
원문: https://marvinh.dev/blog/speeding-up-javascript-ecosystem/
📖 요약: 대부분의 인기 있는 라이브러리들은 불필요한 타입 변환을 피하거나 함수 내부에서 함수를 생성하지 않음으로써 속도를 높일 수 있습니다.
Rust나 Go와 같은 다른 언어로 모든 자바스크립트 빌드 도구를 다시 작성하는 추세이긴 하지만, 현재의 자바스크립트 기반 도구도 충분히 빠를 수 있습니다. 일반적인 프런트엔드 프로젝트의 빌드 파이프라인은 보통 함께 작동하는 여러 도구들로 이뤄져 있습니다. 그러나 도구가 다양화되며 도구의 메인테이너 입장에서는 어떤 도구와 주로 같이 사용되는지 알아야 하므로 성능 문제를 발견하기가 보다 어려워졌습니다.
순수하게 언어 관점에서 보면 자바스크립트는 확실히 Rust나 Go보다 느리지만, 현재의 자바스크립트 도구들은 상당히 개선될 여지가 있습니다. 물론 자바스크립트가 더 느리긴 하지만, 오늘날 비교하면 그렇게까지 느리지는 않을 겁니다. 요즘 JIT 엔진은 엄청나게 빠르거든요!
호기심에 이끌려 그 모든 시간이 어디에서 사용된 것인지 일반적인 자바스크립트 기반 도구들을 프로파일링 해보려 합니다. 매우 인기 있는 파서이자 CSS 트랜스파일러인 PostCSS부터 살펴봅시다.
PostCSS에서 4.6초 절약하기
오래된 브라우저에서 CSS 사용자 정의 프로퍼티에 대한 기본적인 지원을 추가하는 postcss-custom-properties라는 매우 유용한 플러그인이 있습니다. 어찌 된 일인지 내부적으로 사용되는 하나의 정규식으로 인한 4.6초의 큰 비용이 성능 추적 결과상에서 매우 두드러지게 나타났습니다. 이상해 보였습니다.
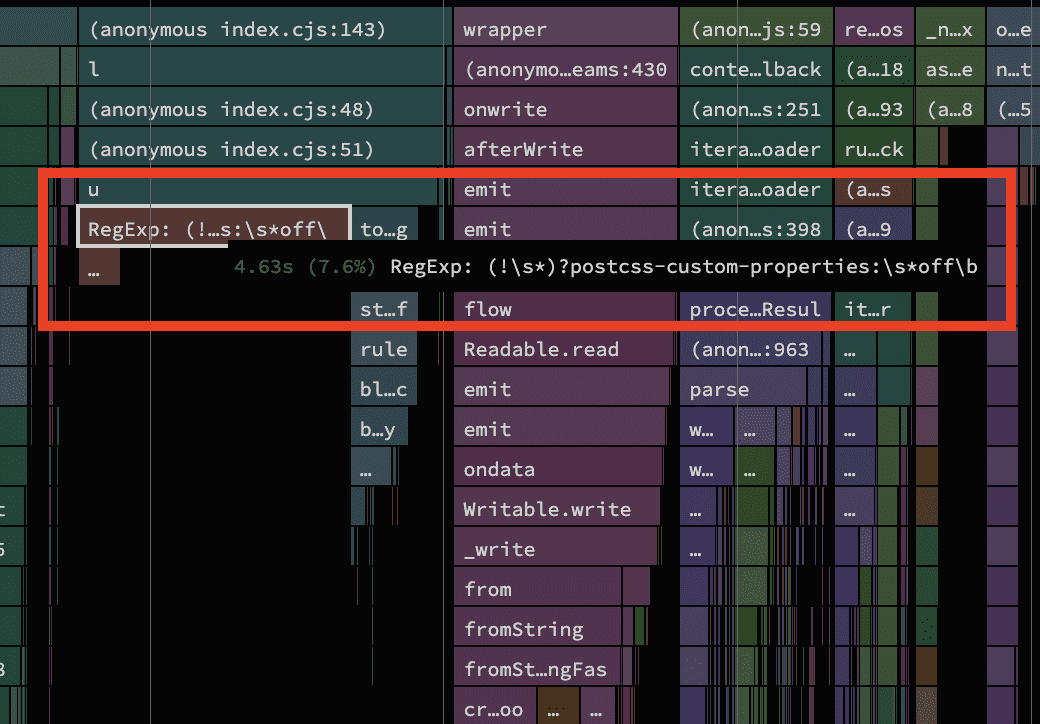
정규식은 eslint 에서 특정 린팅 규칙을 비활성 하는 것처럼 플러그인의 동작을 변경하기 위해 특정 주석 값을 찾는 것으로 보였습니다. README 에 언급되어 있지는 않았지만, 소스 코드를 살펴보니 앞서 짐작한 것을 확인할 수 있었습니다.
정규식은 CSS 규칙이나 선언이 해당 주석에 의해 선행되는지 확인하는 함수에서 생성되고 있었습니다.
function isBlockIgnored(ruleOrDeclaration) {
const rule = ruleOrDeclaration.selector ? ruleOrDeclaration : ruleOrDeclaration.parent;
return /(!\s*)?postcss-custom-properties:\s*off\b/i.test(rule.toString());
}rule.toString() 호출이 꽤 빠르게 눈에 띄었습니다. 한 타입이 다른 타입으로 변환되는 부분은 변환을 수행하지 않으면 항상 시간을 절약할 수 있기 때문에 성능 문제를 다루고 있는 경우 살펴볼 가치가 있습니다. 이 시나리오에서 흥미로운 점은 rule 변수가 항상 커스텀 toString 메서드를 갖는 object를 담는다는 것입니다. 애초에 문자열이 아니었기 때문에 정규식을 테스트하기 위해 항상 약간의 직렬화 비용을 지불하고 있다는 것을 알 수 있습니다. 경험상 많은 수의 짧은 문자열을 매칭하는 것이 몇 개의 긴 문자열을 매칭하는 것보다 훨씬 느립니다. 이는 최적화를 기다리는 주요 후보입니다!
이 코드에서 다소 문제가 되는 부분은 postcss 주석의 존재 여부와 관계없이 모든 입력 파일이 이 비용을 지불해야 한다는 것입니다. 긴 문자열에 대해 하나의 정규식을 실행하는 것이 짧은 문자열에 대해 반복해서 정규식을 실행하는 것과 직렬화 비용보다 저렴하다는 것을 알고 있으므로, 파일에 postcss 주석이 포함되지 않다는 것을 알고 있는 경우 isBlockIgnored를 호출조차 하지 않도록 함수를 가드 할 수 있습니다.
수정 사항이 적용되면서 빌드 시간이 무려 4.6초나 단축되었습니다.
SVG 압축 속도 최적화
다음으로 살펴볼 것은 SVG 파일을 압축하기 위한 라이브러리인 SVGO입니다. 꽤 멋지고 SVG 아이콘이 많은 프로젝트에 필수적입니다. CPU 프로파일에서 SVG 압축에 3.1초가 소비된 것으로 나타났습니다. 속도를 더 높일 수 있을까요?
프로파일링 데이터를 통해 살펴보았을 때 strongRound라는 함수가 눈에 띄었습니다. 이 함수 직후에는 항상 약간의 GC 클린업이 뒤따랐습니다.(작은 빨간 박스 참조)
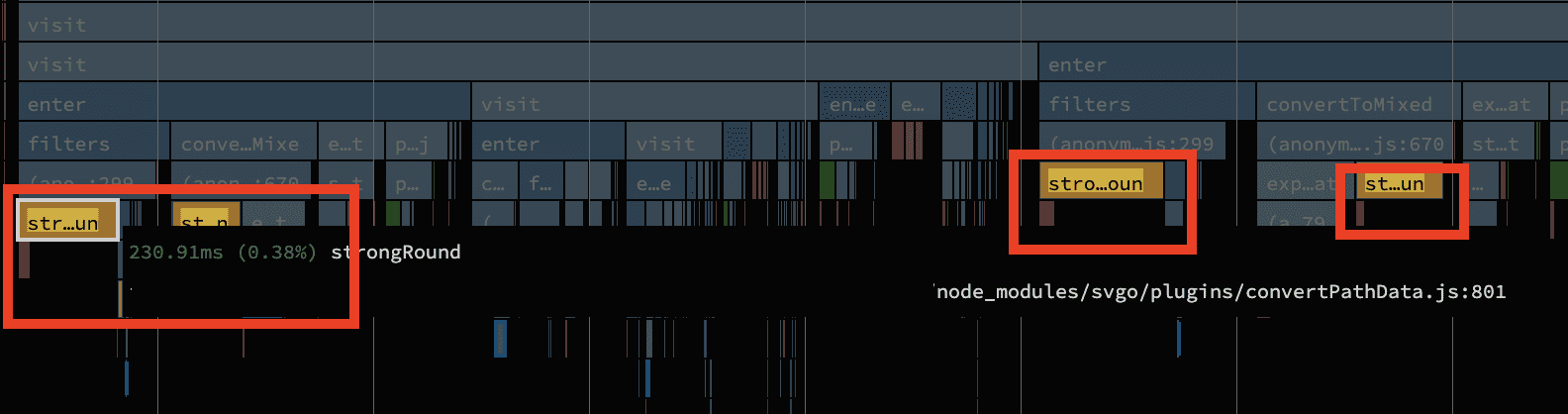
이는 제 호기심을 자극했습니다! Github에서 소스를 가져와봅시다.
/**
* 데이터의 지정된 소수점 자릿수로 유지하는 과정에서 부동 소수점 숫자의 정확도를 감소시킵니다.
* 2.3491를 반올림한 값은 2.349가 아닌 2.35가 됩니다.
*/
function strongRound(data: number[]) {
for (var i = data.length; i-- > 0; ) {
if (data[i].toFixed(precision) != data[i]) {
var rounded = +data[i].toFixed(precision - 1);
data[i] =
+Math.abs(rounded - data[i]).toFixed(precision + 1) >= error
? +data[i].toFixed(precision)
: rounded;
}
}
return data;
}아하, 일반적인 SVG 파일에 많이 있는 숫자를 압축할 때 사용하는 함수군요. 이 함수는 number 배열을 받고 배열의 요소들을 변경할 것으로 예상됩니다. 구현에 사용되는 변수 타입을 살펴보겠습니다. 조금 더 자세히 살펴보면 문자열과 숫자 간 변환이 양방향으로 많이 존재함을 알 수 있습니다.
function strongRound(data: number[]) {
for (var i = data.length; i-- > 0; ) {
// string과 number를 비교 -> string이 number로 변환됨
if (data[i].toFixed(precision) != data[i]) {
// number로부터 string을 생성하고 즉시 number로 다시 변환
var rounded = +data[i].toFixed(precision - 1);
data[i] =
// 또 string으로 변환되고 즉시 number로 다시 변환되는 다른 number
+Math.abs(rounded - data[i]).toFixed(precision + 1) >= error
? // 이전 if문 조건에 사용된 값과 동일하지만, 또다시 number로 변환됨
+data[i].toFixed(precision)
: rounded;
}
}
return data;
}숫자를 반올림하는 작업은 숫자를 문자열로 변환하지 않고 약간의 수학만으로도 수행할 수 있는 작업으로 보입니다. 일반적으로 최적화할 때는 숫자로 표현하는 것이 좋은데, 주된 이유는 CPU가 숫자를 다루는데 매우 뛰어나기 때문입니다. 약간의 변경으로 항상 숫자로 유지되게 해 문자열로 변환하는 것을 완전히 피할 수 있습니다.
// `Number.prototype.toFixed`과 동일하지만 반환 값을 문자열로 변환하지 않습니다.
function toFixed(num, precision) {
const pow = 10 ** precision;
return Math.round(num * pow) / pow;
}
// 모든 문자열 변환을 제거하고 대신 자체 `toFixed()` 함수를 호출하도록 재작성되었습니다.
function strongRound(data: number[]) {
for (let i = data.length; i-- > 0; ) {
const fixed = toFixed(data[i], precision);
// 보세요, 이제 엄격한 동등 비교를 사용할 수 있습니다!
if (fixed !== data[i]) {
const rounded = toFixed(data[i], precision - 1);
data[i] =
toFixed(Math.abs(rounded - data[i]), precision + 1) >= error
? fixed // 이제 여기서 이전 값을 재사용할 수 있습니다.
: rounded;
}
}
return data;
}프로파일링을 다시 실행해 빌드 시간을 약 1.4초 단축할 수 있음을 확인했습니다! 이에 대한 PR을 등록했습니다.
짧은 문자열에 대한 정규식 (파트 2)
strongRound 부근의 또 다른 함수는 완료하는 데 거의 1초(0.9초)가 걸려 의심스러워 보였습니다.
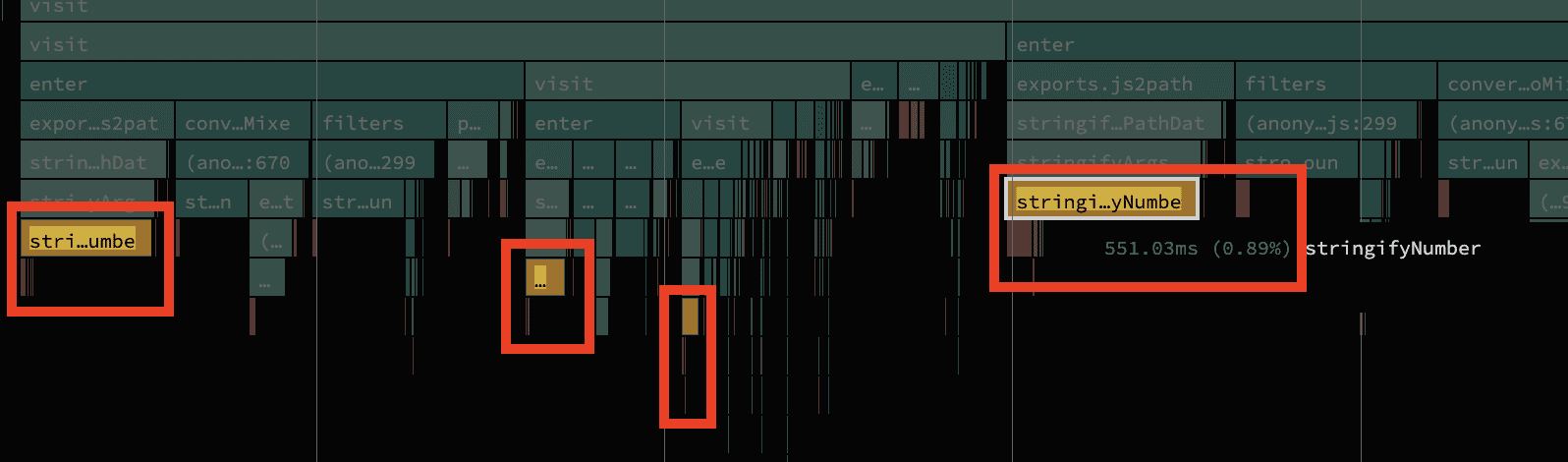
stringRound와 마찬가지로 이 함수도 숫자를 압축하지만, 숫자에 소수점이 있고 1보다 작고 -1보다 큰 경우 맨 앞의 0을 제거하는 트릭이 추가되었습니다. 따라서 0.5는 .5로 -0.2는 -.2로 각각 압축될 수 있습니다. 특히 마지막줄이 흥미로워 보입니다.
const stringifyNumber = (number: number, precision: number) => {
// ...생략
// 소수에서 0을 제거
return number.toString().replace(/^0\./, '.').replace(/^-0\./, '-.');
};여기서는 숫자를 문자열로 변환하고 정규식을 호출합니다. 숫자의 문자열 버전은 짧은 문자열일 가능성이 매우 큽니다. 그리고 우리는 숫자가 n > 0 && n < 1과 n > -1 && < 0을 동시에 만족시킬 수 없다는 것을 알고 있습니다. NaN 조차도 그런 힘을 갖고 있지 않습니다! 이를 통해 우리는 정규식 중 하나만 일치하거나 일치하지 않거나 둘 다 일치하지 않는다는 것을 추론할 수 있습니다. .replace 호출 중 적어도 하나는 항상 낭비됩니다.
각각의 경우를 직접 구분함으로써 이를 최적화할 수 있습니다. 0이 맨 앞에 존재하는 숫자를 처리하는 경우에만 교체 로직을 적용해야 합니다. 이러한 숫자 확인은 정규식 탐색을 수행하는 것보다 빠릅니다.
const stringifyNumber = (number: number, precision: number) => {
// ...생략
// 소수에서 0을 제거
const strNum = number.toString();
// 간단한 숫자 확인 사용
if (0 < num && num < 1) {
return strNum.replace(/^0\./, '.');
} else if (-1 < num && num < 0) {
return strNum.replace(/^-0\./, '-.');
}
return strNum;
};한 단계 더 나아가 문자열의 맨 앞에 0이 있는 것이 100% 확실하므로 정규식 탐색을 완전히 제거하고 문자열을 직접 조작할 수 있습니다.
const stringifyNumber = (number: number, precision: number) => {
// ...생략
// 소수에서 0을 제거
const strNum = number.toString();
if (0 < num && num < 1) {
// 일반 문자열 처리만 필요합니다.
return strNum.slice(1);
} else if (-1 < num && num < 0) {
// 일반 문자열 처리만 필요합니다.
return '-' + strNum.slice(2);
}
return strNum;
};이미 svgo의 코드 베이스에 맨 앞의 0을 트리밍 하는 별도의 함수가 존재하므로 이를 대신 활용할 수 있습니다. 또 다른 0.9초가 절약됐습니다! 업스트림 PR
인라인 함수, 인라인 캐시 및 재귀
monkeys라는 함수는 이름만으로도 흥미를 끌었습니다. 성능 추적에서 저는 그것이 내부에서 여러 번 호출되었음을 볼 수 있었고, 이건 여기서 일종의 재귀가 일어나고 있다는 강력한 지표입니다. 이는 트리와 같은 구조를 탐색하는 데 흔히 사용됩니다. 보통 어떤 탐색이 사용되면, 그 부분이 코드의 "핫" 패스가 될 가능성이 큽니다. 모든 시나리오에 해당되는 것은 아니지만 제 경험상 좋은 경험법칙입니다.
function perItem(data, info, plugin, params, reverse) {
function monkeys(items) {
items.children = items.children.filter(function (item) {
// reverse pass
if (reverse && item.children) {
monkeys(item);
}
// main filter
let kept = true;
if (plugin.active) {
kept = plugin.fn(item, params, info) !== false;
}
// direct pass
if (!reverse && item.children) {
monkeys(item);
}
return kept;
});
return items;
}
return monkeys(data);
}여기에는 내부 함수를 다시 호출하는 또 다른 함수를 생성하는 함수가 있습니다. 추측하건대 모든 인자를 다시 전달하지 않고 일부 키 입력을 저장하기 위한 것 같습니다. 문제는 외부 함수를 자주 호출할 때 내부에서 생성되는 함수는 최적화하기가 상당히 어렵다는 것입니다.
function perItem(items, info, plugin, params, reverse) {
items.children = items.children.filter(function (item) {
// reverse pass
if (reverse && item.children) {
perItem(item, info, plugin, params, reverse);
}
// main filter
let kept = true;
if (plugin.active) {
kept = plugin.fn(item, params, info) !== false;
}
// direct pass
if (!reverse && item.children) {
perItem(item, info, plugin, params, reverse);
}
return kept;
});
return items;
}이전처럼 클로저로 인자를 캡처하는 대신 항상 모든 인자를 명시적으로 전달해 내부 함수를 제거할 수 있습니다. 이 변경의 영향은 조금 미미하지만, 전체적으로 0.8초를 더 절약했습니다.
다행히도 이는 이미 새로운 메이저 버전인 3.0.0 릴리즈에서 해결되었지만, 생태계가 새로운 버전으로 전환되기까지 조금 시간이 걸릴 것입니다.
for...of의 변환에 주의
@vanilla-extract/css에서 거의 동일한 문제가 발생합니다. 배포된 패키지는 다음 코드와 함께 제공됩니다.
class ConditionalRuleset {
getSortedRuleset() {
//...
var _loop = function _loop(query, dependents) {
doSomething();
};
for (var [query, dependents] of this.precedenceLookup.entries()) {
_loop(query, dependents);
}
//...
}
}이 함수의 흥미로운 점은 원본 소스 코드에는 존재하지 않는다는 것입니다. 원본 소스에서는 표준 for...of 루프입니다.
class ConditionalRuleset {
getSortedRuleset() {
//...
for (var [query, dependents] of this.precedenceLookup.entries()) {
doSomething();
}
//...
}
}babel이나 타입스크립트의 repl에서 이 문제를 재현할 수 없었지만 빌드 파이프라인에서 이 문제가 발생한 것을 확인할 수 있습니다. 빌드 도구에서 공유되는 추상화인 것 같다는 것을 고려했을 때 더 많은 프로젝트가 이에 의해 영향을 받는다고 생각됩니다. 그래서 지금은 node_modules 내부의 로컬 패키지에 패치를 적용했고, 이를 통해 빌드 시간이 0.9초 더 단축된 것을 확인할 수 있었습니다.
시멘틱 버저닝(semver)의 흥미로운 사례
이것은 제가 뭔가를 잘못 설정한 것일지도 모르겠습니다. 기본적으로 프로파일은 파일을 변환할 때마다 모든 babel 설정이 항상 새로 읽힌다는 것을 보여줬습니다.

스크린샷으로 보기에는 조금 어렵지만 시간을 많이 잡아먹는 함수 중 하나가 npm의 cli에서 사용하는 것과 같은 패키지인 semver 패키지의 코드였습니다. 엥? semver가 babel과 무슨 상관이 있나요? 이를 떠올리는 데까지 시간이 꽤 걸렸습니다. @babel/preset-env의 대상 브라우저 목록을 파싱 하기 위한 것입니다. 대상 브라우저 목록 설정이 매우 짧아 보일 수 있지만, 이는 궁극적으로 290개의 개별 대상으로 확장되었습니다.
이것만으로는 충분히 영향을 미치지 못하지만, 유효성 검사 함수를 사용할 때의 할당 비용을 놓치기 쉽습니다. babel의 코드 베이스에 조금 흩어져 있지만 기본적으로 대상 브라우저의 버전은 "10" -> "10.0.0"와 같이 semver 문자열로 변환된 후 유효성을 검사합니다. 이러한 버전 번호의 일부는 이미 semver 형식과 일치합니다. 이러한 버전과 버전 범위는 변환해야 하는 가장 낮은 공통 기능 세트를 찾을 때까지 서로 비교됩니다. 이 접근법에는 아무런 문제가 없습니다.
여기서 성능 문제가 발생합니다. 파싱 된 semver 데이터 타입 대신 semver 버전이 문자열로 저장되기 때문입니다. 즉, semver.valid('1.2.3')에 대한 모든 호출은 새 semver 인스턴스를 생성하고 즉시 삭제합니다. semver.lt('1.2.3', '9.8.7')과 같이 문자열을 사용해 semver 버전을 비교할 때도 마찬가지입니다. 그래서 성능 추적에서 semver가 두드러지게 나타났던 것입니다.
또다시 node_modules에 로컬 패치를 적용해 빌드 시간을 4.7초 줄일 수 있었습니다.
결론
이 시점에서 더 이상 찾아보지는 않았지만, 인기 있는 라이브러리에서 이런 사소한 성능 문제를 더 많이 발견할 수 있으리라 생각합니다. 오늘은 주로 몇 가지 빌드 도구에 대해 살펴보았지만, UI 컴포넌트나 기타 라이브러리에서도 일반적으로 성능 저하 문제가 동일하게 발생합니다.
이걸로 Go나 Rust의 성능을 따라잡기 충분할까요? 그럴 가능성은 작지만, 분명한 것은 자바스크립트 도구들이 지금보다 빨라질 수 있다는 것입니다. 그리고 이 글에서 살펴본 것은 빙산의 일각에 불과합니다.
🚀 한국어로 된 프런트엔드 아티클을 빠르게 받아보고 싶다면 Korean FE Article(https://kofearticle.substack.com/)을 구독해주세요!

290개의 댓글

이 글에서는 널리 사용되고 있는 자바스크립트 기반 빌드 도구들을 프로파일링해 성능 문제를 찾고 이를 해결한 방법을 소개하고 있습니다.

WalgreensListensCon is a customer feedback platform that allows customers to share their feedback and insights about the - https://walgreenslistenscon.com/

The first Dollar General store opened in the US in 1939. Dollar General, formerly J. L. Turner, is the owner of a number of businesses in addition to Dollar General Market, Dollar General Financial, and Dollar General Global Sourcing.
https://dgcustomerfirstwin.site/

McDonald's has set up a survey and feedback website in order to hear from real customers. They can then provide them prizes for taking part in questionnaires about their dining experiences.
https://mcdvoecewin.store/
Therefore, by participating in the survey, you not only get rewards but also aid McDonald's in improving the quality of both its service and cuisine.
https://mcdvoecewin.store/
Therefore, by participating in the survey, you not only get rewards but also aid McDonald's in improving the quality of both its service and cuisine.
https://mcdvoecewin.store/
Therefore, by participating in the survey, you not only get rewards but also aid McDonald's in improving the quality of both its service and cuisine.
https://mcdvoecewin.store/
Therefore, by participating in the survey, you not only get rewards but also aid McDonald's in improving the quality of both its service and cuisine.
https://mcdvoecewin.store/

The corporation uses the data from surveys to better understand client preferences, pinpoint areas for development, and make strategic business decisions.
https://kohsfeedback.shop/

Customers may quickly locate the closest Food Lion outlet based on their location by using TalkToFoodLion. The software makes use of geolocation technologies to deliver precise details on store hours, product availability, and in-store promotions. https://wwwtalktofoodlion.shop/>
Customers may quickly locate the closest Food Lion outlet based on their location by using TalkToFoodLion. The software makes use of geolocation technologies to deliver precise details on store hours, product availability, and in-store promotions. https://wwwtalktofoodlion.shop/>

customer preferences, identify areas for improvement, and make necessary changes to enhance customer satisfaction.https://tellthebell.shop/

Customer Satisfaction at Ross The Customer Satisfaction Survey consists of straightforward inquiries about your interactions with Ross Stores and The notion that Ross Listens is an effort to learn what the clients think about the caliber of goods and services provided by the shop. https://wwwrosslistens.shop/
Customer Satisfaction at Ross The Customer Satisfaction Survey consists of straightforward inquiries about your interactions with Ross Stores and The notion that Ross Listens is an effort to learn what the clients think about the caliber of goods and services provided by the shop. https://wwwrosslistens.shop/
Speaking with Food Lion Speaking with Food Lion Customers were invited to offer their thoughts since the company wanted to know how satisfied you were with their service. To assist clients in comprehending issues and locating answers, Food Lion offers an online survey. https://wwwtalktofoodlion.shop/

This post will be lengthy. We shall first learn about Lowe's as a firm. The Lowes guest satisfaction survey's purpose, benefits, eligibility, and regulations are then discussed, along with a user manual that explains how to take part and customer service. You can skip ahead to the section you're interested in reading by scrolling down.
https://lows-comsurvey.com/

A guest satisfaction survey can be completed online at https://lowescomsurveys.com/, according to Lowe's. Customers that participate can win a $500 gift card as well as lovely presents. Sounds intriguing, doesn't it? To find out how to enter this lucky draw and win the reward, be sure to read the article.

The Big Lots supermarket chain in the United States of America has an online consumer feedback survey website at https://biglotscomsurveywin.info/. You would undoubtedly be aware of the Big Lots survey if you frequently visit the department store.
The website https://loescomsurveys.com/ Are you a regular Lowe's customer? Take the Lowe's Survey and share your opinions and observations! We value your feedback as we work to give our consumers the greatest possible purchasing experience.

McDonald's provides its customers with an online tool called the Mcdfoodforthoughts survey. Customers can provide insightful comments and share their experiences about how the fast-food business can improve its service going forward by completing the feedback survey at https://mcdfoodforthoughts.org/.
Prepaid debit cards from Netspend are widely utilized because they don't demand a minimum amount or a credit check. With a Netspend card, your transactions are covered by Deposit Insurance Corporation. Debit cards from MasterCard and Visa are accepted worldwide for purchases. Make cash withdrawals from ATMs anywhere in the world with your credit or debit card, either in person, over the phone, or online.https://activatellbeenmastarcard.shop/

Thus, this company's primary motivation for conducting a survey is to use the input to improve the restaurant.Along with answering a few questions, you will be asked to rank the quality of Hy-Vee's customer service from your most recent visit.
https://hey-veesurvey.shop/

By taking part in this survey, you will have the opportunity to provide insightful comments that the firm can utilize to improve its offerings and customer support. The store is happy to provide you a multi-use coupon within the first 24 hours of usage as a thank you for your time. You can use this offer to save 10% on your subsequent visit. https://jcpenneycomsurvey.live/

Are you a frequent Lowes customer? If so, please get in contact with us! We've just finished a survey regarding the https://lows-survey.org/ shopping experience, and we'd like to invite all of our customers to take part.

Answering a few short and straightforward questions about staff conduct, store atmosphere, merchandise, and facilities on Caseysfeedback.com will make it very easy for you to provide feedback about your most recent dining experience at one of their locations.
https://caseys500.shop/

In America, Lowes is a well-known network of hardware and home improvement stores. With locations throughout the globe, it began as a little hardware store in North Carolina. Moreover, installation and maintenance services are provided. The company's weekly serving of 20 million clients attests to its legitimacy and renown.
https://loves-survey.com/
It's possible that you will purchase nothing. You may still participate in the contest by filling out a paper entry form if you would rather not participate in the online poll. One of America's most recognisable home improvement firms is now conducting a customer satisfaction survey. https://homedpotcomsurveys.info/
At lowessurvey.com, the retailer is conducting an online visitor satisfaction survey. A $500 gift card and lovely presents are up for grabs for consumers who participate. Sounds intriguing, don't they? Check out the article to find out how to enter this fortunate draw and win the reward. https://loescomsurveys.com/

All you have to do is complete the Del Taco Guest Satisfaction Survey with a few questions about your most recent visit and submit your suggestions and opinions. https://surveydaltaco3.shop/
Regarding your most recent visit, Hard Rock Cafe would want to hear from you. Share what you like and don't like. Because they appreciate your comments and utilise it to improve. Therefore, it makes no difference if your feedback is kind or unfavourable.

Employees are encouraged to keep providing exceptional customer service by this accolade, which also helps to uphold high standards at all Publix locations. https://publexsurvey1000.shop/

Party City will be able to enhance the quality of their offerings and customer service with the aid of the Party City Customer Feedback Survey, which will enable you to receive even better treatment on your subsequent visit to one of their locations. https://partycityfeedback.shop/
Kroger feedback is an online survey input stage that it owns. Respondents are asked about their satisfaction with the supermarket's services in a straightforward Kroger customer satisfaction survey, which can be found at https://krgerfeedbackwin.org/ products and services.

By answering this survey, you will provide the business with insightful input that they can utilize to enhance their offerings. You will receive one entry into a sweepstakes for a $500 Lowe's gift card as payment for your participation. https://wwwloescomsurvey.shop/

This article will give you all the details you need to participate in the LongHorn Steakhouse Experience Survey, including eligibility requirements, restrictions, and instructions on how to complete the online form step-by-step. https://longhornsurvey.shop/

It is of the utmost importance to provide its clientele with a wide selection of delectable food options, service that is friendly and courteous, and dining establishments that are spotless.
https://eplfeedback1.shop/

Firehouse Subs is a casual dining restaurant brand based in America that was founded in 1994. With a focus on all kinds of subs, the restaurant business provides over 900 Firehouse Subs locations with great food and service. https://firehouselistens500.shop/
This is the ideal spot for you to participate in the Ross Customer Satisfaction Survey by sharing your ideas, as you will find all the information you require to complete the Ross Stores Survey. https://wwwrosslistens.shop/

This page will walk you through the process of participating in the Caribou Coffee Customer Feedback Survey step-by-step. It will also provide you with information about the survey's requirements, rules, and regulations, as well as Caribou Coffee Rewards. https://tellcaribou.shop/

The online customer satisfaction survey, Talk to Hannaford, is provided by Hannaford and gauges how satisfied customers are with the goods and services they provide. https://talktohannafordcom.shop/

The hashtag tellthebell is frequently linked to the Taco Bell fast-food restaurant franchise. Actually, it's Tell The Bell, referring to a Taco Bell customer satisfaction survey. https://tellthebell500.shop/

MyGreatLakes helps young people realize their aspirations by providing student loans to millions of students nationwide. The company understands the importance of a college education for success. https://greatlakeslogin.shop/

The Victoria Mastercard Credit Card is accepted anywhere Mastercard is accepted, comes in black, and has the Mastercard logo on it.
https://comenitynetvicturiassecretactivate.shop/
The Victoria Mastercard Credit Card is accepted anywhere Mastercard is accepted, comes in black, and has the Mastercard logo on it.
https://comenitynetvicturiassecretactivate.shop/
The Victoria Mastercard Credit Card is accepted anywhere Mastercard is accepted, comes in black, and has the Mastercard logo on it.
https://comenitynetvicturiassecretactivate.shop/
The Victoria Mastercard Credit Card is accepted anywhere Mastercard is accepted, comes in black, and has the Mastercard logo on it.
https://comenitynetvicturiassecretactivate.shop/
The Victoria Mastercard Credit Card is accepted anywhere Mastercard is accepted, comes in black, and has the Mastercard logo on it.
https://comenitynetvicturiassecretactivate.shop/
The Victoria Mastercard Credit Card is accepted anywhere Mastercard is accepted, comes in black, and has the Mastercard logo on it.
https://comenitynetvicturiassecretactivate.shop/
The Victoria Mastercard Credit Card is accepted anywhere Mastercard is accepted, comes in black, and has the Mastercard logo on it.
https://comenitynetvicturiassecretactivate.shop/

The PayGOnline website gives consumers the option to log in and access a portal where they may instantly pay their bills in a matter of seconds. https://paygonline.shop/

This portal is incredibly user-friendly, simply accessible, and specifically designed with the convenience of the employees in mind. https://upsersemployeelogin.shop/

Go to indigocard.com/activate, log in, and enter your card information to activate your new Indigo card. https://activateguide.info/indigocard-com-activate/ Nevertheless, you must register as a member of the website before you may activate your new card there.

This card has gained a reputation as the best public assistance provider because it does not impose annual fees on its users while providing them with advantages.

The original Kentucky Fried Chicken recipe was created and manufactured by Harland Sanders, while the company's name was coined in 1950 by Don Anderson, a menial sign painter. It was not until he gave Pete Harman the rights to his recipe that the name was finally changed to KFC.
https://mykfcxperiencesurvey.shop/

Why does JCPenney conduct surveys? www.Jcpenney.com/survey
When you visit JC Penney next time, fill out the customer feedback survey if you want your opinions to be considered.
One of the biggest, most well-known, and most well-liked banks in the US is Chase Bank. It is also referred to as JP Morgan Chase Bank, and it is doing a great job of serving food services and retailers. Additionally, they provide their clients with a wide range of personal banking services that are utilised to issue loans and various investments. Additionally, they used to offer their clients very user-friendly online and mobile banking services.
https://nonotify.com/chase-bank-hours/

Home Depot is the first site most Americans visit when they start shopping for supplies for home improvement projects. From the CEO to the newest employee, everyone's top priority is the satisfaction of the consumer. https://homdpotcomsurveys.org/

Participating allows you to provide feedback on what you love (or believe could be better!) to Cracker Barrel, helping them improve their food and service. https://crackerbarrelsurvey.autos/

You can spend as much as you like with the ACE Flare Account without having to worry about accruing interest on your credit card. Keep in mind that there are restrictions on both purchases and withdrawals when using the ACE Flare Card. https://aceflare.shop/

The purpose of the DunkinRunsOnYou survey is to ask customers about their top priorities and help fill in any gaps. https://dunkinrunsonyou500.shop/
this is a fabulous information, i'm enjoying to read this info - http://www.technobullion.com/
The idea you presented is truly innovative and the content is distinctively valuable.
https://kilgorelifestyle.com/

The tellthebell survey is a great way for Taco Bell to hear what its consumers have to say. In order to stay ahead of the competition in the fast food sector, Taco Bell utilizes the data collected from its “Tell the Bell” survey to assess and improve its menu items. https://tellthebell.shop/

Dollar General appreciates your input and makes use of it to enhance its goods and services. You can help them make shopping even more enjoyable for everyone by answering the survey. https://dgcustoomerfirstt.autos/
Tech No Bullion is a website that covers a variety of topics including celebrity news and technology. The content is detailed and tailored to keep readers informed about the latest trends and insights. https://technobullion.com/della-beatrice-howard-robinson-the-woman-behind-ray-charles-heart/
Your input is valued by Dollar General, and it's used to enhance their offerings. You may contribute to their efforts to improve shopping for all by filling out the survey. https://dgcustoomerfirstt.autos/
Whenever you look, you can find Dollar General! There is always a Dollar General nearby thanks to its dozens of locations across the country.https://publiixsurveey.autos/

So, what's the recipe for pizza dough that works for all of your favorite looks? Let's examine the science and art of making pizza dough so that you can start down the path to pizza greatness. https://pizzacalculator.org/
Your feedback truly motivates me to continue sharing valuable content. I'll definitely keep working on bringing more insightful and engaging information your way.
https://www.thebarnyardblog.com/
Try Phillipa Mariee for latest information & trending updates.
https://phillipamariee.com/

In order to improve its offers, Maurices is asking customers for input on things like store atmosphere, service, and product quality. Maurices knows from years of experience in the fashion sector that success is largely dependent on satisfied customers. The organization can find areas for development by analyzing the feedback. https://tellmaurices.autos/
Amazon Fresh Weekly Ad!! If you’re an Amazon Fresh shopper, visit here weekly to read the current Amazon Fresh weekly ad or to preview some forthcoming Amazon Fresh bargains with the ✳️ Amazon Fresh ad preview.
Viral Times Magazine is a contemporary online platform that engages readers with a diverse range of topics, https://viraltimesmagazine.com/tamara-gilmer-wiki-bio-career-ethnicity-ex-husband-children-net-worth-and-more/
I will always appreciate all of your work.
https://profile.hatena.ne.jp/justingclare33/profile

For those who may not be aware, we offer the Guest Obsessed Survey as part of our commitment to giving our visitors the best experience possible. https://guestobsessed.bar/

The www.tellpopeyes.com customer feedback procedure, known as the "TellPopeyes Survey," allows restaurants to learn about the in-restaurant eating experiences of their patrons and provide them with the tools they need to consistently provide superior service. https://tellpopeyes.bar/

That is what I was looking for, what information, present here at this site!
https://njmc.me/
Regards from mywawavisit! Do you need help finding the ideal destination? We have options for everyone, whether you're looking for a serene rural setting or an active downtown.
https://mywawavisit.bar/
Regards from mywawavisit! Do you need help finding the ideal destination? We have options for everyone, whether you're looking for a serene rural setting or an active downtown.
https://mywawavisit.bar/

Walgreens puts its customers first, even in a world where everyone else is more concerned with money than with customers. https://walgreenslistensx.shop/

With new models arriving every day, Pic N Save's rebuildable vehicle showroom has the best and largest indoor inventory of rebuildable cars in Canada. There are usually plenty of cars with clear titles up for grabs. https://picknsavecomfeedback.autos/

The Tell Slim Chickens survey is a handy method to provide insightful feedback. The restaurant greatly benefits from your feedback in terms of both service and food quality. it guarantees an enhanced encounter each time you go there. https://tellslimchickenssmgcom.autos/

Each person is allowed only one survey entry per purchase, and there’s a limit to how many times an individual can enter during a given sweepstakes period. https://talktostopandshop.shop/

They're rewarding everyone who completes the survey with free lunch in exchange for their opinion. https://mcdfoodforthoughts.autos/

The Greatest Ways to Have Fun at Panda To keep up its good name, Panda Express asked its loyal customers for their thoughts through a customer satisfaction survey. https://pandaguestexperience.boats/
The Finest Ways to Have Fun at Panda Panda Express conducted a customer satisfaction survey to get feedback from its loyal customers in an attempt to uphold its stellar reputation. https://pandaguestexperience.boats/

Head over to Myzaxbysvisit.com today, complete the survey, and help Zaxby’s continue to deliver the best possible service to its customers. https://myzaxbysfedbacks.shop/
Panda Express is one of America's largest fast-food chains. Panda Express currently operates over 2000 shops in North America and Asia. https://pandaguestexperience.boats/

The management of Culver started a customer satisfaction survey program called the Tell Culvers Survey. Those who finish the survey will receive monthly incentives for a whole year.
https://tellculvers.boats/

Health and wellness items, prescription filling, photo services, and health information are its primary areas of expertise. https://walgreenslistens.boats/

After the survey period, winners of the FirehouseListens poll are chosen at random from among all qualifying contributions. To be eligible for this drawing, participants must finish the survey and provide their contact information. https://firehouselistens.boats/

A shipping company called MycoverageInfo can be of great assistance to you in locating the ideal insurance plan. The most dependable insurance services are offered to customers by MyCoverageInfo to help safeguard their future. Home loans, insurance, auto insurance, and other services are provided by MyCoverageInfo.
A brand-new online tool called MyCoverageInfo was created to assist clients in managing their active insurance policies. Through this site, customers can access their loan information and leave all further processing to the portal. In this manner, insurance updates and payment activities are not a concern for borrowers.

You can, however, mail a note to the store. A manager will soon take up your work and finish the necessary tasks. https://kohlsfeedback.cam/

Hello...
PaybyPlatema is a time-saving solution that enables all car owners to pay all costs online. Even though using the PaybyPlatema Login to make a toll payment is simple, the customer service team is always there to assist users in any situation when they run into problems.
Hello...
PaybyPlatema is a time-saving solution that enables all car owners to pay all costs online. Even though using the PaybyPlatema Login to make a toll payment is simple, the customer service team is always there to assist users in any situation when they run into problems.

It's common knowledge that Taco Bell is among the greatest places in the world to sample new cuisine. It has completely altered Mexican cuisine. Tacos are now even more delicious when additional ingredients are added. https://tellthebell.cam/

Del Taco, a massive restaurant franchise, must maintain high standards for both food quality and customer service. The best instrument for this is the customer satisfaction survey. https://myopinion.boats/

The American retail business Lowe's Companies Inc., usually referred to as just Lowe's, specializes in home improvement.Lowe's was founded in North Carolina in 1921 and now has locations in the US, Canada, and Mexico. https://lowesc0msurvey.cfd/

Completing the survey offers you the opportunity to express your opinions and enter a lottery to win £500 worth of Waitrose gift cards. https://weitrosehaveyoursay.boats/
Completing the survey offers you the opportunity to express your opinions and enter a lottery to win £500 worth of Waitrose gift cards. https://weitrosehaveyoursay.boats/

All timestamps are kept on Walmart's centrally located Global Time and Presence (Walmart GTA) web platform. Walmart's GTA Portal allows users to check in and out using an RFID card or a portable device. Through this portal, Walmart employees can obtain information regarding Global Times' presence.
The Walmart Global Time and Presence (GTA) interface is the central location for all timestamps. Walmart's GTA Portal allows employees to check in and leave using an RFID card or a portable device. This portal gives Walmart employees information about the Global Times presence.

This will result in your registration for the Publix Customer Satisfaction Survey. Additionally, you have a chance to win the $1,000 gift card. https://publixsurvey.boats/

Receiving reviews of Wingstop Restaurant Stores, both good and bad, helps patrons choose restaurants wisely and guarantees that they will be happy with the caliber of the food and service. https://mywingstopsurvey.boats/
Amazon's New Weekly Promotion! If you shop at Amazon Fresh, visit this page every week to see the current weekly ad or use the ✳️ Amazon Fresh ad preview to see what sales are coming up.
You can find a lot of Amazon Fresh deals this week or some coming up with the ✳️ Amazon Fresh weekly advertisements.
Return often to keep abreast of the most recent Amazon Fresh promotions.

Are you sick and tired of sluggish access to your money during times of dire need due to subpar services? Or are you trying to find a business that can provide fast money without any delays or disruptions? If so, Payday eLoanWarehouse is the best option for you because it provides amazing immediate cash up to $5,000 anytime you need it. Yes, you read correctly! Payday loans from the eLoanWarehouse are unquestionably your finest option in a variety of circumstances.
Understanding your payday alternatives with this lender aids in making prudent financial decisions, especially when dealing with unforeseen costs or short-term demands.
https://peydayloanseloanwarehouse.info/

However, in order to remain iconic, you must pay attention to those who walk in their shoes: you! This is why the MyConverseVisit survey is so important. https://myconversevisitt.click/

WalgreenListens gives clients a stage to impart their fair insights about their shopping experience. This criticism straightforwardly influences the progressions and upgrades Walgreens executes. https://wlgreenslistenscom.store/
WalgreenListens gives clients a stage to impart their fair insights about their shopping experience. This criticism straightforwardly influences the progressions and upgrades Walgreens executes. https://wlgreenslistenscom.store/
WalgreenListens gives clients a stage to impart their fair insights about their shopping experience. This criticism straightforwardly influences the progressions and upgrades Walgreens executes. https://wlgreenslistenscom.store/
WalgreenListens gives clients a stage to impart their fair insights about their shopping experience. This criticism straightforwardly influences the progressions and upgrades Walgreens executes. https://wlgreenslistenscom.store/

And how might they best get better? By talking to you personally! Tellgamestop.com's GameStop Survey allows you to share your thoughts about what you like and what may be improved, from product selection and shop atmosphere to customer service. https://tellgamestopp.click/
And how might they best get better? By talking to you personally! Tellgamestop.com's GameStop Survey allows you to share your thoughts about what you like and what may be improved, from product selection and shop atmosphere to customer service. https://tellgamestopp.click/

Hen House is a part of your life, not just a store, thanks to its local roots and emphasis on communal values. Your comments support this cherished brand's growth and ability to provide its consumers with the greatest experience possible. https://henhousefeedback.click/

Com is their method of gathering input on what is effective, what needs improvement, and what you hope to see going forward. https://tellwinndixiee.click/

Better Item Choice: Client ideas have prompted the expansion of specialty items and neighborhood top picks in unambiguous stores. https://waallgreenslistens.com/
In contrast to certain other surveys, this one is short, simple to do, and allows you to contribute any other ideas or experiences that are important to you. https://tellwinndixiee.click/
In the consistently developing retail and drug store scene, consumer loyalty isn't simply vital — it's a need. Walgreens, a confided in name in the drug store and retail world, has been at the very front of focusing on client criticism through its imaginative stage, WalgreensListens. https://waallgreenslistens.com/

Five Guys has gained international popularity as a fast-casual restaurant brand thanks to its distinctive, totally customized burgers and hand-cut fries. https://fiveguyscomsurveyy.click/

To check the balance of your gift card account, visit the official PrepaidGiftBalance website. Also, the service is called prepaidgiftbalance These days, checking the balances of essential credit and debit cards is simple thanks to secure internet access. A large number of customers invest and obtain prepaid gift cards from various retailers.
https://prepaidgiftbelance.cfd/
To check the balance of your gift card account, visit the official PrepaidGiftBalance website. Also, the service is called prepaidgiftbalance These days, checking the balances of essential credit and debit cards is simple thanks to secure internet access. A large number of customers invest and obtain prepaid gift cards from various retailers.
https://prepaidgiftbelance.cfd/

You may enhance your shopping experience and get amazing incentives by taking part in their survey, which can be found at Mygabes.com/survey. https://wwwmygabesc0msurvey.click/

Customers can provide comments about their previous experience at a LongHorn Steakhouse restaurant using the user-friendly online survey platform LongHornSurvey.com.
[url=https://longhornsurvey.autos/] Longhorn Survey [/url]
This survey acts as a conduit between patrons and the business, enabling patrons to express their thoughts regarding the cuisine, service, and general ambiance of their dining encounter. https://longhornsurvey.autos/

There is more to taking part in MyGabe's.com/survey than just finding discounts and rewards. The goal is to assist Gabe's in making their shopping experience better for you and all of their devoted patrons. https://wwwmygabescomsurvey.click/

When you take the time to leave feedback, Five Guys offers you a little bit extra, like a coupon for free fries, a discount on your next order, or the chance to win a $1000 gift card. https://fiveguyscomsurvey.click/

A consumer will be eligible to get a $25* $100 gist card each month if they properly complete the survey. Making sure that customers actively engage in the survey is made possible by this excellent method. https://tellgamestop.bond/
A consumer will be eligible to get a $25* $100 gist card each month if they properly complete the survey. Making sure that customers actively engage in the survey is made possible by this excellent method. https://tellgamestop.bond/
A consumer will be eligible to get a $25* $100 gist card each month if they properly complete the survey. Making sure that customers actively engage in the survey is made possible by this excellent method. https://tellgamestop.bond/
A consumer will be eligible to get a $25* $100 gist card each month if they properly complete the survey. Making sure that customers actively engage in the survey is made possible by this excellent method. https://tellgamestop.bond/
Your comments will not only assist ALDI's future, but they may also earn you a $100 ALDI gift card! Yes, you heard that you can get rewarded for voicing your opinions. https://tellaldi.cfd/
More than just answering a few questions, taking part in the Tell Aldi's Survey gives you the opportunity to win great rewards and help ALDI make your shopping experience better. https://tellaldi.cfd/
Completing the Tell Aldi's Survey is more than simply answering a few questions; it's also an opportunity to win great rewards and help ALDI make your shopping experience better. https://tellaldi.cfd/

Your opinion is very important at Casey's. You have the opportunity to express your experience—whether positive, negative, or anywhere in between—through the Caseysfeedback survey. What's the best part? Everyone is benefiting from this circumstance! https://caseysfeedback.click/
In order to provide the greatest, Regal is always improving its immersive sound systems, opulent seating, and everything in between. What is their secret? listening to clients such as yourself. https://talktoregal.click/
Whether it's more efficient service, more comfortable seating, or a greater assortment of snacks, your suggestions enable Regal to improve their customer service. We all benefit from it! https://talktoregal.click/

Keep your receipt for the next time you buy at Belk! You might be the fortunate recipient of a $500 gift card if you take a few minutes to do the survey. https://belksurvey.click/
Now, Krispy Kreme is a worldwide sensation, with its famous hot, freshly made donuts available in more than 30 nations. https://krispykremelistens.click/

In this way, they may resolve problems and improve both your and other customers' experiences. https://wwwtalktohannaford.cfd/
If you recently ate at Charley's Philly Steaks, you may fill out the survey at tellcharleys.com to express your opinions or provide recommendations. A customer satisfaction study was recently carried out by the business. https://tellcharleyss.cfd/
If you recently ate at Charley's Philly Steaks, you may fill out the survey at tellcharleys.com to express your opinions or provide recommendations. A customer satisfaction study was recently carried out by the business. https://tellcharleyss.cfd/
If you recently ate at Charley's Philly Steaks, you may fill out the survey at tellcharleys.com to express your opinions or provide recommendations. A customer satisfaction study was recently carried out by the business. https://tellcharleyss.cfd/

Founded in 1996, Murphy USA presently has hundreds of outlets throughout the US, offering a wide range of convenience store goods and reasonable fuel costs to its customers. https://tellmurphyusa.click/
Founded in 1996, Murphy USA presently has hundreds of outlets throughout the US, offering a wide range of convenience store goods and reasonable fuel costs to its customers. https://tellmurphyusa.click/

We all desire a simple, effective, and pleasurable shopping experience, whether we're supermarket shopping or just stopping in for a quick item. https://storeopinion-ca.click/
Let's examine what the AcmeMarketsSurvey is, how to take part, and the importance of your feedback. Spoiler alert: completing this survey will earn you some fantastic benefits in addition to helping Acme Markets. https://acmemarketssurveyus.click/

Taco John's customer support team is ready to help if you have any questions, issues, or comments that go beyond the parameters of the TellTacoJohns survey. http://telltacojohnscom.autos/
In addition to helping Taco John's continuously enhance its services, customers who actively participate in the poll have the opportunity to get special benefits. http://telltacojohnscom.autos/
Fantastic news for fans of Tim Hortons! Tim Hortons increased its breakfast hours to 11 AM on April 1, 2023. This allows you to savor their mouthwatering morning pastries and sandwiches for an additional hour! https://timhortonsbreakfasthours.autos/
You can get free food and other benefits by taking the official Long John Silvers Survey. A corporation can set up a feedback poll as a terrific opportunity. https://mylongjohnsilversexperience.autos/

Everyone is aware that Taco Bell is among the greatest places in the world to sample new cuisine. Everything about Mexican food has altered as a result. Tacos have become even more delicious as a result of fresh additions. https://tellthebell.cam/
His mother's encouragement helped the new restaurant gain popularity among students quite fast. The mouthwatering Philly cheesesteaks, piled Connoisseur Fries, and cool lemonade at Charley's Steakery drew crowds. https://tellcharleys.boats/

You participate in the MyStarbucksVisit survey as a partner in creating the Starbucks experience, not just as a customer. Therefore, let's hear what you think following your next visit. https://mystarbucksvisitt.autos/

We extend a warm welcome to you on the official Walgreenslistens customer survey website, www.walgreenslistens.com. https://walgreenslistens.boats/

Let's take a moment to honor Pep Boys before we begin the survey. Established in 1921, this well-known chain of vehicle repair shops has been keeping our rides comfortable and our wallets content for more than a century. Pep Boys has everything you need, including new tires, a fast oil change, and that elusive car accessory. https://pepboyssurveyus.click/

Under the Little Caesars brand, Little Caesar Enterprises Inc. has become the third-largest pizza company in the United States, after Pizza Hut and Domino's Pizza. https://littlecaesarslistenss0.boats/
You can help IHOP improve their services and provide you a better eating experience in the future by answering our guest satisfaction survey. Your feedback as a consumer significantly affects everyone's overall satisfaction and quality. https://talktoihop.boats/
Starbucks has the ability to keep coffee enthusiasts returning for more, whether they want a traditional latte, a cool Frappuccino, or a seasonal special. https://mystarbucksvisitt.cfd/
Sprouts Farmers Market has been a popular place for people who appreciate natural, organic, and affordable grocery shopping for many years. https://sproutsfeedbackcom.autos/

Customers can give their opinions on several facets of the business's services and goods by accessing the survey on Tsclistens.com. https://tsclistens.boats/


Beachbody On Demand can be the ideal option for you if you're a fitness enthusiast searching for a way to work out from the convenience of your home. Numerous workouts and fitness routines are available to you through this digital fitness platform. We'll answer some commonly asked questions and walk you through the process of turning on Beachbody On Demand on your device in this post. Now let's get started: https://beachbodyondemandactivete.pro/

Wingstop would be happy to hear your candid opinions and recommendations on how to enhance their chicken wings and other products to better suit your tastes. https://mywingstopsurvey.boats/

Have you ever wished you could get compensated for sharing your thoughts about your most recent supermarket run? Guess what, though? You can now! Welcome to Talktofoodlion, the definitive resource for the Food Lion Survey. https://talktofoodlioncom.cfd/
The recently implemented Happy Hour at Sonic Drive-In, a well-known American drive-in business, allows you to take advantage of half-priced drinks and slushes every day from 2 to 4 p.m., making sure that your taste buds and budget are both pleased. https://sonichappyhour.boats/

The Medicare Administrative Contractor (MAC) for Jurisdictions H and L, Novitas, strongly encourages providers to use our free online portal, Novitasphere, to submit redeterminations and make claim changes. These features save providers a great deal of time because they are quick and simple to use.
The Claim Correction tool is one of Novitasphere's most used features. This is how Part B clients can send Novitas their clerical error reopenings. The steps are as easy as 1-2-3: Go into Novitasphere, make the necessary corrections, and submit! Watch this brief instructional video to see how simple it is: https://novitaspherre.site/

Sonic Happy Hour welcomes you! At participating Sonic locations, indulge in a range of reduced food and beverages. https://sonichappyhour.boats/

A few breakfast items may be offered all day at some locations, particularly during special promotions. https://tacocabanabreakfasthours.click/

You are cordially invited to take part in JCPenney's Customer Satisfaction Survey. By allowing you to provide feedback on their goods and services, this survey enables JCPenney to enhance and customize their offerings to better suit the needs of its clients. https://jcpenneycomsurvey.boats/

Weekly Ad for Aldi! If you shop at Aldi, visit this page every week to see the current weekly ad or use the ✳️ Aldi ad preview to see what forthcoming sales are coming up.
You can find a lot of Aldi offers this week or some coming up with the ✳️ Aldi weekly advertising. The standard weekly Aldi ad will often be posted after the Aldi in-store ad.
Many of the items in the Aldi ad are on sale even without coupons, however we are unable to combine these in-store discounts with coupons!

Sonic Drive-In is a breakfast destination that blends convenience, variety, and flavor—it's more than simply a fast-food restaurant. Sonic has what you need, whether you're craving a light parfait, a sweet treat, or a substantial burrito. https://sonicbreakfasthours.click/

Scan to inform the body of your whereabouts if you feel like you're not having fun. https://longhornsurvey.boats/
This week's ShopRite Weekly Ad and next week's ShopRite Ad! To view every page of the ShopRite weekly ad circular, use the left and right arrows.
Get your coupons ready for the early ShopRite weekly ad preview, which includes certain ShopRite weekly ad bogo specials, and plan your shopping trip in advance! Make sure you are viewing all of the latest ShopRite weekly discounts by returning frequently.

Dwarf Grill, now known as Dwarf House, is where Chick-fil-A first opened. Tweedy, Samuel When Cathy opened it, it was a full-service restaurant. At the time, it was in a neighborhood close to Atlanta. https://chickfilabreakfasthours.buzz/

Do you also want to know how to obtain this deal? Stay tuned as we walk you through the process of this customer experience survey. See the guidelines and detailed instructions for joining. https://mycfavisit.boats/

Let's start by asking when Taco Bell's breakfast will be available. Although 7:00 AM to 11:00 AM is the ideal timeframe for breakfast, keep in mind that times may differ significantly based on where you are. https://tacobellbreakfasthourss.cfd/

This week's Food City Weekly Ad and next week's Food City Ad! To view every page of the Food City weekly ad circular, use the left and right arrow keys. Prepare your coupons for the early Food City weekly ad preview and plan your shopping trip in advance!
Looking through the Food City weekly flyer is a breeze. The Food City sales this week are broken down into categories to make it simple to determine if the item you're looking for is on sale or not. Make sure to check the Food City advertisement for the upcoming week to see if the product you wish to purchase is on sale so that you never

You can provide Jack in the Box with feedback and assist them in improving their goods and services by completing this quick and simple survey on jacklistens. https://jacklistenscom.boats/

This week's Jewel Osco Weekly Ad and the ✳️ Jewel Osco Ad are coming up! Go through the Jewel Osco weekly ad circular from cover to cover.
Prepare your coupons for the early peek of the Jewel Osco weekly ad, which will include some bogo deals! Make sure you are viewing all of the latest Jewel Osco weekly discounts by returning frequently.
https://jeweloscoweeklyad.shop/

Through the Churchslistens survey, the business is able to determine what customers think about their restaurants, food, and general level of service. The company's efforts to continuously develop depend heavily on this feedback. https://churchschickenfeedback.boats/

Take the survey by going to www.dennylistens.com. You can choose the language in which you are most comfortable by taking the survey, which is accessible in English, French, and Spanish. https://dennyslistens.boats/

To improve administration and quality, surveys and client input are crucial. To address Kroger's concerns, the company has implemented an online feedback system via the survey and input website. https://krogerfeedback.boats/

The exciting part is about to begin! You might win free Cane's for a full year by spending a few minutes filling out the Raising Cane's Survey. Imagine getting to eat those delicious, soft chicken fingers for nothing at all—it's a foodie's paradise! https://raisingcanessurvey.boats/

Your feedback will enable us to better understand your preferences and areas for improvement, ranging from our in-store atmosphere to our fashion collections. https://tellmaurices.boats/

Let's take advantage of this wonderful opportunity and explore all the information you require to effectively communicate your message! https://wfmcomfeedbackcom.cfd/

Additionally, McDonald's is using the findings of the McDVOICE study to raise the caliber of their meals. Customers who complete the survey and provide their contact details will receive a coupon good for a discount at a certain McDonald's. https://mcdvoice.boats/

To learn more about the stores, they can take a survey at www.publixsurvey.com. The supervisors can evaluate the caliber of the services they offer. https://publixsurvey.boats/
To learn more about the stores, they can take a survey at www.publixsurvey.com. The supervisors can evaluate the caliber of the services they offer. https://publixsurvey.boats/
The majority of you are already aware that big businesses use basic surveys to raise the caliber of their goods and services. This project is being undertaken by a recently established large corporation. https://publixsurvey.boats/

Hey, you're the VIP here, so tell us what's working and what isn't! That's how they say it. So take out that receipt and let's talk about how you can participate in the feedback process. https://walgreenslistenss.cfd/

A seafood combo is simple to get from Long John Silver's drive-thru, with golden fries, delicious shrimp, and crispy fish that satiate desires with every bite. https://mylongjohnsilversexperience.boats/

You can share your thoughts on your shopping experience at the Lowe's survey. Rate staff friendliness, store cleanliness, and other factors. Your voice counts for improvements since completing the survey entitles you to a $500 monthly sweepstakes. https://lowescomsurvey10.click/

However, it benefits you as much as Starbucks! Each time you fill out the MyStarbucksVisit survey, you're opening up the possibility of winning prizes that could enhance your subsequent coffee date. https://mystarbucksvisitph.cfd/

Contribute to Lowe's improvement by leaving your feedback in their survey! After rating your buying experience and filling out the customer satisfaction survey, you can enter. https://cvshealthsurveyme.click/

TalkToWendys' Wendy's Customer Satisfaction Survey allows you to share your thoughts on the cuisine, service, and atmosphere. available at. https://talktowendys.boats/

The DunkinRunsOnYou survey was enjoyable to complete! I can share my Dunkin' Donuts experience quickly, and the free classic donut coupon is a great bonus. Fantastic work paying attention to what consumers have to say and improving visits. https://dunkinrunsonyou.boats/

You may win a $1000 gift card or PC points by telling Loblaws about your recent experiences at stores like Maxi or No Frills in the StoreOpinion.ca survey. https://storeopinion-ca.boats/

We will also install a number of cookies when you log in so that we can store your login credentials and screen display preferences. https://costafeedback.autos/

My excursion to Marshalls was amazing; there were so many fashionable alternatives! I gave them feedback to assist them get better at Survey.Marshallsfeedback.com. It's an easy and quick survey. https://marshallssfeedback.click/

P. Terry's is all about being authentic, from their delicious milkshakes and hand-cut fries to their famous all-natural beef patties. This place offers only made-to-order goodness—no frozen goods. https://myptvisitsmg.cfd/
P. Terry's is all about being authentic, from their delicious milkshakes and hand-cut fries to their famous all-natural beef patties. This place offers only made-to-order goodness—no frozen goods. https://myptvisitsmg.cfd/

Why is Tropical Smoothie Cafe unique? Every visit seems like a little vacation because of their infatuation with using only the freshest foods. https://tsclistenss.cfd/

Enjoy Panda Express? Pandaguestexperience.com is the place to complete the Pandaguestexperience survey! Provide candid feedback, answer questions regarding your meal, and receive a validation voucher good for a complimentary entrée on your subsequent visit. https://pandaguestexperience.boats/

Your input is valued by KFC! Tell us about your eating experience by filling out the TalktoKFC survey at www.talktokfc.com. You can win a weekly $1,000 prize or a coupon in as little as a few minutes. https://talktokfcconz.boats/
Your input is valued by KFC! Tell us about your eating experience by filling out the TalktoKFC survey at www.talktokfc.com. You can win a weekly $1,000 prize or a coupon in as little as a few minutes. https://talktokfcconz.boats/

A Burger King online survey asks respondents about their most recent experience dining at any of their locations. This survey is an easy method to learn how satisfied Burger Kind patrons are with their meals and what they think about the food quality, the service, and many other aspects of the business. https://mybkexperience.boats/

Today, Whole Foods Market is the place to go for natural, organic products that satisfy your conscience and taste buds. https://wfmc0mfeedback.cfd/

TalkToFridays: Kindly fill out the TGI Fridays questionnaire.Are you unsure about how to complete the survey? You're at the proper location!Using Your Input to Enhance TGI Fridays https://talktofridaysus.boats/

The official website. Do you frequently purchase items from Family Dollar? This is your chance to speak up if so! https://ratefd.boats/

The Kohl's management store's load and condition are changed once a year. Items such as clothing, shoes, toys, tools, chairs, blankets, colors, jewels, transistors, fittings, and more can all be utilized. https://kohlsfeedback.cam/

Myopinion.deltaco.com, a popular fast-food company in the United States, offers Mexican cuisine prepared in an American manner. In the United States, the firm manages around 500 restaurants. Lake Forest, California, is home to its headquarters. https://myopinion.boats/

Activating my L.L. Bean Mastercard at activate.llbeanmastercard.com was easy. With just my card number and other basic information needed, the process was quick, easy to use, and safe. https://activatellbeenmastarcard.boats/

Besides playing the role of VIP critic, you may also receive discounts or a chance to win fantastic prizes. Ready to seize this incredible opportunity? Let's go over all you need to know to express your opinions and keep your pocketbook happy! https://biglotscomsurveyo.autos/

Savor a delicious Chick-fil-A breakfast while indulging in their well-known Chick-n-Minis. To share your experience and get a free sandwich, complete the Chick-fil-A online survey. https://chickfilabreakfasthours.click/

The best ingredients are found in every aisle of Hen House, from locally sourced veggies to farm-fresh eggs. https://henhousefeedback.boats/

A brand founded on quality, freshness, and customer pleasure, Hen House is more than simply a typical grocery store. Since its founding, Hen House has been dedicated to delivering the best meats, freshest veggies, and outstanding customer service. https://henhousefeedback.boats/

Just five minutes are needed to complete the Krispy Kreme Survey at krispykremelistens.com. Give your criticism and use a validation code to receive a complimentary doughnut as a reward. https://krispykremelistens.boats/
The Longhorn Survey is available on LongHornSurvey.com to gather consumer input. To be eligible to win a $100 gift card each month, rate the food and service. https://longhornsurvey.cam/

By providing input on their delicious wings, I assisted Zaxby's in enhancing the eating experience. https://myzaxbysvisit.boats/

Gamers may find the newest video games, consoles, accessories, and memorabilia at GameStop, a haven for gamers. https://tellgamestop.click/

TellCulvers.com's Culver's survey was enjoyable to complete. I received a complimentary coupon for dessert, and the process was quick and simple. A great approach to receive rewards for sharing feedback https://tellculvers.boats/

Click here to complete the Jamba Juice Guest Satisfaction Survey: TellJamba.com. By sharing your opinions about smoothies and service, you can enter to win discounts or a $500 cash reward. https://telljambacom.cfd/

As a thank you for your time, you will also receive a unique bonus code. Don't pass up this chance to have a say and get some tasty benefits! https://tellmazzios.click/

Telltacojohns.com's official Taco John's Survey allows you to share your experience and receive exclusive benefits like discounts. Taco John's values your opinion. https://telltacojohnscom.click/

Visualise this: In 1964, Tim Horton, a hockey icon, establishes a little coffee shop in Hamilton, Ontario, with the goal of making the ideal cup. https://telltims-ca.cfd/

You will be entered to win a $50 gift card as a prize for doing this My Wingstop Survey, which asks you to be honest about your most recent visit. https://wingstopcomsurvey.boats/

Your VIP ticket to improving Walgreens is this survey, regardless of whether you're giddy with the quick prescription pickup or sneering at a long line. Additionally, did I mention that there is a chance to win some delicious prizes? Let's work together to unravel this exciting journey! https://wwwwalgreenslistenscom.cfd/
With millions of customers each month, Aldi Weekly Ad is a quickly growing supermarket business in the United States. ALDI is rapidly growing into one of the biggest grocery stores in the United States, with about 2,000 locations spread across 36 states.
Aldi's weekly advertisements have established a reputation for providing high-quality products at reasonable costs. Get the most recent information about the Aldi weekly ad here.

Check out this week's complete ✳️ Food Lion Weekly Ad and next week's Food Lion Ad! Go read the Food Lion Weekly Circular from cover to cover. Prepare your coupons for the early Food Lion deals and schedule your shopping trip in advance!
This week's Food Lion sales ad is really simple to look at. To make it simple to determine if the item you're looking for at the Food Lion grocery shop is on sale or not, the sales are divided into different categories.

A recent visit's receipt and a few minutes of your time are all you need. Let's talk about how to participate, the guidelines, and the importance of your viewpoint. https://weisfeedback.boats/

This incentive helps the store improve daily by encouraging consumers to provide candid comments. https://talktogiantfoods.boats/

As part of its official Customer Satisfaction Survey, it is asking customers to provide input. Gaining more insight into the opinions of customers regarding the whole experience and service they received during their visit is the aim. https://talktohannafordcom.boats/

is the best place for you to leave reviews and improve your Whataburger experience. Burger lovers all throughout the country have made Whataburger their favorite because of its flawlessly prepared, juicy, and fresh burgers. https://whataburgervisit.cam/

The official Pollo Tropical survey site, Pollolistens.com, was created to collect consumer input and improve the eating experience. https://pollolisten.boats/

To provide feedback, go to www.thefreshmarketsurvey.com if you have recently shopped at Fresh Market. Enhancing their services and products is made possible by the Fresh Market Survey. https://thefreshmarketsurvey.boats/

Use MyWingstopSurvey to provide comments on your most recent Wingstop experience. By taking part, you may enhance their service and have a better future dining experience. https://wingstopcomsurvey.click/

Enhancing the customer experience is the goal of the Pep Boys Survey. Participation enables the team to efficiently enhance car maintenance and repair services. https://pepboyssurveyus.boats/

An easy option for people to share their buying experiences is through TellMurphyUSA. Customer happiness and service quality are successfully enhanced by the Murphy Guest Survey. https://tellmurphyusa.boats/

By using the T.J. Maxx Survey to provide feedback, you can demonstrate that the organisation values your thoughts. Your suggestions enable them to better assist you. https://www-tjmaaxxfeedbackk.boats/

In states like New Jersey, people have grown to rely on AcmeMarkets, a reputable grocery chain in the Northeastern United States. https://acmemarketssurveyus.boats/

Visit this link to view the most recent Ralphs Weekly Ad! You can either go through this week's Ralphs Weekly Sales Ad or select a different date to see one.
Each Ralphs Weekly Circular's dates are mentioned, making it simple to choose which one to view.

By completing TellBrueggers' Bruegger's Bagels Survey, you can directly improve the quality of the food, speed of service, and general customer experience at their locations. https://tellbrueggers.boats/

PublixSurvey is an online customer satisfaction survey created by Publix Super Markets. The primary goal of the survey is to collect feedback from customers about their shopping experiences at Publix stores. https://publixsurvey.site/
By participating in the survey, customers help Publix understand areas of improvement and maintain high standards of customer service. The feedback is crucial for enhancing store operations, staff training, and customer satisfaction. https://publixsurvey.site/how-to-take-publix-customer-survey/

Do not forget to complete the Kroger Survey if you have lately shopped at Kroger. Your frank viewpoint counts and has the potential to truly impact the situation. https://wwwkrogerfeedbackcom.cfd/

Check out this week's entire ✳️ Ingles Weekly Ad and next week's Ingles Ad! To view every page of the Ingles weekly ad circular, use the left and right arrow keys.
Prepare your coupons for the early Ingles weekly ad preview and plan your shopping trip in advance. Make sure you are seeing all of the latest Ingles weekly promotions by returning frequently.

You can provide Jack in the Box with feedback and assist them in improving their goods and services by completing this quick and simple survey on jacklistens. Who doesn't enjoy receiving complimentary tacos? To take advantage of this opportunity, please complete the survey as soon as you can.
https://jaklistenscom.store

The CVS Survey is simple to complete. To give honest feedback, simply go to www.cvshealthsurvey.com, enter the information from your receipt, and respond to a few questions. https://cvshealth-survey.cfd/
CVS appreciates your contributions. When you visit a pharmacy or retail store next, fill out the CVS Survey at www.cvshealthsurvey.com to help them serve you better. https://cvshealth-survey.cfd/

With millions of customers each month, Aldi Weekly Ad is a quickly growing supermarket business in the United States. ALDI is rapidly growing into one of the biggest grocery stores in the United States, with about 2,000 locations spread across 36 states.
Aldi's weekly advertisements have established a reputation for providing high-quality products at reasonable costs. Get the most recent information about the Aldi weekly ad here.
Check out this week's complete Food Lion Weekly Ad and next week's Food Lion Ad! Go read the Food Lion Weekly Circular from cover to cover. Prepare your coupons for the early Food Lion deals and schedule your shopping trip in advance!
This week's Food Lion sales ad is really simple to look at. To make it simple to determine if the item you're looking for at the Food Lion grocery shop is on sale or not, the sales are divided into different categories.

Explore a pretty collection of trendy girls dresses for wedding for your kids girls online in India at MiniStitch, an exclusive kidswear brand. https://ministitch.in/
See the full Jewel Osco Weekly Ad this week and the ✳️ Jewel Osco Ad the following week! Examine every page of the Jewel Osco weekly ad circular.
Get your coupons ready for the early Jewel Osco weekly ad preview, which features some Jewel Osco weekly ad bogo deals! Return often to ensure you are seeing all of the most recent Jewel Osco weekly discounts.

sI appreciate you sharing the Winn-Dixie Weekly Ad. To find the finest bargains, I always look at these before I go shopping. This preview website is quite helpful if you prefer to check the offerings for the upcoming week beforehand.

Go to RossListens.com to complete the Ross Survey, give your candid thoughts, and enter a drawing to win a $100 or $1000 Ross gift card. https://rosslistenss.cfd/

Why enter now? Everything from the merchandise on the shelf to the smiles at the register is shaped by your input, which is like a superpower. https://kolsfeedbackcom.cfd/

I found the BagelExperience.com Bagel Survey to be enjoyable. In addition to being simple and easy to use, it gives you coupons for your next delectable visit or free bagels. https://bagelexperience.cfd/
I found the BagelExperience.com Bagel Survey to be enjoyable. In addition to being simple and easy to use, it gives you coupons for your next delectable visit or free bagels. https://bagelexperience.cfd/
Check out the complete ✳️ Winn Dixie Sale Ad for this week and the Winn Dixie Ad Preview for next week! To view every page of the Winn Dixie Weekly Flyer, use the left and right arrow keys. We appreciate Sam alerting us to the early advertisement!
Prepare your coupons for the early Winn Dixie weekly circular and plan your shopping trip in advance! Make sure you are viewing all of the latest Winn Dixie weekly discounts by returning frequently.
Check out this week's complete Smart and Final Weekly Ad and next week's Smart and Final Ad! To view every page of the Smart and Final weekly ad circular, use the left and right arrow keys. Prepare your coupons for the early Smart and Final weekly ad preview and plan your shopping trip in advance!
Perusing the Smart and Final weekly flier is a breeze. This week's Smart and Final sales are divided into categories to make it simple to determine if the item you're looking for is on sale or not. Check out the Smart and Final advertisement the following week, regardless of the goods you wish to purchase.
Check out this week's complete Food Lion Weekly Ad and next week's Food Lion Ad! Go read the Food Lion Weekly Circular from cover to cover. Prepare your coupons for the early Food Lion deals and schedule your shopping trip in advance!
This week's Food Lion sales ad is really simple to look at. To make it simple to determine if the item you're looking for at the Food Lion grocery shop is on sale or not, the sales are divided into different categories.
Make sure you are viewing all of the latest Food Lion weekly promotions by returning frequently.

Surely, we all enjoy a nice game? There are certain simple guidelines in the White Castle Survey to ensure that everyone participates fairly and that the responses are sincere. https://whitecastlesurveys.autos/

Advice for pros: to access the official survey, go directly to Pandaexpress.com/feedback. You are far too valuable to give your opinions (and personal information) to any dubious impersonation websites. https://pandaexpresscomfeedback.autos/survey/

Panda Express uses the PandaGuest Experience Survey to improve their offerings and customer service. You receive a complimentary entrée in addition to helping to build better dining experiences. https://pandaguestexperience.bond/

You can think of it as a dialogue with Hollister. What went well on your most recent shopping excursion, what could be improved, https://tellhcocom.boats/

Wingstop has amazing flavours! Sharing my opinions about Wingstop's incredible wings and service was made simple and quick by the Wingstop.com/survey survey. https://mywingstopsurveys.cfd/

Still more awesome? Certain surveys, depending on the time and place, enter you into a $1,000 gift card contest. Just five minutes and a few clicks will allow you to express your candid opinions. https://bargainshoplistens.cfd/

Check out this week's entire Ingles Weekly Ad and next week's Ingles Ad! To view every page of the Ingles weekly ad circular, use the left and right arrow keys.
Prepare your coupons for the early Ingles weekly ad preview and plan your shopping trip in advance. Make sure you are seeing all of the latest Ingles weekly promotions by returning frequently.
Looking through the Ingles weekly flyer is a breeze. This week's Ingles sales are broken down into categories to make it simple to determine if the item you're looking for is on sale or not. regardless of the goods you choose to purchase.

I loved my free Dilly Bar reward from DQFanFeedback.com, and the brief form made providing feedback enjoyable. https://dqfanfeedbackcom.autos/

Coffee lovers and fans of convenience stores, hello! Perhaps you should stay if you recently stopped by Wawa for a quick dinner or coffee. https://mywawavisits.boats/

To improve their Dunkin' Doughnuts experiences, customers can voice their thoughts about the food quality, cleanliness, and service by visiting DunkinRunsOnYou.com. https://dunkinrunsonyouu.bond/

MyBKExperience is Burger King's official customer feedback platform designed to help the fast-food giant improve its service and customer satisfaction. https://mybkexperiencee.online/

In order to participate in Little Caesars Listens, customers must have a recent receipt. Quick, available in English and Spanish, and available to U.S. citizens aged 18 and over. https://littlecaesarslistenss.autos/

Waitrosehaveyoursay.com is used to get feedback on staff and store quality through the I Hope Survey. In-depth feedback leads to significant improvements that improve everyone's overall shopping experience. https://waitrosehaveyoursaycom.cfd/

The Ihope Survey asks recent clients to evaluate the level of care, relationships with personnel, and cleanliness of the facility. It is connected to Banfield's customer satisfaction initiatives. It's a rapid way to express views that raise the bar for pet healthcare requirements everywhere. https://tellbanfield.autos/
Aldi Weekly Ad is a rapidly growing grocery company in America, servicing millions of customers each month. With nearly 2,000 shops in 36 states, ALDI is rapidly becoming one of the top supermarket retailers in the United States.
Aldi weekly advertising are well-known for setting high standards in terms of quality and affordability. Get the most recent updates on Aldi's weekly ad here.

Check out this week's complete ✳️ Publix Weekly Ad and next week's Publix Ad preview! Go through the Publix weekly ad circular from cover to cover.
Depending on your store, the new ad will run for one week starting on either Wednesday or Thursday. Make sure to check your store's schedule. Get your coupons ready for the early ✳️ Publix weekly ad preview, which includes certain Publix weekly ad bogo discounts, and plan your shopping trip in advance!
This week's Whole Foods advertisement is really simple to look through. The sales are sorted into categories so that it is easy to discern if the product you are looking for at Whole Foods supermarket store is on sale or not. To avoid going over budget, make sure to check the Whole Foods weekly ad for the upcoming week to see if the product you want to purchase is on sale.

I thought about my last order when I took the Church's Chicken Survey: crispy, succulent chicken tenders with fresh fried okra on the side. It all came hot and precise. The team's effectiveness made a hectic day into a delicious treat. Five starred! https://churchschickenfeedbackk.click/

After getting a fast Jumbo Jack combo, I recently completed the JackListens survey. The drive-thru service was prompt, and the meal was hot and fresh. https://jacklistensc0m.click/

I like how Walgreens offers a large variety of over-the-counter treatments. I saved time during a hectic errand run thanks to the staff's warm greets and helpful assistance finding products. https://walgreenslistens.autos/

Check out this week's complete ✳️ Dollar General Weekly Ad and next week's ✳️ Dollar General Ad! Go through the entire Dollar General weekly sales advertisement. Prepare your coupons for the upcoming weekly ad from Dollar General! The images are courtesy of Laney Saves.
Browse the Dollar General ad preview and find the best offers to save a lot of money! Don't pass up the fantastic deals in the weekly flyer from Dollar General!
It's quite simple to look through the Dollar General weekly sales advertisement. To make it simple to determine if the item you're looking for is on sale or not, Dollar General's sales are divided into categories.

See this week's complete ✳️ Walgreens Weekly Ad and next week's ✳️ Walgreens Ad! Go through the entire Walgreens advertisement scan. Prepare for the upcoming Walgreens sales advertisement!
Looking through the Walgreens Circular is a breeze. To make it simple to determine if the product you're looking for is on sale or not, Walgreens' sales are broken down into categories. To avoid going over budget, always check the Walgreens weekly circular to see if the product you want to buy is on sale.
Look through this week's Walgreens ad to find the best discounts and save a ton of money!

Thank you for the rewards program. Every month, it truly saves me money. The store is consistently supplied and clean. https://walgreenslistenssurvey.cfd/
이 글에서는 널리 사용되고 있는 자바스크립트 기반 빌드 도구들을 프로파일링해 성능 문제를 찾고 이를 해결한 방법을 소개하고 있습니다. 어떤 부분이 성능 문제를 유발했고, 이를 어떻게 해결했는지 살펴보며 진행중이신 프로젝트를 한 번 점검해 보시는 것도 좋을 것 같습니다. Dollar General Customer Satisfaction Survey