알고리즘이란?
알고리즘이란 문제를 해결하기 위해 필요한 계산절차나 처리과정의 순서이다
알고리즘은 유한성을 가지며 언젠가는 끝나야하는 속성을 가지고있다.
일상속에서의 알고리즘
최단거리나 최단시간내에 집에서 회사까지 가는 길을 찾는것, 라면을 끓이기 위해 필요한 재료준비와 조리를 순서대로 진행하는것 등이 될수있다. 프로그래밍에서의 알고리즘은 input값을 통해 output값을 얻기 위한 계산 과정을 말하는 것으로 문제를 해결할때 정확하고 효율적으로 결과값을 얻기위해 알고리즘이 필요하다.
좋은 알고리즘이란?
알고리즘을 작성할때는 효율성을 고려해야한다.
알고리즘의 성능을 분석할때에 공간복잡도(총 저장공간의 양)와 시간복잡도(총 소요시간)를 계산하게된다.
당연히 좋은 알고리즘이란 공간복잡도와 시간복잡도가 작게 나오는것이다. 최근 공간복잡도에 대한 부분은 하드웨어의 발달로 인해 상대적으로 줄어 시간복잡도에 좀 더 초점이 맞춰지기 시작했다.
재귀(recursion)함수
재귀 알고리즘이란 하나의 함수에서 자기 자신을 다시 호출하여 작업을 수행하는 알고리즘이다.
이러한 재귀함수는 자신의 로직을 내부적으로 반복하다가, 일정한 조건이 만족되면 함수를 이탈하여 결과를 도출한다.
재귀 vs 반복문
보통 재귀와 반복문이 많이 비교되곤 한다. 항상 그런 것은 아니지만 많은 경우에 재귀로 처리할 수 있는 문제는 반복문으로도 처리할 수 있고, 반대로 반복문으로 처리할 수 있는 것은 재귀로 처리할 수 있다. 코드를 짜는 사람 마음이지만 때로는 반복문보다 재귀를 사용했을 때 더 이해하기 쉬운 코드가 될 때가 있다. 그러므로 우리는 두 가지 방법을 모두 명확하게 알고 있어야 한다.
재귀함수 호출의 원리는 스택으로 진행된다.
재귀 알고리즘이 어렵다고 느껴지는 이유 중 하나는 사람의 머리로 컴퓨터가 실행하는 재귀적 행동을 따라 갈 수 없기 때문이다. 재귀 알고리즘을 보다 쉽게 상상하려면,
1. 같은 함수가 호출 되는 것이 아니라, 복사된 함수가 호출 된다고 생각할것.
2. 함수 호출의 원리는 결국 스택으로 진행된다. 함수가 호출되면 기존 함수 스택 위에 호출된 함수가 쌓이게 되고, 더 이상 쌓을 함수(스택)이 없게 되면 위에서부터 차례대로 실행하게된다. (아래 예제와 그림참조)
팩토리얼 구하기
재귀함수의 예제로 많이 등장하는 팩토리얼이다.
팩토리얼이란 자기자신부터시작해서 1 감소한 숫자들을 곱한 값이다.
예를들어 5!을 다르게 표현하자면 5 x 4 x 3 x 2 x 1 = 120이 된다.
- 반복문
function factorial (n) {
var result = 1;
for (var i = n; i >= 1; i--) {
result *= i;
}
return result;
}n부터 1까지의 수를 반복하여 result 변수에 곱한다. 곱셈을 해야 하므로 result 변수의 초기값은 당연히 1이어야 한다.
- 재귀
function factorial (n) {
if (n == 1 || n == 0) { //재귀호출을 중단시키는 base case(termination case)를 작성하지않으면 콜스택이 가득 차서 에러를 출력한다.
return 1;
}else{
return n * factorial(n - 1);
}
}
console.log(factorial(5))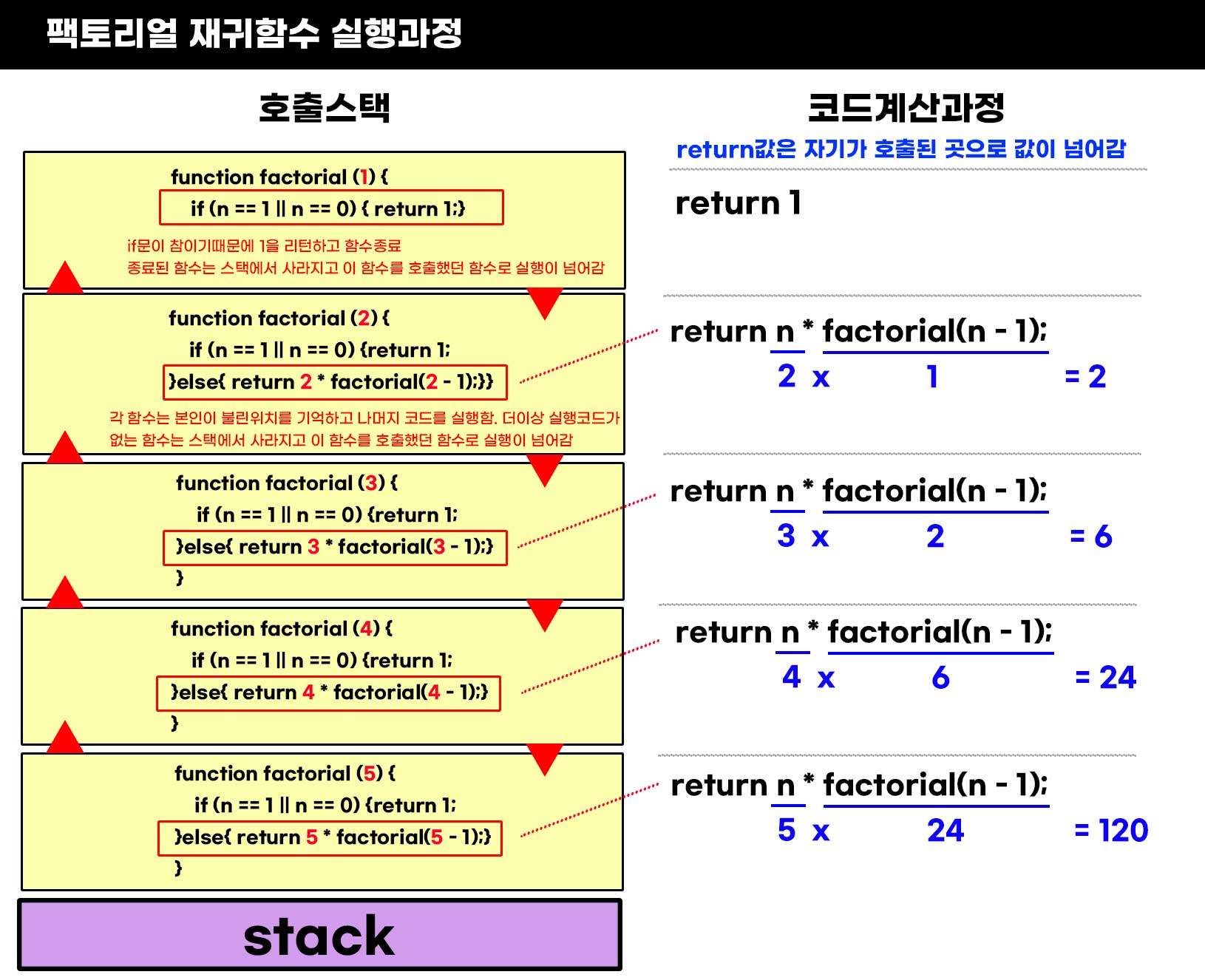
- 먼저 파라미터 n의 값으로 5이 전달된다.
- stack에 5을 저장하고 factorial(5 - 1) = factorial(4)을 실행한다.
- n의 값으로 4가 전달된다. stack에 4를 저장하고 factorial(4 - 1) = factorial(3)을 실행한다. (반복)
- n의 값으로 1이 전달된다. n이 1이면 1을 리턴하고 함수를 종료한다.
- factorial(1)이 1을 return하고 종료하였으므로 2 * 1을 연산하고 그 값인 2를 return한다. (반복)
- 리턴된 5와 24을 곱한 후 그 값인 120을 리턴하고 모든 함수가 종료된다.
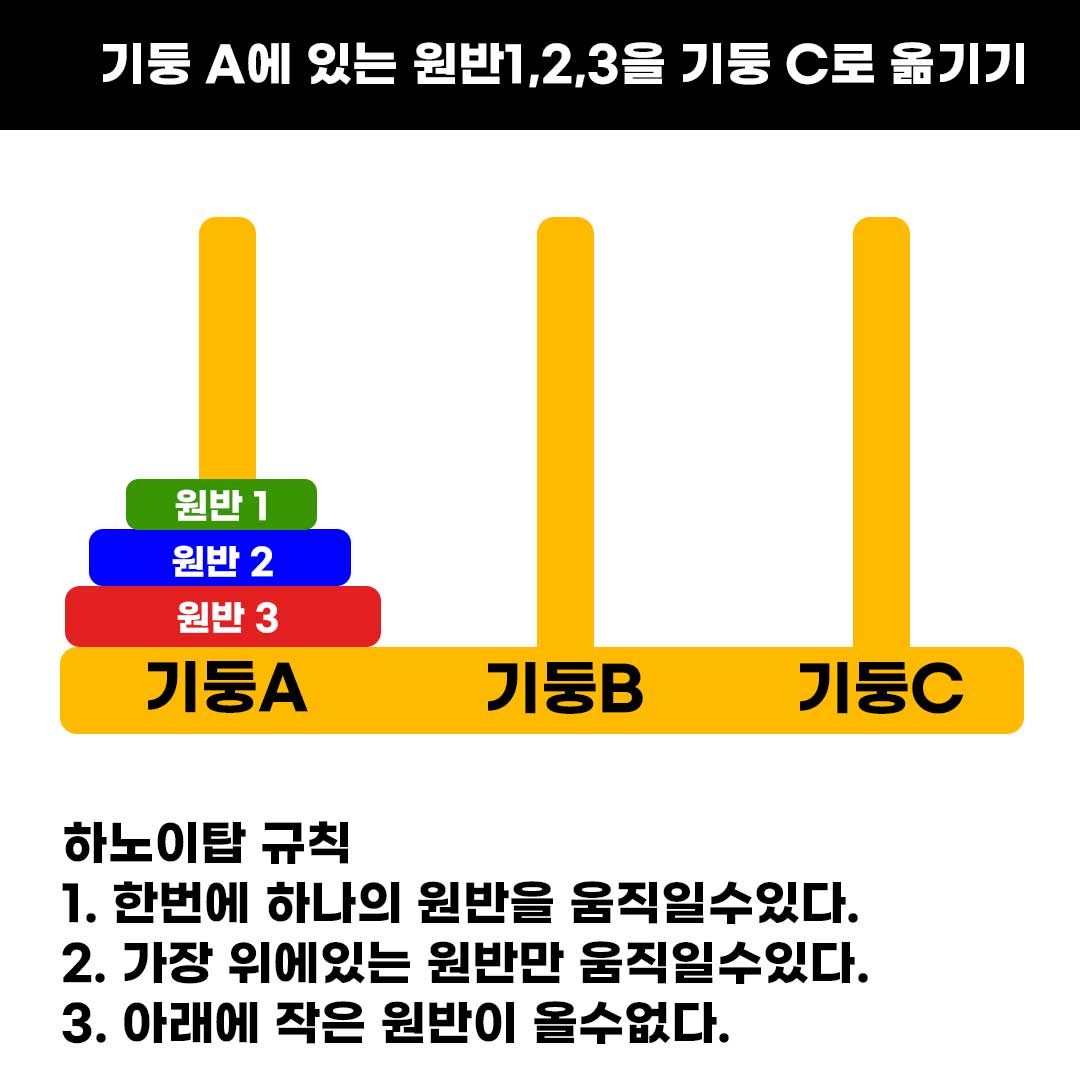
하노이 탑
하노이의 탑은 재귀응용으로 자주 나온다.
아래 세가지 틀을 꼭 기억하자.
1.아래 원반을 제외한 나머지 원반을 목표와 다른곳으로 보내기
2.아래 원반을 목표지점으로 보내기
3.목표와 다른곳에 있던 원반들을 다시 목표지점으로 보내기
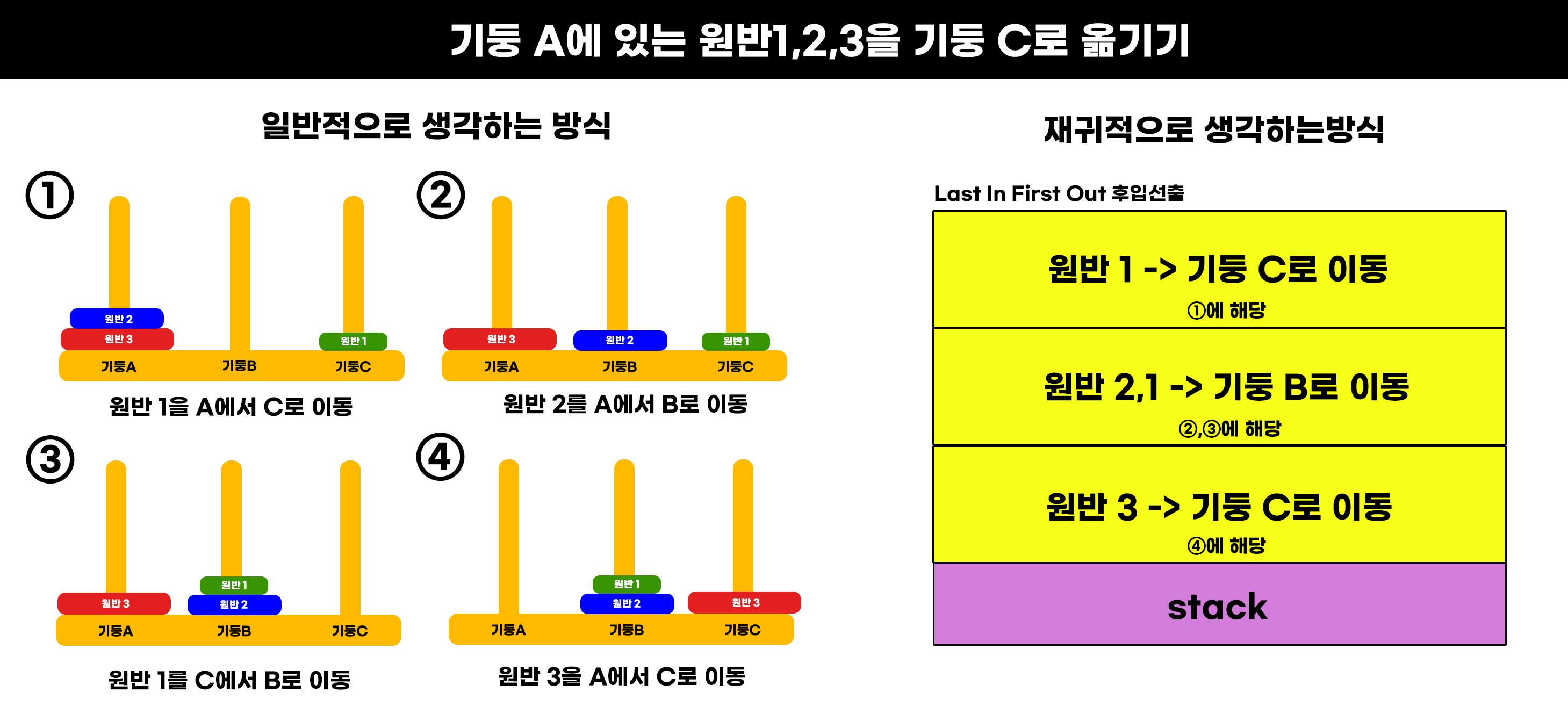 이제 원반3이 C로 이동했으니 B에있는 원반 (1,2)도 C로 이동해줘야한다.
이제 원반3이 C로 이동했으니 B에있는 원반 (1,2)도 C로 이동해줘야한다.
앞에서 실행한 것과 비슷하게, B에서 시작하니 인자 from의 값은 B가 들어있는 temp, 목표기둥 to에는 C가들어있는 to, 나머지 기둥 temp에는 from을 넣어준다.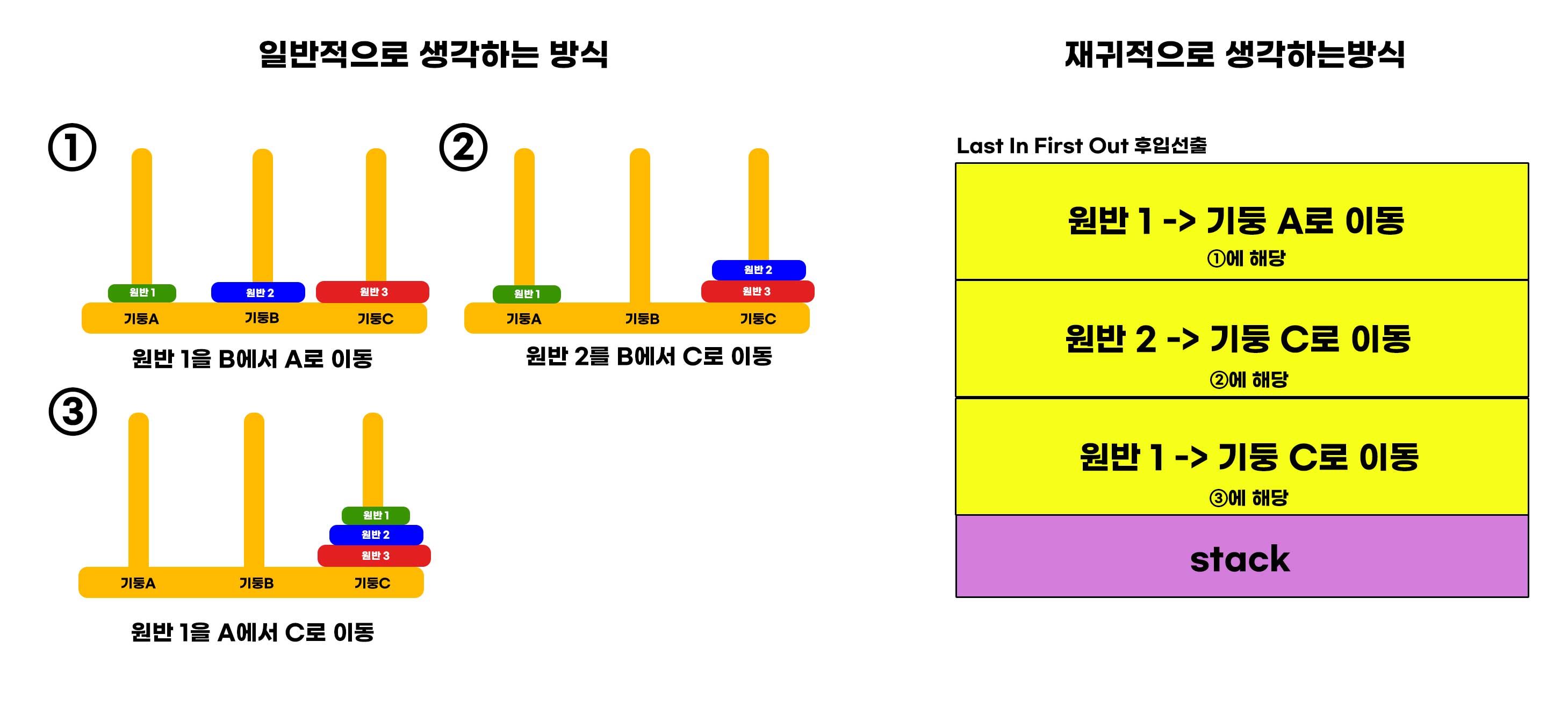
아래코드는 위에 그림을 식으로 표현한 값이다.
function hanoi(count, from, to, temp){
if(count==0) return //옮길 원반이 없으면 함수 종료
hanoi(count - 1, from, temp, to) //원반 1,2 B로 이동
console.log(`원반 ${count}를 ${from}에서 ${to}로 이동`) //원반 3, A에서 C로 이동
hanoi(count - 1, temp, to, from) //원반3이 C로 이동했으니 B에 있는 1,2도 C로 이동
}
hanoi(3, "A","C","B") //원반의개수, from(시작은 기둥 A에서), to(목표기둥은 C), temp(임시 기둥 B)
//원반 1를 A에서 C로 이동
//원반 2를 A에서 B로 이동
//원반 1를 C에서 B로 이동
//원반 3를 A에서 C로 이동
//원반 1를 B에서 A로 이동
//원반 2를 B에서 C로 이동
//원반 1를 A에서 C로 이동재귀함수의 장점
1. 코드의 가독성: 재귀 함수는 코드를 더 간결하게 만들 수 있다. 일반적으로 재귀 함수를 사용하면 코드의 가독성이 높아지며, 복잡한 알고리즘을 이해하기 쉬워진다.
2. 코드의 재사용성: 재귀 함수를 사용하면 여러 곳에서 사용할 수 있는 일반적인 함수를 만들 수 있다. 이렇게 만들어진 함수는 다른 함수에서 호출될 수 있으며, 코드의 재사용성을 높여준다다.
3. 알고리즘의 간결성: 일부 알고리즘은 재귀적으로 정의되기 때문에, 이러한 알고리즘을 재귀 함수로 구현하면 코드가 더 간결해진다.
재귀 함수의 단점
1. 메모리 사용: 재귀 함수는 함수를 호출할 때마다 스택에 데이터를 저장하기 때문에, 메모리 사용량이 늘어날 수 있다. 이로 인해 스택 오버플로우가 될수있다.
2. 속도: 재귀 함수는 일반적으로 반복문보다 느리다. 함수 호출이 많아질수록 성능이 저하될 수 있다.
3. 디버깅의 어려움: 재귀 함수를 디버깅할 때는 각각의 함수 호출이 어떻게 이루어지는지 추적하는 것이 어려울 수 있다.
정렬(sort)
정렬 알고리즘은 데이터를 특정한 순서로 정렬하는 알고리즘이다.
대표 알고리즘으로 버블정렬, 선택정렬, 삽입정렬, 병합정렬, 퀵정렬을 꼽을수가 있다.
연결리스트로도 정렬을 표현할수있지만 배열로 표현하면 좀더 직관적이고 쉽게 이해할수있어 배열로 작성했다.
1. 버블정렬
버블정렬은 앞에 있는 숫자와 옆에있는 숫자를 비교해서 자리를 바꾸는 알고리즘이다.
바깥의 for문이 반복될때마다 정렬되지 않은 원소 중에 가장 큰 원소가 정렬되고 안쪽 for문은 반복 횟수가 점점 줄어든다. (원소가 하나씩 정렬될수록 정렬되지 않은 원소들이 줄어들기때문)
이를 원소가 한개남을때까지 반복한다.
구현하기 상대적으로 쉽지만 데이터가 늘어날때 계산도 함께 늘어나기때문에 시간복잡도 O(n2)으로 볼수있어 성능면에서는 좋지않다.
function BubblesSort(arr){
for(let i = 0; i < arr.length - 1; i++){
for(let j = 0; j < (arr.length - i - 1); j++){
if(arr[j] > arr[j+1]){
let temp = arr[j]
arr[j] = arr[j+1]
arr[j+1] = temp
}
}
}
}
let arr = [4,2,3,1]
console.log(arr) // [4,2,3,1]
BubblesSort(arr)
console.log(arr)// [1,2,3,4]2. 선택정렬
선택정렬은 배열의 정렬되지 않은 영역의 첫번째 원소를 시작으로 마지막원소까지 비교후 가장작은 값을 첫번째 원소로 가져온다. 정렬되지 않은 영역을 전부 순회하고 나면 그 중 가장 작은값이랑 가장 앞에 있는 원소와 자리를 교체한다. 그리고 그 다음 원소로 넘어가 반복실행을 하며 정렬한다.
버블정렬과 마찬가지로 바깥쪽 for문이 실행될수록 안쪽 for문이 줄어드는 형태이고
데이터가 늘어날때 계산도 함께 늘어나기때문에 시간복잡도 O(n2)으로 볼수있다.
function SelectionSort(arr){
for(let i =0; i<arr.length -1; i++){
let minValueIndex = i;
for(let j= i+1; j<arr.length; j++){
if(arr[j] < arr[minValueIndex]){
minValueIndex = j
}
}
let temp = arr[i]
arr[i] = arr[minValueIndex]
arr[minValueIndex] = temp
}
}
let arr = [3,1,4,2]
console.log(arr) // [3,1,4,2]
SelectionSort(arr)
console.log(arr) // [1,2,3,4]3. 삽입정렬
삽입정렬은 선택정렬과 마찬가지로 정렬된영역과 정렬되지 않은 영역으로 나눠 진행한다.
삽입정렬은 정렬되지않은 영역에서 데이터를 하나씩 꺼내서 정렬된 영역 내 적절한 위치에 삽입해서 정렬하는 알고리즘이다. 가장 처음 요소는 정렬이 되었다고 가정을 하고 두번째 요소부터 배열의 길이만큼 순회한다.
버블,선택정렬과 마찬가지로 바깥쪽 for문이 실행될수록 안쪽 for문이 줄어드는 형태이기때문에
데이터가 늘어날때 계산도 함께 늘어나기때문에 시간복잡도 O(n2)으로 볼수있다.

function insertionSort(arr){
for(let i=1; i<arr.length;i++){ //정렬되지 않은 데이터의 첫번째
let insertingData = arr[i]
let j //삽입 위치 기억
for(j=i-1; j>=0; j--){ //역순
if(arr[j]> insertingData){
arr[j+1] = arr[j] //참이면 오른쪽에 덮어쓰기
}else{
break //for문 탈출, 삽입할 원소보다 작은 원소의 자리 찾았을때
}
}
arr[j+1] = insertingData
}
}
let arr = [4,1,5,3,6,2]
console.log(arr) //[4,1,5,3,6,2]
insertionSort(arr)
console.log(arr)// [1,2,3,4,5,6]4. 병합정렬
병합정렬은 이전에 배운 정렬과 비교하면 조금 복잡한 정렬 알고리즘에 속한다.
병합정렬은 분할정복(divide and conquer)방법을 사용하여 정렬을 수행하는 알고리즘이다.
병합정렬의 큰틀은 이렇다.
1. 주어진 배열을 두 개의 부분 배열로 분할한다.
2. 각 부분 배열을 병합정렬 알고리즘을 재귀적으로 적용하여 각각을 정렬한다.
3. 두 개의 정렬된 부분 배열을 병합하여 전체 배열을 정렬한다.
function MergeSort(arr, leftIndex, rightIndex){
if(leftIndex < rightIndex){ //배열의 원소가 1개가 될때까지
let midIndex = parseInt((leftIndex + rightIndex) / 2) //left인덱스와 right 인덱스의 중간값
MergeSort(arr, leftIndex, midIndex) //왼쪽 재귀적으로 호출해 정렬
MergeSort(arr, midIndex+1, rightIndex)//오른쪽 재귀적으로 호출해 정렬
Merge(arr, leftIndex, midIndex, rightIndex)
}
}
function Merge(arr, leftIndex, midIndex, rightIndex){
let leftAreaIndex = leftIndex
let rightAreaIndex = midIndex+1
let tempArr = []
tempArr.length = rightIndex+1
tempArr.fill(0,0, rightIndex+1)
let tempArrIndex = leftIndex
while(leftAreaIndex <= midIndex && rightAreaIndex <= rightIndex){
if(arr[leftAreaIndex] <= arr[rightAreaIndex]){
tempArr[tempArrIndex] = arr[leftAreaIndex++]
}else{
tempArr[tempArrIndex] = arr[rightAreaIndex++]
}
tempArrIndex++
}
//오른쪽 영역이 병합이 덜됐다면 for문을 돌면서 오른쪽 영역 나머지 전부 차례대로 tempArr에 넣어줌(결국 한쪽 영역이 전부 병합되었다면 나머지 영역은 이미 정렬된것과 마찬가지)
if(leftAreaIndex > midIndex){//왼쪽영역을 가르키는 leftAreaIndex가 오른쪽영역으로 침범했을때
for(let i = rightAreaIndex; i<=rightIndex; i++){
tempArr[tempArrIndex++]= arr[i]
}
}else{ //왼쪽영역 병합 덜되었다면 for문 돌면서 왼쪽 영역 나머지 전부 차례대로 tempArr에 넣어줌
for(let i = leftAreaIndex; i<=midIndex; i++){
tempArr[tempArrIndex++] = arr[i]
}
}
//병합이 완료된 후 arr로 복사해준다.
for(let i = leftIndex; i<=rightIndex; i++){
arr[i] = tempArr[i]
}
}
let arr = [3,5,2,4,1,7,8,6]
console.log(arr)
MergeSort(arr, 0, arr.length-1)
console.log(arr)코드해석
처음에는 배열 전체인 [3,5,2,4,1,7,8,6]를
MergeSort(arr, 0, arr.length-1) 로 호출하게 된다.
그리고 MergeSort 함수에서 배열의 길이가 1보다 작을때까지 반으로 나눠주게 되는데,
이 경우에는 배열의 길이가 8 이므로 midIndex는 3이 된다.
그래서 MergeSort를 다시 재귀적으로 두번 호출하게 된다.
-
MergeSort(arr, 0, 3)
이번에는 midIndex가 1이 되므로 MergeSort(arr, 0, 1)과 MergeSort(arr, 2, 3)를 다시 재귀적으로 호출하게 된다.
MergeSort(arr, 0, 1)은 배열 [3,5]를 다시 MergeSort하게 된다.
MergeSort(arr, 2, 3)은 배열 [2,4]를 다시 MergeSort하게 된다.
Merge(arr, 0, 1, 3)을 호출하여 두 개의 정렬된 배열을 합친다. -
MergeSort(arr, 4, 7)
이번에는 midIndex가 5이 되므로 MergeSort(arr, 4, 5)와 MergeSort(arr, 6, 7)을 다시 재귀적으로 호출하게 된다.
MergeSort(arr, 4, 5)는 배열 [1,7]을 다시 MergeSort하게 된다.
MergeSort(arr, 6, 7)는 배열 [8,6]을 다시 MergeSort하게 된다.
Merge(arr, 4, 5, 7)을 호출하여 두 개의 정렬된 배열을 합친다.
 그리고 마지막으로 Merge(arr, 0, 3, 7)을 호출하여 두 개의 정렬된 배열을 합친다.
그리고 마지막으로 Merge(arr, 0, 3, 7)을 호출하여 두 개의 정렬된 배열을 합친다.
이렇게 합쳐진 배열은 [1,2,3,4,5,6,7,8] 이 된다.
성능
이 알고리즘은 분할과 정복 단계에서 O(nlogn)의 시간 복잡도를 가지므로 전체 알고리즘의 시간 복잡도는 O(nlogn)이다. 또한 병합정렬은 안정적인 정렬 알고리즘이며, 비교 연산에 기반하여 작동하기 때문에 어떤 종류의 데이터에 대해서도 사용할 수 있다. 그러나 병합정렬은 배열의 크기가 큰 경우에는 추가적인 메모리를 필요로 하기 때문에 공간 복잡도가 크다는 단점이 있고 또한 구현하기 어렵다.
개인적인 생각
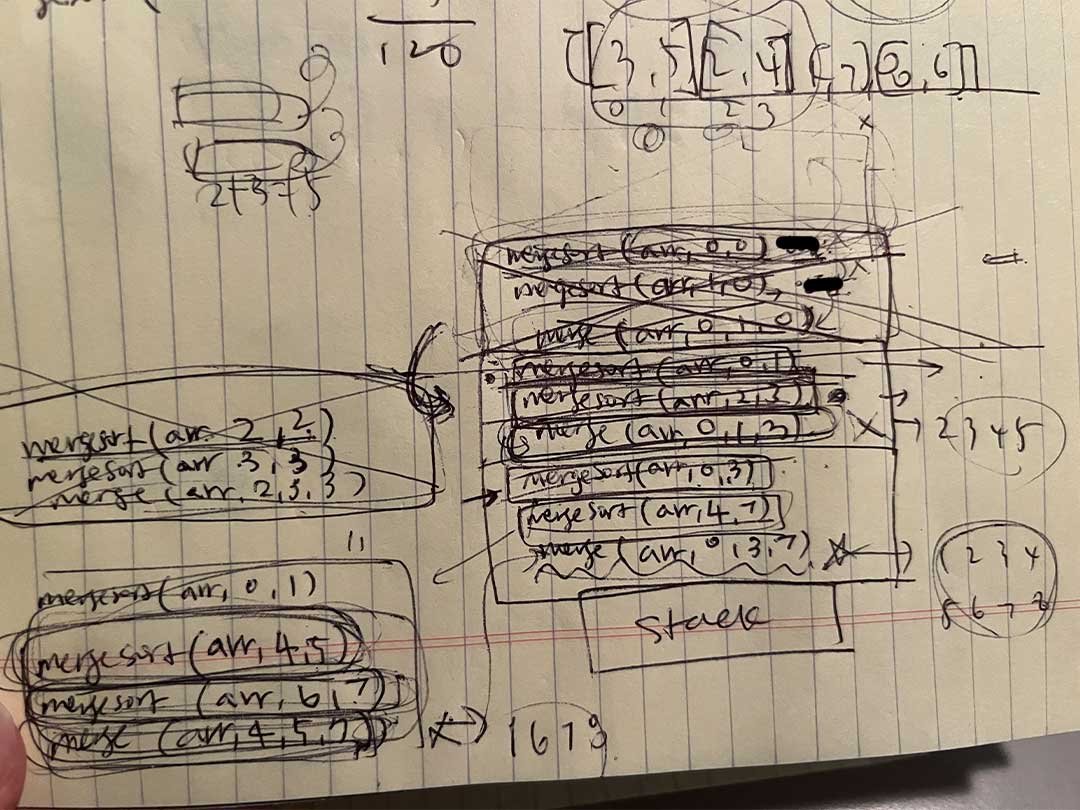 앞에 개념들은 괜찮았는데 병합정렬 처음 접했을때 어나더레벨이였음.
앞에 개념들은 괜찮았는데 병합정렬 처음 접했을때 어나더레벨이였음.
재귀 분할정복과 정렬이 합쳐지면서 그림,애니메이션,코드를 봐도 이해하는데 힘들어서 직접 스택을 그려서 하나하나 호출과정을 그렸다..정말 옛날에 수학 노가다 해서 문제푸는 그런느낌이였달까.. 이해하고나니 와 진짜 이런걸 어떻게 생각한지 정말 신기하다... 아무런 성능생각없이 웹페이지 만들때가 너무좋았다.
5. 퀵정렬
퀵 정렬 또한 분할정복(divide and conquer) 알고리즘을 사용하여 정렬하는 하는 방식이다.
퀵 정렬의 큰틀은 이렇다.
1. 기준점(pivot)을 선택한다. 대부분은 첫 번째 원소(가장 왼쪽에 있는 값)를 기준점으로 선택한다.
2. pivot을 기준으로 리스트를 두 개의 부분 리스트로 나눈다. pivot보다 작은 원소는 모두 왼쪽 부분 리스트로, pivot보다 큰 원소는 모두 오른쪽 부분 리스트로 보낸다.
3. 부분 리스트를 재귀적으로 정렬한다. 이를 위해 다시 pivot을 선택하고 부분 리스트를 두 개의 부분 리스트로 나눈다. (퀵정렬은 한번 진행될때마다 pivot이 정렬되고 정렬된 배열을 좌우로 나눠 같은 방식으로 재귀호출해 정렬한다)
4. 부분 리스트가 더 이상 나누어지지 않으면 정렬이 완료된다.
function quickSort(arr, left, right){//arr,0,8
if(left <= right){
let pivot = divide(arr, left, right) // 정렬된 피벗의 위치 리턴 (인덱스 4)
quickSort(arr, left, pivot -1) //왼쪽 영역 정렬
quickSort(arr, pivot +1, right) //오른쪽 영역 정렬
}
}
function divide(arr, left, right){
let pivot = arr[left];
let leftStartIndex = left + 1
let rightStartIndex = right
while(leftStartIndex <= rightStartIndex){ // 지나치기전까지
while(leftStartIndex <= right && pivot >= arr[leftStartIndex]){
leftStartIndex++ //피봇의 값이 leftStartIndex보다 크면 오른쪽으로 이동
}
while(rightStartIndex >= (left + 1) && pivot <= arr[rightStartIndex]){
rightStartIndex-- //피봇의 값이 작으면 왼쪽으로 이동
}
if(leftStartIndex <= rightStartIndex){
//leftstartindex가 rightstartindex를 지나치지 않는 조건
swap(arr, leftStartIndex,rightStartIndex)
}
}
//지나치면 서로 멈추고 피봇과 rightStartIndex값을 교환함 -> pivot이 자기 자리를 찾음
swap(arr, left, rightStartIndex)
return rightStartIndex //정렬된 피봇의 위치 리턴
}
function swap(arr, index1, index2){
let temp = arr[index1]
arr[index1] = arr[index2]
arr[index2] = temp
}
let arr = [5,3,7,2,6,4,9,1,8]
console.log(arr)
quickSort(arr, 0, arr.length-1)
console.log(arr)코드해석

- leftStartIndex가 pivot보다 큰 값 만날때까지 오른쪽으로 이동한다
- 큰값 (7)을 만나면 멈추고 rightStartIndex가 왼쪽으로 이동한다
- rightStartIndex가 pivot보다 작은 값(1)을 만나면 멈춘다
- leftStartIndex와 rightStartIndex가 멈추면 이 둘의 값(1,7)을 교환한다 (swap)
- 다시 leftStartIndex가 이동하고 rightStartIndex또한 이동하며 반복된다. 그러다 leftStartIndex와 rightStartIndex를 서로 지나치게되면 더이상 이동없이 멈춘다.
- 이때 pivot의 값과 rightStartIndex의 값을 교환한다. 이때 pivot의 값이였던 5는 정렬이 완료되게되고 해당 인덱스의값을 리턴한다.
- 정렬된 인덱스의 값을 중심으로 왼쪽 오른쪽 영역을 나눠 각각 같은 방식으로 진행하면 모든데이터가 정렬된다. ([4,3,1,2,5,6,9,7,8] 5를 중심으로 왼쪽은 5보다 작은값, 오른쪽은 5보다 큰값)
퀵정렬의 성능
이 알고리즘은 대부분의 경우 다른 정렬 알고리즘보다 빠르고, 평균 시간 복잡도가 O(n log n)이다. (데이터가 한개가 될때까지 반으로 나누고 이 작업을 데이터 n개만큼 반복해야하므로)
하지만 pivot선택을 잘못해 한쪽으로 치우쳐진경우 퀵 정렬의 시간 복잡도는 최악의 경우 O(n^2)이 될 수 있다. 즉 pivot을 선택하는 방법과 리스트의 상태에 따라 결정된다.
개인적인 생각
앞에 병합정렬을 이해하고 나면 퀵정렬은 이해하는데 꽤 쉽다
메모이제이션
앞에서 재귀함수에 대해 살펴봤다.
재귀함수를 사용했을때 장점도 있었지만 콜스택의 영역을 차지하는것, 성능관련 많은 단점이 있었다.
이것을 극복하기 위해 메모이제이션이라는 개념이 등장한다.
메모이제이션은 함수의 결과를 저장하고 이전에 계산된 값으로 캐시하여 같은 인수로 다시호출될때
중복된 계산을 방지하는 기법이다.
피보나치 수열을 예로들어 그냥 재귀함수를 호출했을 때와 메모이제이션 기법을 사용해
재귀호출을 했을때 어떤 차이점이 있는지 확인해보려한다.
function fibonacci1(n){
if(n == 0 || n == 1) return n;
return fibonacci1(n - 2) + fibonacci1(n - 1);
}
function fibonacci2(n, memo){
if(n == 0 || n == 1) return n;
if(memo[n] == null){
memo[n] = fibonacci2(n - 2, memo) + fibonacci2(n - 1, memo);
}
return memo[n];
}
let start = new Date();
console.log(fibonacci1(40)); //102334155 (40번째 값출력)
let end = new Date();
console.log(`fibonacci1 함수 실행시간: ${end - start}ms`); //fibonacci1 함수 실행시간: 1174ms
start = new Date();
console.log(fibonacci2(40, {})); //102334155
end = new Date();
console.log(`fibonacci2 함수 실행시간: ${end - start}ms`); //fibonacci2 함수 실행시간: 0ms코드해석
피보나치 수열은 매번 이전 두 항을 더해서 다음 항을 만들어가는 수이다. 예를 들어, 0과 1로 시작하면 다음 항은 0+1=1, 그 다음 항은 1+1=2, 그리고 1+2=3, 2+3=5, 3+5=8, ... 이렇게 계속해서 더해나가면서 수열이 만들어진다. (1,1,2,3,5,8....)
1. fibonacci1 함수
위 코드에서 fibonacci1 함수는 일반적인 재귀 함수로, 매번 중복된 계산을 수행한다.
머리속에서 잘 그려지지 않아 스택에서 함수 실행 과정을 그려봤다.

2. fibonacci2 함수 with 메모이제이션 기법
- fibonacci2(n, memo) 함수는 n번째 항을 계산하기 위해 memo라는 객체를 인자로 받는다.
memo는 함수의 실행 도중에 이전에 계산한 결과값을 저장하기 위한 객체로, memo[n]은 n번째 항의 값을 저장하는 속성이다. - 함수는 n이 0이거나 1일 경우, n 값을 반환하며 재귀호출을 종료한다. 그렇지 않은 경우에는 memo[n] 값이 null인지 확인한다.
- memo[n] 값이 null이라면 이전에 계산한 결과가 없으므로, fibonacci2(n-2, memo)와 fibonacci2(n-1, memo)를 호출하여 n번째 항의 값을 계산한다. 이 때, 호출된 값은 memo[n]에 저장된다.
- memo[n] 값이 null이 아니라면, memo[n] 값이 이미 계산되어 저장되어 있으므로, 중복 계산을 피하기 위해 저장된 memo[n] 값을 반환한다.
3. fibonacci1과 fibonacci2함수의 차이점
실행 시간을 비교하면, fibonacci1 함수는 중복 계산을 수행하므로 계산에 시간이 더 소요된다. 반면에 fibonacci2 함수는 중복 계산을 최소화하므로 더 빠르게 실행된다.
메모이제이션이 완전 대박같지만 몇가지 단점이 있다.
- 메모리 사용량 증가: 메모이제이션을 사용하면 이전에 계산된 값들을 저장하고 있어야 하므로, 메모리 사용량이 증가할 수 있다. 따라서, 계산할 데이터의 크기가 매우 크다면 메모리 부족 문제가 발생할 수 있다.
- 캐시 무효화 문제: 메모이제이션은 함수의 인수가 같으면 항상 같은 결과를 반환하므로, 함수 내부에서 외부 데이터를 변경하는 경우에는 예기치 않은 결과가 반환될 수 있다. 이러한 경우에는 메모이제이션된 값을 다시 계산해야 한다.
- 메모이제이션 코드 추가: 메모이제이션을 사용하려면 함수 내부에 추가적인 코드를 작성해야 한다. 이는 코드의 복잡도를 증가시키며, 코드의 가독성을 낮춘다.
타뷸레이션
타뷸레이션 또한 다이나믹 프로그래밍의 한 기법으로, 작은 문제의 결과값을 저장하면서, 전체 문제의 해결을 위해 필요한 계산을 수행하는 방법이다. 이전의 메모이제이션 기법과는 달리, 재귀 호출이나 스택을 사용하지 않기 때문에, 대부분의 경우에 성능이 더 우수하다.
function fibonacci3(n){
if(n <= 1) return n;
let table = [0, 1];
for(let i = 2; i <= n; i++){
table[i] = table[i - 2] + table[i - 1];
}
return table[n];
}
start = new Date();
console.log(fibonacci3(40));
end = new Date();
console.log(`fibonacci3 함수 실행시간: ${end - start}ms`);코드해석
위의 코드에서 table 배열은 작은 문제의 결과값을 저장하는 배열이다.
table[0]과 table[1]에는 각각 0과 1이 저장되어 있다. 그리고 반복문을 사용하여 table[i]에 table[i-2]와 table[i-1]의 값을 더한 결과를 저장한다. 이렇게 하면, table[n]에는 전체 문제인 n번째 피보나치 수열의 값이 저장되게된다.
성능
이 방법은 전체 문제의 해결에 필요한 모든 중간 값을 계산하여 table 배열에 저장하기 때문에, 동적 계획법에서 사용되는 부분 문제들의 순서를 결정하는 "의존성" 문제에 대해 고민할 필요가 없어지는 장점이 있다. 또한, 재귀 함수를 사용하지 않기 때문에, 스택 오버플로우가 발생하지 않는다는 장점도 있다.
일반적인 for문과 다른점은?
function fibonacci(n) {
let prev = 0;
let curr = 1;
for (let i = 2; i <= n; i++) {
let next = prev + curr;
prev = curr;
curr = next;
}
return curr;
}
console.log(fibonacci(5)); // 5처음에 타뷸레이션방법과 일반 for문이 살짝 비슷하지 않나라고 생각했는데 다르다.
for문 방식은 작은 문제들을 저장하지 않고, 큰 문제를 해결하기 위해 필요한 최소한의 작은 문제들만을 계산하고 이를 바탕으로 해결하는 방식이다.
또한 메모이제이션(memoization)과도 조금 다르다.
메모이제이션은 함수가 한 번 계산한 값을 저장해놓고, 같은 값이 필요할 때 이를 재사용하는 방식으로 작동한다. 그러나 위 코드에서는 반복문을 사용하여 작은 문제들을 계산하면서, 이전의 계산 결과를 저장하는 역할을 한다.
마무리
개인적으로 이해력이 빠르지 않다고 생각합니다.
그래서 직접 그리면서 눈으로 보고 확인해야합니다.
인프런강의중 그림으로 쉽게 배우는 자료구조와 알고리즘(기본편)이 많이 도움되었습니다.
위 예시들도 애니메이션을 통해 친절하게 잘 설명해주십니다.
도움이 될까봐 적어봅니다 :)
출처
https://m.blog.naver.com/pst8627/221658169228
https://siyoon210.tistory.com/58
https://im-developer.tistory.com/102
https://www.inflearn.com/course/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-%EA%B8%B0%EB%B3%B8/dashboard
https://velog.io/@beton/%EB%AC%B8%EC%A0%9C%ED%92%80%EC%9D%B4%EC%9E%AC%EA%B7%80%ED%95%A8%EC%88%98%EC%9D%98-%ED%98%95%ED%83%9C%EB%A1%9C-%ED%94%BC%EB%B3%B4%EB%82%98%EC%B9%98-%EC%88%98%EC%97%B4-%EA%B5%AC%ED%95%98%EA%B8%B0
