<DDPG 배경>
DQN(Deep Q Network, 2015)이라는 강화학습에서 시작
- DQN에서 핵심은 Action-Value function을 근사화하기 위해 심층신경망 사용
- 장점: 센서 인풋 같이 높은 차원의 입력을 사용할 수 있게 됌
- 단점: discrete하고 차원이 낮은 action space를 지닌 task만 해결가능
- 이러한 단점으로 DQN은 action의 종류가 늘어날수록 차원의 저주에 걸림
- action-value function: 해당 policy를 따랐을 때, 모든 state, action의 return에 대한 기댓값
- 차원의저주: ex) 7 자유도(axis) 시스템에서 action 종류가 3개일 때 action space 크기는 3^7 = 2187
<DQN의 단점에 대한 해결책: DDPG>
심층신경망으로 근사화한 action-value function을 사용하는 Model-free, Off-policy actor critic 알고리즘 제안 - 알고리즘 이름은 DDPG: Deep Deterministic Policy Gradient
On policy learning은 자신이 직접 시행착오를 겪으면서 스스로 배우는 것
Off policy learning은 다른이가 시행착오를 겪는것을 보면서 배우는 것
<DDPG 특징>
- 높은 차원이면서 continuous한 action space의 policy를 학습가능
- actor-critic을 그대로 적용하기에 학습수렴이 잘 안되는 점을 DQN 아이디어로 극복
- (1) replay buffer: 데이터를 랜덤으로 추출해서 데이터 간의 상관관계를 최소화시킴
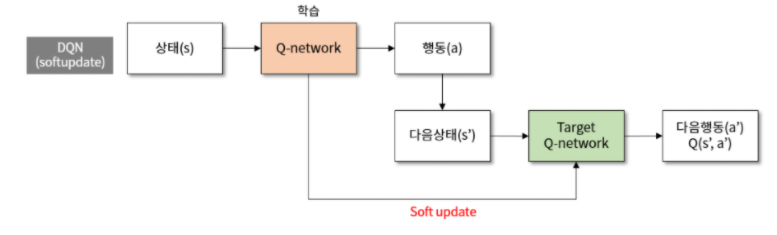
- (2) target Q network: Q-network의 복사본인 target Q-network를 생성-> 학습 도중에 origin-Q-network의 파라미터를 최대한 고정함으로써, 학습이 수렴할 수 있도록 도움
<target Q network를 사용하는 이유>
- Q learning은 매 시간(time step)마다 action-value fucntion(Q-Network)를 업데이트함
- 즉, 매 시간마다 Q-Network의 파라미터가 변경된다는 의미
- 학습 도중에 파라미터가 변경되는 것은 학습 수렴에 안좋은 영향을 끼침
- 학습 도중에 파라미터가 고정되어 있는 Target Q-Network가 필요

Backend Web Developer