1. 인덱스 특징과 종류
인덱스는 검색 연산의 최적화를 위해 데이터베이스 내 열에 대한 정보를 구성한 데이터 구조이다.
- 인덱스를 통해 전체 데이터의 검색 없이 필요ㅛ한 정보에 대해 신속한 조회가 가능하다.
- INSERT, UPDATE, DELETE 등과 같은 DML 작업은 테이블과 인덱스를 함께 변경해야 하기 때문에 오히려 느려질 수 있다는 단점이 존재한다.
1.1 트리 기반 인덱스
DBMS 에서 가장 일반적인 B-트리 인덱스
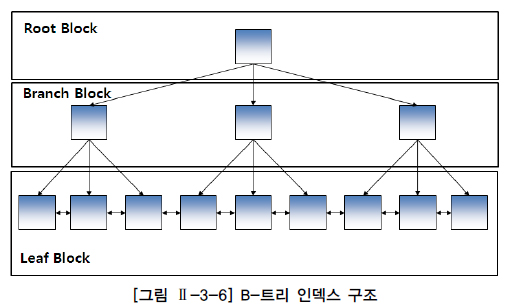
- 브랜치 블록 중에서 가장 상위에 있는 블록을 루프 블록이라고 한다.
- 브랜치 블록은 다음 단계의 블록을 가리키는 포인터를 가지고 있다.
- 리프 블록은 트리의 가장 아래 단계에 존재한다.
- 리프 블록은 (컬럼 데이터, 해당 데이터 행의 위치-RID)로 구성된다.
- 인덱스 데이터는 인덱스를 구성하는 컬럼의 값으로 정렬된다.
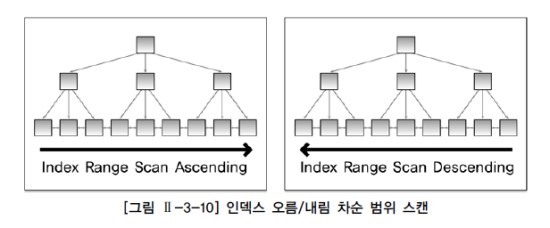
- 리프 블록은 양방향 링크를 가지고 있다. (오름차순/내림차순 검색을 쉽게 할 수 있다.)
- B-트리 인덱스는
=로 검색하는 일치검색과BETWEEN,>등과 같은 연산자로 검색하는 범위검색에 모두 적합하다.
Oracle 에서 트리 기반 인덱스에는 B-트리 인덱스 외에도 비트맵 인덱스, 리버스 키 인덱스, 함수 기반 인덱스 등이 존재한다.
1.2 클러스터형 인덱스(SQL Server)
SQL Server에서는 저장 구조에 따라 클러스터형 인덱스와 비클러스터형 인덱스가 있다.
클러스터형 인덱스
- 인덱스의 리프 페이지가 곧 데이터 페이지이다. 클러스터형 인덱스의 리프 페이지를 탐색하면 해당 테이블의 모든 컬럼 값을 곧바로 얻을 수 있다.
- 리프 페이지의 모든 로우(데이터)는 인덱스 키 컬럼 순으로 물리적으로 정렬되어 저장된다.
- 클러스터형 인덱스는 물리적으로 한가지 순서로만 정렬될 수 있다. 테이블당 한개만 생성할 수 있다.
2. 전체 테이블 스캔과 인덱스 스캔
2.1 전체 테이블 스캔
테이블에 존재하는 모든 데이터를 읽어 가면서 조건에 맞으면 결과로서 추출하고 조건에 맞지 않으면 버리는 방식으로 검색한다.
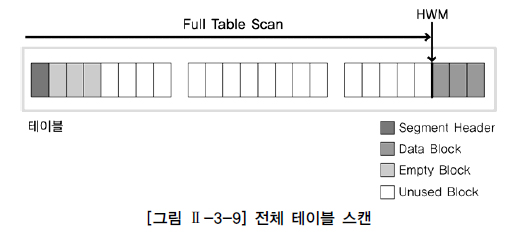
전체 테이블 스캔 방식은 테이블에 존재하는 모든 블록의 데이터를 읽기 때문에 시간이 오래 걸릴 수 있다.
2.2 인덱스 스캔
- 인덱스의 리프 블록 : 인덱스 구성 컬럼 + 레코드 식별자(RID)
- 인덱스는 인덱스 구성 컬럼의 순서로 정렬되어 있다.
- 인덱스 유일 스캔 : 유일 인덱스(Unique Index)를 사용하여 단 하나의 데이터를 추출하는 방식, 중복을 허락하지 않음
- 인덱스 범위 스캔 : 인덱스를 이용하여 한 건 이상의 데이터를 추출하는 방식
- 인덱스 역순 범위 스캔 : 인덱스 리프 블록의 양방향 링크를 이용하여 내림 차순으로 데이터를 읽는 방식