TL;DR: 이 글에서는 <HighTable> 리액트 컴포넌트에서 사용하는 수직 스크롤 관련 다섯 가지 기법을 소개합니다. 이 컴포넌트는 좋은 성능과 접근성을 유지하면서 수십억 행의 테이블을 표시할 수 있습니다.

긴 글이지만, 이는 브라우저에서 수십억 행을 렌더링하는 것의 복잡성과 이 리액트 컴포넌트를 만들기 위해 들인 노력을 반영합니다.
목차
소개
HTML 테이블에 데이터를 표시하는 것은 HTML 기초 과정에서 가장 먼저 만나게 되는 연습 문제 중 하나입니다.
<table>
<thead>
<tr><th>Name</th><th>Age</th></tr>
</thead>
<tbody>
<tr><td>Alice</td><td>64</td></tr>
<tr><td>Bob</td><td>37</td></tr>
</tbody>
</table>하지만 데이터 과학에서 흔히 그렇듯, 단순한 경우에 잘 작동하는 것이 규모가 커지면 깨지기 마련입니다.
이 글에서는 <HighTable> 리액트 컴포넌트에서 수십억 행을 다루기 위해 수직 스크롤 관련 문제를 해결하는 데 사용하는 다섯 가지 기법을 소개하겠습니다.
이 컴포넌트는 열(정렬, 숨기기, 크기 조절), 행(선택), 셀(키보드 탐색, 포인터 상호작용, 커스텀 렌더링)에 대한 기능도 제공합니다. 더 알고 싶으시다면 언제든 질문하거나 코드를 살펴보세요.
<HighTable> 컴포넌트는 hyparam/hightable에서 개발되고 있습니다. Kenny Daniel이 Hyperparam을 위해 만들었으며, 저는 1년간 개발에 기여할 기회가 있었습니다.
이 블로그 글은 Hyperparam의 후원을 받았습니다. 지원해 주셔서 감사드리며, 브라우저에서 수십억 행을 렌더링하는 흥미로운 문제에 도전할 수 있게 해 주셔서 감사합니다!
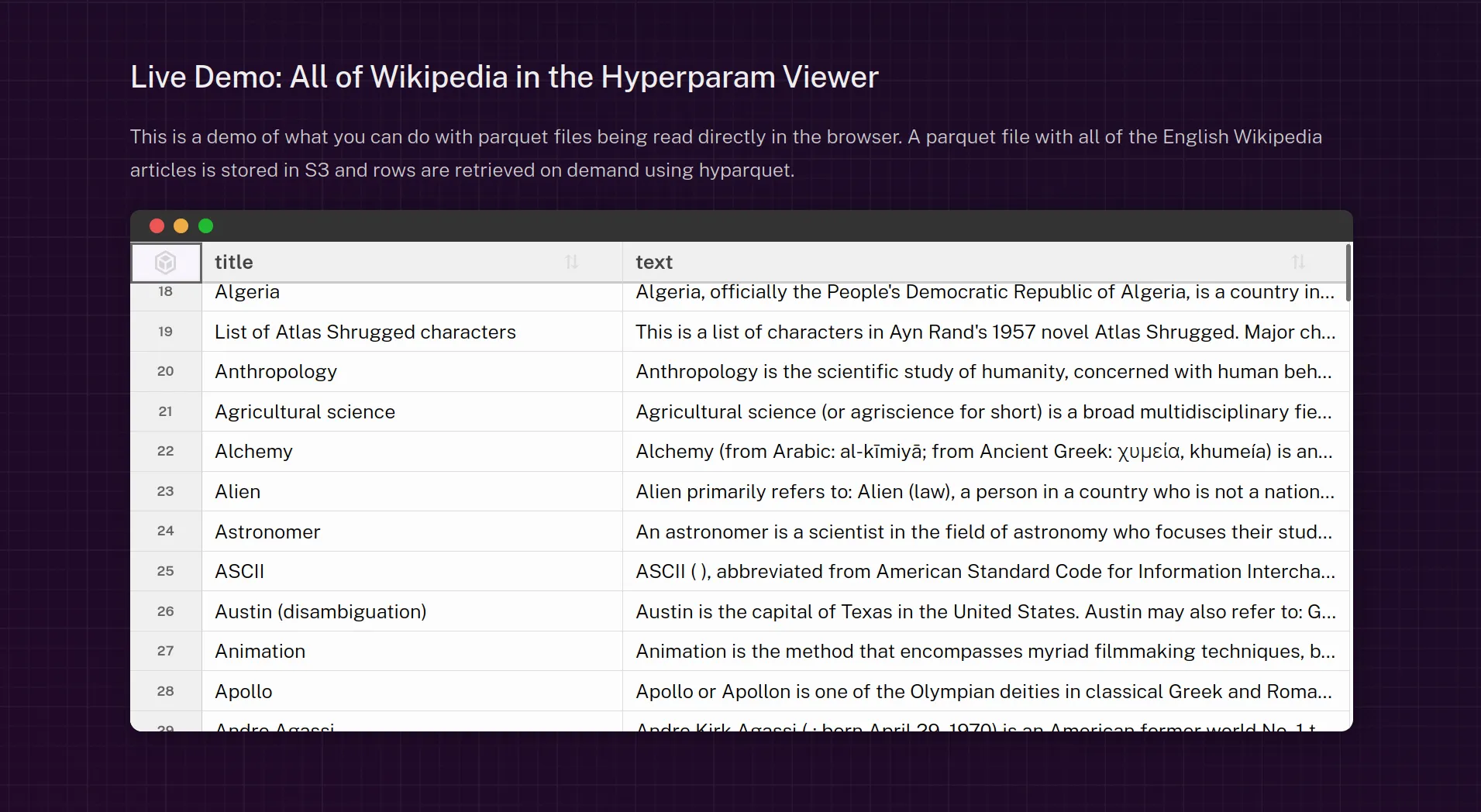
데모
hightable 데모를 직접 사용해 보세요.
HighTable은 Parquet 뷰어, source.coop, 그리고 Hyperparam에서도 사용됩니다.
스크롤링 기초
기법들을 살펴보기 전에, 표준 HTML 테이블에서 스크롤이 어떻게 동작하는지 알아보겠습니다.
HTML 구조는 viewport라고 부르는 스크롤 가능한 컨테이너와 그 안의 table 요소로 구성됩니다.
<div class="viewport" style="overflow-y: auto;">
<table class="table">
...
</table>
</div>이 구조에서 viewport는 고정 높이를 가진 div이며, CSS 속성 overflow-y: auto는 table이 viewport보다 높을 때 수직 스크롤바를 활성화합니다.
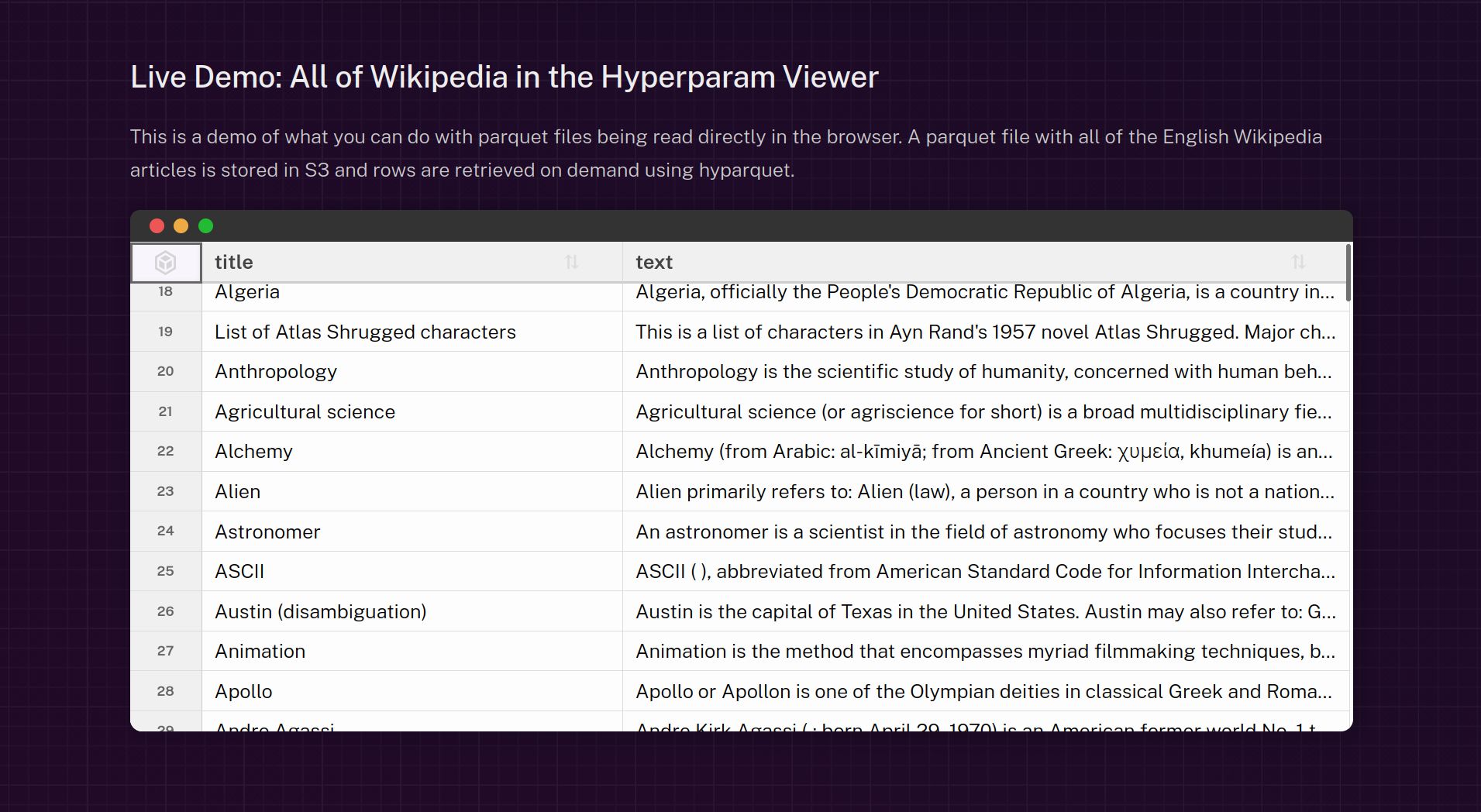
다음 위젯에서 왼쪽 상자를 위아래로 스크롤하여 오른쪽 상자가 스크롤 효과를 모방하는 것을 확인하세요.
키보드를 사용하는 경우, Tab으로 왼쪽 상자에 포커스를 맞추고, 화살표 키 ⏶와 ⏷로 스크롤할 수 있습니다. 그 외에 마우스 휠, 스크롤바 드래그, 터치 스크린에서 손가락으로 스크롤할 수 있습니다.
컴포넌트는 고정 크기의 viewport(파란색 테두리)로 구분됩니다. table(금색 테두리)은 컨테이너 안에 렌더링됩니다. table의 height가 viewport의 height보다 크므로 일부만 보이며, 수직 스크롤바를 통해 보이는 부분을 변경할 수 있습니다. 내부 table element가 viewport 안에서 위아래로 움직이면서 스크롤 효과를 만들어냅니다.
오른쪽에서는 viewport에 대한 table의 상대적 위치를 보여주며 스크롤 효과를 모방합니다.
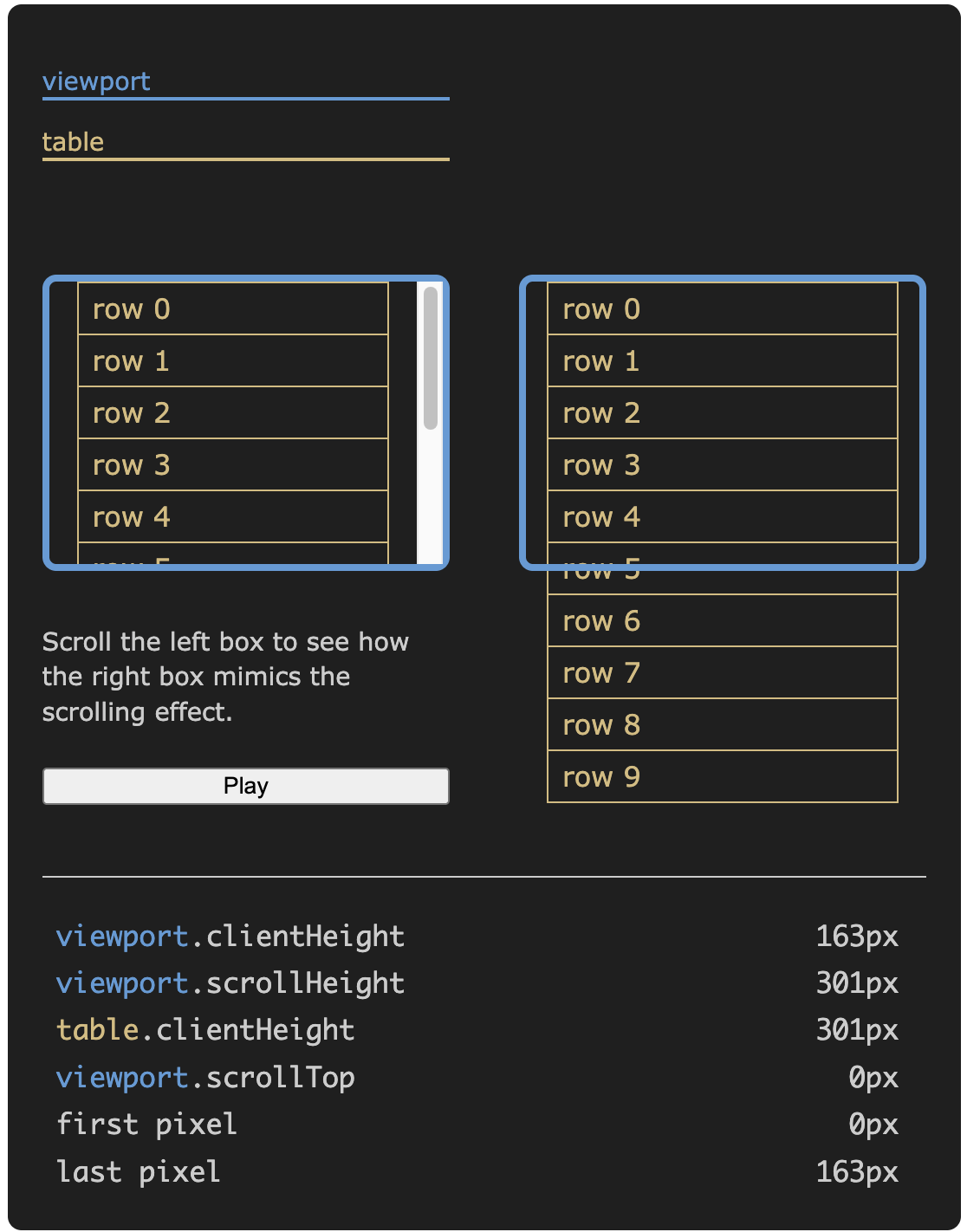
이후에 유용하게 쓰일 몇 가지 정의와 공식을 정리해 보겠습니다.
-
이 글에서는 보이는 영역의 높이인
viewport.clientHeight가 일정하다고 가정합니다. hightable에서는 이 값을 측정하고 리사이즈에 반응합니다. -
스크롤 가능한 콘텐츠의 전체 높이인
viewport.scrollHeight는table.clientHeight와 같습니다. 둘 다 테이블의 행 수에 행 높이를 곱한 값과 같습니다.
const rowHeight = 33 // 픽셀 단위
const numRows = data.numRows // 테이블의 전체 행 수
const height = numRows * rowHeight이 글에서는 행 높이와 행 수가 일정하다고 가정합니다. hightable에서는 data.numRows(테이블 데이터를 담는 자료 구조인 데이터 프레임의 행 수) 변경에 반응합니다. 예를 들어 필터링 시에 말입니다. 하지만 행 높이는 고정이라고 가정합니다(가변 행 높이를 지원하려면 이슈 #395를 참고하세요).
-
viewport.scrollTop은 스크롤 컨테이너 콘텐츠의 상단과 뷰포트 상단 사이의 픽셀 수입니다. 최솟값0px은 테이블 상단을 보여주고, 최댓값viewport.scrollHeight - viewport.clientHeight에서 테이블 하단에 도달합니다. -
보이는 픽셀은 뷰포트 스크롤 상단 위치로부터 계산할 수 있습니다.
const firstVisiblePixel = viewport.scrollTop
const lastVisiblePixel = viewport.scrollTop + viewport.clientHeight
// firstVisiblePixel은 포함(inclusive), lastVisiblePixel은 제외(exclusive)기본 사항을 알았으니, 대규모 데이터셋을 처리하는 방법을 살펴보겠습니다.
기법 1: 지연 로딩
대규모 데이터셋을 다룰 때 첫 번째 문제는 브라우저 메모리에 전부 담을 수 없다는 것입니다. 좋은 소식은 모든 행을 동시에 보고 싶어하지도 않을 것이라는 점입니다. 따라서 시작할 때 전체 데이터 파일을 로딩하는 대신, 보이는 셀만 로딩합니다.
데이터를 지연 로딩한다고 해서 테이블의 HTML 구조가 바뀌지는 않는다는 점에 유의하세요.
다음 위젯은 지연 로딩이 어떻게 동작하는지 보여줍니다. 왼쪽 상자를 위아래로 스크롤하여 오른쪽에서 셀이 필요에 따라 로딩되는 것을 확인하세요.
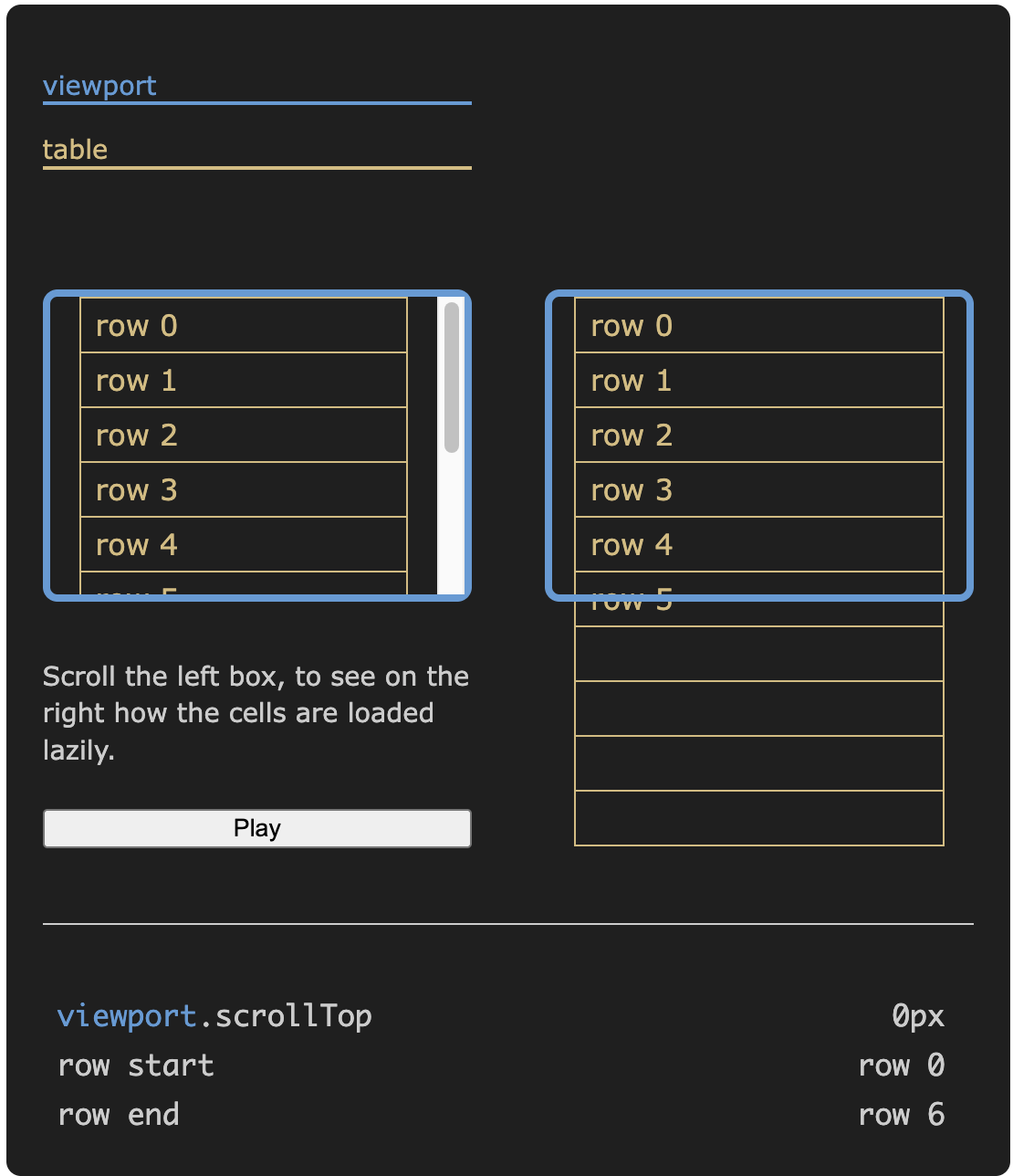
테이블에서 보이는 셀만 로딩됩니다. 스크롤할 때 새로 보이는 셀이 요청되고 백그라운드에서 로딩되며, 사용 가능해지면 렌더링됩니다.
이를 위해 보이는 행을 계산하고 해당 행만 로딩합니다.
const rowStart = Math.floor(firstVisiblePixel / rowHeight)
const rowEnd = Math.ceil(lastVisiblePixel / rowHeight)
// rowStart는 포함(inclusive), rowEnd는 제외(exclusive)hightable에서 데이터 로딩 로직은 리액트 컴포넌트에 data prop으로 전달되는 데이터 프레임에서 처리됩니다.
<HighTable data={data} />데이터 프레임은 필요에 따라(즉, 가져오기와 캐싱을 통해) 데이터를 로딩하는 방법과 렌더링을 위해 로딩된 데이터를 가져오는 방법을 정의하는 객체입니다. types.ts에서 DataFrame TypeScript 정의를 확인할 수 있습니다.
다음은 하나의 열에 대해 랜덤 데이터를 생성하고, 네트워크를 통한 데이터 가져오기를 시뮬레이션하기 위해 지연을 적용하며, 메모리에 값을 유지하는 간소화된 DataFrame 구현입니다.
const cache = new Map()
const eventTarget = new EventTarget()
const numRows = 1_000_000
const data = {
numRows,
eventTarget,
// 캐시된 값을 동기적으로 반환 (있는 경우)
getCell({ row }) {
return cache.get(row);
},
// 주어진 행에 대해 누락된 값을 로딩하고 캐시
async fetch({ rowStart, rowEnd }) {
// 네트워크 지연 시뮬레이션
await new Promise((resolve) => setTimeout(resolve, 100));
for (let row = rowStart; row < rowEnd; row++) {
// 이미 캐시된 행은 건너뛰기
if (cache.has(row)) continue;
// 셀에 대한 랜덤 값을 생성하고 캐시
cache.set(row, {value: Math.random()});
}
// <HighTable>에 보이는 셀을 다시 렌더링하라고 알리는 이벤트 발생
eventTarget.dispatchEvent(new Event('resolve'));
},
}데이터 프레임은 비동기 data.fetch() 메서드를 사용하여 소스로부터 데이터를 로딩합니다. 결과를 캐시해야 하며, 새 데이터가 사용 가능해지면 resolve 이벤트를 디스패치해야 합니다. 소스는 무엇이든 될 수 있습니다. 예제에서는 데이터가 랜덤으로 생성되었습니다. 로컬 파일, 인메모리 배열, 원격 파일(HTTP 범위 요청 사용), REST API 등에서도 가져올 수 있습니다.
데이터 프레임은 또한 주어진 셀의 캐시된 데이터를 가져오거나, 아직 로딩되지 않은 경우 undefined를 반환하는 동기 data.getCell() 메서드를 제공해야 합니다.
스크롤할 때마다 테이블이 렌더링되면서 보이는 행에 대해 data.getCell()을 호출하고, 필요한 경우 백그라운드에서 로딩하기 위해 data.fetch()도 호출합니다(데이터가 이미 캐시되어 있으면 빠르게 반환하는 것은 데이터 프레임의 책임입니다). 새 데이터가 로드되어 resolve 이벤트가 발생될 때마다 테이블이 다시 렌더링됩니다.
원격 Parquet 파일을 (HTTP 범위 요청을 사용하여) 로딩하는 데이터 프레임의 더 완전한 예시는 hyparquet 데모에서 찾을 수 있습니다.
데이터 프레임 구조는 행이나 열 지향이 아니며, 셀 단위로 데이터를 로딩하고 접근할 수 있습니다. 현재 hightable에서는 전체 행을 로딩하지만, 보이는 열을 계산하여 열도 지연 로딩하도록 개선할 수 있습니다. 이 기능에 관심이 있다면 진행 중인 논의에 참여해 주세요.
지연 로딩의 효과
100억 행이 있고 행당 100바이트라고 가정하면 전체 데이터 크기는 1TB입니다. 전체를 메모리에 로딩하는 것은 불가능하지만, 지연 로딩을 사용하면 보이는 부분(한 번에 약 30행)에 대해 3KB만 로딩하면서도 좋은 성능을 유지할 수 있습니다.
데이터를 지연 로딩하는 것은 브라우저에서 대규모 데이터셋을 다루기 위해 필요한 첫 번째 단계입니다. 다음 단계는 한 번에 너무 많은 HTML 요소를 렌더링하지 않는 것입니다.
기법 2: 테이블 슬라이스
소프트웨어 엔지니어링에서 최적화를 시도할 때 첫 번째 단계는 불필요한 연산을 제거하는 것입니다. 우리의 경우, 테이블에 100만 행이 있고 한 번에 30개만 볼 수 있다면, 왜 100만 개의 <tr> HTML 요소를 렌더링해야 할까요? 참고로 Chrome은 최적의 응답성을 위해 300개 미만의 HTML 요소를 생성하거나 업데이트할 것을 권장합니다.
<HighTable> 컴포넌트에서는 테이블의 보이는 행만 렌더링합니다. 나머지 행 요소는 단순히 존재하지 않습니다.
이를 위해서는 viewport와 table 사이에 canvas라고 부르는 중간 div 요소를 추가하여 HTML 구조를 수정해야 합니다.
<div class="viewport" style="overflow-y: auto;">
<div class="canvas" style="position: relative; height: 30000px;">
<table class="table" style="position: absolute; top: 3000px;">
<!-- 테이블은 보이는 행만 렌더링합니다 -->
...
</table>
</div>
</div>이 HTML 구조는 기법 3, 4, 5를 포함하여 이 블로그 글의 나머지 부분에서도 동일하게 유지됩니다.
canvas div는
<canvas>HTML 요소와는 전혀 관련이 없습니다. 혼동될 수 있으니, 더 좋은 이름이 있다면 제안해 주세요.
canvas는 모든 행을 포함할 수 있는 크기로 설정됩니다.
canvas.style.height = `${data.numRows * rowHeight}px`이렇게 하면 뷰포트 스크롤바가 예상 크기로 설정됩니다. 스크롤링 기초 섹션에서 보여준 것처럼, viewport.scrollHeight는 canvas.clientHeight와 같습니다.
canvas는 table slice를 절대 위치로 배치하기 위한 기준점 역할을 합니다.
다음 위젯은 테이블 슬라이싱이 어떻게 동작하는지 보여줍니다. 왼쪽 상자를 위아래로 스크롤하여, 오른쪽에서 보이는 행만 렌더링되면서 스크롤 효과를 모방하는 것을 확인하세요. full table 버튼을 토글하여 렌더링된 행이 full table에 어떻게 배치되는지 확인할 수 있습니다.
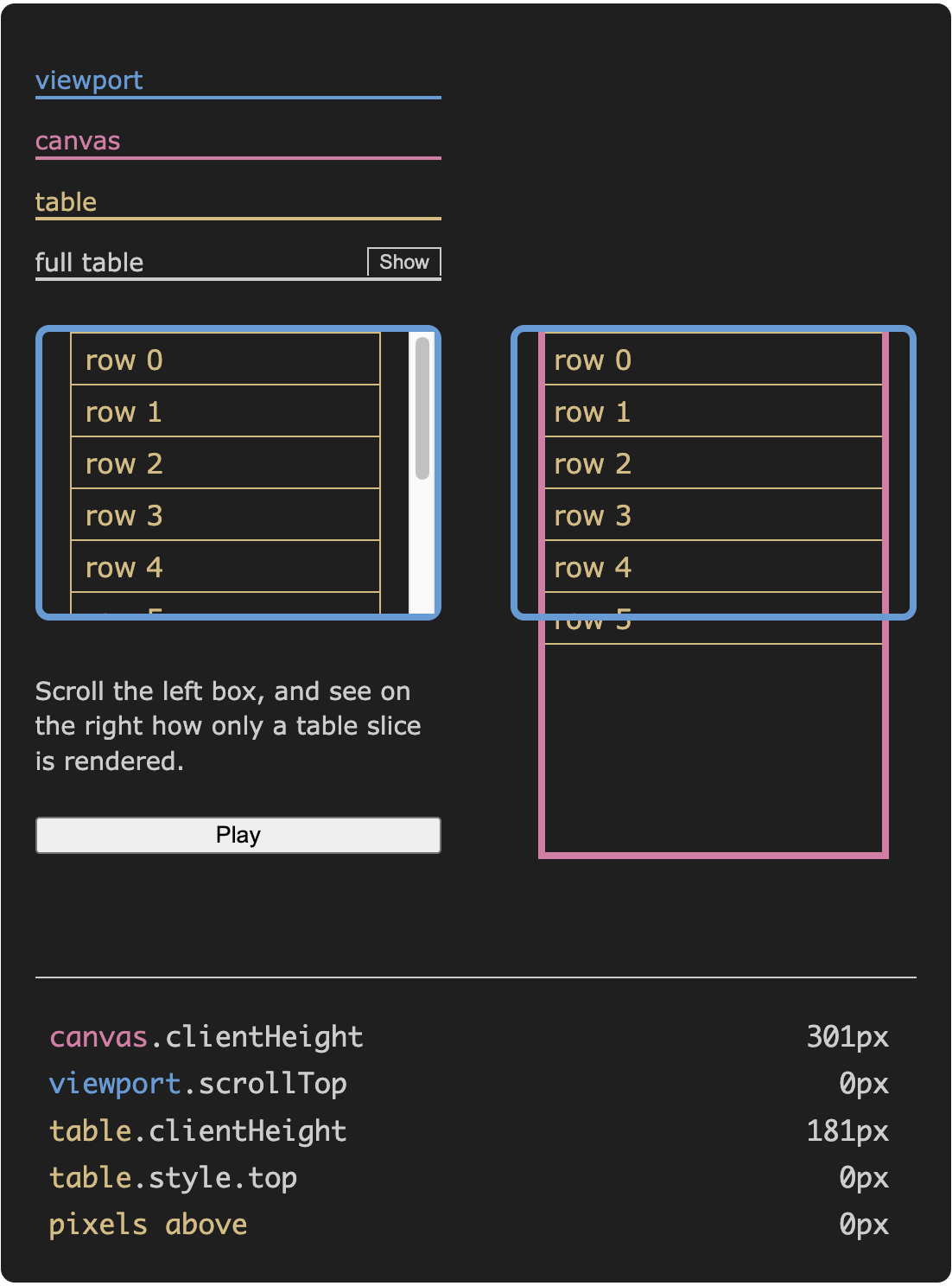
오른쪽에서는 보이는 행만 렌더링되는 것을 확인할 수 있습니다. table slice는 스크롤 위치에 따라 10개 대신 6개(또는 7개)의 행을 포함합니다.
테이블 슬라이스 내부의 HTML 구조는 다음과 같습니다.
<table>
<tbody>
<!-- 행 0~99는 렌더링되지 않음 -->
<!-- 보이는 행 -->
<tr>...행 100...</tr>
<tr>...행 101...</tr>
...
<tr>...행 119...</tr>
<!-- 행 120~999는 렌더링되지 않음 -->
</tbody>
</table>data에 1,000개의 행이 있고, 테이블의 각 행 높이가 30px이며, 뷰포트 높이가 600px(한 번에 약 20행이 보임)라고 가정해 봅시다. 사용자가 3,000px만큼 아래로 스크롤했다면, <HighTable>은 실제 <table> 요소에 100~119행만 렌더링합니다.
위의 HTML은 간소화된 것입니다. hightable에서는 테이블 헤더를 렌더링하고 스크롤링 경험을 개선하기 위해 보이는 행 전후에 패딩 행을 추가합니다.
테이블의 top 위치는 full table에 맞도록 조정됩니다(Show / Hide 버튼을 토글하면 full table을 렌더링합니다). 이 값은 가상 full table 안에서 첫 번째 보이는 행의 위치와 같습니다. viewport.scrollTop과 거의 같지만, 첫 번째 보이는 행 상단의 숨겨진 픽셀만큼 차이가 납니다. 따라서 다음과 같습니다.
table.style.top = `${
viewport.scrollTop - (viewport.scrollTop % rowHeight)
}px`;이 계산은 모든 스크롤 이벤트마다(그리고 뷰포트 높이가 변경되거나 행 수가 업데이트되는 등의 다른 변경이 있을 때마다) 수행됩니다. 계산이 완료되면 새로운 보이는 행으로 table slice가 다시 렌더링되고, 테이블 위치가 새로운 top 값으로 업데이트되며, 필요한 경우 새로운 보이는 셀을 로딩하기 위해 데이터 프레임에 쿼리합니다.
언급할 만한 세부 사항으로 sticky 헤더가 있습니다.
<HighTable>에서 열 이름이 있는 헤더는 별도의 요소가 아닌 table 요소의 일부로<thead>에 렌더링됩니다. 이는 접근성에 도움이 됩니다. 스크린 리더가 각 데이터 셀과 연관된 헤더 셀을 쉽게 식별할 수 있고, 열 크기 조절 시에도 헤더와 데이터 셀이 브라우저에 의해 자동으로 정렬됩니다. CSS 속성position: sticky(MDN의 sticky 참고) 덕분에 스크롤할 때 헤더 행이 뷰포트 상단에 계속 보입니다. 첫 번째 보이는 행을 계산할 때 이를 고려합니다.
테이블 슬라이싱 기법은 수직 스크롤에만 국한되지 않습니다. 수평 스크롤에도 같은 접근 방식을 사용할 수 있습니다(보이는 열만 렌더링). 일반적으로 테이블은 행보다 열이 적기 때문에 덜 중요합니다. 이 기능에 관심이 있다면 진행 중인 가상 열에 대한 논의에 참여해 주세요.
테이블 슬라이싱의 효과
100억 행이 있고 한 번에 30행이 보인다고 가정하면, 100억 개 대신 30개의 HTML 요소만 렌더링합니다. 렌더링되는 요소 수가 일정하므로, 행 수에 관계없이 좋은 성능을 유지할 수 있습니다.
지금까지는 꽤 표준적인 내용이었습니다. 다음 기법들은 hightable에 더 특화된 것으로, 수십억 행을 다룰 때 발생하는 문제를 해결합니다.
기법 3: 무한 픽셀
기법 2는 완벽하게 작동합니다... 깨지기 전까지는요. Eric Meyer가 자신의 블로그 글 Infinite Pixels에서 설명하듯이, HTML 요소에는 최대 높이가 있으며 정확한 값은 브라우저에 따라 다릅니다. 최악의 경우는 Firefox로, 약 1,700만 픽셀입니다. canvas 높이는 행 수에 따라 증가하므로, 행 높이가 33px(hightable의 기본값)인 경우 50만 행을 초과하면 렌더링할 수 없습니다.
hightable에서 이 문제에 대한 접근 방식은 캔버스의 최대 높이를 설정하고 이 제한 이상에서는 스크롤바 해상도를 축소(downscale)하는 것입니다. hightable에서 임계값은 800만 픽셀로 설정되어 있습니다.
구체적으로, 임계값을 초과하면 스크롤된 1픽셀이 전체 테이블의 여러 픽셀에 해당하게 됩니다. 축소 배율(downscaling factor)은 전체 테이블의 이론적 높이와 캔버스의 최대 높이 사이의 비율입니다. 이 배율 덕분에 스크롤바를 절반만큼 스크롤하면, 테이블이 아무리 크더라도 전체 테이블의 중간에 도달합니다.
임계값 이하에서는 축소 배율이 1이므로 이전과 동일하게 동작합니다. 스크롤된 1픽셀이 전체 테이블의 1픽셀에 해당합니다.
축소 배율은 다음과 같이 계산됩니다.
const fullTableHeight = data.numRows * rowHeight
const maxCanvasHeight = 8_000_000
if (fullTableHeight <= maxCanvasHeight) {
downscaleFactor = 1
} else {
downscaleFactor = (fullTableHeight - viewport.clientHeight)
/ (maxCanvasHeight - viewport.clientHeight)
}이제 첫 번째 보이는 행은 다음과 같이 계산됩니다.
firstVisibleRow = Math.floor(
(viewport.scrollTop * downscaleFactor) / rowHeight
)그리고 테이블의 top 위치는 첫 번째 보이는 행을 뷰포트 상단에 맞추도록 설정됩니다.
table.style.top = `${viewport.scrollTop}px`;이를 통해 사용자는 수십억 행이 있어도 전체 테이블을 탐색할 수 있습니다.
다음 위젯은 스크롤바 축소가 어떻게 동작하는지 보여줍니다. 왼쪽 상자를 위아래로 스크롤하여, 오른쪽에서 100억 행을 탐색할 수 있는 스크롤 효과를 확인하세요.
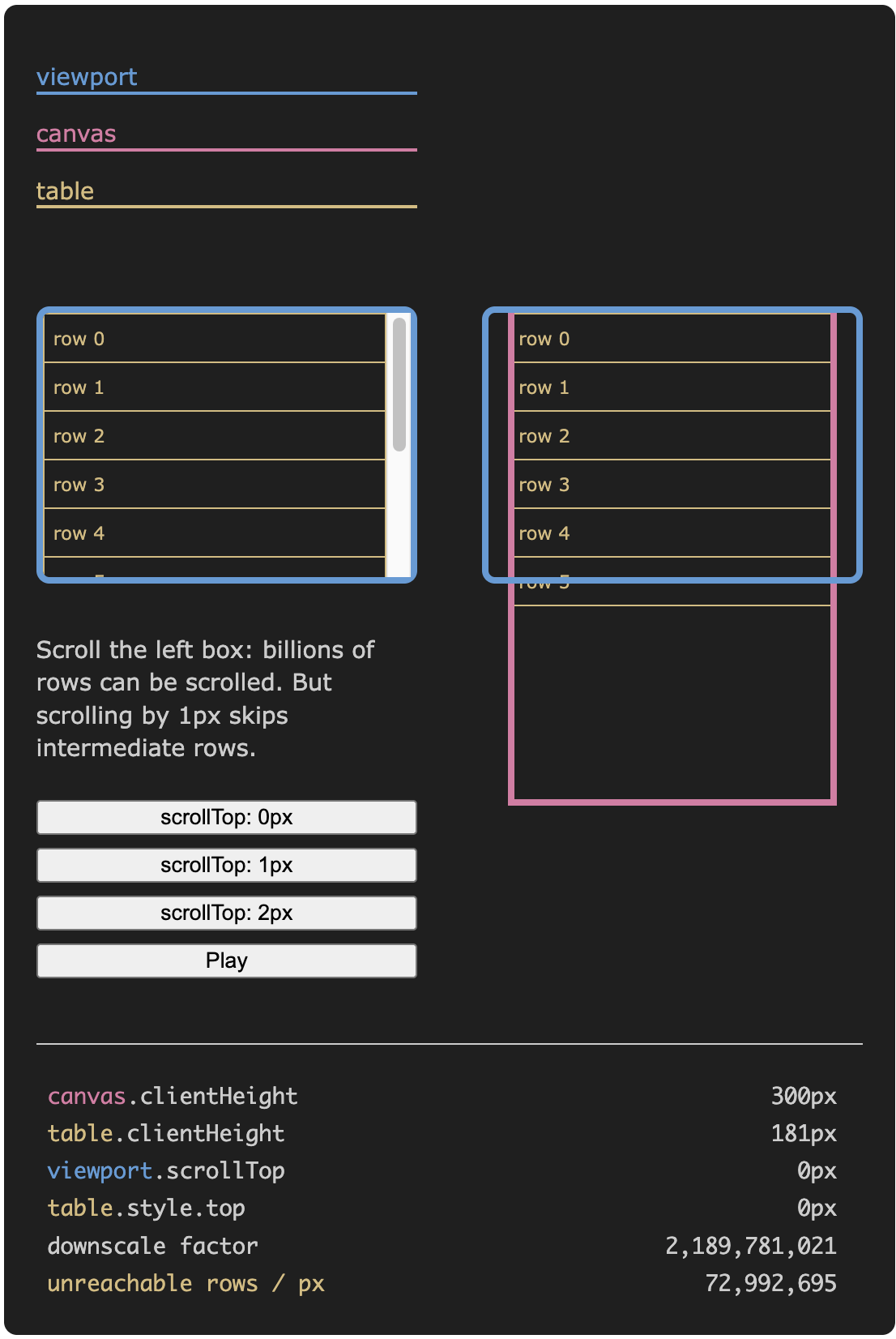
하지만 단점이 있습니다. 네이티브 스크롤바의 정밀도는 물리적 1픽셀로 제한됩니다. "고해상도" 화면에서는 겉보기 정밀도가 CSS 픽셀의 일부(1 / devicePixelRatio)가 됩니다. 하지만 단순화를 위해 1픽셀로 가정합시다.
여담으로, 프로그래밍 방식으로 스크롤 값을 설정하는 것은 예측하기 어렵습니다. 이는 장치 픽셀 비율에 달려 있고, 이 비율 자체는 줌에 따라, 그리고 아마도 다른 요인에도 달려 있습니다. 예를 들어,
element.scrollTo({top: 100})은scrollTop = 100,scrollTop = 100.23, 또는scrollTop = 99.89가 될 수 있습니다. 정확히 알 수는 없지만, 1픽셀 오차 범위 내입니다.
scrollTop값은 예상 범위를 벗어날 수도 있습니다. 예를 들어 음수이거나 최댓값scrollHeight - clientHeight보다 클 수 있습니다. 이런 브라우저별 오버스크롤 효과를 방지하기 위해, 스크롤 이벤트에 반응할 때 hightable은 항상scrollTop값을 예상 범위 내로 클램핑하고 CSS 규칙overflow-y: clip을 적용합니다.hidden대신clip을 사용하면 sticky 헤더가 표시되는데, 솔직히 정확한 이유는 모르겠습니다.
따라서 축소 배율이 크면(위 예제에서 2,189,781,021), 최소 스크롤 이동(1px)은 전체 테이블에서 2,189,781,021 픽셀에 해당합니다. 행 높이가 30px이면 최소 스크롤 이동이 약 72,992,701행에 해당합니다. 이로 인해 도달 가능한 행에 간격이 생깁니다.
viewport.scrollTop = 0이면 보이는 행은 0~5viewport.scrollTop = 1이면 보이는 행은 72,992,700~72,992,705viewport.scrollTop = 2이면 보이는 행은 145,985,401~145,985,406- 이런 식으로 계속...
예를 들어 6~10행으로 탐색할 방법이 없습니다. 6~10행에 도달하기 위해 viewport.scrollTop = 0.00000000274를 설정하는 것은 불가능합니다. 브라우저가 스크롤 위치를 가장 가까운 정수 픽셀로 반올림하기 때문입니다.
무한 픽셀의 효과
100억 행이 있다고 가정하면, 무한 픽셀 기법은 전체 행 범위를 탐색할 수 있게 해줍니다. 행 수에 제한이 없습니다. 캔버스 최대 높이에 맞추기 위해 항상 축소 배율을 늘릴 수 있기 때문입니다.
하지만 제한된 스크롤바 정밀도로 인해, 행 높이가 30px이고 캔버스가 8Mpx인 경우 스크롤된 픽셀당 테이블이 1,250행씩 이동합니다. 즉, 1,250행 중 하나의 행(과 그 이웃)만 도달 가능합니다.
따라서 무한 픽셀 기법은 수십억 행에 대한 전역 탐색을 제공합니다. 하지만 세밀한 스크롤을 허용하지 않으며, 일부 행은 도달 불가능합니다. 기법 4가 이 문제를 해결합니다.
기법 4: 픽셀 단위 정밀 스크롤
이전 기법은 파일 전체를 전역적으로 스크롤할 수 있게 해주지만, 모든 스크롤 제스처가 도달 불가능한 행의 간격을 뛰어넘어 버리기 때문에 사용자가 로컬 스크롤을 할 수 없게 됩니다.
이를 해결하기 위해 로컬과 전역, 두 가지 스크롤 모드를 구현합니다. 로컬 스크롤은 테이블 슬라이스를 픽셀 단위로(즉, 행 단위보다 더 정밀하게) 스크롤하는 것을 의미하고, 전역 스크롤은 스크롤바가 가리키는 위치로 점프하는 것을 의미합니다.
이 로직에는 세 가지 값을 가진 상태가 필요합니다. { scrollTop, globalAnchor, localOffset }
- 마지막 뷰포트 스크롤 top 값은 매 스크롤 이벤트마다 스크롤 이동량을 계산하기 위해 상태에 저장됩니다.
- 전역 앵커(global anchor)는 마지막 전역 스크롤에 해당하는 뷰포트 스크롤 top 값입니다. 전역 스크롤할 때마다 업데이트되지만, 로컬 스크롤에서는 업데이트되지 않습니다.
- 로컬 오프셋(local offset)은 현재 스크롤 위치를 계산하기 위해 전역 앵커에 적용되는 오프셋입니다. 로컬 스크롤할 때마다 업데이트되며, 전역 스크롤 시 0으로 리셋됩니다.
첫 번째 보이는 행은 전역 앵커와 로컬 오프셋으로 계산됩니다.
const firstVisibleRow = Math.floor((
state.globalAnchor * downscaleFactor + state.localOffset
) / rowHeight)테이블의 절대 위치는 이제 다음과 같습니다.
table.style.top = `${viewport.scrollTop + state.localOffset}px`;매 스크롤 이벤트마다 스크롤 이동량(새로운 뷰포트의 스크롤 top과 상태에 저장된 이전 값의 차이)을 계산하고, 다음 중 무엇을 적용할지 결정합니다.
- 스크롤 이동이 큰 경우 전역 스크롤 — 보통 스크롤바 드래그 앤 드롭 시, 새로운 전역 위치로 점프합니다(기법 3).
- 스크롤 이동이 작은 경우 로컬 스크롤 — 예를 들어 마우스 휠을 사용할 때. 이 경우 상태의
globalAnchor값을 변경하지 않고(즉, 실제scrollTop값과 더 이상 동기화되지 않음)localOffset을 조정하여 이동이 로컬로 보이게 합니다(예: 3행 아래로).
코드로 표현하면 로직은 다음과 같습니다(간소화된 의사 코드).
const state = getState()
const delta = viewport.scrollTop - state.scrollTop
if (Math.abs(delta) > localThreshold) {
// 전역 스크롤
state.localOffset = 0
state.globalAnchor = viewport.scrollTop
} else {
// 로컬 스크롤
state.localOffset += delta
}
setState(state)이제 사용자는 현재 행 주변을 탐색할 수도 있고, 데이터의 어느 부분이든 점프할 수도 있습니다.
다음 위젯은 이중 스크롤 모드를 보여줍니다. 왼쪽 상자를 위아래로 스크롤하여, 오른쪽에서 100억 행을 로컬 및 전역으로 탐색할 수 있는 스크롤 효과를 확인하세요.
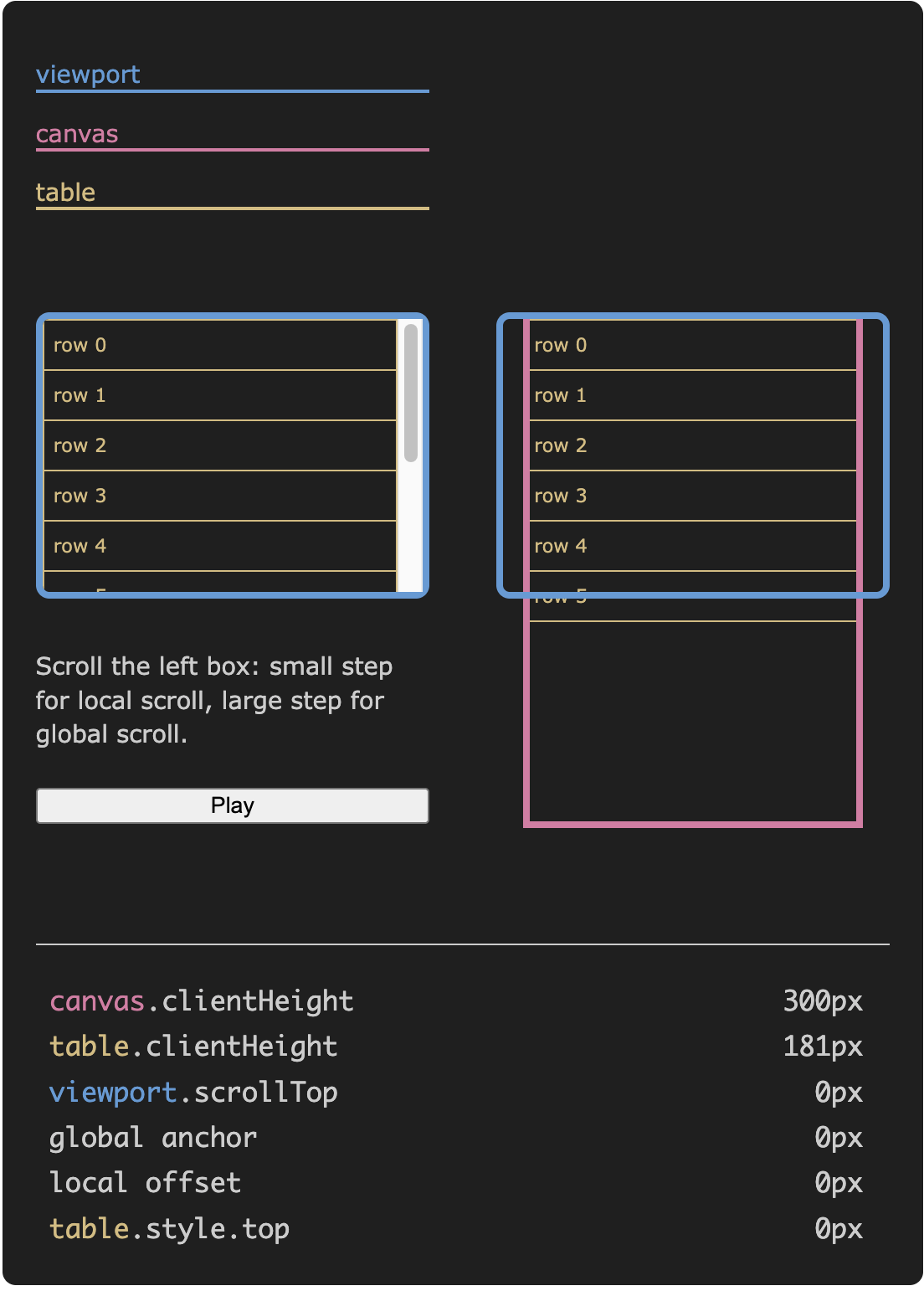
이 접근 방식에서는 작은 스크롤 이동은 로컬로 나타나고, 큰 스크롤 이동은 예상되는 전역 위치로 점프합니다. 사용자는 전체 테이블을 탐색하고 모든 행에 도달할 수 있습니다. 마우스 휠, 터치패드, 키보드(테이블에 포커스가 있을 때), 스크롤바 등 브라우저에서 기대하는 대로 스크롤할 수 있습니다.
픽셀 단위 정밀 스크롤의 효과
100억 행이 있다고 가정하면, 이중 스크롤 모드는 네이티브 스크롤바를 사용하여 full table의 어떤 픽셀에든 접근할 수 있게 합니다. 사용자는 마우스 휠로 로컬 스크롤을, 스크롤바를 드래그하여 전역 스크롤을 할 수 있습니다.
이는 full table의 높이가 최대 canvas 높이(hightable에서 8Mpx)의 제곱 미만일 때 동작하며, 이는 약 64조 픽셀에 해당합니다. 따라서 행 높이가 30px인 경우 약 2조 행까지 1px 정밀도가 보장됩니다.
이 제한을 넘으면 최소 스텝이 1px보다 커지지만, 64조 행까지는 여전히 모든 행에 도달할 수 있습니다! 그 이상에서는 일부 행이 도달 불가능해집니다.
마지막 과제는 로컬 대 전역 스크롤 모드를 신경 쓰지 않고, 키보드를 사용하든 "행으로 이동" 입력을 사용하든 프로그래밍 방식으로 임의의 셀로 이동하는 것(즉, 테이블의 어느 부분이든 랜덤 접근)입니다. 랜덤 접근은 수직 스크롤과 수평 스크롤의 분리를 필요로 합니다. 다음 섹션에서 설명합니다.
기법 5: 2단계 랜덤 접근
hightable의 요구 사항 중 하나는 키보드 탐색을 허용하는 것입니다(예: ↓로 다음 행으로 이동). 다행히 웹 접근성 이니셔티브(WAI)가 그리드 패턴과 데이터 그리드 예제를 통해 가이던스를 제공합니다. 포커스 처리를 위해 tabindex roving을 사용하며, 모든 기대되는 키보드 상호작용을 제공합니다.
브라우저는
cell.focus()를 호출할 때 유용한 기본 동작을 제공합니다. 자동으로 셀로 스크롤하고 포커스를 맞춥니다. 하지만 hightable에서는 이 기본 동작을 사용하지 않습니다. 셀을 뷰포트 중앙에 배치하는 동작이 자연스럽지 않기 때문입니다.기대되는 동작을 얻기 위해, 먼저 다음 행과 열을 보여주기 위한 최소한의 스크롤을
cell.scrollIntoView({block: 'nearest', inline: 'nearest'})으로 수행합니다. 그런 다음 스크롤 동작 없이cell.focus({preventScroll: true})로 포커스를 설정합니다.
안타깝게도 WAI 리소스에서 설명하는 키보드 탐색 기법은 전체 테이블을 위해 설계되었습니다. 하지만 기법 2(테이블 슬라이스), 3(무한 픽셀), 4(픽셀 단위 정밀 스크롤) 때문에 여러 단계가 필요합니다. 특히 사용자가 키보드로 활성 셀을 이동할 수 있도록 하기 위해 수직 스크롤 로직과 수평 스크롤을 분리합니다.
사용자가 활성 셀을 이동하면 최종 위치는 테이블 어디에든 있을 수 있습니다. ↓는 다음 행으로 이동하고, Ctrl+↓는 마지막 행으로 이동합니다. 이동이 크면 필요한 셀을 DOM에 넣기 위해 수직으로 스크롤해야 할 수 있습니다.
<HighTable>을 임베드하는 앱이 "행으로 이동" 기능을 제공하는 경우처럼 테이블의 임의의 행에 접근할 때에도 같은 문제가 발생합니다. 테이블은 로컬 대 전역 스크롤 모드나 수평 스크롤 위치를 신경 쓰지 않고 프로그래밍 방식으로 기대하는 행으로 스크롤하고 기대하는 열의 셀에 포커스해야 합니다.
과정은 다음과 같습니다.
- 필요한 셀의 행이 보이도록 만들 다음 상태(전역 앵커와 로컬 오프셋)를 계산합니다.
- 전역 앵커가 변경되었다면 프로그래밍 방식으로 새로운
scrollTop위치로 스크롤합니다. - 스크롤이 완료되면 테이블 슬라이스를 렌더링하여 필요한 셀을 DOM에 넣습니다.
- 필요한 경우
cell.scrollIntoView({inline: 'nearest'})로 수평 스크롤합니다. cell.focus({preventScroll: true})로 새 셀에 포커스를 설정합니다.
1번(다음 상태 계산)에서는 block: nearest 동작을 준수하여 스크롤 이동을 최소화합니다. 대상 행이 현재 뷰포트 아래에 있으면 다음 뷰포트에서 마지막 보이는 행이 됩니다. 위에 있으면 첫 번째 보이는 행이 됩니다. 이미 보이는 상태라면 수직 스크롤이 적용되지 않습니다.
수직과 수평 스크롤을 분리하기 위한 의사 코드는 프로그래밍 방식의 수직 스크롤 중에 수평 스크롤과 포커스를 방지하는 플래그가 필요합니다.
/* 셀 탐색 코드에서 */
const shouldScroll = state.update()
renderTableSlice()
if (shouldScroll) {
// 프로그래밍 방식 스크롤 중 수평 스크롤 + 포커스를 방지하는
// 플래그 설정
setFlag('programmaticScroll')
viewport.scrollTo({top: state.globalAnchor, behavior: 'instant'})
}/* 스크롤 이벤트 핸들러에서 */
if (isFlagSet('programmaticScroll')) {
// 프로그래밍 방식 스크롤이 완료되면
// 수평 스크롤 + 포커스 허용
clearFlag('programmaticScroll')
}/* 셀 렌더링 코드에서 */
if (!isFlagSet('programmaticScroll')) {
// 수평 스크롤 + 포커스 허용
cell.scrollIntoView({inline: 'nearest'})
cell.focus({preventScroll: true})
}프로그래밍 방식으로 스크롤할 때 스크롤 이벤트를 하나만 받도록 behavior: 'instant'를 설정합니다. 대안인 behavior: 'smooth'는 여러 스크롤 이벤트를 트리거하여 플래그를 너무 일찍 해제하고, 예상치 못한 중간 scrollTop 위치로 인해 내부 상태와 충돌을 일으킬 수 있습니다(미해결 이슈 참고).
2단계 랜덤 접근의 효과
이 기법 덕분에 사용자는 키보드로 테이블의 어떤 임의의 셀에든 접근할 수 있으며, 수십억 행이 있어도 테이블이 기대하는 위치로 스크롤됩니다. 수직과 수평 스크롤이 분리되어 있으므로, 사용자는 →로 수직 스크롤을 트리거하지 않고 다음 열로 이동할 수 있으며, ↓로도 마찬가지입니다.
결론
가짜 스크롤바도 필요 없고, 테이블을 캔버스에 렌더링할 필요도 없습니다. 우리는 웹 플랫폼을 사용합니다. 네이티브 HTML 요소에 기반한 이 다섯 가지 기법 덕분에, hightable은 브라우저에서 원격 데이터 파일의 수십억 행을 매끄럽게 탐색할 수 있게 해줍니다.
이 글이 마음에 드셨다면 GitHub 저장소에 별 ⭐ 을 눌러주세요!
🚀 한국어로 된 프런트엔드 아티클을 빠르게 받아보고 싶다면 Korean FE Article(https://kofearticle.substack.com/)을 구독해주세요!

가상 스크롤링 기법들을 이렇게 체계적으로 정리해주셔서 감사합니다. 특히 무한 픽셀과 2단계 랜덤 접근 부분이 인상적이었는데, 대용량 데이터를 다루는 프로젝트에서 바로 적용해볼 수 있을 것 같습니다. 번역도 자연스럽고 원문의 핵심을 잘 전달해주셨네요.