문제
접근 방법
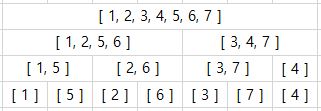
- Merge Sort의 과정이 메모이제이션 된 머지소트트리를 만들었다.
- 어떤 수 X 보다 작은 수의 개수가 K - 1 개라면 X는 K 번째 수이다.
- 각각의 머지 소트 중간 과정은 전부 정렬되어 있으므로 배열 i, j의 범위 에 해당하는 수 중에서 X보다 작은 수의 개수를 탐색하기 위해 이분 탐색을 통해 작은 수의 개수를 탐색 하였다.
- 어떤 수 X를 구하기 위한 방법을 처음에는 입력 배열을 이용하여 이분 탐색을 하려고 하였으나, 입력 배열이 정렬된 상태가 아니었기에 이분 탐색을 사용 할 수 없었다.
그래서 입력 가능한 수의 범위인 -10^9 ~ 10^9 의 범위에서 이분탐색을 통해 X를 구하였다.
풀이 코드
import java.util.*;
import java.io.*;
public class Main {
static int[] nums;
static int[][] tree;
public static void merge_tree(int idx, int start, int end) {
tree[idx] = new int[end - start + 1];
if (start == end) {
tree[idx][0] = nums[start];
return;
}
int center = (start + end) >> 1;
merge_tree(idx * 2, start, center);
merge_tree(idx * 2 + 1, center + 1, end);
int lp = 0, rp = 0, l_size = tree[idx * 2].length, r_size = tree[idx * 2 + 1].length, p = 0;
while (lp < l_size && rp < r_size) {
if (tree[idx * 2][lp] > tree[idx * 2 + 1][rp]) tree[idx][p++] = tree[idx * 2 + 1][rp++];
else tree[idx][p++] = tree[idx * 2][lp++];
}
while (lp < l_size) tree[idx][p++] = tree[idx * 2][lp++];
while (rp < r_size) tree[idx][p++] = tree[idx * 2 + 1][rp++];
}
public static int solution(int s, int e, int K, int idx, int start, int end){
if (end < s || e < start) return 0;
if (s <= start && end <= e) {
int lp = 0, rp = tree[idx].length;
int center;
while (lp < rp) {
center = (rp + lp) >> 1;
if (tree[idx][center] <= K) lp = center + 1;
else rp = center;
}
return rp;
}
int center = (start + end) >> 1;
return solution(s, e, K, idx * 2, start, center) + solution(s, e, K, idx * 2 + 1, center + 1, end);
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
nums = new int[N + 1];
st = new StringTokenizer(br.readLine());
for (int i = 1; i <= N; i++) nums[i] = Integer.parseInt(st.nextToken());
int val = 2;
while (true) {
if (val >= N) {
tree = new int[val << 1][];
break;
}
val = val << 1;
}
merge_tree(1, 1, N);
int s = 0, e = 0, K = 0, l = 0, r = 0, center = 0;
for (int order = 0; order < M; order++) {
st = new StringTokenizer(br.readLine());
s = Integer.parseInt(st.nextToken()); // 시작 인덱스 1시작
e = Integer.parseInt(st.nextToken()); // 끝 인덱스
K = Integer.parseInt(st.nextToken()); // K번째 수
l = -(int)1e9;
r = (int)1e9;
while (l <= r) {
center = (l + r) >> 1;
if (solution(s, e, center, 1, 1, N) < K) l = center + 1;
else r = center - 1;
}
bw.write(l + "\n");
}
bw.flush();
}
}
틀렸던 코드 부분
// 어떤 수 X (함수 내에서는 K) 보다 작은 수의 개수를 찾는 과정
if (s <= start && end <= e) {
if (start == end) return tree[idx][0] < K ? 1 : 0;
int lp = 0, rp = tree[idx].length - 1;
int pivot, center;
while (lp < rp) {
center = (rp + lp) >> 1;
pivot = tree[idx][center];
if (pivot < K) lp = center + 1;
else rp = center;
}
return rp;
}왜 틀렸을까?
2가지 실수를 하였다.
1. X보다 작은수의 개수를 찾는 함수 내부에서 리프 노드에서 탐색할 때 반환이 제대로 되지 않아서, 리프노드일 때를 조건을 달아주었다.
2. rp 의 값을 배열의 길이 - 1 로 해야 마지막 인덱스에 접근 할 수 있다고 생각하여 -1을 달아 주었다.
이분탐색의 경계조건을 아직 정확하게 이해하지 못한 것 같다.
이분 탐색의 오른쪽 끝값을 배열의 길이로 하였더니 배열의 길이가 1 인 리프노드에서도 값이 정확하게 나왔다.
upper_bound 와 lower_bound를 구현하는 방법을 공부해야겠다.
느낀점
- 작성한 코드가 내가 계획한대로 작동하는지 여러 테스트 케이스를 통해서 미리 확인하는 습관을 들여야겠다.
- 설계단계에서 정확한 로직을 통해 설계대로 작동할 수 있도록 해야겠다.

ssafy