CQRS 이해하기
1. CQRS란?
CQRS는 command query responsibility segregation의 약자로 명령과 쿼리의 책임을 가진 구성요소를 분리하는 것을 말한다.
명령
- 시스템 데이터 변경하는 기능
ex) 주문 취소, 배송완료
쿼리
- 시스템 데이터를 조회하는 기능
- 쿼리는 시스템의 상태를 단지 반환하기만 하고 상태를 변경시키지 않아야 한다.
ex) 주문 목록 조회
책임
- 구성 요소의 역할
-> 객체의 역할이라고 생각하면 편하다.
분리
- 시스템 데이터를 조회하는 기능
ex) 주문 목록 조회
정리
명령(시스템 데이터 변경하는 기능)역할을 수행하는 구성요소와 쿼리(시스템 데이터를 조회하는 기능)역할을 수행하는 구성요소를 나누는 것이 CQRS이다.
그럼 왜 CQRS를 사용해야 할까?
우선 CQRS를 사용하지 않고, 명령과 쿼리를 단일 모델로 다룰 시 어떻게 되는지 먼저 살펴보자.
2. 명령과 쿼리를 단일 모델에 둔다면?
-
우선 여러 테이블들이 한 테이블안에서 서로 엮이게 된다.
-> 예를 들어 member 테이블에 member에 대한 기능들 이외에, 회원의 예약 에 대한 정보와 회원의 장바구니 목록과 같은 정보들이 포함된다면 어떻게 될까?
처음 기능을 개발할 때는 편하겠지만, 이런식으로 여러 정보들이 쌓인다면, 복잡성이 증가할 것이다.
-> 테이블의 의미가 명확해지지 않아 어떤 책임을 수행해야 할 때 경계가 모호해진다. -
기능에 따라 사용하는 테이블의 필드도 달라진다.
-> 예를 들어 회원의 기본 정보 조회에는 회원의 예약 목록과 장바구니 목록과 같은 정보는 필요 없다.
-> 이런 문제들로 의미/가독성과 유지 보수성이 떨어진다.
좀 더 자세히 살펴보자.
1. 명령과 쿼리가 다루는 데이터가 다르다.
- 명령의 경우 주로 한 영역의 데이터만 다루는 반면, 쿼리는 시스템이 복잡해질 수록 여러 영역의 데이터를 다루는 경향이 있다.
-> 명령의 경우 해당 데이터만 변경하면 되지만, 쿼리의 경우 조회에 여러 영역의 데이터가 필요한 경우가 많다.
2. 명령과 쿼리는 코드 변경 빈도나 사용자도 다르다.
- 변경 빈도가 사용자가 다른 기능의 코드가 한 코드에 있으면, 서로 다른 이유로 다른 시점에 코드가 변경되게 된다.
-> 이는 곧 책임의 크기가 적당하지 않은 것을 의미한다.
-> 단일 책임 원칙 위배
3. 기능마다 트래픽이나 성능 요구가 다르다.
- 그래서 기능마다 적절한 성능 향상 방법이 다르다.
-> 단일 모델로는 다양한 성능 향상 기법의 적용이 어려울 수 있다.
결국 명령과 쿼리를 분리하지 않는 것은 전지전능한 객체를 만드는 것과 같다.
이는 객체지향의 핵심인 시스템의 요구사항인 협력을 분리하여 책임으로 나누고, 책임을 수행할 역할을 가진 객체들의 상호작용의 개념과 정반대이다.
그래서 명령과 쿼리를 분리하는 것이다.
3. CQRS의 장점
- 모델의 모호함이 사라진다.
- 명령 모델과 쿼리 모델이 무엇을 표현하고 있는지가 명확하다.
-> 코드 가독성, 유지 보수성이 높아짐
- 기능에 따라 성능 향상 기법을 적용하는 것이 용이해진다.
ex) 쿼리쪽에는 캐시, 명령쪽에는 비동기를 적용할 수 있다.
4. CQRS 구현 형태
구현 형태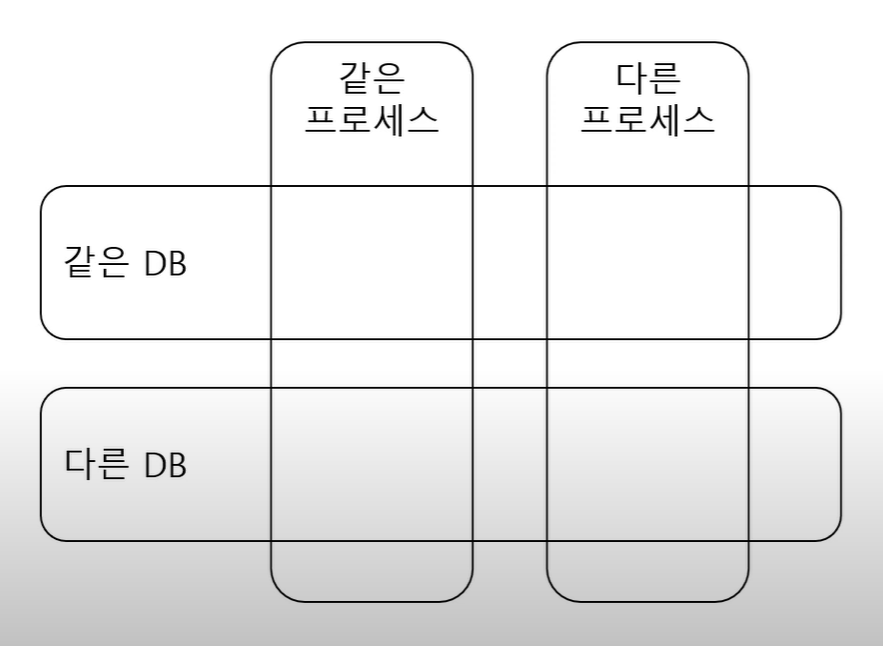
4-1. 같은 프로세스 같은 DB
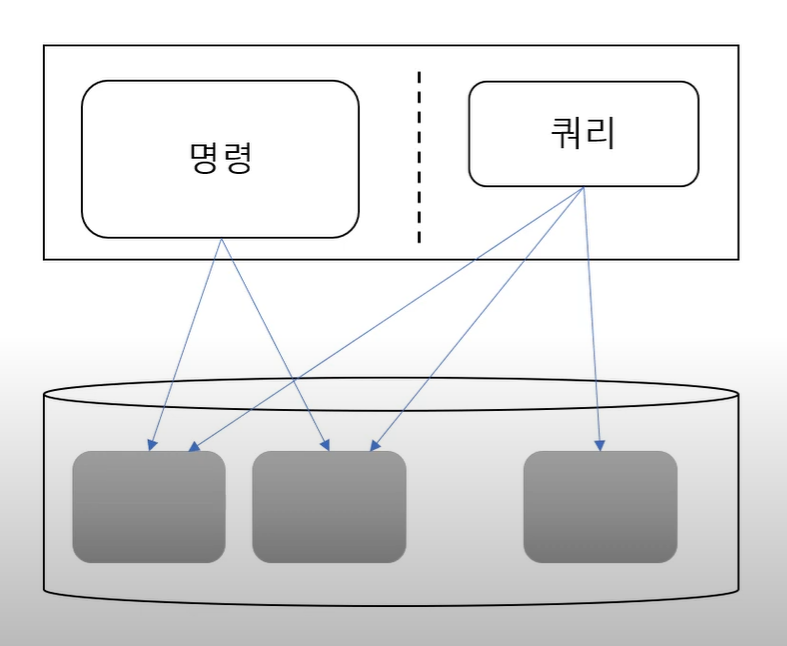
쿼리 수준에서는 명령과 쿼리를 구분하지만, 데이터 수준에서는 구분하지 않는다.
4-2. 같은 프로세스 같은 DB, 다른 테이블
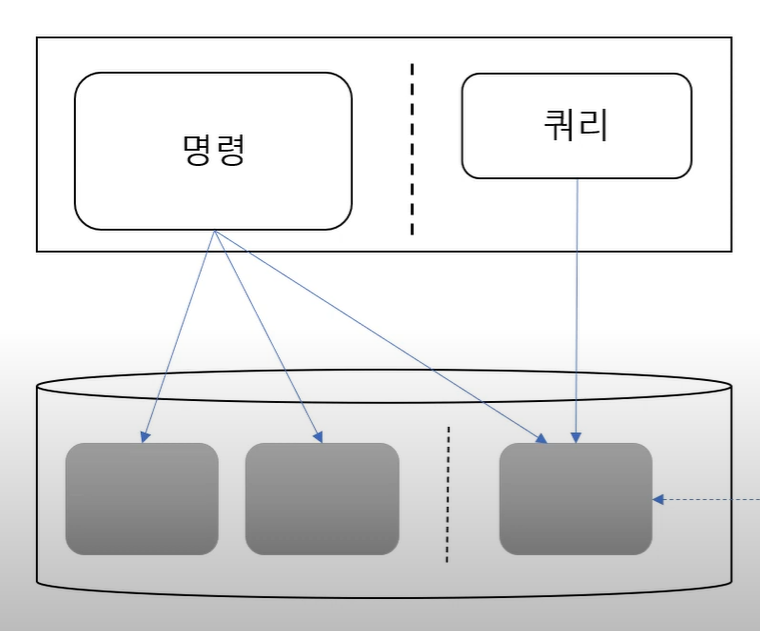
명령과 쿼리가 코드 수준에서는 분리되며, 데이터 수준에서도 분리된다.
단, 데이터가 같은 DB에 있는 형태이다.
예를 들어 최근 조회수가 많은 글 목록을 별도의 테이블로 생성하고, 쿼리 모델은 이 테이블을 이용해서 구현하는 방식이다.
-
쿼리 전용 테이블 사용
ex) 조회수가 많은 글 목록 테이블 -
명령이 쿼리 전용 데이터 변경 유발
-> 명령이 상태를 변경할 때, 쿼리 전용 테이블을 함께 변경해야 한다.
4-3. 같은 프로세스 다른 DB
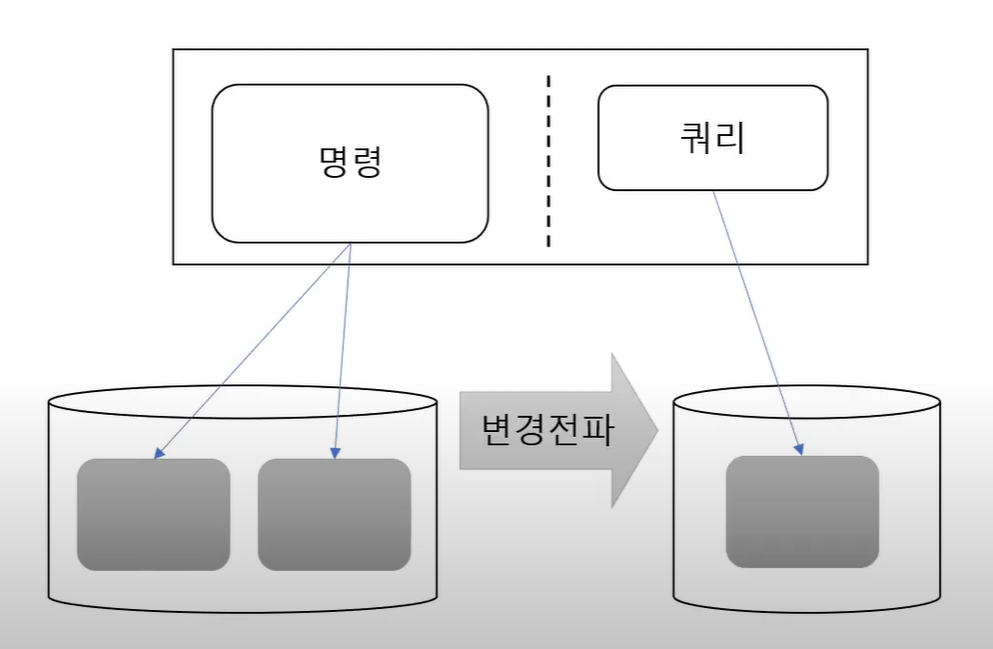
이 방식에서는 명령이 데이터를 변경하면, 그 변경 내용을 쿼리쪽 DB에 전달하는 방식이다.
예를 들어 상품 목록을 Redis와 같은 저장소에 저장하고, 쿼리 모델은 Redis를 사용하는 식으로 하는 방식이다.
4-4. 다른 프로세스 다른 DB
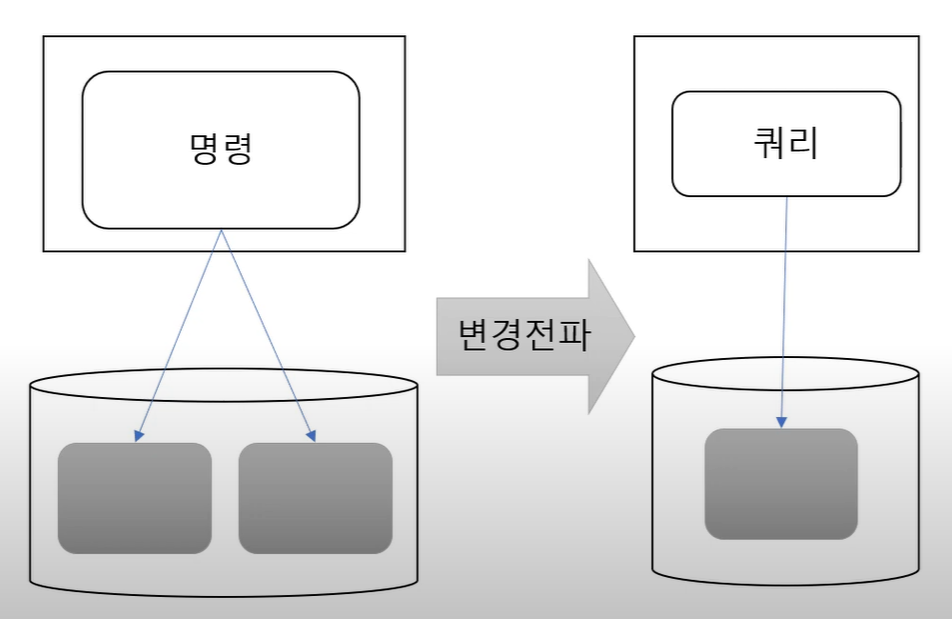
micro service에서 자주 사용하는 방식이다.
5. 주의할 점
만약 명령과 쿼리를 다른 DB로 사용한다면, 전파하는 방식이 다양해질 수 있다.
이때 주의할 점이 발생하는데, 주의할 점은 아래와 같다.
-
데이터 유실
-> 데이터 유실 허용 여부에 따라 DB트랜잭션 범위가 중요해진다. -
허용 가능 지연 시간
-> 명령의 변경 내역을 얼마나 빨리 쿼리쪽에 반영해야 하느냐에 따라 구현의 선택이 달라질 수 있다. -
중복 전달
쿼리쪽 DB에 변경된 데이터를 전달하는 과정에서 문제가 발생하게 되면, 다시 전달할 수 있는 수단이 필요하다.
-> 이런 수단을 만들다 보면 이미 반영된 데이터가 중복 전달되는 경우가 생길 수 있다.
-> 그래서 중복으로 데이터를 전달하더라도, 쿼리쪽 DB가 망가지지 않도록 별도의 조치가 필요하다.
참고 자료
https://www.youtube.com/watch?v=xf0kXMTFJm8
https://www.youtube.com/watch?v=H1IF3BUeFb8
