
서론
지금까지 개발을 하면서 JDBC 사용부터 시작해 JdbcTemplate, 그리고 JPA까지 사용해보며 경험한 일들을 정리해보려고 한다.
JPA를 사용하면서 느낀 편리한 점들이 많았지만, 시간이 지나면서 그 구체적인 이점들을 점점 잊게 되는 것 같아 이 기회에 기록해두기로 했다.
JDBC 를 사용하며
개발을 공부하던 중 처음으로 DB를 사용해야 하는 상황이 생겼다. Java의 JVM 메모리 세상에서 벗어나 외부 DB에 접근하려면 Java에서 제공하는 JDBC 인터페이스를 활용하면 비교적 쉽게 접근할 수 있었다.
데이터베이스는 종류가 다양하다. 따라서 매번 모든 데이터베이스의 규칙에 맞춰 코드를 작성하는 것은 비효율적이다. SQL 쿼리 문법 또한 데이터베이스에 따라 조금씩 다르기 때문에, 하나의 Java 코드가 다양한 데이터베이스에서 작동할 수 있으려면 표준화된 인터페이스가 필요하다.
이를 가능하게 해주는 것이 바로 JDBC (Java Database Connectivity) 이다.
JDBC 인터페이스는 우리가 DB에 보다 쉽게 접근할 수 있도록 여러 객체를 제공해준다.
- DriverManager: 데이터베이스 연결을 관리
- Connection: 데이터베이스와 연결된 객체
- Statement, PreparedStatement: SQL 쿼리를 실행하는 객체
- ResultSet: 쿼리 결과를 담는 객체
이 다섯 가지 객체를 주로 활용해 우리는 DB와 통신할 수 있다.
간단하게 사용하는 과정을 보자.

DAO (Data Access Object, DB에 직접 접근하는 객체) 클래스 상단에는 MySQL 서버 주소, DB 이름, 옵션, 서버 아이디와 비밀번호 등을 설정해둔다.
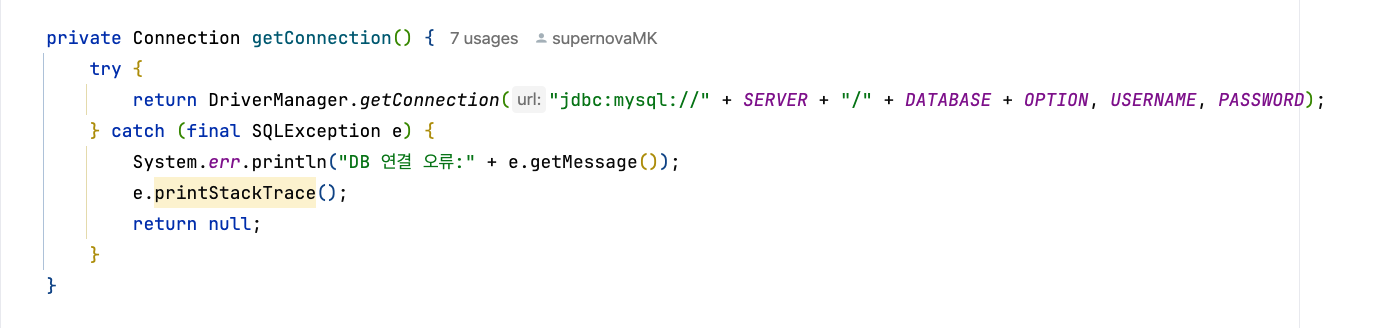
먼저 getConnection() 메서드를 통해 공통된 연결을 받아오게 된다.
DriverManager.getConnection() 안에 JDBC URL을 전달하고, 반환된 값으로 Connection 객체를 얻는다.
이 과정에서 반드시 예외 처리를 해야 하는데, 이는 SQLException이 체크 예외이기 때문이다.

String 문으로 Sql 문을 미리 작성한다. 이제 반환 받은 Connection을 연결해서 사용해보자.
우선 문자열로 SQL 문을 작성하고, connection.prepareStatement()에 해당 쿼리를 전달한다.
그다음 PreparedStatement.setInt() 등을 이용해 ?에 해당하는 값을 파라미터 인덱스에 맞게 주입한다.
마지막으로 preparedStatement.executeUpdate()를 통해 쿼리를 실행한다.
이 과정에서도 예외 처리가 필요하므로, try-with-resources 구문을 사용했다.
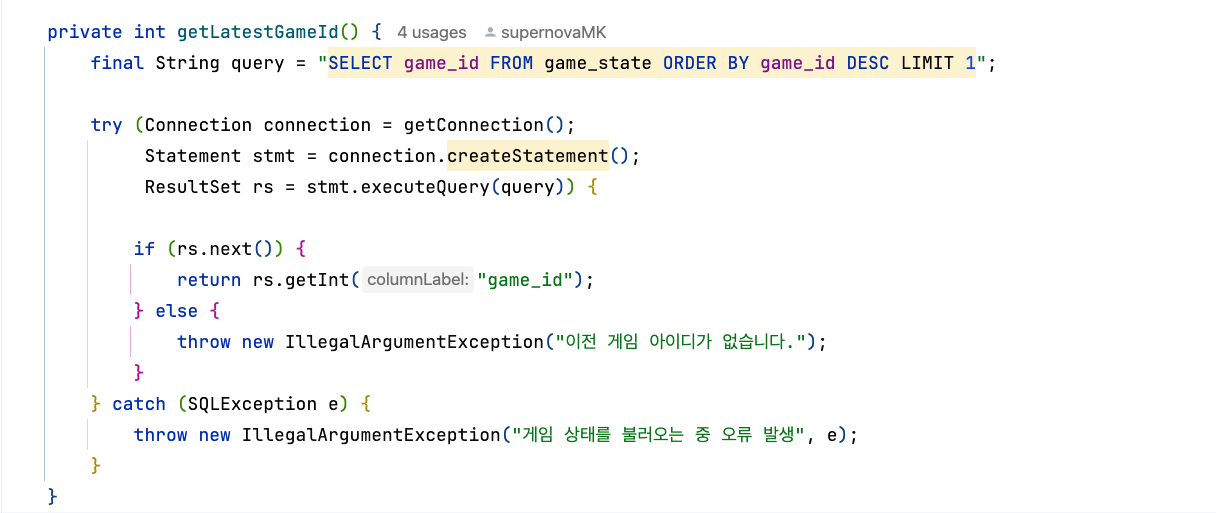
SELECT 문으로 데이터를 조회할 때는 ResultSet 객체를 통해 실행 결과를 받아온다.
이때 테이블의 컬럼명을 직접 문자열로 작성해야 하며, 이 과정에서 오타나 컬럼명 변경 등으로 인해 오류가 발생할 수 있다.
즉, 우리가 집중해야 할 비즈니스 로직과는 다르게, 반복적으로 작성해야 하는 코드나 신경 써야 할 요소들이 상당히 많다.
JDBC 덕분에 DB에 접근하는 과정 자체는 가능해졌지만, 반복되는 보일러 코드들(예외 처리, 커넥션 연결 등)과 유지보수 측면에서는 분명 불편한 점이 많다.
불편함을 느꼈는나?
그럼 우리는 멈춰있을 수 없다. 더 나은 방법을 찾아야한다.
JdbcTemplate을 사용하며
이제는 Spring 프로젝트에서 JdbcTemplate을 사용해보며 DB에 연결을 시도한 과정을 따라가보자.
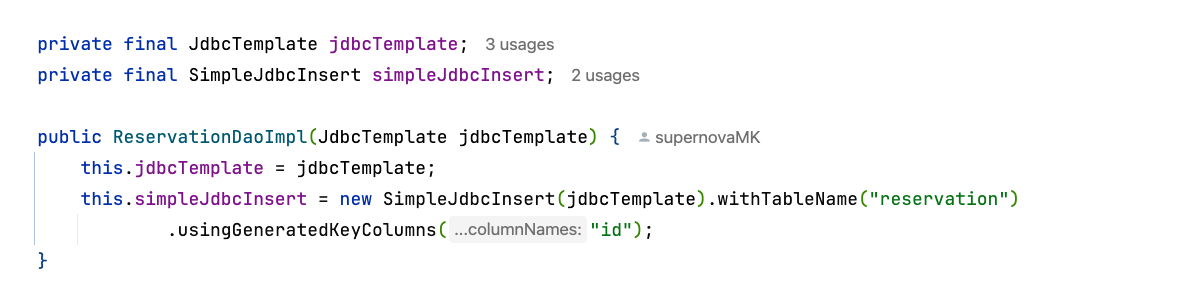
implementation 'org.springframework.boot:spring-boot-starter-jdbc 의 의존성을 주입해주게 된다면 JdbcTemplate은 빈 객체로 주입받을 수 있다.
spring.datasource.url=jdbc:h2:mem:database 를 통해서 우리는 h2 데이터베이스를 사용해서 연결하겠다를 application.properties에 명시를 해둔다.
이제 준비가 끝났다. 우리는 바로 비즈니스로직에 집중하여 구현하면 된다.
jdbcTemplate을 활용하는 방법과 자세한 설명에 대해서 알고 싶다면 지난 포스팅을 보면 확인할 수 있다.

JdbcTemplate을 사용해서 작성한 코드이다. 전에 직접 관리해야했던 try with resource 구문이 없어진 것을 확인 할 수 있다. 또한 매번 DB의 연결을 위해서 직접 Connection을 얻어와 사용해야했던 지점들이 모두 사라진 것을 확인할 수 있다.
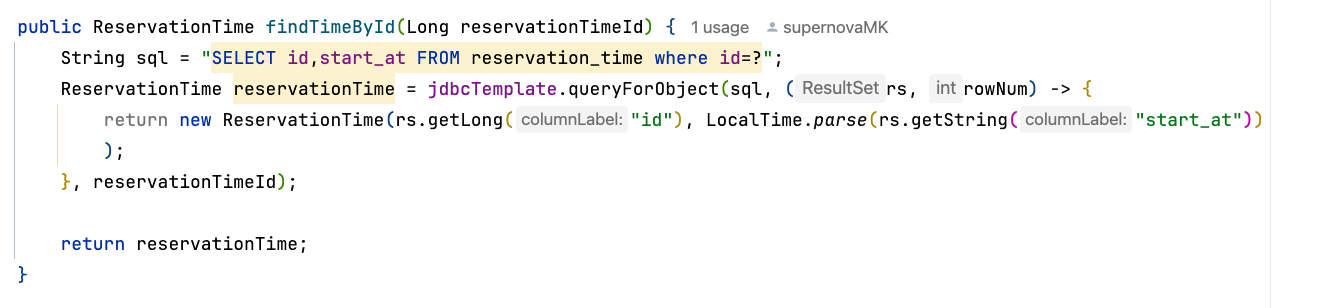
Select 시 반복되는 resultSet을 직접 .next()를 사용해가며 관리할 필요 없이 직접 ResultSet을 구현하여 쉽게 객체를 생성할 수 있다는 점을 확인할 수 있다.
sql문과 resultSet만 적절하게 사용해준다면 우리는 DB의 연결에 더이상 신경쓸 부분이 없다.
예외처리는 모두 런타임 예외로 관리할 수 있다. 하지만 개발을 하는 과정에서 몇가지 힘든 상황을 경험하였다. sql문을 작성하거나 rs.getString()안에 정확하게 테이블 칼럼 명을 잘못 적었을때의 경우에는 어디서 문제가 생긴지 당황하였지만, 이 부분은 내가 감당해야하는 부분이라고 생각되었다.
JdbcClient
추가적으로 이번 폰트의 테코톡을 듣고 새롭게 알게 된 정보가 있다. 바로 Jdbc Client 이다.
Jdbc Template은 기본적으로 Optional반환과 같이 기본적으로 제공해줄 만한 부분들을 제공해주지 않고 있었다. 따라서 사람들이 직접 Spring에게 요청을 하였지만 Spring 측에서는 해당 부분은 Jdbc Template이 신경써야하는 범위가 아니라는 입장을 전했다고 한다.
그러다가 몇년 전에 Optioanl과 같은 기능들을 제공하고 조금더 메소드 체이닝과 같은 기능들이 함께 가능해진 JdbcClient가 나왔다고 한다. JdbcClient의 설명만 들으면 그저 JdbcTemplate의 상위호환 처럼만 느껴진다. 하지만 더 추가적인 기능을 제공하는만큼 몇가지 단점들도 존재하지 않을까 생각해본다.
본론으로 다시 돌아와서 Jdbc Template을 사용하면서 우리는 많은 편리함을 느꼈다. 반복되는커넥션 연결, 예외 처리 , 직접 작성해야했던 resultSet.next() 들을 더 이상 신경 쓸 필요가 없었다.
이제 불편함이 해결되었는가? 하지만 아직 만족하기에는 아쉽다. 이제 내가 겪은 문제들을 추가적으로 살펴보겠다.
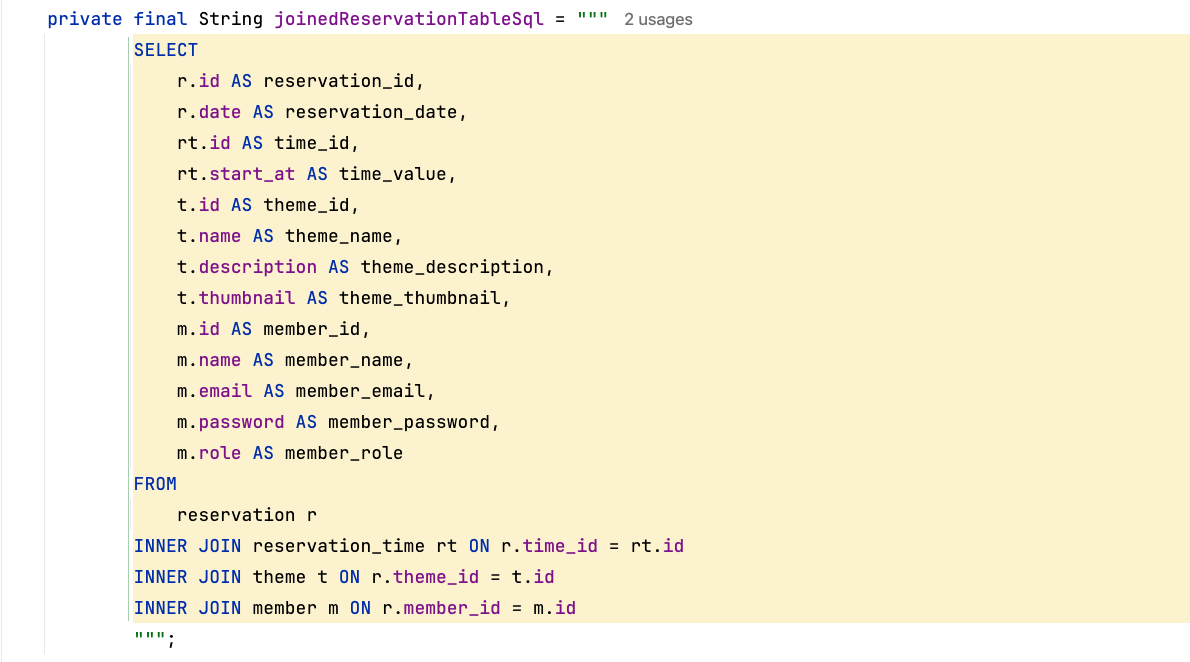
만약 하나의 클래스가 다른 클래스에 대해서 알고 있다면 직접 쿼리문에 join을 사용해서 sql문을 직접 작성해야한다. 우리가 사용하는 클래스는 본래 자신의 정보를 모두 알고 있다. Reservation이라는 객체는 자신이 필드로 가지고 있는 다른 객체들에 대한 내용을 모두 메모리 주소로 불러와 값을 가지고 있지만 테이블은 그렇지 않다. 테이블에는 참조키를 알고 있지만 직접 데이터를 불러오기 위해서는 하나의 테이블로 만들어서 사용해야한다. 테이블의 패러다임과 자바 객체의 패러다임의 불일치로 인해서 우리는 직접 이를 매핑해주고 있었다.
JPA를 사용하며
이번에는 JPA의 Hibernate 구현체를 사용하며 겪은 이야기를 적어보고자 한다.
JPA란 간단히 말해서 Java 객체와 관계형 데이터베이스 테이블을 매핑해주는 ORM(Object-Relational Mapping) 표준 인터페이스이다.
즉, SQL을 직접 작성하지 않고도 Java 객체만으로 데이터베이스를 조작할 수 있도록 해주는 기술이다.
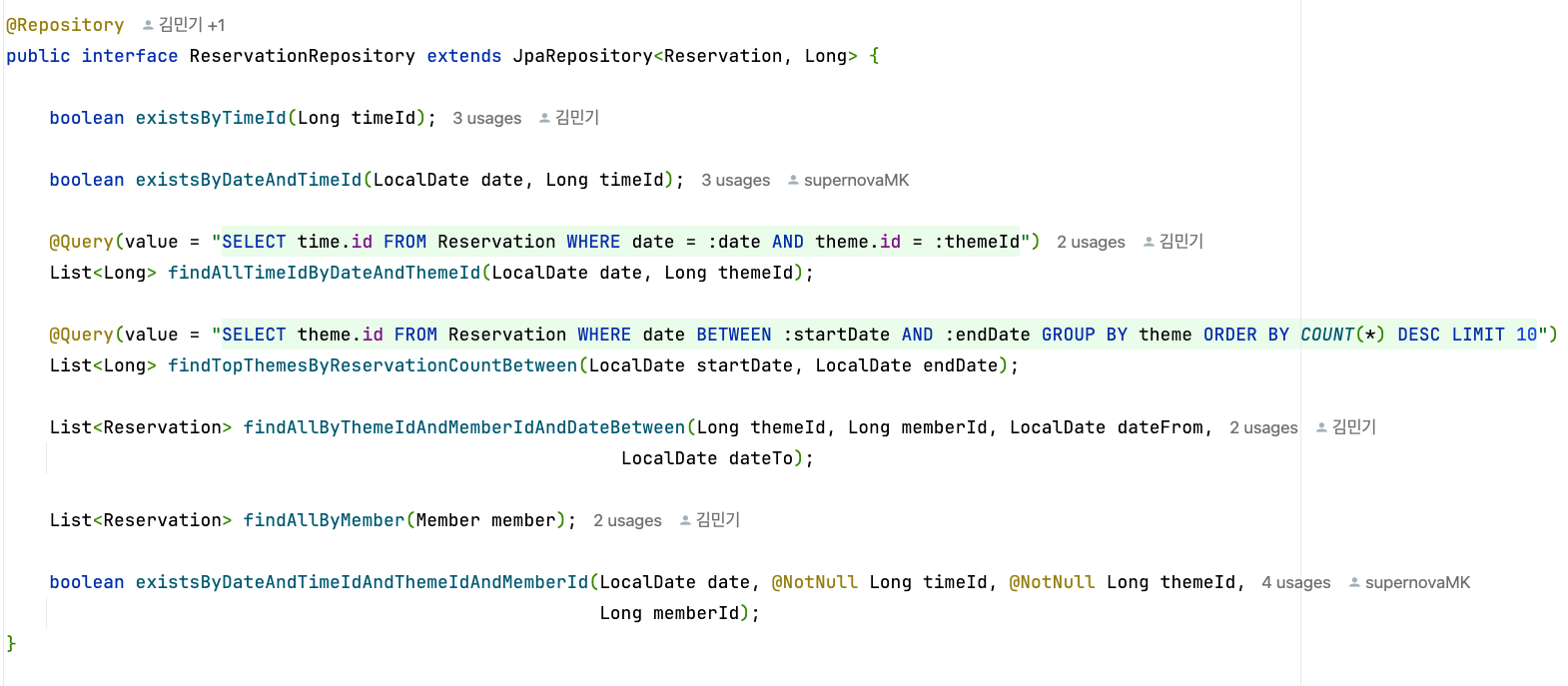
JPA는 인터페이스 기반으로 정의되어 있으며, 실제 구현은 Hibernate와 같은 구현체에 의해 제공된다.
개발자는 직접 구현할 필요 없이, @Entity, @Id, @GeneratedValue 등의 어노테이션과 JpaRepository 또는 EntityManager를 사용하여 DB 연동을 손쉽게 처리할 수 있다.
또한, 이전에 반복해서 작성하던 SQL 쿼리들이 대부분 사라진 것을 확인할 수 있다.
메서드 명만으로 원하는 쿼리를 자동 생성해주는 메서드 쿼리 이름 전략이 적용되며,
필요에 따라 @Query 어노테이션을 활용해 JPQL 또는 native SQL을 직접 작성할 수도 있다.
무엇보다 눈에 띄는 변화는, 반복되던 스켈레톤 코드들이 보이지 않는다는 점이다.
더 이상 DB 연결, 쿼리 생성, 매핑, 자원 해제 등 반복적인 작업들을 개발자가 직접 처리하지 않아도 된다.
객체와 테이블 간의 매핑도 @OneToMany, @ManyToOne 등의 어노테이션으로 선언만 해주면 자동으로 처리된다.
우리는 이제 더욱 비즈니스 로직에 집중할 수 있는 환경을 갖추게 된 것이다.
처음 JPA를 사용했을 때, 허무함이 찾아왔다.
너무 간편한 나머지, 앞서 배운 JDBC, JdbcTemplate에 들인 시간들이 무색해지기도 했다.
'내가 이걸 직접 배웠어야 하나?'라는 생각이 들 정도로 손쉽게 개발이 가능했다.
하지만 조금만 깊게 들어가 보면, JPA는 결코 마법이 아니다.
JPA 내부에서는 여전히 JDBC를 사용하고 있고, 단순한 쿼리 작업이라면 오히려 JdbcTemplate이 더 효율적인 경우도 존재한다.
게다가 JPA는 다음과 같은 몇 가지 주의점이 있다:
- 지연 로딩(Lazy Loading)의 이해 부족으로 인한 N+1 문제
- 복잡한 쿼리 작성 시 JPQL의 한계
- 트랜잭션 처리의 이해 부족으로 인한 데이터 정합성 문제
이러한 내용은 앞으로 더 학습하고, 나중에 다시 블로깅해보며 정리해볼 예정이다.
마치며
JDBC부터 시작해 JdbcTemplate, 그리고 JPA에 이르기까지
나는 단순한 SQL 실행을 넘어 데이터와 객체를 다루는 방식의 변화를 경험할 수 있었다.
처음에는 단순히 DB와 연결하고 쿼리를 실행하는 것만으로도 충분하다고 생각했지만,
점차 반복되는 코드, 복잡한 예외 처리, 객체 간 매핑의 불일치를 마주하면서 더 나은 방법을 고민하게 되었다.
JdbcTemplate은 그런 고민을 덜어주는 훌륭한 도구였고,
JPA는 객체지향적으로 사고할 수 있는 새로운 패러다임을 열어주었다.
하지만 JPA 또한 만능은 아니며, 그 내부에 숨어 있는 동작 원리를 이해하지 못하면 더 큰 문제를 만들 수도 있다.
결국 중요한 것은 도구 자체가 아니라, 도구를 '언제', '왜', '어떻게' 써야 하는지 판단하는 능력이지 않을까 생각해본다.



저도 비슷한 경험을 했는데, 글로 정리해주셔서 감사합니다