티베로 유틸리티
티베로 유틸리티 특징
- 접속 정보가 필요하다.
- (ip, port, db_name, username, password)
- 접속을 위한 인터페이스 드라이버 라이브러리 파일 필요
- tbsql : cli libaray파일
- tbexport, tbimport, tbloader, T-up : jdbc library 파일
- tbsql을 제외한 유틸리티들은 동작을 위해 JDK가 설치되어 있어야 한다.
툴들은 전부 접속을 해야하고 대상은 인스턴스
tbSQL을 제외하곤 구동을 위해 모두 JDK가 설치되어 있어야 한다.
서버 실행, 인스턴스에 접속하는 부분이 중요하다.
서버와 접속해야 제대로 실행된다. == 접속정보가 세팅되어있어야 한다.
- 접속정보 다섯가지 :
- ip정보 (티베로 인스턴스의 위치)
티베로 인스턴스가 제대로 동작하고 있어야 한다.
tbSQL
- 터미널에서 SQL질의를 수행하는 유틸리티
- 텍스트 모드의 쿼리 툴
- 가장 기본적이고 중요한 툴
티베로 설치부터 sql 조회도 할 수 있다.
그리고 서버를 운영하는 관리자(DBA)의 입장에서 중요한 툴
tbStudio
- sql문장을 작성하고 실행하는 툴이다.
- GUI를 제공
- 테크넷에서 다운받아 사용 가능
- 자바로 만들어졌다. 동작을 위해서는 JDK가 필요하다.
서버 운영자보다는 어플리케이션 개발 시 많이 사용
tbExport/tbImport
- DB에 저장된 Scchema객체 및 데이터를 추출/적재하는 도구
- 터미널에서 사용 가능
- 사용용도
- 백업/복구 용도로 사용 가능.
- 데이터를 옮기는 용도로 사용 가능.
- 저장공간의 재구성을 위해 사용 (조각 모음 )
- 단편화된 공간을 재구성할 때 사용된다.
- 추출(export)된 파일에는 DDL(create table …)문과 data가 들어있다.
- 추출한 파일을 실행(import)하면 빈공간 없이 compact하게 데이터가 들어간다.
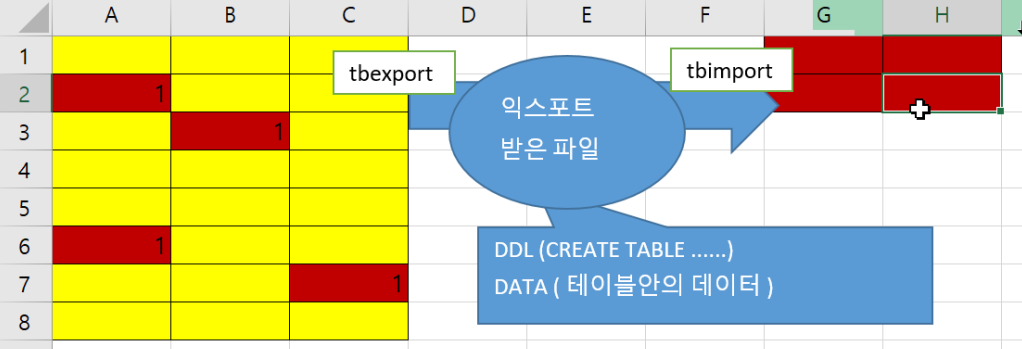
특정 테이블을 지정해서 추출하고, 파일로 저장해서 다시 DB에 집어넣을 수 있다.
서로 다른 데이터베이스에 있는 데이터를 옮기는 용도로 사용할 수 있다.
tbLoader
- 데이터를 데이터베이스에 적재한다.
테이블을 별도로 만들어두고, 데이터를 집어넣는 단계에서 사용한다.
단, text 형식일 때 Loader가 읽어서 데이터베이스에 집어넣는다.
T-UP
- 테이블을 선택해서 마이그레이션할 수 있다.
- 데이터 마이그레이션이란 source 데이터베이스에서 꺼내서 Target 데이터베이스로 내용물을 옮기는 과정이다.
마이그레이션이란 쉽지 않은 작업이다.
1. 옮겨야할 데이터가 많을 수 있다. 데이터가 많을 경우에는 옮기는 시간이 매우 오래 걸릴 수 있다.
2. 오라클의 테이블 -> 티베로의 테이블로 마이그레이션
- 서로 다른 벤더 사의 마이그레이션일 경우 데이터를 변환하는 작업이 필요하다.
일반적으로는 마이그레이션 소프트웨어가 별도로 존재한다. 여러가지 마이그레이션 소프트웨어가 있다는 것을 알아두시오. 아주 간단한 마이그레이션 기능만 가지고 있는 것이 T-UP이다.
마이그레이션은 요약하면 2가지를 옮기는 작업이다(DDL, DATA)
tbSQL
SQL문장을 입력 받아서 티베로 인스턴스에게 전달받고...다시 전달하는 채팅기능
tbSQL을 시작한다고 해도 인스턴스와 연결되는 것은 아니다. 접속정보를 전달받아서 연결해야한다.
접속정보를 전달하지 않은 상태에서는? sql문을 작성해도 실행되지 않는다.
tbSQL 환경설정
SHOW ALL
SET 명령 ON | OFF
- autocommit
- 자동 커밋 모드 설정 가능
set autocommit ON
- autotrace
- 실행계획 출력 여부 설정 가능
- 기본 설정은 실행계획이 출력되지 않는 것이다.
set AutoTrace ON- AutoTrace 을 ON 으로 설정하면 sql 문장을 실행한 뒤 실행계획을 조회해서 결과를 화면에 출력한다. (실행계획 조회 쿼리를 서버에 전달하고 결과를 받아오는 것)
단, 설정은 현재 tbsql 세션 실행 중에만 적용되고 tbsql종료 시에는 기본 설정으로 다시 돌아간다.
환경설정 세팅을 고정하기 위해서는 설정 세팅을 자동화해야 한다.
- tbsql실행 시 자동 실행되는 특정 파일.(?)
tbSQL 시작 및 종료
접속 시 사용자 정보가 사용된다.
- tbSQL 시작
- 실행 후 유저 정보를 이용해서 접속
conn명령어 사용
- 실행과 동시에 유저 정보를 이용해서 접속
- 실행 후 유저 정보를 이용해서 접속
- tbSQL 종료
disconnect명령 사용 시 tbsql은 계속 구동된다. 유저의 접속만 끊어진 상태exit/quit명령은 tbsql까지 종료시킨다.
tbSQL 기본 기능
tbSQL 자체 명령어를 이용해서 서버에게 명령을 내리거나 다른 자체적인 일을 수행할 수 있다.
Query 수행
쿼리를 서버에 전달한다.
tbPSM 프로그램의 입력
tbsql은 sql랭귀지 뿐만 아니라 tbPSM 랭귀지도 지원한다.
tbPSM랭귀지는 티베로 유틸리티 안내서에서 자세히 알아볼 수 있다.
tbStudio
티베로를 이용하는 개발을 돕는 GUI 툴로, 개발에 필요한 기능과 환경을 제공한다.
tbStudio는 티베로에서 배포하고 있는 쿼리 툴이다. 대표적인 쿼리 툴로는 Toad for Oracle 등이 있다. Orange for Tibero라는 쿼리 툴도 있다.
호환성
-
티베로의 호환성은 오라클의 부분집합이다.
티베로는 오라클이 제공하는 기능의 일부분에 대한 기능을 가지고 있다. -
예를 들어,
데이터를 처리하기 위해 사용되는 랭귀지 두 가지(집합연산 처리 랭귀지, 절차적인 랭귀지)가 있는데 오라클과 티베로에서의 이름은 각각 다음과 같다.
오라클에서는 SQL과 PL/SQL
티베로에서는 tbSQL과 tbPSM -
보통 조직이 다루는 가장 중요한 정보일수록 오라클DB에 저장되어있다.
3Tier구조와 sql툴
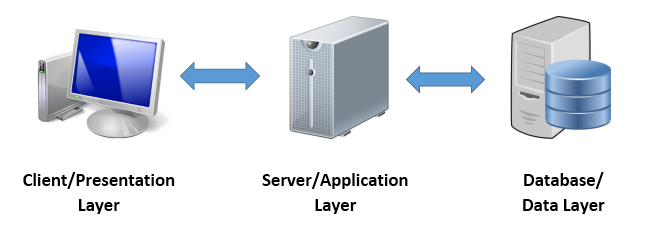 이미지 출처 : http://dohyunworlds.blogspot.com/2016/08/3-3-tier-architecture.html
이미지 출처 : http://dohyunworlds.blogspot.com/2016/08/3-3-tier-architecture.html
- 3Tier구조에서 서버/애플리케이션 계층이 DB계층에 접근하기 위해서는 sql쿼리가 필요하다. sql쿼리를 만들기 위해 필요한 툴이 tbStudio가 되는 것이다.
예전 2Tier 구조에서는 서버/애플리케이션 계층이 데이터를 가지고 있었다. 따라서 애플리케이션 개발자가 데이터 처리를 위한 로직도 구현해야 했다. 데이터 관리 소프트웨어(mySQL 등)의 등장 이후로는 서버에서 데이터 처리 기능이 분리되어 이제 서버는 데이터를 직접 다루지 않고 sql랭귀지를 통해 db에 데이터 처리를 맡기는 흐름이 되었다.
주요기능
- Tibro Studio의 환경설정
- 일반적인 SQL문 작성
- 스키마객체의 관리
- 스키마 객체:
- 테이블, 인덱스, 뷰, 프로시저 등의 특정한 스키마에 속한 오브젝트(객체)
- 특정 유저의 스키마에 속한 객체
- 객체들의 생성, 변경, 삭제등의 작업을 돕는다.
- 스키마 객체:
- 외부 유틸리티 및 프로그램의 실행
- tbExport 등의 유틸리티가 내장되어 있다.
- 개발 도구를 이용한 데이터베이스 개발
설치 및 실행방법
티베로 스튜디오 기동을 위해서는 JRE 1.6버전 이상이 반드시 설치되어 있어야 한다.
JDK1.8설치해야한다... 다른 거 안 됨
tbStudio.ini
- JVM 메모리 옵션
- 자바를 사용하는 애플리케이션은 공통적으로 가지고 있는 옵션이다.
환경설정
- window - DataFormat
- NLS Format
기능
SQL Editor
- 일반적인 SQL문 편집 가능
- 실행계획 출력 가능
- 실행계획을 출력하는 기능은 성능향상을 위해 필요하다. 실행계획을 변경하기 위해 사용하는 것이 sql힌트이다.
- 실행계획을 출력하는 기능은 성능향상을 위해 필요하다. 실행계획을 변경하기 위해 사용하는 것이 sql힌트이다.
PSM Editor
- PL/SQL 문장 편집 및 컴파일 기능
- tibero의 PL/SQL에 해당하는 tbPSM 랭귀지로 작성한 스키마 객체
- 데이터 처리를 목적으로 하고 있는 객체
- 데이터를 가져와서 가공
- 일반적인 프로그램과 다른 점
- DB와 연동해서 db에서 값을 가져오는 형식으로 작성. 연동이 간단하다.
- 일반적인 서버/애플리케이션 계층의 애플리케이션(자바 등)이 DB와 연동하기 위해서는 네트워크를 타야 한다. 데이터 연동을 위해서는 db 클라이언트, 네트워크 부하 등 성능을 낮추는 요소들이 많고 DB와 연동하기 위한 코드 자체의 양이 많아진다. 반면 PL/SQL은 DB자체에 존재하기 때문에 상대적으로 연동이 간단하다.
스키마 트리 브라우저
- 계층구조로 스키마 객체를 확인할 수 있다.
- Schema Tree Browser - 컨텍스트 메뉴
- Schema Object Detail
- 테이블 통계정보 등 확인 가능
- 테이블 통계정보 등 확인 가능
Export / Import
- tbExport와 tbImport는 별도로 존재하지만 Tibero Studio에 내장되어 있기도 하다.
- DB구조와 데이터를 binary 파일로 Export 및 Import 수행
- Rows 체크를 하지 않으면 DDL만 들어있다(DML제외).
tbExport / tbImport
.txt파일과 .dat(바이너리 파일)을 내보낼 수 있다.
tbExport / tbImport은 티베로 서버안에 기본적으로 포함되어 있다. (bin폴더)
Tibero 내부 스키마를 sql문 형태로 추출하고 Import할 수 있다.
tbStudio에서 진행하는 방법
접속정보
- 어떤 접속이든 접속정보에는 항상 다섯가지가 필요하다.
(IP, PORT넘버, DB네임, USER이름, 패스워드)
Export
Export 모드
- full모드
- sys사용자를 제외한 모든 사용자의 객체를 추출한다.
- DBA 권한을 가진 사용자만 사용 가능하다. sys 사용자의 스키마에는 딕셔너리 뷰 가 포함된다. (주의 : 현재 실습 중인 tibero 유저는 sys유저와 비슷한 권한을 부여받은 상태이기 때문에 FULL모드를 사용할 수 있다.)
- 사용자 모드
- 어떤 사용자가 소유한 모든 스키마 정보를 추출할 수 있다.
- 테이블 모드
- Export 모드 옵션
- show DDL Scripts 체크
- CREATE 쿼리 문장이 들어있는
.txt파일을 만들어준다. - show DDL Scripts 을 체크하지 않아도 CREATE문이 포함된
.dat파일은 생성된다. 그러나.dat파일은 바이너리 파일이기 때문에 사용자가 직접 보고 해석할 수 없다. show DDL Scripts옵션으로 만들어진.txt파일은 사용자가 볼 수도 있고 수정도 가능하다.
.dat파일은 티베로에서만 import할 수 있고 export도 마찬가지이다. ExpImp파일 : show DDL Scripts 체크로 만들어진 .txt 파일
- CREATE 쿼리 문장이 들어있는
Import
Import는 DDL을 실행하고 데이터를 집어넣는 작업이다.
DDL과 데이터는 .dat파일 내에 들어있다.
.dat파일 내에서 import할 범위를 정의할 수 있다
Import 모드
- full모드
- sys사용자를 제외한 모든 사용자의 객체를 Import한다.
- DBA 권한을 가진 사용자만 사용 가능하다. sys 사용자의 스키마는 딕셔너리 뷰를 포함한다.
- 사용자 모드
- 어떤 사용자가 소유한 모든 스키마 정보를 Import할 수 있다.
- 테이블 모드
- 특정 테이블만 Import
리프레시 : 딕셔너리 뷰에서 정보를 조회해서 트리구조를 보여주는 것
tbImport 툴이 사용하는 파라미터.(?)
테이블 TRUNCATE 후 데이터 Import하는 경우
- 스키마만 존재하고 데이터는 없는 상태가 된다.
- 이 상태에서 Import를 한다면 Duplicate 발생. 이미 스키마가 존재하기 때문에 CREATE문의 충돌로 인해 데이터는 Import되지 않는다. Import의 동작은 1) DDL문을 실행하고 2) 데이터를 집어넣는 두 가지 작업 순서로 진행되는데 첫 번째 작업인 DDL에서 충돌이 발생하면 두 번째 작업을 실행하지 않기 때문에 데이터는 들어가지 않게 된다.
- 해결방법
- 테이블을 DROP한 뒤 진행한다.
- Import시 옵션을 조정한다.
- Advanced Options -
Ignore the "schema object already exist"옵션 설정 - 에러 발생 시 무시하고 뒷작업을 진행한다.
- Advanced Options -
putty에서 진행하는 방법
실행파일은 $TB_HOME/client/bin 에 존재한다.
tbexport / tbimport 치면 파라미터 조회 가능
Export
디렉토리 생성
[tibero@T1:/tibero]$ mkdir expimpexport 접속정보와 파라미터
- tbexport
IP=localhostPORT=8629SID=tiberoUSERNAME=sysPASSWORD=tiberoFULL=YFILE=/tibero/expimp/default.datSCRIPT=Y - 접속정보
IP: 현재 tiberoDB와 tbExport가 동일한 곳에 설치되어있으므로localhostPORT: 기본값과 동일한 경우 생략 가능SID: 데이터베이스 이름USERNAME: 유저 이름PASSWORD: 패스워드- 파라미터
FULL: FULL MODE 설정 (default = N)FILE: 경로와 이름 설정SCRIPT: .txt파일 저장
FULL MODE에서는 sys유저를 제외한 모든 유저의 스키마가 export된다.
일반적으로 export작업은 관리자가 한다. export 시에는 여러 정보(ex: 딕셔너리)에 대한 접근이 가능해야한다. 따라서 보통은 그런 권한이 있는 sys유저로 작업한다.
Import
Import접속정보와 파라미터
- tbimport
IP=localhostPORT=8629SID=tiberoUSERNAME=sysPASSWORD=tiberoTABLE=TIBERO.DEPTIGNORE=Y; (접속정보 동일)
- 파라미터
TABLE: 대상 테이블IGNORE: 객체가 이미 존재해서 발생하는 에러를 무시한다.
즉, 스키마만 존재하고 데이터는 없는 상태에서 Import시 CREATE문으로 인해 발생하는 에러를 무시하고 데이터를 INSERT하도록 한다. (default = N)
원격에서 export받아서 로컬에 import
-
로컬에서 로컬로 작업했던 것과 차이점
- export받는 대상과 import 대상의 스키마가 동일하지 않다.
FROMUSER=원격유저이름TOUSER=로컬유저이름 파라미터 추가 필요
tibero.selgrade여야 하는데
edu.selgarde여서 에러 발생(추가정리 필요)
[tibero@T1:/tibero]$ tbsql tibero/tmax
SQL> SELECT * FROM SALGRADE@TLINK; -- 원격 DB에 있는 테이블 조회
GRADE LOSAL HISAL
---------- ---------- ----------
1 700 1200
2 1201 1400
3 1401 2000
4 2001 3000
5 3001 9999
[tibero@T1:/tibero]$ mkdir expimp2 -- 원격 DB export할 디렉토리 생성
[tibero@T1:/tibero]$ cd expimp2
-- tbexport 실행
[tibero@T1:/tibero/expimp2]$ tbexport IP=10.188.191.33 PORT=8629 SID=tibero USERNAME=edu PASSWORD=edu TABLE=EDU.SALGRADE FILE=default.dat SCRIPT=Y
-- 로컬 DB 테이블 확인
[tibero@T1:/tibero/expimp2]$ tbsql tibero/tmax
SQL> ls table
NAME SUBNAME TYPE
---------------------------------- ------------------------ --------------------
DEPT TABLE
EMP TABLE
-- tbimport 실행
[tibero@T1:/tibero/expimp2]$ tbimport IP=localhost PORT=8629 SID=tibero USERNAME=tibero PASSWORD=tmax TABLE=SALGRADE FROMUSER=EDU TOUSER=TIBERO;
-- 로컬 DB 확인
SQL> ls table
NAME SUBNAME TYPE
---------------------------------- ------------------------ --------------------
DEPT TABLE
EMP TABLE
SALGRADE
SQL> SELECT * FROM SALGRADE;
GRADE LOSAL HISAL
---------- ---------- ----------
1 700 1200
2 1201 1400
3 1401 2000
4 2001 3000
5 3001 9999
tbLoader
tbLoader는 대량의 데이터를 한번에 Tibero 데이터베이스에 저장하기 위한 유틸리티
컬럼 데이터만 일반 텍스트 파일로 만들어서 한꺼번에 적재한다.
tbLoader 구동 전, 티베로에는 .dat파일을 넣을 테이블이 존재해야 한다.
tbLoader가 .dat파일에 담긴 값을 읽어서 티베로에 넣는다.
실행 시 log파일과 bad파일을 남긴다.
tbLoader입출력 파일
- 컨트롤파일 : 실행을 위한 파라미터를 지정한 파일
- 필드의 데이터를 어떤 컬럼에 넣을 것인가? 를 결정
- 데이터파일 : 데이터베이스의 테이블에 저장할 데이터가 들어있는 텍스트 파일
- 고정된 레코드 형태
- 구분자 없이 위치로 구분한다.
- 유연성 부족(중간에 데이터를 삽입하기 위해서는 구조를 전부 바꿔야 한다.)
- 속도가 빠르다.
- 분리된 레코드 형태
- 구분자(,)로 구분한다.
- 유연한 사용
- 속도가 느리다.
- 고정된 레코드 형태
- 로그 파일
- tbLoader의 실행 과정을 기록한다.
- 오류 파일
- 로드에 실패한 레코드의 데이터를 기록한다.
세 가지 경우의 tbLoader예제
분리된 레코드 형태, 고정된 레코드 형태, BLOB과 CLOB 타입과 같은 대용량 데이터가 존재 하는 경우
분리된 레코드 형태
- 테이블을 생성한다(모든 예제에서 공통 사항이다).
- 컨트롤 파일을 작성한다.
- 데이터 파일을 작성한다.
- tbLoader 유틸리티를 실행한다.
- 로그 파일과 오류 파일을 확인한다.
- 테이블을 생성
- 컨트롤 파일 작성
- loader 디렉토리 스스로 만들어야
-- 컨트롤 파일
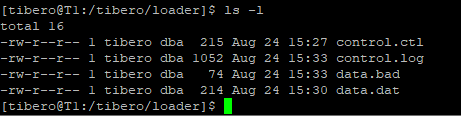
[tibero@T1://tibero/loader]$ cat control.ctl
LOAD DATA
INFILE './data.dat' -- 현재 디렉토리의 data.dat파일
APPEND
INTO TABLE club
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '|\n'
IGNORE 1 LINES -- 데이터 파일 첫 번째 줄의 레코드 무시
(
id integer external,
name,
masterid integer external
)
- 데이터 파일 작성
-- 데이터 파일
[tibero@T1:/tibero/loader]$ cat data.dat
id name masterid|
111111,FC-SNIFER,2345|
dkkkkkkkkkk|
111112,"DOCTOR CLUBE ZZANG",2222|
111113,"ARTLOVE",3333|
111114,FINANCE,1235|
111115,"DANCE MANIA",2456|
111116,"MUHANZILZU",2378|
111117,"INT'L",5555- tbLoader 유틸리티 실행
tbloader userid=tibero/tmax@tibero control=./control.ctl
-- userid=Username/password@dbname control=컨트롤파일명- 로그 파일과 오류 파일 확인
- 오류 파일을 찾아서 고쳐서 수정한 뒤 로딩해야 한다.
-- 수정 이전 data.bad
[tibero@T1:/tibero/loader]$ cat data.bad
dkkkkkkkkkk| -- 필드가 분리되지 않았다.
111112,"DOCTOR CLUBE ZZANG",2222| -- VARCHAR(10)을 넘어간다.
111115,"DANCE MANIA",2456| -- VARCHAR(10)을 넘어간다.-- data.bad를 복사해서 수정한 data2.dat 파일
[tibero@T1:/tibero/loader]$ cat data2.dat
111118,"dkkkkkkkkk",9999|
111112,"DOCTOR CLU",2222|
111115,"DANCE MANI",2456
-- 컨트롤 파일 수정
[tibero@T1:/tibero/loader]$ cp control.ctl control2.ctl
[tibero@T1:/tibero/loader]$ vi control2.ctl
[tibero@T1:/tibero/loader]$ cat control2.ctl
LOAD DATA
INFILE './data2.dat'
APPEND
INTO TABLE club
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '|\n'
(
id integer external,
name,
masterid integer external
)
-- loader 다시 수행
[tibero@T1:/tibero/loader]$ tbloader userid=tibero/tmax@tibero control=./control2.ctlT-UP
Analyzer
- 이관 이전 전환대상 DB
- source는 오라클 / MsSQL 등 여러 DB가 될 수 있다.
Migrator
- 이관 대상 (target DB)
- 티베로만 가능하다.
PC에서 T-up소프트웨어를 시작하면 네트워크를 거쳐서 서버 장비에 연결한다. 이기종 DB 간 연결을 위해서는 인터페이스 파일이 있어야 한다. T-UP을 이용한 이기종 DB 연결은 쉘로 진행하는 것보다 훨씬 간단하다.
Source Database
- 마이그레이션 대상이 되는 소스 데이터베이스에 접속
Type Conversion
- 소스 데이터베이스의 데이터 타입 변환에 관한 정보를 조회 (기본값 설정 되어있음)
Schema Object
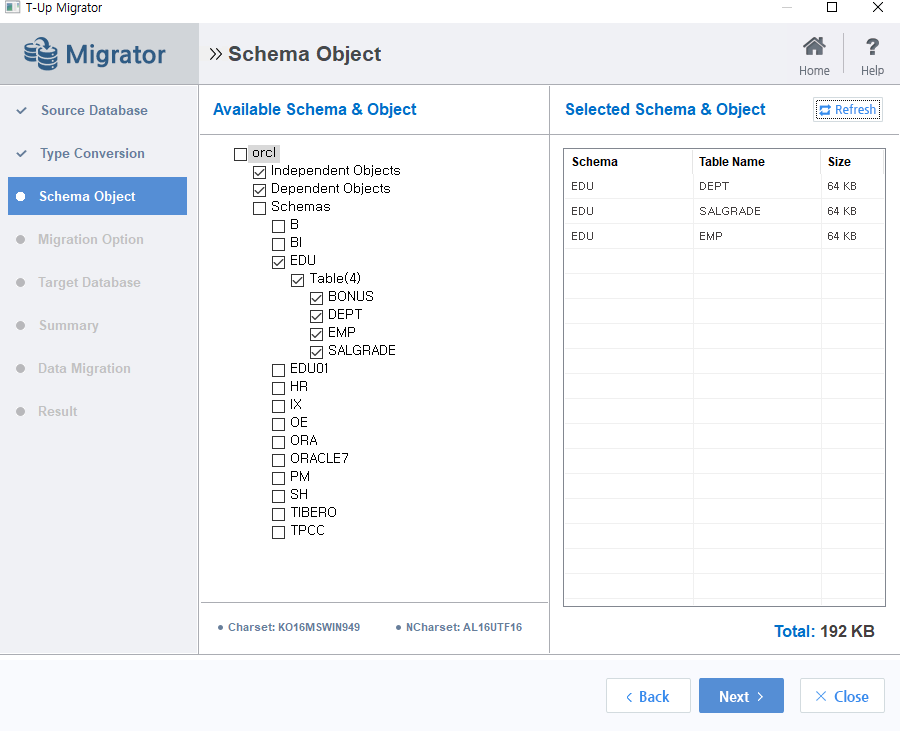
- 마이그레이션 대상 스키마 및 오브젝트를 선택
Migration Option

- Data Transfer
- 소스DB(오라클) 에서 데이터를 추출해서 꺼내온다.
- DDL
- 소스DB(오라클) 에서 스키마를 추출해서 꺼내온다.
- 앞서 선택한 소스 DB에 접속하고 DDL을 가져와서 티베로DB에 테이블 생성, 데이터를 소스 DB에서 가져와서 티베로 DB에 이관
Target Database
- 로컬DB(티베로) 접속 정보
Summary
- 앞 단계에서 선택된 정보를 보여준다.
Data Migration
- 실제 마이그레이션 진행
Result
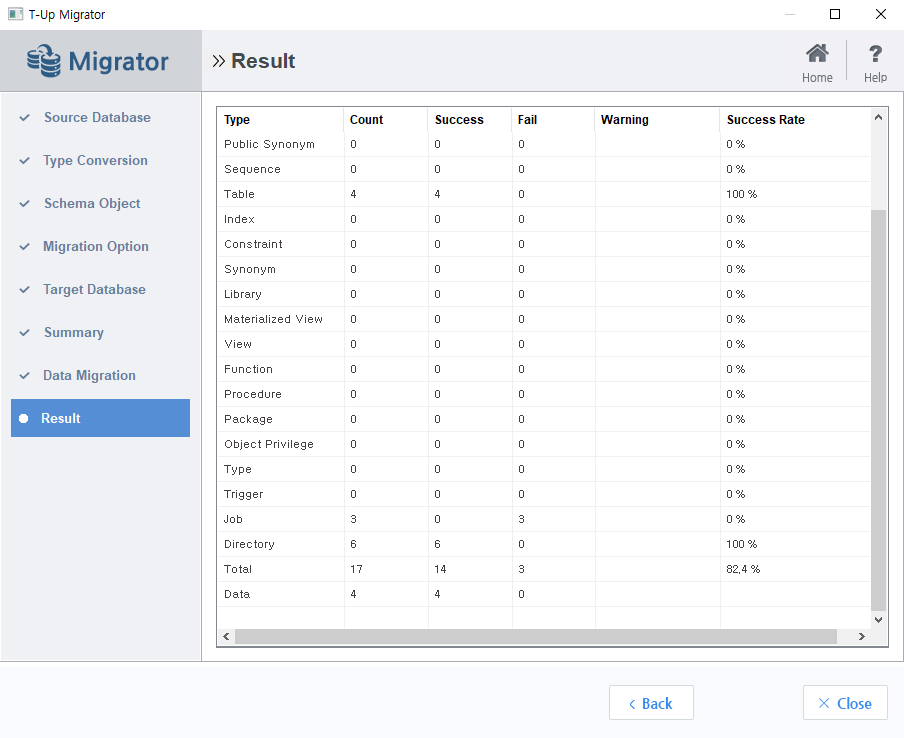
숙제
- tbsql 셀프 스터디
TIP
이미지 자료 출처
- 충남대학교 티베로 DB 엔지니어링 교육 강사 자료
- 티베로 공식문서
