문자 인코딩에 대한 이것저것~~~
비트와 바이트
비트
컴퓨터가 처리할 수 있는 가장 작은 단위의 정보를 나타내는 것으로 0과 1로 이루어져 있다
바이트
컴퓨터에서 가장 기본적인 단위로 1byte는 8bit로 구성된다
1byte는 0~255까지의 값(256까지의 수)을 표현할 수 있다(00000000 ⇒ 0, 11111111 ⇒ 255)
문자 인코딩이란
사용자가 입력한 문자나 기호들을 컴퓨터가 이해할 수 있는 이진 데이터로 변환하는 과정으로 표는 character set이라고 불림(컴퓨터와 대화하기 위해서 필수!!)
유니코드
전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 국제 표준 문자 인코딩 코드표이다
유니코드는 코드 포인트를 통하여 표현되며 16진수 숫자 값 앞에 U+ 를 붙인다
\u라는 접두어가 사용될 시에는 Unicode Escape라고 불리며 이는 프로그래밍 언어에서 유니코드 문자를 표현하기 위해서 사용된다
** 코드 포인트 : 특정 유니코드 문자에 부여되어 있는 고유한 16진수의 숫자 값(16진수 : 0x00 ~ 0xFF)
다국어 기본 평면(Basic Multilingual Plane, BMP)
유니코드의 첫번째 평면으로 U+0000~U+FFFF 까지의 영역을 차지하며 거의 모든 근대 문자와 특수문자, 한글, 한자 등을 포함한다
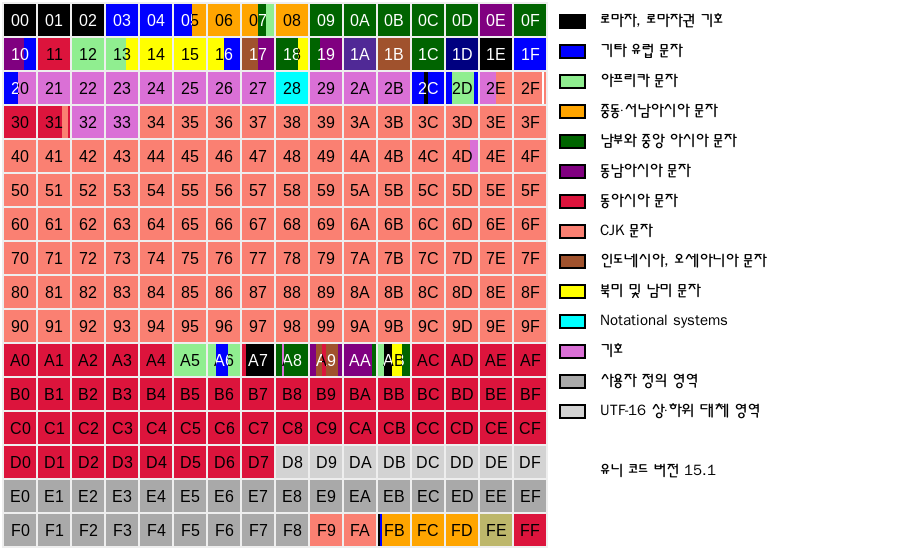
문자 인코딩 방식
ASCII (American Standard Code for Information Interchange)
1960년대 미국에서 ANSI에서 정의한 표준 부호체계로 영문 알파벳을 사용하는 대표적인 문자 인코딩 방식으로 7비트 이진 코드를 사용하여 알파벳, 숫자, 특수 문자들을 표현한다
1비트는 패리티 비트로 통신 중 생기는 오류 발생을 잡는 역할을 하고 있다
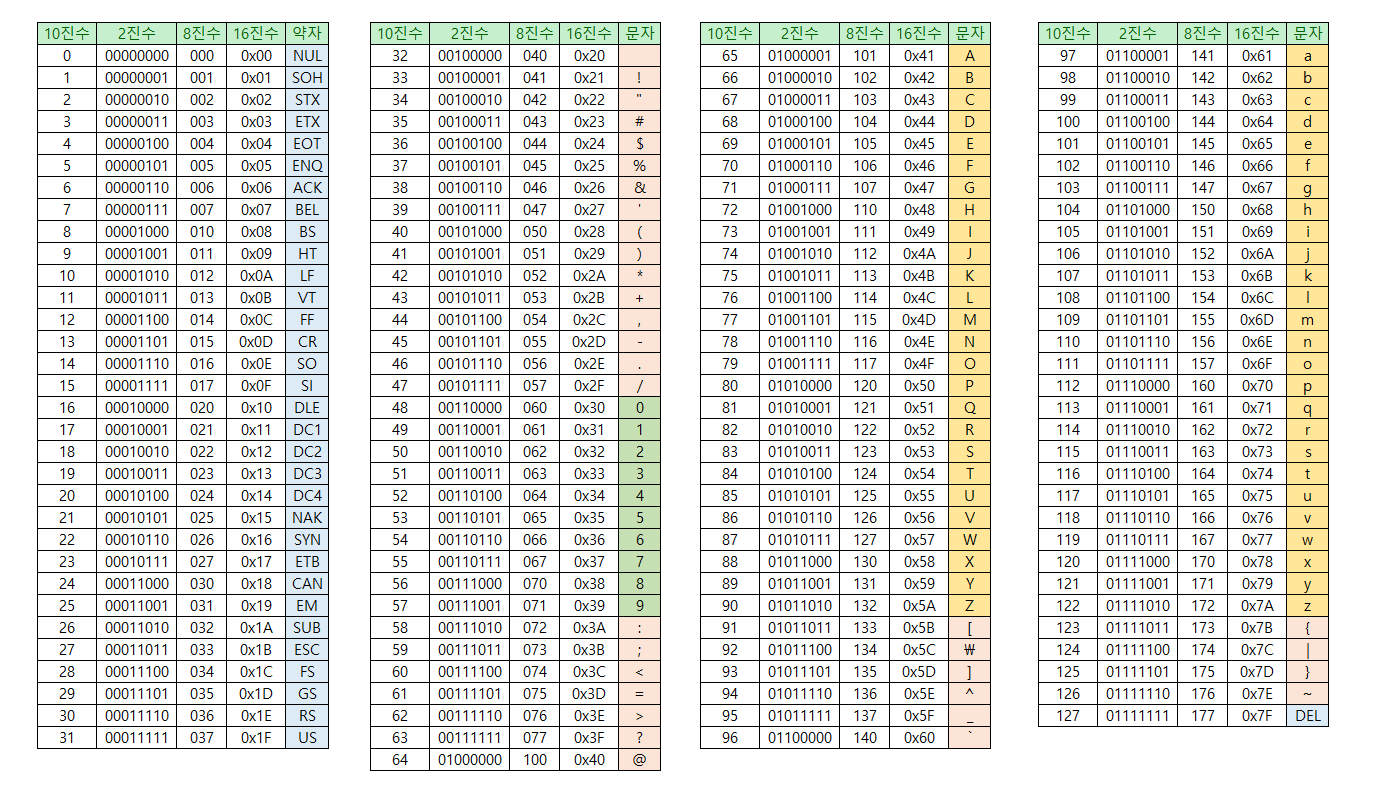
char c = 'A';
int dec = c;//65 10진수
String binary = toBinaryString(dec);//1000001 2진수
String hex = toHexStrung(dec)//41 16진수EUC-KR (Extended Unix Code for Korean)
완성형 인코딩 방식으로 완성된 단어가 있어야만 표현이 가능하다(완성된 문자가 없을 경우 한글이 깨져보일 수 있음)
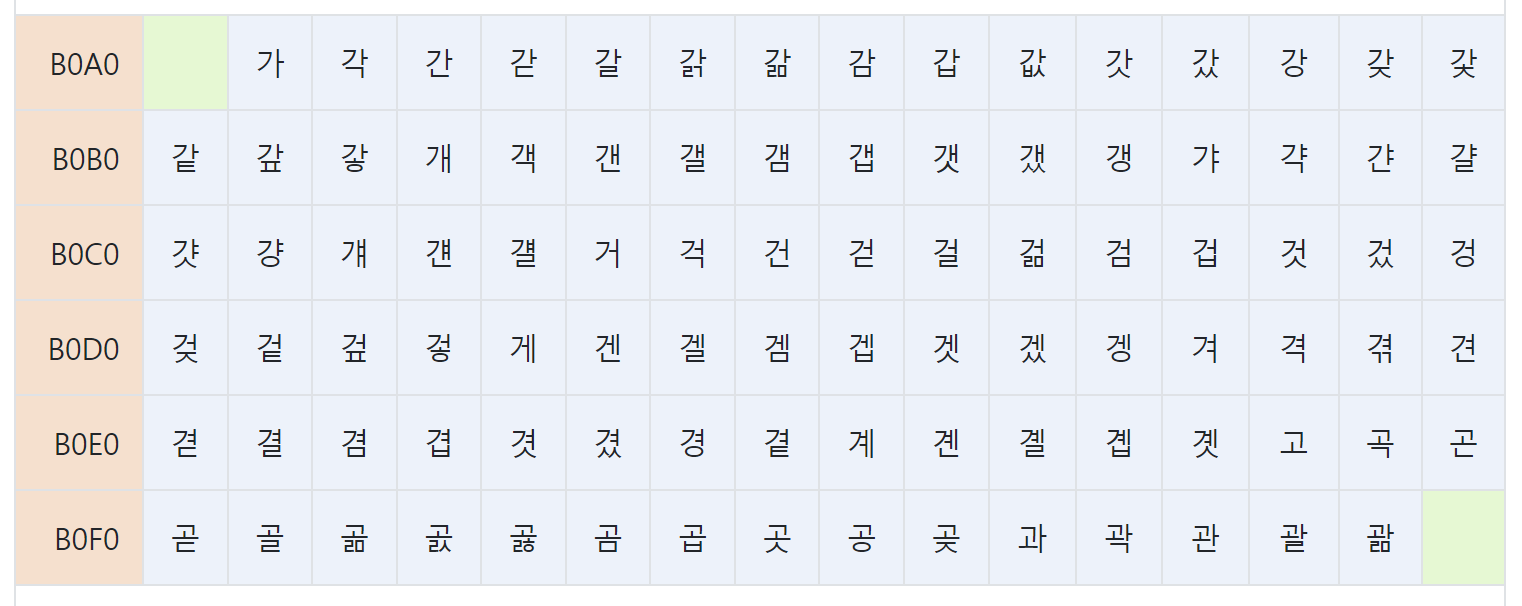
EUC-KR 코드표 일부. 완성형 단어로 이루어져 있음 https://uic.io/ko/charset/show/euc-kr/
한글 한글자에 2byte를 사용하며 EUC-KR로 표현 불가능한 글자와 동시에 사용할 수 없다
EUC-KR로 인코딩되어 있는 것을 다른 인코딩 방식으로 읽을 경우 글자들이 모두 깨져서 읽힐 수 있다
UTF-8 (Unicode Transformation Format - 8-bit)
유니코드를 위한 가변 길이 문자 인코딩 방식으로 문자 하나를 표현하기 위해 1byte~ 4byte를 사용한다(6byte까지 사용 가능하나 거의 사용하지 않음)
웹에서 많이 사용되며, XML 및 HTML 기본 인코딩 방식이다
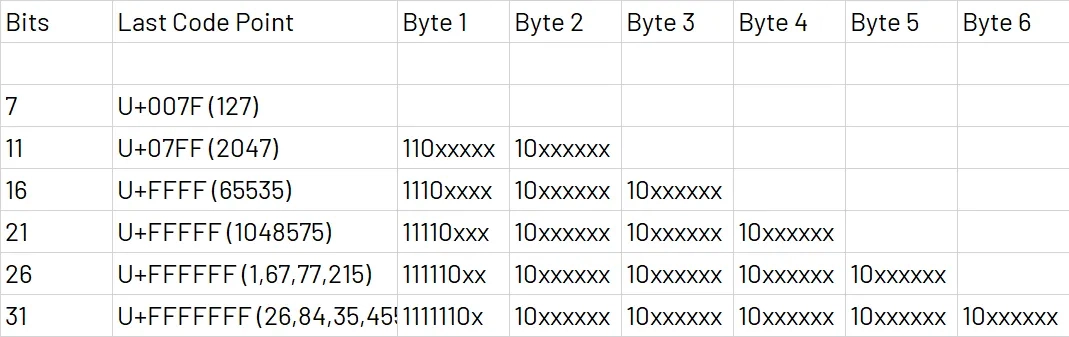
첫번째 바이트에 총 몇 바이트를 사용하는지 알리는 비트를 넣고(2바이트 : 110, 3바이트 : 1110, 4바이트 : 1110) 두번째 바이트부터는 10을 넣음
1바이트(U+0000 ~ U+007F)
ASCII 코드 전체로 첫번째 비트는 0을 넣고 나머지 문자는 최대 7비트로 표현한다.
2바이트(U+0080 ~ U+07FF)
문자는 최대 11비트로 표현하며 중동, 유럽지역 언어를 포함한다
3바이트(U+0800 ~ U+FFFF)
문자는 최대 16비트로 표현하며 한글 포함 아시아권 언어를 포함한다
4바이트((U+10000 ~ U+10FFFF)
문자는 최대 21비트로 표현하며 BMP(Basic Multilingual Plane) 에 속하지 않는 문자 전부를 포함한다
UTF-16(Unicode Transformation Format 16-bit)
자바,자바스크립트에서 기본으로 쓰여진다
2btye로 문자를 표현하는 인코딩 방식으로 특수한 경우에는 서로게이트 페어를 사용하여 4byte로 문자를 표현한다
** 서로게이트 페어 : 두 개의 16비트 코드 유닛으로 구성된 32비트 인코딩
High Surrogate : 첫번째 16비트 코드 유닛
Low Surrogate : 두번째 16비트 코드 유닛
JavaScript) 이모지를 출력했는데 코드 유닛이 나오는 이유
JavaScript에서 'hello😊cut-off'.substring(0,6); 를 실행하였을 때 결과는 다음과 같다.
'hello😊cut-off'.substring(0,6);
-> 'hello\uD83D'JavaScript는 기본적으로 UTF-16을 사용한다.
‘😊’의 경우 U+1F60A 의 코드포인트(유니코드) 를 가지므로 16비트가 초과되기 때문에 서로게이트 페어를 사용하여 두 개의 코드 유닛으로 구성하여야한다.
해당 문자열을 16진수로 변경하였을 때
const str = 'hello😊cut-off';
escape(str);
-> 'hello%uD83D%uDE0Acut-off'😊의 코드 유닛이 ‘%uD83D%uDE0A’ 로 나오는 것을 볼 수 있다.
문자열의 경우 UTF-16 코드 유닛 기준으로 인덱스를 처리하기 때문에 코드 유닛이 각각 다른 인덱스에 저장된다
공백을 기준으로 해당 문자열을 잘랐을 때
const str = 'hello😊cut-off';
str.split("");
-> ['h', 'e', 'l', 'l', 'o', '\uD83D', '\uDE0A', 'c', 'u', 't', '-', 'o', 'f', 'f']😊 을 표현하기 위해서는 두 개의 코드 유닛이 필요하다.
'hello😊cut-off'.substring(0,6);은 High Surrogate 까지만 반환되었기 때문에 lone surrogate가 되어 이모지가 올바르게 출력되지 않았다.
이모지를 올바르게 출력되기 위해서는 Surrogate Pair 모두 반환되어야 한다.
'hello😊cut-off'.substring(0,7);
-> 'hello😊'
// slice()도 사용 가능
const str = 'hello😊cut-off';
str.slice(0,7);
-> 'hello😊'
// str을 배열에 저장한 후 문자열로 출력
const str = 'hello😊cut-off';
[...str].slice(0,6).join('');
-> 'hello😊'해당 문자열을 다른 방식으로 출력하였을 때는 어떨까?
///배열을 통한 출력
const str = 'hello😊cut-off';
const arr = [...str];
console.log(arr);
-> ['h', 'e', 'l', 'l', 'o', '😊', 'c', 'u', 't', '-', 'o', 'f', 'f']
///for...of문을 통한 출력
const str = 'hello😊cut-off';
for(let char of str){ console.log(char);}
-> h e l l o 😊 c u t - o f f
///for문을 통한 출력
const str = 'hello😊cut-off';
for (let i = 0; i < str.length; i++) {
console.log(str[i]);}
-> h e l l o � � c u t - o f f1) 배열을 통한 출력
배열의 경우 비트 크기 등과는 관계없이 한 요소가 한 인덱스를 차지하기 때문에 이모지가 올바르게 출력된다
2) for...of문을 통한 출력
for…of 문은 iterator를 사용하여 문자열을 순회함 → iterator는 문자열 값의 유니코드 코드 포인트를 개별 문자열로 산출하기 때문에 서로게이트가 유지되어 이모지가 올바르게 출력된다
https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/String/@@iterator
3) for문을 통한 출력
for문은 문자열의 인덱스를 기반으로 순회함 → 두 개의 코드 유닛이 각각 나뉘어져 출력되어 서로게이트가 유지되지 않기 때문에 이모지가 올바르게 출력되지 않고 �로 표시된다
JavaScript) charCodeAt/codePointAt 의 차이
charCodeAt()
문자열에서 주어진 인덱스 위치의 UTF-16 코드 유닛을 숫자값으로(10진수) 반환
codePointAt()
문자열에서 주어진 인덱스 위치의 전체 코드 포인트를 숫자값으로(10진수) 반환
const str = '😊';
console.log(str.charCodeAt(0));// 55357 => 10진수
console.log(str.charCodeAt(0).toString(16));// d83d => 16진수
-> 첫번째 코드 유닛
console.log(str.charCodeAt(1)); // 56842
console.log(str.charCodeAt(1).toString(16));// de0a
-> 두번째 코드 유닛
console.log(str.codePointAt(0)); // 128522
console.log(str.codePointAt(0).toString(16));// 1f60a4
-> 전체 유니코드 코드포인트
console.log(str.codePointAt(1)); // 56842
console.log(str.codePointAt(1).toString(16));// de0a
-> 두번째 코드 유EUC-KR이 “힣”, “뷁” 을 표현하지 못하는 이유
간단하게 이야기하면 EUC-KR의 character set에는 “힣”, “뷁”에 대한 코드가 없기 때문이다.
“힣”, “뷁” 을 표현하기 위해서는 더 포괄적인 문자를 지원하는 유니코드 기반의 인코딩 방식을 사용하는 것이 좋다.
class Test {
public static void main(String[] args) {
String word = "힣뷁";
String arr[] = {"UTF-8", "EUC-KR"};
for(String type : arr) {
try {
byte[] bytes = word.getBytes(type);
String answer = new String(bytes, type);
System.out.println(type + " : " + answer);//UTF-8 : 힣뷁, EUC-KR : ??
}catch (UnsupportedEncodingException e){
throw new RuntimeException(e);
}
}
}
}MySQL 에서 이모지 깨짐(character set = uft8)
mysql의 uft8은 3byte로 문자를 표한하는 인코딩 방식이다. 그렇기 때문에 4byte의 문자열인 이모지를 저장할 수 없다.
이러한 경우 character set을 4byte 문자열 지원이 가능한 utf8mb4를 사용하면 이모지가 깨지지 않고 올바르게 노출된다.
문자열 > 코드포인트 > 코드유닛 > 이진수(UTF-16)
public class EncodingFlow2 {
// 코드 유닛을 16자리 이진수 문자열로 변환
String Binary(int codeUnit) {
return String.format("%16s", Integer.toBinaryString(codeUnit)).replace(' ', '0');
}
// 코드 포인트를 코드 유닛(UTF-16)으로 변환
public int[] codePointToCodeUnits(int codePoint) {
System.out.println(0xD800);
if (codePoint >= 0x0000 && codePoint <= 0xFFFF) {
return new int[]{codePoint};
} else if (codePoint >= 0x010000 && codePoint <= 0x10FFFF) {
codePoint -= 0x010000;
int highSurrogate = 0xD800 + (codePoint >> 10);
int lowSurrogate = 0xDC00 + (codePoint & 0x3FF);
return new int[]{highSurrogate, lowSurrogate};
} else {
throw new IllegalArgumentException("Invalid code point: " + codePoint);
}
}
// 문자열의 코드 포인트 > 코드 유닛 > 이진수 변환
public void CodePoint(String word) {
for (int i = 0; i < word.length(); i++) {
int codePoint = word.codePointAt(i);
System.out.println("codePoint : " + codePoint);
System.out.println("charCount : " + Character.charCount(codePoint));
if (Character.charCount(codePoint) == 2) {
i++;
}
int[] codeUnits = codePointToCodeUnits(codePoint);
for (int codeUnit : codeUnits) {
String binary = Binary(codeUnit);
System.out.println("codeUnit : " + Integer.toHexString(codeUnit));
System.out.println("binary : " + binary);
}
}
}
public static void main(String[] args) {
String word = "abc😊";
EncodingFlow2 ef = new EncodingFlow2();
ef.CodePoint(word);
}
}
