Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model 논문 요약 및 강의 리뷰
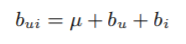
by 투빅스 15기 류채은
간단 요약: Latent Factor model과 Neighborhood model을 융합(integrated)시킨 모델로 넷플릭스 데이터 속 사용자로부터 오는 명백한 피드백(explicit feedback)과 불명확한 피드백(implicit feedback)을 활용하여 더 높은 정확도를 얻었다. 또한, top-K recommendation task에 대한 성과에 기반한 새로운 평가 척도를 제안했다.
기존 Collaborative Filtering의 특징:
- 오직 과거 사용자 행동 양식에만 기반한다.
- Explicit profile의 생성을 요구하지 않는다.
- Domain knowledge가 필요 없다
- Extensive data collection이 필요 없다
Neighborhood model과 Latent Factor model의 특징:
[Neighborhood models]
- Items 사이의 관계 혹은 사용자 사이의 관계를 계산(compute)한다.
- Localized relationships일 때 효율적이다.
- 모든 사용자를 기반한 weak signals에 대한 총체를 파악하는데 약하다.
[Latent Factor models]
- 이 모델의 예시로 SVD(Singular Value Decomposition)가 있다.
- Items와 사용자 모두 같은 latent factor space로 transform시켜 바로 비교 가능하게 만든다.
- 사용자 피드백으로부터 가져온 factors를 통해 평가한다.
- 전체적인 구조를 파악하는데 용이하다.
- 긴밀한 관계(strongly associated)를 맺는 작은 데이터 셋을 파악하는 데 약하다.
<두 모델의 공통점>
- Neighborhood models와 Latent Factor models를 각각 사용할 경우 모두 최적의 결과를 얻기 힘들다.
▶ 따라서, 이 논문에서는 neighborhood approach와 latent factor approach의 장점을 결합시키고 implicit feedback과 explicit feedback을 모두 활용하는 모델을 제안한다.
[기본 Variables]
- User: u,v
- Item: I,j
Baseline estimates:
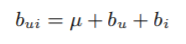
μ: overall average rating
평가기준의 관대함 정도 등에 대한 user and item effects를 고려했다.
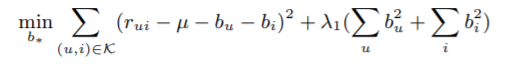
ㄴ b_u와 b_i를 구하기 위한 식
[Neighborhood models]
아이템 기반 접근법(item-oriented approach)으로 아이템 사이의 유사도를 활용한다.
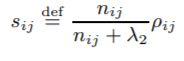
ㄴ 유사성 척도(similarity measure)
N_ij: i와 j 둘 다 평가한 사용자 수

R_ui: 관측되지 않은 사용자 u의 i에 대한 평가
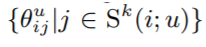 ㄴInterpolation weights
ㄴInterpolation weights
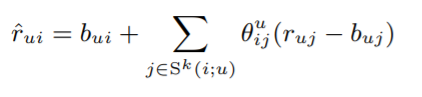
ㄴInterpolation weights를 고려한 더 나은 neighborhood 모델
[Latent Factor models]
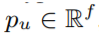
ㄴ사용자 벡터
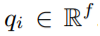
ㄴ아이템 벡터
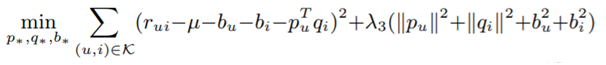
ㄴSimple gradient descent를 사용한 방법
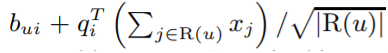
ㄴNSVD model
[Implicit feedback & Netflix data]
Implicit feedback on Netflix data: 영화 본 기록(movie rental history)과 평가 여부(1-평가, 0-평가하지 않음)
[새로운 Neighborhood model]
*모델의 개선되는(improve) 과정을 기록함
1) 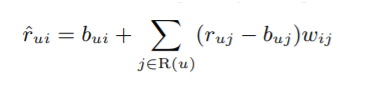
기존과 달리 특정 사용자에 국한되지 않은 독립된 가중치(weights)를 통해 평가하지 않은 작품에 대한 선호도(missing rating)도 고려한다.
2)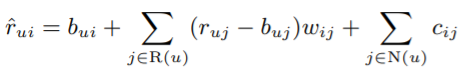
사용자 u의 모든 아이템에 대한 평가를 더하고 예측치는 baseline에서 지나치게 떨어지지 않는다.
3) 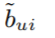
ㄴr_ui에 대한 다른 모델을 사용한 예측
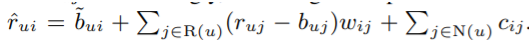
4)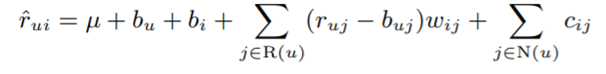
5)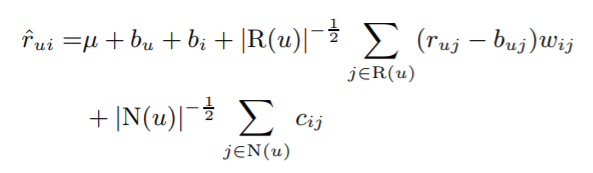
평가를 많이 한 사용자와 적게 한 사용자 간의 양극화를 완화하는 방향으로 개선되었다.
6)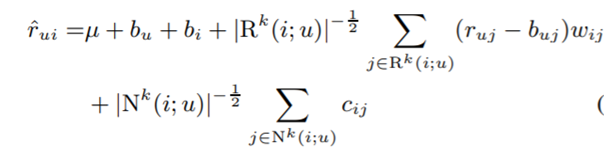 가장 영향이 큰 가중치는 i와 비슷한 아이템과 관련 있을 것이다.
가장 영향이 큰 가중치는 i와 비슷한 아이템과 관련 있을 것이다.
모델 파라미터 학습 방법
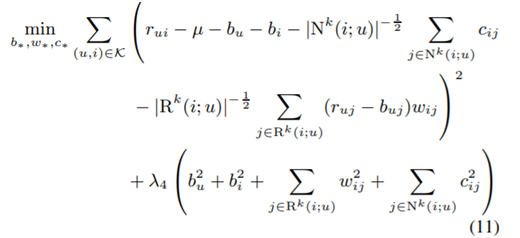
모델 학습 결과
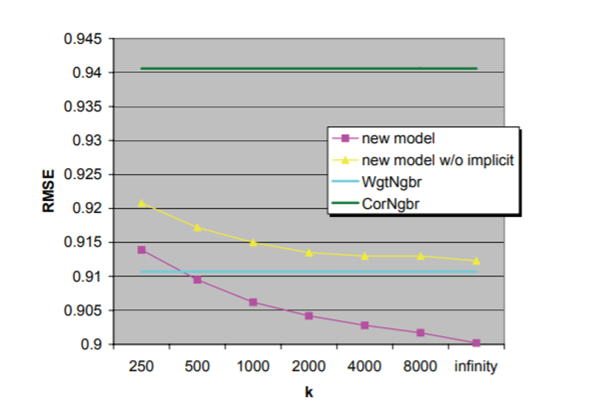
값이 낮을수록 좋은 성과를 내는 것을 뜻하며 새로운 모델의 성과가 가장 좋음을 알 수 있다.
<런닝타임>
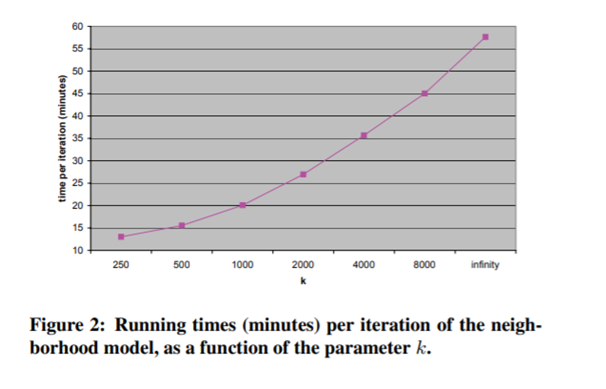
[Latent Factor Models Revisited]
[SVD]
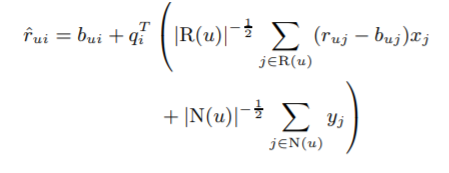
[Asymmetric-SVD]
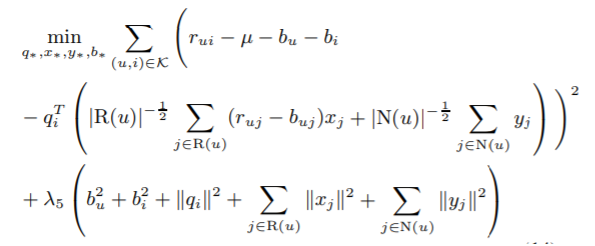
ㄴParameter 학습 방법
장점:
- Parameter 수의 감소
- 새로운 사용자 수용 가능성
- 설명가능성(explainability)
- Implicit feedback의 효율적인 고려(integration)
[SVD++]
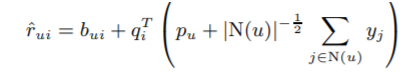
ㄴParameters는 gradient descent통해 학습한다
<비교 평가: RMSE 점수>
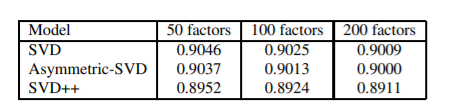 이 표를 통해 Implicit feedback을 직접적으로 활용한 SVD++의 성과가 가장 높음을 알 수 있다.
이 표를 통해 Implicit feedback을 직접적으로 활용한 SVD++의 성과가 가장 높음을 알 수 있다.
[An Integrated Model]
Combined Model : Neighborhood + Latent Factor + Implicit Data
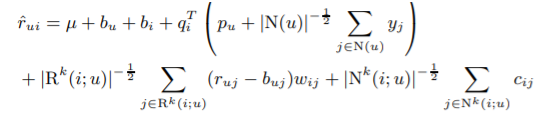 ㄴNeighborhood model과 SVD++을 결합함
ㄴNeighborhood model과 SVD++을 결합함
일반적인 아이템과 사용자의 특성(general properties of the item and the user), 아이템 프로필과 사용자 프로필의 상호작용(interaction between the user profile and the item profile), 미세 조정 값(fine grained adjustments)를 고려했다.
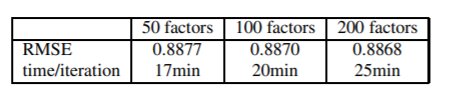 ㄴ평가
ㄴ평가
단일 모델(ex. SVD++) 사용할 때보다 더 높은 성과를 낸 것을 알 수 있다.
[Evaluation through a top-k recommender]
RMSE값이 하향 조정되었을 때에 대한 효과를 top-K recommendation의 질(quality)을 통해 알아보았다.
과정: 각 item마다 1000개의 랜덤의 영화를 도출한다. 이후, 관련된 평가(associated ratings)을 예측하고, 0%부터 100%까지의 평가를 얻는다.
위 과정을 다음 5가지 방법에 사용했다.
-
방법(MovieAvg): the aforementioned non-personalized prediction rule, RMSE=1.053.
-
방법(CorNgbr): correlation-based neighborhood model, RMSE = 0.9406
-
방법(WgtNgbr):the improved neighborhood approach, RMSE= 0.9107
-
방법: the SVD latent factor model, RMSE=0.9025
-
방법: the integrated model, RMSE=0.8870
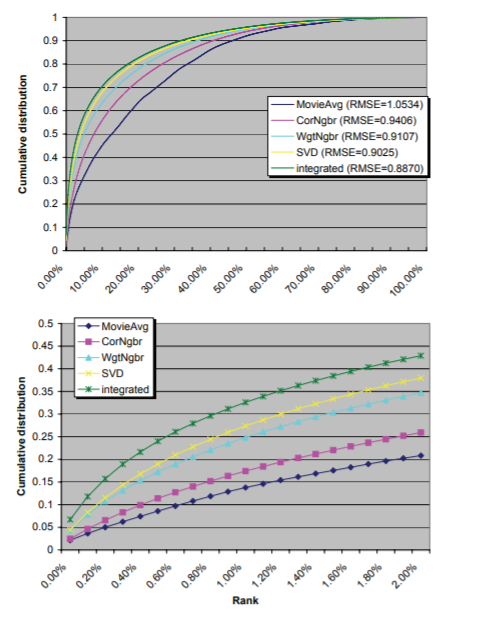
ㄴIntegrated model이 가장 높은 성과를 나타내며 RMSE의 작은 개선이 K products의 질에 대한 큰 개선을 가져옴을 알 수 있다.
