Object
java.lang
- 자바가 기본으로 제공하는 라이브러리(클래스모음) 중
- 가장 기본이 되는 패키지.
- 자바 언어를 이루는 가장 기본이 되는 클래스들을 보관하는 패키지를 뜻함

- 기본적인 정보들
import 생량
-
java.lang 패키지는 모든 자바 애플리케이션에 자동으로 임포트( import )된다. 따라서 임포트 구문을 사용하지 않
아도 된다. -
import java.lang.System;
원래는 이렇게 되있어야됨.
-
자바입장에선 내 영역이니 그냥 생략해!
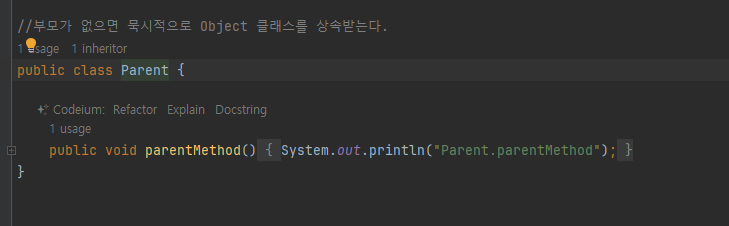
Object

- 자바에서 모든 클래스의 최상위 부모 클래스는 항상 Object 클래스이다
-
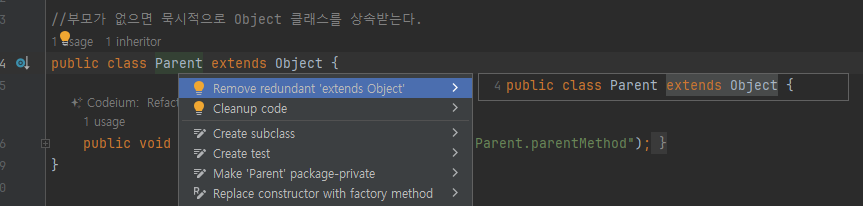
부모가 없으면 묵시적으로 Object 클래스를 상속 받는다
-
적어두지 않으면 자동으로 상속된다
-
public class Parent extends Object {
-
숨겨져있는 코드!
-
Object는 생략하는걸 권장
-
child
-
클래스에 상속 받을 부모 클래스를 명시적으로 지정하면 Object 를 상속 받지 않는다
-
이미 명시적으로 상속했기 때문에 자바가 extends Object 코드를 넣지 않는다.
묵시적(Implicit) vs 명시적(Explicit)
-
묵시적: 개발자가 코드에 직접 기술하지 않아도 시스템 또는 컴파일러에 의해 자동으로 수행되는 것을 의미
-
명시적: 개발자가 코드에 직접 기술해서 작동하는 것을 의미
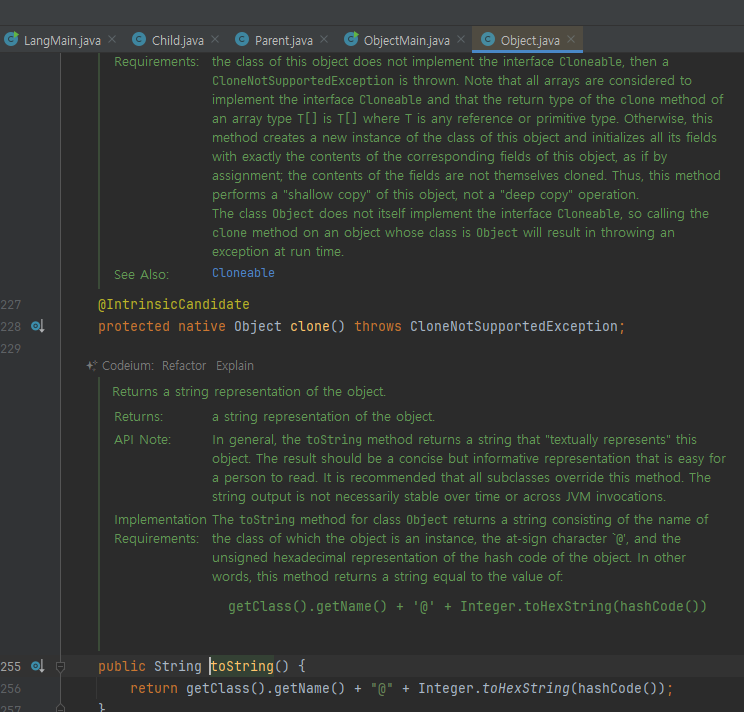
- 전 강의에서 배웠던내용
- 자바에서 모든 객체의 최종 부모는 Object 다
자바에서 Object 클래스가 최상위 부모 클래스인 이유
- 공통 기능 제공
- 다형성의 기본 구현
공통기능 제공
-
객체의 정보 제공
-
객체 비교
-
객체의 클래스 확인
-
이런 기능들을 개발자가 직접 구현하면?
번거로움 -
메서드 이름이 제각각 (일관성 부족) ex) toString() vs objectInfo(), equals() vs same()
해결책: Object 클래스 -
최상위 부모 클래스
-
모든 객체에 필요한 공통 기능을 제공
-
모든 객체는 Object 클래스의 기능을 상속받아 편리하게 사용 가능
-
객체라는 개념에서 필요한 공통기능을 모아 둔게 오브젝트

- 평소에 알던거지만 굉장히 중요한 정보들이다
- 뒤에서 따로 정리!
다형성의 기본 구현
-
부모-자식 관계와 Object 클래스
-
부모 클래스는 자식 클래스의 객체를 담을 수 있음
Object 클래스는 모든 클래스의 부모 클래스
Object 클래스와 다형성 -
Object 클래스는 다형성을 지원하는 기본 메커니즘 제공
-
모든 자바 객체는 Object 타입으로 처리 가능
다양한 타입의 객체를 통합적으로 처리할 수 있게 해줌
Object 클래스의 활용 -
Object 클래스는 모든 객체를 담을 수 있는 '그릇'
서로 다른 타입의 객체를 한 곳에 보관해야 할 때 Object 클래스를 사용
object 다형성
-
기본 예제
-
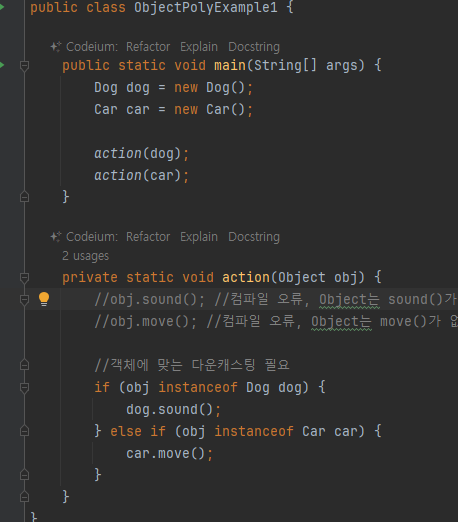
object는 모든 객체의 부모 따라서 어떤 객체든지 인자로 전달 가능

- 전편 강의랑 이어지는내용
- 최상위 부모인 object는 더이상 위로 올라갈수 없음
- 그리고 아래로 내려가는건 안됨 (자식의 특별한 성질을 실행못함)
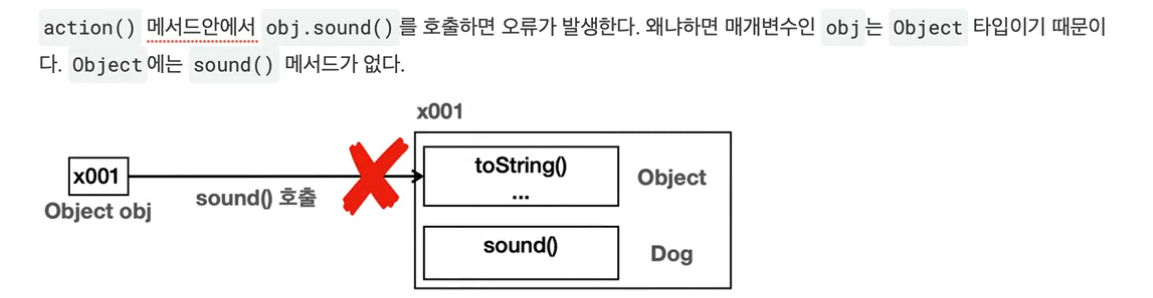
Object를 활용한 다형성의 한계
- Object는 모든 객체를 대상으로 다형적 참조가능
- 쉽게 이야기해 Object는 모든 객체의 부모이므로 모든 객체담음
- Object를 통해 받은 객체를 호출하려면 다운 캐스팅 필요
- Object가 세상의 모든 메서드를 알고있는건아님
-
허나 다형성 제대로 활용하려면
-
다형성 참조 + 메서드 오버라이딩 함께사용
-
그러나 Object는 모든 객체의 부모이므로 모든 객체를 대상으로 다형성 참조는 가능하지만, 메서드 오버라이딩 활용 X
-
결국 각 객체의 기능을 호출하려면 다운캐스팅을 해야함
Object 활용
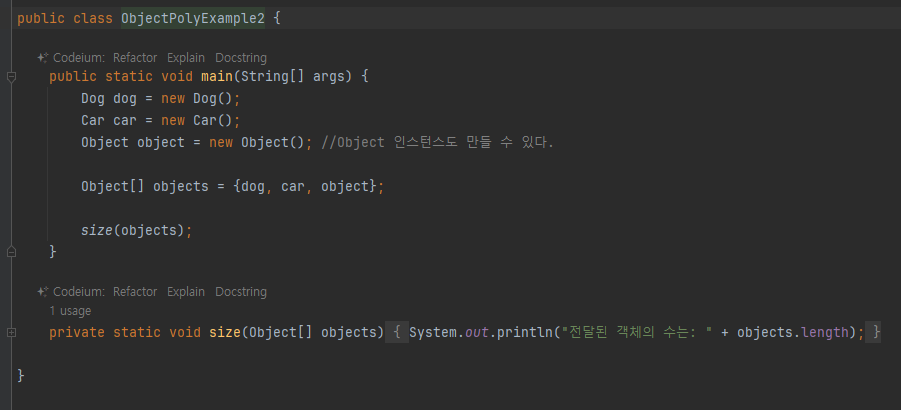
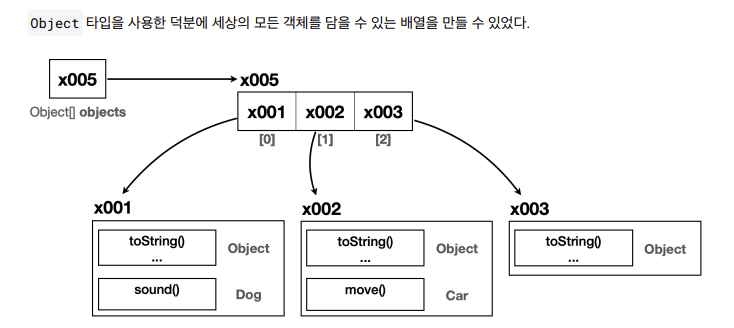
- size() 메서드는 Object 타입만 사용 Object 타입의 배열은 세상의 모든 객체 담을수 있기에 새로운클래스 추가되거나 변경 되어도 이 메서드 수정 X
Obejct 가 없다면?
-
void action(Obj obj) 과 같이 모든 객체를 받을 수 있는 메서드를 만들 수 없다
-
object[] objects처럼 모든 객체를 저장할수 있는 배열 만들수 없다
-
허나 커스텀 MyObject 클래스 만들고 상속하면되지만,
-
전 세계 모든 개발자가 비슷한 클래스를 만들고 서로 호환이 안되겟지
toString
- 객체의 정보를 문자열 형태로 제공
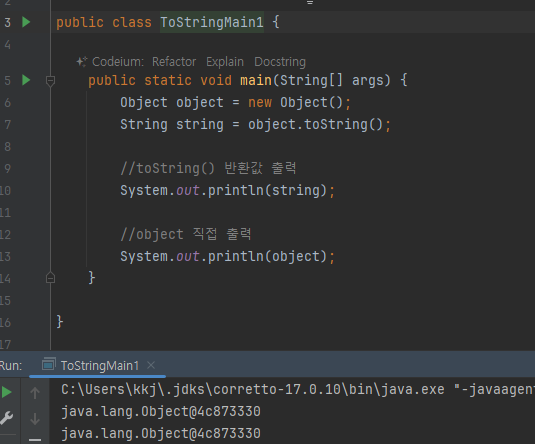
- 인스턴스@참조값
- 결과가 같다 ?

- Object 가 제공하는 toString() 메서드는 기본적으로 패키지를 포함한 객체의 이름과 객체의 참조값(해시
코드)를 16진수로 제공한다
- 해시코드( hashCode() )에 대한 정확한 내용은 이후에 별도로 다룬다. 지금은 객체의 참조값 정도로 생각
하면 된다.
Println vs toString
- 그런데 toString() 의 결과를 출력한 코드와 object 를 println() 에 직접 출력한 코드의 결과가 완전히 같다.
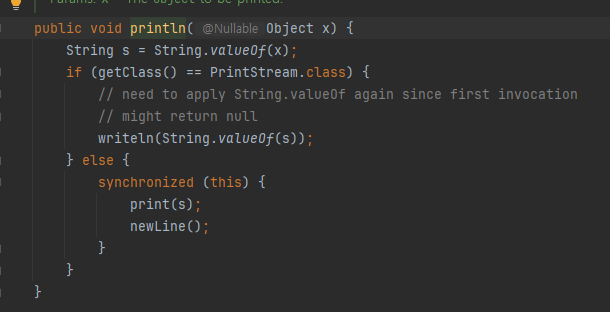

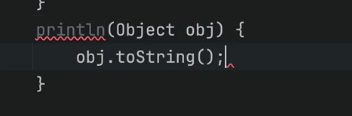
- println 이 toString을 호출해줌
- 둘다 비슷한 기능이라 생각하자
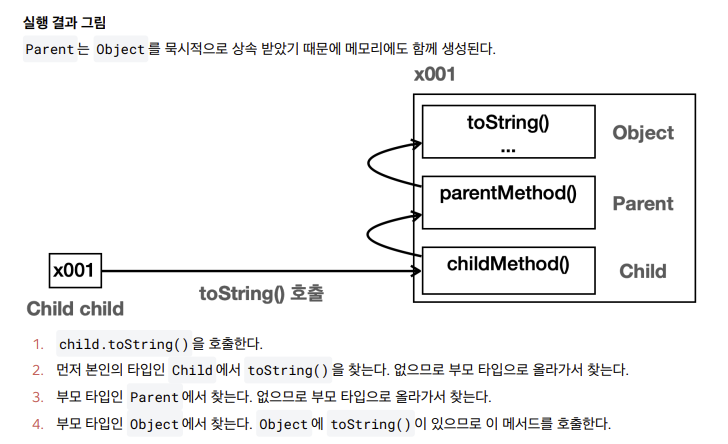
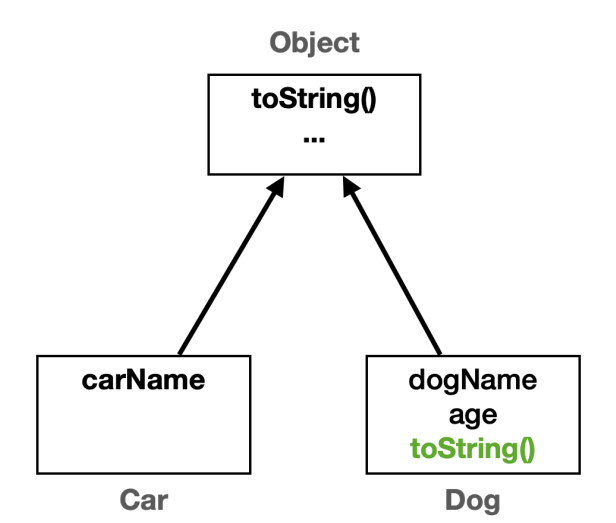
toString() 오버라이딩
- Object.toString() 메서드가 클래스 정보와 참조값을 제공하지만 이 정보만으로는 객체의 상태를 적절히 나타내
지 못한다. 그래서 보통 toString() 을 재정의(오버라이딩)해서 보다 유용한 정보를 제공하는 것이 일반적
-
기본 예제코드 및 메모리 설명
-
왜 객체정보가 나와있는지 하 이제야 알게되는게 진짜신기!
-
자식객체에 toString이 없으니 Object Tostring으로하지
-
원래 알고있엇지만 이런식으로 좀더 지식이 깊어지는느낌
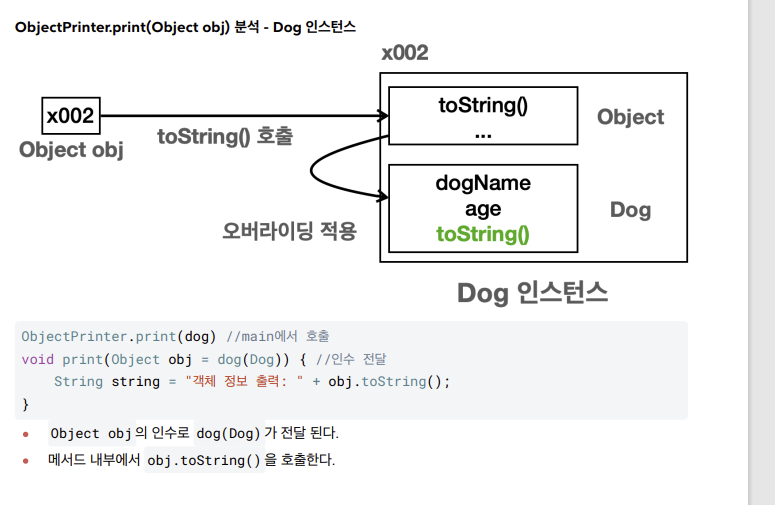
-
오버라이딩이 우선 순위를 가짐으로 자식 메서드가 실행
-
참조값알고 싶으면 ?
-
String refValue = Integer.toHexString(System.identityHashCode(dog1));
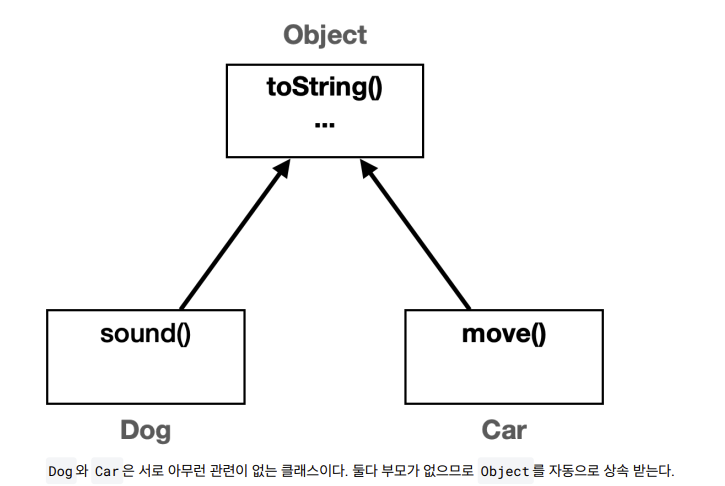
Object와 OCP
만약 Object 가 없고, 또 Object 가 제공하는 toString() 이 없다면 서로 아무 관계가 없는 객체의 정보를 출력하
기 어려울 것이다. 여기서 아무 관계가 없다는 것은 공통의 부모가 없다는 뜻이다.
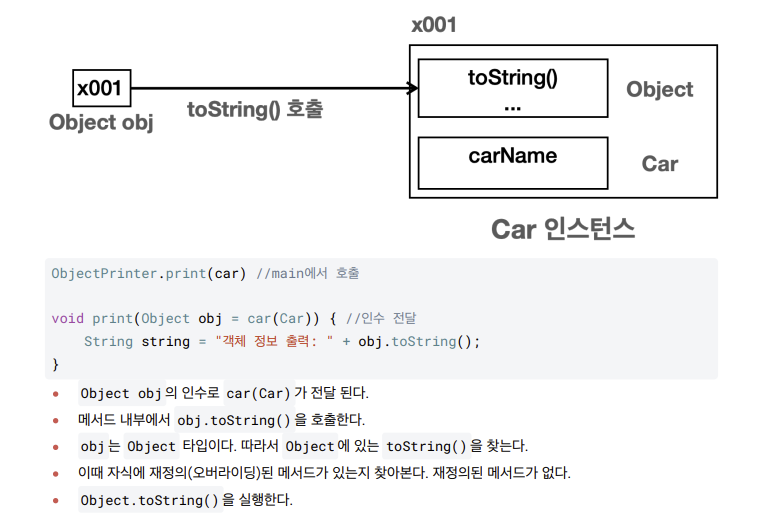
public class BadObjectPrinter {
public static void print(Car car) { //Car 전용 메서드
String string = "객체 정보 출력: " + car.carInfo(); //carInfo() 메서드 만듬
System.out.println(string);
}
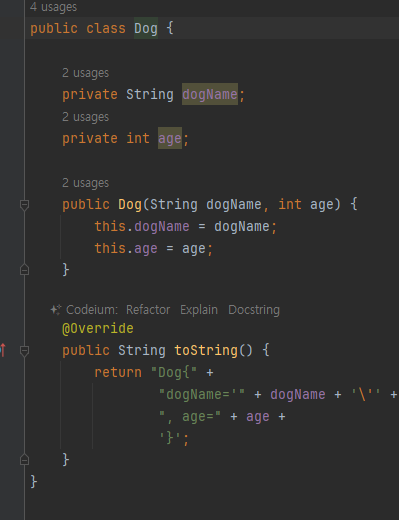
public static void print(Dog dog) { //Dog 전용 메서드
String string = "객체 정보 출력: " + dog.dogInfo(); //dogInfo() 메서드 만듬
System.out.println(string);
}
}- 각각의 클래스마다 각자 다른 메서드를 만들었어야 된다.
- 구체적인 타입인 Car, Dog 사용
- 만약 이후 구체적 클래스가 10개로 늘어나면?
- Object 클래스와 메서드 오버라이딩 문제 해결할 Object.toSTring 메서드가 있따 ( 비슷한 공통 부모클래스 만들어서 해결해도 됨)

-
부모타입으로 갈수록 추상적 / 하위타입으로 구체적
-
추상적인것의 의존 vs 구체적인것의 의존
-
이에 관해 ObjectPrinter와 Object를 사용하는 구조는 다형성 매우 잘 활용
-
다형성을 잘 활용한다? 다형적 참조와 메서드 오버라이딩 적절히 사용
다형적 참조
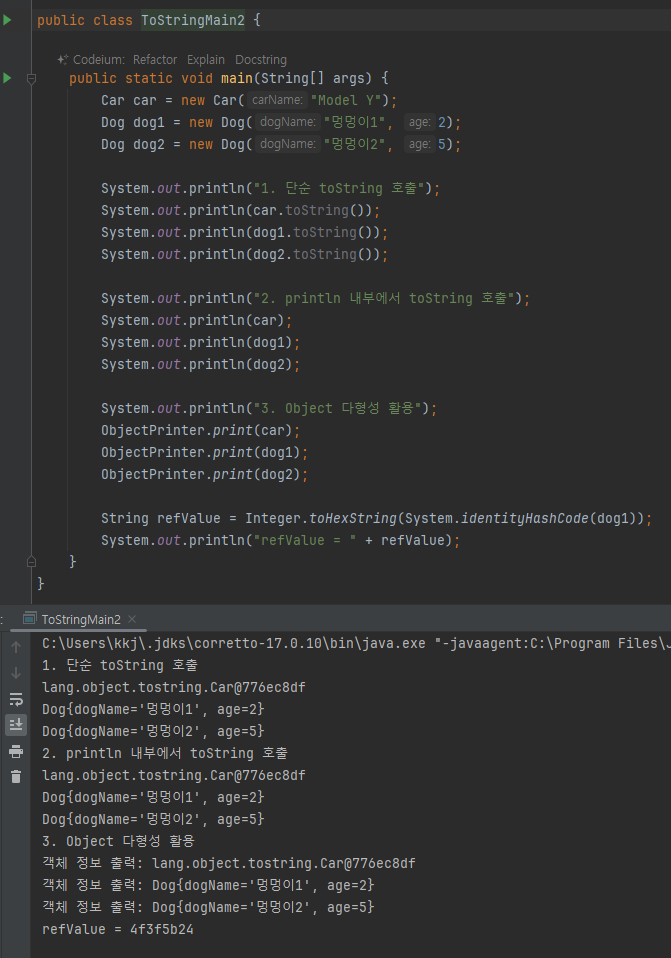
- print(Object obj) , Object 타입을 매개변수로 사용해서 다형적 참조를 사용한다. Car ,
Dog 인스턴스를 포함한 세상의 모든 객체 인스턴스를 인수로 받을 수 있다
메서드 오버라이딩
- : Object 는 모든 클래스의 부모이다. 따라서 Dog , Car 와 같은 구체적인 클래스는
Object 가 가지고 있는 toString() 메서드를 오버라이딩 할 수 있다. 따라서 print(Object obj) 메서
드는 Dog , Car 와 같은 구체적인 타입에 의존(사용)하지 않고, 추상적인 Object 타입에 의존하면서 런타임에
각 인스턴스의 toString() 을 호출할 수 있다
OCP 원칭
- open: 새로운 클래스를 추가하고 , toSTring() 오버라이딩 해서 기능확장
- closed: 새로운 클래스를 추가해도 Object 와 toString() 을 사용하는 클라이언트 코드인
ObjectPrinter 는 변경하지 않아도 된다
System.out.println()
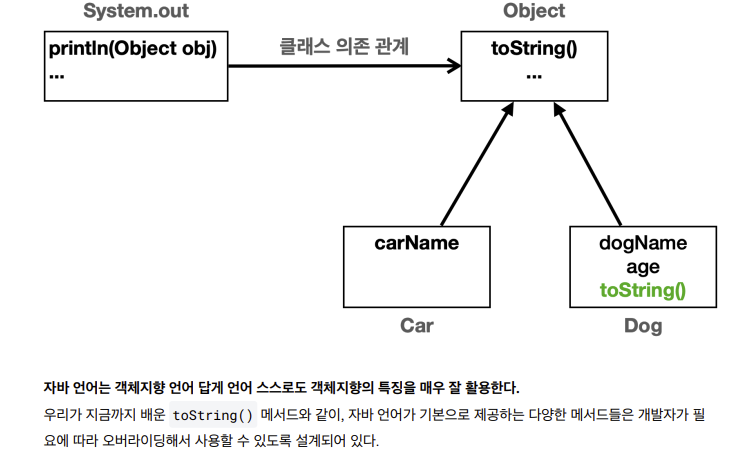
-
ObjectPrinter.print() 는 사실 System.out.println() 의 작동 방식을 설명
-
System.out.println() 메서드도 Object 매개변수를 사용하고 내부에서 toString() 을 호출
-
System.out.println() 를 사용하면 세상의 모든 객체의 정보( toString() )를 편리하게 출력할 수 있다
-
println 은 수정할 필요가 없다!
-
모든 최상위 부분의 오브젝트에만 의존하고 거기에 있는 toString 메서드만 사용하기때문
-
object 에만 의존함
-
뭐가넘어오든간에 toString 호출하거나 오버라이딩 호출하면됨
자바 언어는 객체지향 언어 답게 언어 스스로도 객체지향의 특징을 매우 잘 활용한다.

equals 동일성과 동등성
- 동일성 : == 연산자를 사용해서 두 객체의 참조가 동일한 객체를 가리키고있는지확인
- 동등성 : equals() 메서드를 통해 두 객체가 논리적으로 동등한지 확인
단어 정리
- 동일은 완전히 같음 / 동등은 가치나 수준을 의미하지만 형태나 외곤등이 완전히 같지 않을 수 있음
- 쉽게 -> 동일성은 물리적으로 같은 메모리에 있는 객체 인스턴스인지 참조값확인
- 동등성은 논리적으로 같은지 확인
- 동일성은 자바머신 기준이고 메모리의 참조가 기준이므로 물리적이다.
- 반면 동등성은 보통 사람이 생각하는 논리적인 기준에 맞추어 비교
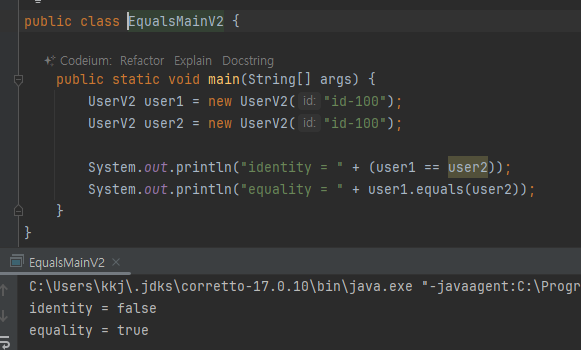
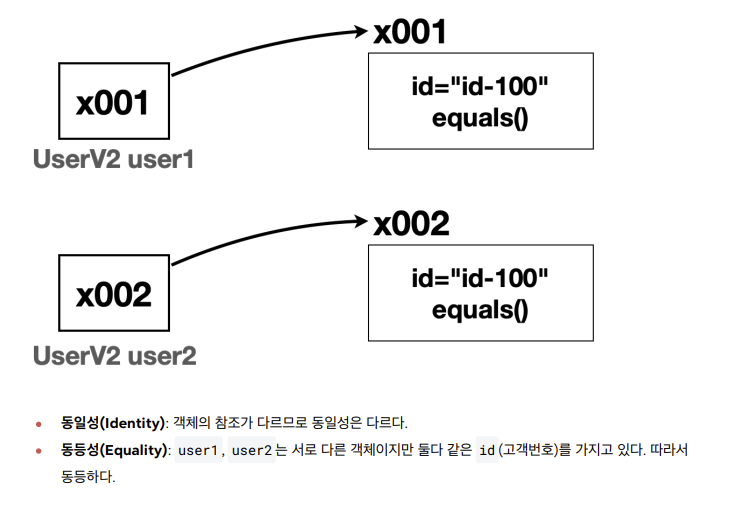
User a = new User("id-100") //참조 x001
User b = new User("id-100") //참조 x002
- 물리적으로 다른 메모리에 있는 객체지만 회원번호 기준으로 생각하면 논리적으로 같은 회원으로 봄
- 동일성은 다르지만 동등성은 같다
String s1 = "hello";
String s2 = "hello";
-
물리적으로 각각의 다른 메모리에 존재하지만 논리적으로 같은 문자열임
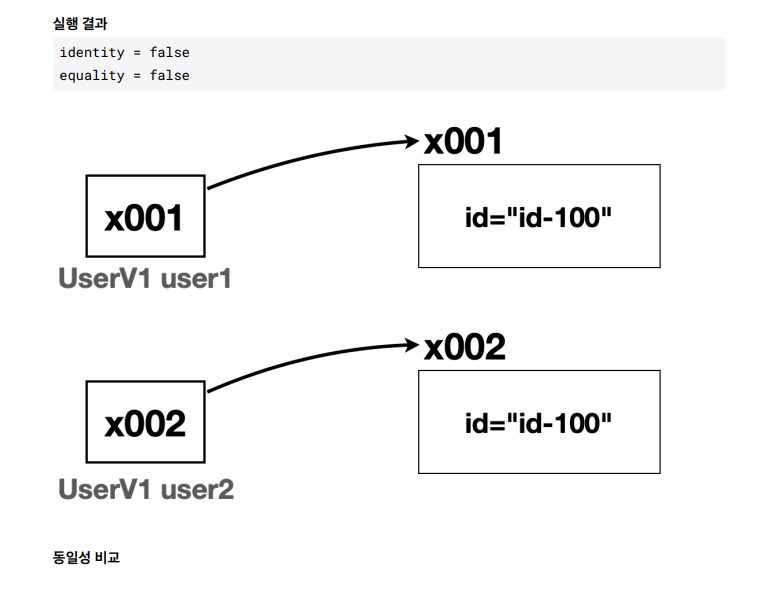
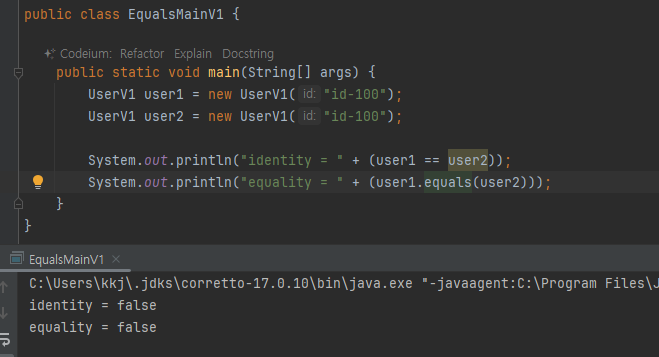
- 오버라이드 되지않아 false
user1.equals(user2)
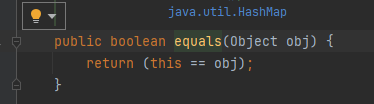
return (user1 == user2) //Object.equals 메서드 안
return (x001 == x002) //Object.equals 메서드 안
return false
false
- 이런식으로 실행 됨
- 동등성 비교시 equals 메서드를 재정의해야됨 아니면 Object는 동일성 비교를 기본으로 제공
equals 구현
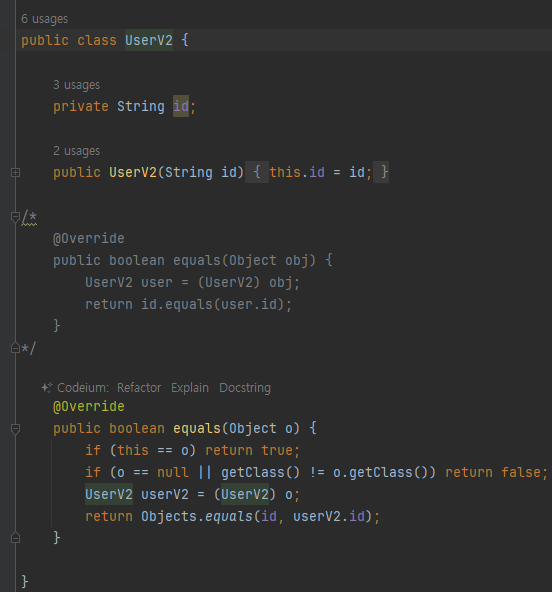
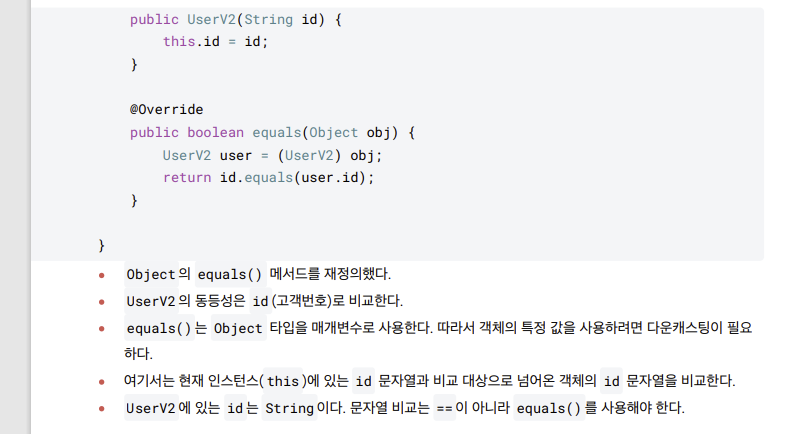
- 파라미터가 Object 타입이기때문에 다운 캐스팅을 한번 해줘야된다.
- 동등성 오버라이딩

-
마지막으로 equals() 메서드 구현 규칙
-
객체는 자기 자신과 동등? x.euals(x) 는항상 true
Object의 나머지 메서드
clone() 객체를 복사할 때 사용한다. 잘 사용하지 않으므로 다루지 않는다.
hashCode() equals() 와 hashCode() 는 종종 함께 사용된다. hashCode() 는 뒤에 컬렉션 프레임워
크에서 자세히 설명한다.
getClass() 뒤에 Class 에서 설명한다.
notify() , notifyAll() , wait() 멀티쓰레드용 메서드이다. 멀티쓰레드에서 다룬다
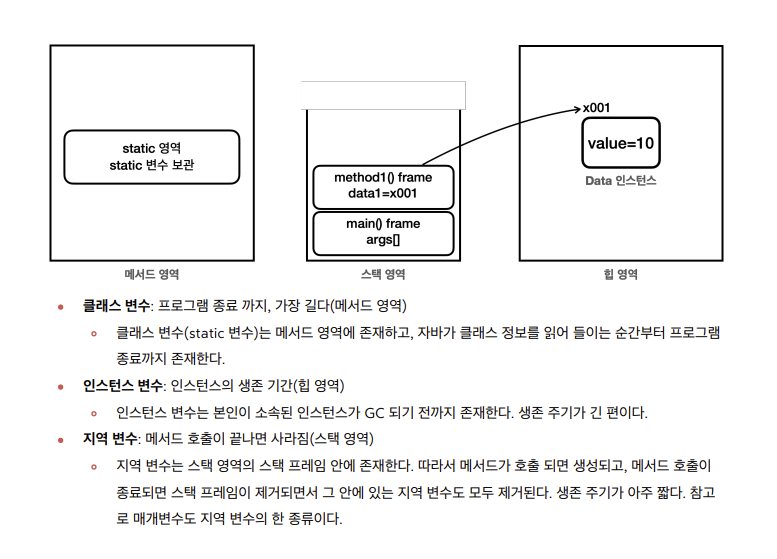
불변 객체
기본형과 참조형의 공유
- 기본형: 하나의 값을 여러 변수에서 절대 공유하지 않음
- 참조형: 하나의 객체를 참조값을 통해 여러 변수에서 공유할 수 있다.
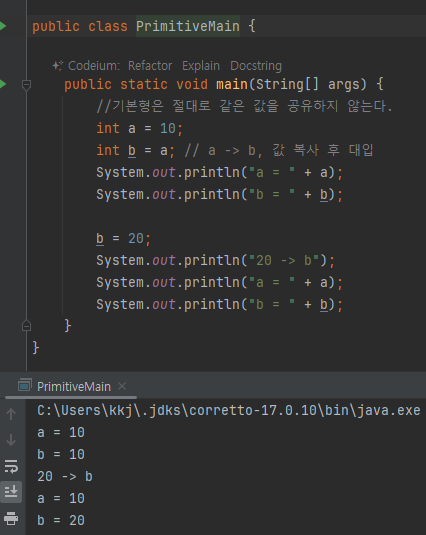
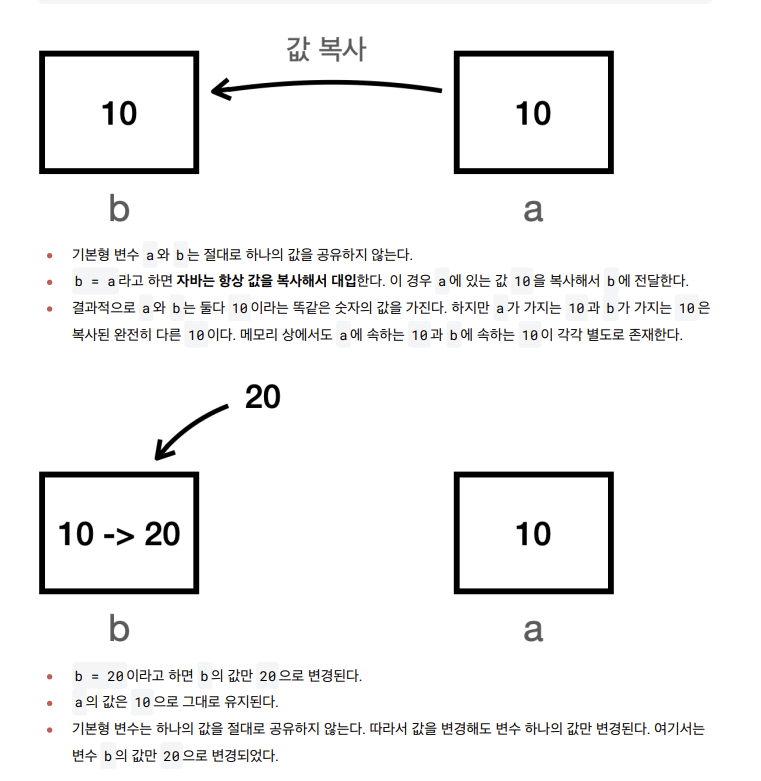
- 전 강의 리마인드 !
- 너무나 당연한거라 패스..
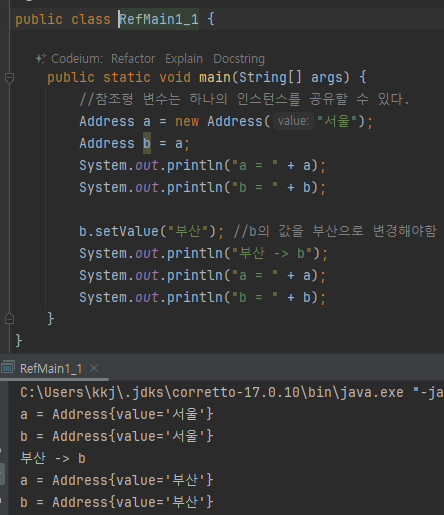

- 참조형은 같은곳을 가리키는 메모리주소를 복사하기때문에 이런 결과가나옴
- 참조값을 통해 같은 인스턴스를 참조한다. 가리킨다
공유참조 사이드 이펙트
- 사이드 이펙트? 어떤 계산이 주된 작업 외에 추가적인 부수 효과를 일으키는 것을 말함
-
앞선 코드를 예시들어 설명
-
사이드 이펙트는 프로그램 특정 부분에서 발생한 변경이 의도치 않게 다른 부분에 영향을 미치는 경우에 발생
-
이로인해 디버깅이 어려워지고 코드 안정성 저하
해결방안
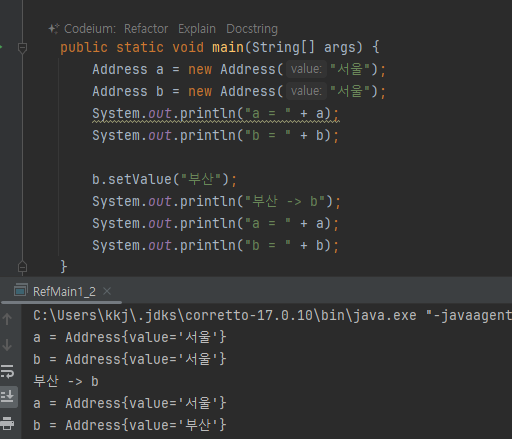
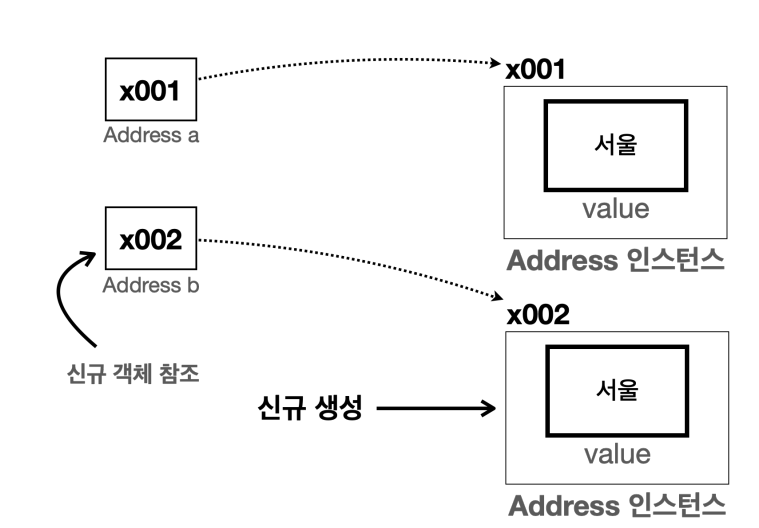
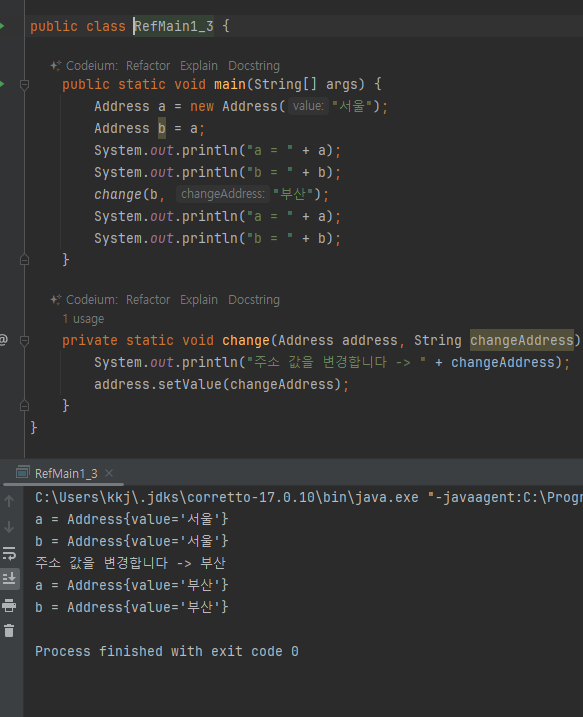
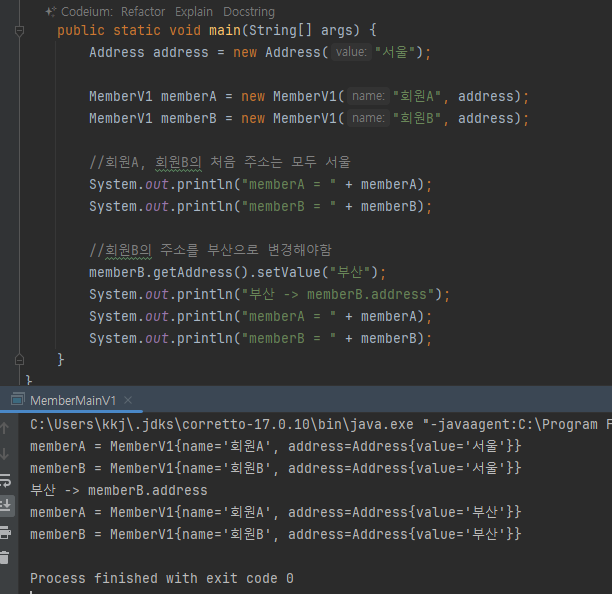
Address a = new Address("서울");
Address b = new Address("서울");
- 서로 다른 인스턴스 참조하면 됨
- 메모리관점으로 쉽게 설명 한다
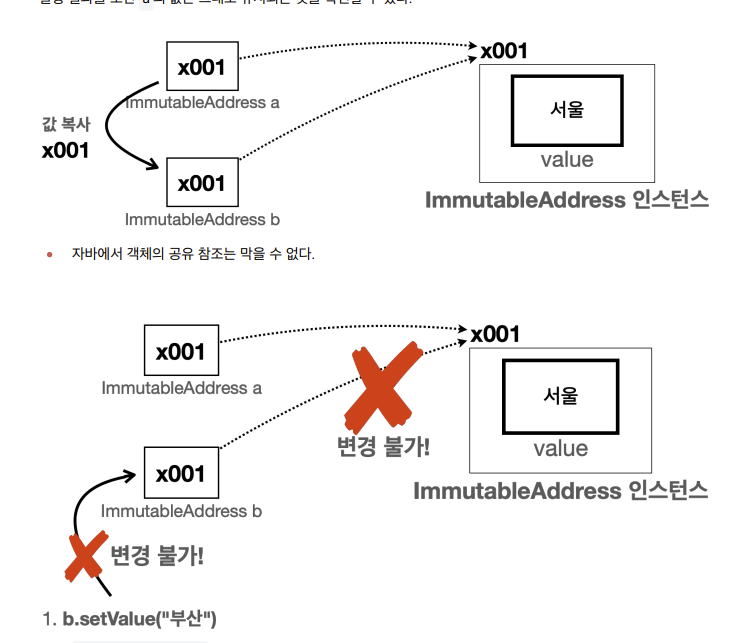
여러 변수가 하나의 객체 공유하는 것을 막을 수 없음
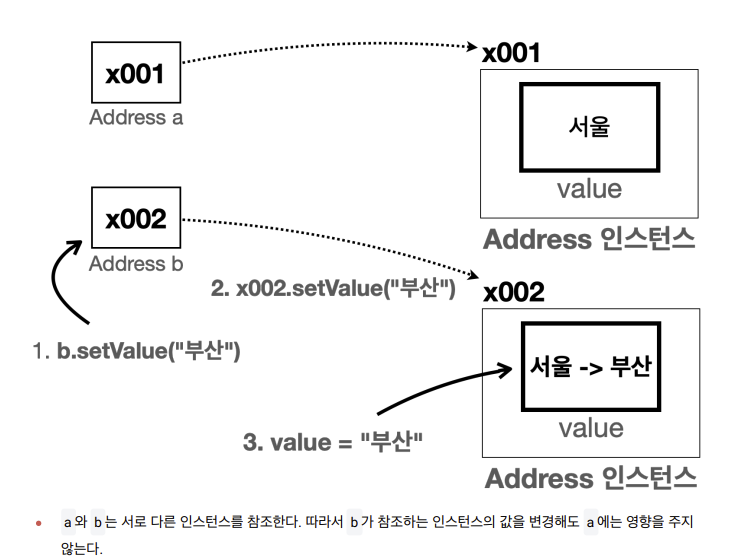
- 지금까지 발생한 모든 문제는 같은 객체(인스턴스)를 변수 a , b 가 함께 공유하기 때문에 발생했다.
- 따라서 객체를 공유하지 않으면 문제가 해결된다. 여기서 변수 a , b 가 서로 각각 다른 주소지로 변경할 수 있어야 한다.
- 이렇게 하려면 서로 다른 객체를 참조하면 된다
-
정리하면 여러 변수가 하나의 객체를 공유하지 않으면 지금까지 설명한 문제들 발생 X
-
허나 하나의 객체를 여러 변수가 공유하지 않도록 강제로 막을 수 있는 방법이 없다
참조 공유를 막을수 있는 방법이 없다
Address a = new Address("서울");
Address b = a; //참조값 대입을 막을 수 있는 방법이 없다.
- b = a 와 같은 코드를 작성하지 않도록 해서, 여러 변수가 하나의 참조값을 공유하지 않으면 문제가 해결될 것 같다.
- 하지만 Address 를 사용하는 개발자 입장에서 실수로 b = a 라고 해도 아무런 오류가 발생하지 않는다.
- 왜냐하면 자바 문법상 Address b = a 와 같은 참조형 변수의 대입은 아무런 문제가 없기 때문이다.
Address b = new Address("서울") //새로운 객체 참조
Address b = a //기존 객체 공유 참조
- 새로운 객체를 참조형 변수를 대입하든 기존 객체를 참조형 변수를 대입하든
- 이 코드는 자바 문법상 정상인 코드
- 참조값을 다른 변수에 대입하는 순간 여러 변수가 하나의 객체를 공유하게 됨
- 객체의 공유를 막을수 있는 방법이 없다..
- 객체의 공유가 필요할때도 있지만 때로는 공유하는 것이 사이드 이펙트를 만듬
- 허나 실제로 훨씬 더 복잡한 상황에서 이러한 문제가발생
-
음 개인적으로 그냥 헷갈리게 함수 추가해서 변경한거같은대 위에 예씨랑 같은거 아닌감..
-
그러나 그냥 캡슐화관점에서 change 그냥 주소바뀌는구나 생각하고 ! 사이드 이펙트가!
-
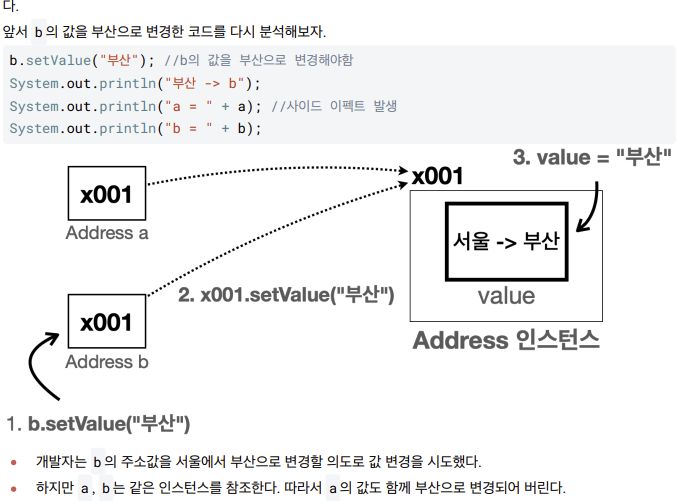
main() 메서드만 보면 a 의 값이 함께 부산으로 변경된 이유를 찾기가 더 어렵다
-
여러 변수가 하나의 객체를 참조하는 공유 참조를 막을 수 있는 방법은 없다. 그럼 공유 참조로 인해 발생하는 문제를 어
떻게 해결할 수 있을까? 단순히 개발자가 공유 참조 문제가 발생하지 않도록 조심해서 코드를 작성해야 할까
불변 객체 도입
- 지금까지 문제 -> 공유하면 안되는 객체를 여러 변수에서 공유했기 때문에 발생한 문제
- 객체의 공유를 막을 수 있는 방법은 없다.
- 그러나 공유 자체는 문제가아님, 객체를 공유한다고 사이드 이펙트 발생하지 않음
- 공유된 객체의 값을 변경한 것에 있음

- 이런 경우 메모리와 성능상 더 효율 적
- 왜냐? 인스턴스를 하나생성하지 않아도 되니 생성 시간줄어서 성능상 효율적이니
- 공유참조가 오히려 더 효율적? (값만 안변경한다면)
b.setValue("부산"); //b의 값을 부산으로 변경해야함
System.out.println("부산 -> b");
System.out.println("a = " + a); //사이드 이펙트 발생
System.out.println("b = " + b)
- 진짜 문제는 이후에 b가 공유 참조하는 인스턴스의 값을 변경하기 때문에 발생한다.
- 참조형 객체는 처음부터 여러 참조형 변수에 공유될수 있도록 설계됨 문제가 아님
- 직접적인 원인은 객체의 값을 어디선가변경했기때문
- ADDRESS 를 변경못하게하면 ?
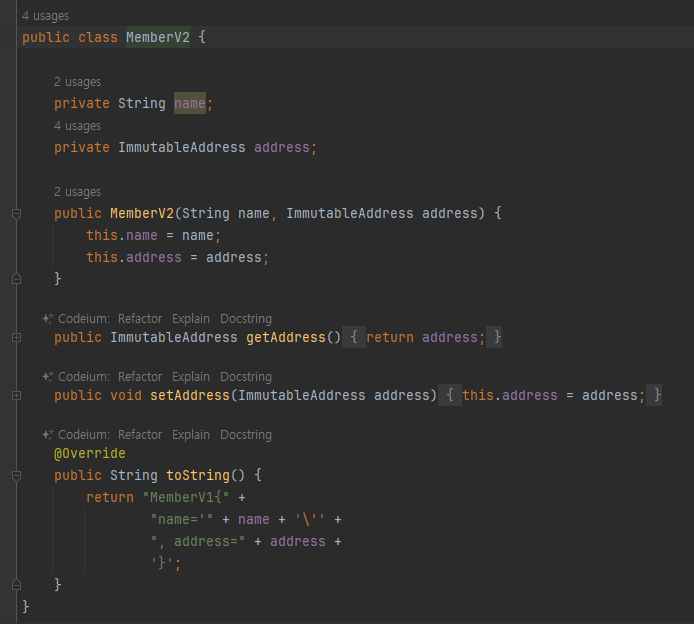
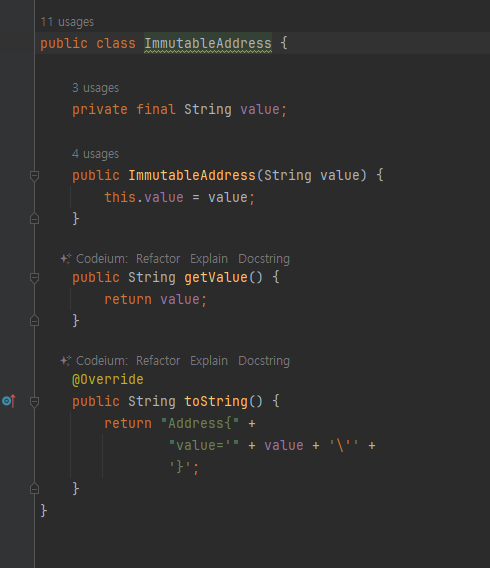
불변 객체 도입
- 객체의 상태(내부값 , 필드 ,멤버변수) 가 변하지 않는 객체를 불변 객체라 함
- 앞서 만들었떤 Address 클래스를 상태가 변하지않는 불변 클래스로 만들자

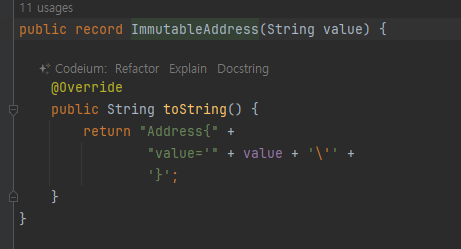
- 레코드 객체로 변환!
- 불변인 final로 선언
- final 선언으로 의도적으로 얘는 바뀌면 안되!
- final 이 핵심이 아니라 안에 값이 변경될수 없는게 불변 객체
- 이 클래스는 생성자를 통해서만 값을 설정할 수 있고, 이후에는 값을 변경하는 것이 불가능하다
- ImmutableAddress 의 경우 값을 변경할 수 있는 b.setValue() 메서드 자체가 제거되었다.
- 이제 ImmutableAddress 인스턴스의 값을 변경할 수 있는 방법은 없다.
- ImmutableAddress 를 사용하는 개발자는 값을 변경하려고 시도하다가, 값을 변경하는 것이 불가능하다는 사
실을 알고, 이 객체가 불변 객체인 사실을 깨닫게 된다.
( setter 컴파일 오류 )
정리
-
불변이라는 단순한 제약을 사용해서 사이드 이펙트라는 큰 문제를 막을 수 있다
-
객체의 공유 참조는 막을 수 없다. 그래서 객체의 값을 변경하면 다른 곳에서 참조하는 변수의 값도 함께 변경되는
사이드 이펙트가 발생한다. 사이드 이펙트가 발생하면 안되는 상황이라면 불변 객체를 만들어서 사용하면 된다.
불변 객체는 값을 변경할 수 없기 때문에 사이드 이펙트가 원천 차단된다 -
불변 객체는 값을 변경할 수 없다. 따라서 불변 객체의 값을 변경하고 싶다면 변경하고 싶은 값으로 새로운 불변
객체를 생성해야 한다. 이렇게 하면 기존 변수들이 참조하는 값에는 영향을 주지 않는다

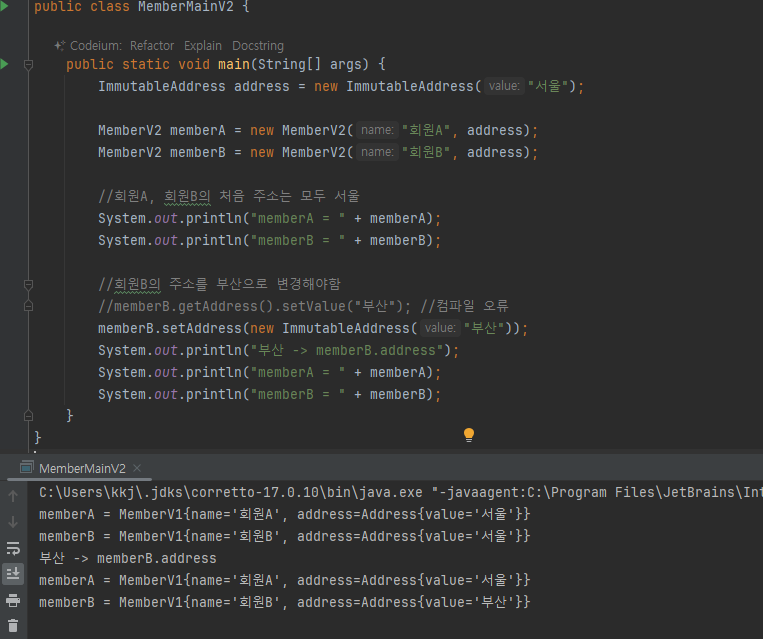
불변객체 예제
- 참조가 같은곳을 가르키니까 둘다 부산으로!
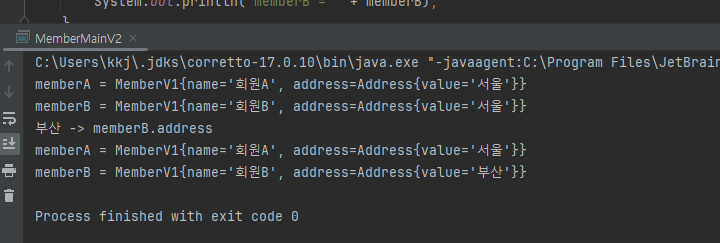
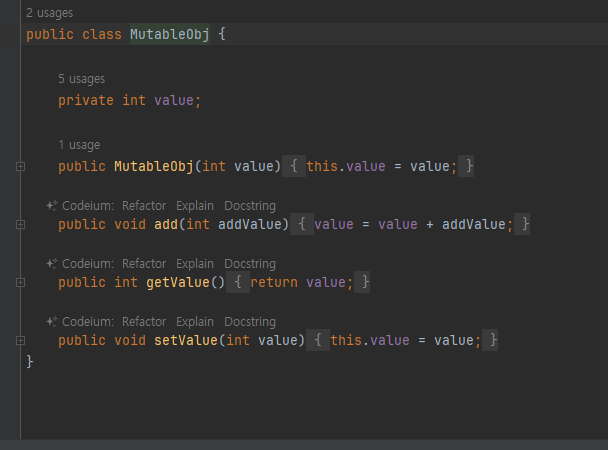
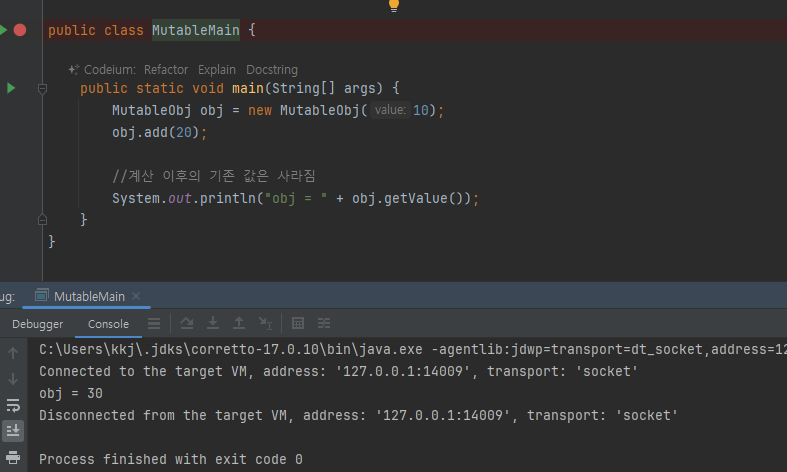
- 사이드 이펙트가 발생하지 않는다. 회원A 는 기존 주소를 그대로 유지한다.
불변객체 값 변경
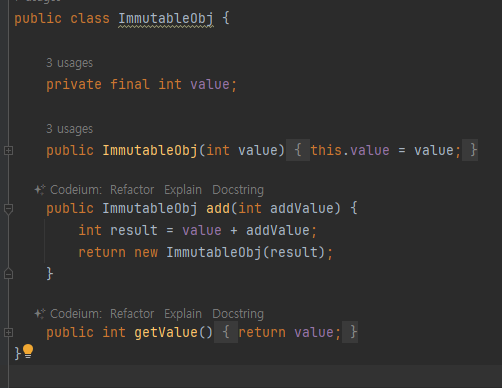
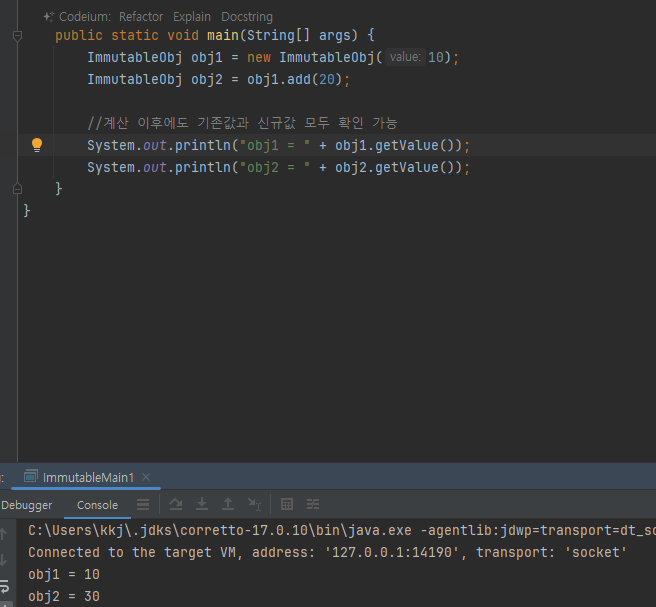
- 변경가능 객체
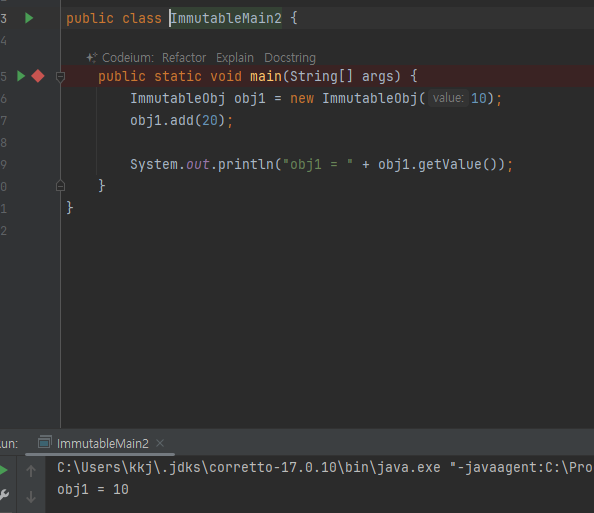
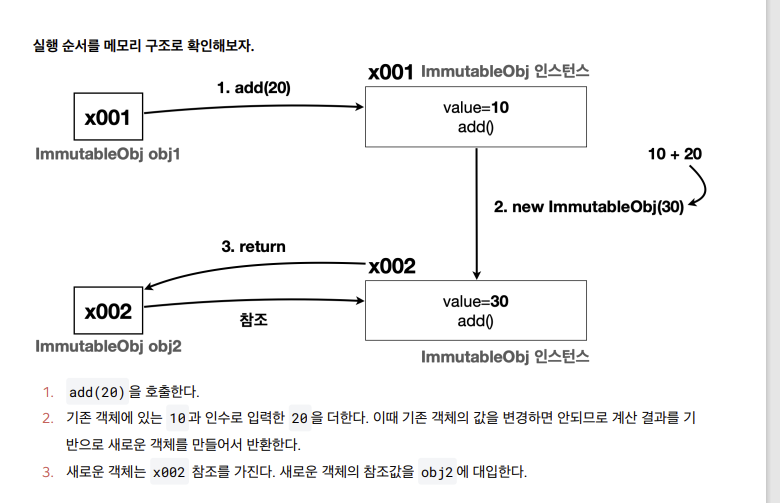
- 불변객체의 예시들
String Class

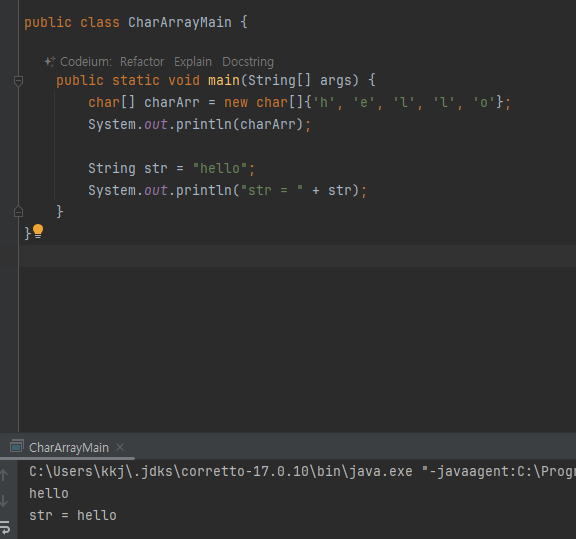
- char[] 을 직접 다루는 방법은 매우 불편하기 때문에 자바는 문자열을 매우 편리하게 다룰 수 있는 String 클래스를 제공
- String 사용방법 예시
- String 은 클래스다. int , boolean 같은 기본형이 아니라 참조형이다. 따라서 str1 변수에는 String 인스턴
스의 참조값만 들어갈 수 있다. 따라서 다음 코드는 뭔가 어색?

- 편의성을 위해서..
String 클래스 구조

- char[] 를 가지고 있었다.
- 실제로 문자하나하나를..
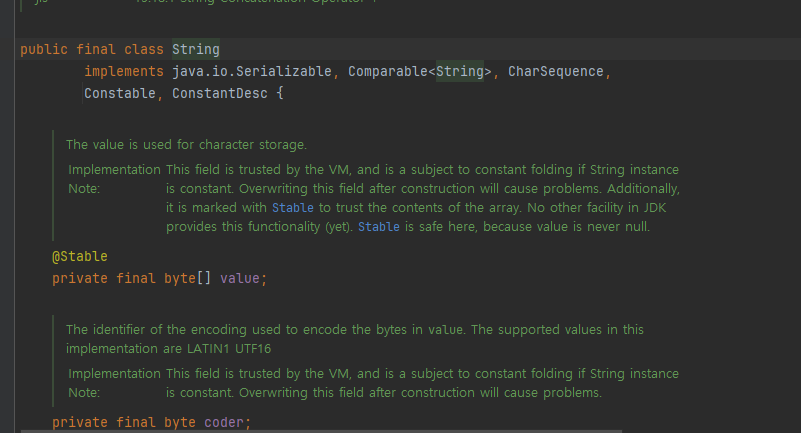
속성 필드
private final char[] value;
- 여기에는 String 의 실제 문자열 값이 보관된다. 문자 데이터 자체는 char[] 에 보관된다.
- String 클래스는 개발자가 직접 다루기 불편한 char[] 을 내부에 - 감추고 String 클래스를 사용하는 개발자가 편리하게 문자열을 다룰 수 있는 수 있도록 다양한 기능을 제공한다.
- 그리고 메서드 제공을 넘어서 자바 언어 차원에서도
여러 편의 문법을 제공한다.

- 자바 9 부턴 달라지는구나
- 메모리를 효율적으로 사용하기 위해 바이트 사용
- 항상 2바이트씩 썻던걸 영어만있으면 1바이트 한글 숫자 등있으면 2바이트씩.
속성
length() : 문자열의 길이를 반환한다.
charAt(int index) : 특정 인덱스의 문자를 반환한다.
substring(int beginIndex, int endIndex) : 문자열의 부분 문자열을 반환한다.
indexOf(String str) : 특정 문자열이 시작되는 인덱스를 반환한다.
toLowerCase() , toUpperCase() : 문자열을 소문자 또는 대문자로 변환한다.
trim() : 문자열 양 끝의 공백을 제거한다.
concat(String str) : 문자열을 더한다
- 다양한 기능들을 제공
- 스트링은 클래스라 속성과 기능을 제공한다
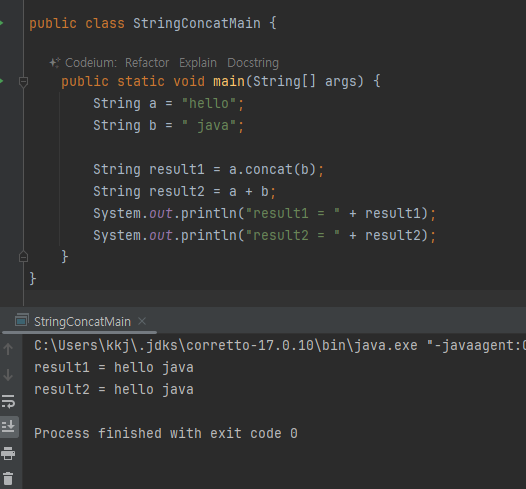
String 클래스와 참조형
- 조형은 변수에 계산할 수 있는 값이 들어있는 것이 아니라 x001 과 같이 계산할 수 없는 참조값이 들어있다. 따라서
원칙적으로 + 같은 연산을 사용할 수 없다.
-
요런식으로..
-
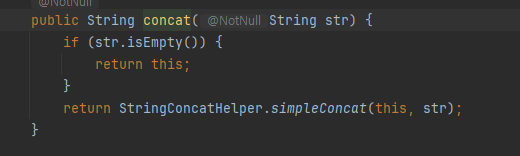
자바에서 문자열을 더할 때는 String 이 제공하는 concat() 과 같은 메서드를 사용해야 한다.
-
하지만 문자열은 너무 자주 다루어지기 때문에 자바 언어에서 편의상 특별히 + 연산을 제공한다.
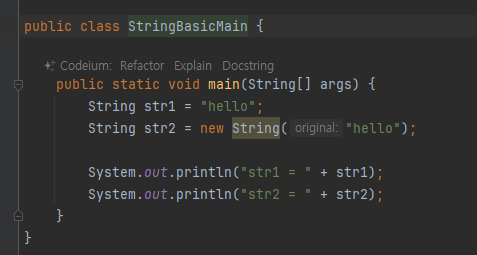
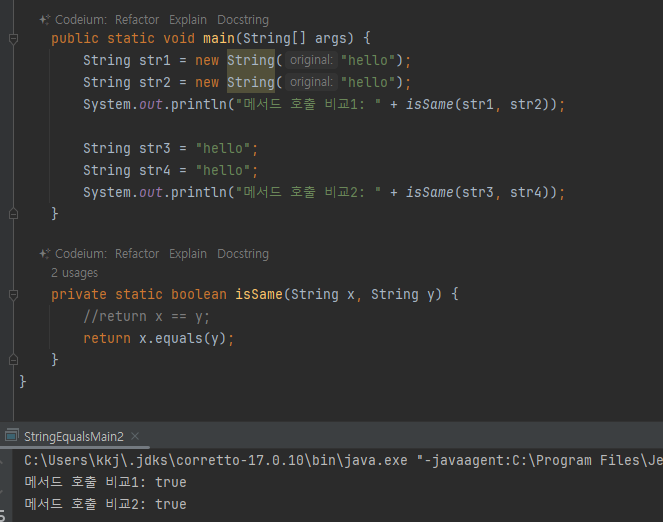
String 클래스 비교
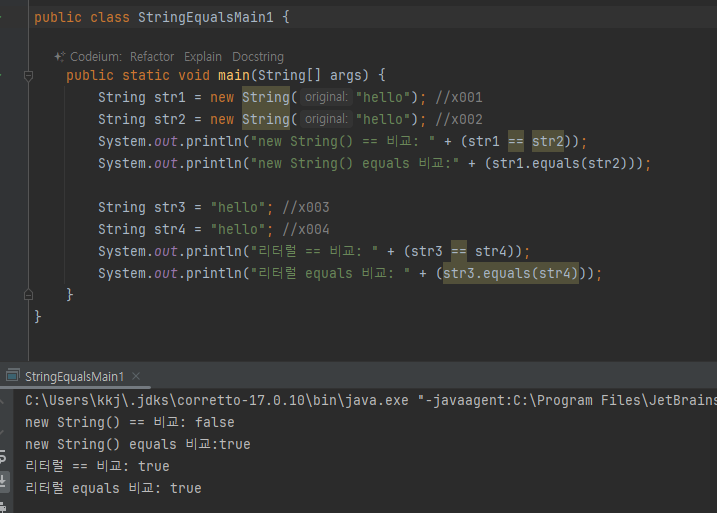
- String 클래스 비교할 때는 == 비교가 아니라 항상 equals() 비교
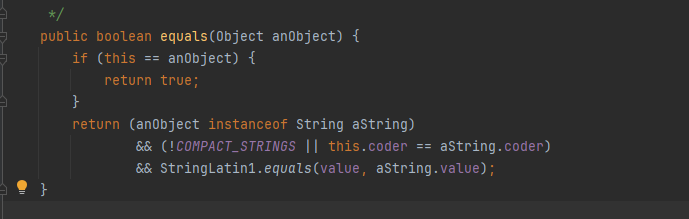
-
각각의 인스턴스를 비교해
-
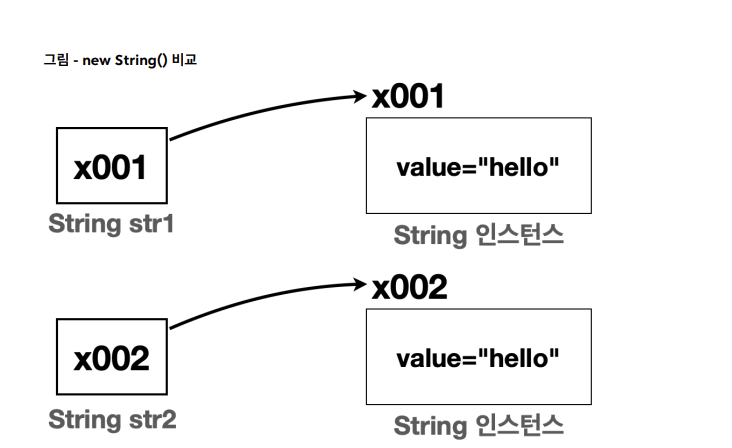
str1 과 str2 는 new String() 을 사용해서 각각 인스턴스를 생성했다. 서로 다른 인스턴스이므로 동일성
( == ) 비교에 실패한다. -
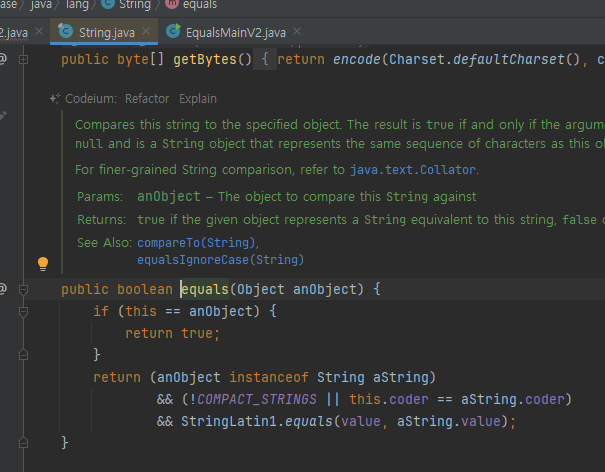
둘은 내부에 같은 "hello" 값을 가지고 있기 때문에 논리적으로 같다. 따라서 동등성( equals() ) 비교에 성
공한다. 참고로 String 클래스는 내부 문자열 값을 비교하도록 equals() 메서드를 재정의 해두었다.

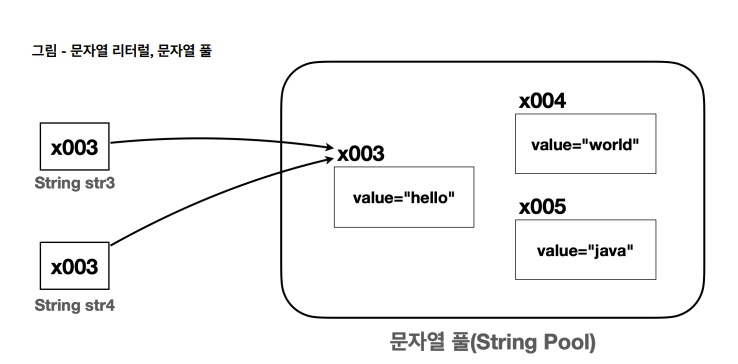
-
String str3 = "hello" 와 같이 문자열 리터럴을 사용하는 경우 자바는 메모리 효율성과 성능 최적화를 위해 문자열 풀을 사용한다
-
자바가 실행되는 시점에 클래스에 문자열 리터럴이 있으면 문자열 풀에 String 인스턴스를 미리 만들어둔다. 이때 같은 문자열이 있으면 만들지 않는다
-
String str3 = "hello" 와 같이 문자열 리터럴을 사용하면 문자열 풀에서 "hello" 라는 문자를 가진
String 인스턴스를 찾는다. 그리고 찾은 인스턴스의 참조( x003 )를 반환한다. -
String str4 = "hello" 의 경우 "hello" 문자열 리터럴을 사용하므로 문자열 풀에서 str3 과 같은x003 참조를 사용한다
-
문자열 풀 덕분에 같은 문자를 사용하는 경우 메모리 사용을 줄이고 문자를 만드는 시간도 줄어들기 때문에 성능도 최적화 할 수 있다
따라서 문자열 리터럴을 사용하는 경우 같은 참조값을 가지므로 == 비교에 성공한다.
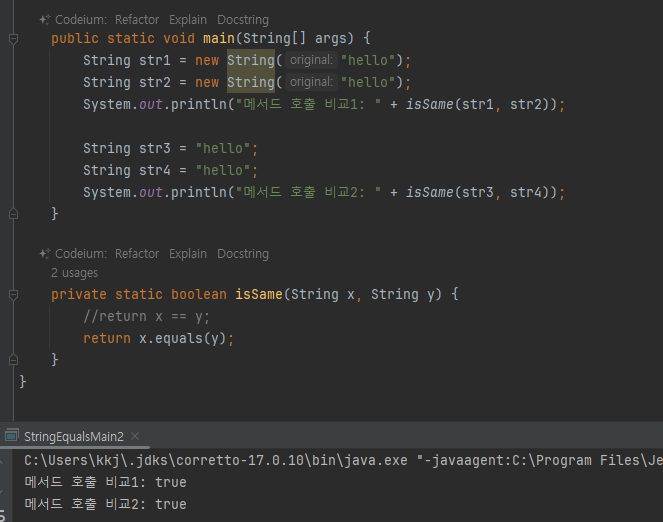
- 면 문자열 리터럴을 사용하면 == 비교를 하고, new String() 을 직접 사용하는 경우에만 equals() 비교 를 사용하면 되지 않을까?
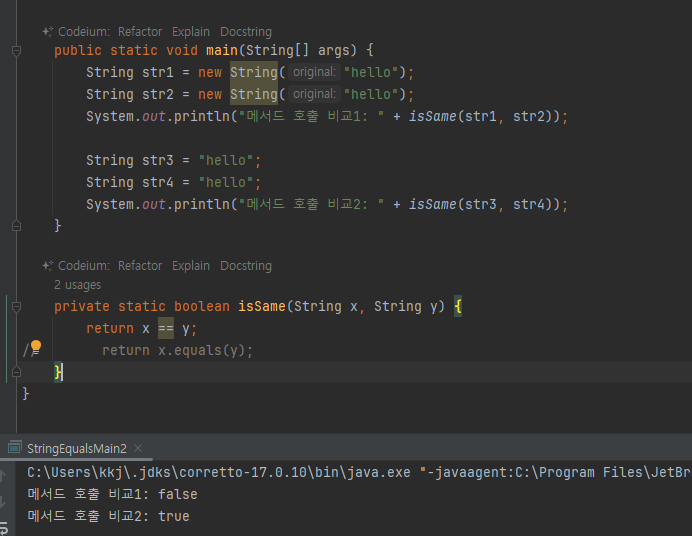
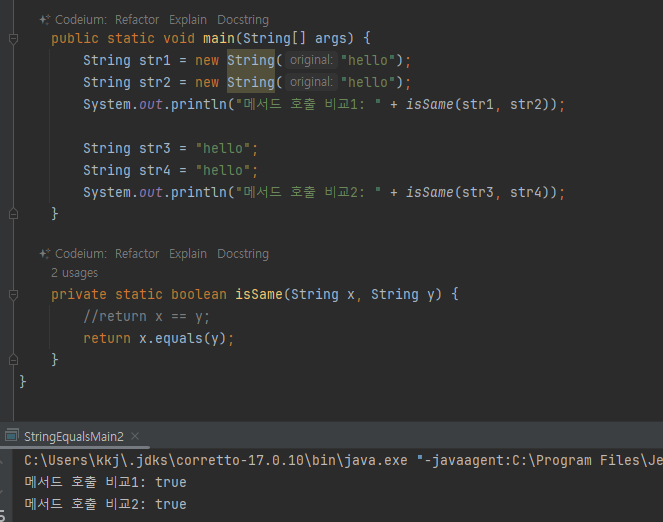
- main() 메서드를 만드는 개발자와 isSame() 메서드를 만드는 개발자가 서로 다르다고 가정해보자.
- isSame() 의 경우 매개변수로 넘어오는 String 인스턴스가 new String() 으로 만들어진 것인지, 문자열 리터
럴로 만들어 진 것인지 확인할 수 있는 방법이 없다
따라서 문자열 비교는 항상 equals() 를 사용해서 동등성 비교를 해야 한다.
String 클래스 불변 객체
- String 은 불변 객체이다. 따라서 생성 이후에 절대로 내부의 문자열 값을 변경할 수 없다.
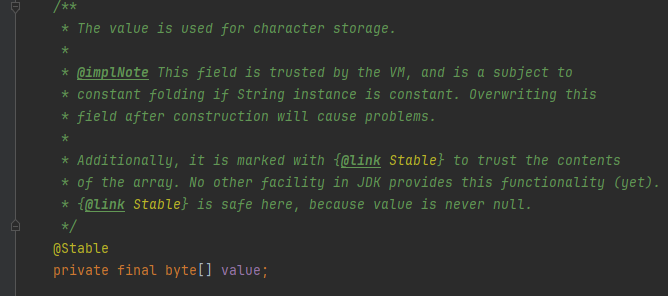
- final로 선언되있는 문자열
- 이런식으로 동작 신기신기
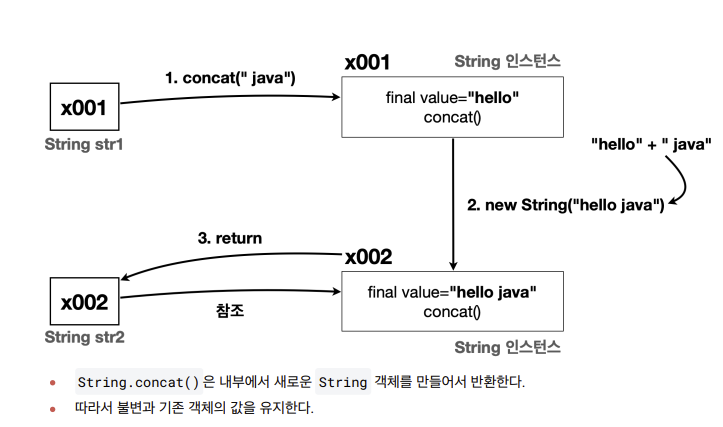
String이 불변으로 설계된 이유?
- 문자열 풀에 있는 String 인스턴스의 값이 중간에 변경되면 같은 문자열을 참고하는 다른 변수의 값도 함께 변경된다
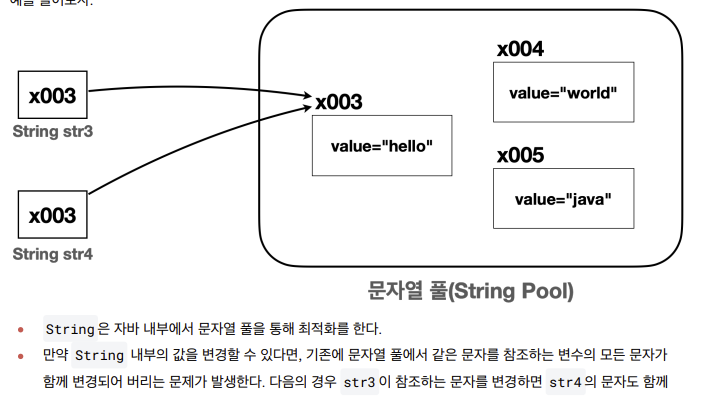

- 같은 문자열풀에있는 값이 변경되버리면 사이드이펙트가..
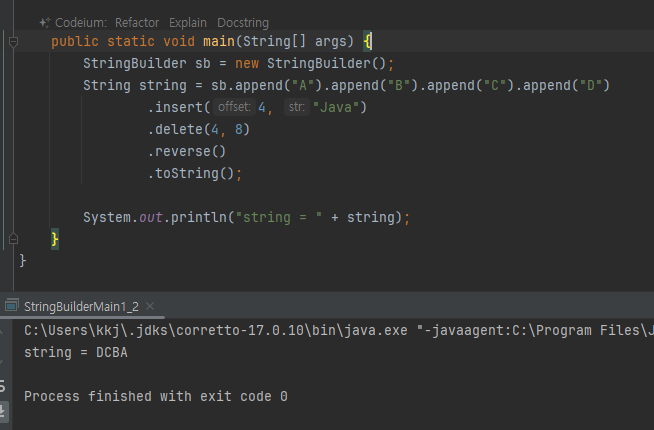
SpringBuilder - 가변 String
"A" + "B"
String("A") + String("B") //문자는 String 타입이다.
String("A").concat(String("B"))//문자의 더하기는 concat을 사용한다.
new String("AB") //String은 불변이다. 따라서 새로운 객체가 생성된다.
- 불변은 내부값 변경 X 변경된 값을 기반으로 새로운 String 객체 생성
String str = "A" + "B" + "C" + "D";
String str = String("A") + String("B") + String("C") + String("D");
String str = new String("AB") + String("C") + String("D");
String str = new String("ABC") + String("D");
String str = new String("ABCD");
- 이 경우 총 3개의 String 클래스가 추가로 생성된다.
- 그런데 문제는 중간에 만들어진 new String("AB") , new String("ABC") 는 사용되지 않는다.
- 최종적으로 만들어진 new String("ABCD") 만 사용된다.
- 결과적으로 중간에 만들어진 new String("AB") , new String("ABC") 는 제대로 사용되지도 않고, 이후 GC의 대상이 된다
불변인 String 클래스의 단점은 문자를 더하거나 변경할 때 마다 계속해서 새로운 객체를 생성해야 한다는 점이다.
문자를 자주 더하거나 변경해야 하는 상황이라면 더 많은 String 객체를 만들고, GC해야 한다. 결과적으로 컴퓨터의
CPU, 메모리를 자원을 더 많이 사용하게 된다. 그리고 문자열의 크기가 클수록, 문자열을 더 자주 변경할수록 시스템의
자원을 더 많이 소모한다
- 참고로 실제로는 문자열 다룰때 자바가 내부에서 최적화함
StringBuilder
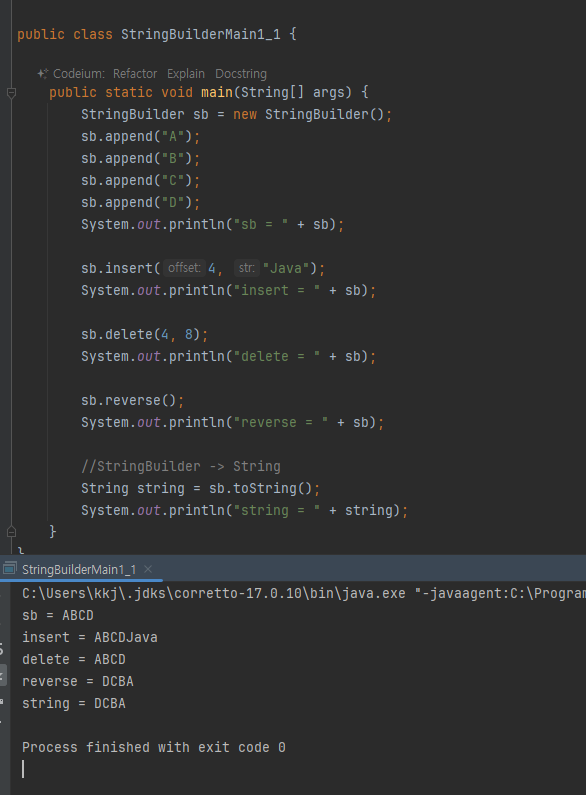
- 가변으로 변하는 문자열 예제
- 에, StringBuilder 는 가변적이다. 하나의 StringBuilder 객체 안에서 문자열을 추가, 삭제, 수정할수 있으며, 이때마다 새로운 객체를 생성하지 않는다. 이로 인해 메모리 사용을 줄이고 성능을 향상시킬 수 있다.
- 허나 사이드 이펙트 주의
String 최적화

- 자바는 컴파일시 리터럴를 합쳐버림
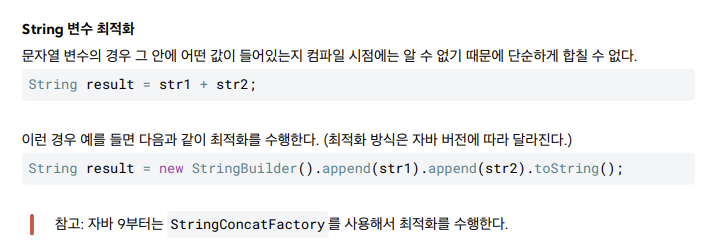
- 변수의 경우 컴파일 시점에서 알수 없기때문에
- 단순하게 못합침?
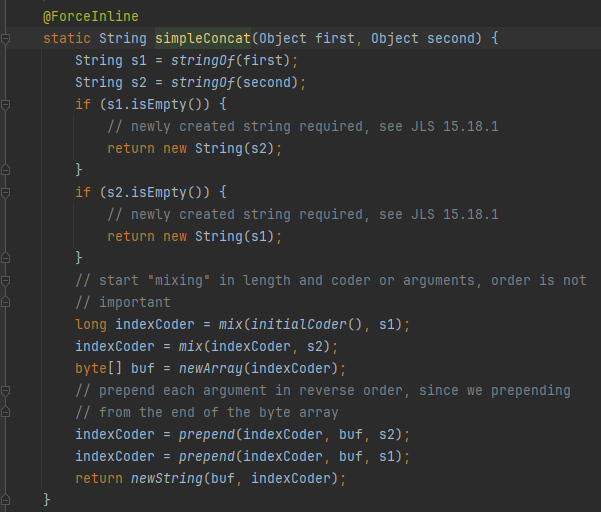
- StringConcatFactory는 좀 처음듣는 개념
- 간단한경우 StringBuilder 최적화 이렇게 해주기때문에
- 단순히 문자열 연산해도됨
String 최적화가 어려운 경우
- 다음과 같이 문자열을 루프안에서 문자열을 더하는 경우에는 최적화가 이루어지지 않는다.
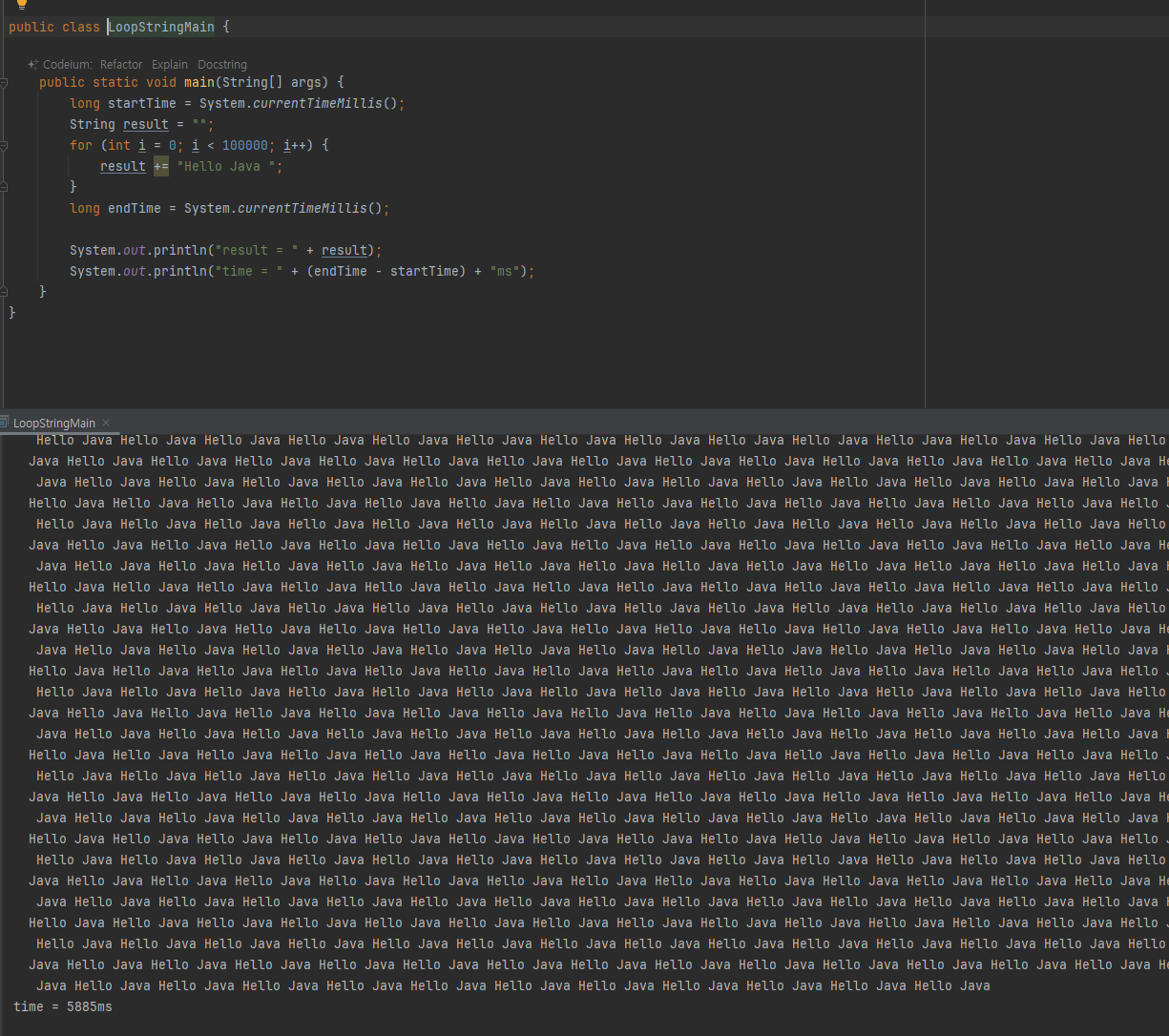
- 5초나 걸리네
String result = "";
for (int i = 0; i < 100000; i++) {
result = new StringBuilder().append(result).append("Hello Java
").toString()
}
- 반복문의 루프 내부에서는 최적화가 되는 것 처럼 보이지만, 반복 횟수만큼 객체를 생성해야 한다.
반복문 내에서의 문자열 연결은, 런타임에 연결할 문자열의 개수와 내용이 결정된다. - 이런 경우, 컴파일러는 얼마나 많
은 반복이 일어날지, 각 반복에서 문자열이 어떻게 변할지 예측할 수 없다. 따라서, 이런 상황에서는 최적화가 어렵다.
- 반복문에서는 어찌 할 수 없어서.. 이런결과가..
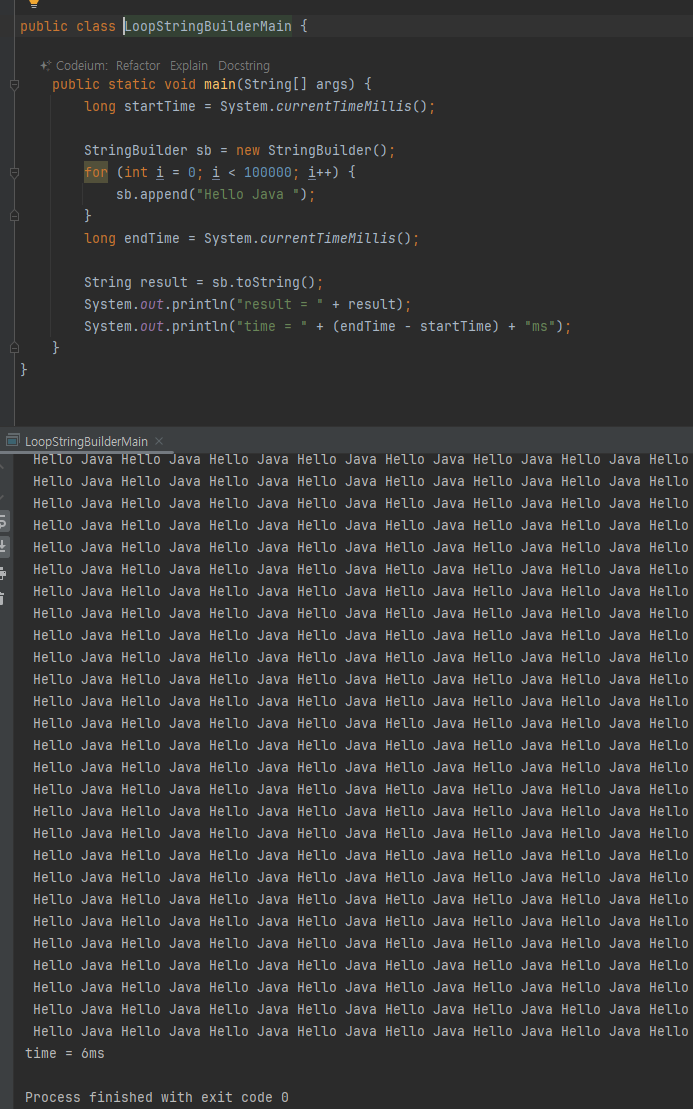
- 빌더로 바꾸니 이렇게 간단히 성능향상
정리
- 문자열을 합칠 때 대부분의 경우 최적화가 되므로 + 연산을 사용하면 된다.
- StringBuilder를 직접 사용하는 것이 더 좋은 경우
- 반복문에서 반복해서 문자를 연결할 때
- 조건문을 통해 동적으로 문자열을 조합할 때
- 복잡한 문자열의 특정 부분을 변경해야 할 때
- 매우 긴 대용량 문자열을 다룰 때

- 버퍼는 거의 쓰지 않는다.
메서드 체이닝
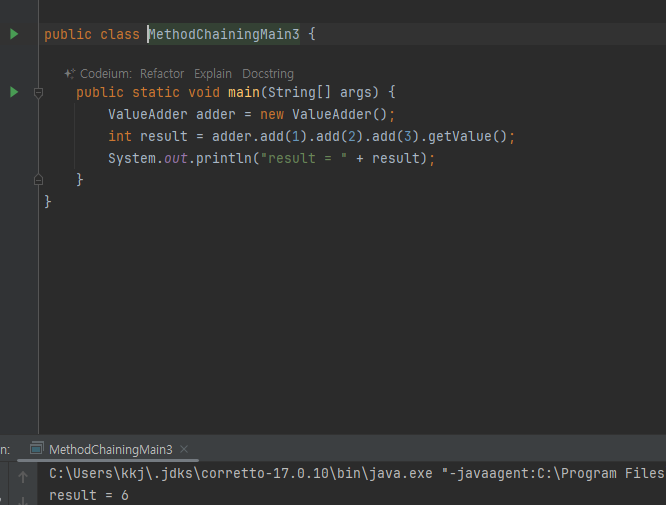
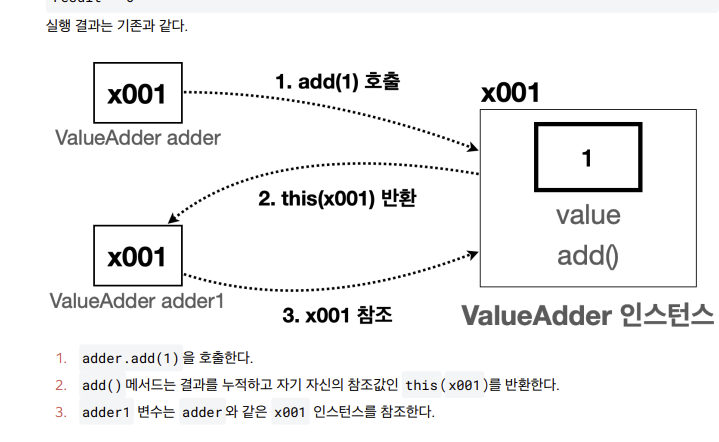
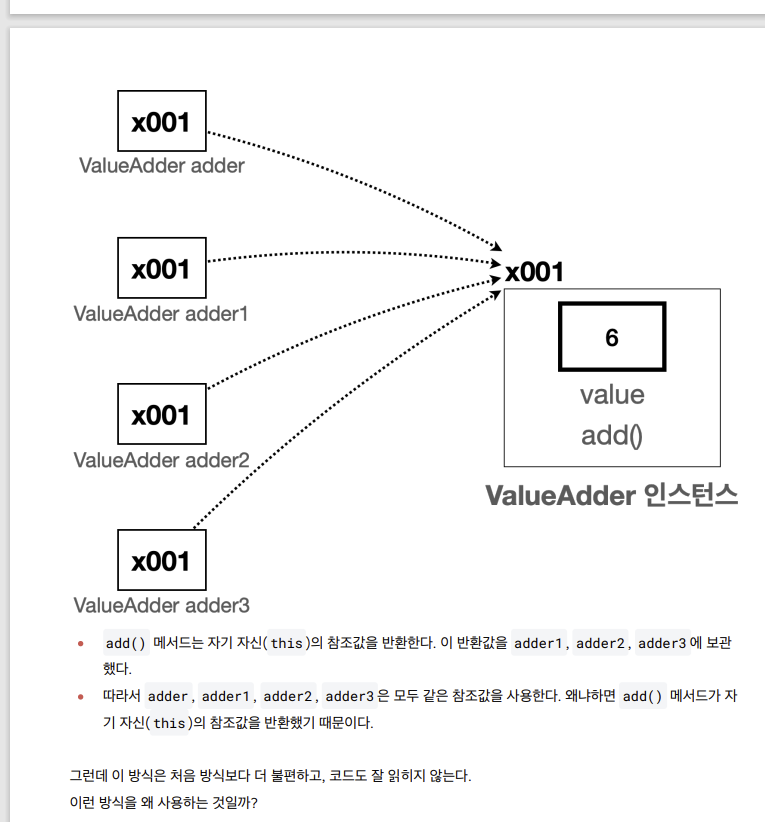
-
그냥 메서드 더하는건대...
-
코드가 잘 읽히지 않아서 불편함
-
메서드 호출의 결과로 자기 자신의 참조값을 반환하면, 반환된 참조값을 사용해서 메서드 호출을 계속 이어갈 수 있다.
-
코드를 보면 . 을 찍고 메서드를 계속 연결해서 사용한다. 마치 메서드가 체인으로 연결된 것 처럼 보인다.
-
이러한 기법을 메서드 체이닝이라 한다
StringBuilder와 메서드 체인(Chain)
public StringBuilder append(String str) {
super.append(str);
return this;
}
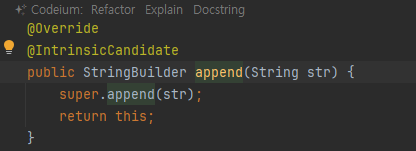
- 이런식으로 활용?
- 만드는 사람이 수고로우면 쓰는 사람이 편하고, 만드는 사람이 편하면 쓰는 사람이 수고롭다"는 말이 있다.
- 메서드 체이닝은 구현하는 입장에서는 번거롭지만 사용하는 개발자는 편리해진다.
- 참고로 자바의 라이브러리와 오픈 소스들은 메서드 체이닝 방식을 종종 사용한다
래퍼 클래스 - 기본형의 한계

- 기본형의 대한 설명들, 당연한 말들
- 객체지향 프로그래밍의 장점을 살릴 수 없다?
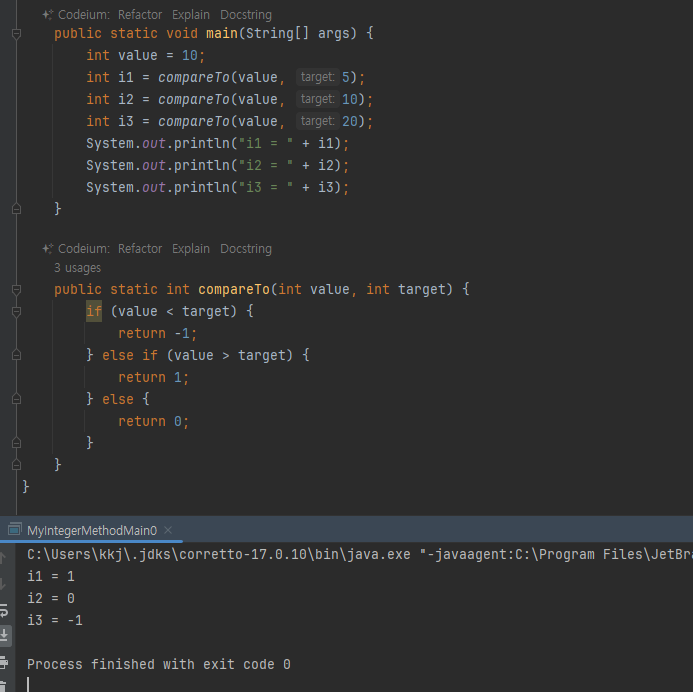
-
여기서는 value 와 비교 대상 값을 compareTo() 라는 외부 메서드를 사용해서 비교한다.
-
그런데 자기 자신인value 와 다른 값을 연산하는 것이기 때문에 항상 자기 자신의 값인 value 가 사용된다.
-
이런 경우 만약 value가 체라면 value 객체 스스로 자기 자신의 값과 다른 값을 비교하는 메서드를 만드는 것이 더 유용할 것이다.
직접만든 래퍼 클래스
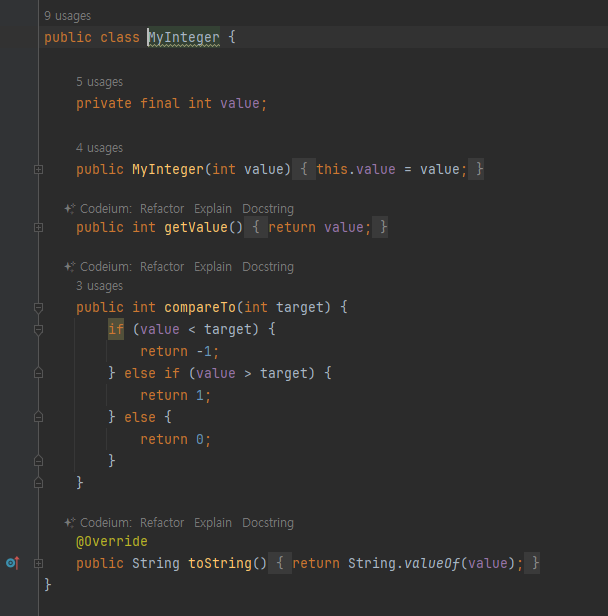
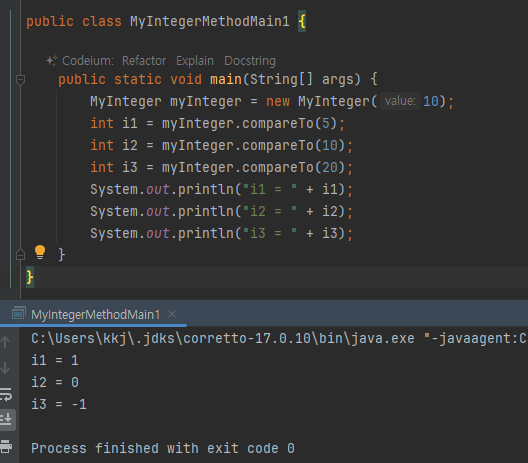
-
객체로 만들어서하면 객체지향적으로 코드가 짜지네
-
MyInteger 클래스는 단순한 데이터 조각인 int 를 내부에 품고, 메서드를 통해 다양한 기능을 추가했다. 덕분에 데이터 조각에 불과한 int 를 MyInteger 를 통해 객체로 다룰 수 있게 되었다.
-
기본형은 내부 함수를 가질수없다 이장에 가장 중요한 내용?
-
그러므로 객체지향적일수 없다.
래퍼클래스 - 기본형의 한계
- 기본형은 항상 값을 가져야됨 하지만 때로는 데이터가 없음을 상태가 필요할수 있다.
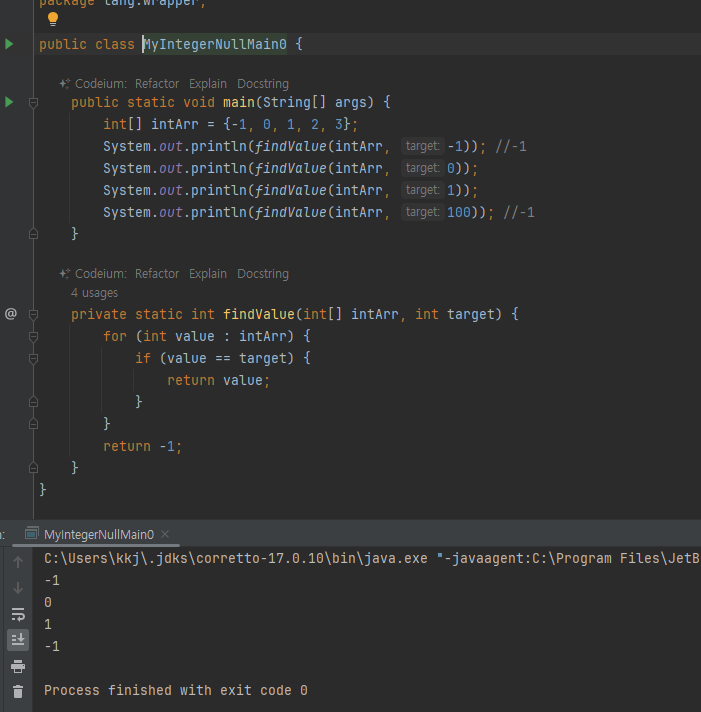
-
findValue() 는 배열에 찾는 값이 있으면 해당 값을 반환하고, 찾는 값이 없으면 -1 을 반환한
-
findValue() 는 결과로 int 를 반환한다. int 와 같은 기본형은 항상 값이 있어야 한다.
-
여기서도 값을 반환할 때 값을 찾지 못하면 숫자 중에 하나를 반환해야 하는데 보통 -1 또는 0 을 사용한다
- 실행 결과를 보면 입력값이 -1 일 때 -1 을 반환한다. 그런데 배열에 없는 값인 100 을 입력해도 같은 -1 을 반환한다.
- 입력값이 -1 일 때를 생각해보면, 배열에 -1 값이 있어서 -1 을 반환한 것인지, 아니면 -1 값이 없어서 -1 을 반환한 것인지 명확하지 않다
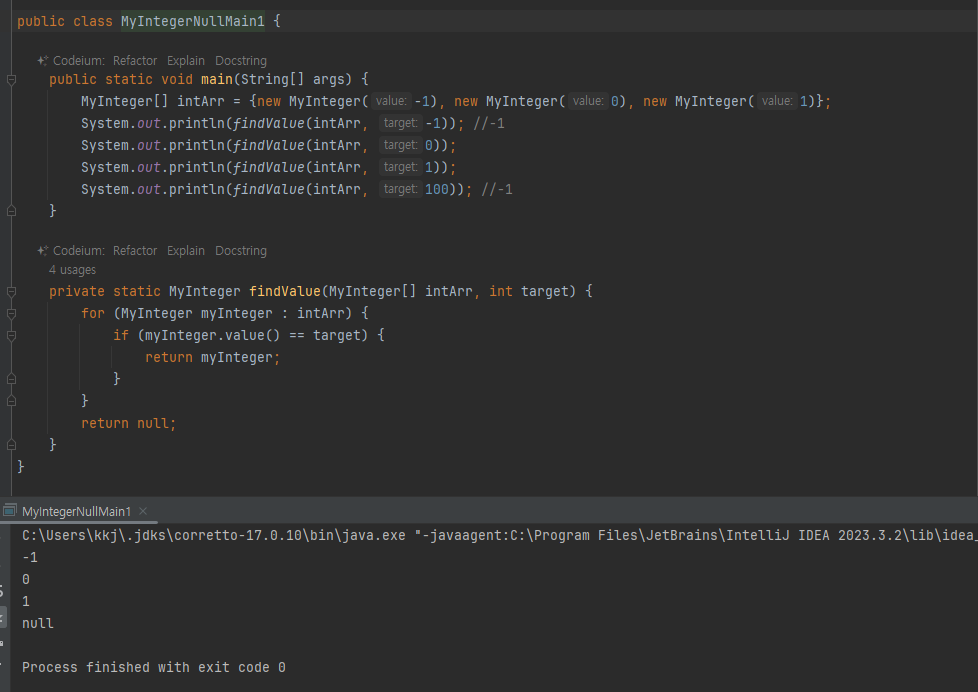
-
100 을 입력했을 때는 값이 없다는 null 을 반환한다.
-
기본형은 항상 값이 존재해야 한다. 숫자의 경우 0 , -1 같은 값이라도 항상 존재해야 한다. 반면에 객체인 참조형은 값이 없다는 null 을 사용할 수 있다
-
다. 물론 null 값을 반환하는 경우 잘못하면 NullPointerException 이 발생할
수 있기 때문에 주의해서 사용해야 한다 -
실제로 첫번째함수 리턴을 null로하면 컴파일 에러 발생
-
기본형은 기본적으로 값이 항상 존재해야되기때문에 null을 넣을수 없어서
래퍼클래스 - 자바 래퍼클래스

- 기본 래퍼클래스들의 특징
- 불변
- equals로 비교해야 함
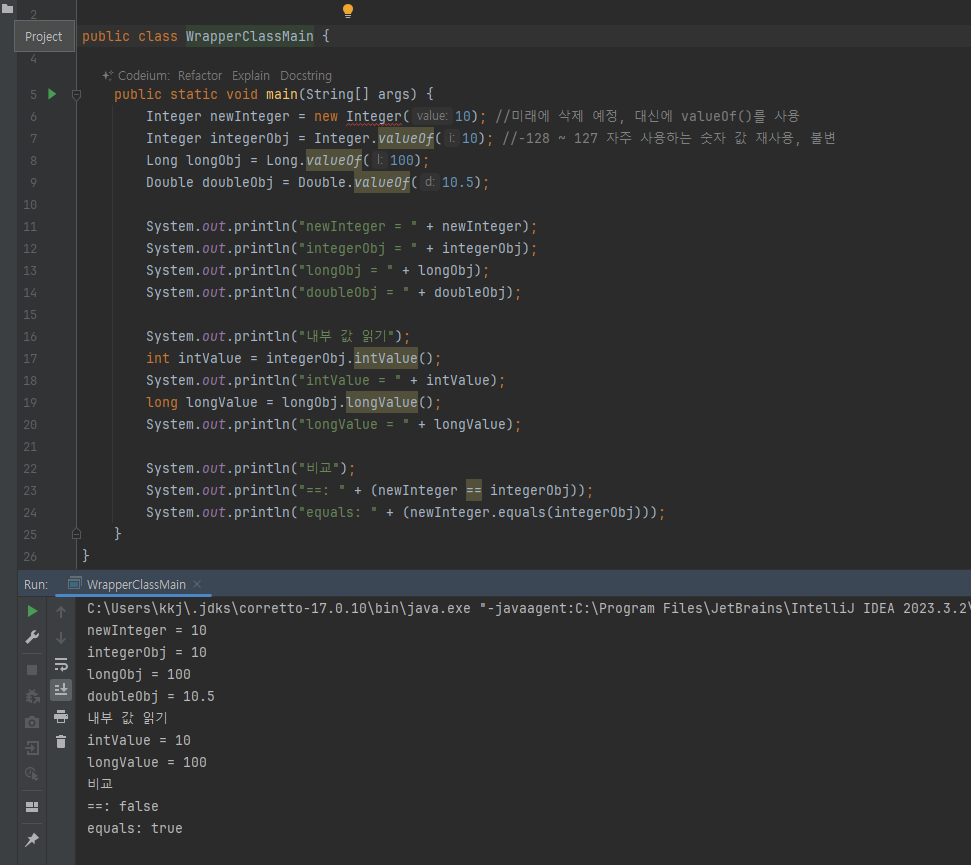

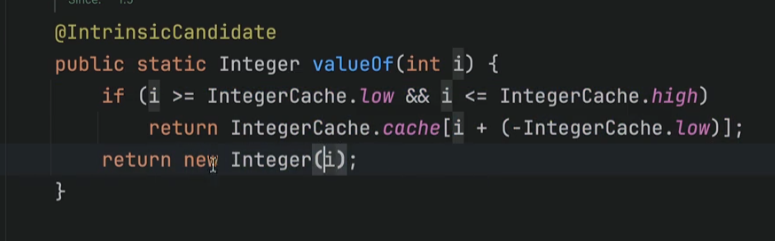
- valueOf를 써라
- -128 ~ 127 문자열 풀 처럼 미리 만들어 놓은값을 사용한다.
- 자바가 뭐 성능최적화를 해줄께 이런의미로 받아들이면될듯
래퍼 클래스 생성 - 박싱
-
기본형을 래퍼 클래스로 변경하는 것을 마치 박스에 물건을 넣은 것 같다고 해서 박싱(Boxing)이라 한다.
-
new Integer 대신 valueOf를 사요여하자 내부에서 객체 생성하고 돌려 줌
-
성능 최적화 기능도 있음 -128~127 범위 Integer클래스 미리 생성해 줌
-
해당 범위 값 조회하면 미리 생성된
Integer객체를 반환함 해당 범위 값이 없으면 New IOnteger() 호출 -
문자열 풀과 비스하게 자주사용하는 숫자를 미리 생성 재사용
-
참고로 이런 최적화 방식은 미래에 더나은 방식으로 바뀔 수 있음
-
intValue() - 언박싱(Unboxing)
-
래퍼 클래스에 들어있는 기본형
-
박스에 들어있는 물건을 꺼내는 거 같다고 해서 언방식 이라 함
-
비교는 equals() 사용
-
래퍼 클래스는 객체이기 때문에 == 비교를 하면 인스턴스의 참조값을 비교한다.
-
래퍼 클래스는 내부의 값을 비교하도록 equals() 를 재정의 해두었다. 따라서 값을 비교하려면 equals() 를 사용해야 한다
래퍼 클래스 - 오토박싱
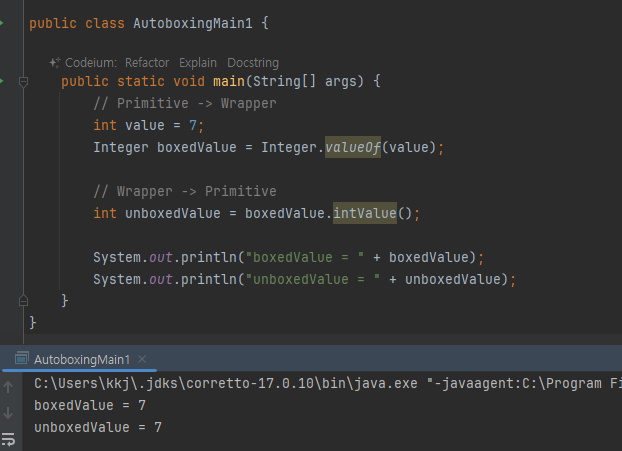
- 박싱: valueOf
- 언박싱 : : xxxValue() (예: intValue() , doubleValue() )
개발자들이 오랜기간 개발을 하다 보니 기본형을 래퍼 클래스로 변환하거나 또는 래퍼 클래스를 기본형으로 변환하는일이 자주 발생했다.
그래서 많은 개발자들이 불편함을 호소했다.
자바는 이런 문제를 해결하기 위해 자바 1.5부터 오토 박싱(Auto-boxing), 오토 언박싱(Auto-Unboxing)을 지원한다
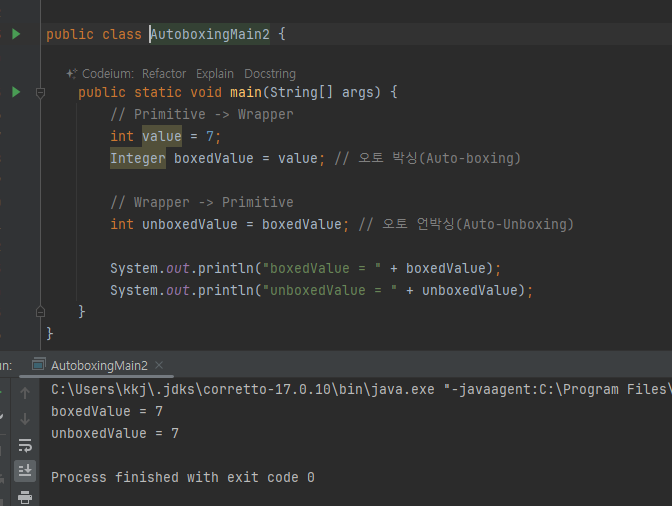
- 오토 박싱과 오토 언박싱은 컴파일러가 개발자 대신 valueOf , xxxValue() 등의 코드를 추가해주는 기능이다.
- 덕분에 기본형과 래퍼형을 서로 편리하게 변환할 수 있다
래퍼클래스 주요 메서드
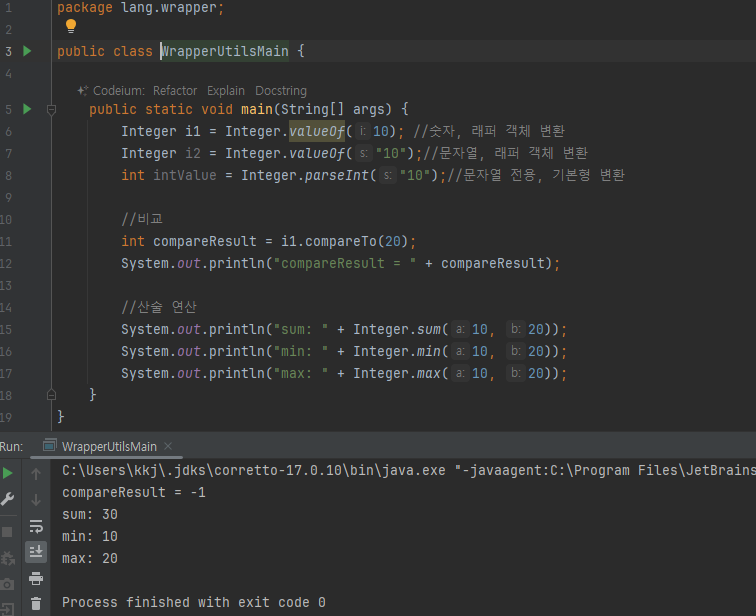
- valueOf() : 래퍼 타입을 반환한다. 숫자, 문자열을 모두 지원한다.
- parseInt() : 문자열을 기본형으로 변환한다.
- compareTo() : 내 값과 인수로 넘어온 값을 비교한다. 내 값이 크면 1 , 같으면 0 , 내 값이 작으면 -1 을 반환한다.
- Integer.sum() , Integer.min() , Integer.max() : static 메서드이다. 간단한 덧셈, 작은 값, 큰 값 연산을 수행한다
parseInt() vs valueOf()
- 원하는 타입에 맞는 메서드를 사용하면 된다.
- valueOf("10") 는 래퍼 타입을 반환한다.
- parseInt("10") 는 기본형을 반환한다.
- Long.parseLong() 처럼 각 타입에 parseXxx() 가 존재한다.
래퍼 클래스와 성능
- 래퍼 클래스는 객체이기 때문에 기본형보다 다양한 기능을 제공한다.
- 그렇다면 더 좋은 래퍼 클래스만 제공하면 되지 기본형을 제공하는 이유는 무엇일까?
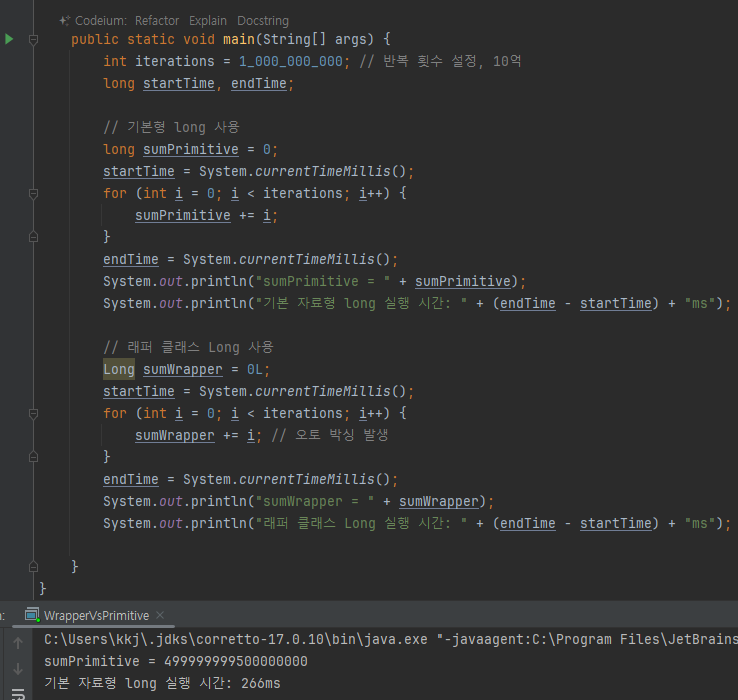
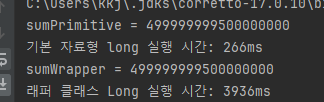
-
기본형 연산이 래퍼 클래스보다 대략 5배 정도 빠른 것을 확인할 수 있다. 참고로 계산 결과는 시스템 마다 다르다
-
기본형은 메모리에서 단순히 그 크기만큼의 공간을 차지한다. 예를 들어 int 는 보통 4바이트의 메모리를 사용한다.
-
래퍼 클래스의 인스턴스는 내부에 필드로 가지고 있는 기본형의 값 뿐만 아니라 자바에서 객체 자체를 다루는데필요한 객체 메타데이터를 포함하므로 더 많은 메모리를 사용한다.
-
자바 버전과 시스템마다 다르지만 대략 8~16바이트의 메모리를 추가로 사용한다
기본형, 래퍼 클래스 어떤 것을 사용?
-
이 연산은 10억 번의 연산을 수행했을 때 0.3초와, 1.5초의 차이다.
-
기본형이든 래퍼 클래스든 이것을 1회로 환산하면 둘다 매우 빠르게 연산이 수행된다
-
0.3초 나누기 10억, 1.5초 나누기 10억이다
-
일반적인 애플리케이션을 만드는 관점에서 보면 이런 부분을 최적화해도 사막의 모래알 하나 정도의 차이가 날 뿐임
-
CPU 연산을 아주 많이 수행하는 특수한 경우이거나, 수만~ 수십만 이상 연속해서 연산을 수행해야 하는 경우라면 기본형을 사용해서 최적화를 고려하자.
-
그렇지 않은 일반적인 경우라면 코드를 유지보수하기 더 나은 것을 선택하면 된다.
유지보수 vs 최적화
-
유지보수 vs 최적화를 고려해야 하는 상황이라면 유지보수하기 좋은 코드를 먼저 고민해야 한다. 특히 최신 컴퓨터는 매우 빠르기 때문에 메모리 상에서 발생하는 연산을 몇 번 줄인다고해도 실질적인 도움이 되지 않는 경우가 많다.
-
코드 변경 없이 성능 최적화를 하면 가장 좋겠지만, 성능 최적화는 대부분 단순함 보다는 복잡함을 요구하고, 더많은 코드들을 추가로 만들어야 한다. 최적화를 위해 유지보수 해야 하는 코드가 더 늘어나는 것이다.
-
그런데 진짜문제는 최적화를 한다고 했지만 전체 애플리케이션의 성능 관점에서 보면 불필요한 최적화를 할 가능성이 있다.
-
특히 웹 애플리케이션의 경우 메모리 안에서 발생하는 연산 하나보다 네트워크 호출 한 번이 많게는 수십만배 더오래 걸린다.
-
자바 메모리 내부에서 발생하는 연산을 수천번에서 한 번으로 줄이는 것 보다,
네트워크 호출 한 번을 더 줄이는 것이 더 효과적인 경우가 많다. -
권장하는 방법은 개발 이후에 성능 테스트를 해보고 정말 문제가 되는 부분을 찾아서 최적화 하는 것이다
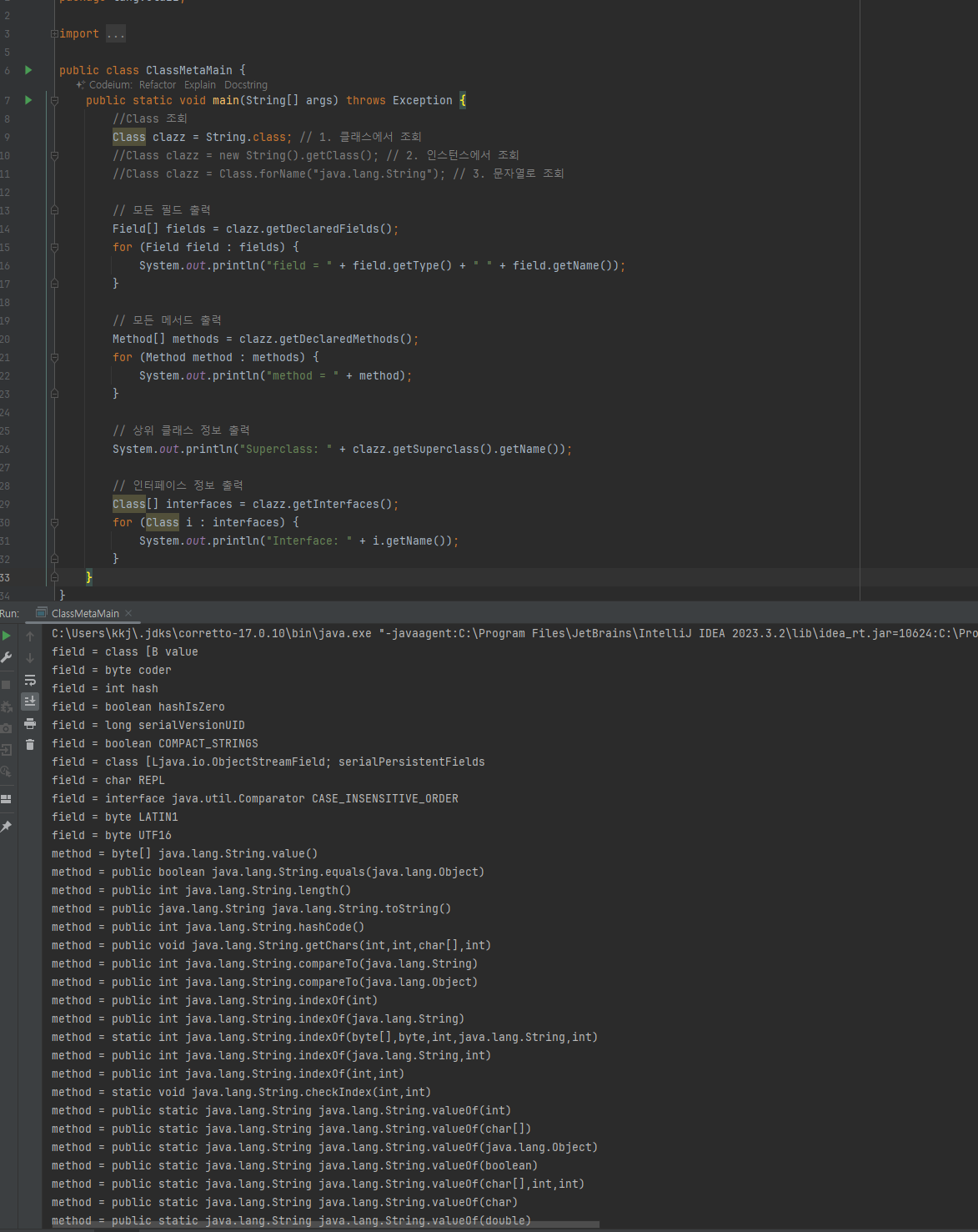
Class 클래스
- 자바에서 Class 클래스는 클래스의 정보(메타데이터)를 다루는데 사용된다. Class 클래스를 통해 개발자는 실행중인 자바 애플리케이션 내에서 필요한 클래스의 속성과 메서드에 대한 정보를 조회하고 조작할 수 있다.
주요 기능
- 타입 정보 얻기: 클래스 이름 슈퍼클래스 , 인터페이스 접근 제한자 등 정보 조회
- 리플렉션: 클래스에 정의된 메소드 필드 생성자 등을 조회하고 이를 통해 객체 인스턴스를 생성하거나 메소드를 호출하느 ㄴ등작업 가능함
- 동적 로딩과 생성: Class.forName() 메서드를 사용하여 클래스를 동적으로 로드하고 newInstance() 메서드를 통해 새로운 인스턴스 생성가능
- 애노테이션처리: 클래스에 적용된 애노테이션 조회하고 처리하는 기능 제공
-
class vs clazz - class는 자바의 예약어다. 따라서 패키지명, 변수명으로 사용할 수 없다.
-
발자들은 class 대신 clazz 라는 이름을 관행으로 사용한다. clazz 는 class 와 유사하게 들리고, 이 단어가 class 를 의미한다는 것을 쉽게 알 수 있다
- Class 클래스는 다음과 같이 3가지 방법으로 조회할 수 있다.
Class clazz = String.class; // 1.클래스에서 조회
Class clazz = new String().getClass();// 2.인스턴스에서 조회
Class clazz = Class.forName("java.lang.String"); // 3.문자열로 조회

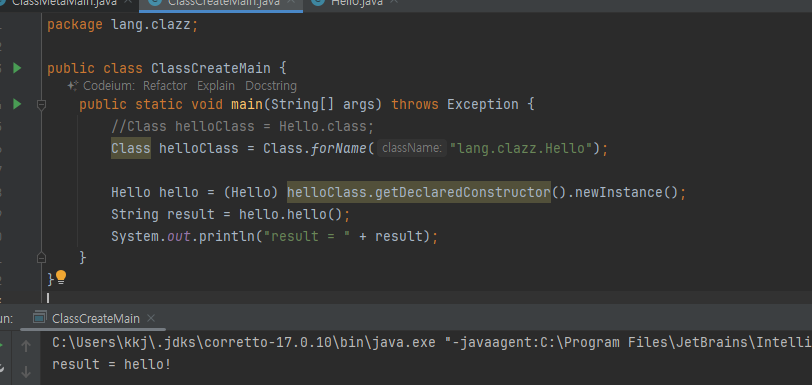
리플렉션 - reflection
- Class 를 사용하면 클래스의 메타 정보를 기반으로 클래스에 정의된 메서드, 필드, 생성자 등을 조회하고, 이들을 통해객체 인스턴스를 생성하거나 메서드를 호출하는 작업을 할 수 있다.
- 이런 작업을 리플렉션이라 한다. 추가로 애노테이션정보를 읽어서 특별한 기능을 수행할 수 도 있다.
- 최신 프레임워크들은 이런 기능을 적극 활용한다.지금은 Class 가 뭔지, 그리고 대략 어떤 기능들을 제공하는지만 알아두면 충분하다.
- 지금은 리플렉션을 학습하는 것보다 훨씬 더 중요한 기본기들을 학습해야 한다. 리플렉션은 이후에 별도로 다룬다
System Class
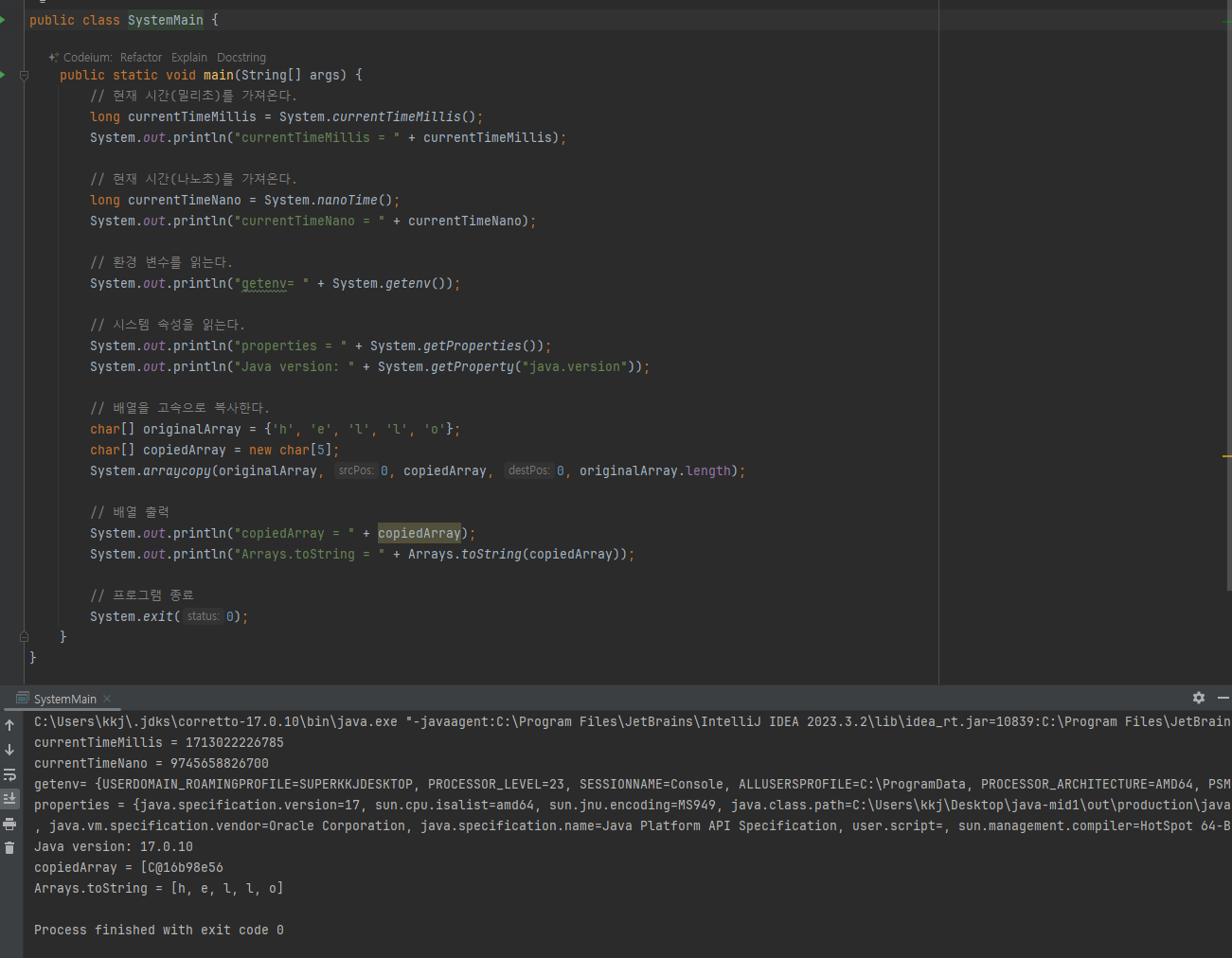

- 배열 고속복사 언젠가는 사용하겠지.?
Math, Random 클래스
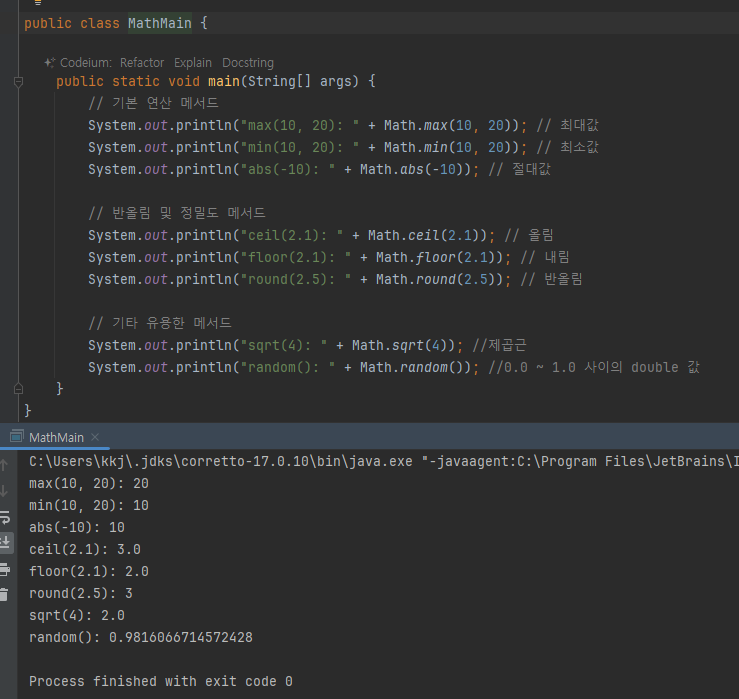
- 이런게 있다 알아두는 정도
- 참고: 아주 정밀한 숫자와 반올림 계산이 필요하다면 BigDecimal 을 검색해보자.
Random 클래스
- 랜덤의 경우 Math.random() 을 사용해도 되지만 Random 클래스를 사용하면 더욱 다양한 랜덤값을 구할 수 있다.
참고로 Math.random() 도 내부에서는 Random 클래스를 사용한다
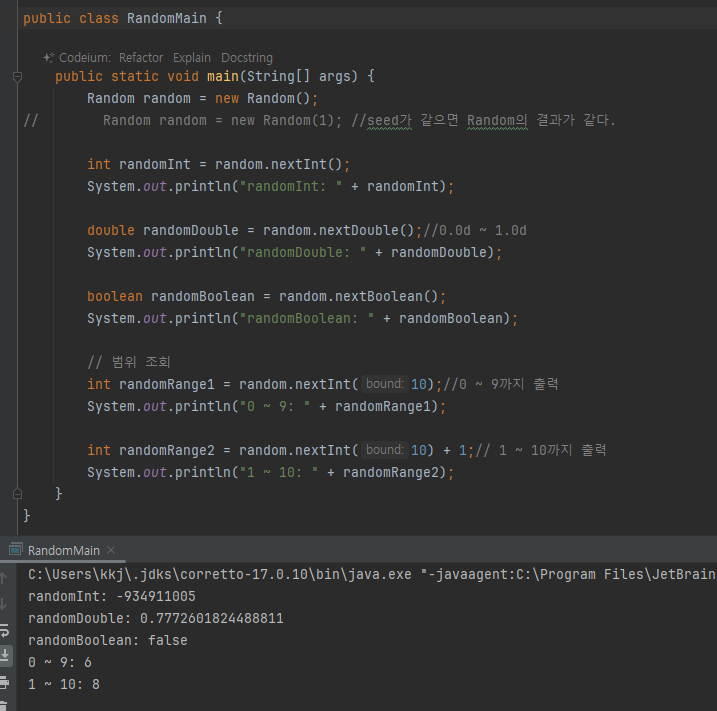
- random.nextInt() : 랜덤 int 값을 반환한다.
- nextDouble() : 0.0d ~ 1.0d 사이의 랜덤 double 값을 반환한다.
- nextBoolean() : 랜덤 boolean 값을 반환한다.
- nextInt(int bound) : 0 ~ bound 미만의 숫자를 랜덤으로 반환한다. 예를 들어서 3을 입력하면 0, 1, 2 를 반환한다.
씨드 - Seed
- 랜덤은 내부에서 씨드(Seed)값을 사용해서 랜덤 값을 구한다. 그런데 이 씨드 값이 같으면 항상 같은 결과가 출력된다.
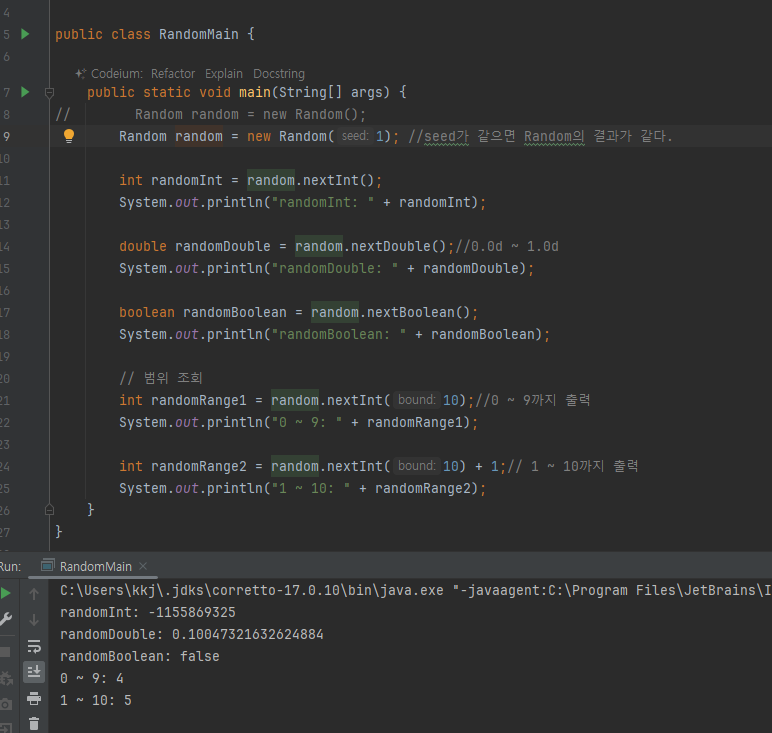
- Seed 가 같으면 실행 결과는 반복 실행해도 같다.
- 반복 실행해도 같은 값
-
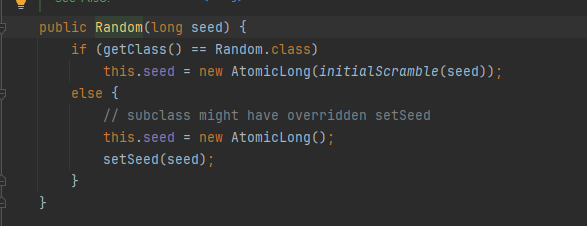
new Random() : 생성자를 비워두면 내부에서 System.nanoTime() 에 여러가지 복잡한 알고리즘을 섞어서
씨드값을 생성한다. 따라서 반복 실행해도 결과가 항상 달라진다. -
new Random(int seed) : 생성자에 씨드 값을 직접 전달할 수 있다. 씨드 값이 같으면 여러번 반복 실행해도실행 결과가 같다.
-
이렇게 씨드 값을 직접 사용하면 결과 값이 항상 같기 때문에 결과가 달라지는 랜덤 값을 구할수 없다. 하지만 결과가 고정되기 때문에 테스트 코드 같은 곳에서 같은 결과를 검증할 수 있다.
-
참고로 마인크래프트 같은 게임은 게임을 시작할 때 지형을 랜덤으로 생성하는데, 같은 씨드값을 설정하면 같은 지형을 생성할 수있다
열거형 ENUM
- 열거형이 생겨난 이유 ?

- 단순히 문자열을 입력하는 방식은, 오타가 발생하기 쉽고, 유효하지 않는 값이 입력될 수 있다.
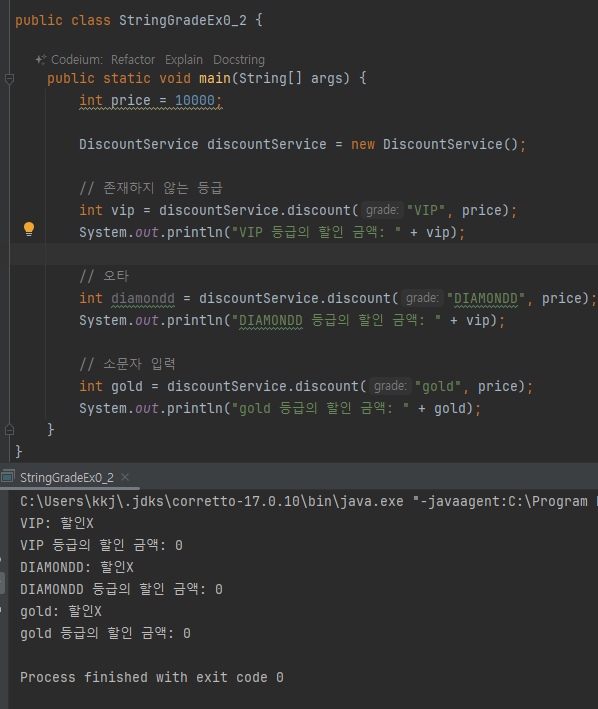
-
이런식의 오타가 일어날수 있음
-
타입 안정성 부족: 문자열은 오타가 발생하기 쉽고, 유효하지 않은 값이 입력될 수 있다
-
데이터 일관성: "GOLD", "gold", "Gold" 등 다양한 형식으로 문자열을 입력할 수 있어 일관성이 떨어진다
-
안정성과 일관성이 떨어짐
String 사용 시 타입 안정성 부족 문제
- 값의 제한 부족: String 으로 상태나 카테고리를 표현하면, 잘못된 문자열을 실수로 입력할 가능성이 있다. 예를들어, "Monday", "Tuesday" 등을 나타내는 데 String 을 사용한다면, 오타("Munday")나 잘못된 값("Funday")이 입력될 위험이 있다.
- 컴파일 시 오류 감지 불가: 이러한 잘못된 값은 컴파일 시에는 감지되지 않고, 런타임에서만 문제가 발견되기 때문에 디버깅이 어려워질 수 있다
문자열과 타입 안전성2
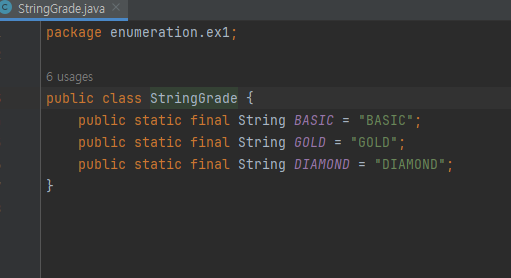
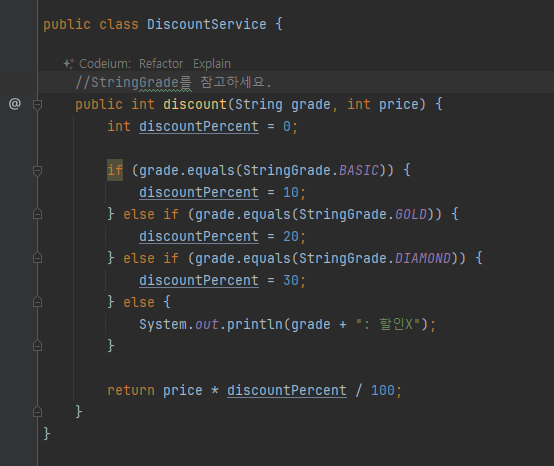
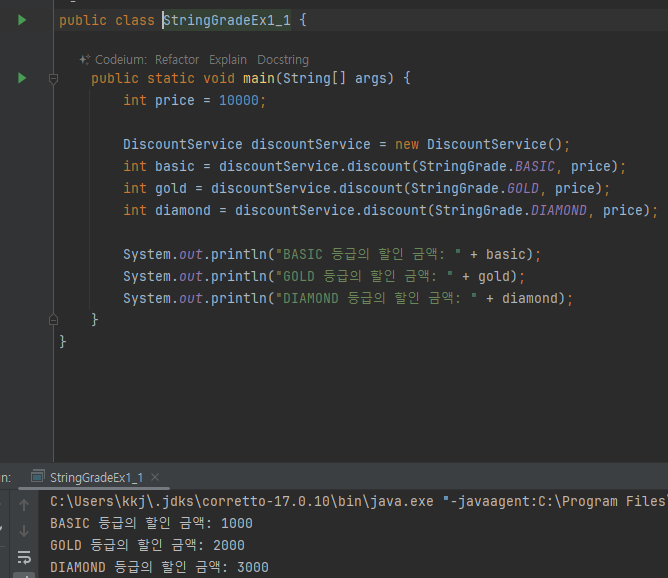
-
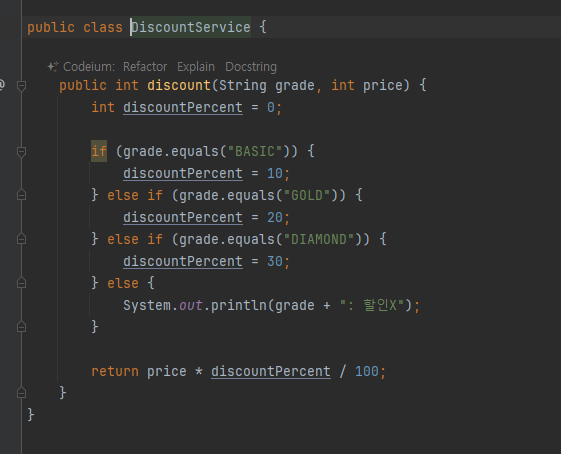
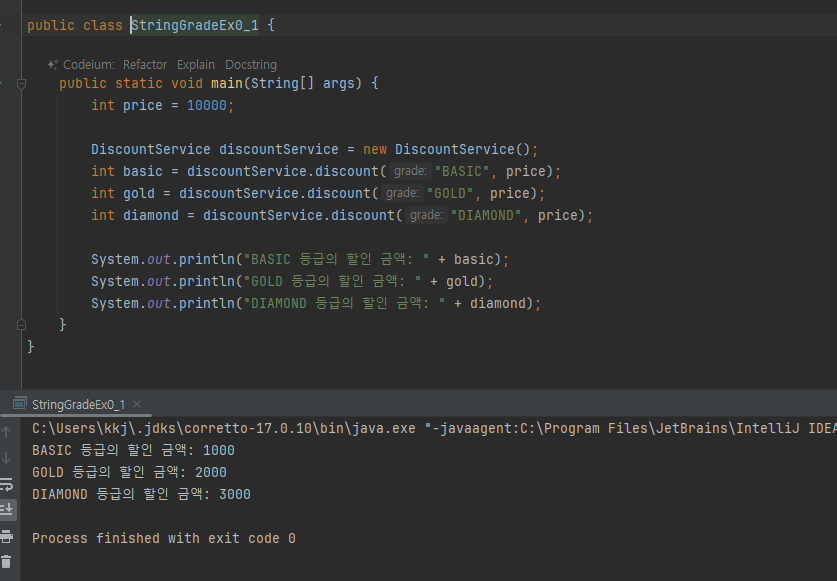
문자열 상수를 사용한 덕분에 전체적으로 코드가 더 명확해졌다. 그리고 discount() 에 인자를 전달할 때도
-
StringGrade 가 제공하는 문자열 상수를 사용하면 된다. 더 좋은 점은 만약 실수로 상수의 이름을 잘못 입력하면 컴파일 시점에 오류가 발생한다는 점이다. 따라서 오류를 쉽고 빠르게 찾을 수 있다
-
문자열 상수를 사용해도, 지금까지 발생한 문제들을 근본적으로 해결할 수 는 없다. 왜냐하면 String 타입은어떤 문자열이든 입력할 수 있기 때문이다
- 이런식으로 타입 안정성이 떨어지네
public int discount(String grade, int price) {}
- 사용해야 하는 문자열 상수가 어디에 있는지 discount() 를 호출하는 개발자가 어떻게 알 수 있을까?
- 다음코드를 보면 분명 String 은 다 입력할 수 있다고 되어있다.
타입 안전 열거형 패턴
-
지금까지 설명한 문제를 해결하기 위해 많은 개발자들이 오랜기간 고민하고 나온 결과가 바로 타입 안전 열거형 패턴이다.
-
enum 은 enumeration 의 줄임말인데, 번역하면 열거라는 뜻이고, 어떤 항목을 나열하는 것을 뜻한다.
-
우리의 경우 회원 등급인 BASIC , GOLD , DIAMOND 를 나열하는 것이다. 여기서 중요한 것은 타입 안전 열거형 패턴을 사용하면 이렇게 나열한 항목만 사용할 수 있다는 것이 핵심이다.
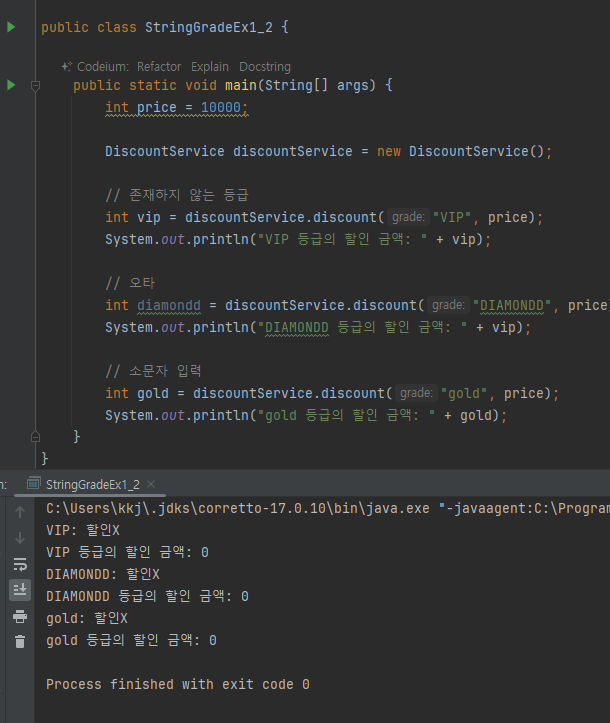
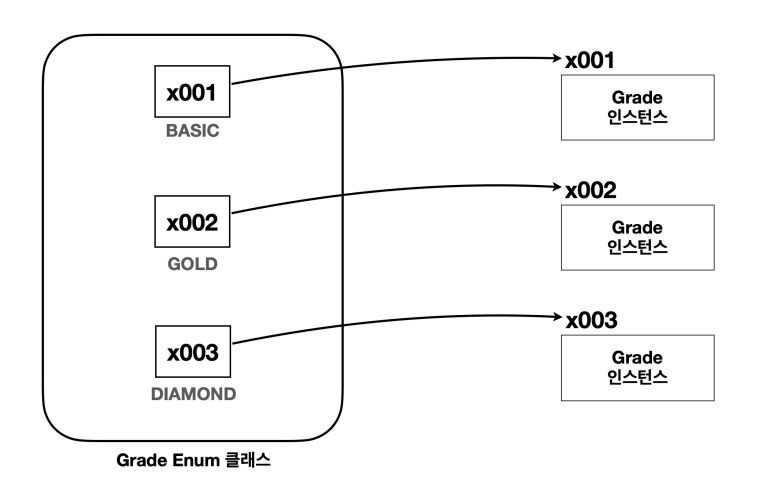
- 이때 각각의 상수마다 별도의 인스턴스를 생성하고, 생성한 인스턴스를 대입한다.
- 각각을 상수로 선언하기 위해 static , final 을 사용한다.
- static 을 사용해서 상수를 메서드 영역에 선언한다.
- final 을 사용해서 인스턴스(참조값)를 변경할 수 없게 한다
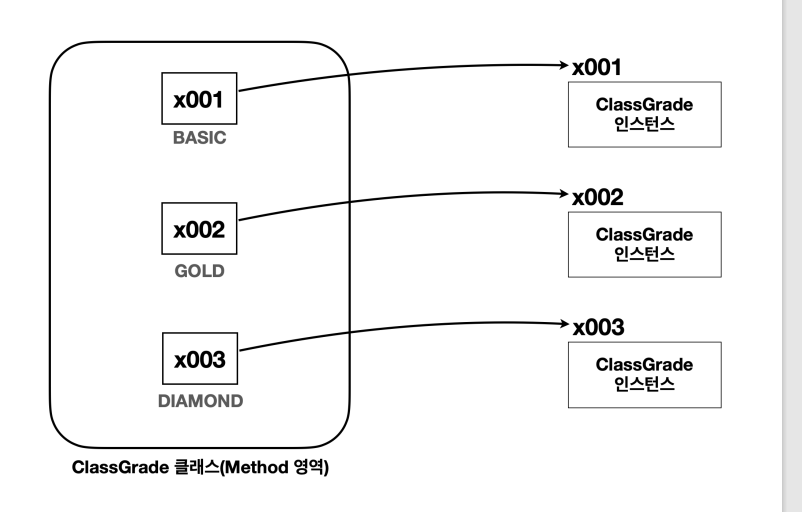
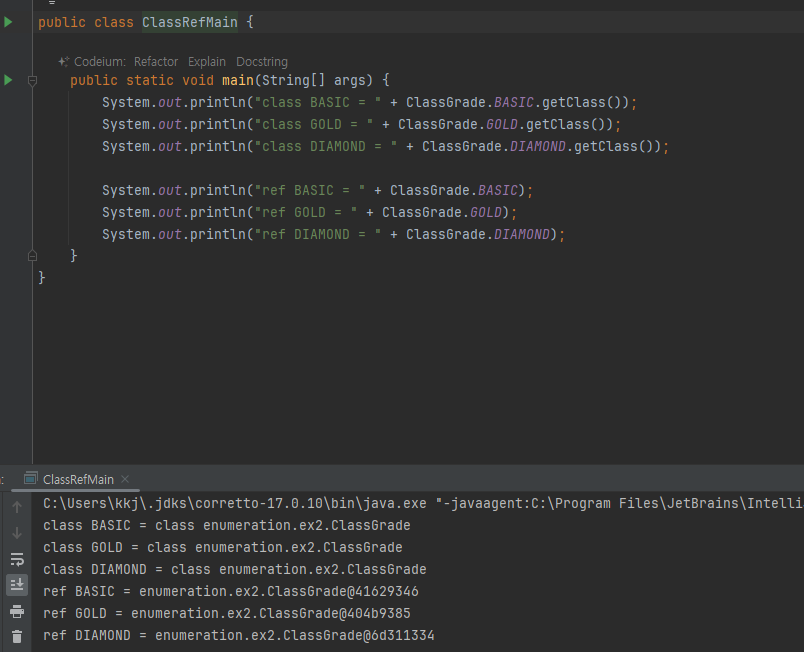
-
각각의 상수는 모두 ClassGrade 타입을 기반으로 인스턴스를 만들었기 때문에 getClass() 의 결과는 모두ClassGrade 이다
-
각각의 상수는 모두 서로 각각 다른 ClassGrade 인스턴스를 참조하기 때문에 참조값이 다르게 출력된다.
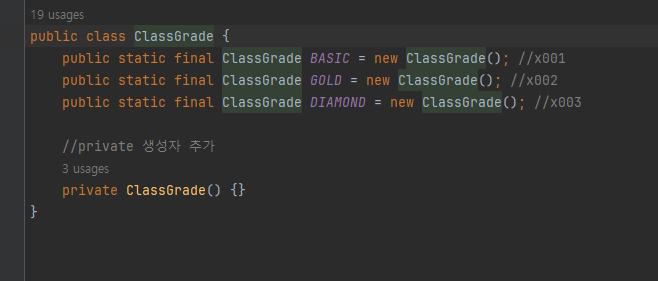
-
static 이므로 애플리케이션 로딩 시점에 다음과 같이 3개의 ClassGrade 인스턴스가 생성되고, 각각의 상수는 같은 ClassGrade 타입의 서로 다른 인스턴스의 참조값을 가진다.
- ClassGrade BASIC : x001
- ClassGrade GOLD : x002
- ClassGrade DIAMOND : x003
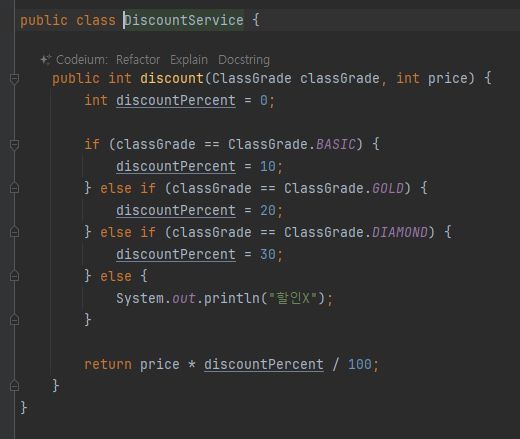
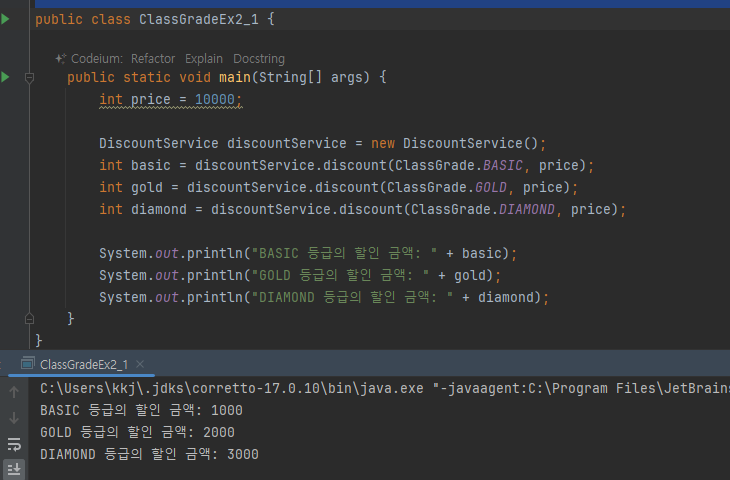
- discount() 메서드는 매개변수로 ClassGrade 클래스를 사용한다
- 값을 비교할 때는 classGrade == ClassGrade.BASIC 와 같이 == 참조값 비교를 사용하면 된다.
private 생성자
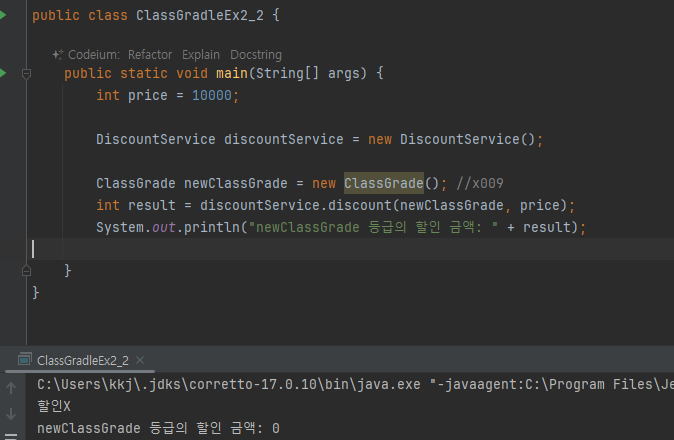
-
그런데 이 방식은 외부에서 임의로 ClassGrade 의 인스턴스를 생성할 수 있다는 문제가 있다.
-
문제를 해결하려면 외부에서 ClassGrade 를 생성할 수 없도록 막으면 된다. 기본 생성자를 private 으로 변경하자
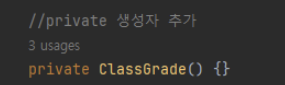
-
private 생성자를 사용해서 외부에서 ClassGrade 를 임의로 생성하지 못하게 막았다.
-
private 생성자 덕분에 ClassGrade 의 인스턴스를 생성하는 것은 ClassGrade 클래스 내부에서만 할 수있다.
-
앞서 우리가 정의한 상수들은 ClassGrade 클래스 내부에서 ClassGrade 객체를 생성한다.
-
쉽게 이야기해서 ClassGrade 타입에 값을 전달할 때는 우리가 앞서 열거한 BASIC , GOLD , DIAMOND 상수만 사용할 수 있다
타입 안전 열거형 패턴"(Type-Safe Enum Pattern)의 장점
타입 안정성 향상: 정해진 객체만 사용할 수 있기 때문에, 잘못된 값을 입력하는 문제를 근본적으로 방지할 수 있다.
데이터 일관성: 정해진 객체만 사용하므로 데이터의 일관성이 보장된다
조금 더 자세히
- 제한된 인스턴스 생성: 클래스는 사전에 정의된 몇 개의 인스턴스만 생성하고, 외부에서는 이 인스턴스들만 사용할 수 있도록 한다. 이를 통해 미리 정의된 값들만 사용하도록 보장한다.
- 타입 안전성: 이 패턴을 사용하면, 잘못된 값이 할당되거나 사용되는 것을 컴파일 시점에 방지할 수 있다. 예를 들어, 특정 메서드가 특정 열거형 타입의 값을 요구한다면, 오직 그 타입의 인스턴스만 전달할 수 있다.
- 여기서는 메서드의 매개변수로 ClassGrade 를 사용하는 경우, 앞서 열거한 BASIC , GOLD , DIAMOND 만 사용할 수 있다
- 단점
- 이 패턴을 구현하려면 다음과 같이 많은 코드를 작성해야 한다. 그리고 private 생성자를 추가하는 등 유의해야 하는부분들도 있다
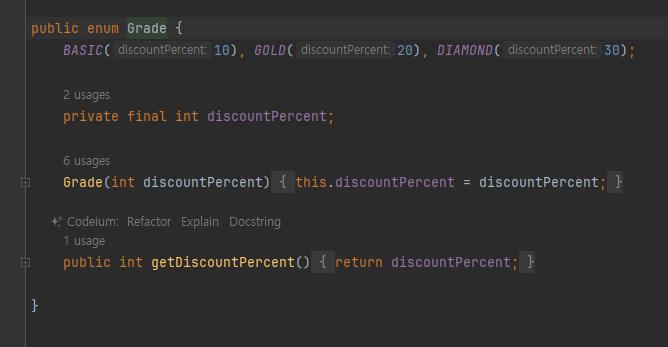
열거형 - Enum Type
- 회원의 등급은 상수로 정의한 BASIC , GOLD , DIAMOND 만 사용할 수 있다는 뜻
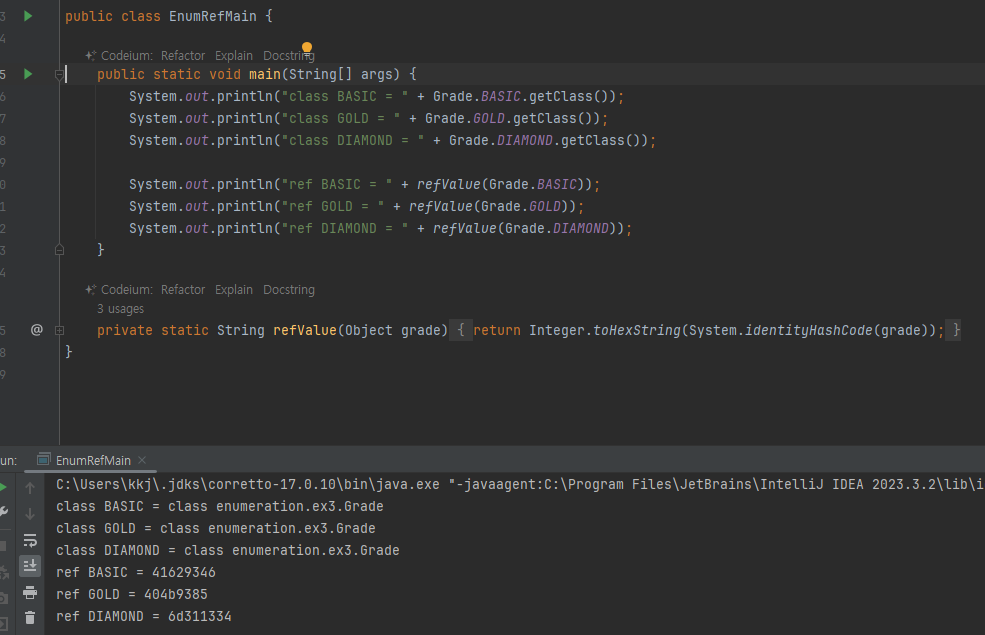
- 참고로 열거형은 toString() 을 재정의 하기 때문에 참조값을 직접 확인할 수 없다. 참조값을 구하기 위해refValue() 를 만들었다.
- System.identityHashCode(grade) : 자바가 관리하는 객체의 참조값을 숫자로 반환한다.
- Integer.toHexString() : 숫자를 16진수로 변환, 우리가 일반적으로 확인하는 참조값은 16진수열거형도 클래스이다. 열거형을 제공하기 위해 제약이 추가된 클래스라 생각하면 된다
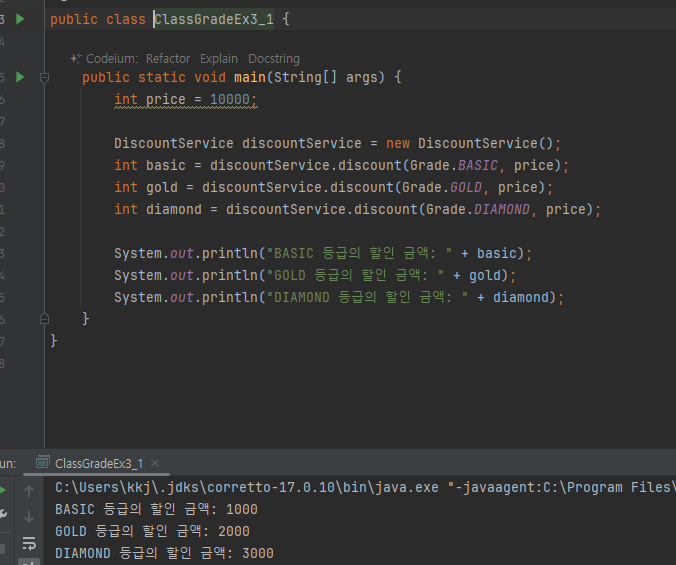
- 열거형으로 바꾼 클래스
열거형은 외부 생성 불가
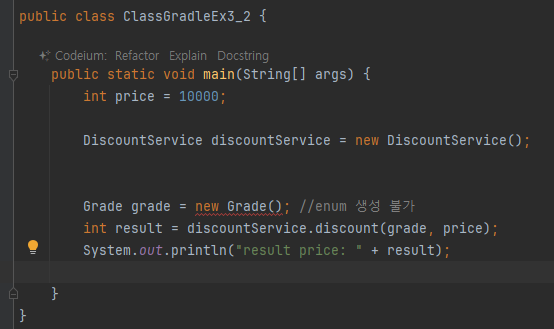
- 오류 메시지: enum classes may not be instantiated
열거형(ENUM)의 장점
-
타입 안정성 향상: 열거형은 사전에 정의된 상수들로만 구성되므로, 유효하지 않은 값이 입력될 가능성이 없다. 이런 경우 컴파일 오류가 발생한다
-
간결성 및 일관성: 열거형을 사용하면 코드가 더 간결하고 명확해지며, 데이터의 일관성이 보장된다.
-
확장성: 새로운 회원 등급을 타입을 추가하고 싶을 때, ENUM에 새로운 상수를 추가하기만 하면 된다.
-
열거형을 사용하는 경우 static import 를 적절하게 사용하면 더 읽기 좋은 코드를 만들 수 있다.
열거형 - 주요 메서드
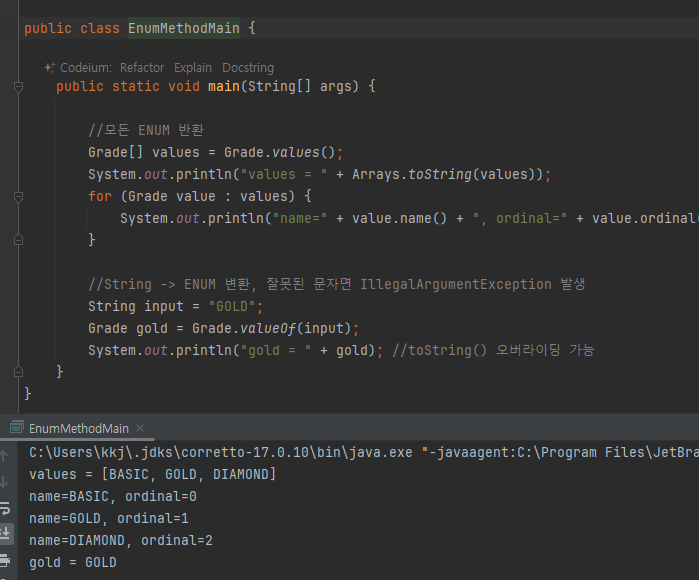

- Ordinal() 가급적 사용 지양
- 이 값을 사용하다 중간 상수를 선언하는 위치가 변경되면 전체 상수위치가 변경될 수 있음

- 그림 처럼..
열거형 정리
- 열거형은 java.lang.Enum 자동(강제)으로 상속 받음
- 열거형은 이미 java.lang.Enum 상속받앗기 때문에 추가 상속 불가능
- 열거형은 인터페이스를 구현 가능
- 열거형에 추상 메서드 선언하고 구현가능
- 이 경우 익명클래스와 같은 방식 사용
열거형 - 리팩토링 1
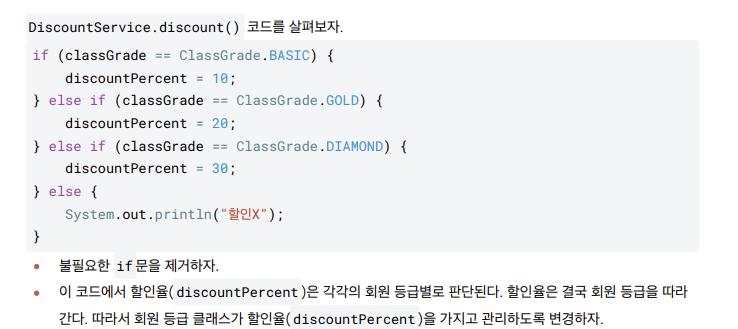
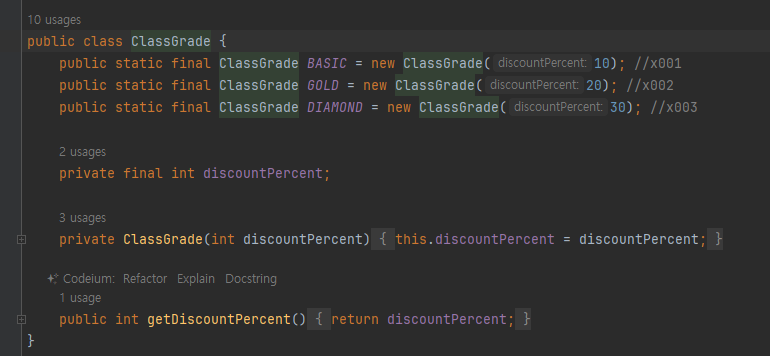

- 이런식으로 열거형 사용시 불필요한 리펙토링을 줄일 수 있다.
리펙토링 2
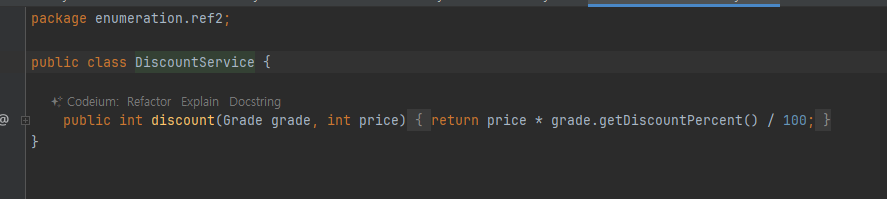
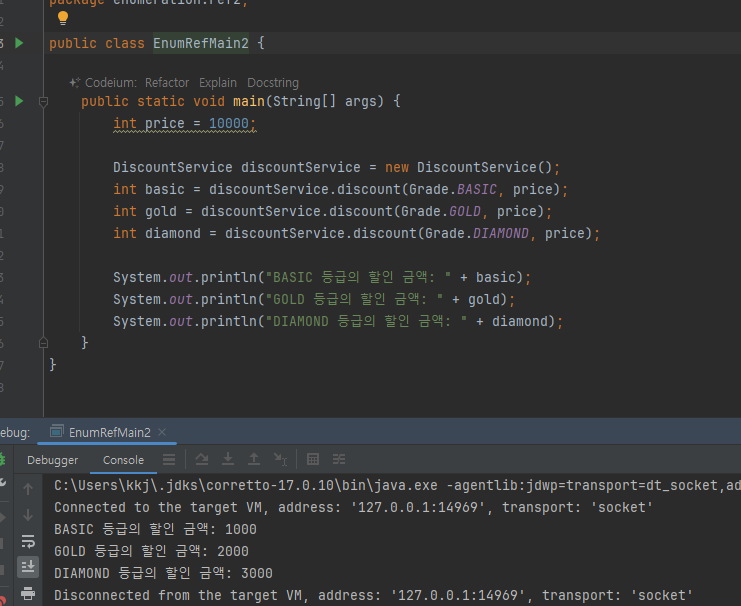
- 위와 동일
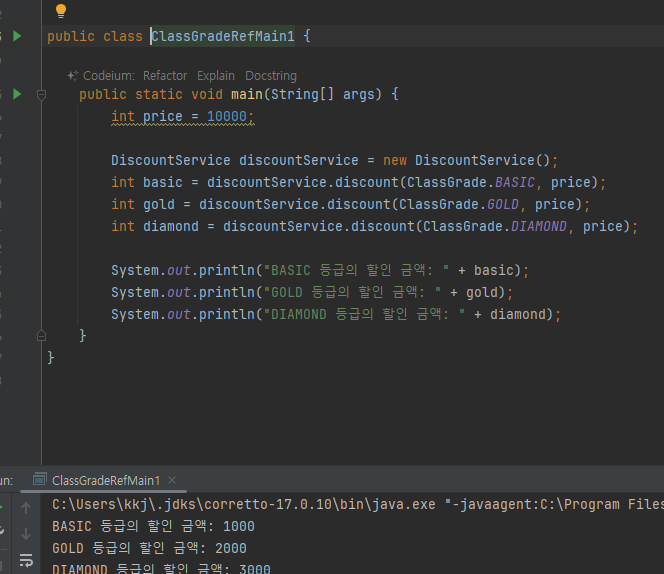
public class DiscountService {
public int discount(Grade grade, int price) {
return price * grade.getDiscountPercent() / 100;
}-
이 코드를 보면 할인율 계산을 위해 Grade 가 가지고 있는 데이터인 discountPercent 의 값을 꺼내서 사용한다.
-
결국 Grade 의 데이터인 discountPercent 를 할인율 계산에 사용한다.
-
객체지향 관점에서 이렇게 자신의 데이터를 외부에 노출하는 것 보다는, Grade 클래스가 자신의 할인율을 어떻게 계산하는지 스스로 관리하는 것이 캡슐화 원칙에 더 맞다
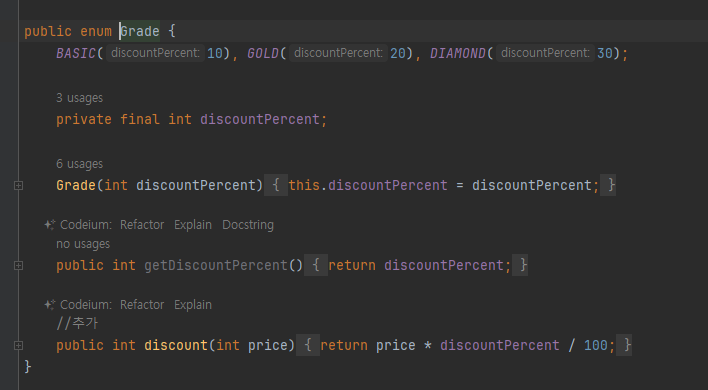

-
코드동작은 기존이랑 같다
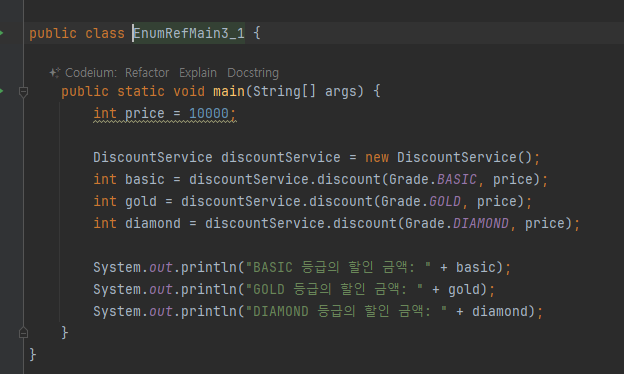
DiscountService 제거
- Grade 가 스스로 할인율을 계산하면서 DiscountService 클래스가 더는 필요하지 않게 되었다.
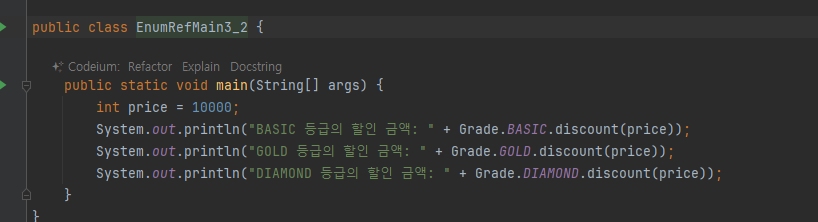
중복 제거
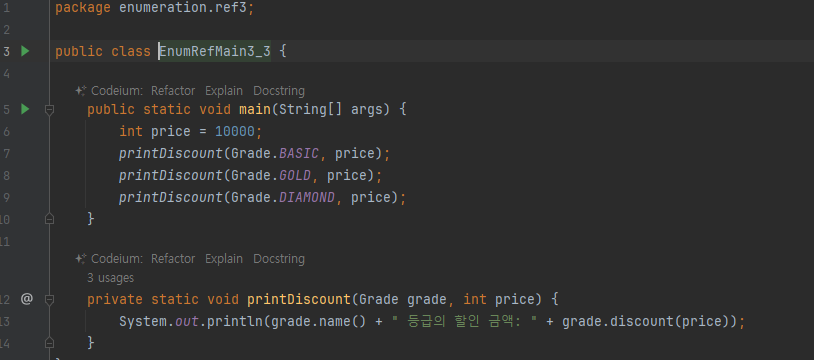
ENUM 목록
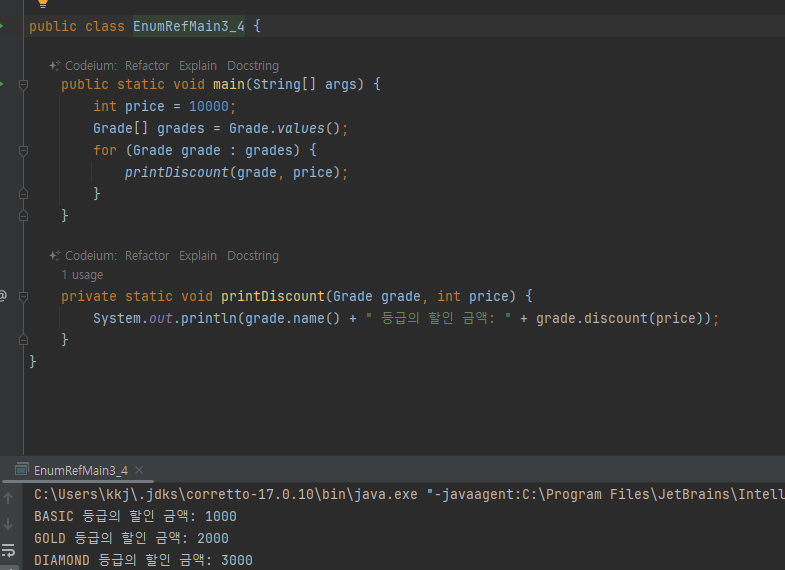
- 이후에 새로운 등급이 추가되더라도 main() 코드의 변경 없이 모든 등급의 할인을 출력해보자.
날짜와 시간
- 날짜 시간차이 계산 / 윤년계산 / 일광 절약시간 타임존.
- 이런 종류의 시간계산은 은근히 어렵다.
타임존 계산
세계는 다양한 타임존으로 나뉘어 있으며, 각 타임존은 UTC(협정 세계시)로부터의 시간 차이로 정의된다. 타임존 간의 날짜와 시간 변환을 정확히 계산하는 것은 복잡하다.
타임존 목록:
-
Europe/London: GMT, UTC
-
US/Arizona: -07:00
-
America/New_York: -05:00
-
Asia/Seoul: +09:00
-
Asia/Dubai: +04:00
-
Asia/Istanbul: +03:00
-
Asia/Shanghai: +08:00
-
Europe/Paris: +01:00
-
Europe/Berlin: +01:00
-
GMT, UTC (London/ UTC / GMT)는 세계 시간의 기준이 되는 00:00 시간대이다.
-
GMT (그리니치 평균시, Greenwich Mean Time)
처음 세계 시간을 만들 때 영국 런던에 있는 그리니치 천문대를 기준으로 했다.
태양이 그리니치 천문대를 통과할 때를 정오로 한다.
UTC (협정 세계시, Universal Time Coordinated)
JDK 8 (java.time패키지)
-
java.time 패키지는 이전 API의 문제점을 해결하면서, 사용성, 성능, 스레드 안전성, 타임존 처리 등에서 크게개선되었다.
-
변경 불가능한 불변 객체 설계로 사이드 이펙트, 스레드 안전성 보장, 보다 직관적인 API 제공으로 날짜와 시간 연산을 단순화했다
-
LocalDate , LocalTime , LocalDateTime , ZonedDateTime , Instant 등의 클래스를 포함한다.
-
이전 java.util.Data / Calender 등의 문제들..이있어서 위에 패키지가 나옴

- 참고용 자료 읽어보기만.
자바 날짜와 시간라이브러리 소개
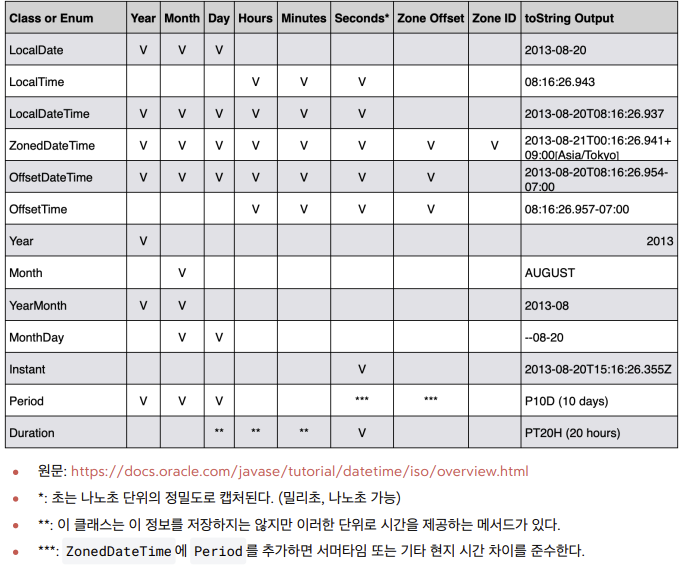
- 초는 나노초 단위로 정밀도 캡처
LocalData, LocalTime, LocalDateTime
-
LocalDate : 날짜만 표현할때 사용 년월일 다룸 / 2013-11-21
-
LocalTime : 시간만 표현할때 사용 시분초 / 08:20:30.213
-
LocalDateItme : 위 두개념 합한 개념 / 2013-11-21T08:20:30.213
-
앞에 Local (현지의, 특정 지역의)이 붙는 이유는 세계 시간대를 고려하지 않아서 타임존이 적용되지 않기 때문이다.
-
특정 지역의 날짜와 시간만 고려할 때 사용한다
- 애플리케이션이 개발시 국내 서비스만 고려시 등..
ZonedDateTime , OffsetDateTime
-
ZonedDateTime: 시간대를 고려한 날짜와 시간을 표현할때 사용 여기서 시간대를 표현하는 타임존이 포함 됨
-
예) 2013-11-21T08:20:30.213+9:00[Asia/Seoul]
-
+9:00 은 UTC(협정 세계시)로 부터의 시간대 차이이다. 오프셋이라 한다. 한국은 UTC보다 +9:00 시간이다.
-
Asia/Seoul 은 타임존이라 한다. 이 타임존을 알면 오프셋과 일광 절약 시간제에 대한 정보를 알 수 있다.
-
일광 절약 시간제 적용 됨.
-
OffsetDateTime : 시간대를 고려한 날짜와 시간을 표현할때 사용
-
타임존은 없고 UTC로 부터 의 시간대 차이인 고정된 오프셋만 포함
-
2013-11-21T08:20:30.213+9:00
-
일광 절약 시간제 적용 X
Asia/Seoul 같은 타임존 안에는 일광 절약 시간제에 대한 정보와 UTC+9:00와 같은 UTC로 부터 시간 차이인 오프
셋 정보를 모두 포함하고 있다.
- 일광 절약 식나제(DST, 썸머타임) 을 알려면 타임존을 알아야 됨.
- ZonedDateTime은 일관 절약 시간제를 함께처리
- 반면 타임존 알수없는 OffsetDateTime은 일광 절약시간제 처리못함.
ZonedDateTime 은 시간대를 고려해야 할 때 실제 사용하는 날짜와 시간 정보를 나타내는 데 더 적합하고,
OffsetDateTime 은 UTC로부터의 고정된 오프셋만을 고려해야 할 때 유용하다
Instant
- Instant 는 UTC(협정 세계시)를 기준으로 하는, 시간의 한 지점을 나타낸다. Instant 는 날짜와 시간을 나노초 정밀도로 표현하며, 1970년 1월 1일 0시 0분 0초(UTC)를 기준으로 경과한 시간으로 계산된다.
- 쉽게 이야기해서 Instant 내부에는 초 데이터만 들어있다. (나노초 포함)
- 따라서 날짜와 시간을 계산에 사용할 때는 적합하지 않다.
Period, Duration
-
시간 개념은 크게 2가지 표현
-
특정 시점의 시간(시각)
- 이 프로젝트는 2013년 8월16일까지 완료해야함
- 다음 회의는 11시 30분에 진행
- 내 생일은 8월 16일
-
시간의 간격(기간)
- 앞으로 4년은 더 공부해야해
- 이 프로젝트는 3개월 남았어
- 라면은 3분동안 끓여야되
-
Period, Duration은 시간의 간격(기간)을 표현하는대 사용
-
시간의 간격은 영어로 amount of time(시간의 양)으로 불림
Period
- 두 날짜 사이의 간격을 년 월일 단위로 나타냄
Duration
- 두 시간 사이의 간격을 시 분 초(나노초) 단위로 나타냄
기본 날짜와 시간 - LocalDateTime
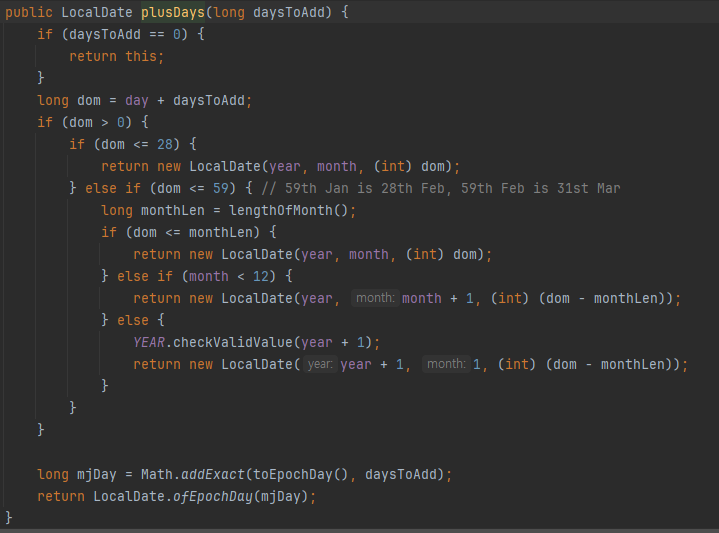
- 위에 설명있어 설명 생략
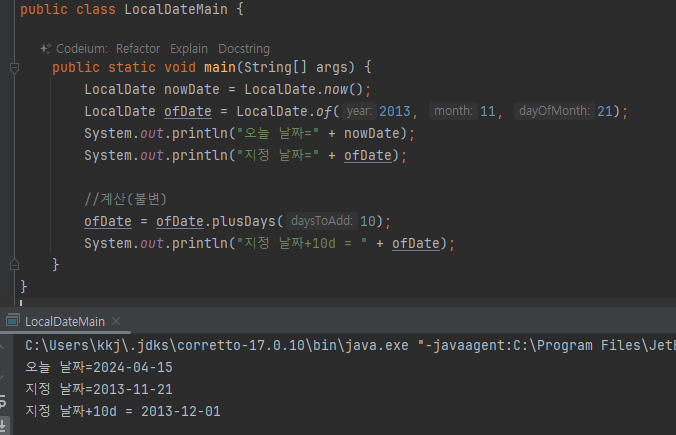
- 모든 날짜 클래스는 불변이다. 따라서 변경이 발생하는 경우 새로운 객체를 생성해서 반환하므로 반환값을 꼭 받아야 한다.
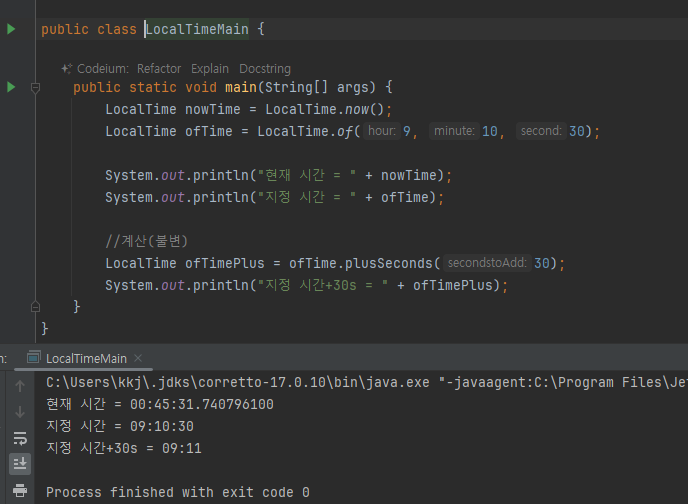
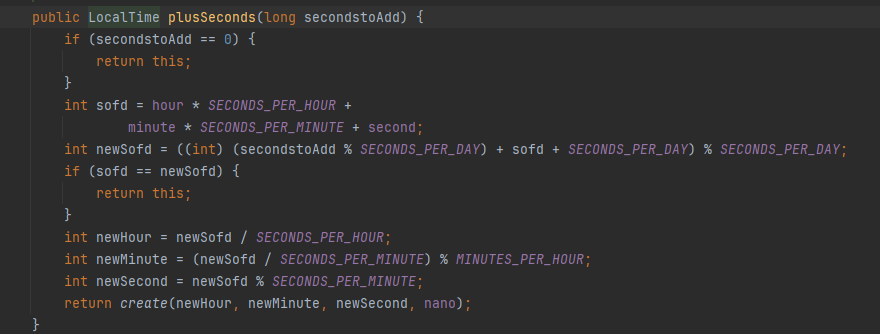
- 여기도 역시 불변..

- isEquals(): 다른 날짜시간과 시간적으로 동일한지 비교한다. 시간이 같으면 true 를 반환한다
isEquals() vs equals()
- isEquals() 는 단순히 비교 대상이 시간적으로 같으면 true 를 반환한다. 객체가 다르고, 타임존이 달라도 시간적으로 같으면 true 를 반환한다. 쉽게 이야기해서 시간을 계산해서 시간으로만 둘을 비교한다.
- 예) 서울의 9시와 UTC의 0시는 시간적으로 같다. 이 둘을 비교하면 true 를 반환한다.
- equals() 객체의 타입, 타임존 등등 내부 데이터의 모든 구성요소가 같아야 true 를 반환한다.
- 예) 서울의 9시와 UTC의 0시는 시간적으로 같다. 이 둘을 비교하면 타임존의 데이터가 다르기 때문에false 를 반환한다
타임존 - ZonedDateTime
- "Asia/Seoul" 같은 타임존 안에는 일광 절약 시간제에 대한 정보와 UTC+9:00와 같은 UTC로 부터 시간 차이인 오프셋 정보를 모두 포함하고 있다
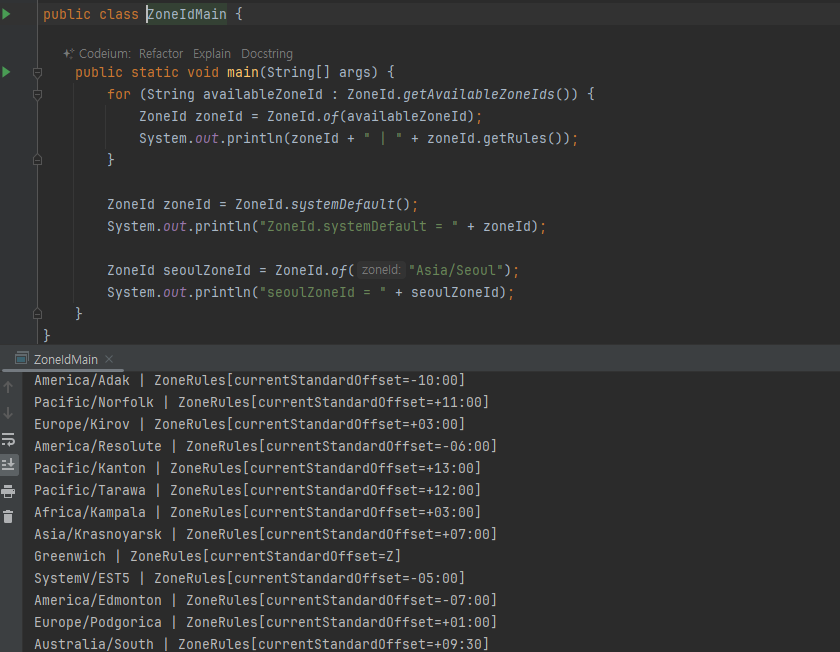

-
여러가지 타임존이 나옴..
-
ZoneId 는 내부에 일광 절약 시간 관련 정보, UTC와의 오프셋 정보를 포함하고 있다.
ZonedDateTime
- LocalDateTime + ZoneId 합쳐진 것

-
+9:00 은 UTC(협정 세계시)로 부터의 시간대 차이이다. 오프셋이라 한다. 한국은 UTC보다 +9:00 시간이다
-
Asia/Seoul 은 타임존이라고 한다. 이 타임존을 알면 오프셋도 알 수 있다. +9:00 같은 오프셋 정보도 타임존에 포함된다.
-
추가로 ZoneId 를 통해 타임존을 알면 일광 절약 시간제에 대한 정보도 알 수 있다. 따라서 일광 절약 시간제가 적용된다
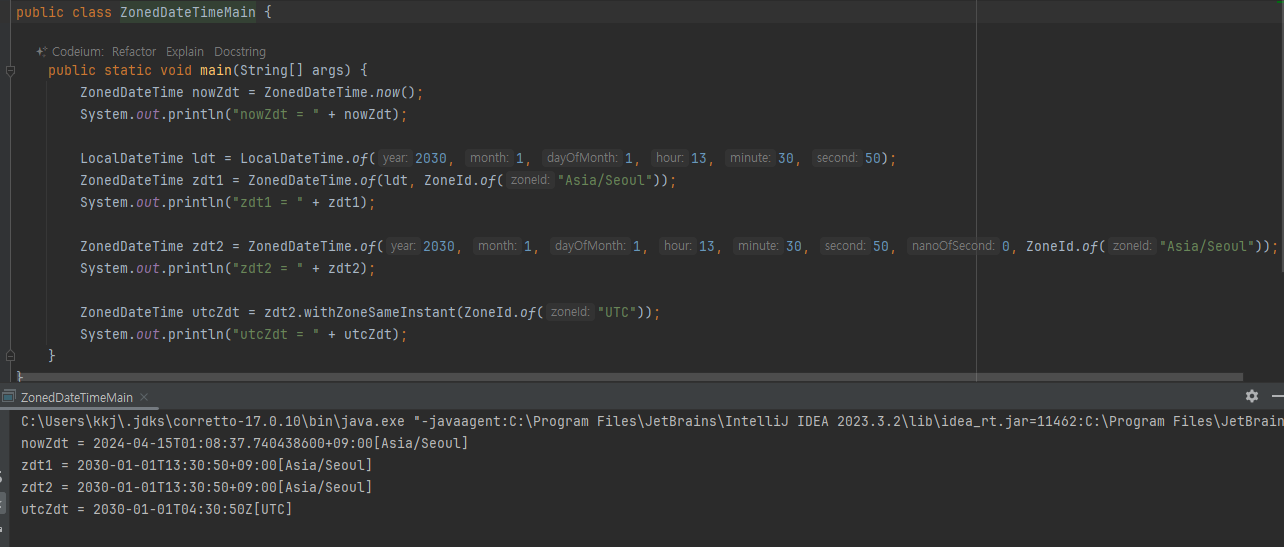
- 생성
- now() : 현재 날짜와 시간을 기준으로 생성한다. 이때 ZoneId 는 현재 시스템을 따른다. ( ZoneId.systemDefault()
- of(...) : 특정 날짜와 시간을 기준으로 생성한다. ZoneId 를 추가해야 한다.
- LocalDateTime 에 ZoneId 를 추가해서 생성할 수 있다
- 타임존 변경
- withZoneSameInstant(ZoneId) : 타임존을 변경한다. 타임존에 맞추어 시간도 함께 변경된다. 이 메서드를 사용하면 지금 다른 나라는 몇 시 인지 확인일 수 있다 예를 들어서 서울이 지금 9시라면, UTC 타임존으로 변경하면 0시를 확인할 수 있다
OffsetDateTime
- OffsetDateTime 은 LocalDateTime 에 UTC 오프셋 정보인 ZoneOffset 이 합쳐진 것이다.
public class OffsetDateTime {
private final LocalDateTime dateTime;
private final ZoneOffset offset
}
-
OffsetDateTime: 시간대를 고려한 날짜와 시간을 표현할 때 사용한다. 여기에는 타임존은 없고, UTC로 부터의 시간대 차이인 고정된 오프셋만 포함한다
-
ex) 2013-11-21T08:20:30.213+9:00
-
ZoneId가 없으므로 일광 절약 시간제가 적용되지 안흔ㄴ다
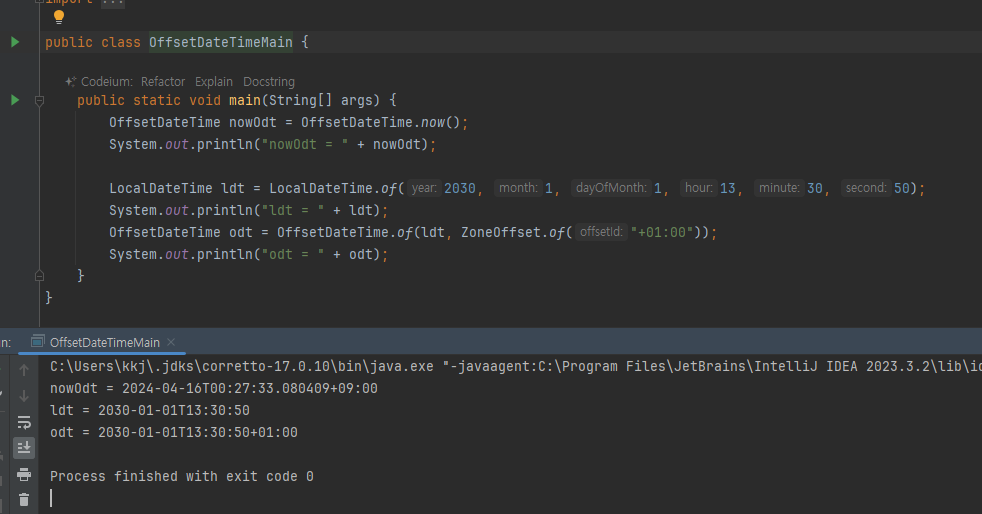
ZonedDateTime vs OffsetDateTime
-
ZonedDateTime 은 구체적인 지역 시간대를 다룰 때 사용하며, 일광 절약 시간을 자동으로 처리할 수 있다. 사용자 지정 시간대에 따른 시간 계산이 필요할 때 적합하다.
-
OffsetDateTime 은 UTC와의 시간 차이만을 나타낼 때 사용하며, 지역 시간대의 복잡성을 고려하지 않는다. 시간대 변환 없이 로그를 기록하고, 데이터를 저장하고 처리할 때 적합하다
참고
ZonedDateTime 이나 OffsetDateTime 은 글로벌 서비스를 하지 않으면 잘 사용하지 않는다. 따라서 너무 깊이있게 파기 보다는 대략 이런 것이 있다 정도로만 알아두면 된다. 실무에서 개발하면서 글로벌 서비스를 개발할 기회가 있다면 그때 필요한 부분을 찾아서 깊이있게 학습하면 된다.
기계 중심의 시간 - Instant
- Instant 는 UTC(협정 세계시)를 기준으로 하는, 시간의 한 지점을 나타낸다. Instant 는 날짜와 시간을 나노초 정밀도로 표현하며, 1970년 1월 1일 0시 0분 0초(UTC 기준)를 기준으로 경과한 시간으로 계산된다.
- 쉽게 이야기해서 Instant 내부에는 초 데이터만 들어있다. (나노초 포함
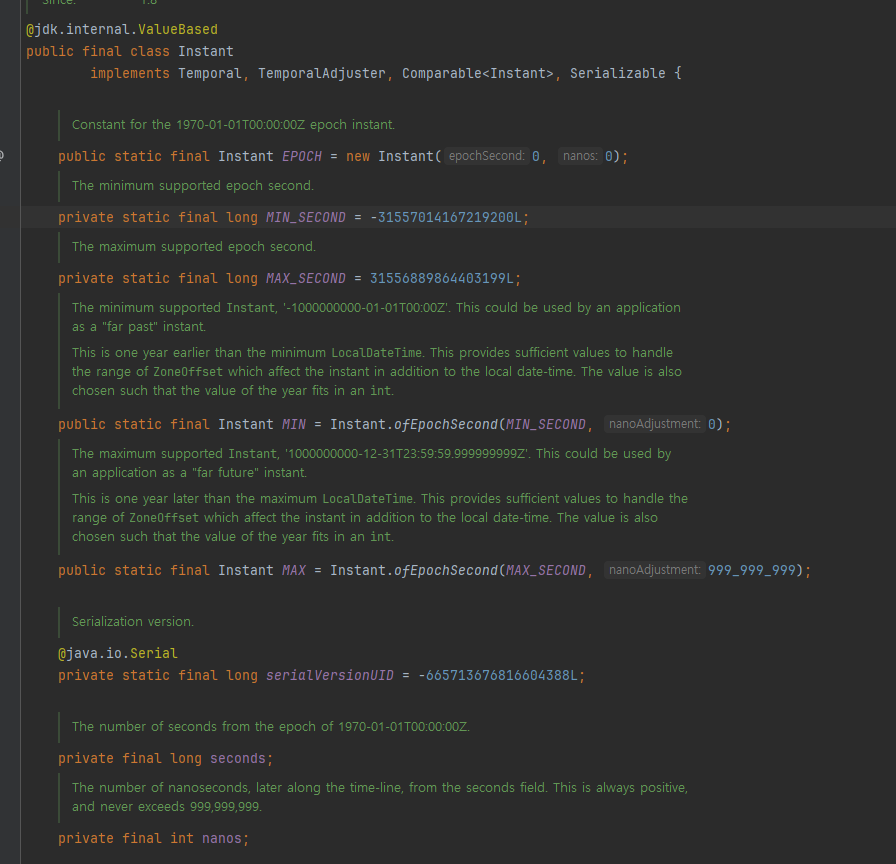
public class Instant {
private final long seconds;
private final int nanos;
...
}
- UTC 기준 1970년 1월 1일 0시 0분 0초라면 seconds 에 0이 들어간다.
- UTC 기준 1970년 1월 1일 0시 0분 10초라면 seconds 에 10이 들어간다.
- UTC 기준 1970년 1월 1일 0시 1분 0초라면 seconds 에 60이 들어간다.
참고 - Epoch 시간
Epoch time(에포크 시간), 또는 Unix timestamp는 컴퓨터 시스템에서 시간을 나타내는 방법 중 하나이다. 이는1970년 1월 1일 00:00:00 UTC부터 현재까지 경과된 시간을 초 단위로 표현한 것이다. 즉, Unix 시간은 1970년 1월
1일 이후로 경과한 전체 초의 수로, 시간대에 영향을 받지 않는 절대적인 시간 표현 방식이다.
참고로 Epoch라는 뜻은 어떤 중요한 사건이 발생한 시점을 기준으로 삼는 시작점을 뜻하는 용어다.
Instant 는 바로 이 Epoch 시간을 다루는 클래스이다
Instant 특징
장점
- 시간대 독립성 : UTC 기준으로 하므로 시간대 영향 받지 않음 전 세계 어디서나
동일한 시점을 가리키는데 유용하다 - 고정된 기준점: 모든 Instant는 1970년 1월 1일 UTC기준으로 하기 때문에 시간 계산 비교과 명확하고 일관됨
단점
- 사용자 진화적이지 않음: Instant는 기계적 시간처리에는 적합하지만
사람이 읽고 이해하기 직관적이지 않다 예를 들어 날짜와 시간을 꼐산하고 사용하는데 필요한 기능이 부족하다 - 시간대 정보 부재: Instant에는 시간대 정보가 포함되이씾않아 특정 지역의 날짜와 시간으로 변환하려면 추가적인 작업이 필요하다
사용 예
-
전 세계적인 시간 기준 필요 시 : Instant는 UTC 기준으로 하므로 전 세계적으로 일관된 시점을 표현할때 사용하기 좋음 , 로그 기록 , 트랜잭션 , 타임스탬프 , 서버간의 시간동기화등에 해당
-
시간대 변환없이 시간 계산 필요시: 시간대의 변화 없이 순수하게 시간의 흐름(지속시간 계산) 만을 다루고 싶을때 Instant가 적합함, 이는 시간대 변환의 복잡성 없이 계싼 할 수 있게해줌
-
데이터 저장 및 교환 : 데이터베이스에 날짜와 시간 정보를 저장하거나 다른 시스템과 날짜와 시간 정보를 교환할때 Instant를 사용하면 모든 시스템에서 동일한 기준점(UTC)를 사용하게 되므로 데이터 일관성 유지 쉬움
일반적으로 날짜와 시간을 사용할 때는 LocalDateTime , ZonedDateTime 등을 사용하면 된다. Instant 는 날짜를 계산하기 어렵기 때문에 앞서 사용 예와 같은 특별한 경우에 한정해서 사용하면 된다.
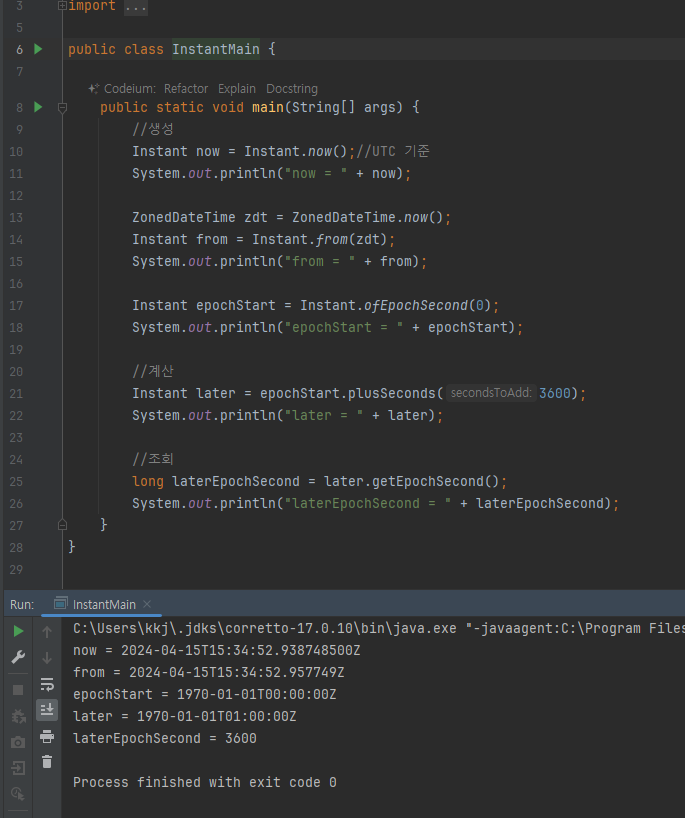
- 생성
- now() : UTC를 기준 현재 시간의 Instant 를 생성한다.
- from() : 다른 타입의 날짜와 시간을 기준으로 Instant 를 생성한다. 참고로 Instant 는 UTC를 기준으로하기 때문에 시간대 정보가 필요하다. 따라서 LocalDateTime 은 사용할 수 없다.
- ofEpochSecond() : 에포크 시간을 기준으로 Instant 를 생성한다. 0초를 선택하면 에포크 시간인 1970년1월 1일 0시 0분 0초로 생성된다
- 계산
- plusSeconds() : 초를 더한다. 초, 밀리초, 나노초 정도만 더하는 간단한 메서드가 제공된다
Instant 정리
- 조금 특별한 시간, 기계 중심, UTC 기준
- 에포크 시간으로부터 흐른 시간을 초 단위로 저장
- 전세계 모든 서버 시간을 똑같이 맞출 수 있음, 항상 UTC 기준이므로 한국에 있는 Instant , 미국에 있는 Instant 의 시간이 똑같음
- 서버 로그, epoch 시간 기반 계산이 필요할 때, 간단히 두 시간의 차이를 구할 때
- 단점: 초 단위의 간단한 연산 가능, 복잡한 연산 못함
- 대안: 날짜 계산 필요하면 LocalDateTime 또는, ZonedDateTime 사용
기간, 시간의 간격 - Duration, Period
Period

-
두 날짜 사이의 간격을 년 월 일 단위로 나타냄
- 이 프로젝트는 3개월 정도 걸릴듯
- 기념일이 183일 남음
- 프로젝트 시작일과 종료일 사이의 간격: 프로젝트 기간
public class Period {
private final int years;
private final int months;
private final int days;
}
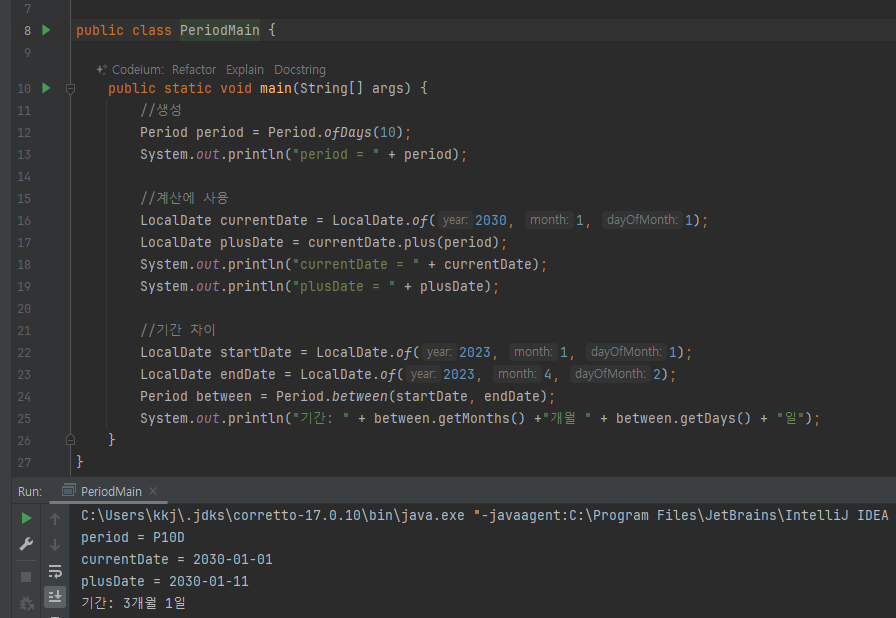
- 계산에 사용 , 기간 차이등 이런 기능이 있넹.
Duration
-
두 시간 사이의 간격을 시 분 초(나노초) 단위로 나타냄
- 라면 끓이는 시간 3분
- 영화 상영 시간은 2시간 30분임
- 서울에서 부산까지 4시간..
public class Duration {
private final long seconds;
private final int nanos;
}
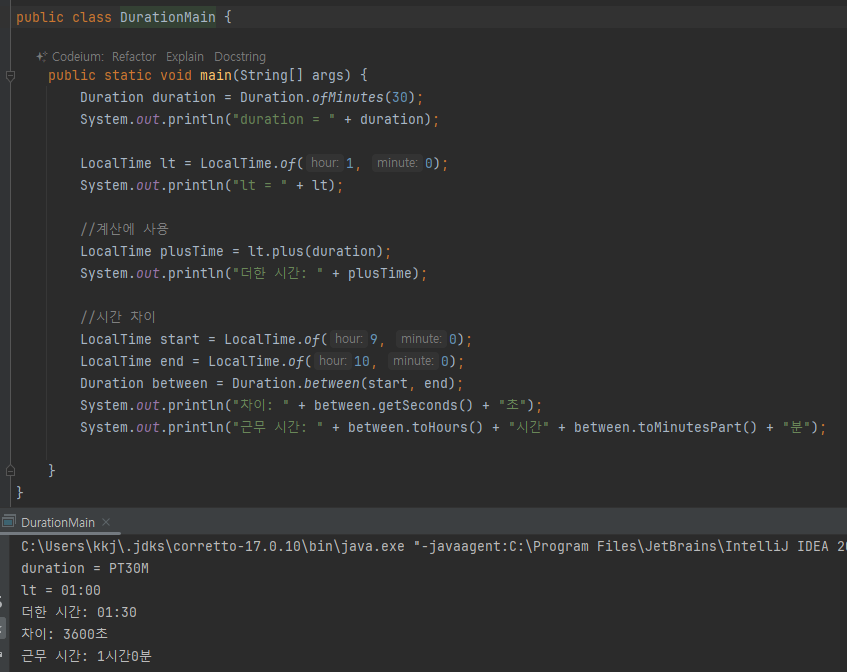
- 30분 더한 계산사용 / 시간차이 등 기능이 있음
날짜와 시간의 핵심 인터페이스
- 날짜와 시간은 특정 시점의 시간(시각)과 시간의 간격(기간)으로 나눌 수 있다.

- 반복되는 설명
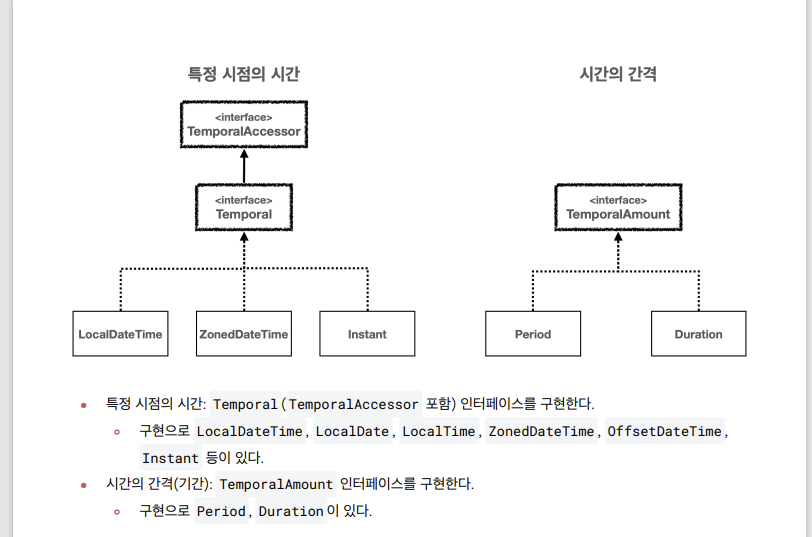

- 진짜넹
TemporalAccessor 인터페이스
- 날짜와 시간을 읽이 위한 기본 인터페이스
- 이 인터페이스는 특정 시점의 날짜와 시간 정보를 읽을 수 있는 최소한의 기능 제공
Temporal 인터페이스
-
TemporalAccessor의 하위 인터페이스로 날짜와 시간을 조작(추가,빼기 등) 하기 위한 기능 제공 이를 통해 날짜와 시간을 변경하거나 조정 할 수 있다.
-
간단히 말하면 TemporalAccessor는 일기전용 접근을 Temporal은 읽기와 쓰기(조작) 모두 지원
TemporalAmount 인터페이스
- 시간의 간격?(시간의 양, 기간) 을 나타내며 날짜와 시간 객체에 적용하여 그 객체를 조정 할 수 있다. 예를 들어 특정 날짜에 일정 기간을 더하거나 빼는 데 사용 됨
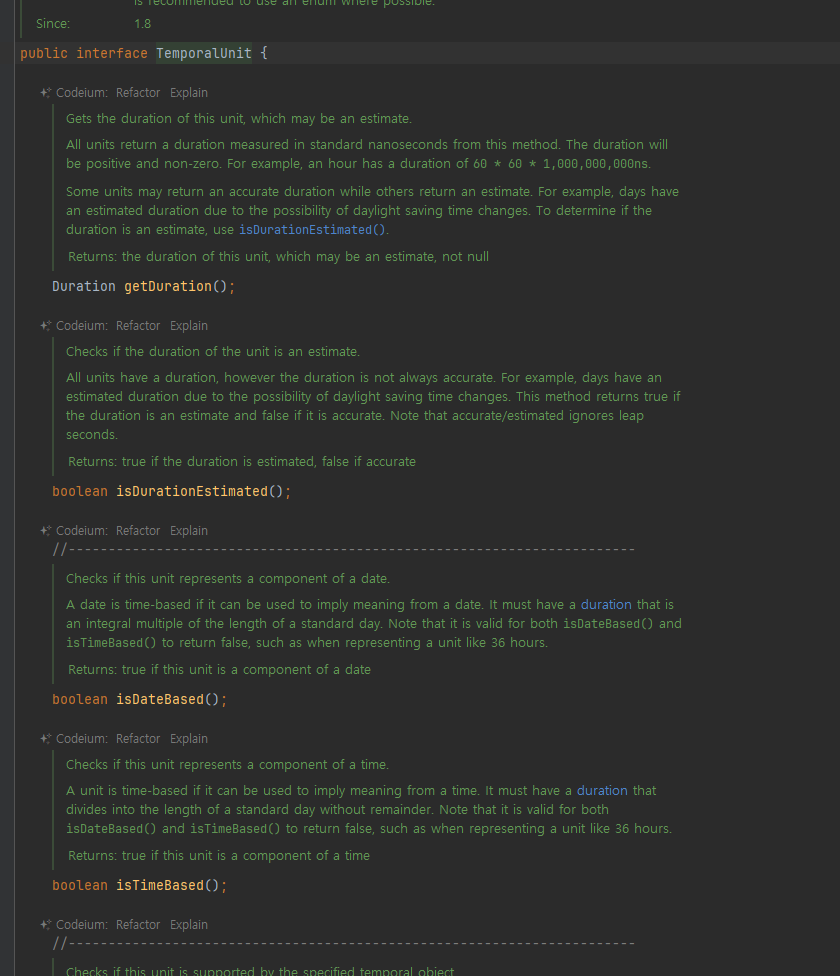
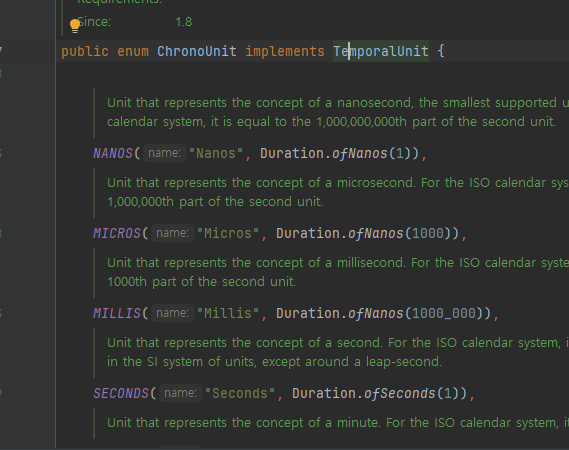
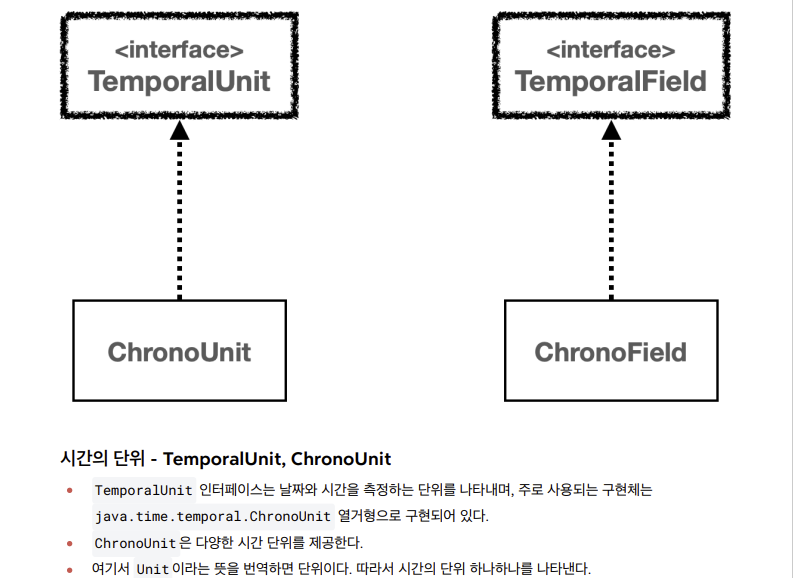
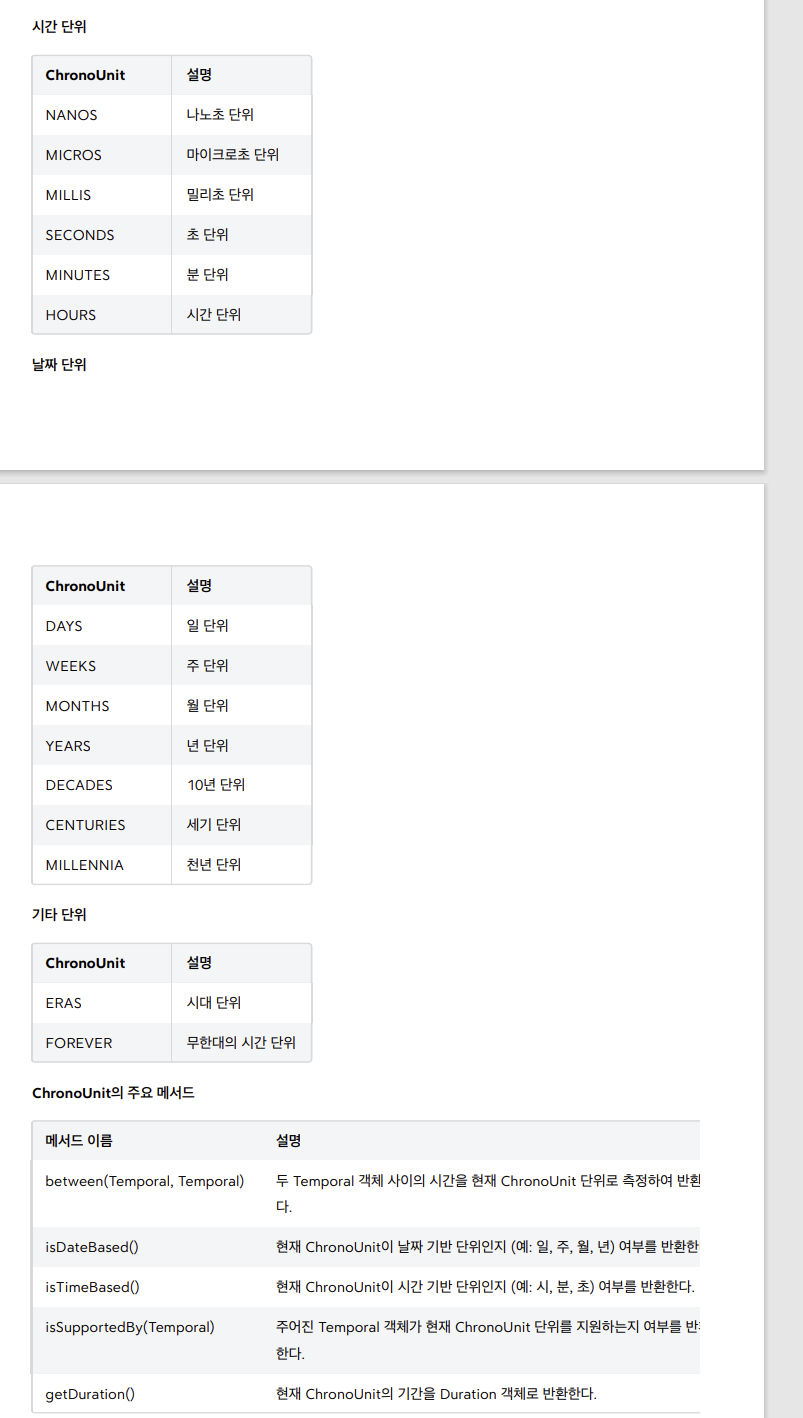
시간의 단위와 시간 필드
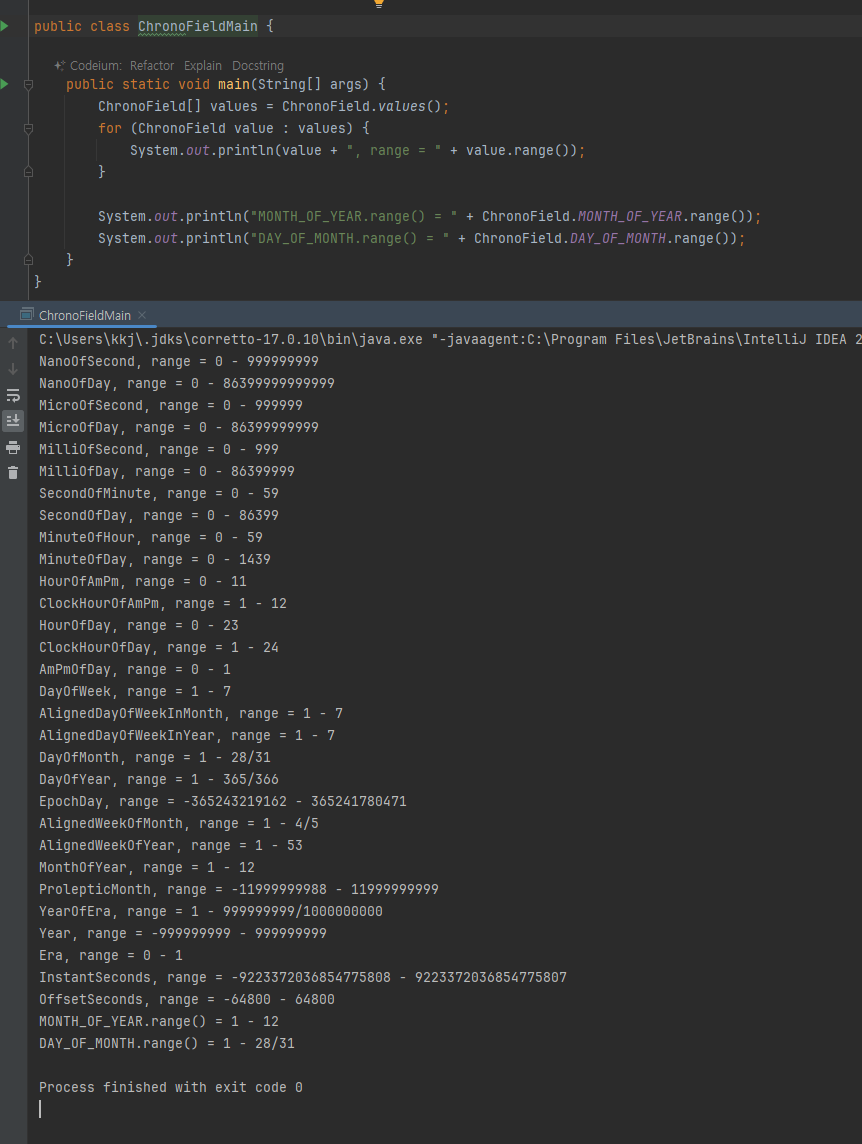
- 다음으로 설명할 날짜와 시간의 핵심 인터페이스는 시간의 단위를 뜻하는 TemporalUnit ( ChronoUnit )과 시간의 각 필드를 뜻하는 TemporalField ( ChronoField )이다
- 이런 여러가지 단위가 있구나..
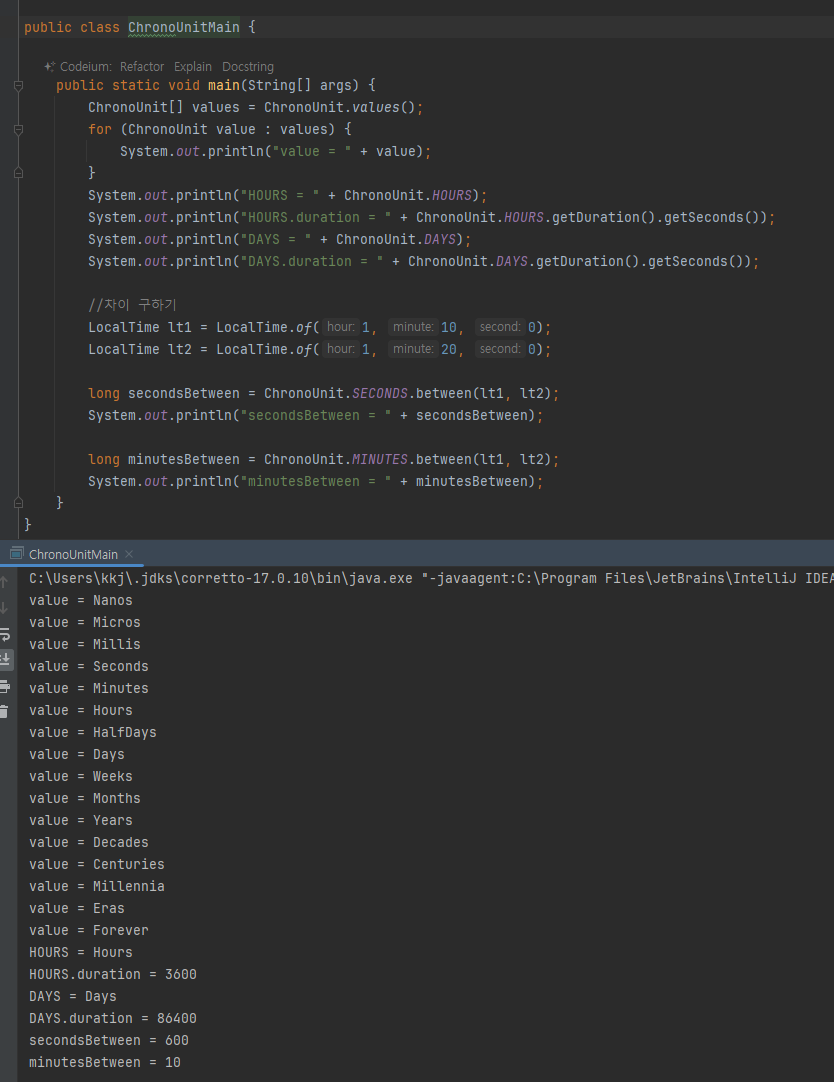
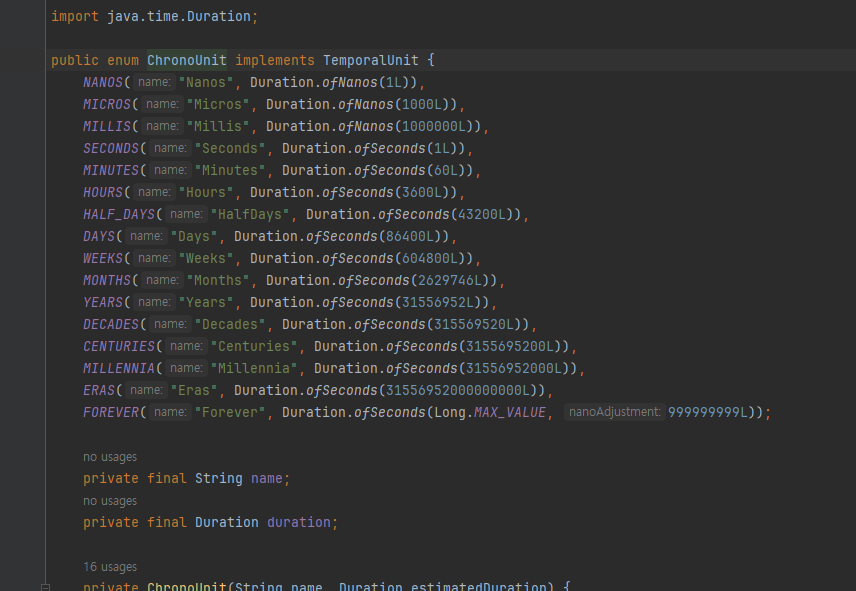
- ChronoUnit 을 사용하면 두 날짜 또는 시간 사이의 차이를 해당 단위로 쉽게 계산할 수 있다. 예제 코드에서는 두 LocalTime 객체 사이의 차이를 초, 분 단위로 구한다.
시간 필드 - ChronoField
- ChronoField 는 날짜 및 시간을 나타내는 데 사용되는 열거형이다. 이 열거형은 다양한 필드를 통해 날짜와 시간의
특정 부분을 나타낸다. 여기에는 연도, 월, 일, 시간, 분 등이 포함된다.
-
TemporalField 인터페이스는 날짜와 시간을 나타내는데 사용된다. 주로 사용되는 구현체는java.time.temporal.ChronoField 열거형으로 구현되어 있다
-
ChronoField 는 다양한 필드를 통해 날짜와 시간의 특정 부분을 나타낸다. 여기에는 연도, 월, 일, 시간, 분 등이 포함된다.
-
여기서 필드(Field)라는 뜻이 날짜와 시간 중에 있는 특정 필드들을 뜻한다. 각각의 필드 항목은 다음을 참고하자.
- 예를 들어 2024년 8월 16일이라고 하면 각각의 필드는 다음과 같다.
- YEAR : 2024
- MONTH_OF_YEAR : 8
- DAY_OF_MONTH : 16
-
단순히 시간의 단위 하나하나를 뜻하는 ChronoUnit 과는 다른 것을 알 수 있다. ChronoField 를 사용해야날짜와 시간의 각 필드 중에 원하는 데이터를 조회할 수 있다

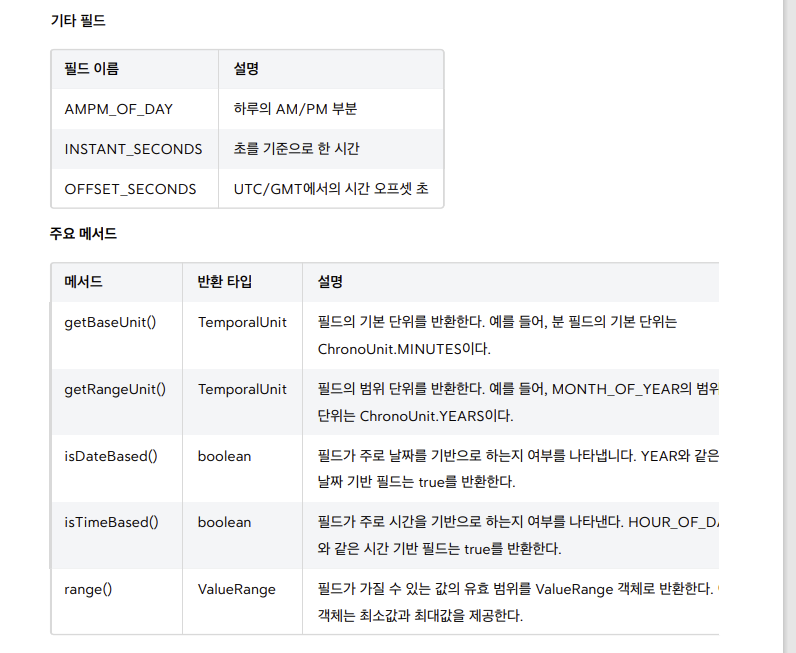
- TemporalUnit(ChronoUnit) , TemporalField(ChronoField) 는 단독으로 사용하기 보다는 주로 날짜와
시간을 조회하거나 조작할 때 사용한다. 다음 시간을 통해서 날짜와 시간을 조회하고 조작하는 방법을 알아보자.
날짜와 시간 조회하고 조작하기
-
날짜와 시간 조회하기
-
날짜와 시간을 조회하려면 날짜와 시간 항목중에 어떤 필드를 조회할 지 선택해야 한다. 이때 날짜와 시간의 필드를 뜻하는 ChronoField 가 사용된다.
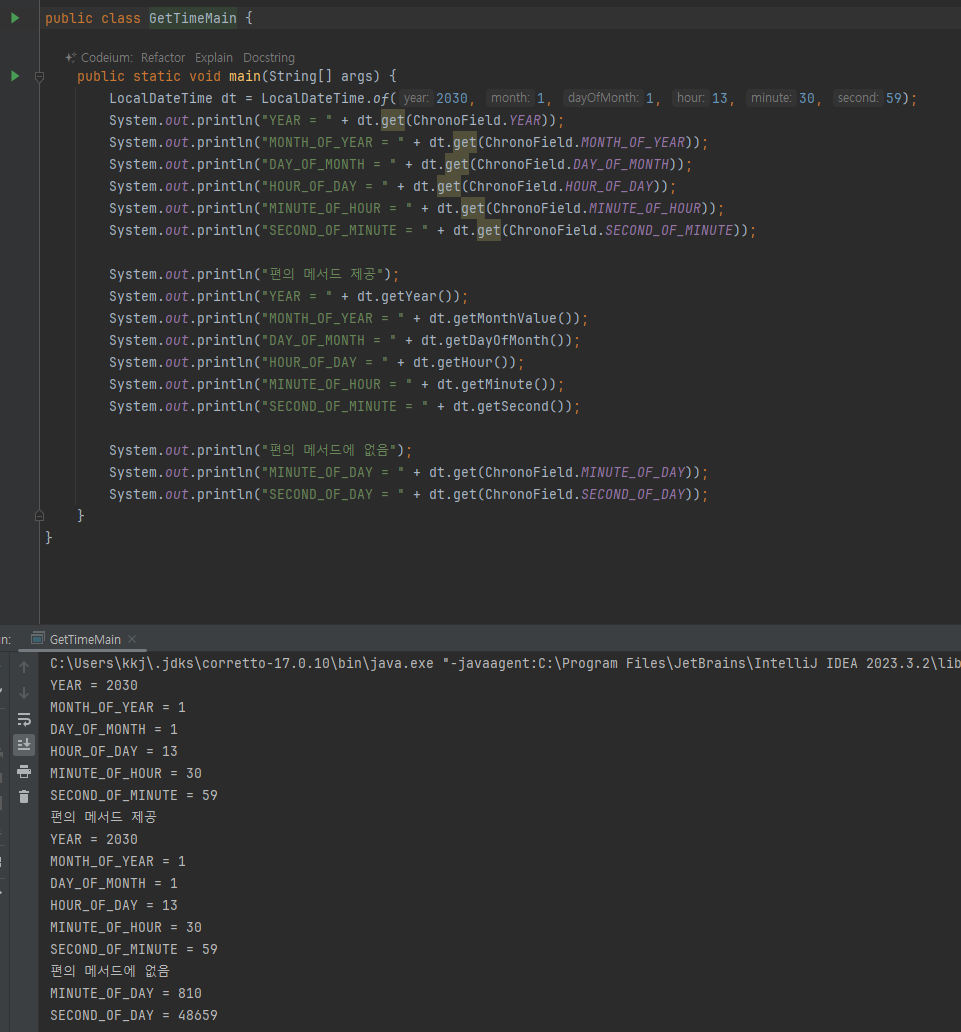
TemporalAccessor.get(TemporalField field)
-
LocalDateTime 을 포함한 특정 시점의 시간을 제공하는 클래스는 모두 TemporalAccessor 인터페이스를구현한다
-
TemporalAccessor 는 특정 시점의 시간을 조회하는 기능을 제공한다
-
get(TemporalField field) 을 호출할 때 어떤 날짜와 시간 필드를 조회할 지 TemporalField 의 구현인 ChronoField 를 인수로 전달하면 된다
편의 메서드 사용
- get(TemporalField field) 을 사용하면 코드가 길어지고 번거롭기 때문에 자주 사용하는 조회 필드는 간단한 편의 메서드를 제공한다
- dt.get(ChronoField.DAY_OF_MONTH)) dt.getDayOfMonth()
편의 메서드에 없음
- 자주 사용하지 않는 특별한 기능은 편의 메서드를 제공하지 않는다.
- 편의 메서드를 사용하는 것이 가독성이 좋기 때문에 일반적으로는 편의 메서드를 사용하고, 편의 메서드가 없는경우 get(TemporalField field) 을 사용하면 된다.
날짜와 시간 조작하기
- 날짜와 시간을 조작하려면 어떤 시간 단위(Unit)를 변경할 지 선택해야 한다. 이때 날짜와 시간의 단위를 뜻하는 ChronoUnit 이 사용된다
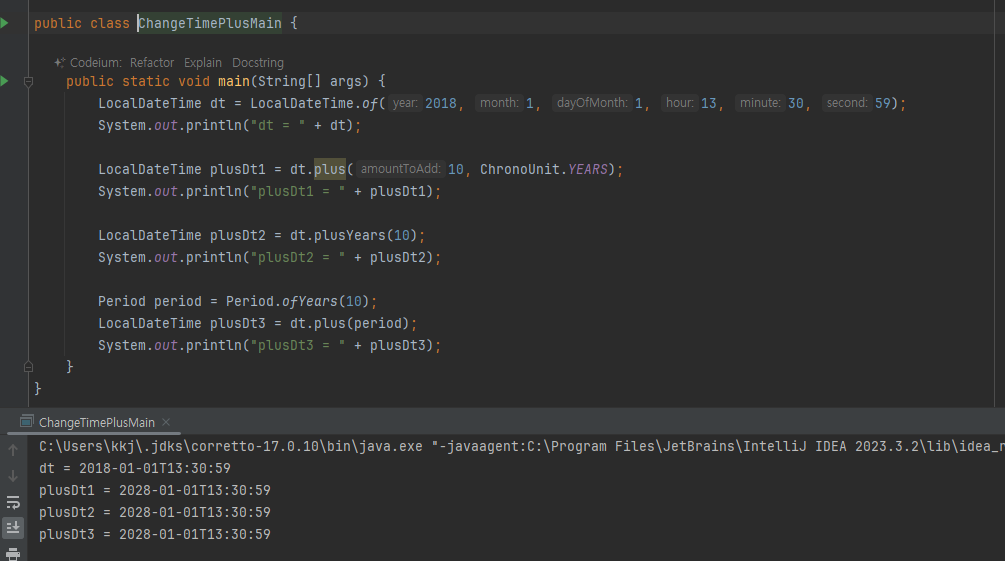
Temporal plus(long amountToAdd, TemporalUnit unit)
- LocalDateTime 을 포함한 특정 시점의 시간을 제공하는 클래스는 모두 Temporal 인터페이스를 구현한다.
- Temporal 은 특정 시점의 시간을 조작하는 기능을 제공한다.
- plus(long amountToAdd, TemporalUnit unit) 를 호출할 때 더하기 할 숫자와 시간의 단위(Unit)를
전달하면 된다. - 이때 TemporalUnit 의 구현인 ChronoUnit 을 인수로 전달하면 된다.
불변이므로 반환 값을 받아야 한다. - 참고로 minus() 도 존재한다.
편의 메서드 사용
- dt.plus(10, ChronoUnit.YEARS) dt.plusYears(10)
Period를 사용한 조작
- Period 나 Duration 은 기간(시간의 간격)을 뜻한다. 특정 시점의 시간에 기간을 더할 수 있다
정리
시간을 조회하고 조작하는 부분을 보면 TemporalAccessor.get() , Temporal.plus() 와 같은 인터페이스를
통해 특정 구현 클래스와 무관하게 아주 일관성 있는 시간 조회, 조작 기능을 제공하는 것을 확인할 수 있다.
덕분에 LocalDateTime , LocalDate , LocalTime , ZonedDateTime , Instant 와 같은 수 많은 구현에 관
계없이 일관성 있는 방법으로 시간을 조회하고 조작할 수 있다
-
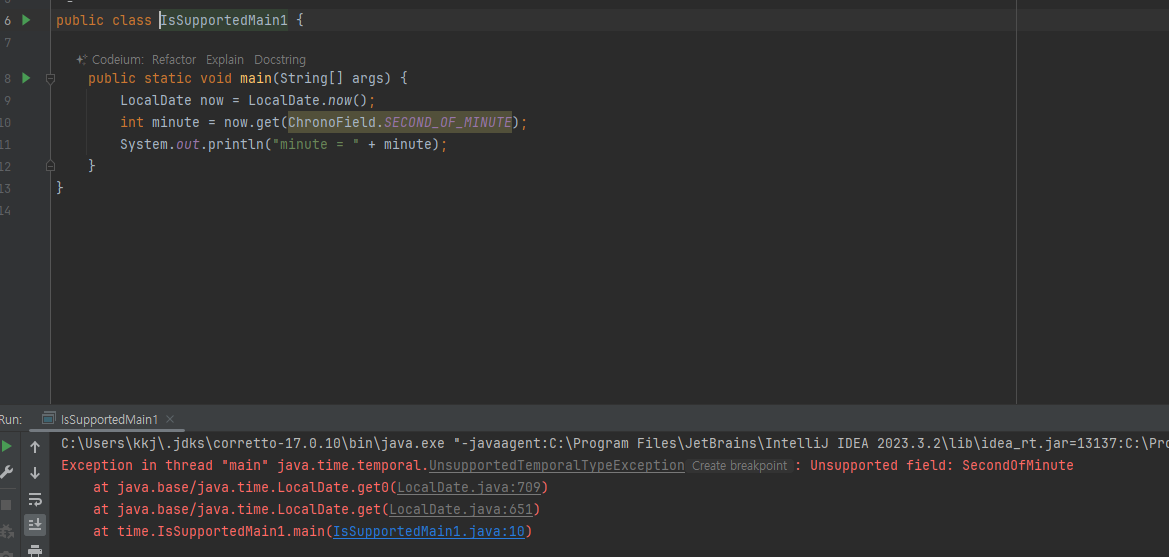
하지만 모든 시간 필드를 다 조회할 수 있는 것은 아니다.
-
LocalDate 는 날짜 정보만 가지고 있고, 분에 대한 정보는 없다. 따라서 분에 대한 정보를 조회하려고 하면 예외가 발생한다.
-
이런 문제를 예방하기 위해 TemporalAccessor 와 Temporal 인터페이스는 현재 타입에서 특정 시간 단위나 필드를 사용할 수 있는지 확인할 수 있는 메서드를 제공한다.
날짜와 시간 조회하고 조작하기2


등. 날짜 시간은 여기까지
중첩 클래스 내부 클래스 1
다음과 같이 for문 안에 for문을 중첩하는 것을 중첩(Nested) for문이라 한다.
for (...) {
//중첩 for문
for (...) {
}

-
클래스 안에 클래스 중첩 정의한게 중첩 클래스
-
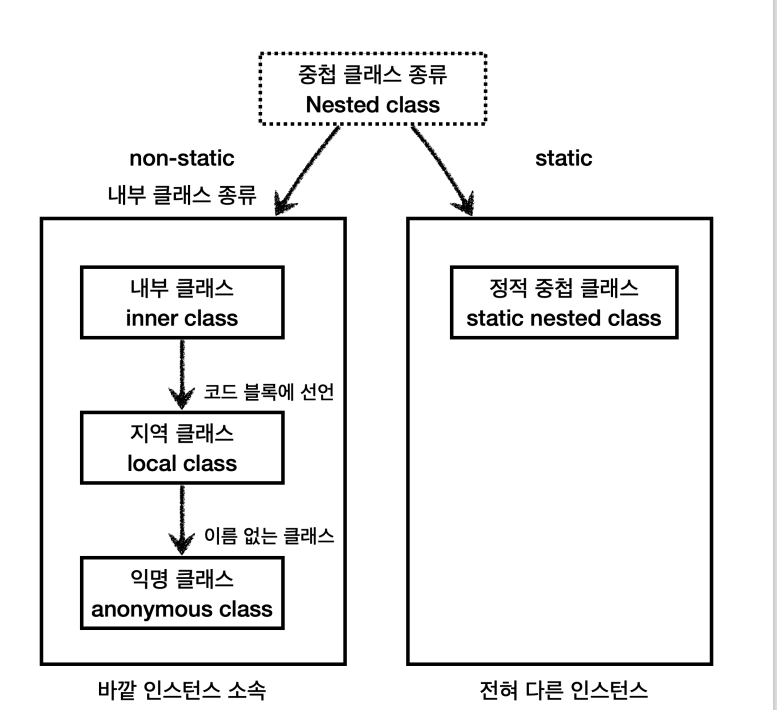
4가지 종류의 중첩클래스
-
크게는 2가지
-
정적 중첩 클래스
-
내부 클래스
- 내부 클래스
- 지역 클래스
- 익명 클래스
중첩 클래스 정의하는 위치는 변수의 선언 위치와 같다.
중첩 클래스의 선언 위치
-
정적 중첩 클래스 -> 정적 변수와 같은위치
-
내부 클래스-> 인스턴스변수와 같은위치
-
지역클래스 -> 지역 변수와 같은위치

-
정적 중첩 클래스는 정적 변수와 같이 static이 붙어있음
-
내부클래스는 인스턴스 변수와 같이 static이 붙어있지 않다.

- 지역 클래스는 지역 변수와 같이 코드 블럭안에 클래스 정의
- 참고로 익명 클래스는 지역 클래스의 특별한 버전
정적 중첩 클래스와 내부 클래스로 분류
- 위 설명 대로 크게 2개로 분류하는걸 확인할 수 있음
중첩이라는 단어와 내부 단어 차이?
-
중첩(Nested): 어떤 다른 것이 내부에 위치하거나 포함되는 구조적 관계
-
내부 (inner) 나의 내부에 있는 나를 구성하는 요소
-
정리하면 중첩은 나의 안에 있지만 내것이 아님. 단순한 위치만 안에 있음
-
내부는 나의 내부의 구성요소를 말함
-
ex) 큰 나무 상자안에 전혀 다른 작은 나무상자 넣은것이 중첩
-
나의 심장은 나의 내부에서 나를 구성하는 요소
-
다시 정리하면 중첩 클래스는 바깥 클래스 안에 있지만 바깥 클래스와 관계없는 전혀 다른 클래스
-
내부 클래스는 바깥 클래스의 내부에 있으면서 바깥 클래스 구성 요소
-
핵심은 바깥 클래스 입장에서 봐야된다.
-
나의 인스턴스에 소속되는지 여부를 확인해야되
-
정적 중첩 클래스는 바깥 클래스와 전혀다른 클래스 바깥 클래스 인스턴스 소속 X
-
내부 클래스는 바깥클래스의 구성요소 바깥 클래스 인스턴스에소속
정적 중첩클래스
- static이 붙고
- 바깥 클래스의 인스턴스에 소속되지않음
내부 클래스
- static이 붙지않고
- 바깥 클래스의 인스턴스에 소속
내부 클래스의 종류
- 내부클래스 : 바깥클래스의 인스턴스 멤버에 접근
- 지역클래스 : 내부클래스 특징 + 지역 변수에 접근
- 익명 클래스 : 지역클래스 특징 + 클래스의 이름이 없는 특별 클래스
용어 정리
- 중첩클래스 : 정적 중첩 클래스 + 내부클래스 종류 모두 포함
- 정적 중첩 클래스 / 내부 클래스 , 지역클래스 , 익명 클래스
중첩 클래스 언제사용?
- 내부 클래스를 포함한 모든 중첩 클래스는 특정 클래스가 다른 하나의 클래스 안에 사용되거나 둘이 아주 긴밀하게 연결되어 있는 특별한경우 사용
- 외부의 여러 클래스가 특정 중첩 클래스를 사용한다면 중첩 클래스로 만들면 안됨.
중첩클래스 사용 이유
-
논리적으로 그룹화 : 특정 클래스가 다른 하나의 클래스 안에서만 사용되는 경우
해당 클래스 안에 포함하는 것이 논리적으로 더 그룹화 됨. 패키지를 열었을때 다른곳에서 사용될 필요가 없는 중첩 클래스가 외부에 노출되지 않는 장점도 있다 -
캡슐화 : 중첩 클래스는 바깥 클래스의 private 멤버에 접근할 수 있다.
-
이렇게 둘은 긴밀하게 연결하고 불필요한 public 메서드를 제거할 수있다.
이부분은 말로이해하기 어렵기 때문에 예제를 통해. -
이 부분 설명을 적다보니 configuration? yml에 정의된 공통? 환경설정 변수를
-
사용할때 중첩 클래스를 사용해본적이있따. 여기에 설명대로 논리적 캡슐화가 이루어지는 느낌이다
-
이 때사용한건 내부클래스였다.
정적 중첩 클래스
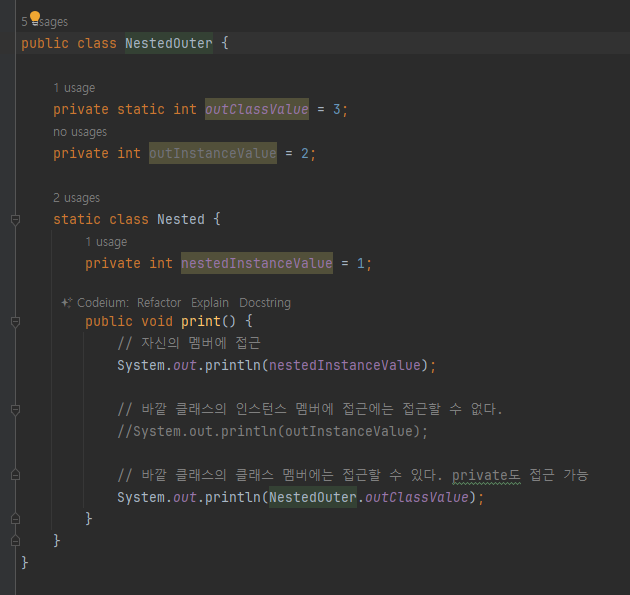
-
정적 중첩 클래스
- 자신의 멤버에는 당연히 접근 가능
- 바깥 클래스의 인스턴스 멤버 접근 X
- 바깥 클래스의 클래스 멤버에 접근할 수 있다.
private 접근 제어자
-
private 접근 제어자는 같은 클래스 안에 있을 때 접근 가능
-
중첩 클래스도 바깥 클래스와 같은 클래스 안에 있다. 따라서 중첩 클래스는 바깥 클래스의 private 접근 제어자에 접근할 수 있다.
-
같은 클래스 같은 클래스 안에 접근할 수 있다 중요
-
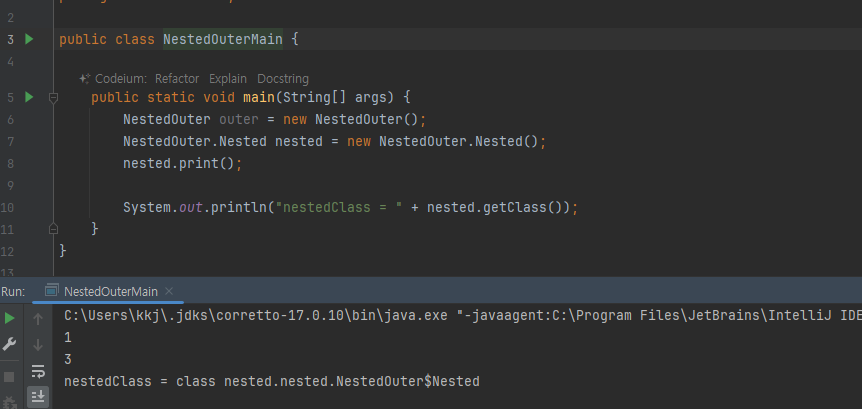
정적 중첩클래스는 new 바깥클래스.중접클래스()로 생성
-
여기서 new NestedOuter() 로 만든 바깥 클래스의 인스턴스와 new NestedOuter.Nested() 로 만든 정적 중첩 클래스의 인스턴스는 서로 아무 관계가 없는 인스턴스이다
-
단지 클래스 구조상 중첩
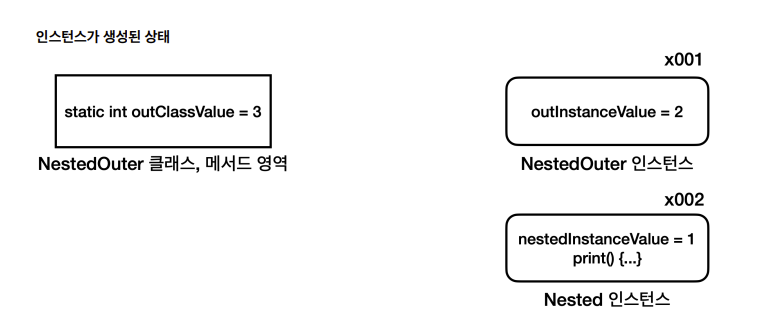
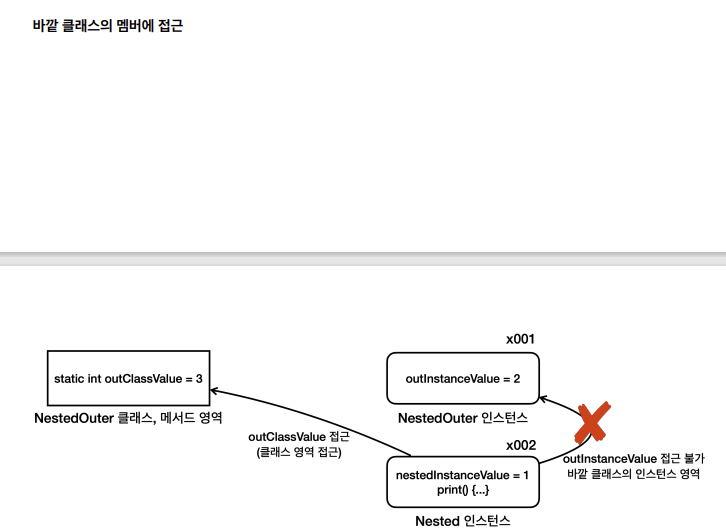
- 정적 중첩 클래스는 바깥 클래스의 인스턴스 필드에 접근 X
- 하지만 바깥 클래스가 만든 정적 필드에는 바로 접근 가능
- 바깥 인스턴스의 참조가 없기 때문이다.
정리
-
정적 중첩 클래스는 사실 다른 클래스를 그냥 중첩해 둔 것일 뿐이다! 쉽게 이야기해서 둘은 아무런 관계가 없다.
-
NestedOuter.outClassValue 와 같은 정적 필드에 접근하는 것은 중첩 클래스가 아니어도 어차피 클래스명.정적 필드명 으로 접근할 수 있다
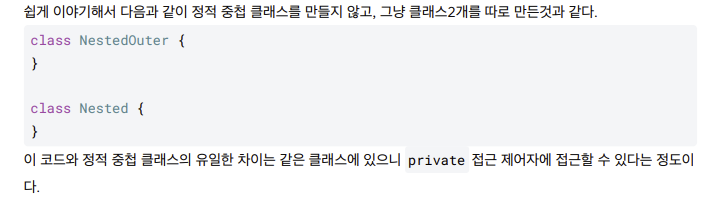
- 쉽게 이야기해 다음과 같이 정적 중첩 클래스 만들지않고 그냥 크래스 2개 따로 만든것과 같다
정적 중첩 클래스의 활용
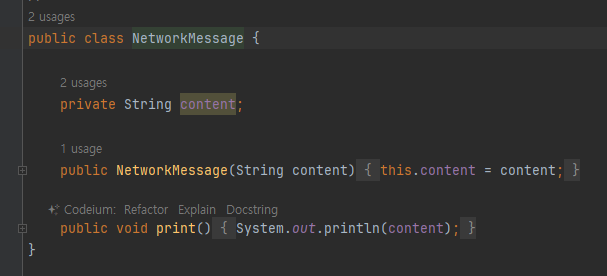
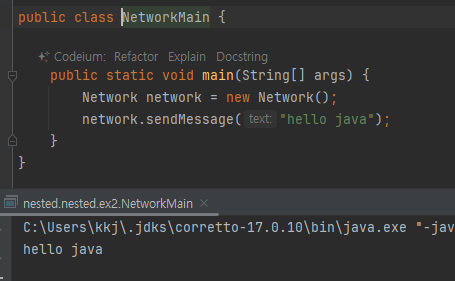
- NetworkMessage는 Network 객체 안에서만 사용되는 객체
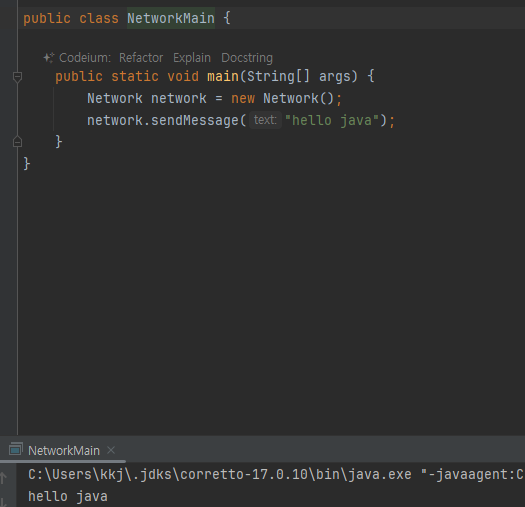
-
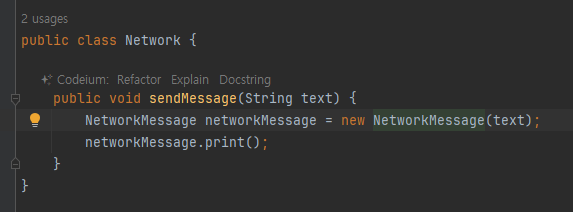
NetworkMain 은 오직 Network 클래스만 사용한다. NetworkMessage 클래스는 전혀 사용하지 않는다.
-
EX1 패키지는 두 클래스 가 보임 Network / NetworkMessage
Network 관련 라이브러리를 사용하기 위해서 ex1 패키지를 열어본 개발자는 아마도 두 클래스를 모두 확인해볼 것이다. 그리고 해당 패키지를 처음 확인한 개발자는 Network 와 NetworkMessage 를 둘다 사용해야 하나? 라고 생
각할 것이다. NetworkMessage 에 메시지를 담아서 Network 에 전달해야 하나?와 같은 여러가지 생각을 할 것이다.
아니면 NetworkMessage 가 다른 여러 클래스에서 사용되겠구나 라고 생각할 것이다.
두 클래스의 코드를 모두 확인하고 나서야 아~ Network 클래스만 사용하면 되는구나, NetworkMessage 는 단순히Network 안에서만 사용되는구나 라고 이해할 수 있다
리팩토링
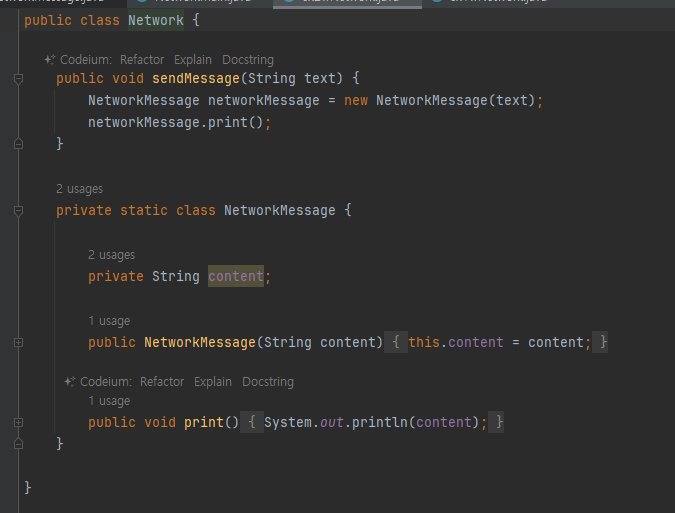
-
NetworkMessage 클래스를 Network 클래스 안에 중첩해서 만들었다.
-
NetworkMessage 의 접근 제어자를 private 설정했다. 따라서 외부에서 NetworkMessage 에 접근할 수 없다
-
ex2 패키지에는 이제 Network 밖에없음
-
NewWork 관련 라이브러리를 사용하기 위해 ex2 패키지를 열어본 개발자는
해당 클래스만 확인 추가로 NetworkMessage가 중첩 클래스에 private 접근 제어자
되어있는걸 보고 Network 내부에서만 단독으로 사용하는 클래스 인지
중접클래스 접근
- NestedOuter.Nested nested = new NestedOuter.Nested();
- 여기서는 private로 되어있어서 접근 불가능

내부 클래스
- 내부 클래스는 바깥 클래스의 인스턴스에 소속 됨.
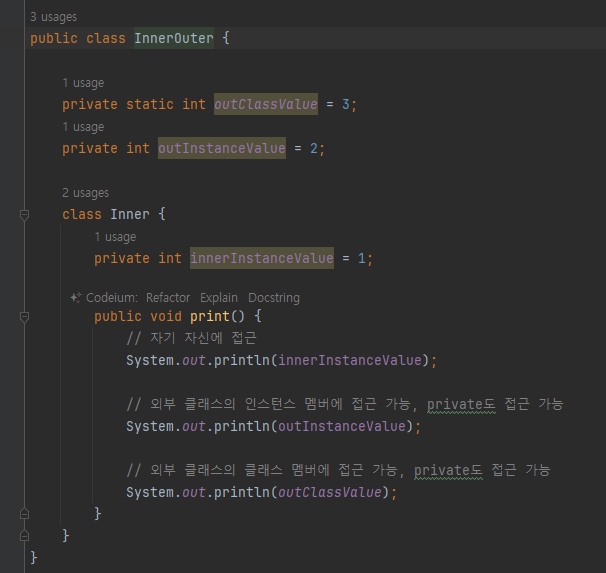
Private 접근제어자
-
private 접근 제어자는 같은 클래스 안에 있을 때만 접근할 수 있다.
-
내부 클래스도 바깥 클래스와 같은 클래스 안에 있다. 따라서 내부 클래스는 바 깥 클래스의 private 접근 제어자에 접근할 수 있다.
-
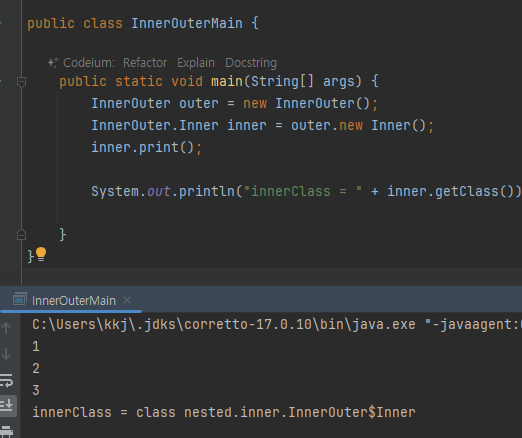
내부 클래스는 바깥 클래스의 인스턴스에 소속 / 바깥 클래스의 인스턴스 정보를 알아야 생성 가능
-
내부 클래스는 new 바깥클래스의 인스턴스 참조.내부클래스()로 생성
-
내부 클래스는 바깥클래스의 인스턴스에 소속되어야 하기때문에 바깥클래스의 인스턴스 참조가 필요
-
outer.new Inner()로 생성한 내부 클래스는 개념상 바깥 클래스의 인스턴스 참조 가짐
-
outer.new Inner() 로 생성한 내부 클래스는 개념상 바깥 클래스의 인스턴스 내부에 생성된다
-
따라서 바깥 클래스의 인스턴스를 먼저 생성해야 내부 클래스의 인스턴스 생성 가능
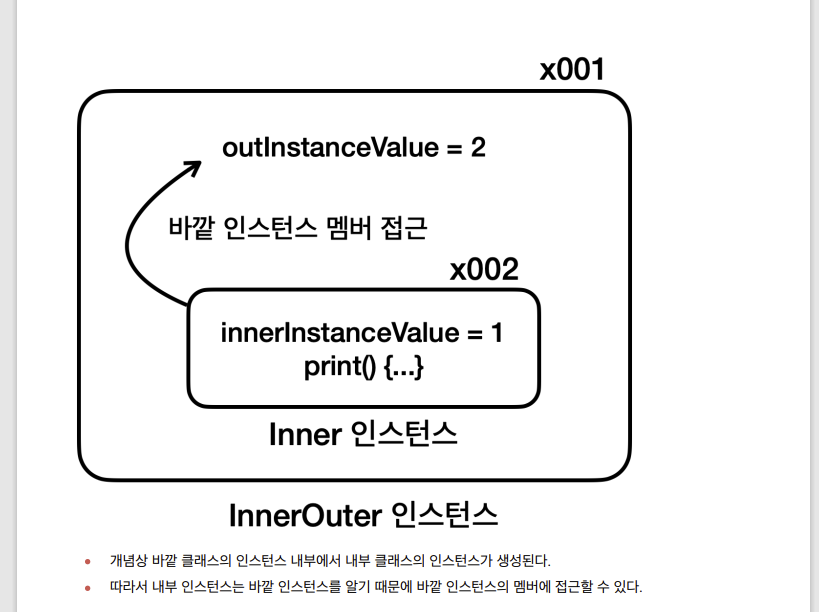
실제 내부 클래스 생성
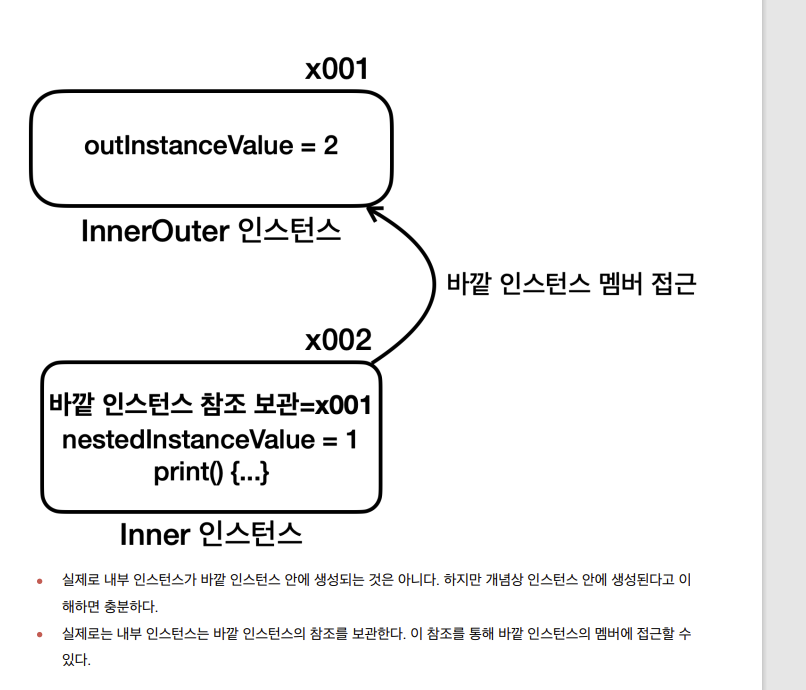
정리
- 정적 중첩 클래스와 다르게 내부 클래스는 바깥 인스턴스에 소속된다.
- 중첩 : 어떤 다른 것이 내부에 위치하거나 포함되는 구조적 관계
- 내부 : 나의 내부에 있는 나를 구성하는 요소
내부 클래스의 활용
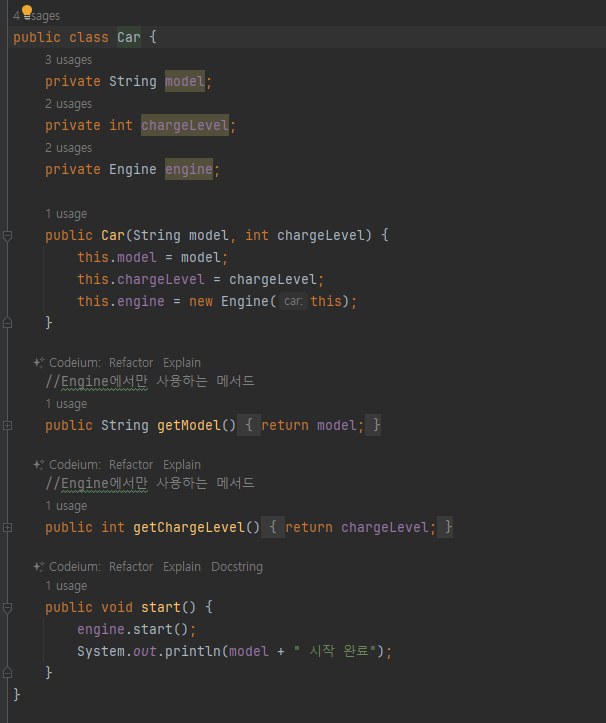
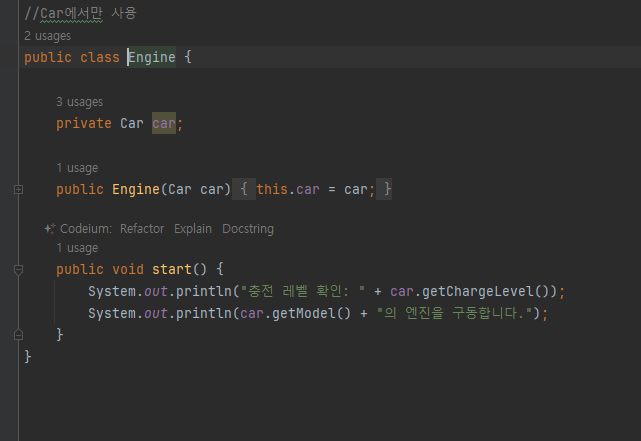
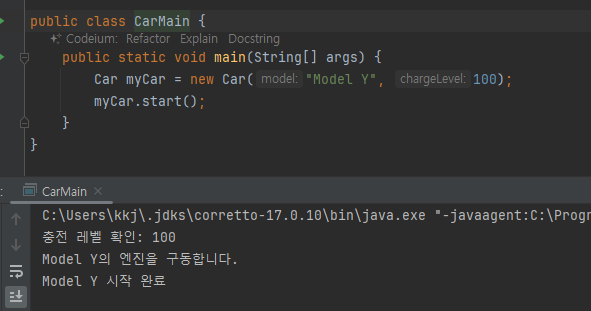
- Car 클래스는 엔진에 필요한 메서드를 제공해야 함
- 다음 메서드는 엔진에서만 사용하고 다른 곳에선 사용하지않는다
- getModel()_, getChargeLevel
- 결론적으로 Car 클래스는 엔진에서만 사용하는 기능을 위해 메서드를 추가해서 모델 이름과 충전 레벨을 외부에 노출해야 함
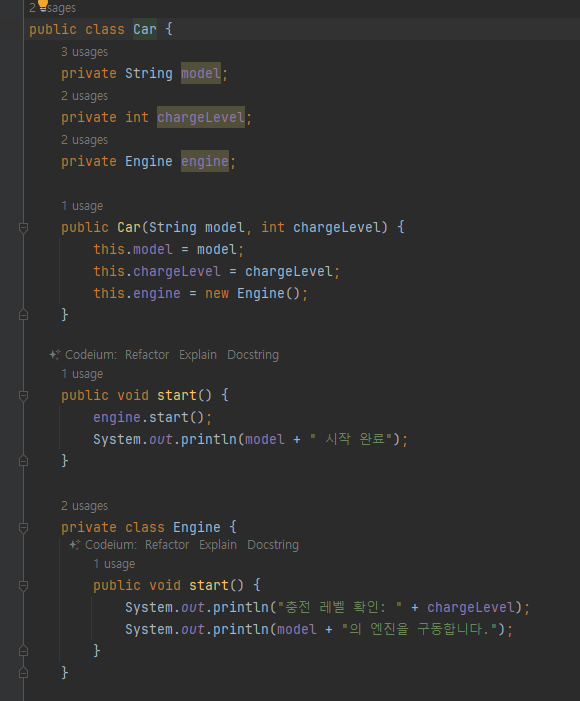
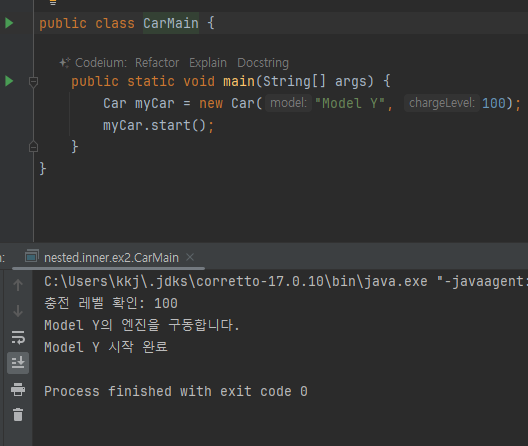
-
엔진을 내부 클래스로만듬.
-
car의 인스턴스 변수들을 다 접근 가능
-
바깥 클래스에서 내부 클래스의 인스턴스를 생성할 때는 바깥 클래스 이름을 생략할 수 있다.
-
ex) new Engin()
-
바깥 클래스에서 내부 클래스의 인스턴스를 생성할 때 내부 클래스의 인스턴스는 자신을 생성한 바깥 클래스의 인스턴스를 자동으로 참조함 new Engine() 로 생성된 Engine 인스턴스는 자신을 생성한 바깥의 Car 인스턴스를 자동으로 참조한다
리펙토링 전에 문제
- Car 클래스는 엔진에 필요한 메서드를 제공해야됨,
- getModel/getChareLevel 엔진에서만 사용하는 메서드
- 결과적으로 엔진에서만 사용하는 기능을 위해 메서드를 추가해서 모델 이름과 충전레벨을 외부에 노출해야 함
리팩토링 전에는 결과적으로 모델 이름과 충전 레벨을 외부에 노출했다. 이것은 불필요한 Car 클래스의 정보들이 추가
로 외부에 노출되는 것이기 때문에 캡슐화를 떨어뜨린다.
리팩토링 후에는 getModel() , getChargeLevel() 과 같은 메서드를 모두 제거했다. 결과적으로 꼭 필요한 메서
드만 외부에 노출함으로써 Car 의 캡슐화를 더 높일 수 있었다
중첩 클래스는 언제 사용해야 하나?
- 중첩 클래스는 특정 클래스가 다른 하나의 클래스안에서만 사용되거나,
둘이 아주 긴밀하게 연결되어 있는 특별한 경우에만 사용해야 함 - 외부 여러곳에서 특정 클래스 사용한다면 중첩 클래스로 사용하면 안됨
중첩 클래스 사용이유
-
논리적 그룹화 : 특정 클래스가 다른 하나의 클래스 안에서만 사용되는 경우 해당 클래스 안에 포함하는 것이 논리적으로 더 그룹화가 됨, 패키지를 열었을때 다른 곳에서 사용할 필요가 없는 중첩 클래스가 외부에 노출되지않는 장점도 있음
-
캡슐화 : 중첩 클래스는 바깥 클래스의 private 멤버에 접근할 수 있다 이렇게 해서 긴밀하게 연결하고 불필요한 public 메서드를 제거 가능
같은 이름의 바깥 변수 접근
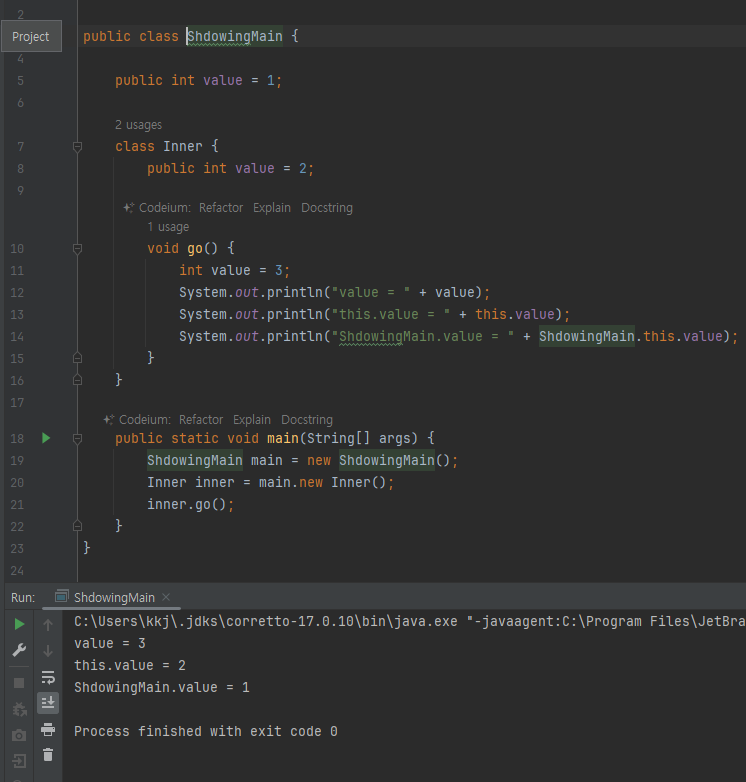
-
바깥 클래스의 인스턴스 변수와 내부 클래스의 인스턴스 변수가 같으면?
-
우선순위는 가깝거나 구체적인것이 우선관
-
여기선 가까운곳.
-
다른 변수들을 가려서 보이지 않게하는 것을 새도잉(Shadowing)이라 함.
중첩내부클래스 2
지역클래스 - 시작
- 내부 클래스의 특징을 그대로 가짐
- 지역 변수같은 느낌으로 생각하자
- 바깥 클래스이 인스턴스 멤버 접근 가능.
class Outer {
public void process() {
//지역 변수
int localVar = 0;
//지역 클래스
class Local {...}
Local local = new Local();
}
}-
클래스안에 지역변수처럼 선언함

-
지역 클래스는 지역 변수처럼 접근제어자 사용 못함
왜?
-
지역클래스의 범위는 지역클래스 메서드내에 정의되기때문에 해당 메서드 내에서만 유효 메서드 외부에서 지역클래스 접근 못함
-
따라서 접근제어자 의미가없다
-
접근 제어자의 목적: 접근 제어자는 클래스, 메서드, 변수 등의 접근 범위를 제어하기 위해 사용됨
-
따라서 하지만 지역 클래스는 이미 메서드 내부로 접근이 제한되어 있기 때문에 추가적인 접근 제어가 필요하지 않음
지역 클래스 예제2
-
내부 클래스를 포함한 중첩 클래스들도 일반 클래스처럼 인터페이스를 구현하거나, 부모 클래스를
상속할 수 있다
지역클래스 - 지역 변수 캡쳐 1
- 단순하게 지역 클래스가 접근하는 지역 변수의 값은 변경하면 안된다 이해하고 넘어가자


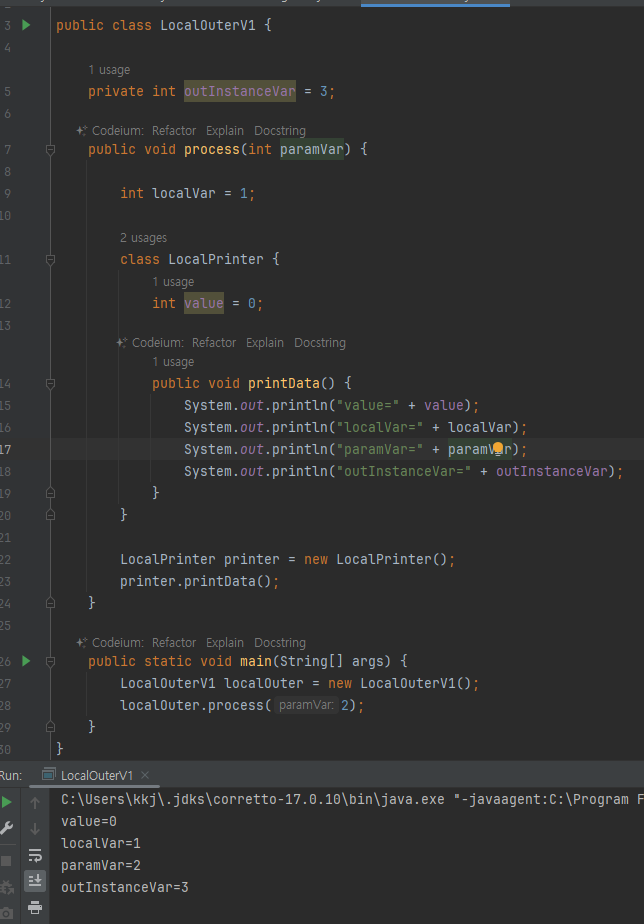
- main() 메서드에서 LocalPrinter 인스턴스 x002를 생성하고 print() 메서드를 호출
- 이때 LocalPrinter 인스턴스는 outInstanceVar 값으로 x001을 가지는 LocalOuter 인스턴스를 참조
- process() 메서드가 실행되면서 paramVar=2, localVar=1 값을 가지는 process() 프레임이 생성
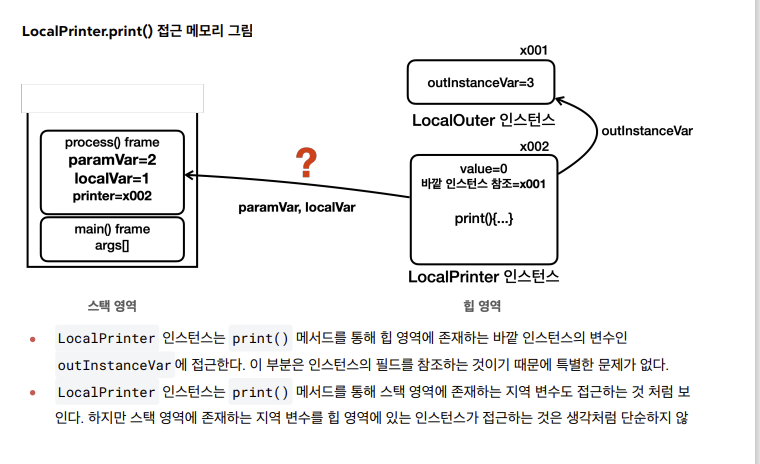
- LocalPrinter 인스턴스의 print() 메서드를 통해 LocalPrinter 인스턴스 내부의 outInstanceVar에 접근
- 이 outInstanceVar는 LocalOuter 인스턴스의 필드를 참조하는 것이기 때문에 값을 읽을 수 있다.
- 하지만 스택 영역에 존재하는 지역 변수들(paramVar, localVar)은 직접 접근이 불가능

- 지역 변수의 생명주기는 메서드 실행이 끝나면 사라지기에 GC 대상이 된다.
- 지역 변수인 paramVar와 localVar는 process() 메서드가 실행되면 동안에만 생존
- 하지만 로컬 프린터 인스턴스는 이러한 지역 변수의 paramVar, localVar에 접근해야 하는데, 이는 process() 메서드가 이미 종료되어으므로 해당 지역 변수들도 이미 제거된 상태이기에 접근이 불가능한 상황
- 이런 상황을 해결하기 위해서는 지역 변수의 값들을 로컬 클래스 내부에서 복사하여 저장해두어야만 메서드 종료 이후에도 계속 사용 가능함.
그런대 ? 결과는?

- 어떻게 제거된 지역 변수들에 접근할 수 있는 것일까?
- 더 정확히 이야기 하면 LocalPrinter.print() 메서드를 실행
하면 이 메서드도 당연히 스택 프레임에 올라가서 실행된다. main() 에서 print() 를 실행했으므로 main() 스택
프레임 위에 print() 스택 프레임이 올라간다. 물론 process() 스택 프레임은 이미 제거된 상태이므로 지역 변수
인 localVar , paramVar 도 함께 제거되어서 접근할 수 없다
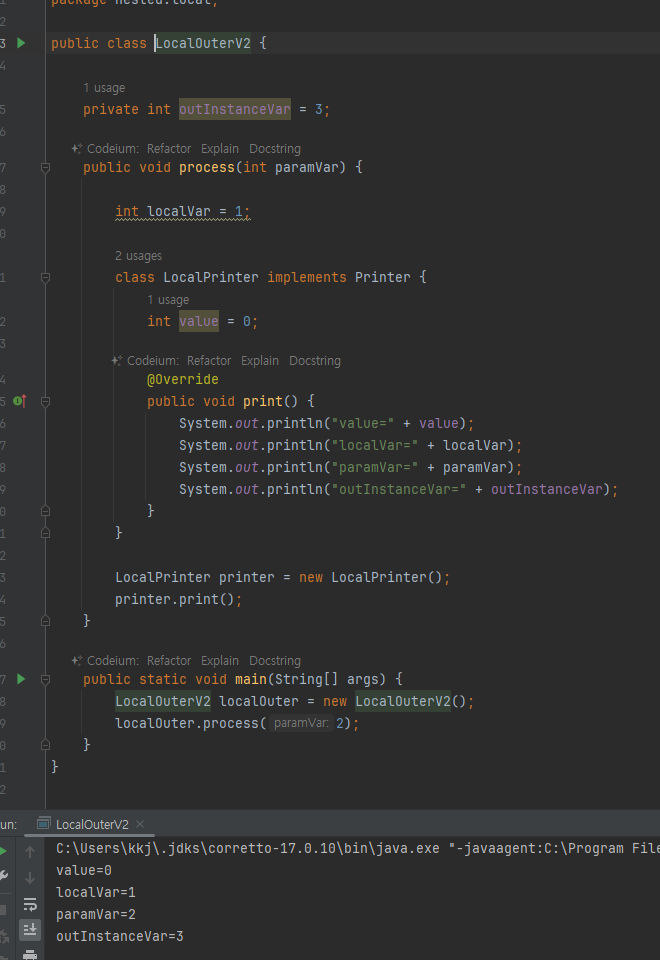
지역 클래스 - 지역 변수 캡처2
- 지역변수는 이미 지워졌는대 어떻게 값은 출력 될까?
지역 변수 캡처
- 자바는 이런 문제를 해결하기 위해 징겨 클래스의 인스턴스를 생성하는 시점에 필요한 지역 변수를 복사해서
- 생성한 인스턴스에 함께 넣어둠, 이런 과정을 변수 캡처 라 함.
- 인스턴스를 생성할때 필요한 지역 변수를 복샇래 보관해둠,
- 모든 지역 변수를 캡쳐하는 것이 아니라 접근이 필요한 지역변수만 캡쳐
징겨 클래스의 인스턴스 생성과 지역변수 캡쳐 과정

- process() 메서드가 실행되면서 paramVar=2, localVar=1, printer=x002 값을 가지는 process() 프레임이 생성
- 지역 변수 복사 단계에서는 paramVar=2와 localVar=1 값이 LocalPrinter 인스턴스의 필드로 복사
- 그리고 LocalPrinter 인스턴스는 생성되어 print() 메서드가 호출
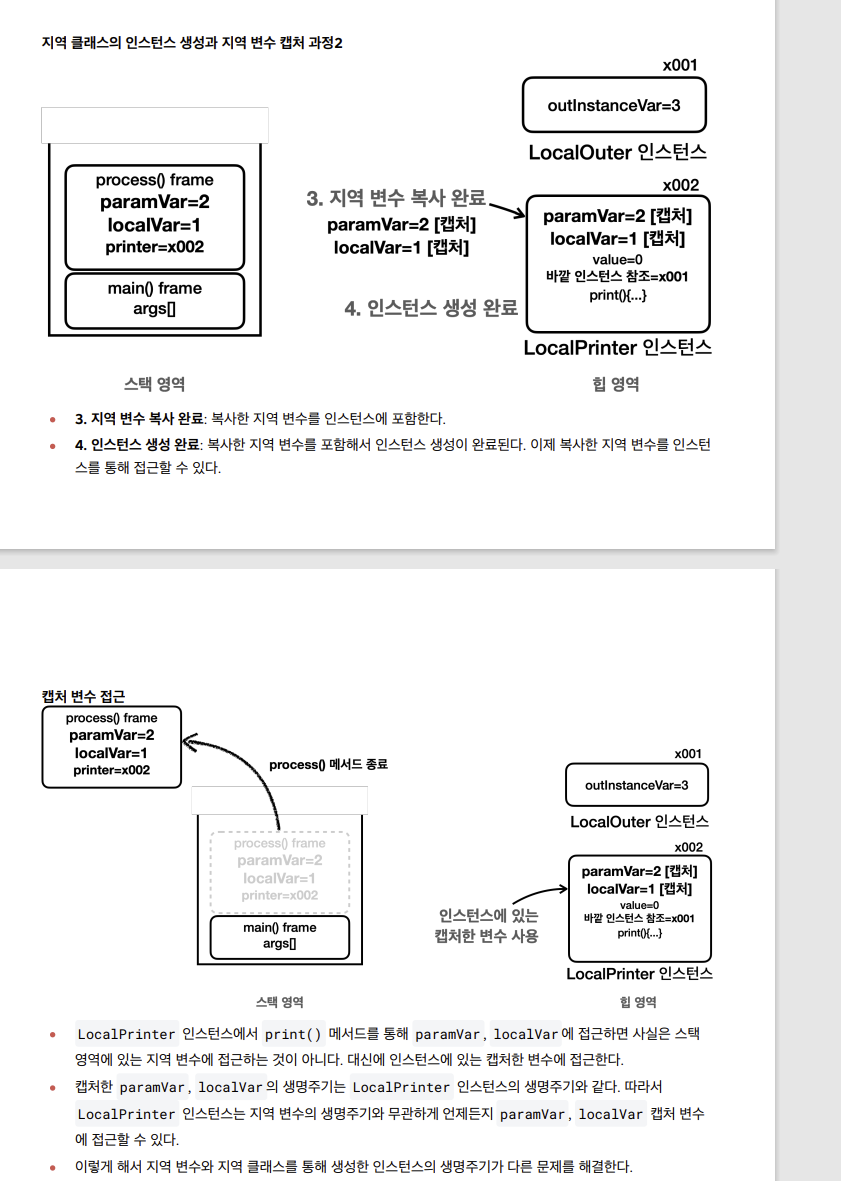
- LocalPrinter 인스턴스에서 print() 메서드를 통해 paramVar와 localVar에 접근
- 이때 지역 변수에 접근하는 것이 아니라, 대신에 인스턴스에 있는 캡처된 변수에 접근
- 결과적으로 LocalPrinter 인스턴스 내부의 복사된 paramVar와 localVar 값에 성공적으로 접근
- 이렇게 해서 지역 변수의 지역 클래스를 통해 생성한 인스턴스의 생명주기가 다른 문제를 해결

- 필드 확인
- 캡처변수 val$localVar 이런식으로 표현됨
- 지역 클래스는 인스턴스를 생성할 때 필요한 지역 변수를 먼저 캡처해서 인스턴스에 보관한다. 그리고 지역 클래스의 인
스턴스를 통해 지역 변수에 접근하면, 실제로는 지역 변수에 접근하는 것이 아니라 인스턴스에 있는 캡처한 캡처 변수에
접근한다
지역 클래스 -지역 변수 캡처 3
- 지역 클래스가 접근하는 지역변수는 절대로 중간에 값이 변하면 안된다.
- 따라서 final 로 선언하거나 또는 사실상 final 이어야 한다. 이것은 자바 문법이고 규칙이다
용어 - 사실상 final

-
영어로 effectively final이라 한다. 사실상 final 지역 변수는 지역 변수에 final 키워드를 사용하지는 않았지만,
값을 변경하지 않는 지역 변수를 뜻함 -
final 키워드를 넣지 않았을 뿐이지, 실제로는 final 키워드를 넣은 것 처
럼 중간에 값을 변경하지 않은 지역 변수이다. 따라서 사실상 final 지역 변수는 final 키워드를 넣어도 동일하게
작동해야 한다 -
지역 클래스가 접근하는 지역 변수는 왜 final 또는 사실상 final 이어야 할까? 왜 중간에 값이 변하면 안될까?
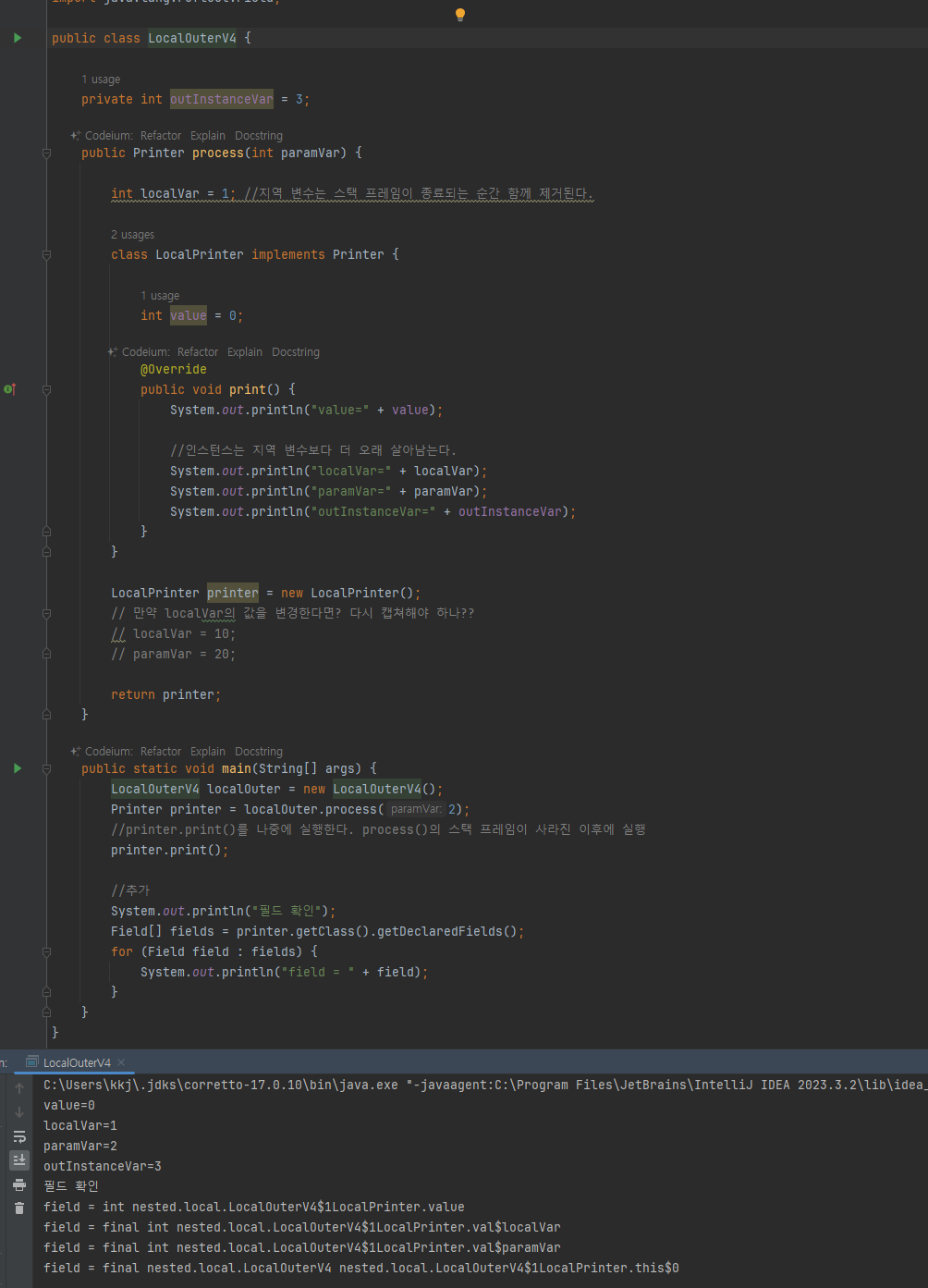

- Printer printer = new LocalPrinter();
- LocalPrinter를 생성하는 시점에 지역 변수인 localVar, paramVar를 캡처한다.
- 지역 변수 값을 변경 하면?
- 이렇게 되면 스택 영역에 존재하는 지역 변수의 값과 인스턴스에 캡처한 캡처 변수의 값이 서로 달라지는 문제가 발생한
다. 이것을 동기화 문제
- 물론 자바 언어를 설계할 때 지역 변수의 값이 변경되면 인스턴스에 캡처한 변수의 값도 함께 변경하도록 설계하면 된
다. 하지만 이로 인해 수 많은 문제들이 파생될 수 있음
캡처 변수의 값을 변경하지 못하는 이유
-
지역 변수의 값을 변경하면 인스턴스에 캡처한 변수의 값도 변경해야함
-
반대로 인스턴스에 있는 캡처 변수의 값을 변경하면 해당 지역 변수의 값도 다시 변경해야 됨
-
개발자 입장에서보면 사이드 이펙트 및 디버깅 어려움
-
지역 변수의 값과 인스턴스에 있는 ㅋㅂ처 변수의 값을 서로 동기화 해야하는데 멀티쓰레드 상황에선 이런 동기화는 매우 어렵고
-
성능에 나쁜ㅇ 영향을 줌.
-
근본적으로 변경하지못하게 막아 복잡한 문제 해결
익명 클래스 - 시작

- 내부클래스를 생성하기위해
- 선언 / 생성 두가지 단계를 거침
/선언
class LocalPrinter implements Printer{
//body
}
//생성
Printer printer = new LocalPrinter();
- 지역 클래스의 선언과 생성
익명 클래스 -지역 클래스의 선언 생성 한번에
- Printer printer = new Printer() {}
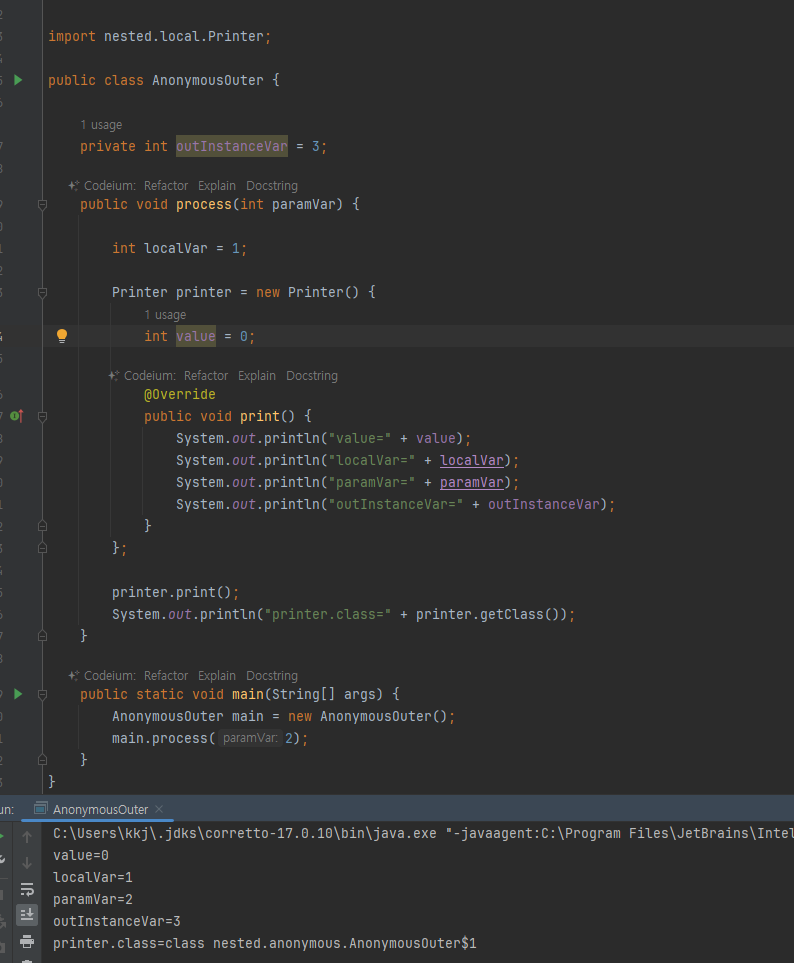
new Printer() {body}
- 본문을 정의하면서 동시의 생성
- new 다음에 바로 상속 받으면서 구현 부모 타입 입력하면됨
- Printer라는 이름의 인터페이스를 구현한 익명 클래스를 생성 하는 것
- 바디 부분은 구현 부분
- 정리하면 Printer를 상속(구현) 하면서 생성
익명 클래스 특징
- 익명 클래스는 이름 없는 지역 클래스를 선언 동시 생성
- 부모 클래스 상속 받거나 인터페이스를 구현해야함, (상위 클래스나 인터페이스가 필요함)
- 이름을 가지지않으므로 생성자 가질 수 없다 (기본 생성자만 사용됨)
- AnonymousOuter$1 과 같이 자바 내부에서 바깥 클래스 이름 + $ + 숫자로 정의된다. 익명 클
래스가 여러개면 $1 , $2 , $3 으로 숫자가 증가하면서 구분된다
장점
- 클래스 별도 정의하지않고 즉석 구현할수있어 코드 간결
- 복잡하거나 재사용 필요시 별도 클래스 정의하면 됨
사용못할 때

-
단 한번의 인스턴스만 생성가능하므로 여러번 생성시 사용 못하고 지역클래스 사용해야됨
-
지역 클래스가 일회성으로 사용되는 경우나 간단한 구현 제공시 사용
익명 클래스 활용

- 리펙토링 전
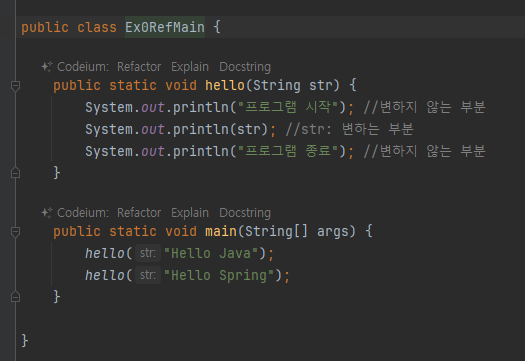
public static void hello() {
System.out.println("프로그램 시작"); //변하지 않는 부분
//변하는 부분 시작
System.out.println("Hello Java");
System.out.println("Hello Spring");
//변하는 부분 종료
System.out.println("프로그램 종료"); //변하지 않는 부분
}
- 핵심은 변하는 부분 변하지 안흔 부분 분리
활용 2
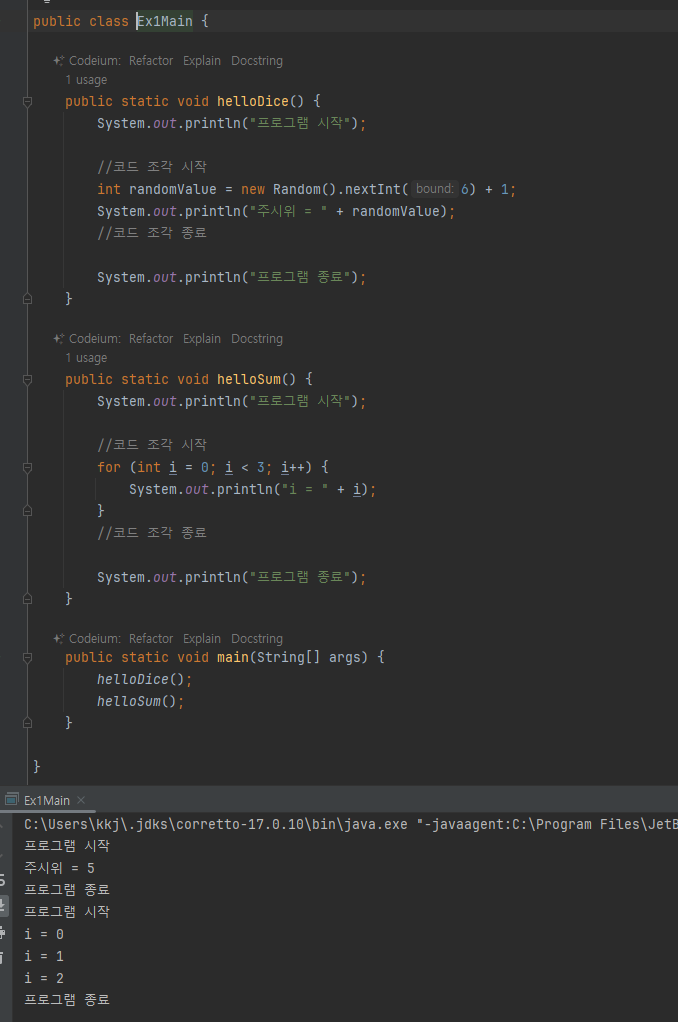


- 단순 스트링을 바꿔주는게아닌 코드조각을 전달을 어떻게할까?
- 코드 조각은 보통 메서드에서 정의, 따라서 코드 전달을 위해 메서드가 필요
- 그래서 인스턴스를 전달하고 인스턴스 메서드 호출
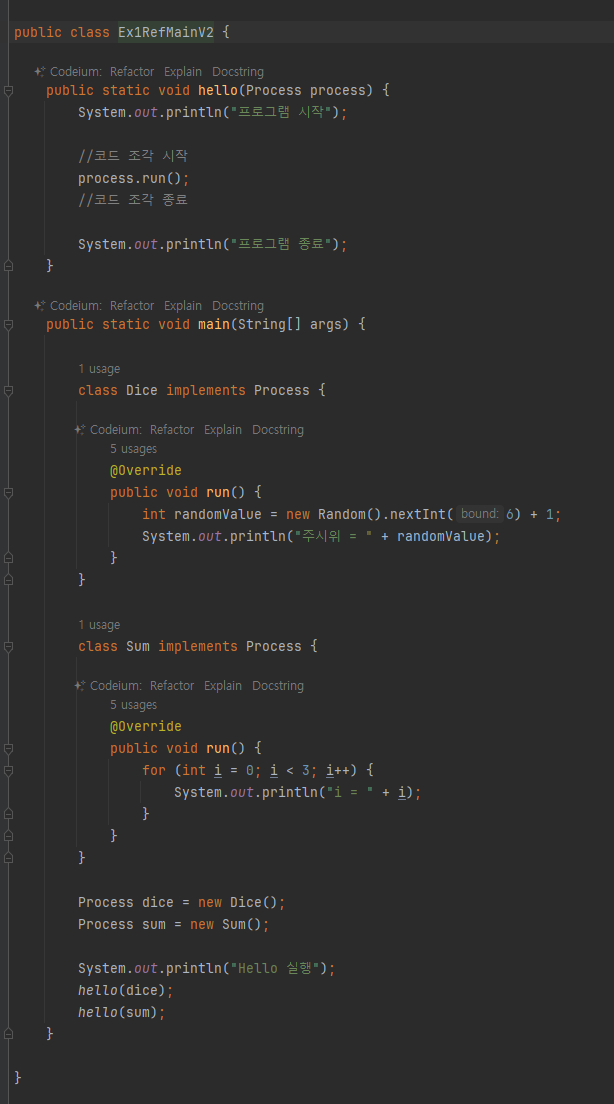
활용 3 (내부클래스)
활용 4 (익명클래스)

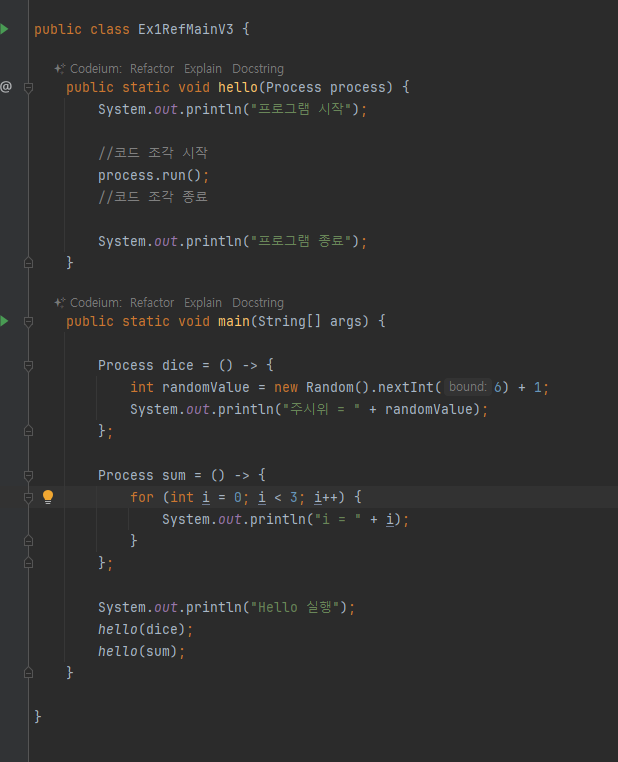
-
자바 8로 들어오면서 람다 코드도 추가함
-
() 함수 -> { 바디(구현체 시작 }
활용 5(참조값 직접전달)

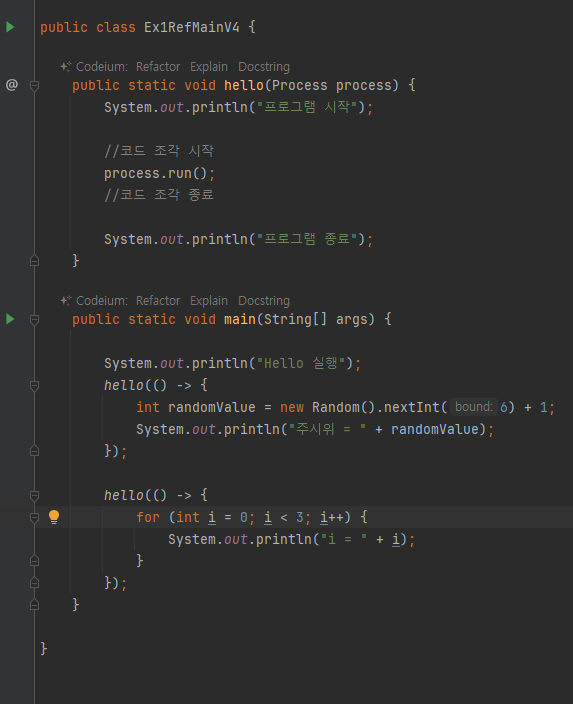
람다
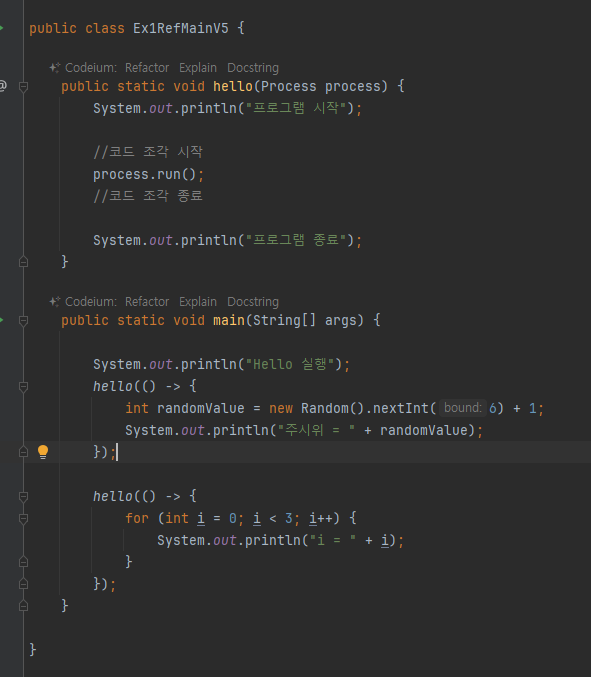
- 마지막 람다 전달
예외처리1 - 이론
예외 처리가 필요한 이유1
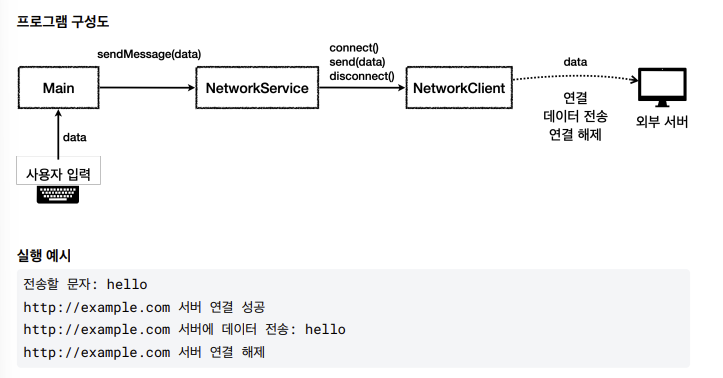
- 예외 처리가 필요한 이유를 알아보기 위해 간단한 프로그램 먼저 만들기
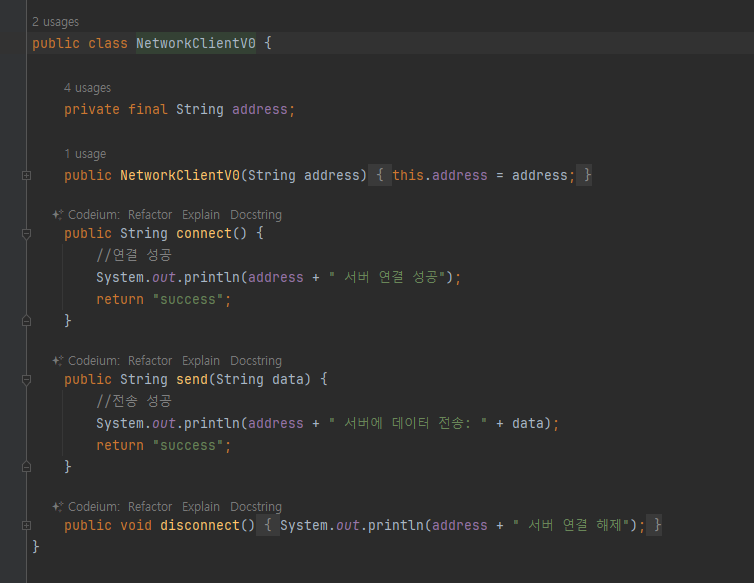

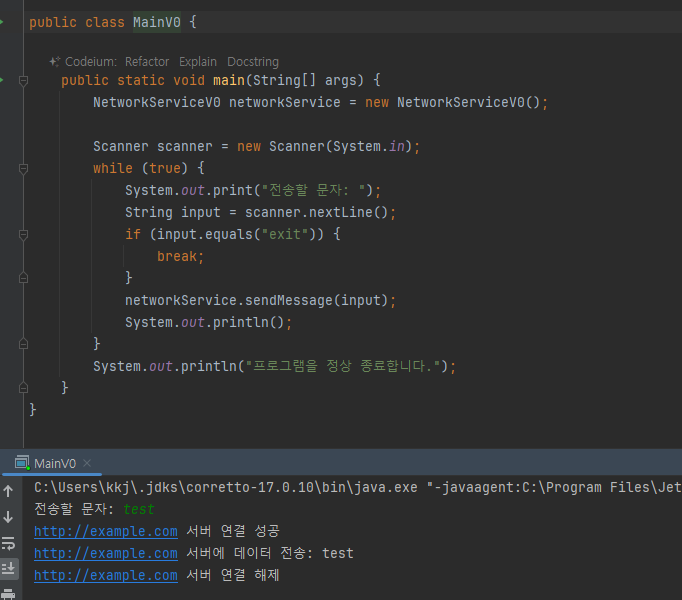
오류상황 만들기
- 외부 서버 통신시 다양한 문제 발생
- 연결 실패 / 데이터 전송 문제
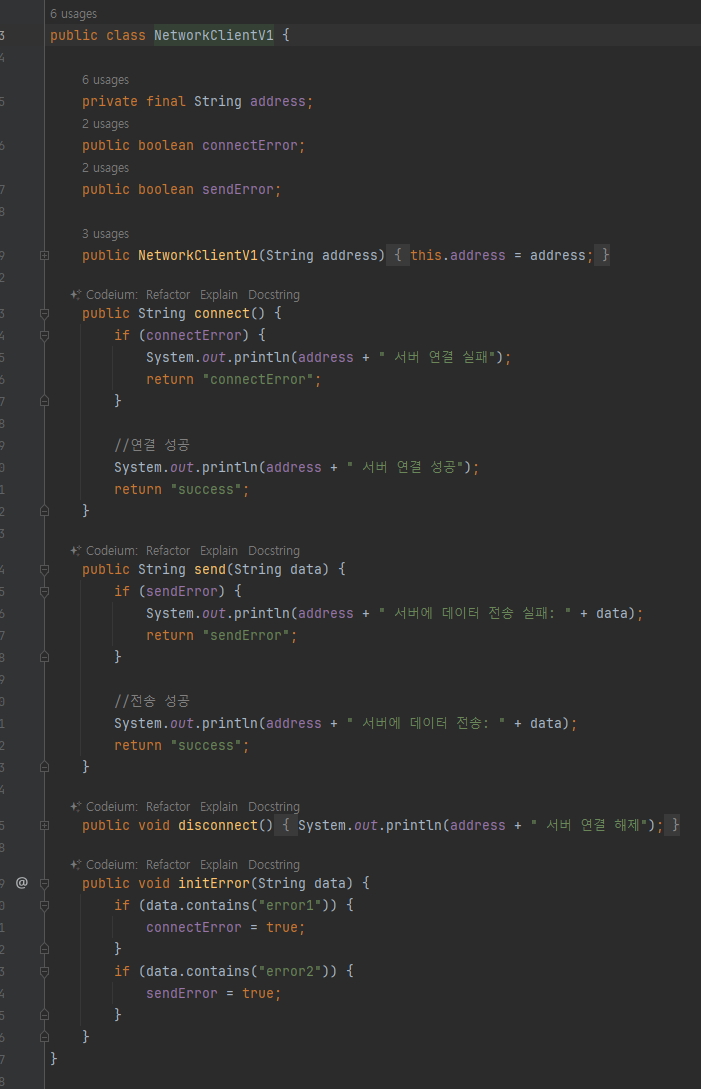


- 연결이 실패하면 데이터를 전송하지 않아야 하는데, 여기서는 데이터를 전송한다.
- 오류가 발생했을 때 어떤 오류가 발생했는지 자세한 내역을 남기면 이후 디버깅에 도움이 될 것이다. 오류 로그를 남겨야 한다
