SQL
1.SQL / 01 / 기초-1
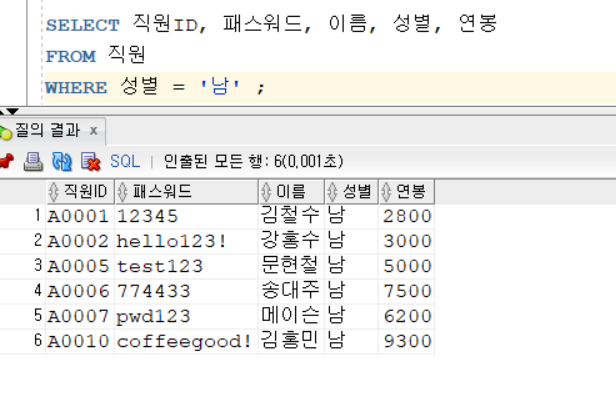
데이터베이스에 정보를 저장하고 처리하기 위한 프로그래밍 언어SELECT 문법만 잘 알아도 실무 SQL 80% 이해 가능하다table(테이블) : 데이터를 저장하는 저장소 역활테이블은 2차원의 행과 열로 이루어져있다. (무조건 직사,정사각형)pandas 라이브러리 처럼,
2.SQL / 01 / 기초-2
SELECT 에서 \* 쓰면, 다른 컬럼 선택 ❌단독으로만 사용 가능함수도 사용 ❌ (함수 안에, 특정 컬럼이 포함 됨) 시험에 몹시 자주 나오는 키워드SELECT 부분에서 출력하는 컬럼에 새로운 별칭(ALIAS) 부여SELECT 외에도 사용 가능AS 대신에 공백 가
3.SQL / 01 / 기초-3
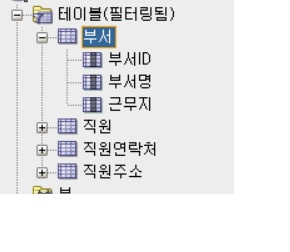
1) FROM에 엔터티(정보저장의 집합) => (부서,직원,직원연락처,직원주소) SELECT에 그 엔터티의 속성(행=컬럼) 이 들어간다 !! (부서 클릭시, 부서ID,부서명,근무지) <= 속성(컬럼)2) JOIN시, 공통의 속성으로 WHERE에서 결합한
4.SQL / 01 / 기초-4
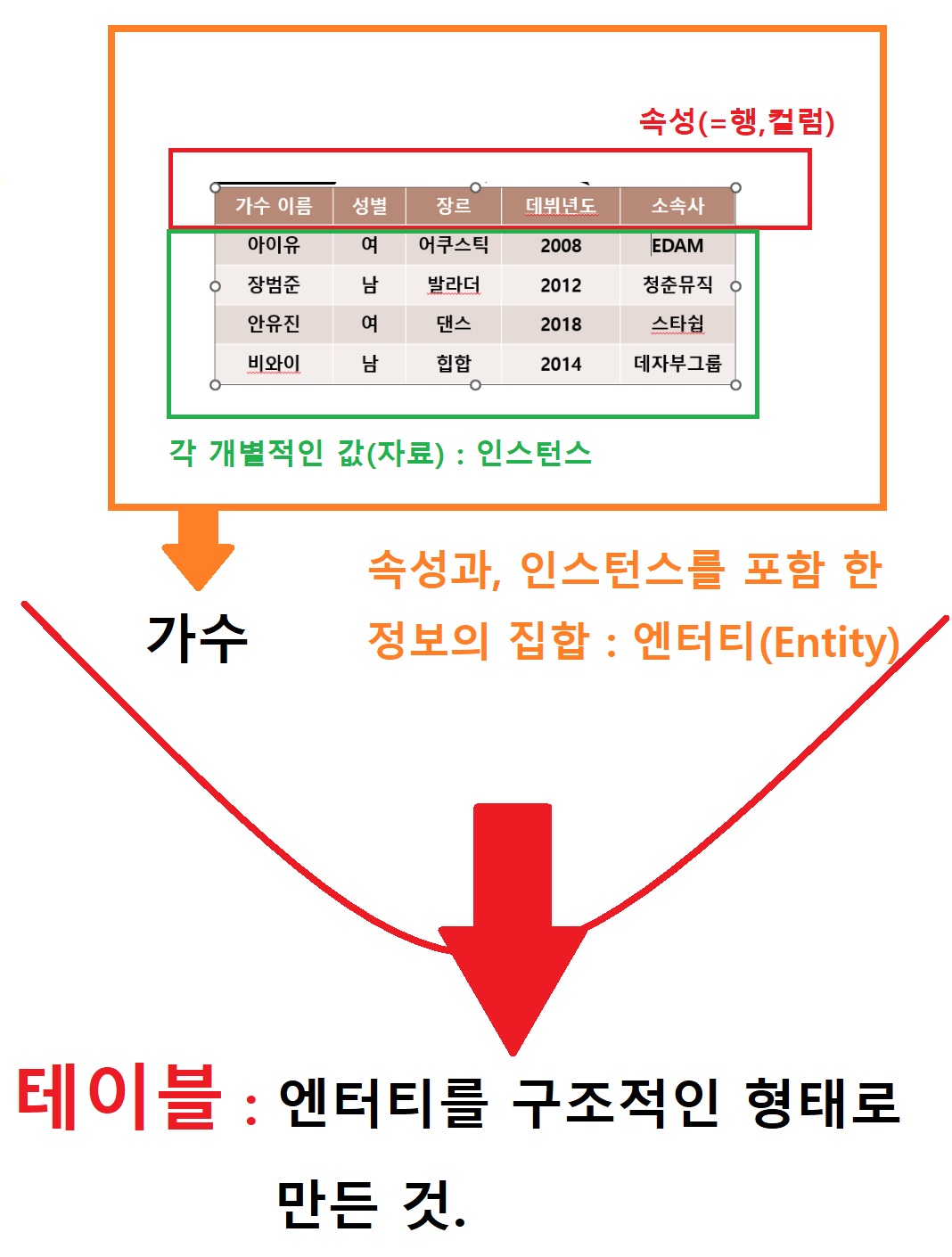
엔터티 : 저장 된 정보의 집합테이블 : 엔터티를 구조화해서 형태로 만든 것엔터티는 속성과, 인스턴스를 가지고 있음속성 : 행(=컬럼)인스턴스 : 각 개별적인 값,자료SELECT 👉 테이블의 속성(행,컬럼) 의 위치FROM 👉 테이블 위치보통 이런 경우, 별칭을 써
5.SQL / 01 / 기초-5

ANSI(미국국립표준협회) 문법은 모든 DBMS에서 사용가능한 조인 문법✅ 오라클 ▶ ANSI INNER JOIN ① FROM절에서 콤마 (,) 지우고 (무슨) JOIN 입력② WHERE ▶ ON 변경③ ON 뒤에 괄호로 감싸주기✅ 오라클 ▶ ANSI OUTER
6.SQL / 01 / 기초-6

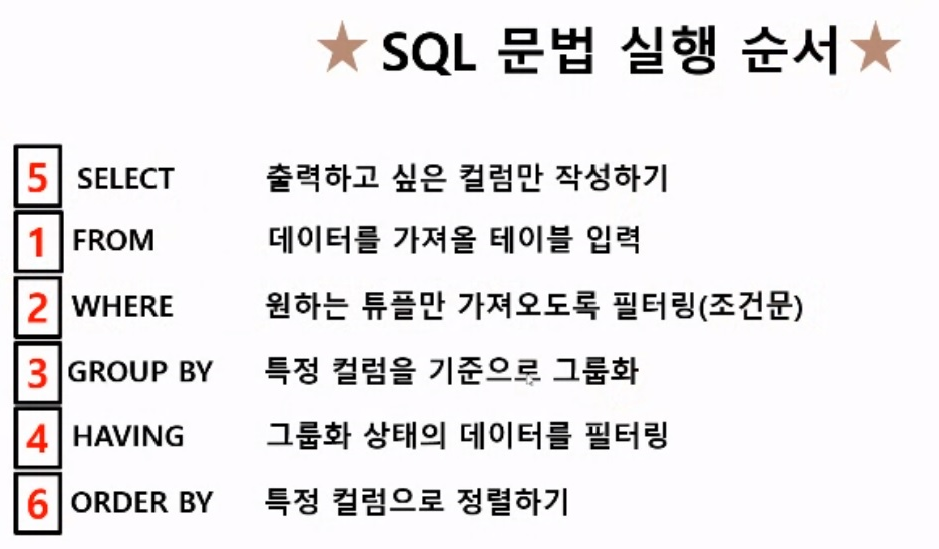
SQL의 순서(흐름)과, 각 절의 특성에 대해 알고 있기특정 컬럼을 기준으로 그룹화 (≒합친다)집계를 편하게 하기 위해 사용GROUP BY 그룹화 후, 그룹화 되지 않는 컬럼과 나란히 사용 X❗ 집계함수로 처리한 컬럼은 HAVING, ORDER BY, SELECT 입력
7.SQL / 04 / "column ambiguously defined"
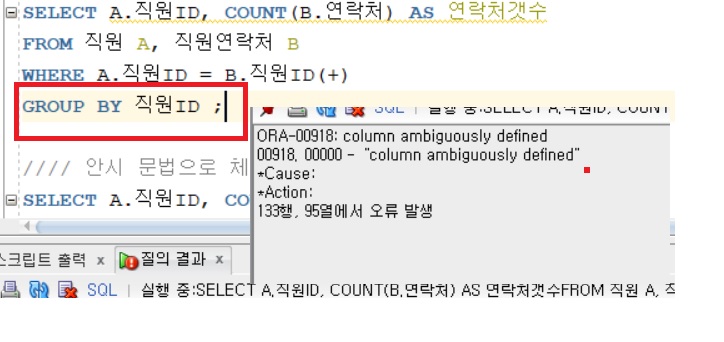
= 컬럼이 애매하게 정의되었습니다.
8.SQL / 01 / 기초-7
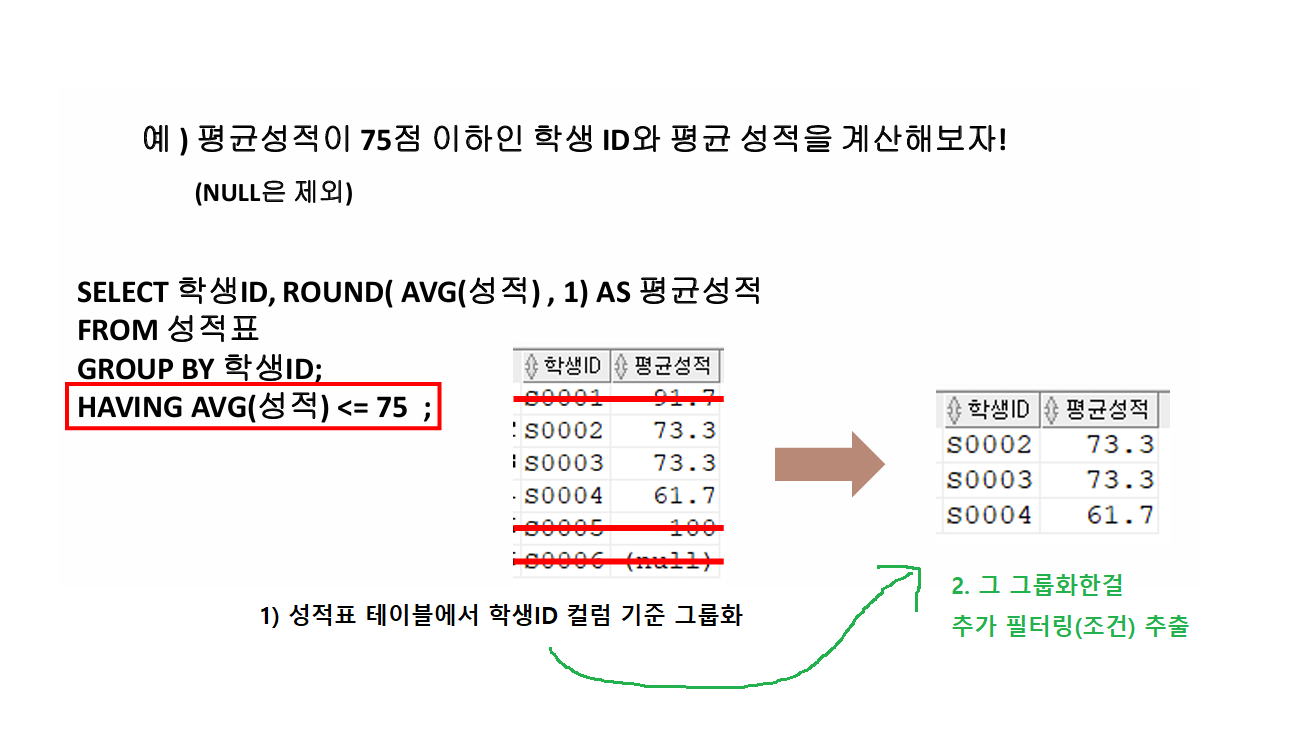
그룹화(GROUP BY / 3번째) 된 데이터를 필터링(조건)집계함수 사용 가능 !!WHERE절은 집계함수 사용이 불가능 !!WHERE절은(조건/2번째) 는 GROUP BY(3번째) 보다 먼저 실행 됨 !!출력시, 데이터 오름차순 or 내림차순 설정 기본값 (오름차순)
9.SQL / 01 / 기초-8
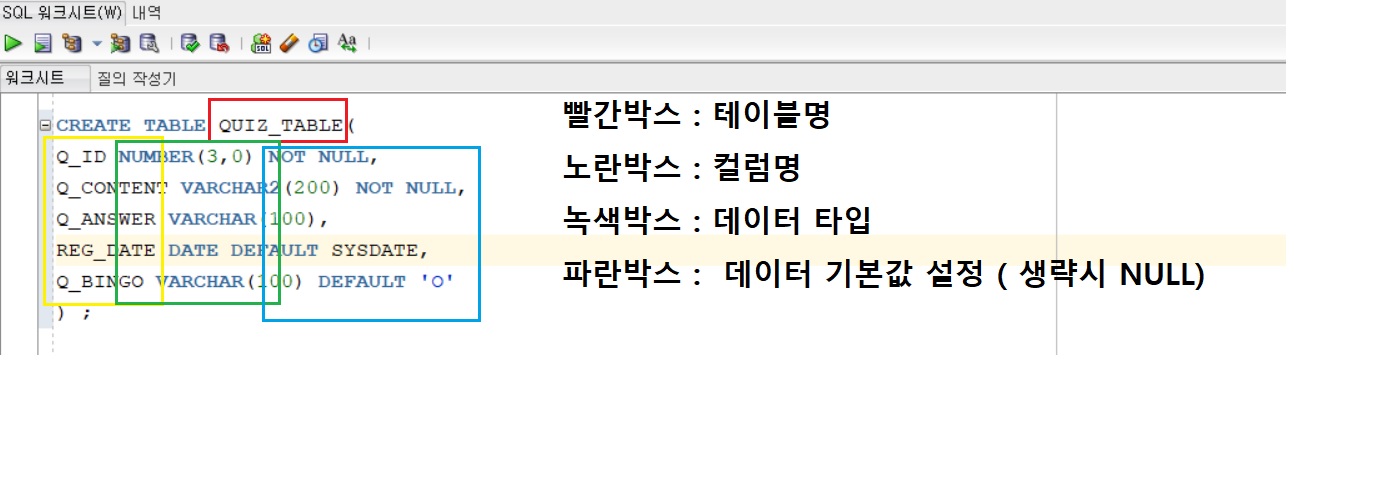
Data Definition Language테이블 같은 데이터저장소 객체의 생성, 수정, 삭제자료형(DATA TYPE)을 꼭 지정해주자 ▶ for 효율성CREATE : 새로운 저장소 객체를 생성 👉 무조건 영어,대문자로 시작ALTER : 테이블을컬럼(열) 단위로수정
10.SQL / 01 / 기초-9

* DML / 데이터 조작어 Data Manipulation Language 테이블에 데이터를 입력, 수정, 삭제 DDL이 뼈대, 집짓기라면, DML은 지은 집에 사람을 입주 SELECT 도 DML에 들어감 DDL 보다 시험에서 좀 더 다뤄지는 ① INSERT
11.SQL / 01 / 기초-10
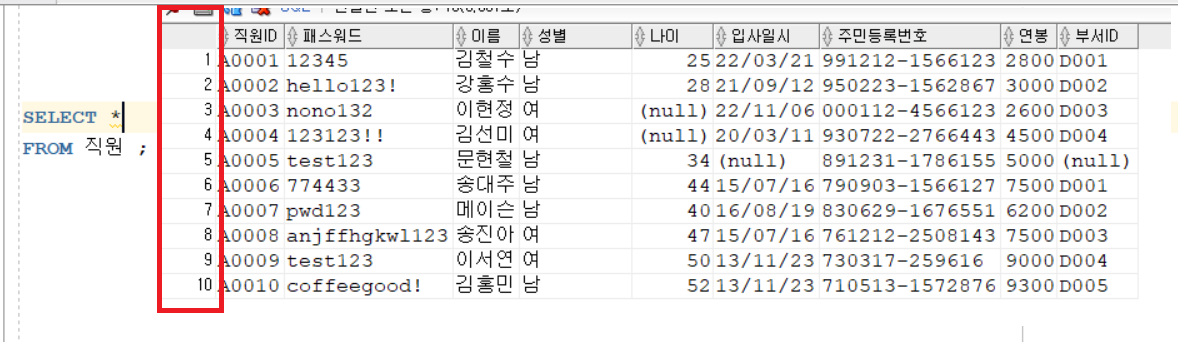
한꺼번에 많은 양이 노출 되면 서버에 부담이 생김예) 1페이지,2페이지,3페이지 테이블의 튜플에 임시로 부여되는 일련번호WHERE(조건)에 ROWNUM을 사용하여, 출력되는 튜플 개수 제한 가능선행 되는 값이 먼저 있어야, 후행 되는 값 사용 가능
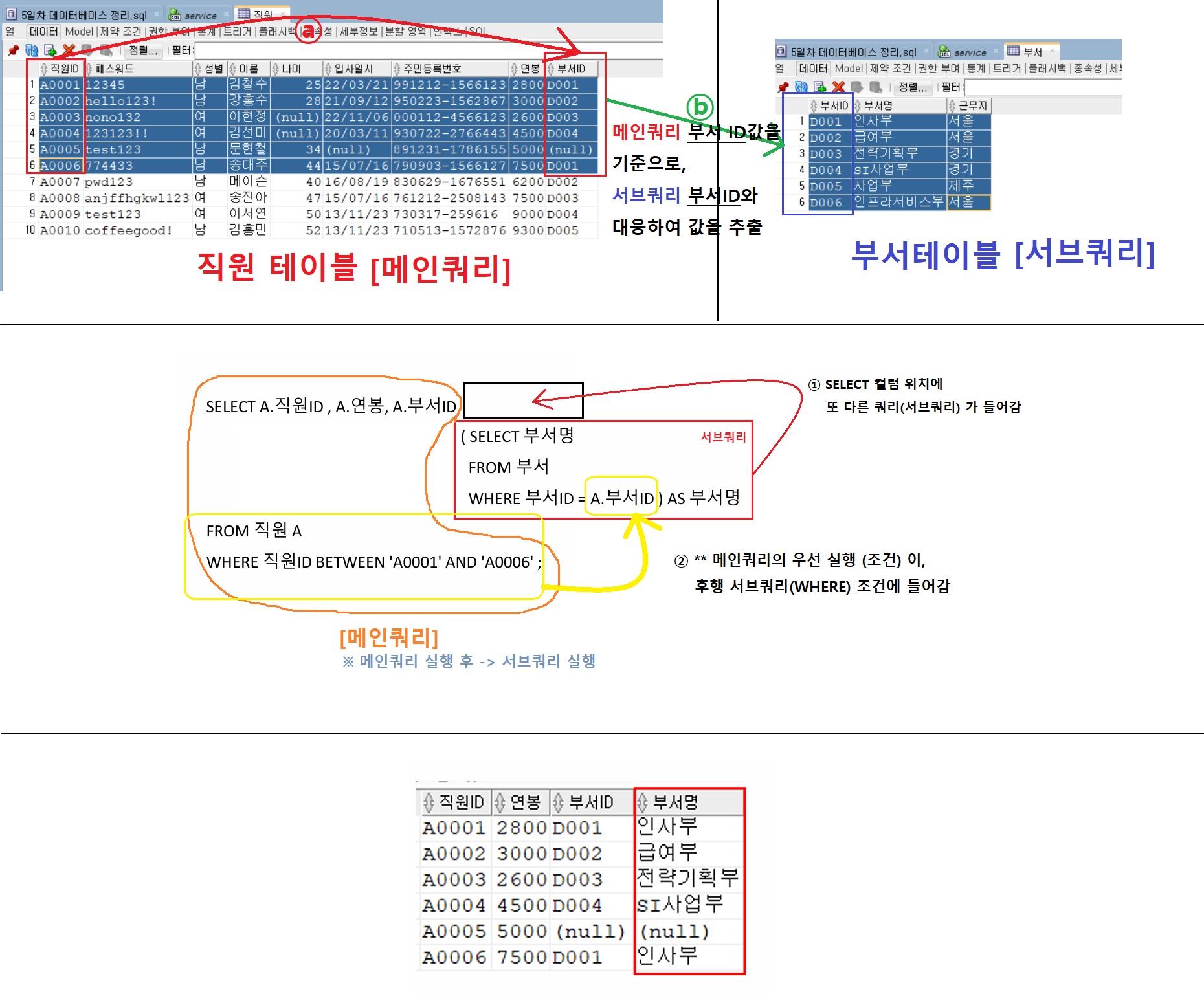
12.SQL / 01 / 기초-11
다른 쿼리 내부에 포함되어 있는 SELECT 쿼리실무 多多SELECT 에서 사용되는 서브쿼리하나의 컬럼에 대해 하나의 행만 반환출력 되는 하나의 값이 없다면 NULL값 반환메인쿼리에서 출력되는 튜플의 수 = 서브쿼리 반복 실행