4.3 멀티 쓰레드 컨슈머
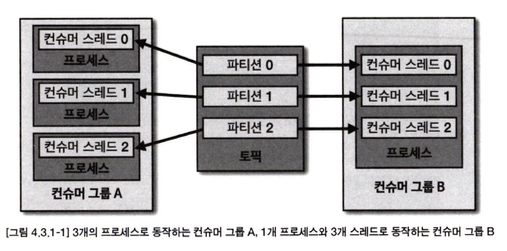
카프카는 처리량을늘리기 위해 파티션과 컨슈머 개수를 늘려서 운영할 수 있다. 파티션을 여러 개로운영하는 경우 데이터를 병렬처리하기 위해서 파티션 개수와 컨슈머 개수를 동일하게 맞추는 것이 가장 좋은 방법
파티션 개수가 n개라면 동일 컨슈머 그 룹으로 묶인 컨슈머 스레드를 최대 n개 운영할 수 있다
문제점
멀티 스레드 애플리케이션으로 컨슈머(Consumer)를 운영할 때는 여러 가지 중요한 점을 고려해야 합니다. 각각의 스레드가 독립적으로 동작하지만, 하나의 프로세스 안에서 실행되기 때문에 스레드 간의 상호작용과 자원 공유에 신중한 관리가 필요합니다. 다음은 멀티 스레드 컨슈머를 안전하게 운영하기 위해 고려해야 할 주요 사항들입니다:
- 예외 처리와 프로세스 안정성
멀티 스레드 애플리케이션에서는 하나의 스레드에서 예외적 상황(예: OutOfMemoryException)이 발생할 경우, 그 예외가 전체 프로세스에 영향을 미칠 수 있습니다. 스레드 하나가 실패하더라도 나머지 스레드들이 정상적으로 동작하도록 처리하는 것이 중요합니다. 만약 컨슈머 스레드에서 심각한 예외가 발생해 프로세스가 비정상적으로 종료되면, 다른 스레드들도 함께 종료되어 데이터 처리에서 중복 혹은 유실이 발생할 수 있습니다.
따라서, 각 스레드에서 예외가 발생했을 때 그 예외가 다른 스레드나 전체 애플리케이션에 영향을 미치지 않도록 예외 처리(Exception Handling)를 철저히 설계해야 합니다. 이를 위해, 스레드 내부에서 발생한 예외를 개별적으로 처리하거나, 안전하게 로그를 남긴 후 적절한 복구 로직을 적용해야 합니다.
- 스레드 세이프(Thread Safe)
스레드 세이프하지 않은 코드에서 스레드들이 동시에 동일한 자원에 접근하거나 조작할 경우, 데이터 무결성에 문제가 생길 수 있습니다. 예를 들어, 여러 스레드가 동시에 동일한 데이터 구조에 접근하거나 변경할 때, 그 데이터가 예상치 못한 상태로 변형될 위험이 있습니다.
이러한 문제를 방지하려면 스레드 세이프(Thread Safe)한 로직과 변수를 적용해야 합니다. 이를 위해, 락(Lock)을 사용하여 동시에 접근하는 스레드의 수를 제한하거나, 동기화(Synchronization) 기법을 적용하여 자원의 일관성을 보장할 수 있습니다. 또한, Atomic 클래스나 ThreadLocal 변수를 사용해 스레드별로 독립적인 자원 관리를 구현할 수 있습니다.
- 비정상적인 스레드 종료
멀티 스레드 환경에서 일부 스레드가 비정상적으로 종료될 경우, 그 스레드가 담당하고 있던 작업이 제대로 완료되지 않거나 중복으로 처리될 가능성이 있습니다. 이로 인해 데이터 처리 중 중복이나 유실 문제가 발생할 수 있으며, 특히 메시지 큐나 데이터베이스 연동 시 이런 문제가 심각해질 수 있습니다.
이를 방지하기 위해 다음과 같은 방법을 적용할 수 있습니다:
- 재시도 메커니즘: 특정 작업이 실패했을 때 자동으로 재시도하는 기능을 추가하여 일시적인 오류로 인한 데이터 유실을 막습니다.
- 트랜잭션 처리: 트랜잭션 기반으로 데이터를 처리하여, 작업이 완료되지 않았을 경우 롤백하고, 완료된 경우에만 커밋되도록 처리합니다.
- 체크포인트/로그: 작업이 어느 단계에서 중단되었는지 기록하여, 이후 스레드가 재시작되었을 때 이어서 처리할 수 있도록 합니다.
- 스레드 간 독립성 보장
- 각 컨슈머 스레드가 독립적으로 동작해야 하며, 다른 스레드에 영향을 미치지 않도록 해야 합니다. 이를 위해서는 스레드마다 별도의 자원 할당과, 공유 자원에 대한 동시 접근 제어가 필요합니다. 특히 상태 공유가 발생하지 않도록 주의해야 하며, 필요한 경우 공유 자원에 대한 락(lock) 처리를 명확하게 해야 합니다.
- 자원 관리
멀티 스레드는 각각 메모리, 파일 핸들, 네트워크 소켓 등의 자원을 사용하기 때문에, 자원 관리가 중요한 이슈가 됩니다. 특히 많은 스레드가 동시에 실행될 경우, 메모리 부족 등의 리소스 고갈 문제가 발생할 수 있습니다. 이를 방지하기 위해 다음을 고려할 수 있습니다:
- 스레드 풀(Thread Pool)을 사용하여 스레드 수를 제한하고, 과도한 스레드 생성으로 인한 자원 낭비를 방지합니다.
- 각 스레드가 작업을 마친 후에는 자원을 명시적으로 해제하여, 시스템 자원이 지속적으로 점유되는 문제를 막습니다.
- 컨슈머 스레드는 1개만 실행하고 데이터 처리를 담당하는 워커 스레드(worker thread)를 여러 개 실행하는 방법 인 멀티 워커 스레드 전략
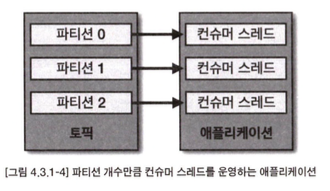
- 컨슈머 인스턴스에서 poll() 메서드를 호출하는 스레드를 여러 개 띄워서 사용하는 컨슈머 멀 티 스레드 전략
1. 카프카 컨슈머 멀티 워커 쓰레드 전략
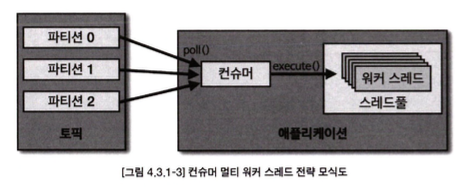
카프카(Kafka)를 활용해 데이터를 병렬로 처리하기 위한 효율적인 전략 중 하나는 멀티 워커 쓰레드를 사용하는 것입니다. 이는 카프카 컨슈머에서 받은 레코드를 여러 스레드를 통해 병렬로 처리함으로써 처리 속도를 크게 향상시킬 수 있습니다. 이를 구현하기 위해 자바의 ExecutorService 라이브러리를 활용할 수 있으며, 다음과 같은 방식으로 쓰레드를 생성하고 관리할 수 있습니다.
- ExecutorService와 스레드 풀(Thread Pool) 사용
ExecutorService는 자바에서 스레드를 효율적으로 관리하기 위한 라이브러리입니다. 이를 통해 스레드 풀(Thread Pool)을 구성하고, 스레드를 재사용하거나 새로운 스레드를 생성할 수 있습니다. 예를 들어, 아래와 같이 Executors.newCachedThreadPool()을 사용하여 스레드를 캐싱하고, 필요할 때마다 새로운 스레드를 동적으로 생성하는 스레드 풀을 만들 수 있습니다.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
ExecutorService executorService = Executors.newCachedThreadPool();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(10));
for (ConsumerRecord<String, String> record : records) {
ConsumerWorker worker = new ConsumerWorker(record.value());
executorService.submit(worker);
}
}이 코드는 카프카 컨슈머로부터 레코드를 받아, 각 레코드를 처리하기 위해 ConsumerWorker라는 워커 쓰레드를 생성하고 이를 executorService에 제출합니다. 이렇게 하면 병렬 처리가 가능해져 처리 속도를 크게 높일 수 있습니다.
- 스레드 사용의 이점
스레드를 활용해 카프카에서 받아온 레코드를 병렬로 처리하면 다음과 같은 이점을 얻을 수 있습니다:
- 처리 속도 향상: 여러 스레드가 동시에 레코드를 처리함으로써 병렬 처리가 가능해져 전체 처리 시간이 단축됩니다.
- 리소스 효율성: 스레드 풀을 사용해 리소스를 효율적으로 관리할 수 있습니다. 필요에 따라 스레드를 생성하고, 사용 후에는 재사용할 수 있기 때문에 불필요한 스레드 생성을 막고 시스템 자원을 절약할 수 있습니다.
- 멀티 스레드 사용 시 주의사항
멀티 스레드 환경에서 발생할 수 있는 몇 가지 주의사항이 있습니다. 이 부분은 안정적이고 정확한 데이터 처리를 위해 반드시 고려해야 합니다.
1) 자동 커밋(Autocommit)으로 인한 데이터 유실 위험
카프카 컨슈머에서 자동 커밋 설정이 활성화된 경우, 각 레코드가 완전히 처리되지 않았음에도 커밋이 발생할 수 있습니다. 이는 리밸런싱(Rebalancing)이나 컨슈머 장애 발생 시, 아직 처리되지 않은 데이터를 커밋한 것으로 간주되어 데이터 유실로 이어질 수 있습니다.
이 문제는 카프카 컨슈머의 수동 커밋 설정으로 해결할 수 있습니다. 즉, 각 레코드의 처리가 완료된 후에만 커밋을 수행함으로써 데이터 유실을 방지할 수 있습니다.
consumer.commitSync(); // 수동으로 커밋
2) 레코드 처리 순서의 역전(Out-of-Order) 현상
멀티 스레드 환경에서는 레코드가 순서대로 처리되지 않을 수 있습니다. 이는 스레드를 생성하는 순서는 일정하지만, 스레드 간의 처리 시간이 다를 수 있기 때문입니다. 만약 나중에 생성된 스레드가 더 빨리 완료되면, 레코드 순서가 뒤바뀌는 현상이 발생할 수 있습니다.
이런 역전 현상이 문제가 되지 않는 경우(예: 로그 수집, 모니터링 데이터 처리)에는 빠른 처리가 우선시되므로 문제가 없을 수 있습니다. 그러나 순서가 중요한 데이터 처리(예: 거래 데이터 처리)에서는 이러한 문제를 해결하기 위한 추가적인 설계가 필요합니다. 순서를 보장하려면 단일 스레드로 처리하거나 오더링 메커니즘을 도입하는 방법이 있습니다.
3) 컨슈머 스레드 안정성
멀티 스레드로 컨슈머를 운영할 경우, 각 스레드에서 예외 상황이 발생하면 프로세스 전체가 종료될 위험이 있습니다. 이를 방지하기 위해 개별 스레드에서 예외가 발생해도 다른 스레드에 영향을 주지 않도록 예외 처리를 철저히 설계해야 합니다. 스레드별로 트랜잭션을 적용하거나, 예외를 처리하는 로직을 구현하여 안정성을 높일 수 있습니다.
- 멀티 스레드 컨슈머의 적합한 활용 사례
멀티 스레드로 레코드를 병렬로 처리하는 전략은 데이터의 순서가 중요하지 않거나, 일부 데이터 유실이 발생해도 큰 문제가 되지 않는 경우에 매우 적합합니다. 예를 들어:
- 서버 리소스 모니터링: CPU, 메모리 등의 리소스를 실시간으로 모니터링하는 파이프라인에서 병렬 처리를 통해 데이터를 빠르게 처리할 수 있습니다.
- IoT 데이터 수집: IoT 장치에서 발생하는 대규모 센서 데이터를 수집하여 실시간으로 처리하는 경우, 스레드를 통해 병렬로 데이터를 처리하면 성능을 크게 향상시킬 수 있습니다.
- 카프카 컨슈머 멀티 스레드 전략
public void run() {
consumer = new KafkaConsumer<>(prop);
consumer.subscribe(Arrays.asList(topic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
logger.info("Received record: {}", record);
}
}
}
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < CONSUMER_COUNT; i++) {
ConsumerWorker worker = new ConsumerWorker(configs, TOPIC_NAME, i);
executorService.execute(worker);
}컨슈머 랙
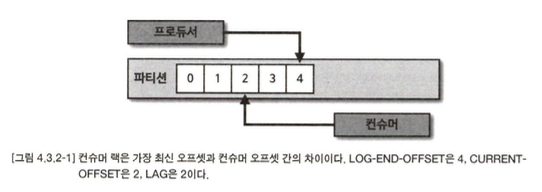
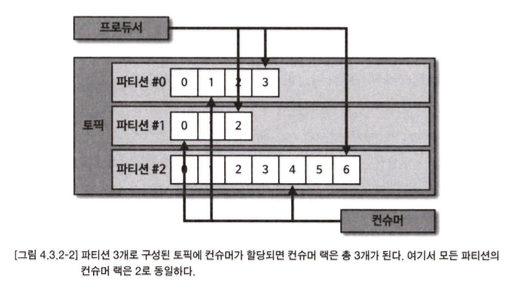
컨슈머 랙(LAG)은 토픽의 최신 오프셋(LOG-END-OFFSET)과 컨슈머 오프셋(CURRENT- OFFSET) 간의 차이다. 프로듀서는 계속해서 새로운 데이터를 파티션에 저장하고 컨슈머는 자신이 처리할 수 있는 만큼 데이터를 가져간다. 컨슈머 랙은 컨슈머가 정상 동작하는지 여부 를 확인할 수 있기 때문에 컨슈머 애플리케이션을 운영한다면 필수적으로 모니터 링해야 하는 지표이다.
컨슈머 랙은 컨슈머 그룹과토픽,파티션별로 생성된다. 1개의 토픽에 3개의 파티션이 있고 1개 의 컨슈머 그룹이 토픽을 구독하여 데이터를 가져가면 컨슈머 랙은 총 3개가 된다.
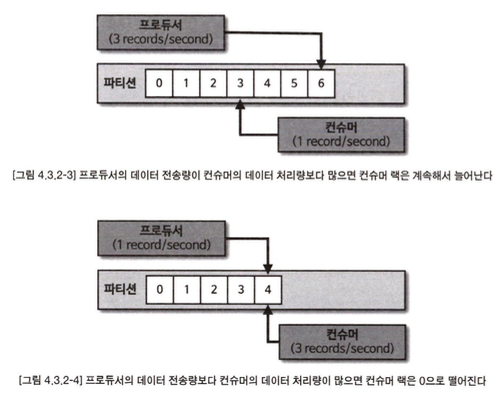
프로듀서가 보내는 데이터양이 컨슈머의 데이터 처리량보다 크다면 컨슈머 랙은 늘어난다. 반 대로 프로듀서가 보내는 데이터양이 컨슈머의 데이터 처리량보다 적으면 컨슈머 랙은 줄어들 고 최솟값은。으로 지 연이 없음을 뜻한다.
컨슈머 랙을 모니터 링하는 것은 카프카를 통한 데이터 파이프라인을 운영하는 데에 핵심적인 역할을 한다. 컨슈머 랙을 모니터 링함으로써 컨슈머의 장애를 확인할 수 있고 파티션 개수를 정하는 데에 참고할 수 있기 때문이다.
Kafka 컨슈머 랙(Lag) 조회 방법: 3가지 접근 방식 비교
- Kafka 명령어를 사용하여 컨슈머 랙 조회
Kafka에서 제공하는 기본 명령어인 kafka-consumer-groups.sh를 사용하면 특정 컨슈머 그룹의 컨슈머 랙을 확인할 수 있습니다. 예를 들어, my-group 컨슈머 그룹이 test-topic 토픽을 구독하고 있을 때, 해당 컨슈머 그룹의 상태를 명령어로 확인할 수 있습니다.
특징 및 장단점
특징: Kafka 내장 명령어로 쉽게 사용할 수 있으며, 추가적인 설치나 설정이 필요 없습니다.
• 장점: 빠르게 테스트 환경에서 컨슈머 랙을 확인하는 데 적합합니다. 특정 시점에 대한 랙 상태를 즉시 확인할 수 있습니다.
• 단점: 일회성 조회에 그치기 때문에 지표를 지속적으로 모니터링하기 어렵습니다. 주로 테스트 환경에서 유용하며, 운영 환경에서는 한계가 있습니다.
사용 예시:

- metrics() 메서드를 사용하여 컨슈머 랙 조회
KafkaConsumer 인스턴스의 metrics() 메서드를 통해 애플리케이션 내에서 컨슈머 랙을 모니터링할 수 있습니다. 이 메서드는 records-lag-max, records-lag, records-lag-avg와 같은 지표를 제공하여 컨슈머 랙 상태를 파악할 수 있습니다.
특징 및 장단점
특징: 컨슈머 애플리케이션에서 제공하는 기본 메서드로, 코드에 직접 포함시켜 사용할 수 있습니다.
장점: 컨슈머 애플리케이션 실행 중 실시간으로 컨슈머 랙을 모니터링할 수 있습니다.
단점:
1. 컨슈머 애플리케이션이 정상적으로 실행될 때만 동작하기 때문에, 비정상 종료 시에는 랙을 모니터링할 수 없습니다.
2. 각 컨슈머 애플리케이션마다 동일한 모니터링 코드를 중복해서 작성해야 합니다.
3. 서드 파티 애플리케이션에서는 컨슈머 랙을 모니터링할 수 없습니다.
사용 예시:

metrics() 메서드를 통해 컨슈머 랙 상태를 실시간으로 파악할 수 있지만, 운영 환경에서 여러 애플리케이션에 적용하기에는 번거로울 수 있습니다.
- 외부 모니터링 툴을 사용하여 컨슈머 랙 조회
외부 모니터링 툴을 사용하면 컨슈머 랙을 모니터링하는데 더욱 효율적입니다. 대표적으로 Datadog, Confluent Control Center와 같은 툴들이 있으며, Burrow는 컨슈머 랙 모니터링에 특화된 오픈소스 툴입니다. 이러한 툴을 사용하면 Kafka 클러스터 전반의 다양한 지표를 모니터링할 수 있으며, 컨슈머 랙 역시 한눈에 파악할 수 있습니다.
특징 및 장단점
특징: 종합적인 Kafka 클러스터 모니터링을 지원하며, 컨슈머 랙을 비롯한 다양한 지표를 수집하고 시각화할 수 있습니다.
장점: 클러스터 내 모든 컨슈머와 토픽에 대한 랙 정보를 한 번에 모니터링할 수 있습니다. 또한, 애플리케이션과 독립적으로 지표를 수집하기 때문에 프로듀서나 컨슈머의 성능에 영향을 주지 않습니다.
단점: 설정 및 구축에 추가적인 비용과 시간이 필요할 수 있으며, 초기에 사용법을 익히는 데 시간이 걸릴 수 있습니다.
사용 예시:
Datadog: Datadog의 Kafka 인티그레이션을 통해 클러스터의 성능 및 랙을 모니터링할 수 있습니다.
Burrow: REST API를 통해 특정 컨슈머 그룹의 랙 정보를 조회할 수 있습니다.
- 링크드인에서 공개한 오픈소스 컨슈머 랙 체크 툴이다. 버로우를 카프카 클러스터와 연동하면 REST API를 통해 컨슈머 그룹별 컨슈머 랙을 조회
컨슈머 랙 모니터링 아키텍처
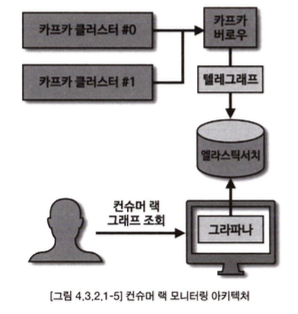
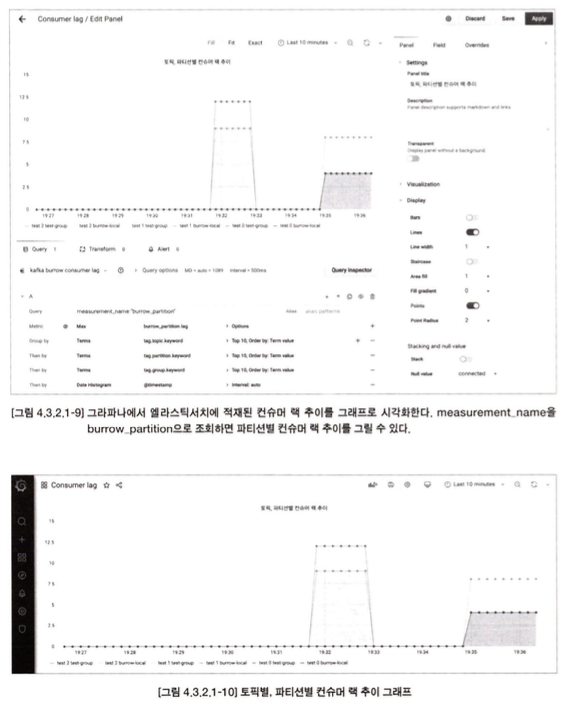
컨슈머 배포 프로세스
카프카 컨슈머 애플리케이션을 운영할 때, 로직 변경 및 배포는 필수적입니다. 배포 방법은 크게 두 가지로 나뉩니다: 중단 배포와 무중단 배포. 선택은 서비스 운영의 중요도와 중단 가능 여부에 따라 달라집니다.
- 중단 배포
중단 배포는 기존 애플리케이션을 완전히 종료한 후, 개선된 코드를 가진 신규 애플리케이션을 배포하는 방식입니다. 이 방식은 물리 서버를 운영하거나 제한된 리소스를 사용할 때 적합합니다.
특징: 배포 중에 컨슈머 랙이 발생하여 데이터 처리 지연이 생길 수 있습니다.
장점: 애플리케이션의 이전 버전과 새로운 버전의 처리 데이터를 명확히 구분할 수 있으며, 오류 발생 시 롤백이 용이합니다.
단점: 신규 버전 배포가 지연되면 서비스 중단이 길어질 수 있습니다.
- 무중단 배포
중단이 불가능한 상황에서는 무중단 배포가 필요합니다. 주로 가상 서버나 클라우드 환경에서 활용되며, 여러 방식으로 나뉩니다.
블루/그린 배포: 이전 버전과 신규 버전을 동시에 실행하여 트래픽을 전환하는 방식입니다.
•장점: 리밸런스가 한 번만 발생하므로, 대규모 파티션 환경에서도 짧은 리밸런스 시간으로 배포가 가능합니다.
•적용 사례: 파티션과 컨슈머 개수가 동일한 환경에서 유리합니다.
롤링 배포: 기존 인스턴스를 순차적으로 교체하며 배포하는 방식입니다.
•장점: 인스턴스 할당과 반환으로 인한 리소스 낭비를 최소화합니다.
•단점: 리밸런스가 여러 번 발생하므로, 파티션 개수가 적을 때 적합합니다.
카나리 배포: 소규모 데이터를 신규 버전에 선제 적용하여 문제를 사전에 탐지하는 방식입니다.
•장점: 신규 애플리케이션에 대한 위험을 미리 탐지하여 전체 배포 전 안정성을 확인할 수 있습니다.
•적용 사례: 사전 테스트가 필요한 경우, 일부 파티션에만 컨슈머를 배정해 검증 후 나머지 파티션으로 확대 적용합니다.
4.4 스프링 카프카
build.gradle dependency
dependencies (
compile 'org.springframework.kafka:spring-kafka:2.5.10.RELEASE' ❶
compile 1org.spri ngframework.boot:spri ng-boot-starter:2.4.0' ❷
)4.4.1 스프링 카프카 프로듀서
- 카프카 프로듀서는 카프카 템플릿이라고 불리는 클래스를 사용하여 데이터를 전송할 수 있따
- 프로듀서 팩토리 클래스를 통해 생성할 수 있다.
- 스프링 카프카 제공 기본 카프카 템플릿
application.yaml에 설정한 프로듀서 옵션값은 애플리케이션이 실행될 때 자동으로 오버라 이드되어 설정된다. application.yaml에서 설정할수 있는 프로듀서 옵션값
spring, kafka.producer.acks spring.kafka.producer.batch-size
spring, kafka.producer.bootstrap-servers spring. kafka.producer.buffer-memory
spring. kafka.producer.client-id spring.kafka.producer.compression-type spring.kafka.producer.key-serializer spring, kafka・producer.properties.★
spring, kafka.producer.retries
spring. kafka.producer.transaction-i d-pr은tix spring. kafka. producer.value-serializer스프 링 카프카에서 프로듀서를 사용할 경우에는 필수 옵션이 없다. 그렇기 때문에 만약 옵션을 설
정하지 않으면 bootstrap-servers는 localhost:9092, key-serializer와 value-serializer는 StringSerializer로 자동 설정되어 실행된다. 연결하고자 하는 대상 서버가 my-kafka:9092이 고 acks 옵션을 all로 설정하고 싶다면 다음과 같이 application.yaml에 설정한다.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.core.KafkaTemplate;
@SpringBootApplication
public class SpringProducerApplication implements CommandLineRunner { // 'implements' 키워드의 오타 수정
private static final String TOPIC_NAME = "test"; // 'TOPIC_NAME'을 final로 변경하여 상수 선언
@Autowired
private KafkaTemplate<Integer, String> template; // KafkaTemplate을 통해 메시지를 Kafka로 전송
public static void main(String[] args) {
SpringApplication application = new SpringApplication(SpringProducerApplication.class);
application.run(args); // Spring Boot 애플리케이션 실행
}
@Override
public void run(String... args) throws Exception {
// 메시지 10개를 Kafka의 'test' 토픽에 전송
for (int i = 0; i < 10; i++) {
template.send(TOPIC_NAME, i, "test" + i); // 키를 'i', 메시지를 'test' + i로 설정
}
System.exit(0); // 메시지 전송 후 애플리케이션 종료
}
}- send(String topic, K key, V data): 메시지 키, 메시지 값을 포함하여 특정 토픽으로 전달
- send(String topic, Integer partition, K key, V data) : 메시지 ヲ 메시지 값이 포함된 레 코드를 특정 토픽의 특정 파티션으로 전달
- send(String topic, Integer partition, Long timestamp K key, V data): 메시지 ヲ|, 메시지 값, 타임스탬프가 포함된 레코드를 특정 토픽의 특정 파티션으로 전달
- send(ProdcuerRecord<K, V> record): 프로듀서 레코드(ProducerRecord) 객체를 전송
- 커스텀 카프카 템플릿
커스텀 카프카 템플릿은 프로듀서 팩토리를 통해 만든 카프카 템플릿 객체를 빈으로 등록하여 사용하는 것이다. 프로듀서에 필요한 각종 옵션을 선언하여 사용할 수 있으며 한 스프링 카프 카 애플리케이션 내부에 다양한 종류의 카프카 프로듀서 인스턴스를 생성하고 싶다면 이 방식 을 사용하면 된다
package com.example; // 패키지 선언 수정
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaTemplateConfiguration { // 클래스 이름과 어노테이션 수정
@Bean
public KafkaTemplate<String, String> customKafkaTemplate() { // 메서드 이름 수정
Map<String, Object> props = new HashMap<>(); // 설정 맵 초기화
// Kafka 서버 설정
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "my-kafka:9092"); // Kafka 브로커 주소
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); // 키 직렬화 설정
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); // 값 직렬화 설정
props.put(ProducerConfig.ACKS_CONFIG, "all"); // 모든 레플리카에 전송된 후에만 성공 처리
// ProducerFactory 생성
ProducerFactory<String, String> pf = new DefaultKafkaProducerFactory<>(props);
// KafkaTemplate 생성 및 반환
return new KafkaTemplate<>(pf);
}
}4.4.2 Spring Kafka Consumer
스프링 카프카 컨슈머: 리스너 타입과 커밋 전략의 세분화
스프링 카프카(Spring Kafka)는 Apache Kafka와의 통합을 간편하게 제공하여, 메시지 처리를 더욱 손쉽게 구현할 수 있게 합니다. 이때, 카프카 컨슈머(Consumer)의 리스너(listener) 타입과 커밋 전략을 구분하여 다양한 메시지 처리 요구사항을 충족할 수 있도록 세분화된 기능을 제공합니다. 이번 포스트에서는 스프링 카프카에서 제공하는 컨슈머 리스너의 타입과 커밋 전략에 대해 자세히 알아보겠습니다.
- 리스너 타입 (Listener Types)
스프링 카프카에서 컨슈머 리스너는 크게 레코드 리스너(MessageListener)와 배치 리스너(BatchMessageListener)의 두 가지 타입으로 나눌 수 있습니다. 리스너의 종류에 따라 메시지 처리 방식에 차이가 있으며, 각 리스너는 고유한 사용 시나리오에 맞게 설계되었습니다.
(1) 레코드 리스너 (MessageListener)
레코드 리스너는 Kafka에서 전달받은 단일 레코드를 처리하는 리스너 타입입니다. 스프링 카프카의 기본 리스너 타입으로 설정되어 있으며, 메시지 한 개씩 처리하는 방식이 필요한 경우에 유용합니다. 예를 들어, 실시간으로 들어오는 메시지를 하나씩 처리해야 하거나, 메시지 처리 순서가 매우 중요한 애플리케이션에서 자주 사용됩니다.
@KafkaListener(topics = "my-topic")
public void listen(String message) {
System.out.println("Received message: " + message);
}(2) 배치 리스너 (BatchMessageListener)
배치 리스너는 한 번에 여러 개의 레코드를 처리할 수 있도록 설계된 리스너입니다. 기본적으로 Kafka의 poll() 메서드에서 여러 개의 메시지를 가져오며, 배치 리스너를 통해 한 번에 처리할 수 있습니다. 대량의 데이터를 효율적으로 처리해야 하는 상황에서 사용되며, 레코드 처리의 순서가 크게 중요하지 않을 때 유용합니다.
@KafkaListener(topics = "my-topic", containerFactory = "batchFactory")
public void listenBatch(List<String> messages) {
System.out.println("Received batch messages: " + messages);
}- 확장된 리스너 타입
스프링 카프카에서는 기본 리스너 외에도 추가적인 기능을 제공하는 확장된 리스너들이 있습니다. 이러한 리스너들은 각기 다른 상황에서 사용되며, 메시지의 수동 커밋이나 컨슈머 정보를 활용한 처리가 가능하게 합니다. 확장된 리스너들은 아래와 같은 형태로 나뉩니다:
(1) AcknowledgingMessageListener
이 리스너는 수동으로 메시지를 커밋해야 하는 상황에서 사용됩니다. 메시지가 정상적으로 처리되었음을 명시적으로 확인하는 “acknowledge” 메서드를 사용하여 Kafka에 커밋을 알릴 수 있습니다. 이를 통해 메시지의 정확한 처리가 이루어졌을 때만 커밋을 수행하게 할 수 있습니다.
public class MyAcknowledgingListener implements AcknowledgingMessageListener<String, String> {
@Override
public void onMessage(ConsumerRecord<String, String> record, Acknowledgment acknowledgment) {
System.out.println("Received: " + record.value());
acknowledgment.acknowledge(); // 수동 커밋
}
}(2) ConsumerAwareMessageListener
이 리스너는 Kafka의 Consumer 객체에 접근할 수 있게 하여, 해당 객체의 메서드들을 통해 세부적인 처리가 가능합니다. 예를 들어, 컨슈머 그룹이나 오프셋 정보 등을 활용한 메시지 처리가 필요할 때 사용됩니다.
public class MyConsumerAwareListener implements ConsumerAwareMessageListener<String, String> {
@Override
public void onMessage(ConsumerRecord<String, String> record, Consumer<?, ?> consumer) {
System.out.println("Received: " + record.value() + " from partition: " + consumer.assignment());
}
}(3) AcknowledgingConsumerAwareMessageListener
이 리스너는 Acknowledgment와 Consumer 객체 둘 다 사용할 수 있는 리스너입니다. 이를 통해 메시지의 수동 커밋과 컨슈머에 대한 세부적인 정보 접근이 동시에 가능합니다.
public class MyAckConsumerAwareListener implements AcknowledgingConsumerAwareMessageListener<String, String> {
@Override
public void onMessage(ConsumerRecord<String, String> record, Acknowledgment acknowledgment, Consumer<?, ?> consumer) {
System.out.println("Received: " + record.value() + " from partition: " + consumer.assignment());
acknowledgment.acknowledge(); // 수동 커밋
}
}(4) BatchAcknowledgingMessageListener
배치 리스너에서 수동 커밋이 필요한 경우 사용됩니다. 배치로 처리된 여러 레코드들을 한꺼번에 처리한 후, 수동으로 커밋할 수 있습니다.
public class MyBatchAckListener implements BatchAcknowledgingMessageListener<String, String> {
@Override
public void onMessage(List<ConsumerRecord<String, String>> records, Acknowledgment acknowledgment) {
System.out.println("Received batch of records: " + records.size());
acknowledgment.acknowledge(); // 수동 커밋
}
}(5) BatchConsumerAwareMessageListener
배치 리스너이면서, 컨슈머 객체에 접근할 수 있는 리스너입니다. 다수의 레코드를 배치로 처리하면서 동시에 컨슈머의 상태 정보를 활용하여 세밀한 처리가 가능합니다.
public class MyBatchConsumerAwareListener implements BatchConsumerAwareMessageListener<String, String> {
@Override
public void onMessage(List<ConsumerRecord<String, String>> records, Consumer<?, ?> consumer) {
System.out.println("Received batch of records from consumer: " + consumer.assignment());
}
}(6) BatchAcknowledgingConsumerAwareMessageListener
이 리스너는 배치 메시지를 처리하면서 컨슈머 객체에 접근하고, 수동 커밋을 지원하는 리스너입니다. 배치로 데이터를 처리하면서도 오프셋을 수동으로 관리할 수 있어 높은 제어권을 제공합니다.
public class MyBatchAckConsumerAwareListener implements BatchAcknowledgingConsumerAwareMessageListener<String, String> {
@Override
public void onMessage(List<ConsumerRecord<String, String>> records, Acknowledgment acknowledgment, Consumer<?, ?> consumer) {
System.out.println("Received batch of records from consumer: " + consumer.assignment());
acknowledgment.acknowledge(); // 수동 커밋
}
}카프카 컨슈머를 구현할 때, 커밋(commit)을 관리하는 것은 중요한 작업 중 하나입니다. 특히 메시지 처리가 끝난 후 오프셋을 저장하는 커밋 방식은 메시지의 중복 처리나 데이터 손실을 방지하는 데 필수적입니다. 기본적인 카프카 클라이언트 라이브러리에서는 오토 커밋(Auto Commit), 동기 커밋(Synchronous Commit), 비동기 커밋(Asynchronous Commit) 등의 커밋 방식을 사용할 수 있지만, 운영 환경에서는 더 다양한 커밋 요구사항이 있습니다. 이러한 다양한 커밋 방식은 로직을 새로 작성해야 하므로 구현이 복잡해질 수 있습니다.
하지만 스프링 카프카(Spring Kafka)에서는 이러한 커밋 방식을 보다 쉽게 관리할 수 있도록 다양한 커밋 전략을 제공합니다. 스프링 카프카에서 커밋 전략을 ‘AckMode’라고 부르며, 여러 가지 커밋 방식이 미리 정의되어 있어, 사용자가 상황에 맞는 전략을 선택할 수 있게 합니다. 이 AckMode는 카프카 프로듀서에서 사용하는 acks 옵션과는 다른 개념이므로, 이 두 용어를 혼동하지 않도록 주의해야 합니다.
AckMode란?
AckMode는 메시지 처리가 완료된 후 오프셋을 어떻게 커밋할지 결정하는 방식입니다. Ack는 “Acknowledgment(인정)“의 줄임말로, 메시지를 성공적으로 처리한 것을 카프카에 알리기 위해 사용됩니다. 스프링 카프카는 다양한 AckMode를 제공하며, 이를 통해 메시지 처리 후의 오프셋 커밋을 자동화하거나 수동으로 처리할 수 있습니다.
스프링 카프카에서 제공하는 주요 AckMode는 다음과 같습니다:
-
RECORD
• 각 레코드마다 커밋: 메시지를 하나 처리할 때마다 오프셋을 커밋하는 방식입니다. 가장 세밀한 커밋 방식이며, 각 메시지 처리 후 바로 커밋하므로 데이터 유실을 최소화할 수 있지만, 오버헤드가 크고 성능 저하가 있을 수 있습니다.
-
BATCH (기본값)
• 배치 단위로 커밋: poll() 메서드로 가져온 여러 레코드를 배치로 처리한 후 커밋합니다. 기본적으로 스프링 카프카에서 사용하는 커밋 방식이며, 성능과 신뢰성 사이의 균형을 제공합니다. 한 번에 여러 레코드를 처리한 후 커밋하기 때문에 성능상 이점이 있지만, 장애 발생 시 일부 데이터 손실이 있을 수 있습니다.
-
TIME
• 일정 시간 간격으로 커밋: 특정 시간마다 커밋을 수행합니다. 예를 들어, 1분마다 메시지 처리 상태를 커밋하고 싶을 때 사용할 수 있습니다. 이 방식은 시간을 기준으로 커밋하기 때문에, 시간 범위 내에서 처리된 모든 메시지가 커밋됩니다.
-
COUNT
• 특정 레코드 개수마다 커밋: 정해진 수의 레코드를 처리할 때마다 커밋합니다. 예를 들어, 100개의 메시지를 처리한 후에 한 번 커밋하는 식으로 동작합니다. 메시지 개수를 기준으로 커밋 시점을 결정하는 방식입니다.
-
COUNT_TIME
• 레코드 개수 또는 시간 중 먼저 도달한 조건에 따라 커밋: 일정 시간마다 커밋하거나, 정해진 레코드 수만큼 처리한 후 커밋합니다. 둘 중 하나의 조건이 먼저 만족되면 커밋을 수행합니다. 예를 들어, 5분이 지났거나 1000개의 레코드가 처리되면 커밋을 수행합니다.
-
MANUAL
• 수동 커밋: 수동으로 커밋을 호출해야 커밋이 이루어집니다. 개발자가 메시지 처리 완료 시점에 수동으로 커밋을 명시적으로 호출해야 하므로, 메시지 처리 흐름을 세밀하게 제어할 수 있습니다. 수동 커밋 방식을 사용할 때는 Acknowledgment 객체를 통해 커밋을 수행합니다.
@KafkaListener(topics = "my-topic")
public void listen(String message, Acknowledgment ack) {
// 메시지 처리
ack.acknowledge(); // 수동 커밋
}
-
MANUAL_IMMEDIATE
• 수동 커밋 + 즉시 반영: MANUAL과 비슷하지만, 수동 커밋을 호출하면 즉시 오프셋을 반영합니다. 일반적인 수동 커밋 방식에서는 처리된 메시지가 일정 주기마다 커밋될 수 있지만, MANUAL_IMMEDIATE는 호출 즉시 오프셋이 반영되므로 신속하게 커밋이 이루어집니다.
스프링 카프카에서의 기본 설정
스프링 카프카 컨슈머에서 AckMode의 기본값은 BATCH입니다. 즉, poll() 메서드를 통해 가져온 레코드 배치를 처리한 후에 오프셋을 커밋합니다. 또한, 컨슈머의 enable.auto.commit 옵션은 기본적으로 false로 설정되어 있어, 자동으로 커밋을 수행하지 않고, 스프링 카프카가 제공하는 커밋 로직에 따라 커밋이 이루어집니다.
기본 리스너 컨테이너
application.yaml에서 설정할 수 있는 컨슈머 와 리스너 옵션값은 다음과 같다.
spring:
kafka:
consumer:
# 자동 커밋 간격(밀리초 단위) - auto commit이 활성화된 경우, 얼마나 자주 커밋할지 설정
auto-commit-interval: 1000
# 오프셋을 처음부터 가져올지 가장 마지막 오프셋부터 가져올지 설정 (earliest 또는 latest)
auto-offset-reset: earliest
# Kafka 클러스터에 연결할 서버 주소 (comma-separated list)
bootstrap-servers: my-kafka:9092
# Consumer 클라이언트 ID - 컨슈머를 식별하는데 사용
client-id: my-consumer-client-id
# 자동 커밋을 활성화할지 여부 (true로 설정하면 자동으로 커밋)
enable-auto-commit: false
# 메시지 가져오기 대기 시간 최대 값 (밀리초 단위)
fetch-max-wait: 500
# 메시지 가져오기 최소 크기 (바이트 단위)
fetch-min-size: 1000
# 컨슈머 그룹 ID 설정
group-id: my-consumer-group
# 하트비트 전송 간격 (밀리초 단위)
heartbeat-interval: 3000
# 메시지 키 디시리얼라이저 설정
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 한 번에 가져올 최대 레코드 수
max-poll-records: 500
# 카프카 컨슈머 속성 (추가적인 Kafka consumer 속성 설정)
properties:
isolation.level: read_committed
# 메시지 값 디시리얼라이저 설정
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# ack-count 기반 커밋 설정 - 이 값에 따라 지정된 레코드 수 처리 후 커밋
ack-count: 100
# AckMode 설정 (RECORD, BATCH, TIME, COUNT 등 선택 가능)
ack-mode: BATCH
# 커밋할 시간 간격 설정 (밀리초 단위)
ack-time: 3000
# 리스너 클라이언트 ID
client-id: my-listener-client-id
# 컨슈머 동시성 (몇 개의 스레드가 병렬로 컨슈머를 실행할지 설정)
concurrency: 3
# 이벤트가 발생하지 않았을 때 대기 간격 (밀리초 단위)
idle-event-interval: 10000
# 컨테이너 구성 로깅 여부
log-container-config: true
# 컨슈머 상태 모니터링 간격 (밀리초 단위)
monitor-interval: 30000
# polling 중지로 간주될 임계값 설정
no-poll-threshold: 3.0
# poll 타임아웃 (밀리초 단위)
poll-timeout: 3000
# 리스너 타입 설정 (ex. batch로 설정하면 배치 단위로 처리)
type: singlepackage com.example;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.TopicPartition;
import org.springframework.kafka.annotation.PartitionOffset;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.Acknowledgment;
@SpringBootApplication
public class SpringConsumerApplication {
private static final Logger logger = LoggerFactory.getLogger(SpringConsumerApplication.class);
public static void main(String[] args) {
SpringApplication application = new SpringApplication(SpringConsumerApplication.class);
application.run(args);
}
// 리스너 1: 기본 레코드 리스너
@KafkaListener(topics = "test", groupId = "test-group-00")
public void recordListener(ConsumerRecord<String, String> record) {
logger.info("Received record: {}", record.toString());
}
// 리스너 2: 메시지 값만 처리하는 리스너
@KafkaListener(topics = "test", groupId = "test-group-01")
public void singleTopicListener(String messageValue) {
logger.info("Received message: {}", messageValue);
}
// 리스너 3: 특정 설정이 포함된 리스너
@KafkaListener(topics = "test", groupId = "test-group-02",
properties = {
"max.poll.interval.ms:60000",
"auto.offset.reset:earliest"
})
public void singleTopicWithPropertiesListener(String messageValue) {
logger.info("Received message with properties: {}", messageValue);
}
// 리스너 4: 동시성을 설정한 리스너
@KafkaListener(topics = "test", groupId = "test-group-03", concurrency = "3")
public void concurrentTopicListener(String messageValue) {
logger.info("Received concurrent message: {}", messageValue);
}
// 리스너 5: 특정 파티션을 지정한 리스너
@KafkaListener(topicPartitions = {
@TopicPartition(topic = "test01", partitions = {"0", "1"}),
@TopicPartition(topic = "test02", partitionOffsets = @PartitionOffset(partition = "0", initialOffset = "3"))
}, groupId = "test-group-04")
public void listenSpecifiedPartition(ConsumerRecord<String, String> record) {
logger.info("Received record from specific partition: {}", record.toString());
}
}커스텀 리스너 컨테이너
package com.example;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.listener.ConsumerAwareRebalanceListener;
import org.springframework.kafka.listener.config.ContainerProperties;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.apache.kafka.common.TopicPartition;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class ListenerContainerConfiguration {
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> customContainerFactory() {
// Kafka Consumer 설정
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "my-kafka:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// Kafka ConsumerFactory 생성
DefaultKafkaConsumerFactory<String, String> cf = new DefaultKafkaConsumerFactory<>(props);
// ConcurrentKafkaListenerContainerFactory 설정
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(cf);
// Consumer Rebalance Listener 설정
factory.getContainerProperties().setConsumerRebalanceListener(new ConsumerAwareRebalanceListener() {
@Override
public void onPartitionsRevokedBeforeCommit(Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
// 파티션 할당 해제 전 호출되는 콜백
System.out.println("Partitions revoked before commit: " + partitions);
}
@Override
public void onPartitionsRevokedAfterCommit(Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
// 파티션 할당 해제 후 호출되는 콜백
System.out.println("Partitions revoked after commit: " + partitions);
}
@Override
public void onPartitionsAssigned(Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
// 파티션 할당 시 호출되는 콜백
System.out.println("Partitions assigned: " + partitions);
}
@Override
public void onPartitionsLost(Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
// 파티션을 잃었을 때 호출되는 콜백
System.out.println("Partitions lost: " + partitions);
}
});
// Listener 설정
factory.setBatchListener(false); // 배치 리스너 비활성화 (레코드 단위 처리)
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.RECORD); // 개별 레코드 단위로 커밋
return factory;
}
}