3장
이 장에서는 컴퓨터가 실질적으로 다루는 기계어 코드와 어셈블리 코드에 대해 탐구한다.
C와 같은 고급 언어들은 다른 컴퓨터에서도 높은 호환성을 지니며 컴파일과 실행이 가능하다.
하지만 어셈블리 코드는 컴퓨터 기계에 매우 의존적이다.
이러한 기계어들은 인텔 주도하에 발전해 왔으며, AMD와 같은 경쟁사도 이러한 성장에 중요한 기여를 해왔다.
이러한 역사적 흐름에 따라 기계어는 역사적 문맥을 함께 보아야 이해할 수 있는 다소 기형적인 설계가 포함되기도 한다.
3.1 칩과 기계어의 발전 역사
인텔에 의해 발전되어온 현대 컴퓨터 역사는 x86이라 불리는 프로세서 제품군 발전과 함께 이루어져 왔다. 이러한 chip들은 무어의 법칙이라 불리는 엄청난 성장 속도와 함께 기하급수적으로 성장했으며, 이에 따라 칩별로 사용하는 트랜지스터의 양도 함께 늘어났다.
칩셋의 발전과 함께 다양한 종류의 인스트럭션과 정의 들도 함께 늘어나거나 수정되었다.
ex. 부동소수점 인스트럭션, 32-64비트 확장, SSE 인스트럭션 클래스 추가 등
3.2 프로그램의 인코딩
컴파일 옵션 -Og, -O1, -O2 에 따라 기계어 코드를 생성하는 최적화 수준의 조정이 가능하다.
최적화 수준을 올리면 프로그램 구동은 빨리 동작하지만, 컴파일 시간이 증가하고, 디버깅 도구 실행이 어려워진다.
-
기계 수준 코드
기계 수준 프로그래밍에서 중요한 2가지
1- 인스트럭션 집합구조(ISA)가 기계수준 프로그램의 형식과 동작을 정의한다.
2- ISA는 가상주소를 사용한다. -
코드 예제
어셈블리 코드, 목적 파일의 바이너리 형식 등 확인
역어셈블러: 기계어 코드로부터 어셈블러 코드와 유사한 형태를 생성. gcc가 생성한 어셈블러 코드와는 약간 다름. -
형식에 대한 설명
어셈블리어 코드 오른편에 주석을 달아 소통할 것.
3.3 데이터 형식
인텔 프로세서들은 근본적으로 16비트 구조를 사용했기에 1워드는 일반적으로 16비트를 ㅌ오칭.
32비트는 더블워드, 64비트는 쿼드 워드라 부른다
int(32bit), 포인터(char)(64bit), long(64bit), long double(80bit)(호환성 안좋아 사용 비추) 등
3.4 정보 접근하기
x86-64 cpu는 64bit 저장공간을 지닌 16개의 범용 레지스터 지님.
정수 데이터와 포인터 저장.
bit 수의 확장으로 레지스터 내부의 구조 및 명명법도 바뀌어 왔다.
1byte - 2byte - 4byte - 8byte 크기의 공간으로 구분될 수 있으며, 더 작은 공간들의 bit들은 보다 덜 중요한 byte에 접근하여 연산한다.
-
오퍼랜드 식별자 (operand specifier)
인스트럭션은 하나 이상의 오퍼랜드를 가진다.
오퍼랜드: 연산 수행할 소스 값, 결과 저장한 목적지 위치 명시
소스 값: 상수로 주어지거나 레지스터, 메모리로부터 읽을 수 있음.
결과 값: 레지스터나 메모리에 저장됨.
오퍼랜드는 3가지로 구분됨.
1- immedeate: 상수 값
2- register: 레지스터 내용, 8,4,2,1 바이트 중 하나의 레지스터를 가리킴.
3-오퍼랜드: 메모리 참조. 유효주소(계산된 주소)를 통해 메모리 위치에 접근
*메모리 참조를 위한 다양한 주소지정방식이 존재한다. -
데이터 이동 인스트럭션
가장 많이 사용되는 인스트럭션은 데이터를 복사하는 명령이다.
본래대로라면 많은 컴퓨터에서 여러 개의 인스트럭션이 필요했을 데이터 이동이, 오퍼랜드 표시법의 일반성으로 인해 간단해졌다.
-MOV 클래스: 데이터 이동 인스트럭션의 가장 간단한 형태
이 클래스는 4개의 인스트럭션으로 구성되며, 각각은 모두 유사한 기능을 한다.(계산하는 데이터 크기가 다름) ex. movb, mobw, movl, movq // 1,2,4,8 byte
소스 오퍼랜드: 상수, 레지스터 저장 값, 메모리 저장 값 표시
목적 오퍼랜드: 레지스터 or 메모리 주소의 위치 지정
메모리1 to 메모리2 복사 위해선, 2개의 인스트럭션 필요
1- 소스 값 레지스터에 적재하는 인스트럭션
2- 레지스터 값을 목적지에 write 하는 인스트럭션
*본 장에선 오퍼랜드와 value 등을 읽고서 해석할 수 있도록 안내한다.
$ : immediate // % : register // () : memory -
데이터 이동 예제
c코드 - 어셈블러 코드로의 변환과, 각 인스트럭션의 작동을 단계별로 파악해본다.
변수 선언, 포인터 사용에 따른 컴퓨터 내부의 흐름을 확인 가능.
*이 어셈블러 코드에서의 2가지 주요 특징
-c언어에서의 포인터는 어셈블리어에선 단순히 주소이다.
-x와 같은 지역변수들은 종종 레지스터에 저장된다. -
스택 데이터의 저장과 추출, push pop
후입선출인 스택의 특성.
스택은 배열로 구현. 배열의 한쪽 끝에서만 추가, 제거(top), 그림에선 top을 아래로 향하게 그림.
따라서 아래가 top, 위가 bottom으로 그려지고, 해당 그림에서 아래에서 위로 갈수록 adress 값은 커짐.
popq, pushq는 각각 데이터 추출, 추가 기능을 제공. 각 인스트럭션은 한 개의 오퍼랜드를 사용(추가할 소스 데이터, 추출을 위한 데이터 목적지)
pushq, popq 인스트럭션의 작동 내용 및 코드
3.5 산술연산과 논리연산
x86-64 어셈블리 언어는 다양한 산술 및 논리 연산을 지원하며, 이 섹션에서는 이러한 연산에 대해 다룹니다.
3.5.1 유효 주소 로드 (Load Effective Address)
leaq 명령어: 메모리에서 값을 읽는 대신 주소 계산을 수행하여 결과를 레지스터에 저장합니다.
형식: leaq 소스, 대상
용도:
포인터 산술을 수행하여 메모리 주소를 계산합니다.
간단한 산술 연산을 수행하기 위해 사용되며, 실제로는 메모리에 접근하지 않습니다.
예시: leaq 7(%rdx,%rdx,4), %rax는 %rax에 5x + 7을 저장합니다 (%rdx가 x를 저장하고 있을 때).
leaq 7(%rdx, %rdx, 4), %rax의 해석
주소 계산식 7(%rdx, %rdx, 4)은 다음과 같이 구성됩니다:
디스플레이스먼트(Displacement): 7
베이스 레지스터(Base Register): %rdx
인덱스 레지스터(Index Register): %rdx
스케일(Scale): 4
유효 주소 = 디스플레이스먼트 + 베이스 레지스터 + (인덱스 레지스터 × 스케일)
3.5.2 단항 및 이항 연산
단항 연산
형식: 연산자 대상
특징: 대상은 소스이자 목적지입니다.
명령어 목록:
inc D: D = D + 1 (증가)
dec D: D = D - 1 (감소)
neg D: D = -D (부호 반전)
not D: D = ~D (비트 보수)
이항 연산
형식: 연산자 소스, 대상
특징: 소스는 읽기 전용이며, 대상은 읽기 및 쓰기 모두 가능합니다.
주의사항: ATT 문법에서는 소스가 먼저, 대상이 나중에 옵니다.
명령어 목록:
add S, D: D = D + S (덧셈)
sub S, D: D = D - S (뺄셈)
imul S, D: D = D * S (곱셈)
xor S, D: D = D ^ S (비트 XOR)
or S, D: D = D | S (비트 OR)
and S, D: D = D & S (비트 AND)
예시:
subq %rax, %rdx: %rdx = %rdx - %rax를 수행합니다.
3.5.3 시프트 연산
형식: 연산자 시프트량, 대상
시프트 종류:
왼쪽 시프트:
sal 또는 shl: 동일한 기능으로, 왼쪽으로 비트를 이동하고 오른쪽에 0을 채웁니다.
오른쪽 시프트:
sar: 산술 시프트로, 부호 비트를 유지하며 오른쪽으로 비트를 이동합니다.
shr: 논리 시프트로, 오른쪽으로 비트를 이동하고 왼쪽에 0을 채웁니다.
시프트량 지정:
즉시 값(immediate value) 또는 %cl 레지스터를 사용합니다.
%cl은 1바이트 레지스터로, 시프트량을 동적으로 지정할 때 사용됩니다.
예시:
salq $4, %rax: %rax를 왼쪽으로 4비트 시프트합니다.
sarq %cl, %rax: %cl에 지정된 만큼 %rax를 오른쪽으로 산술 시프트합니다.
3.5.4 논의
부호와 무관한 연산: 대부분의 산술 및 논리 연산은 부호 있는 수와 부호 없는 수에 대해 동일하게 작동합니다.
오른쪽 시프트의 차이:
부호 있는 수의 경우 산술 시프트(sar)를 사용하여 부호 비트를 유지합니다.
부호 없는 수의 경우 논리 시프트(shr)를 사용하여 왼쪽에 0을 채웁니다.
2의 보수 표현의 장점: 이러한 연산의 일관성 때문에, 2의 보수 표현이 부호 있는 정수 연산에 선호됩니다.
3.5.5 특별 산술 연산
확장된 곱셈 및 나눗셈
64비트 곱셈의 결과: 두 개의 64비트 정수를 곱하면 최대 128비트의 결과가 생성될 수 있습니다.
곱셈 명령어:
mulq S: %rax와 S를 곱하여 부호 없는 128비트 결과를 %rdx:%rax에 저장합니다.
imulq S: %rax와 S를 곱하여 부호 있는 128비트 결과를 %rdx:%rax에 저장합니다.
나눗셈 명령어:
divq S: %rdx:%rax를 S로 나누어 부호 없는 몫을 %rax에, 나머지를 %rdx에 저장합니다.
idivq S: %rdx:%rax를 S로 나누어 부호 있는 몫을 %rax에, 나머지를 %rdx에 저장합니다.
특별한 명령어:
cqto: %rax의 부호 비트를 확장하여 %rdx에 저장합니다. 이는 부호 있는 나눗셈 전에 사용됩니다.
사용 예시:
곱셈:
assembly
코드 복사
movq %rsi, %rax ; 피연산자 x를 %rax에 복사
mulq %rdx ; x * y를 계산하여 결과를 %rdx:%rax에 저장
나눗셈:assembly
코드 복사
movq %rdi, %rax ; 피제수 x를 %rax에 복사
cqto ; %rdx를 x의 부호로 확장
idivq %rsi ; x / y를 계산하여 몫을 %rax에, 나머지를 %rdx에 저장3.6 제어문
3.6장에서는 C 언어의 조건문, 루프, 스위치 등 제어 구조를 어셈블리 언어로 구현하는 방법을 다룹니다. 어셈블리 언어에서는 데이터 값을 테스트하고 그 결과에 따라 제어 흐름이나 데이터 흐름을 변경하는 방식으로 조건부 실행을 구현합니다.
3.6.1 조건 코드 (Condition Codes)
조건 코드 레지스터: CPU는 최근 산술 또는 논리 연산의 결과를 나타내는 단일 비트 조건 코드를 유지합니다.
CF (Carry Flag): 가장 높은 비트에서 캐리가 발생했을 때 설정됩니다. 부호 없는 연산의 오버플로를 감지하는 데 사용됩니다.
ZF (Zero Flag): 연산 결과가 0일 때 설정됩니다.
SF (Sign Flag): 연산 결과가 음수일 때 설정됩니다.
OF (Overflow Flag): 2의 보수 오버플로가 발생했을 때 설정됩니다.
조건 코드 설정 방법:
산술 및 논리 연산은 조건 코드를 설정합니다.
leaq 명령어는 조건 코드를 변경하지 않습니다.
cmp 명령어: 두 피연산자의 차이에 따라 조건 코드를 설정합니다. 실제 값은 변경하지 않고 조건 코드만 설정합니다.
test 명령어: 두 피연산자의 비트 AND 결과에 따라 조건 코드를 설정합니다.
3.6.2 조건 코드 액세스
조건 코드 사용 방법:
단일 바이트를 0 또는 1로 설정: set 명령어를 사용하여 조건 코드에 따라 바이트 값을 설정합니다.
예: sete (같을 때 설정), setne (같지 않을 때 설정), setl (작을 때 설정) 등.
목적지는 1바이트 레지스터나 메모리 위치여야 합니다.
조건부 점프: 조건에 따라 프로그램의 다른 부분으로 이동합니다.
예: je (ZF가 설정되었을 때 점프), jne (ZF가 설정되지 않았을 때 점프), jl (SF ≠ OF일 때 점프) 등.
조건부 데이터 전송: 조건에 따라 데이터 이동을 수행합니다.
예: cmov 명령어를 사용하여 조건이 참일 때만 데이터를 이동합니다.
set 명령어:
조건 코드에 따라 지정된 바이트를 0 또는 1로 설정합니다.
예: setl %al은 조건이 참이면 %al을 1로, 거짓이면 0으로 설정합니다.
3.6.3 점프 명령어
무조건 점프 (jmp):
프로그램 실행 흐름을 지정된 위치로 이동시킵니다.
직접 점프: 점프 대상이 명령어에 인코딩됩니다 (예: jmp .L1).
간접 점프: 레지스터나 메모리 위치에 저장된 주소로 점프합니다 (예: jmp *%rax).
조건부 점프:
조건 코드에 따라 점프 여부를 결정합니다.
예시:
je 또는 jz: ZF가 설정되었을 때 점프 (두 값이 같을 때).
jne 또는 jnz: ZF가 설정되지 않았을 때 점프 (두 값이 다를 때).
jg: SF ≠ OF이고 ZF = 0일 때 점프 (부호 있는 값이 클 때).
jl: SF ≠ OF일 때 점프 (부호 있는 값이 작을 때).
3.6.4 점프 명령어 인코딩
프로그램 카운터 상대 (PC-relative) 주소 지정:
점프 대상은 점프 명령어 다음 명령어의 주소를 기준으로 오프셋으로 지정됩니다.
오프셋은 1, 2, 또는 4바이트로 인코딩될 수 있습니다.
이는 점프 대상이 코드 내에서 이동하더라도 상대적인 오프셋을 사용하므로 코드 재배치에 유용합니다.
디스어셈블된 코드 분석:
점프 명령어의 바이트 인코딩을 통해 실제 점프 위치를 계산할 수 있습니다.
점프 오프셋은 명령어 주소와 다음 명령어 주소의 차이로 표현됩니다.
3.6.5 조건부 제어를 통한 조건 분기 구현
if-else 문 구현:
조건을 평가하고, 조건에 따라 다른 코드 블록을 실행합니다.
일반적인 구조:
c
코드 복사
if (test-expr)
then-statement
else
else-statement
어셈블리 구현 방법:
조건을 평가하는 명령어 (cmp, test 등)를 사용하여 조건 코드를 설정합니다.
조건부 점프 명령어 (je, jne 등)를 사용하여 해당하는 코드 블록으로 분기합니다.
각 코드 블록은 레이블로 구분되어 있습니다.
예시:
absdiff_se 함수는 두 수의 차이의 절대값을 계산하며, 어셈블리 코드에서는 조건부 점프를 사용하여 if-else 구조를 구현합니다.
3.6.6 조건부 이동을 통한 조건 분기 구현
조건부 이동 명령어 (cmov):
조건 코드에 따라 데이터 이동을 수행합니다.
조건이 참일 때만 소스에서 목적지로 데이터를 이동합니다.
명령어 예시:
cmovge: 조건이 "크거나 같음"일 때 데이터 이동.
cmovl: 조건이 "작음"일 때 데이터 이동.
장점:
조건부 이동은 분기 예측 실패로 인한 성능 저하를 방지할 수 있습니다.
파이프라인을 중단하지 않고도 조건부 연산을 수행할 수 있습니다.
제한 사항:
조건부 이동은 모든 상황에서 사용할 수 없습니다.
조건에 따라 실행되어야 할 코드 블록이 부작용이 없고, 계산 비용이 적을 때 적합합니다.
부작용이 있는 코드나 계산 비용이 큰 경우에는 적합하지 않습니다.
3.6.7 루프
루프 구조의 어셈블리 구현:
루프는 조건부 점프 명령어를 사용하여 구현됩니다.
do-while 루프:
루프 본문을 먼저 실행하고, 조건을 검사하여 반복 여부를 결정합니다.
어셈블리에서는 루프 끝에 조건부 점프를 배치하여 구현합니다.
while 루프:
조건을 먼저 검사하고, 조건이 참이면 루프 본문을 실행합니다.
두 가지 번역 방법이 있습니다:
Jump to Middle: 루프 시작 시 테스트를 수행하기 위해 중간으로 점프합니다.
Guarded Do: 초기 테스트를 수행하고, 조건이 참일 때만 루프를 실행합니다.
for 루프:
for 루프는 while 루프로 변환하여 처리합니다.
초기화, 조건 검사, 업데이트 표현식을 적절히 배치하여 루프를 구성합니다.
루프의 제어 흐름은 조건부 점프 명령어로 관리됩니다.
3.6.8 스위치 문
스위치 문의 구현:
점프 테이블을 사용하여 여러 경우에 대해 효율적인 분기를 수행합니다.
점프 테이블은 각 케이스 레이블에 해당하는 코드 주소를 배열로 저장합니다.
스위치 변수의 값에 따라 점프 테이블에서 해당하는 코드 주소를 찾아 간접 점프를 수행합니다.
점프 테이블의 장점:
많은 수의 케이스를 일정한 시간에 처리할 수 있습니다.
코드의 가독성과 유지보수성을 높입니다.
어셈블리에서의 구현:
점프 테이블은 읽기 전용 데이터 섹션 (.rodata)에 저장됩니다.
간접 점프 명령어 (jmp *)를 사용하여 점프 테이블의 값을 참조합니다.
각 케이스에 해당하는 코드 블록은 레이블로 구분됩니다.
예시:
switch_eg 함수는 여러 케이스를 가지는 스위치 문을 구현하며, 어셈블리 코드에서 점프 테이블을 사용하여 효율적으로 분기합니다.
중복된 케이스나 연속적이지 않은 케이스도 점프 테이블로 처리할 수 있습니다.
3.7 프로시저
일종의 함수, 메소드, 서브루틴, 핸들러 등의 추상화 개념.
지정된 인자들과 리턴 값으로 특정 기능을 구현하는 코드의 추상화.
여러 프로그래밍 언어에서 다양한 이름(함수, 메소드, 서브루틴, 핸들러 등)으로 사용되지만 이 모두는 일반적 특징을 공유함.
프로시저 과정 중 기계어 수준의 처리를 할 땐 크게 3가지 메커니즘 중 하나 이상이 진행된다.
- 제어권 전달 : 프로시저 간 호출과 리턴이 일어날 때, 프로그램 카운터(PC)는 호출과 리턴시 작동되어야 할 코드의 시작주소로 설정된다.
- 데이터 전달 : 호출시 기존 프로시저는 호출 프로시저로 하나 이상의 매개변수를 제공. 반대의 경우 하나의 리턴 값 반환.
- 메모리 할당과 반납 : 호출되는 프로시저는 지역변수를 위한 공간을 할당할 수도 있고, 리턴 시 저장소를 반납할수도 있음.
x86-64 환경에서 프로시저는 레지스터, 메모리 등의 머신 자원을 사용하는 방법에 관한 인스트럭션 및 약속으로 구현된다.
3.7.1 런타임 스택
C언어 및 대부분의 언어에서, 프로시저 호출의 주요 특징은 후입선출 방식의 스택 자료구조를 사용할 수 있다는 것이다.
- 프로그램은 프로시저가 요구하는 저장 장소를 스택을 활용해 관리할 수 있으며,
- 스택과 레지스터는 제어, 데이터, 메모리 할당을 위해 필요한 정보를 저장한다.
- x86-64에서 스택은 작은 주소 방향으로 확장한다. (3.4.4. 참조)
- 스택 포인터: %rsp -> 스택 최상위 원소를 가리킨다.
- pushq, popq 인스트럭션을 이용해 스택 상 저장, 읽기가 이뤄진다.
- 초기화 되지 않은 데이터는 적당량의 스택 포인터를 감소시켜 적당한 공간을 할당한다.
- 스택 포인터를 증가시켜 공간 반납을 할 수 있다.
- 레지스터에 저장할 수 있는 개수 이상의 저장공간이 필요한 경우 스택에 공간이 할당된다. (스택 프레임)
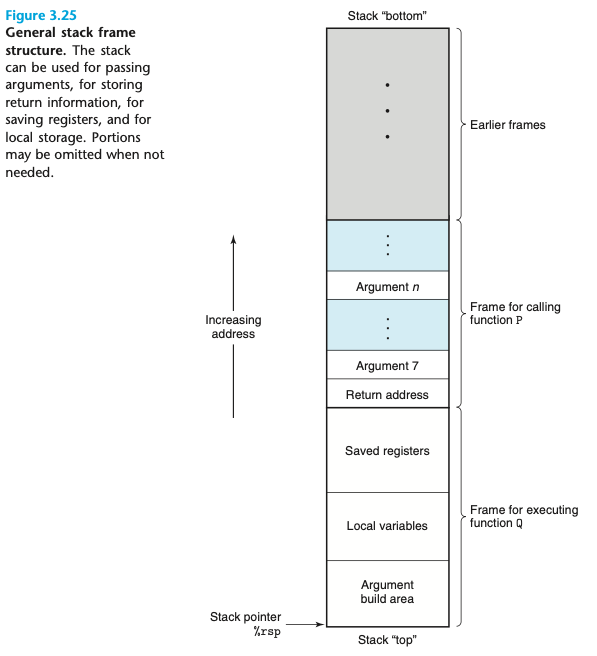
<런타임의 스택의 전체적 구조>
- 현재 실행 중인 프로시저에 대한 프레임은 항상 스택의 맨 위.
- 새로운 프로시저 호출 시, return adress 스택에 push하여 호출된 프로시저가 리턴할 때 재시작 위치 알려줌.
- 이때, return adress 는 기존 프로시저의 스택 프레임에 속하는 것으로 간주.
- 호출된 프로시저는 기존 스택을 확장해 공간을 할당.
- 해당 공간에서 레지스터 값 저장. 지역변수 공간 할당. 자신이 호출하는 프로시저들을 위한 인자 설정.
- 대부분의 프로시저는 시작될 때 고정 크기의 스택 프레임을 할당받음.
- 그러나, 일부는 가변 크기 프레임을 필요로 함. (3.10.5에서 논의)
- 본 예제에서 프로시저 P는 6개의 정수 값(포인터, 정수)를 레지스터로 전송할 수 있지만, 호출할 프로시저가 더 많은 인자 요구한다면 호출 전에 자신의 스택 프레임 내에 인자 몇을 저장한다.
- 실제 x86-64 프로시저는 요청받은 스택 프레임 중 부분만을 할당.
- 많은 프로시저들은 6개 이하의 인자를 가짐.
- 몇몇은 스택 프레임을 요청하지도 않음. (모든 지역변수를 레지스터에 보관할 수 있고, 이 함수가 다른 함수를 호출하지도 않을 때) - '나뭇잎 프로시저'로 불림
3.7.2 제어의 이동
제어를 이동한다는 것은, 단순히 말하면,
프로그램 카운터(PC)를 새로 호출할 프로시저 코드의 시작 주소로 설정하는 것.
- 리턴 시 기존 프로시저에서 시작점을 알기 위해 코드 위치에 대한 기록 필요. (call Q로 기록)
제어권 전달 시
call Q : 주소 A(리턴 주소, call 인스트럭션 바로 다음 인스트럭션의 주소)를 스택에 push -> PC를 Q의 시작으로 설정.
리턴 시
ret : 주소 A를 스택에서 pop, PC를 A로 세팅.
call 인스트럭션 : 호출된 프로시저가 시작하는 인스트럭션의 주소를 목적지로 가짐. 명령은 직접 or 간접.
직접 호출(레이블), 간접 호출('* 식별자' 형식)

위 코드에서, main의 주소 0x400563을 인자로 갖는 call 인스트럭션은 함수 multst-ore 호출. (3.26 a)
스택 포인터 %rsp, 프로그램 카운터 %rip로 표시.
call은 :
리턴 주소(400568)을 스택에 저장하고 400540(multstore 첫번째 인스트럭션)으로 점프.
multstore는 주소 40054d의 ret 인스트럭션ㅇㄹ 만날 때까지 실행됨.
ret은 :
스택에서 400568을 pop해서 이 주소로 점프한 후, call 인스트럭션 바로 다음의 main 실행 재개.
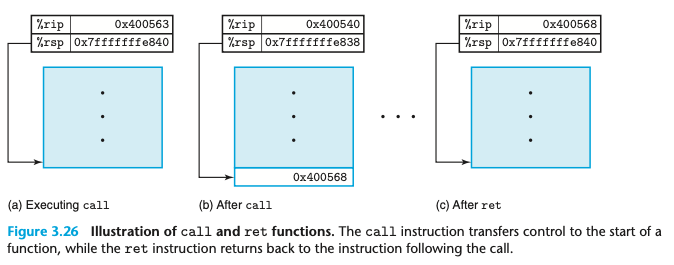
제어를 프로시저로 전달하고 전달받는 상세한 예제. (그림 3.27 a)
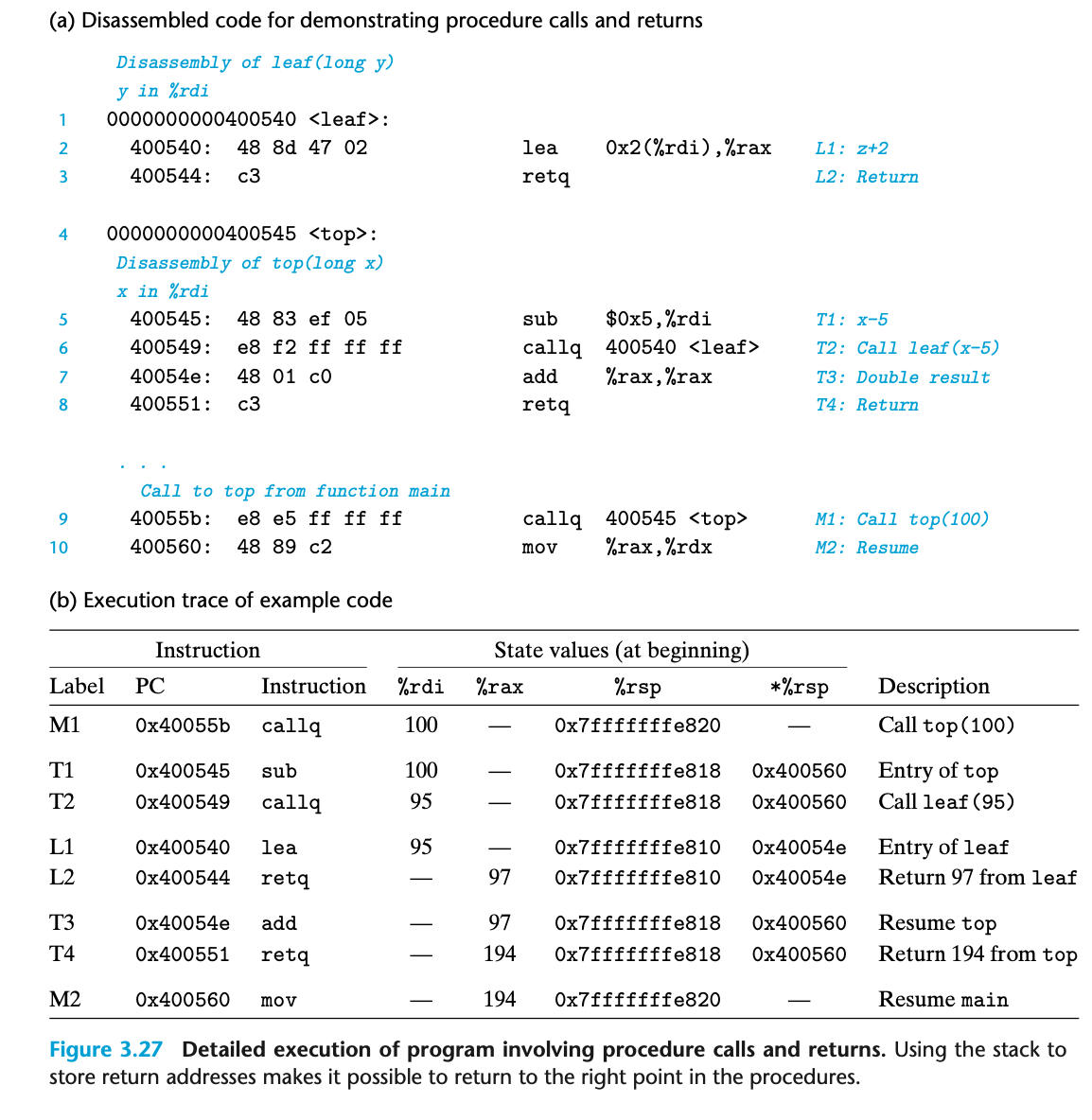
3.7.3 데이터 전송
x86-64에서 대부분의 프로시저간 데이터 전달은 레지스터를 통해 발생.
x86-64에선, 최대 6개의 정수형 인자(정수, 포인터)가 레지스터로 전달될 수 있다.
레지스터들은 전달되는 데이터 형의 길이 따라 레지스터 이름에 따라 정해진 순서로 이용됨.
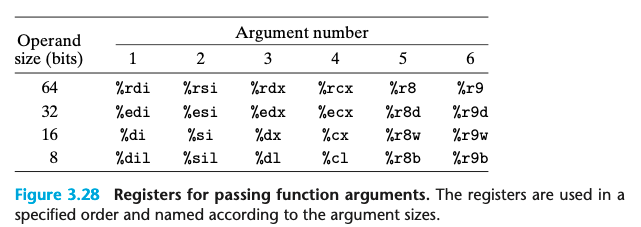
인자 전달 방식: x86-64에서는 최대 6개의 정수형(정수 및 포인터) 인자를 레지스터를 통해 전달하며, 그 순서는 %rdi, %rsi, %rdx, %rcx, %r8, %r9이다. 추가적인 인자는 스택을 통해 전달된다.
레지스터 사용: 인자의 크기에 따라 레지스터의 하위 부분을 사용한다. 예를 들어, 32비트 인자는 %edi, 16비트 인자는 %di를 사용한다.
예제 함수 proc: 다양한 크기의 인자를 가지는 함수로, 앞의 6개 인자는 레지스터로, 나머지 2개 인자는 스택을 통해 전달된다.
3.7.4 스택에 저장되는 지역 변수
스택 프레임 사용 이유:
레지스터에 모든 지역 변수를 저장할 수 없는 경우
주소 연산자 &를 통해 지역 변수의 주소가 필요한 경우
배열이나 구조체와 같은 복잡한 데이터 구조를 사용하는 경우
스택 프레임 구조: 함수는 스택 포인터를 감소시켜 필요한 공간을 확보하고, 함수 종료 시에 이를 복원한다.
예제 함수 caller: 지역 변수 arg1과 arg2를 스택에 저장하고, 이들의 주소를 swap_add 함수에 인자로 전달한다.
3.7.5 레지스터에 저장되는 지역 변수
레지스터 분류:
callee-saved 레지스터: %rbx, %rbp, %r12–%r15는 피호출 함수가 값을 보존해야 한다.
caller-saved 레지스터: 나머지 레지스터는 호출 함수가 필요에 따라 값을 저장해야 한다.
예제 함수 P: 함수 Q를 호출하면서 레지스터 %rbp와 %rbx를 사용하여 값을 저장하고, 호출 전후로 이들을 스택에 저장하고 복원한다.
3.7.6 재귀 프로시저
재귀 호출 처리: 각 함수 호출마다 독립적인 스택 프레임이 생성되며, 레지스터 사용 규칙을 준수하여 재귀 호출을 안전하게 처리한다.
예제 함수 rfact: 재귀적으로 팩토리얼을 계산하며, 레지스터와 스택을 사용하여 재귀 호출의 상태를 관리한다.
3.8 배열의 할당과 접근
C 언어의 배열: 스칼라 데이터를 더 큰 데이터 타입으로 집합화하기 위한 수단으로 사용되며, 간단한 구현으로 인해 기계 코드로의 변환이 비교적 straightforward하다.
포인터와 배열 연산: C 언어는 배열 내 요소의 포인터를 생성하고 이 포인터로 산술 연산을 수행할 수 있는 독특한 기능을 제공한다.
컴파일러 최적화: 최적화된 컴파일러는 배열 인덱싱에 사용되는 주소 계산을 단순화하여, C 코드와 기계 코드 간의 대응을 파악하기 어렵게 만들 수 있다.
3.8.1 기본 원칙
배열 선언: T A[N];와 같이 데이터 타입 T와 정수 N으로 배열을 선언하면, 다음과 같은 효과가 있다:
크기가 L(데이터 타입 T의 바이트 크기) x N인 연속적인 메모리 공간을 할당한다.
배열의 시작 주소를 가리키는 식별자 A를 도입한다.
배열 요소 접근: 인덱스 i(0 ≤ i < N)에 대해, 배열 요소 A[i]는 주소 xA + L × i에 저장된다.
예제:
char A[12]; ⇒ 요소 크기 1바이트, 총 크기 12바이트
int C[6]; ⇒ 요소 크기 4바이트, 총 크기 24바이트
double *D[5]; ⇒ 요소 크기 8바이트(포인터), 총 크기 40바이트
x86-64 메모리 참조 명령어: 배열 접근을 단순화하기 위해 설계되었다. 예를 들어, movl (%rdx,%rcx,4),%eax는 E[i]를 읽기 위해 주소 계산 xE + 4i를 수행한다.
3.8.2 포인터 산술 연산
포인터 연산: C 언어에서는 포인터에 대한 산술 연산이 가능하며, 데이터 타입의 크기에 따라 스케일링된다. 즉, 포인터 p에 정수 i를 더하면 p + i는 xp + L × i가 된다.
연산자 '&'와 '': 주소 생성과 역참조에 사용된다. 배열 인덱싱은 배열과 포인터 모두에 적용되며, A[i]는 (A + i)와 동일하다.
3.8.3 중첩 배열
배열의 배열: 다차원 배열도 기본 배열 할당 및 참조 원칙을 따른다. 예를 들어, int A[5][3];은 5개의 행과 3개의 열을 가진 2차원 배열이며, 행 우선(row-major) 순서로 메모리에 저장된다.
요소 주소 계산: 다차원 배열에서 요소 D[i][j]의 주소는 xD + L × (C × i + j)로 계산된다.
3.8.4 고정 크기 배열
컴파일러 최적화: 고정 크기 다차원 배열에서, 컴파일러는 인덱스 계산을 최적화하여 성능을 향상시킬 수 있다. 예를 들어, 루프 내에서 인덱스 변수를 제거하고 포인터를 사용하여 배열 요소를 순회한다.
예제: fix_matrix 타입의 16×16 배열에서 특정 요소의 계산을 최적화된 코드로 변환하여 성능을 개선한다.
3.8.5 가변 크기 배열
C99 표준의 도입: 가변 크기 배열을 지원하여 런타임 시에 배열의 크기를 결정할 수 있다.
주소 계산: 가변 크기 배열에서도 주소 계산은 고정 크기 배열과 유사하지만, 인덱스 스케일링을 위해 곱셈 연산이 필요하다.
컴파일러 최적화: 루프 내에서 가변 크기 배열을 참조할 때, 컴파일러는 접근 패턴의 규칙성을 활용하여 인덱스 계산을 최적화할 수 있다.
3.9 이기종 자료구조
C 언어는 서로 다른 유형의 객체를 결합하여 하나의 단위를 만드는 두 가지 메커니즘을 제공합니다: struct를 사용한 구조체와 union을 사용한 공용체입니다.
3.9.1 구조체 (Structures)
구조체 선언: struct 키워드를 사용하여 서로 다른 데이터 타입의 멤버를 하나의 단위로 그룹화합니다.
c
코드 복사
struct rec {
int i;
int j;
int a[2];
int *p;
};메모리 배치: 구조체의 모든 멤버는 연속적인 메모리 영역에 저장되며, 구조체의 포인터는 첫 번째 바이트의 주소를 가집니다.
필드 접근: 컴파일러는 구조체의 각 필드에 대한 바이트 오프셋 정보를 유지하고, 이 오프셋을 사용하여 메모리 참조 명령어에서 적절한 변위를 추가합니다.
예를 들어, r->i를 접근하기 위해 구조체 포인터 r에 오프셋 0을 추가합니다.
포인터 생성: 구조체 내 객체에 대한 포인터를 생성할 때, 필드의 오프셋을 구조체의 주소에 추가합니다.
예: &(r->a[i])는 leaq 8(%rdi,%rsi,4), %rax와 같이 계산됩니다.
중첩 구조체: 구조체는 다른 구조체를 포함할 수 있으며, 배열과 구조체도 중첩될 수 있습니다.
3.9.2 공용체 (Unions)
공용체 선언: union 키워드를 사용하여 동일한 메모리 공간을 여러 다른 타입으로 접근할 수 있게 합니다.
c
코드 복사
union U3 {
char c;
int i[2];
double v;
};메모리 배치: 공용체의 모든 필드는 동일한 메모리 위치를 참조하며, 공용체의 전체 크기는 가장 큰 필드의 크기와 같습니다.
사용 예시:
공간 절약: 서로 배타적으로 사용되는 데이터 필드를 공용체로 선언하여 메모리 사용을 최적화할 수 있습니다.
비트 패턴 접근: 다른 데이터 타입의 비트 패턴을 접근하기 위해 사용됩니다.
예: double의 비트 패턴을 unsigned long으로 읽기 위해 공용체를 사용합니다.
주의 사항: 공용체는 C의 타입 시스템을 우회하므로, 잘못 사용하면 버그의 원인이 될 수 있습니다.
3.9.3 데이터 정렬 (Data Alignment)
정렬 제약 조건: 대부분의 시스템에서 특정 데이터 타입은 특정 배수의 주소에 위치해야 합니다. 이는 하드웨어와 메모리 시스템 간의 인터페이스 설계를 단순화합니다.
예: 4바이트 int는 주소가 4의 배수여야 합니다.
정렬 규칙:
1바이트 정렬: char
2바이트 정렬: short
4바이트 정렬: int, float
8바이트 정렬: long, double, 포인터 타입
구조체 내 패딩: 구조체의 각 필드가 정렬 요구 사항을 만족하도록 컴파일러는 필드 사이에 패딩(채움)을 추가할 수 있습니다.
예: 구조체 내에서 char 뒤에 int가 올 경우, int의 정렬을 위해 패딩을 추가합니다.
구조체의 전체 크기: 구조체의 총 크기는 가장 엄격한 정렬 요구 사항의 배수가 되도록 패딩이 추가될 수 있습니다. 이는 구조체의 배열에서 각 요소가 올바르게 정렬되도록 보장합니다.
요약
구조체(struct)와 공용체(union)는 서로 다른 데이터 타입을 하나의 단위로 결합하는 C 언어의 기능입니다.
구조체는 각 필드가 고유한 메모리 공간을 가지며, 필드 접근은 필드의 오프셋을 사용하여 이루어집니다.
공용체는 모든 필드가 동일한 메모리 공간을 공유하여, 한 번에 하나의 필드만 유효한 값을 가집니다.
데이터 정렬은 메모리 접근 효율성과 하드웨어 제약으로 인해 중요하며, 컴파일러는 이를 만족시키기 위해 패딩을 추가할 수 있습니다.
이러한 개념들은 메모리 효율성과 프로그램의 안정성을 높이는 데 중요하며, 시스템 프로그래밍에서 특히 중요합니다.
3.10 기계수준 프로그램에서 제어와 데이터의 결합
도입: 지금까지 프로그램의 제어 흐름과 데이터 구조를 개별적으로 살펴보았습니다. 이 장에서는 기계 수준 프로그램에서 제어와 데이터가 어떻게 상호 작용하는지 탐구합니다.
3.10.1 포인터 이해하기
포인터의 중요성: 포인터는 C 언어의 핵심 요소로, 다양한 데이터 구조 내의 요소에 대한 참조를 생성하는 데 사용됩니다. 하지만 초보 프로그래머에게는 혼란스러울 수 있습니다.
핵심 원칙:
포인터 타입: 모든 포인터는 연관된 타입을 가지며, 이는 포인터가 가리키는 객체의 타입을 나타냅니다.
예: int ip;는 int 타입의 객체를 가리키는 포인터입니다.
포인터 값: 포인터의 값은 해당 타입의 객체의 주소입니다.
포인터 생성: '&' 연산자를 사용하여 포인터를 생성합니다.
포인터 역참조: '' 연산자를 사용하여 포인터를 역참조하여 해당 주소의 값을 가져옵니다.
배열과 포인터의 관계: 배열 이름은 포인터처럼 동작하며, 배열 인덱싱과 포인터 산술은 밀접하게 관련되어 있습니다.
포인터 캐스팅: 한 포인터 타입에서 다른 포인터 타입으로 캐스팅하면 타입은 변경되지만 주소 값은 변하지 않습니다.
함수 포인터: 포인터는 함수도 가리킬 수 있으며, 이는 코드의 참조를 저장하고 전달하는 강력한 기능을 제공합니다.
예: int (fp)(int, int );는 함수를 가리키는 포인터입니다.
3.10.2 실전: gdb 디버거 사용하기
gdb 소개: GNU 디버거인 gdb는 기계 수준 프로그램의 실행을 제어하고 분석할 수 있는 강력한 도구입니다.
주요 기능:
브레이크포인트 설정: 프로그램의 특정 지점에서 실행을 멈출 수 있습니다.
단계별 실행: 프로그램을 한 단계씩 실행하여 동작을 추적할 수 있습니다.
메모리 및 레지스터 검사: 실행 중인 프로그램의 메모리와 레지스터 값을 확인할 수 있습니다.
디스어셈블리: 기계 코드를 역어셈블하여 어셈블리 코드로 확인할 수 있습니다.
3.10.3 메모리 참조 초과와 버퍼 오버플로우
배열 경계 검사 부족: C 언어는 배열에 대한 경계 검사를 수행하지 않으므로, 배열 범위를 초과하여 메모리에 접근할 수 있습니다.
버퍼 오버플로우 문제:
스택에 할당된 배열(버퍼)에서 범위를 초과하여 데이터를 쓰면 스택의 중요한 정보(예: 반환 주소)가 손상될 수 있습니다.
이는 프로그램의 비정상적인 동작이나 보안 취약점을 초래할 수 있습니다.
예시:
gets 함수는 입력 길이에 대한 제한이 없어, 작은 버퍼에 큰 입력을 받을 경우 버퍼 오버플로우가 발생합니다.
반환 주소가 덮어써지면 ret 명령어가 잘못된 주소로 이동하여 프로그램이 충돌하거나 공격자가 원하는 코드를 실행할 수 있습니다.
3.10.4 버퍼 오버플로우 공격 방어
스택 난수화(Stack Randomization):
개념: 프로그램 실행 시마다 스택의 시작 위치를 무작위로 변경하여 공격자가 정확한 스택 주소를 예측하기 어렵게 만듭니다.
ASLR: 주소 공간 배치 난수화(Address Space Layout Randomization)의 한 형태로, 전체 메모리 공간의 레이아웃을 무작위화합니다.
스택 손상 감지(Stack Corruption Detection):
스택 프로텍터:
카나리아 값 사용: 스택 프레임에 특별한 값을 저장하고 함수 종료 시 이 값이 변경되었는지 확인합니다.
동작 원리: 버퍼 오버플로우로 카나리아 값이 변경되면 프로그램이 이를 감지하고 실행을 중단합니다.
실행 가능한 메모리 영역 제한:
NX 비트 사용: 메모리 페이지를 실행 불가능하도록 표시하여 스택이나 힙에 있는 데이터를 코드로 실행하지 못하게 합니다.
효과: 공격자가 임의의 코드를 삽입하여 실행하는 것을 방지합니다.
종합적 대응: 이러한 기법들을 결합하여 버퍼 오버플로우 공격에 대한 방어력을 강화할 수 있습니다.
3.10.5 가변 크기 스택 프레임 지원
문제 상황:
가변 크기 데이터: 함수 내에서 배열의 크기가 실행 시간에 결정되거나 alloca 함수를 사용하여 동적으로 스택 메모리를 할당하는 경우.
프레임 포인터 사용:
필요성: 스택 프레임의 크기를 컴파일 타임에 알 수 없으므로, %rbp 레지스터를 프레임 포인터로 사용하여 스택 프레임을 관리합니다.
동작 방식:
%rbp에 이전 프레임 포인터를 저장하고, 새로운 스택 프레임의 시작 지점으로 설정합니다.
고정 크기의 지역 변수는 %rbp를 기준으로 오프셋을 계산하여 접근합니다.
스택 프레임의 크기를 동적으로 조정합니다.
예시 함수 vframe:
특징: 실행 시 결정되는 크기의 배열을 지역 변수로 선언하여 가변 크기 스택 프레임을 필요로 합니다.
스택 프레임 구성:
스택 프레임에 프레임 포인터, 반환 주소, 지역 변수 등이 포함됩니다.
배열의 크기에 따라 스택 포인터를 조정하여 필요한 메모리를 확보합니다.
요약: 이 장에서는 포인터의 개념과 기계 수준에서의 구현, 디버거를 활용한 프로그램 분석, 버퍼 오버플로우의 위험성과 이에 대한 방어 기법, 그리고 가변 크기 스택 프레임을 지원하기 위한 방법 등을 다루었습니다. 이러한 내용들은 안전하고 효율적인 시스템 프로그램을 작성하는 데 중요한 기반이 됩니다.
3.11 부동소수점 코드
부동소수점 아키텍처는 부동소수점 데이터를 다루는 프로그램이 기계 수준에서 어떻게 매핑되는지를 결정하는 여러 요소로 구성됩니다. 이러한 요소에는 다음이 포함됩니다:
부동소수점 값의 저장 및 접근 방법: 일반적으로 레지스터를 통해 저장 및 접근됩니다.
부동소수점 데이터를 다루는 명령어: 부동소수점 연산을 수행하기 위한 특정 명령어 세트가 있습니다.
함수 인수 전달 및 결과 반환에 대한 관례: 부동소수점 값을 함수에 전달하고 결과를 반환하는 방법에 대한 표준 규칙이 있습니다.
함수 호출 시 레지스터 보존 규칙: 어떤 레지스터가 호출자에 의해 저장되고, 어떤 레지스터가 피호출자에 의해 저장되는지에 대한 규칙이 있습니다.
3.11.1 부동소수점 이동 및 변환 연산
부동소수점 데이터 이동
vmovss / vmovsd: 스칼라 부동소수점 값을 메모리와 XMM 레지스터 사이에서 이동합니다.
vmovss: 단일 정밀도(32비트) 부동소수점 값을 이동.
vmovsd: 이중 정밀도(64비트) 부동소수점 값을 이동.
vmovaps / vmovapd: 정렬된 패킹된 부동소수점 값을 XMM 레지스터 사이에서 이동합니다.
vmovaps: 단일 정밀도 부동소수점 값을 정렬된 방식으로 이동.
vmovapd: 이중 정밀도 부동소수점 값을 정렬된 방식으로 이동.
주의: 메모리에서의 이동 시 16바이트 정렬이 필요하며, 그렇지 않으면 예외가 발생할 수 있습니다.
부동소수점과 정수 간의 변환
부동소수점에서 정수로 변환
vcvttss2si: 단일 정밀도 부동소수점 값을 정수로 변환(잘림).
vcvttsd2si: 이중 정밀도 부동소수점 값을 정수로 변환(잘림).
설명: 부동소수점 값을 정수로 변환할 때, 잘림(truncation) 연산을 수행하여 0에 가까운 쪽으로 반올림합니다.
정수에서 부동소수점으로 변환
vcvtsi2ss: 정수를 단일 정밀도 부동소수점 값으로 변환.
vcvtsi2sd: 정수를 이중 정밀도 부동소수점 값으로 변환.
특징: 3-오퍼랜드 형식으로, 첫 번째 소스는 변환할 정수 값이며, 두 번째 소스와 목적지는 XMM 레지스터입니다.
부동소수점 형식 간의 변환
단일 정밀도에서 이중 정밀도로 변환
vcvtss2sd: 단일 정밀도 부동소수점 값을 이중 정밀도로 변환.
gcc의 구현: gcc는 이 변환을 위해 vunpcklps와 vcvtps2pd 명령어를 조합하여 사용합니다.
이중 정밀도에서 단일 정밀도로 변환
vcvtsd2ss: 이중 정밀도 부동소수점 값을 단일 정밀도로 변환.
gcc의 구현: gcc는 이 변환을 위해 vmovddup와 vcvtpd2psx 명령어를 조합하여 사용합니다.
3.11.2 프로시저에서의 부동소수점 코드
인수 전달 규칙
부동소수점 인수 전달
첫 번째부터 여덟 번째까지의 부동소수점 인수는 XMM 레지스터 %xmm0부터 %xmm7에 전달됩니다.
추가적인 부동소수점 인수는 스택을 통해 전달됩니다.
정수 및 포인터 인수 전달
정수 및 포인터 인수는 범용 레지스터에 전달됩니다 (%rdi, %rsi, %rdx, %rcx, %r8, %r9 등).
함수 반환 값
부동소수점 반환
부동소수점 함수의 반환 값은 %xmm0 레지스터에 저장되어 반환됩니다.
레지스터 보존 규칙
호출자 저장(caller-saved) 레지스터
모든 XMM 레지스터는 호출자 저장 레지스터입니다. 즉, 함수 호출 시 호출자가 이 레지스터의 값을 저장해야 합니다.
3.11.3 부동소수점 산술 연산
산술 명령어
기본 연산
vaddss / vaddsd: 덧셈 (단일 / 이중 정밀도)
vsubss / vsubsd: 뺄셈
vmulss / vmulsd: 곱셈
vdivss / vdivsd: 나눗셈
최대/최소 값 연산
vmaxss / vmaxsd: 최대값 계산
vminss / vminsd: 최소값 계산
제곱근 연산
sqrtss / sqrtsd: 제곱근 계산
예제
함수 double funct(double a, float x, double b, int i)에서 다음과 같이 부동소수점 연산이 수행됩니다:
x를 이중 정밀도로 변환합니다.
a와 x를 곱합니다.
i를 이중 정밀도로 변환합니다.
b를 i로 나눕니다.
두 결과를 빼서 반환합니다.
3.11.4 부동소수점 상수 정의 및 사용
즉시 값 사용 불가
부동소수점 명령어는 즉시(immediate) 값을 직접 오퍼랜드로 사용할 수 없습니다.
상수 로딩 방법
상수를 사용하기 위해서는 상수를 메모리에 저장하고, 명령어에서 메모리 주소를 참조하여 값을 로드합니다.
예를 들어, 섭씨 온도를 화씨로 변환하는 함수 double cel2fahr(double temp)에서는 1.8과 32.0이라는 상수를 메모리에 저장하고 로드하여 사용합니다.
3.11.5 부동소수점 코드에서의 비트 연산 사용
비트 연산 명령어
vxorpd / vxorps: 비트 단위 XOR 연산을 수행하여 부동소수점 값의 부호를 반전시키거나 특정 비트 패턴을 조작할 수 있습니다.
vandpd / vandps: 비트 단위 AND 연산을 수행하여 부동소수점 값에서 특정 비트를 마스킹할 수 있습니다.
응용
절댓값 계산: 부호 비트를 마스킹하여 절댓값을 구할 수 있습니다.
부호 반전: 부호 비트를 토글하여 부동소수점 수의 부호를 반전시킬 수 있습니다.
3.11.6 부동소수점 비교 연산
비교 명령어
ucomiss / ucomisd: 부동소수점 값을 비교하고 조건 코드를 설정합니다. 비교 결과에 따라 ZF, CF, PF 플래그가 설정됩니다.
조건 코드 설정
ZF (Zero Flag): 두 값이 같으면 설정됩니다.
CF (Carry Flag): 비교에서 첫 번째 값이 두 번째 값보다 작으면 설정됩니다.
PF (Parity Flag): 비교하는 값 중 하나가 NaN이면 설정됩니다.
분기 명령어
비교 결과에 따라 다음과 같은 분기 명령어가 사용됩니다:
ja (Jump if Above): CF=0이고 ZF=0일 때 분기.
jb (Jump if Below): CF=1일 때 분기.
je (Jump if Equal): ZF=1일 때 분기.
jp (Jump if Parity): PF=1일 때 분기 (NaN 비교 시 사용).
예제
range_t find_range(float x) 함수에서는 x의 값이 0보다 큰지, 작은지, 같은지, 또는 NaN인지 판단하여 적절한 범주를 반환합니다. 이를 위해 부동소수점 비교 명령어와 조건부 분기 명령어를 사용합니다.
3.11.7 부동소수점 코드에 대한 관찰
정수 코드와의 유사성
부동소수점 코드는 레지스터를 사용하여 값을 저장하고 연산하며, 함수 인수를 전달하는 방식에서 정수 코드와 유사합니다.
복잡성 증가 요인
데이터 타입 다양성: 단일 정밀도와 이중 정밀도 등 여러 부동소수점 데이터 타입이 있으며, 이로 인해 코드가 복잡해집니다.
명령어 다양성: 부동소수점 연산에는 정수 연산보다 더 많은 명령어와 다양한 형식이 사용됩니다.
성능 향상 가능성
SIMD 활용: AVX2의 SIMD 기능을 사용하면 데이터 병렬 처리를 통해 성능을 향상시킬 수 있습니다.
컴파일러 지원: 현재 컴파일러는 이러한 최적화를 자동으로 수행하지 못할 수 있으며, 프로그래머가 SIMD 명령어를 직접 활용하거나 언어 확장을 사용해야 할 수 있습니다.
결론
부동소수점 코드는 복잡하지만, 그 기본 원리는 정수 코드와 유사합니다. x86-64 아키텍처에서 부동소수점 연산을 이해하려면 AVX와 SSE 확장을 이해하고, 레지스터 사용 규칙과 명령어 세트를 숙지해야 합니다. 또한, 부동소수점 연산에서 발생할 수 있는 특수한 상황(예: NaN 처리)을 이해하는 것이 중요합니다. SIMD 기능을 활용하여 성능을 향상시킬 수 있지만, 이는 추가적인 프로그래밍 노력을 필요로 할 수 있습니다.
