강화학습 기반의 End-to-End 자율주행 시스템
Reinforcement Learning based End-to-End Driving System
by 카이스트 AVE Lab
http://ave.kaist.ac.kr/bbs/board.php?bo_table=B_06
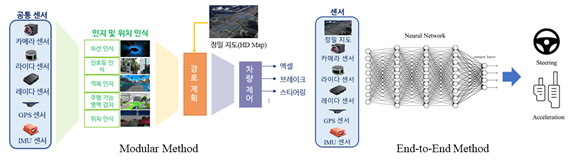
자율주행 자동차의 주행 방식에는 모듈러(Modular) 방식과 종단간(End-to-End) 주행 방식이 있으며, 현재 대부분의 연구 개발은 모듈러 방식으로 진행하고 있다.
모듈러 방식은 사람이 직접 모든 교통 상황을 정의하여 모듈을 구성하므로, 예측 가능한 범위 내에서만 작동하고 사고 발생시 사고 경위를 쉽게 판단할 수 있다는 장점이 있다.
하지만, 알고리즘 설계의 복잡도가 높아서 모든 교통 상황에 대해서 대응을 할 수 없기 때문에 Level5 자율주행 자동차 개발은 불가하고, 현재는 Level 2~3단계 수준으로 상용화가 진행되고 있다.
종단간 주행 방식은 자율주행 시스템을 모듈화하지 않고 심층신경망으로 구현하는 방법이다. 다양한 도로 환경에 대한 충분한 데이터가 있다는 가정하에 입력값 간의 최적화된 조합을 찾아 다양한 교통상황에 대해서 모듈러 방식을 뛰어넘는 성능을 가질 수 있다.
기존에 연구되고 있는 자율주행 심층신경망은 i.i.d.조건(independent and identically distributed condition)을 가정한 데이터(주변환경조건 및 교통상황)로 학습을 하는데,
학습된 환경과 통계적 분포도가 유사한 환경에서는 자율주행에 큰 어려움이 없이 잘 동작하는 장점이 있지만, 새로운 환경에서는 입력 데이터가 학습된 환경과 유사하지 않은 통계적 분포도를 가지는 OOD(Out-of-distribution) 환경에서는 자율주행 자동차가 안정적으로 동작하는 것을 보장할 수 없는 큰 한계가 있다.
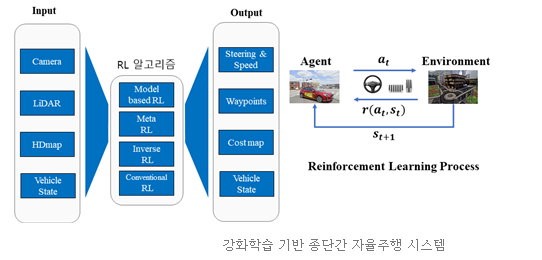
본 연구실은 다양한 OOD 환경에서도 안정적인 Level5의 자율주행 자동차 개발을 목표로 Meta-강화학습 기반의 종단간 주행 방식을 연구하고 있으며, 총 5년동안 20억 규모의 연구재단 과제를 진행하고 있다.
1) Meta-RL based End-to-End Autonomous Driving
(연구재단 과제 수행 중: 2021.03.01~2026.02.28)
기존 자율주행 심층 신경망은 제어 영역(control space)에 변화가 없고 주행 환경의 상태 분포(state distribution)가 일반적인 주행 환경의 상태 분포를 따르는 학습 데이터로 학습되어 있다.
따라서 기존 기술로는 자율주행 차량이 주행 중에 예상 못한 상황(Unexpected Novel Situation – UNS e.g., 타이어 펑크, 브레이크/스티어링휠의 부분적 오작동, 미끄러운 노면에 의한 하나 또는 일부 바퀴들의 미끄러짐, 갑작스러운 짙은 안개 상황 등)을 직면 할 때, 사전 학습되지 않은 UNS 상황에 대한 대처가 불가능하기 때문에 안전한 주행을 보장하지 못한다는 한계를 가지고 있다.
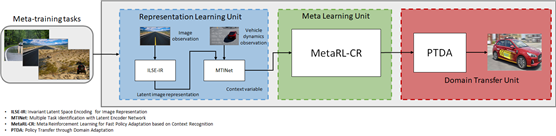
본 연구실의 메타-강화학습기반 End-to-End 자율주행 시스템
현재 본 연구실은 위와 같은 한계를 극복하기 위해 메타 강화학습 기반의 자율주행 에이전트가 학습되지 않은 UNS 상황이 발생한 것을 탐지하는 인공지능과, UNS 탐지 결과에 따른 MPC(Model Predictive Control)기반 최적 제어 신호 생성 policy망을 학습하고 실제 제어하는 메타 강화학습 알고리즘을 개발하는 것을 목표로 연구재단 과제를 진행하고 있으며, 어떠한 상황에도 인간의 개입 없이 자율주행 자동차가 모든 판단과 주행제어를 수행하는 Level5 자율주행 기술 개발을 목표를 하고 있다.
2) Segmentation-based Class-wise Disentangled Latent Encoding(2020~)
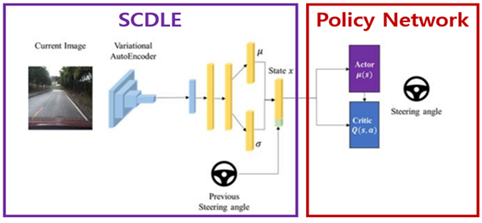
SCDLE 구조
본 연구실에서는 입력된 도로 이미지를 의미 분할하고 변분 오토인코더를 통해 이미지를 압축하여 이를 강화 학습의 상태 변수로 사용해 조향각을 추론 및 평가하는 세계 최초의 심층 신경망을 구성하는 것을 연구하고 있다.
"End-to-end Learning of Driving Models from Large-scale Video Datasets" 논문 세미나
- 사용자 의도 파악을 하고 싶다. --> 이게 autonomous vehicle의 경로 추적하는 거랑 비슷한 거 같더라....
- 굉장히 다양한 환경에서 driving을 해야 하는데, 제어하는 것은 rule-based와 data-driven 방식이 있다.
실제 완성차 업체는 사실 data-driven을 좋아하지 않음. (완벽하게 분석이 불가해서 사고가 났을 때 대책이 없음) - 기존의 End-to-end learning for driving model
DAVE
DAVE-2 by Nvidia : 72시간, 3개의 카메라 data를 가지고 training. 실제 주행시에는 center camera를 활용.
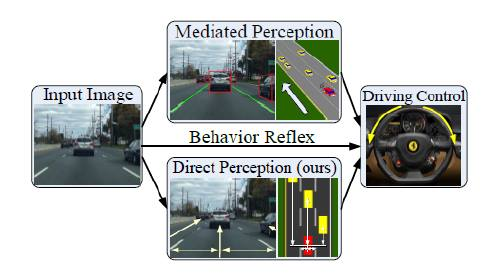
DeepDriving : mediated perception이 현재 완성차 업체들이 원하는 방식.. object 다 detect하고, 위치 다 구하고.. 이걸 바탕으로 제어..
behavior reflex는 DAVE2 같은 input raw image를 그대로 처리하는 end2end 방식
이 논문에서는 direct perception 방식을 제안. input raw image가 아닌 필수적인 정보(차량간 거리, 자기의 레인에서의 위치 등)를 뽑아서 입력으로 주고 처리. (그림 1) - Generic Motion : 기존에는 steering을 얼마나 할지, accel/brake를 얼마나 할지.. 로 제어하는데, 이게 자동차 마다 그 반응값이 다 다름.. 우리는 angular velocity와 speed 값을 직접 구함.
- 여기서는 state 를 raw image만 사용하는 것이 아닌, 모션 센서, GPS등 다양한 값들을 사용
- discrete motion action(straight, stop, left-turn, right-turn) / continuous motion action(generic motion)을 사용.
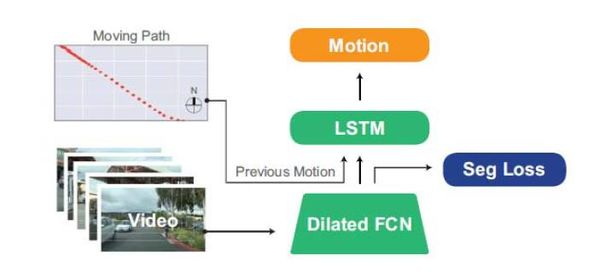
--> continuous action space를 표현하기 위해 many small bins으로 discretize함. (공간을 even하게 나누지는 않음) - FCN-LSTM 구조를 사용.
영상은 dilated FCN으로 분석
moving path 정보(모션센서,GPS등)의 sequence는 LSTM으로 처리. (그림 2 구조 참고)
dilated FCN은 previleged information learning을 사용 --> semantic segmentation을 하도록 학습시킴 --> 이렇게 했더니 전체 이미지 중 작게 바뀌는 것.. ex. 신호등 색이 바뀌는거..
을 잘 찾기 시작하더라... - 그러면 모델이 얼마나 잘 맞아떨어지는지 perplexity로 평가하겠다..
perplexity란 확률분포모델이 sample들을 잘 predict할 수 있느냐? 에 대한 측정.