 로컬 benchmark.py)
3. SparkSession 생성 → spark-master:7077 연결
4. HDFS에서 데이터 읽기 → 192.168.x.x:9000
5. Worker들한테 task 분배
6. 결과를 /tmp에 저장환경 구성
로컬 환경
| 항목 | 버전 |
|---|---|
| OS | macOS (Apple Silicon M1) |
| Hadoop | 3.4.3 (Homebrew) |
| Java | OpenJDK 11 |
| Python | 3.12 (uv 가상환경) |
Docker 환경
| 컨테이너 | 이미지 | 역할 |
|---|---|---|
| spark-master | custom-spark:3.5.0 | Spark Master |
| spark-worker-1~4 | custom-spark:3.5.0 | Spark Worker (2core, 2GB) |
| spark-driver | custom-spark:3.5.0 | benchmark.py 실행 |
custom-spark:3.5.0은 apache/spark:3.5.0 기반으로 pandas, matplotlib, pyspark를 추가 설치한 커스텀 이미지다.
왜 driver를 로컬에서 실행안하고 도커 내부로 두었는지
문제 상황
처음에는 benchmark.py를 로컬 PyCharm에서 직접 실행했다. count, GroupBy는 성공했지만 Sort, Join 같은 shuffle이 필요한 작업에서 계속 실패했다.
Failed to connect to /172.20.0.4:45565
Operation timed outshuffle이 뭔가
Sort나 Join 같은 작업은 여러 Worker에 흩어진 데이터를 재분배해야 한다.
Worker-1: [5, 2, 8]
Worker-2: [1, 9, 3]
↓ 전체 정렬하려면 데이터를 섞어야 함
Worker-1: [1, 2, 3] ← Worker-2 데이터 일부를 받아옴
Worker-2: [5, 8, 9]이 데이터 재분배 과정을 shuffle이라고 한다. shuffle이 끝나면 Worker들은 결과를 Driver에게 돌려줘야 한다.
Driver가 Docker 밖(로컬 Mac)에 있을 때 생기는 문제
로컬 Mac (Driver) Docker 내부 네트워크
────────────────── ──────────────────────
192.168.219.103 172.20.0.4 (worker-1)
172.20.0.5 (worker-2)
172.20.0.6 (worker-3)
172.20.0.7 (worker-4)Worker들이 shuffle 결과를 자신의 내부 IP에 올려놓는다.
Worker-1 → "결과를 172.20.0.4:45565 에 올려뒀어"
Driver → 172.20.0.4:45565 접근 시도
→ Connection timed out ❌172.20.0.x는 Docker 내부 네트워크 주소다. 로컬 Mac에서는 이 주소로 직접 접근이 안 된다. Docker가 포트 포워딩(8081, 8082 등)으로 일부 포트를 열어두긴 하지만, shuffle에서 사용하는 포트는 랜덤으로 생성되기 때문에 포워딩이 안 돼있다.
결국 Driver가 Worker의 shuffle 결과를 가져올 수 없어서 작업이 실패한다.
Driver를 Docker 안으로 이동하면 해결되는 이유
spark-driver 컨테이너를 추가해서 Driver도 같은 Docker 네트워크 안에 넣었다.
Docker spark-net (172.20.0.x 대역)
──────────────────────────────────
spark-driver 172.20.0.2 ← Driver
spark-master 172.20.0.3
spark-worker-1 172.20.0.4
spark-worker-2 172.20.0.5
spark-worker-3 172.20.0.6
spark-worker-4 172.20.0.7이제 Driver, Master, Worker가 전부 같은 172.20.0.x 대역 안에 있다.
Worker-1 → "결과를 172.20.0.4:45565 에 올려뒀어"
Driver → 172.20.0.4:45565 접근 시도
→ 같은 네트워크라 바로 접근 ✅별도의 포트 포워딩 없이도 컨테이너끼리 내부 IP로 자유롭게 통신할 수 있다.
정리
| 항목 | Driver 로컬 Mac | Driver Docker 안 |
|---|---|---|
| Driver IP | 192.168.219.103 | 172.20.0.2 |
| Worker IP | 172.20.0.x | 172.20.0.x |
| 같은 네트워크? | ❌ | ✅ |
| shuffle 통신 | ❌ 실패 | ✅ 성공 |
| count, GroupBy | ✅ 성공 | ✅ 성공 |
| Sort, Join | ❌ 실패 | ✅ 성공 |
count와 GroupBy가 성공한 이유는 shuffle이 없거나 적어서 Worker → Driver 단방향 통신만으로 끝나기 때문이다. Sort와 Join은 Worker들끼리 + Driver와 양방향 통신이 필요해서 같은 네트워크에 있어야 한다.
폴더 구조
JupyterProject/
├── docker/
│ ├── docker-compose.yml
│ └── Dockerfile
├── env/
│ └── hadoop.env
├── resource/
│ ├── amazon.csv (원본 1,465행)
│ └── amazon_big.csv (500배 복제 732,500행)
├── benchmark.py
├── benchmark_results.csv (결과)
└── benchmark_result.png (차트)실행 방법
1. 로컬 HDFS 시작
# HDFS 시작
start-dfs.sh
# 프로세스 확인
jps
# NameNode, DataNode, SecondaryNameNode 세 개가 보여야 함2. HDFS에 데이터 업로드 (최초 1회)
cd ~/PycharmProjects/JupyterProject
# 테스트 데이터 생성 (500배 복제)
python3 -c "
import pandas as pd
df = pd.read_csv('./resource/amazon.csv')
big_df = pd.concat([df] * 500, ignore_index=True)
big_df.to_csv('./resource/amazon_big.csv', index=False)
print(f'생성 완료: {len(big_df):,}행')
"
# HDFS 업로드
hdfs dfs -mkdir -p /data
hdfs dfs -put ./resource/amazon_big.csv /data/amazon_big.csv
hdfs dfs -ls /data3. Docker Spark 클러스터 시작
cd docker
docker-compose up -d
docker logs spark-master | tail -104. 벤치마크 실행
docker exec spark-driver python3 /app/benchmark.py한 번 실행으로 워커 1개 → 2개 → 4개 순서로 자동 테스트된다.
5. 결과 복사
docker cp spark-driver:/tmp/benchmark_results.csv ~/PycharmProjects/JupyterProject/
docker cp spark-driver:/tmp/benchmark_result.png ~/PycharmProjects/JupyterProject/벤치마크 태스크 설명
1. HDFS 읽기 + count
HDFS에서 CSV를 읽고 전체 행 수를 세는 가장 기본적인 작업이다.
df.count()Spark는 lazy evaluation 방식이라 .count() 같은 액션이 호출돼야 실제로 데이터를 읽는다. 워커 수가 많을수록 파일을 병렬로 읽어 빠르다.
2. GroupBy 집계
첫 번째 컬럼(product_id) 기준으로 그룹화해서 각 그룹의 행 수를 세는 작업이다.
df.groupBy(first_col).count().collect()같은 키를 가진 데이터가 여러 워커에 흩어져 있으면 한 곳으로 모아야 집계할 수 있다. 워커가 많을수록 병렬로 처리해 빠르다.
3. Sort Top 1000
숫자형 컬럼 기준으로 내림차순 정렬 후 상위 1000개를 가져오는 작업이다.
df.orderBy(F.col(sort_col).desc()).limit(1000).collect()전체 데이터를 다 봐야 정렬할 수 있어서 데이터 이동(shuffle)이 발생한다. 분산 처리 효과가 잘 드러나는 작업이다.
4. Self Join (50만 rows)
같은 데이터를 두 개로 나눠 서로 Join하는 작업이다.
df1 = df.limit(500_000).withColumn("_key", F.monotonically_increasing_id())
df2 = df.limit(500_000).withColumn("_key", F.monotonically_increasing_id())
df1.join(df2, "_key").count()Join은 같은 키를 가진 데이터를 한 워커로 모아야 해서 shuffle이 가장 많이 발생한다. 워커 수 차이가 가장 크게 나타나는 작업이다.
5. HDFS Parquet 쓰기
처리 결과를 다시 HDFS에 Parquet 형식으로 저장하는 작업이다.
df.limit(100_000).write.mode("overwrite").parquet(out_path)Parquet은 컬럼 기반 저장 포맷으로 CSV보다 빠르고 용량이 작다. HDFS 쓰기 속도는 디스크 I/O에 영향을 받아 워커 수 효과가 상대적으로 작다.
벤치마크 결과
데이터: 732,500행 (amazon_big.csv)
| 태스크 | 1개 | 2개 | 4개 | 개선율 |
|---|---|---|---|---|
| HDFS 읽기 + count | 0.76초 | 0.56초 | 0.29초 | 2.6배 |
| GroupBy 집계 | 1.38초 | 1.16초 | 0.81초 | 1.7배 |
| Sort Top 1000 | 1.48초 | 0.98초 | 0.80초 | 1.85배 |
| Self Join (50만) | 2.09초 | 1.21초 | 0.97초 | 2.15배 |
| Parquet 쓰기 | 8.44초 | 6.80초 | 5.48초 | 1.54배 |

결과 분석
워커 4개가 1개보다 평균 2배 빠르다. 이론상 4배여야 하는데 2배 정도인 이유는 모두 같은 물리 머신(Mac)에서 CPU를 나눠 쓰기 때문이다. 실제 물리적으로 다른 서버에서 실행하면 더 큰 차이가 난다.
Self Join이 가장 큰 효과(2.15배)를 보이는 이유는 shuffle이 가장 많이 발생하는 작업이라 워커가 많을수록 병렬 처리 효과가 크기 때문이다. Parquet 쓰기가 가장 작은 효과(1.54배)를 보이는 이유는 디스크 I/O가 병목이라 워커 수보다 저장 속도가 더 영향을 주기 때문이다.
그 외 알아본 것
start-dfs.sh — HDFS 시작 스크립트
HDFS를 구성하는 프로세스들을 한 번에 시작하는 스크립트다
내부적으로 이 세 가지를 순서대로 실행한다..
NameNode 시작 → DataNode 시작 → SecondaryNameNode 시작| 프로세스 | 역할 |
|---|---|
| NameNode | 파일이 어느 DataNode에 있는지 기록하는 "지도" 역할 |
| DataNode | 실제 파일 데이터를 블록으로 쪼개서 저장하는 창고 |
| SecondaryNameNode | NameNode의 메타데이터를 주기적으로 백업 |
ash
`start-dfs.sh # 시작
stop-dfs.sh # 종료`네임노드 & 데이터노드
HDFS는 파일을 저장할 때 두 가지 역할로 나눠서 관리한다.
네임노드 (NameNode)
파일의 위치 지도를 관리하는 관리자다.
실제 데이터를 저장하지는 않고, "어떤 파일이 어느 데이터노드에 있는지"만 기록한다. 도서관으로 치면 책 자체가 아니라 책의 목차와 위치를 적어둔 안내 데스크다.
네임노드가 기억하는 것들:
- 파일 이름, 크기, 권한
- 파일이 몇 개의 블록으로 쪼개졌는지
- 각 블록이 어느 데이터노드에 저장됐는지
/data/amazon.csv
└── 블록1 → 데이터노드 3번, 7번, 15번
└── 블록2 → 데이터노드 2번, 9번, 11번네임노드는 단 한 대만 존재한다. 그래서 네임노드가 죽으면 전체 HDFS가 멈춘다. 이걸 단일 장애점(SPOF)이라고 하는데, 이를 해결하려고 고가용성(HA) 설정에서는 네임노드를 두 대 띄워서 하나가 죽으면 다른 하나가 이어받는 구조를 쓴다.
데이터노드 (DataNode)
실제 파일 데이터를 블록 단위로 저장하는 일꾼이다.
네임노드의 지시에 따라 블록을 저장하고, 읽고, 복제한다. 수백~수천 대가 붙을 수 있고, 대수가 늘수록 저장 용량과 처리 속도가 함께 늘어난다.
데이터노드가 하는 일:
- 파일 블록을 로컬 디스크에 저장
- 주기적으로 네임노드에 "나 살아있어요" 신호(Heartbeat) 전송
- 복제본이 부족하면 다른 데이터노드로 블록 복사
Heartbeat가 끊기면?
네임노드가 해당 데이터노드를 Dead로 간주
→ 그 노드에 있던 블록을 다른 노드에 자동 복제
→ 복제 수(dfs.replication) 맞출 때까지 계속둘의 관계 요약
파일을 읽을 때 흐름을 보면 역할이 명확해진다.
클라이언트 → 네임노드에 물어봄 "amazon.csv 어디 있어?"
네임노드 → "블록1은 3번 노드, 블록2는 9번 노드에 있어"
클라이언트 → 데이터노드 3번, 9번에 직접 접근해서 데이터 읽음네임노드는 지도, 데이터노드는 창고다. 지도 없이는 창고를 찾을 수 없고, 창고 없이는 지도가 의미가 없다.
