Apache Kafka
- 링크드인에서 Kafka 를 개발하던 엔지니어들이 Kafka 개발에 집중하기 위해 Confluent 라는 회사 창립
- 실시간 데이터 피드를 관리하기 위해 통일된 높은 처리량 , 낮은 지연 시간을 지닌 플랫폼 제공
- Apple , Netflix , kakao , Uber 등 다양한 회사들에서 사용
기존 End-toEnd 연결 방식의 아키텍처
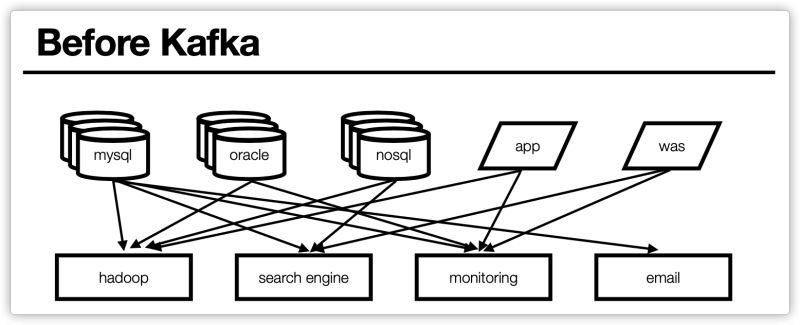
- 데이터 연동의 복잡성 증가
- 서로 다른 데이터 Pipeline 연결 주고
- 확장이 어려운 구조
Kafka 적용 효과
- 모든 시스템으로 데이터를 실시간으로 전송하여 처리할 수 있는 시스템
- 데이터가 많아지더라도 확장이 용이한 시스템
- Producer / Consumer 분리
- 메시지를 여러 Consumer 에게 허용
- 높은 처리량을 위한 메시지 최적화
- Scale-out 가능
단순히 데이터 전달 뿐만 아니라 데이터의 지연 시간을 낮춰주는 용도로 사용한다.
Kafka Broker
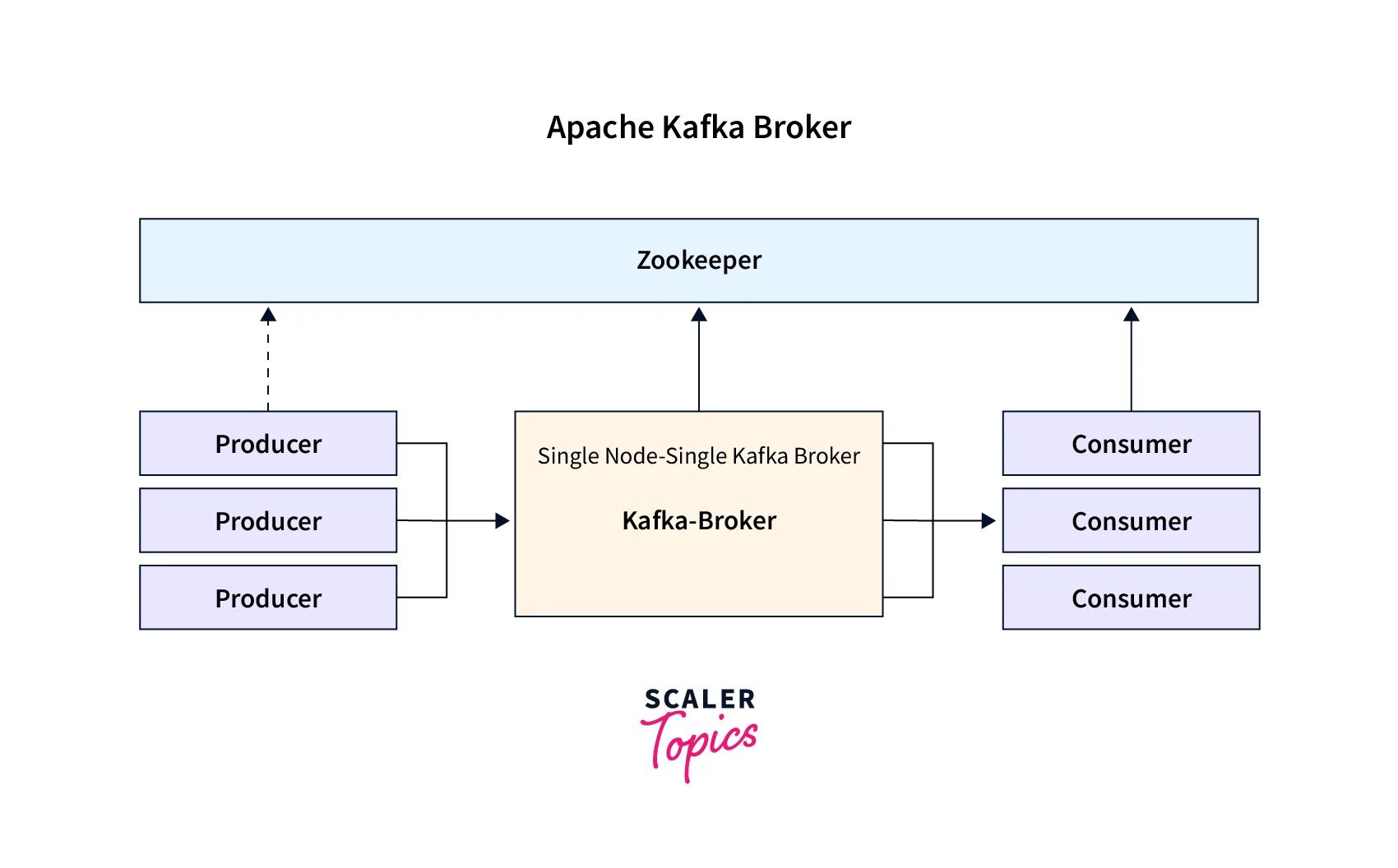
- 실행된 Kafka 애플리케이션 서버를 Kafka Broker 라고 한다.
- 3대 이상의 Broker Cluster 를 구성
- Zookeeper 연동
-> 역할 : 메타데이터 (Broker ID , Controller ID 등) 저장
-> Controller 정보 저장 - n개 Broker 중 1대는 Controller 기능 수행
-> Controller 는 각 Broker 에게 담당 파티션 할당을 수행하고, Broker 정상 동작 모니터링 관리를 한다.
Apache Kafka 설치
Apache Kafka 홈페이지에 들어가서 다운로드를 받으면 된다.
- OS 에 상관없이 같은 파일을 다운로드 받으면 된다.
- 받은 파일의 압축을 풀어보면 여기에 각 OS 마다 필요한 파일들이 존재한다.
- bin->windows 안에는 window 에서 돌아가는 .bat 파일들이 존재한다.
Producer / Consumer
- 다양한 방법이 있지만 가장 많이 사용하는 Kafka client 를 사용
- A 서비스에서 B , C 서비스에 전달을 할 때 다이렉트로 end-to-end 방식이 아닌 중간에 카프카라는 시스템을 두고 전달을 한다.
- topic 에 데이터를 보낸다고 생각하면 된다.
Kafka 서버 기동
- Zookeeper 와 Kafka 서버 구동
- /bin/zookeeper-server-start.sh /config/zookeeper.properties
- /bin/kafka-server-start.sh /config/server.properties
Topic 생성
- /bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092 --partitions 1
Topic 목록 확인
- /bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
Topic 목록 확인
- /bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
메시지 생산
- /bin/kafka-console-producer.sh --broker-list localhost:9092 --topic quickstart-events
메시지 소비
- /bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic quickstart-events --from-beginning
1. 주키퍼 실행 (2181 포트)
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
2. 카프카 메인 서버 실행 (9092 포트)
./bin/kafka-server-start.sh ./config/server.properties
토픽 확인
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
3. 토픽 생성 (토픽명 : quickstart-events)
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic quickstart-events --partitions 1
토픽 확인 명령어 쳐보면 quickstart-events 토픽이 생성된 것을 확인
4. 토픽 상세 정보 보기
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic quickstart-events
5. Producer 와 Consumer 역할을 해보자.
Producer 등록
/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic quickstart-events
Consumer 등록
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic quickstart-events --from-beginning
모든 메시지를 처음부터 얻기 위한 옵션 추가 (--from-beggining)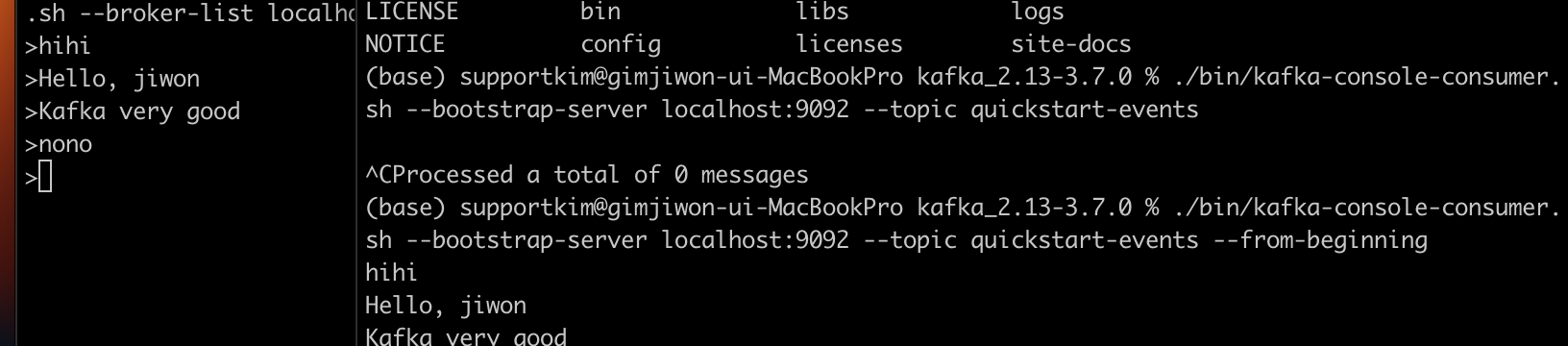
- 위와 같이 Producer 에서 메시지를 보내면 Consumer 로 메시지가 전달되는 것을 확인할 수 있다.
Kafka Connect
- kafka Connect 를 통해 Data 를 import / Export 가능
- 코드 없이 Configuration 으로 데이터를 이동
- Standalone mode , Distribution mode 지원
-> Restful API 통해 지원
-> Stream 또는 Batch 형태로 데이터 전송 가능
-> 커스텀 Connecotr 를 통한 다양한 Plugin 제공 (S3 , File , Mysql...)
흐름
SourceSystem -> Kafka Connect Source -> Kafka Cluster -> Kafka Connect Sink -> Target System(S3...)
OrderService 에서 MariaDB 연동
터미널에서 유레카 서비스 폴더로 이동한다.
- mysql.server.start 로 확인
- mysql -uroot -p 실행하고 비밀번호 입력해서 MariaDB 로 이동
- create database DB명 으로 DB 를 만든다.
그런후 order-service 에 가서 Mysql 의존성을 추가한다.
- h2-console 에 접근하고 id , pw 를 입력해서 해당 DB 에 접속한다.
- users 라는 테이블을 만든다.
생성한 테이블에 Kafka Connect 를 이용해서 users 테이블에 데이터가 insert 되면 그 데이터를 감지했다가 새로운 데이터베이스에 옮기는 작업을 해보자.
Kafka Connect 설치
Kafka Connect 설치 방법
curl -O http://packages.confluent.io/archive/5.5/confluent-community-5.5.2-2.12.tar.gz
curl -O http://packages.confluent.io/archive/6.1/confluent-community-6.1.0.tar.gz
- tar xvf confluent-community-6.1.0.tar.gz
Kafka 폴더에서 명령어로 실행
Kafka Connect 설정 (기본으로 사용)
/config/connect-distributed.properties
Kafka Connect 실행
./bin/connect-distributed ./etc/kafka/connect-distributed.properties
Topic 목록 화인
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --listJDBC Connector 설정
JAVA 에서 관계형 데이터 베이스를 사용하기 위해서 JDBC 라이브러리를 설치해야한다.
- 위에 예제를 해보기 위해서 필요한 작업
- 그래서 JDBC Connector 를 설치해야한다.
- 설치링크
- JDBC Conntor 와 Kafka Connector 를 연결하기 위해서는 plugin 정보를 추가해야한다.
- plugin.path = 위에서 설치한 JDBC Connector 폴더
- JdbcSoucrceConnector 에서 MariaDB 를 사용하기 위해서 mariadb 드라이버 복사
- 위에서 의존성을 추가했기 떄문에 그 maven 폴더에서 mariadb.jar 파일을 가져올 수 있다.
- 그것을 /share/java/kafka 에 넣어주면 된다.
주키퍼 서버 + 카프 메인 서버를 모두 실행 시키고 위에 명령어에서 Kafka Connect 를 실행하면 된다.
- 물론 그 전에 Kafka Connect 를 다운받고 tar xvf 명령어로 압축까지 푼 상태여야한다.
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
실행결과
__consumer_offsets
connect-configs
connect-offsets
connect-status
quickstart-events- 해당 명령어로 topic 을 조회해본 결과 아까 위에서 만든 quickstart-events 말고 4개가 더 추가로 만들어진것을 확인할 수 있다.
- Kafka Connect 가 저장 및 관리하기 위해 만든 topic 이라고 생각하면 된다.
그런후에 설치한 kafka-connect-jdbc 파일에 가서 lib 폴더까지 들어간 후 그 경로를 복사한다.
- kafka connect 압축을 풀었던 confluent-6.1.0 에 들어가서 /etc/kafka/connect-distributed.properties 에서 plugin.path=아까 복사한 경로 의 값으로 바꿔주고 저장하면 된다.
마지막으로 m2/jdbc/mariadb-java-client/version/ 에 들어가서 mariadb-java-client-version.jar 파일을 /confluent-6.1.0/share/java/kafka 로 옮겨주면 된다.
이제 Kafka 를 사용하기 위한 사전 준비는 다 했고 Kafka Source Connect 테스트를 해보자.
Kafka Source Connect 테스트
흐름
SourceSystem -> Kafka Connect Source -> Kafka Cluster -> Kafka Connect Sink -> Target System(S3...)
- 위에서 본 흐름인데, 우선 Kafka Connect Source 에 Database 를 가지도록 하고 그것을 Kafka Cluster (Kafka Topic) 에 저장을 한다.
- 이때 Kafka Topic 에 관심이 있다고 한 Sink 에 전달을 한다.
- 즉 Kafka Connect Sink 는 Target 한 System 에 데이터를 옮겨주는 역할이라고 생각하면 된다.
Kafka Source Connect 추가 (MariaDB)
흐름
- zookeeper 서버 실행 (kafka file)
- kafka-main-server 실행 (kafka file)
- kafka connect 실행 (confluent-6.1.0 file)
- ./bin/connect-distributed ./etc/kafka/connect-distributed.properties 명령어로 실행
{
"name" : "my-source-connect",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://localhost:3306/mydb",
"connection.user":"root",
"connection.password":"password",
"mode": "incrementing",
"incrementing.column.name" : "id",
"table.whitelist":"users",
"topic.prefix" : "my_topic_",
"tasks.max" : "1"
}
}- 위에 있는 JOSN 코드를 넣고 127.0.0.1:8083/connectors POST 요청
-> kafka connect 의 default port 가 8083 - JSON 에서 mode 는 데이터가 등록이 되면서 데이터가 자동으로 증가시키도록 하고 그 증가되는 컬럼은 id 라는 뜻이다.
- whitelist 는 마리아DB 데이터베이스에 특정한 값을 저장을 할 것인데 (insert) 그 database 를 계속 보고 있다가 변경사항이 생긴다면 그 데이터 값을 가지고 와서 topic 에 저장을 한다.
-> 즉 whitelist 에 있는 table 의 값을 가져 온다는 것 (users table)
그 변경사항은 my_topic_users 의 prefix 를 가지는 곳에 넣는다.
테스트를 할 때 MariaDB 에서 데이터를 추가하면 consumer 를 실행했을 때 그 데이터베이스에서 추가한 내용이 출력이 되는지 확인한다.
그런 후 토픽에 잘 보내졌는가? 실제 소스가 만들어졌는가? 를 확인해보면 된다.
127.0.0.1:8083/connectors GET 으로 source 를 볼 수 있고
127.0.0.1:8083/connectors/source명/status GET 으로 요청하면 더 자세하게 볼 수 있다.
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list - 위에 명령어를 통해 topic 을 확인해보자. (kafka file 에서 명령어 실행)
- 확인해보면 아직 데이터에 변경 사항이 없어서 따로 topic 이 만들어지지 않았다.
- 데이터 변경 사항을 만들어서 topic 이 생기도록 해보자.
insert into users(user_id , pwd , name) values('user1' , 'test1111' , 'Username') - 위와 같은 쿼리를 날린 후 다시 위에 있는 topic 조회 명령어를 실행해보자.
실행 결과
__consumer_offsets
connect-configs
connect-offsets
connect-status
my_topic_users
quickstart-events- 위처럼 my_topic_users 가 생겼다.
./bin/kafka-console-consumer.sh --bootstrap-server
localhost:9092 --topic my_topic_users --from-beginning
실행결과
{
"schema":{
"type":"struct",
"fields":[
{"type":"int32","optional":false,"field":"id"},
{"type":"string","optional":true,"field":"user_id"},
{"type":"string","optional":true,"field":"pwd"},
{"type":"string","optional":true,"field":"name"},
{"type":"int64","optional":true,"name":"org.apache.kafka.connect.data.Timestamp","version":1,
"field":"created_at"}],
"optional":false,
"name":"users"},
"payload":{
"id":1,
"user_id":"user1",
"pwd":"test1111",
"name":"Username",
"created_at":1709140788000
}
}
}
- 위의 명령어로 my_topic_users 의 정보를 가져오면 실행 결과 처럼 나온다.
- MariaDB 에서 insert 쿼리를 보내면 consumer 에서 schema , payload 등 값들이 넘어오는 것을 확인할 수 있다.
- payload 는 실제 전달 되는 데이터라고 생각하면 된다.
- 나중에 Topic 을 이용해서 DB 에 저장하고 싶다면 위와 같은 포맷으로 전달하면 된다.
DB 에 직접 데이터를 전달하지 않고 Topic 에 데이터를 전달하기만 하면 그 값이 DB 에 넣을 수 있도록 해야한다.
위와 같은 작업을 해주는 것이 Sink Connect 이다.
Kafka Sink Connect 사용
- topic 에다가 데이터가 쌓이게 되는데 이때 Sink Connect 가 topic 에 전달된 데이터를 가지고 와서 사용하는 것이라고 생각하면 된다.
Source Connect 에서 했던 것 처럼 JSON 형태로 요청을 보내는 형식으로 해본다.
MariaDB 에서 데이터를 추가 하면 my_Db.my_topic_users 에도 들어가는지 확인한다.
Kafka Producer 를 이용해서 Kafka Topic 에 데이터 직접 전송
- kafka-console-producer 에서 데이터 전송 -> Topic 에 추가 -> MariaDB 에 추가
{
"name":"my-sink-connect",
"config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://localhost:3306/mydb",
"connection.user":"root",
"connection.password":"test1357",
"auto.create":"true",
"auto.evolve":"true",
"delete.enabled":"false",
"tasks.max":"1",
"topics":"my_topic_users"
}
}- Source Connect 와 같이 127.0.0.1:8083/connectors POST 로 전달
- Sink Connect 와 연결할 곳은 topics 에 입력하면 된다.
- auto.create 는 topic 와 같은 table 을 생성하겠다는 뜻이다.
- 127.0.0.1:8083/connectors GET 으로 요청해보면 위에서 등록한 source 와 지금 등록한 sink 가 등록된 것을 확인할 수 있다.
sink 가 정상적으로 만들어졌다는 것은 지금 우리가 가지고 있는 데이터베이스에 topic 의 이름과 같은 형태의 테이블이 생성되었다는 것을 확인한다.
- 실제로 show tables; 를 하면 원래 있었던 users 말고 my_topic_users 도 생성된 것을 확인할 수 있었다.
- 실제로 MariaDB 에서 insert 쿼리를 날리면 my_topic_users 테이블에도 데이터가 들어가는 것을 확인할 수 있다.
즉 지금까지 흐름을 보면 MariaDB 에다가 insert 쿼리를 보내면 topic 에 데이터가 전달이 되고 이 topic 에서 다른 Target Table 에 들어가는 것을 확인한 것이다.
이번에는 Producer 에서 직접 콘솔로 데이터를 넣어보자.
(kafka file)
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my_topic_users- 해당 명령어를 실행하면 프롬프트가 변경되는데 여기에 직접 위에서 말한 format 대로 넣어서 데이터를 넣으면 된다.
- schema , payload 의 포맷을 맞춰서 보내면 된다.
- 실제로 넣고 실행한뒤 MariaDB 에서 users 의 테이블을 조회하면 방금 넣었던 데이터가 안 들어가있다.
- 그 이유는 users 는 topic 으로부터 데이터를 가져오는 것이 아니라 자신이 가지고 있는 데이터를 topic 에 넣는 것이기 때문에 Producer 가 넣었던 데이터가 없다.
- 하지만 my_topic_users 테이블에는 데이터가 들어간 것을 확인할 수 있다.
- Sink Connect 만으로도 Target Source 에 반영되게도 할 수 있다.
다음에는 이렇게 배운 Source Connect + Sink Connect 를 이용해서 전에 만들었던 order-service , catalog-service 에도 적용해보자.
- 데이터 동기화 용도
- 단일 데이터베이스에 여러가지 인스턴스로부터 넘겨받은 데이터를 정리하는 용도
- 2가지 용도로 사용할 수 있다.
