Cardinality의 개념과 적용
- Cardinality란?
- Cardinality는 전체 행에 대한 특정 컬럼의 중복 수치를 나타내는 지표이다.
이때 Cardinality는 절대적인 지표가 아닌 상대적인 지표이다.
그렇기에 Cardinality가 높다라 하면 상대적으로 전체 행에 대한 특정 컬럼의 중복 수치가 다른 특정 컬럼에 비해 높다라 생각할 수 있다.
아래 예시를 통해 Cardinality에 대해 조금 더 자세히 알아보자.
- MySQL 테이블
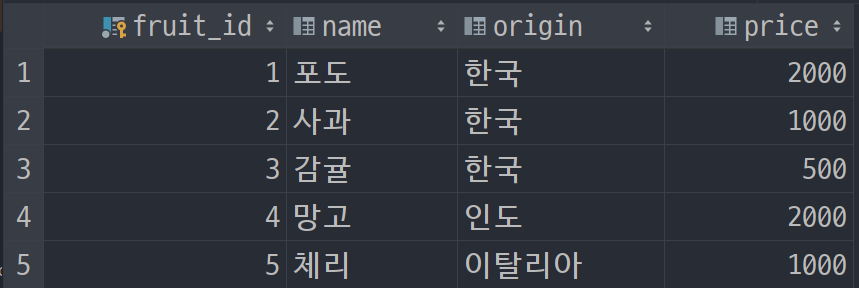
위의 테이블을 보면 name컬럼의 경우 origin에 비해 Cardinality가 높다.
즉, 중복도가 상대적으로 낮으면 Cardinality가 높다.
그럼 Cardinality는 어디에 사용할까?
- Fruit 테이블에 index적용
테이블의 검색속도를 향상시키기 위해서 index를 주로 사용한다.
인덱스를 걸 때, 인덱스를 통해 내가 원하는 데이터만 남아야 효율적이다.
인덱스를 통해 최대한 내가 원하는 데이터에 가깝게 추출하려면, 속성을 인덱싱할 때, Cardinarlity가 높은 속성를 사용해야 한다.
다수의 속성에 인덱스를 걸때는 Cardinarlity가 높은 속성을 우선순위로 둬야한다.
Fruit 테이블의 속성에 index를 걸어보자.
3-1. 다수의 속성에 인덱스 걸기
아래의 쿼리로 Cardinarlity와 index를 이해해보자.
select *
from fruit f
where f.name = '포도'
and f.origin = '한국'
and f.price = '2000';우선 Cardinarlity가 낮은 속성에 인덱스 우선순위를 부여하는 경우를 살펴보자.
create index idx_origin on fruit(origin, price, name);위의 인덱스를 사용하기위해 아래와 같이 쿼리를 작성한다.
select *
from fruit f
use index (idx_origin)
where f.name = '포도'
and f.origin = '한국'
and f.price = '2000';use index를 사용하지 않고, 쿼리를 날리면 옵티마이저가 쿼리 실행계획을 통해 자동으로 인덱스를 선택한다.
이 경우 원하는 인덱스를 사용하기 위해 명시적으로 사용할 인덱스를 작성했다.
위와 같이 쿼리를 날리면, origin -> price -> name 순으로 인덱스가 작동하기에 데이터 수는 3 -> 1 -> 1이 된다.
그럼 Cardinarlity가 상대적으로 높은 name에 인덱스 우선순위를 부여하면 어떻게 될까?
create index idx_name on fruit(name, price, origin);select *
from fruit f
use index (idx_name)
where f.name = '포도'
and f.origin = '한국'
and f.price = '2000';위의 쿼리는 name -> price -> origin 순으로 인덱스가 작동하므로
데이터 수는 1 -> 1 -> 1이 된다.
Cardinarlity가 높은 속성에 인덱스 우선순위를 부여했기에 탐색해야할 데이터의 수 자체가 적어진다.
이를 통해 인덱싱 속성의 순서를 정할 때 Cardinarlity가 얼마나 큰 영향을 미치는지 알 수 있었다.
데이터의 크기가 커지면 커질수록 더 큰 효과를 발휘할 것이다.
- Cardinality 조회
-
index를 조회하면 Cardinality를 확인할 수 있다.
-
comment table

show index from comment;
<정리>
카디널리티가 높다 -> 한 컬럼이 갖고 있는 값의 중복도가 낮다.(=값들이 대부분 다른 값을 가진다.)
카디널리티가 낮다 -> 한 컬럼이 갖고 있는 값의 중복도가 높다.(=값들이 거의 같은 값을 가진다.)
인덱스 설정시 카디널리티가 높은 컬럼을 인덱스로 설정하는 것이 좋다.
