.jpg)
데이터 분석에서 시각화가 중요한 이유는, 숫자로는 바로 파악하기 어려운 패턴을 발견할 수 있게 해주기 때문입니다. dlookr이라는 패키지는 데이터를 수치로 파악하는 것이 용이함은 물론, 시각화로도 잘 정리 해줍니다. 😊
관련하여 정리가 패키지 저작자이신 류충현 님의 블로그 글이 매우 친절하고 잘 정리가 되어 있어 링크 해두겠습니다. 더불어 본 포스팅에 실습 해보도록 하겠습니다.
블로그
요약
시각화
🌷 이상치의 시각화 : plot_outlier()
🌷 정규성 검정의 시각화 : plot_normality()
🌷 상관행렬의 시각화 : plot_correlate()
🌷 두 변수 간 비교 시각화 : plot(relate(target_by(a), b)) - a는 타겟변수, b는 예측 변수
리포트 추출
🌼 진단 리포트 추출 : diagnose_report()
🌼 EDA 리포트 추출 : eda_report()
🌼 데이터 변환 리포트 추출 : transformation_report()
실습
패키지 다운로드
오늘 실습은 새로운 컴퓨터로 진행할 것이기 때문에 패키지 인스톨 부터 모두 진행해보겠습니다! 실습을 할 데이터는 위 블로그와 동일하게 ISLR 패키지의 Carseats입니다.
실습에서 주요 포인트들(시각화와 리포트 추출 함수 사용)은 찾기 쉽도록 꽃모양 아이콘으로 앞에 표시해두었습니다. :)
# 활용할 패키지 설치와 로드
> install.packages("tidyverse")
> install.packages("dlookr")
> install.packages("ISLR") # Carseats 데이터 활용을 위해 인스톨
> library("tidyverse")
> library("dlookr")
> library("ISLR")데이터 시각화
# 내장되어 있는 데이터 정보를 살피려면 help(데이터 명) 명령을 합니다.
> help(Carseats)
Description
A simulated data set containing sales of child car seats at 400 different stores.
# 데이터의 기본 구조를 살펴봅니다.
# 11개의 변수~범주형 변수 3개, 숫자형 변수 8개~로 구성되어 있습니다.
> dplyr::glimpse(Carseats)
Observations: 400
Variables: 11
$ Sales <dbl> 9.50, 11.22, 10.06, 7.40, 4.15, 10.81, 6.63, 11.85, 6.54, 4.69, 9.01, 11.96, 3.98, 10.96, 11.17, 8.71, 7.58, 12.29, 13.91, 8.73, 6.41, 12.1...
$ CompPrice <dbl> 138, 111, 113, 117, 141, 124, 115, 136, 132, 132, 121, 117, 122, 115, 107, 149, 118, 147, 110, 129, 125, 134, 128, 121, 145, 139, 107, 98, ...
$ Income <dbl> 73, 48, 35, 100, 64, 113, 105, 81, 110, 113, 78, 94, 35, 28, 117, 95, 32, 74, 110, 76, 90, 29, 46, 31, 119, 32, 115, 118, 74, 99, 94, 58, 3...
$ Advertising <dbl> 11, 16, 10, 4, 3, 13, 0, 15, 0, 0, 9, 4, 2, 11, 11, 5, 0, 13, 0, 16, 2, 12, 6, 0, 16, 0, 11, 0, 0, 15, 0, 16, 12, 13, 0, 11, 0, 5, 0, 0, 0,...
$ Population <dbl> 276, 260, 269, 466, 340, 501, 45, 425, 108, 131, 150, 503, 393, 29, 148, 400, 284, 251, 408, 58, 367, 239, 497, 292, 294, 176, 496, 19, 359...
$ Price <dbl> 120, 83, 80, 97, 128, 72, 108, 120, 124, 124, 100, 94, 136, 86, 118, 144, 110, 131, 68, 121, 131, 109, 138, 109, 113, 82, 131, 107, 97, 102...
$ ShelveLoc <fct> Bad, Good, Medium, Medium, Bad, Bad, Medium, Good, Medium, Medium, Bad, Good, Medium, Good, Good, Medium, Good, Good, Good, Medium, Medium,...
$ Age <dbl> 42, 65, 59, 55, 38, 78, 71, 67, 76, 76, 26, 50, 62, 53, 52, 76, 63, 52, 46, 69, 35, 62, 42, 79, 42, 54, 50, 64, 55, 58, 30, 44, 64, 50, 42,...
$ Education <dbl> 17, 10, 12, 14, 13, 16, 15, 10, 10, 17, 10, 13, 18, 18, 18, 18, 13, 10, 17, 12, 18, 18, 13, 10, 12, 11, 11, 17, 11, 17, 12, 18, 10, 16, 17,...
$ Urban <fct> Yes, Yes, Yes, Yes, Yes, No, Yes, Yes, No, No, No, Yes, Yes, Yes, Yes, No, Yes, Yes, No, Yes, Yes, No, Yes, Yes, Yes, No, No, Yes, Yes, Yes...
$ US <fct> Yes, Yes, Yes, Yes, No, Yes, No, Yes, No, Yes, Yes, Yes, No, Yes, Yes, No, No, Yes, Yes, Yes, Yes, Yes, No, No, Yes, No, Yes, No, Yes, Yes,...
> summary(Carseats)
Sales CompPrice Income Advertising Population Price ShelveLoc Age Education Urban US
Min. : 0.000 Min. : 77 Min. : 21.00 Min. : 0.000 Min. : 10.0 Min. : 24.0 Bad : 96 Min. :25.00 Min. :10.0 No :118 No :142
1st Qu.: 5.390 1st Qu.:115 1st Qu.: 42.75 1st Qu.: 0.000 1st Qu.:139.0 1st Qu.:100.0 Good : 85 1st Qu.:39.75 1st Qu.:12.0 Yes:282 Yes:258
Median : 7.490 Median :125 Median : 69.00 Median : 5.000 Median :272.0 Median :117.0 Medium:219 Median :54.50 Median :14.0
Mean : 7.496 Mean :125 Mean : 68.66 Mean : 6.635 Mean :264.8 Mean :115.8 Mean :53.32 Mean :13.9
3rd Qu.: 9.320 3rd Qu.:135 3rd Qu.: 91.00 3rd Qu.:12.000 3rd Qu.:398.5 3rd Qu.:131.0 3rd Qu.:66.00 3rd Qu.:16.0
Max. :16.270 Max. :175 Max. :120.00 Max. :29.000 Max. :509.0 Max. :191.0 Max. :80.00 Max. :18.0
# dlookr 패키지를 사용하여, 제가 확인하고 싶은 1) 결측치 여부 2) 범주형 Levels 중 가장 높은 선택지 3) 이상치 정도 4) 수치형 변수들의 기초통계량 을 진단해 보았습니다.
# 결측치는 없습니다. 실제 데이터는 아니어서..
> dlookr::diagnose(Carseats) %>%
+ dplyr::filter(missing_count > 0)
# A tibble: 0 x 6
# ... with 6 variables: variables <chr>, types <chr>, missing_count <int>, missing_percent <dbl>, unique_count <int>, unique_rate <dbl>
# ShelveLoc은 Medium이, Urban과 US는 모두 Yes의 비율이 높습니다.
> dlookr::diagnose_category(Carseats) %>%
+ dplyr::filter(rank == 1)
# A tibble: 3 x 6
variables levels N freq ratio rank
<chr> <fct> <int> <int> <dbl> <int>
1 ShelveLoc Medium 400 219 54.8 1
2 Urban Yes 400 282 70.5 1
3 US Yes 400 258 64.5 1
# 이상치의 평균대비 전체 평균을 비교하여 새로운 변수를 만들고 비율이 가장 높은 순으로 확인했습니다.
# 이상치가 가장 큰 Sales에 대해서만 outlier plot을 만들어 보겠습니다.
> dlookr::diagnose_outlier(Carseats) %>%
+ dplyr::mutate(outliers = outliers_mean / with_mean) %>%
+ dplyr::arrange(desc(outliers))
variables outliers_cnt outliers_ratio outliers_mean with_mean without_mean outliers
1 Sales 2 0.50 15.95 7.496325 7.453844 2.1277092
2 CompPrice 2 0.50 126.00 124.975000 124.969849 1.0082016
3 Price 5 1.25 100.40 115.795000 115.989873 0.8670495
4 Income 0 0.00 NaN 68.657500 68.657500 NaN
5 Advertising 0 0.00 NaN 6.635000 6.635000 NaN
6 Population 0 0.00 NaN 264.840000 264.840000 NaN
7 Age 0 0.00 NaN 53.322500 53.322500 NaN
8 Education 0 0.00 NaN 13.900000 13.900000 NaN
# 🌷🌷🌷 이상치의 시각화
# 해당 데이터는 이상치 정도가 낮은 것으로 보입니다.
> dlookr::plot_outlier(Carseats, Sales)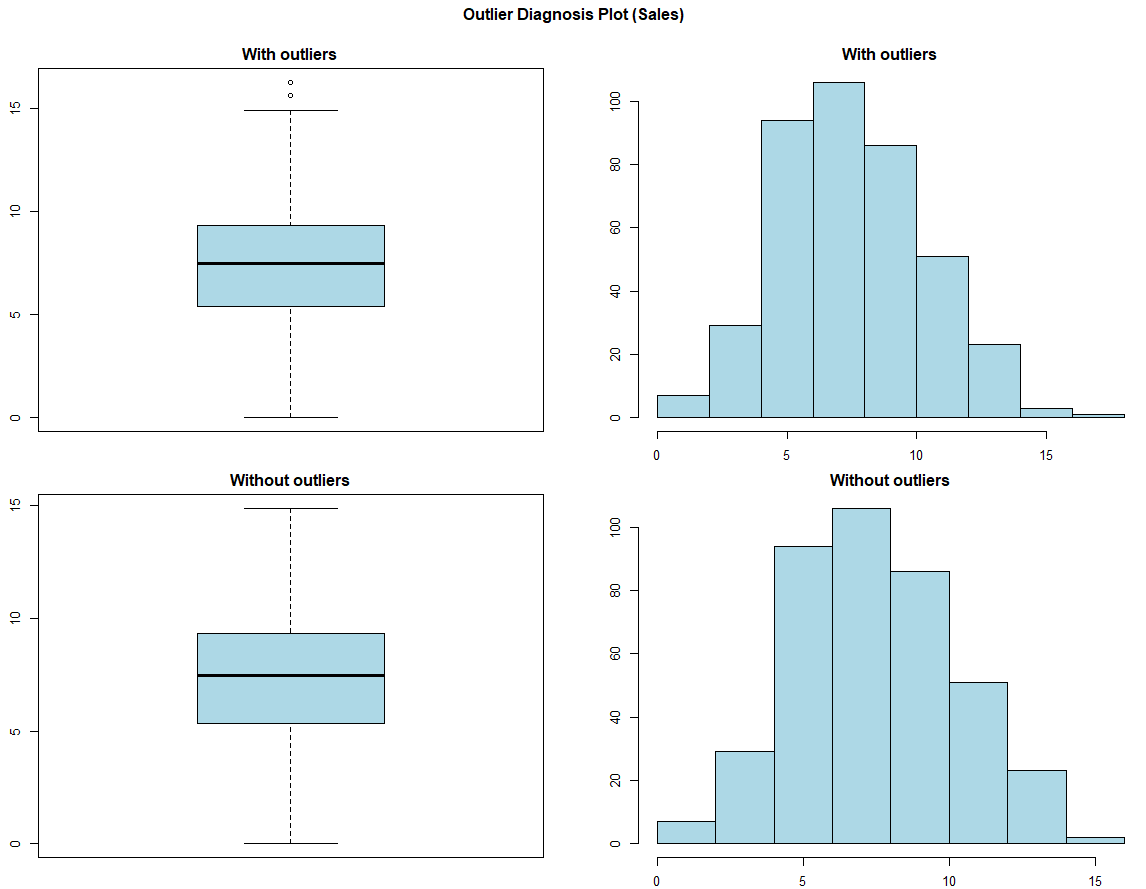
# 그럼 각 수치형 변수에 대해 정규성 검정을 하고, 정규성이 아닌(P value 0.05 이하) 것에 대해 확인해보겠습니다.
# 결과는 정규성 검정의 시각화를 위해 ntest 라는 객체에 저장하였습니다.
> Carseats %>%
+ dlookr::normality() %>%
+ dplyr::filter(p_value <= 0.05) %>%
+ dplyr::arrange(p_value) -> ntest
# A tibble: 5 x 4
vars statistic p_value sample
<chr> <dbl> <dbl> <dbl>
1 Advertising 0.874 1.49e-17 400
2 Education 0.924 2.43e-13 400
3 Population 0.952 4.08e-10 400
4 Age 0.957 1.86e- 9 400
5 Income 0.961 8.40e- 9 400
> ntest$vars
[1] "Advertising" "Education" "Population" "Age" "Income"
# 만약 확인해야 할 변수가 많다면, 하나하나 타이핑하기보다 저장된 객체의 vars 열을 불러 오는 것이 효율적이겠지요.
> dlookr::plot_normality(Carseats, ntest$vars)
# 🌷🌷🌷정규성 검정의 시각화
# 그래프는 Advertising에 대해서만 가지고 왔습니다.
# 아래와 같이 원 데이터, QQ플랏, log와 루트를 활용해 데이터를 변환해준 내역이 나옵니다.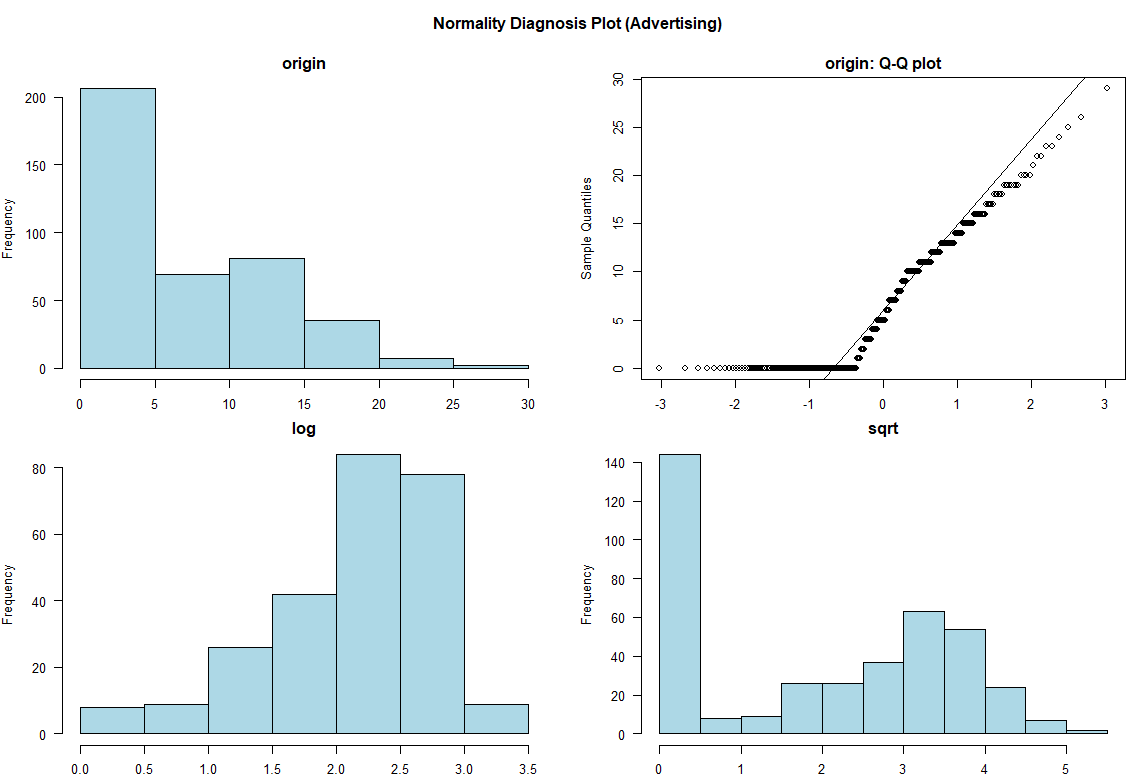
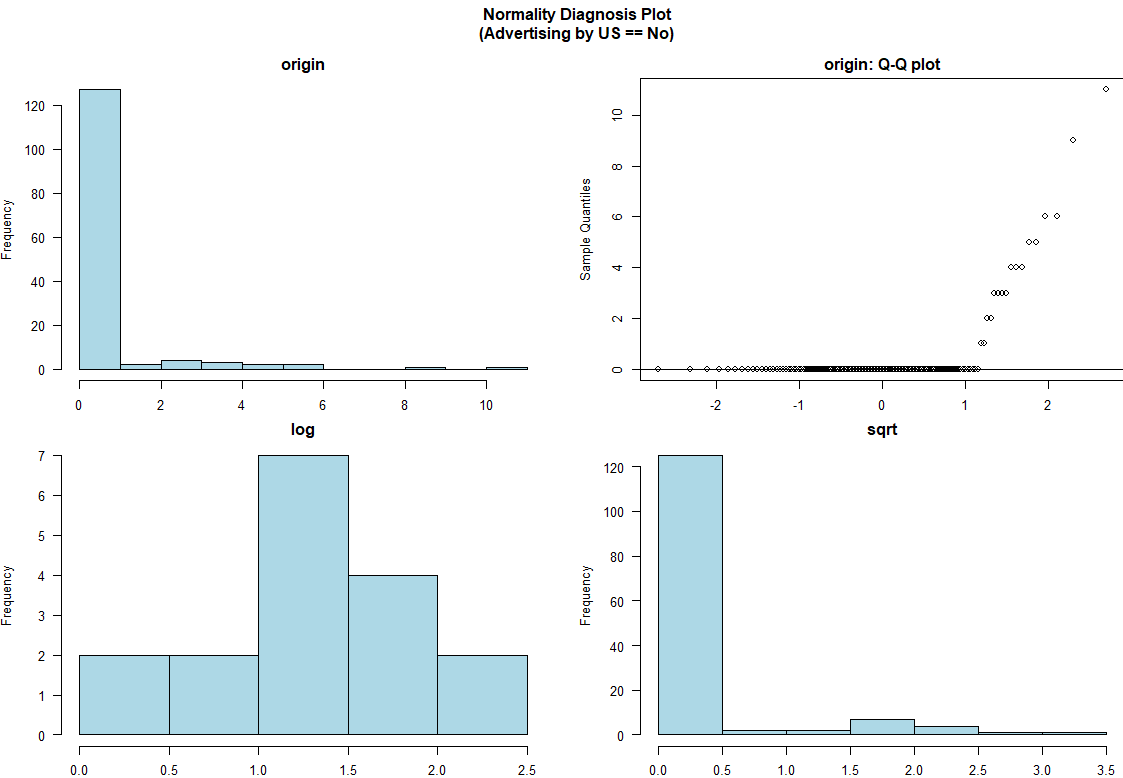
# dplyr의 group_by()함수를 받아주기 때문에 범주형 변수 기준으로 분리하여 시각화도 가능합니다.
> Carseats %>%
+ dplyr::group_by(US) %>%
+ dlookr::plot_normality(Advertising)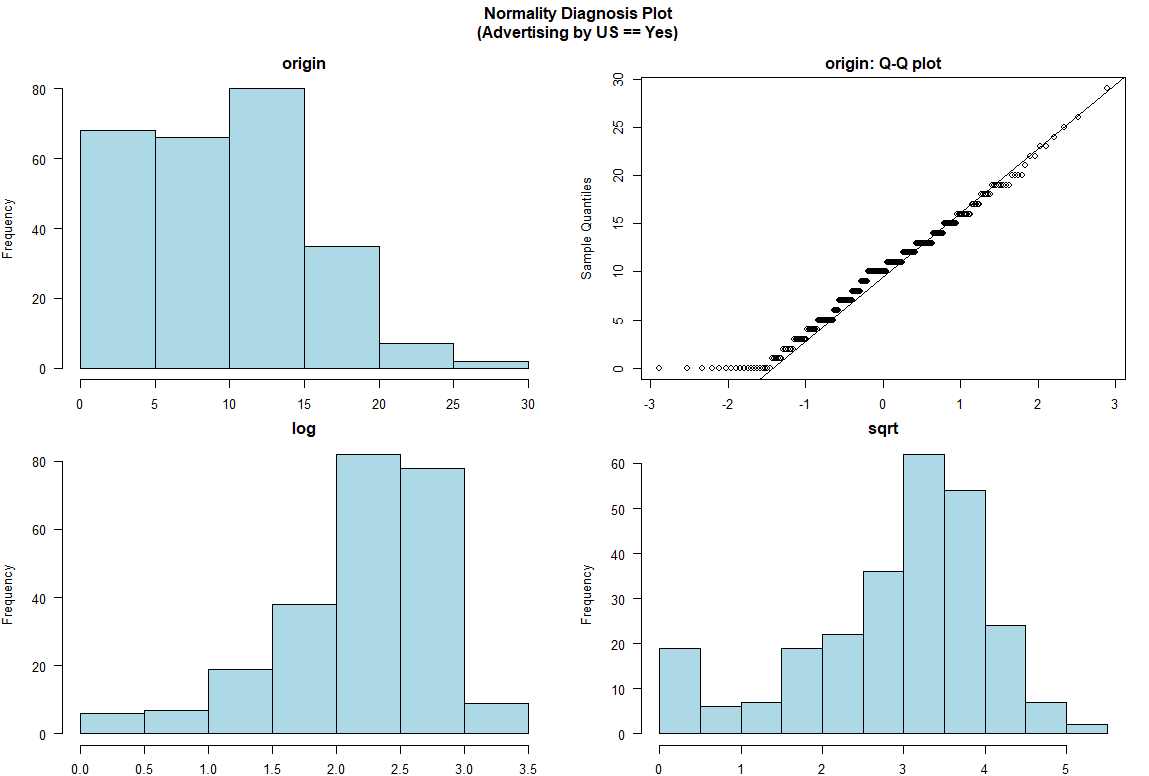
# 이제 각 변수간 상관도가 있는지 궁금합니다.
> Carseats %>%
+ dlookr::correlate() %>%
+ dplyr::filter(as.integer(var1) > as.integer(var2) & abs(coef_corr) >= 0.2) %>%
+ dplyr::arrange(desc(abs(coef_corr)))
# A tibble: 5 x 3
var1 var2 coef_corr
<fct> <fct> <dbl>
1 Price CompPrice 0.585
2 Price Sales -0.445
3 Advertising Sales 0.270
4 Population Advertising 0.266
5 Age Sales -0.232
# 그럼 범주형 변수도 더미변수로 변환하여 상관도가 있는지 확인해봅니다.
# 더미변수 만들기
> carseats %>%
+ dlookr::correlate() %>%
+ dplyr::filter(as.integer(var1) > as.integer(var2) & abs(coef_corr) >= 0.2) %>%
+ dplyr::arrange(desc(abs(coef_corr)))
# A tibble: 7 x 3
var1 var2 coef_corr
<fct> <fct> <dbl>
1 us_D Advertising 0.684
2 Price CompPrice 0.585
3 Price Sales -0.445
4 shelve_D Sales -0.393
5 Advertising Sales 0.270
6 Population Advertising 0.266
7 Age Sales -0.232
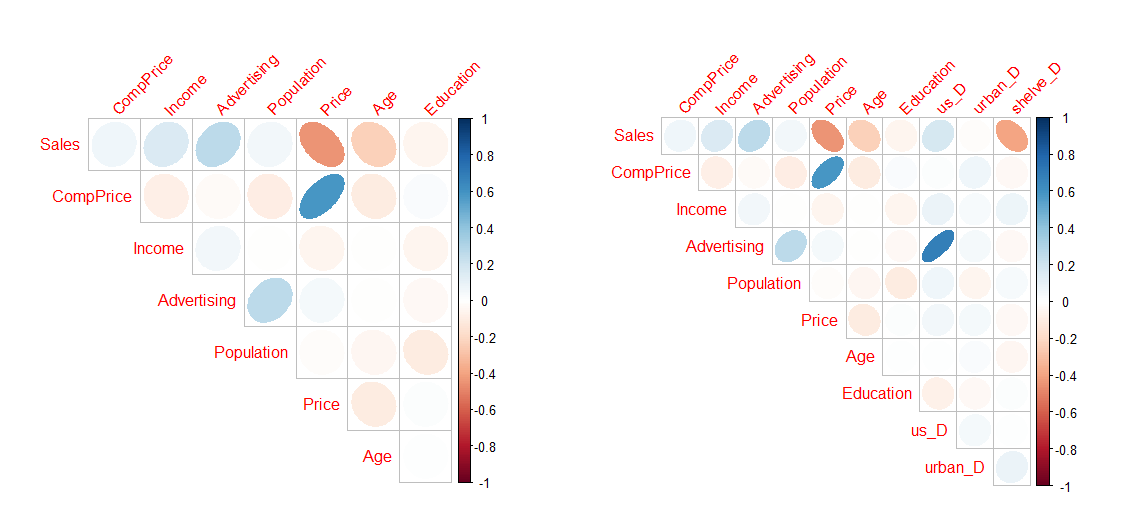
# 🌷🌷🌷 상관행렬의 시각화
# 더미변수가 없는 버전과 있는 버전 모두 상관행렬을 돌려 보았습니다.
par(mfrow = c(1, 2)) # R에서 한 화면에 그래프 표현 가능한 수 를 조정할 수 있는 함수입니다.
plot_correlate(Carseats)
plot_correlate(carseats)
# 상관행렬의 시각화도 dplyr의 group_by()를 받기 때문에 범주형 변수의 레벨에 따른 상관그래프를 확인할 수 있습니다.
par(mfrow = c(2,2))
Carseats %>%
dplyr::group_by(US, Urban) %>%
dlookr::plot_correlate()
Carseats %>%
dplyr::group_by(US) %>%
dlookr::plot_correlate()
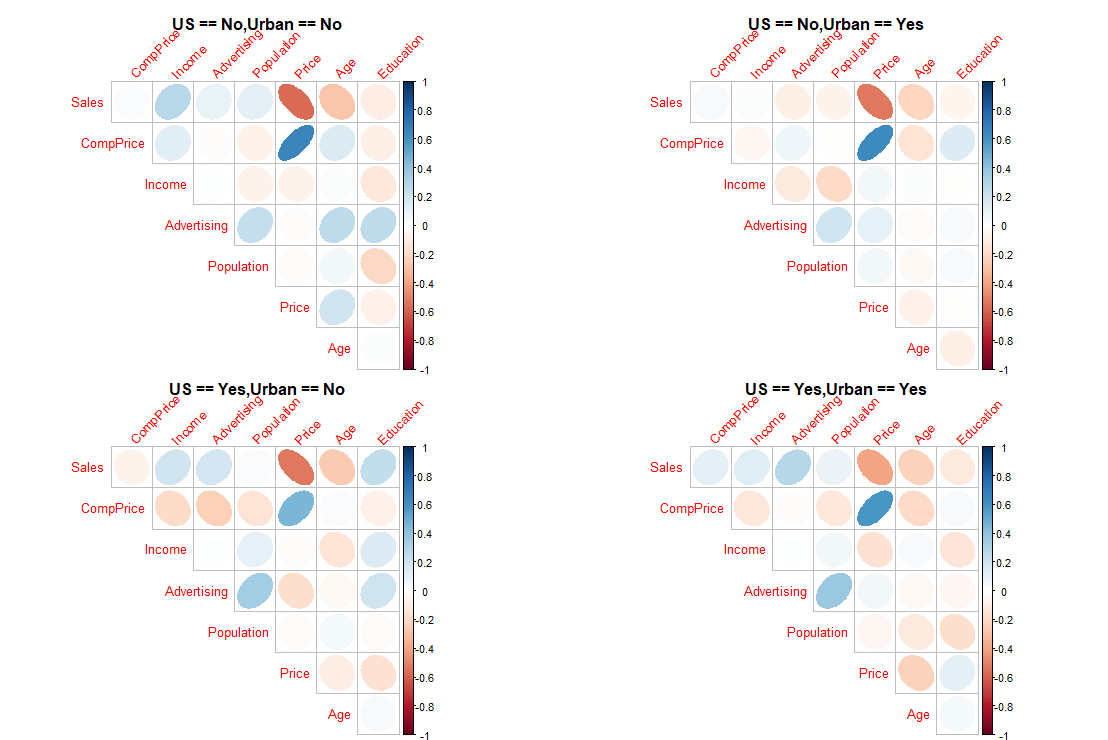
Carseats %>%
dplyr::group_by(Urban) %>%
dlookr::plot_correlate()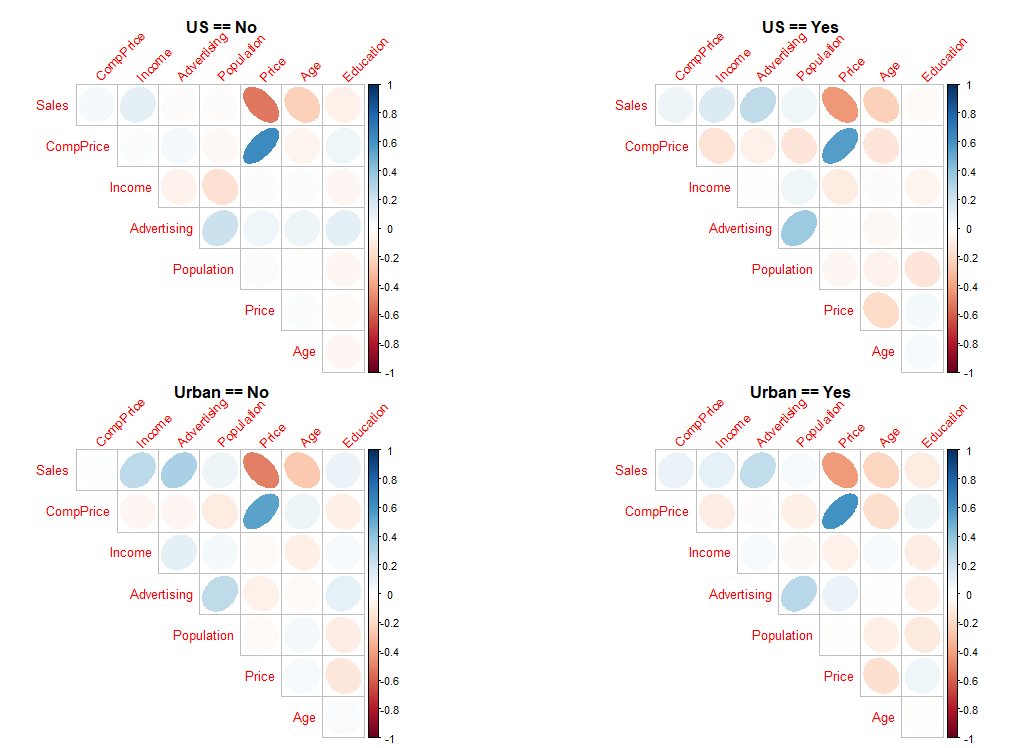
# 그럼 변수간의 비교를 시각화 해보겠습니다.
# 위 상관행렬의 시각화를 보고 아래의 변수들을 비교해 보려 합니다.
# 1) 범주형 변수와 범주형 변수 - US & ShelveLoc / Urban & ShelveLoc
# 2) 범주형 변수와 수치형 변수 - ShelveLoc & Sales / US & Advertising / US & Sales
# 3) 수치형 변수와 수치형 변수 - Price & Sales / Advertising & Sales
# 변수간 비교를 위해서는 (1) dlookr 패키지의 target_by() 함수를 통해 타겟변수를 지정하여야 합니다.
# (2) dlookr의 relate() 함수로 타겟변수와 예측변수의 비교를 구합니다.
# (3) 그리고 plot() 함수로 시각화가 가능합니다.
# 🌷🌷🌷 두 변수 간 비교 시각화
# 🌷🌷 범주형 변수와 범주형 변수 ==> 모자이크 플롯으로 그래프 산출
# ShelveLoc x US
> Carseats %>%
+ dlookr::target_by(ShelveLoc) %>%
+ dlookr::relate(US) %>%
+ plot()
# ShelveLoc x Urban
> Carseats %>%
+ dlookr::target_by(ShelveLoc) %>%
+ dlookr::relate(Urban) %>%
+ plot()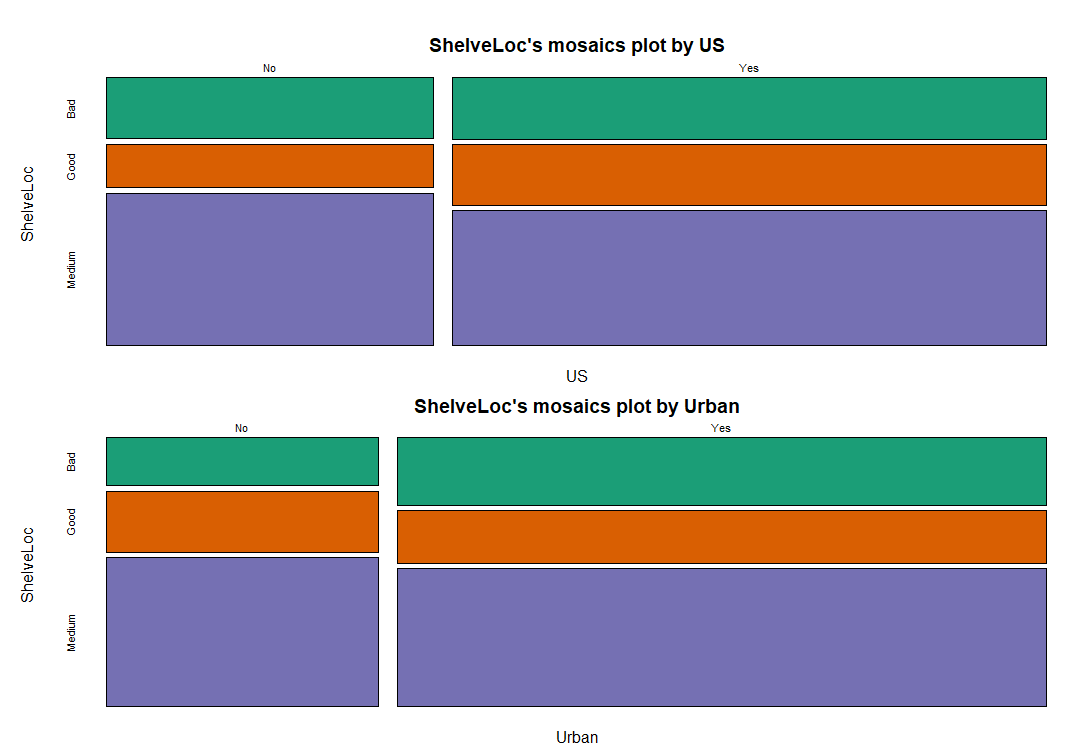
# 🌷🌷 범주형 변수와 수치형 변수 ==> 밀도 플롯으로 그래프 산출
# ShelveLoc x Sales
> Carseats %>%
+ dlookr::target_by(ShelveLoc) %>%
+ dlookr::relate(Sales) %>%
+ plot()
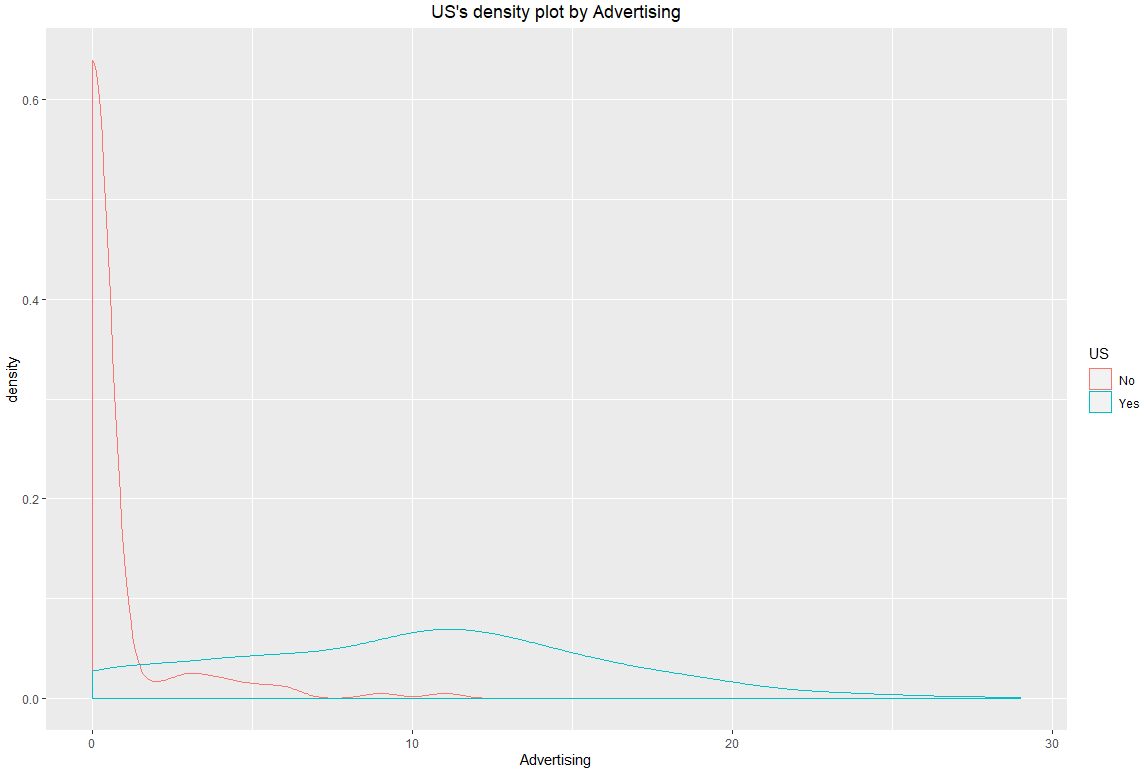
# US X Advertising
> Carseats %>%
+ dlookr::target_by(US) %>%
+ dlookr::relate(Advertising) %>%
+ plot()
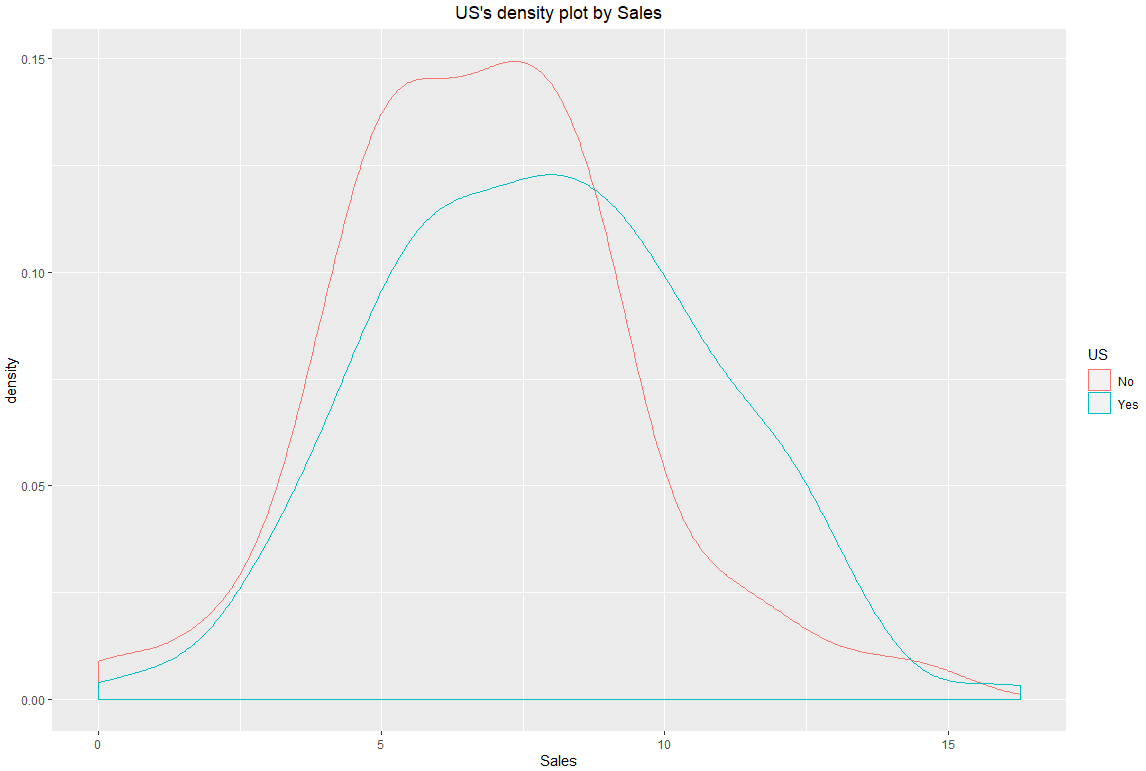
# US X Sales
> Carseats %>%
+ dlookr::target_by(US) %>%
+ dlookr::relate(Sales) %>%
+ plot()
# 참고로, 타겟변수를 범주형으로 하고 예측변수를 수치형으로 하면 아래와 같이 밀도 플롯이 산출되나
# 반대로 타겟을 수치형, 예측을 범주형으로 할 시 박스플랫오르 그래프가 나옵니다.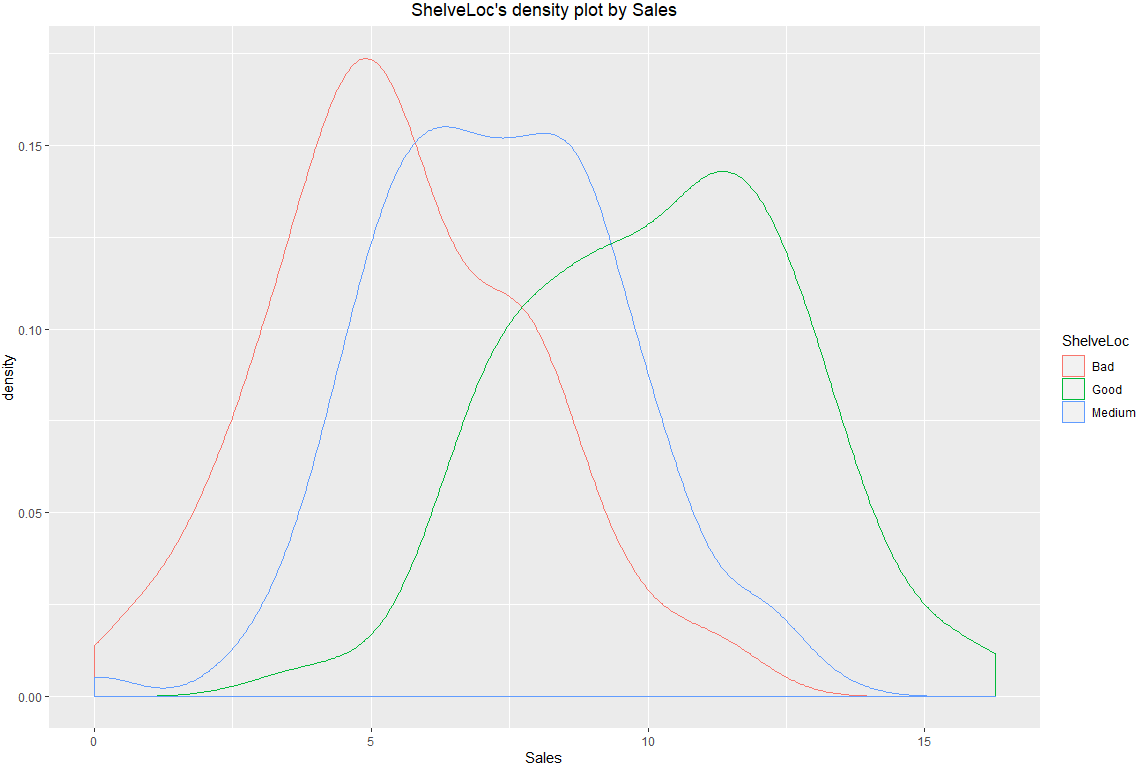
# 🌷🌷 수치형 변수와 수치형 변수 ==> 산점도 그래프 산출
# Price & Sales
> Carseats %>%
+ dlookr::target_by(Sales) %>%
+ dlookr::relate(Price) %>%
+ plot()
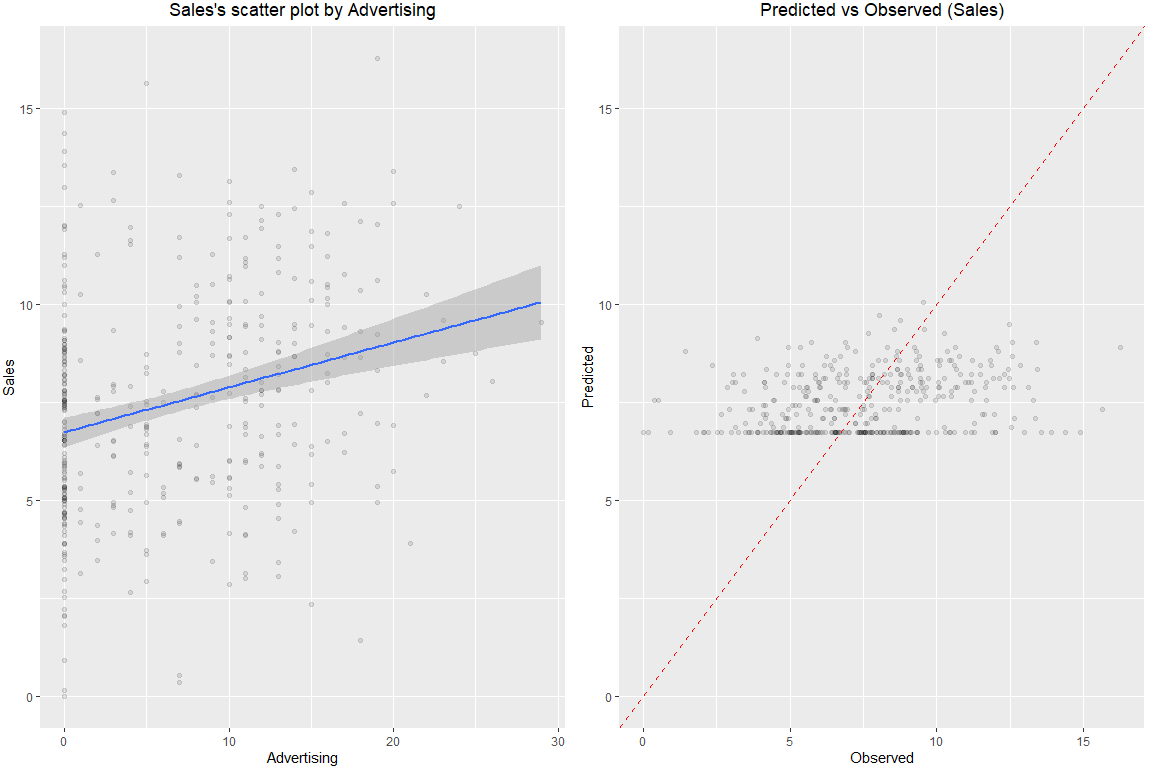
# Advertising & Sales
> Carseats %>%
+ dlookr::target_by(Sales) %>%
+ dlookr::relate(Advertising) %>%
+ plot()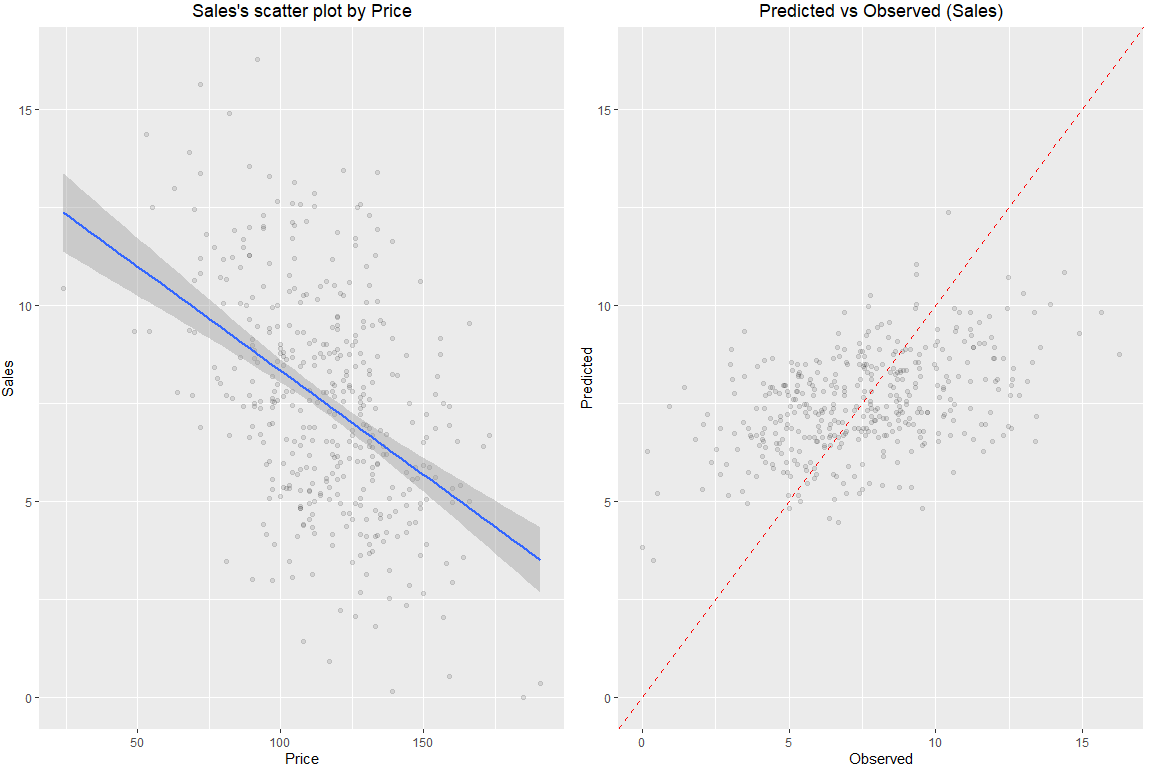
리포트 추출
dlookr은 위 시각화를 한번에 리포트 형태로 추출할 수 있는 기능을 제공합니다. 😊 단시간에 데이터 파악이 필요하다면 매우 유용하게 사용할 수 있습니다! 리포트를 html로 바로 오픈하는 것은 물론, html 혹은 pdf로 다운로드도 가능합니다. => 다운로드 받으려면 dir을 지정해주면 됩니다~~!
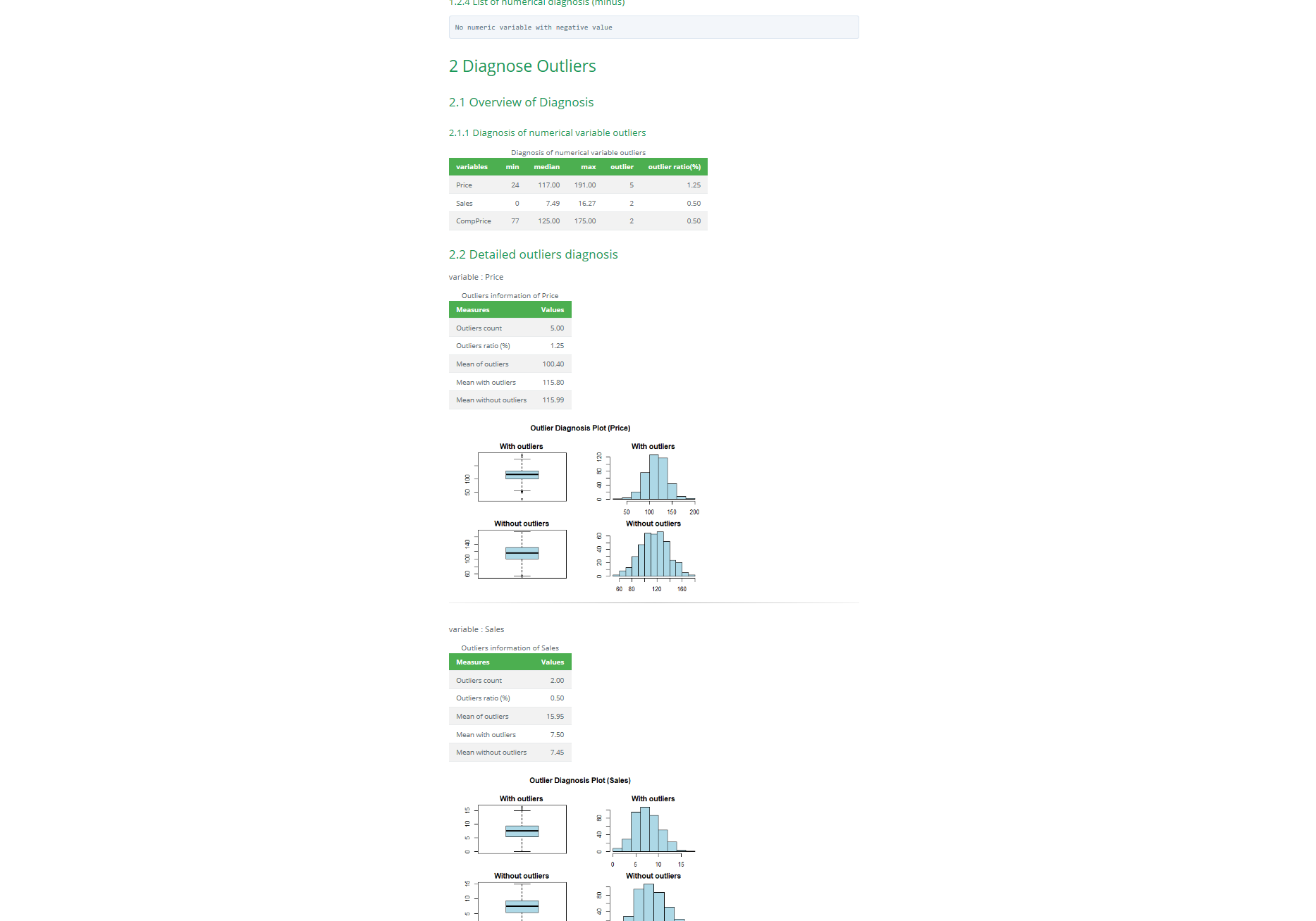
🌼 진단 리포트 추출 : `diagnose_report()`
> dlookr::diagnose_report(Carseats, output_format = "html")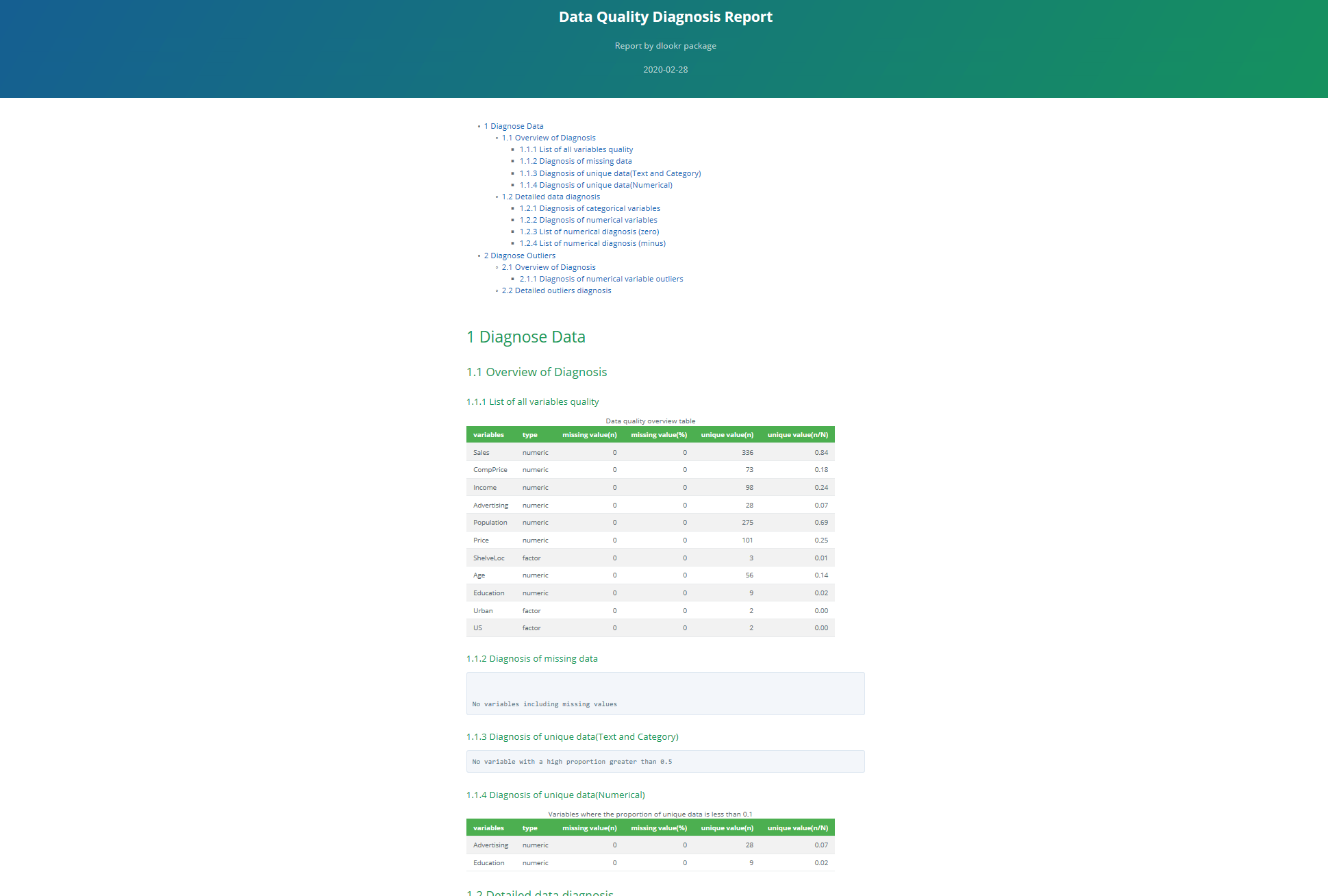
🌼 EDA 리포트 추출 : `eda_report()`
> dlookr::eda_report(Carseats, target = Sales, output_format = "html")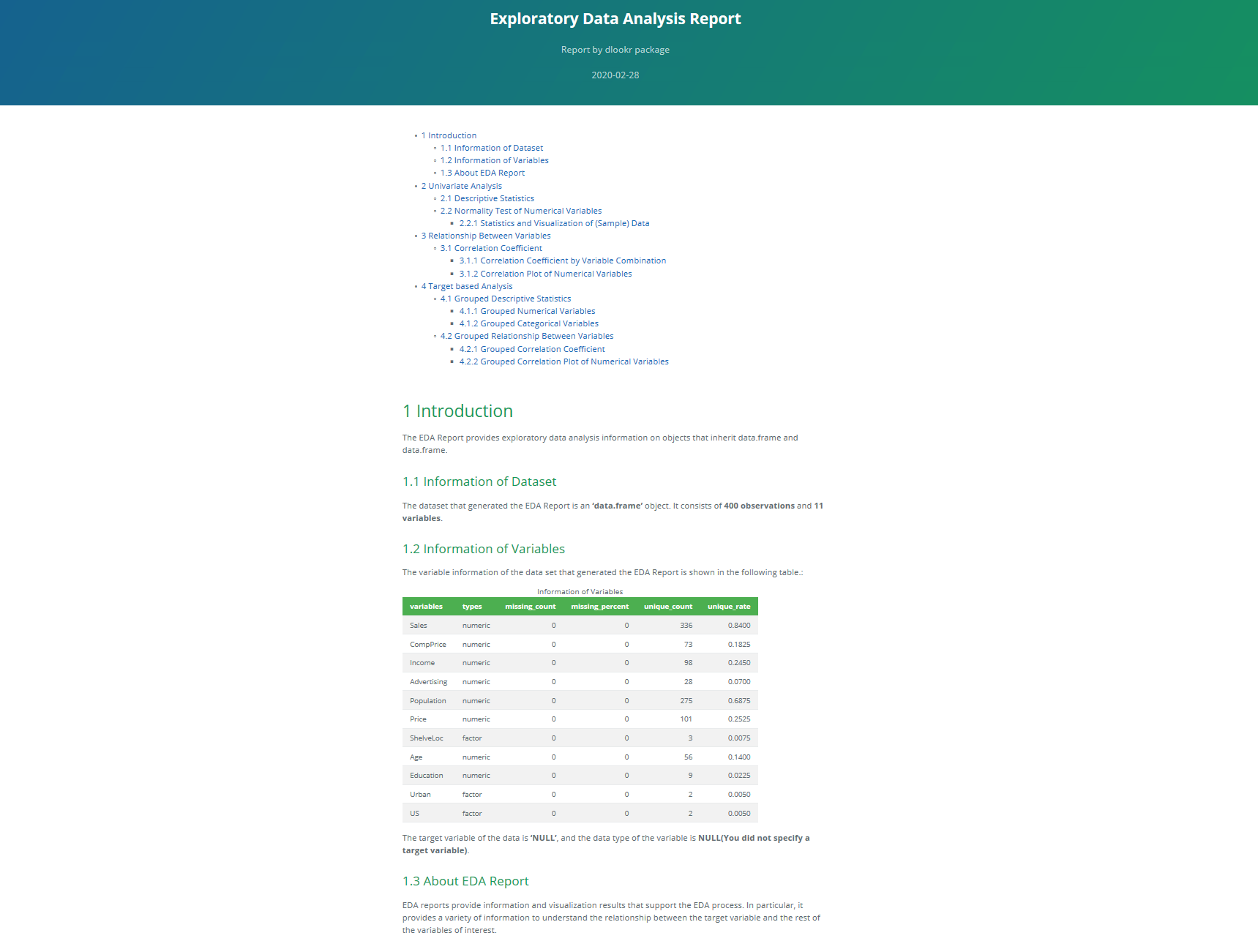
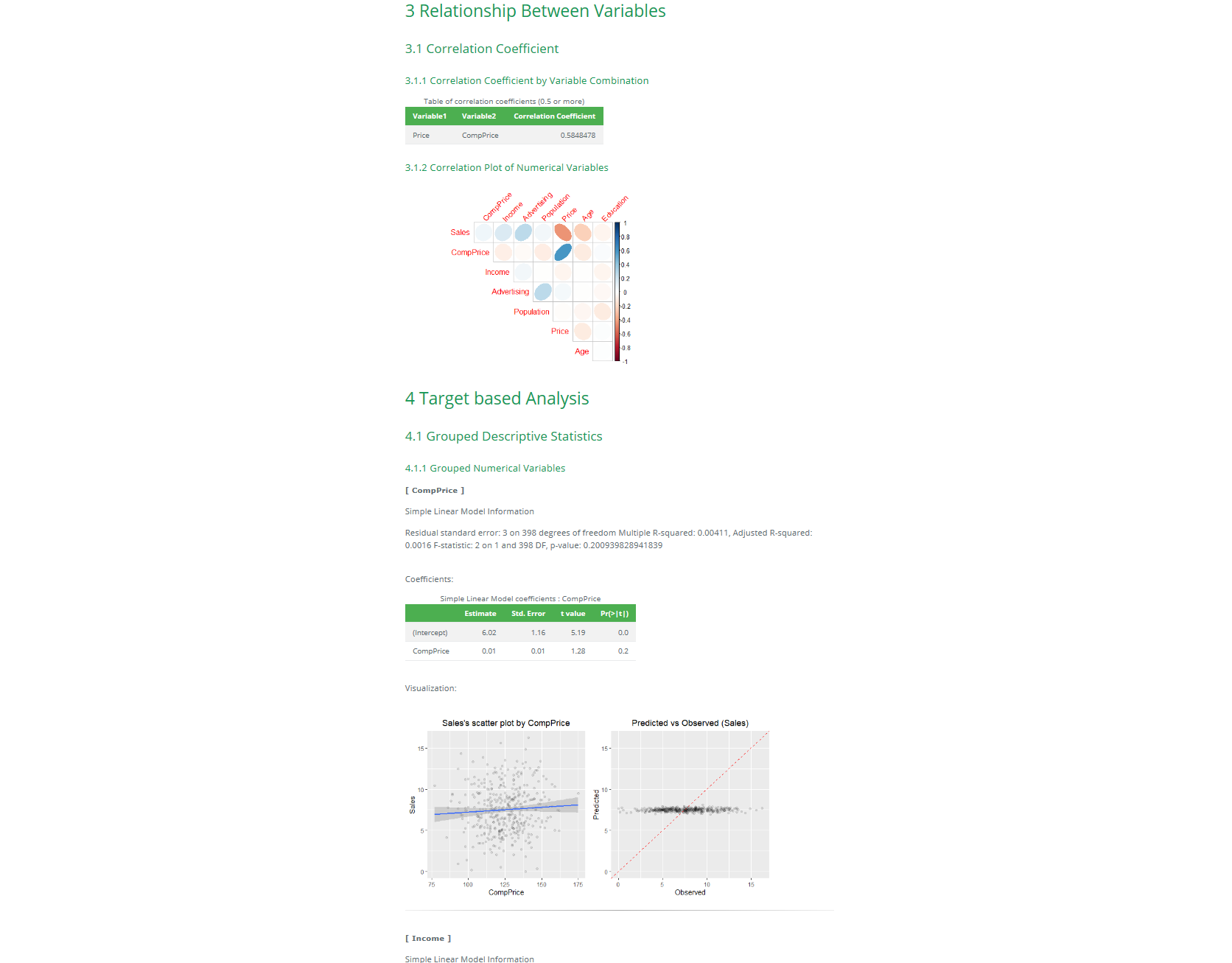
🌼 데이터 변환 리포트 추출 : `transformation_report()`
> dlookr::transformation_report(Carseats, output_format = "html")
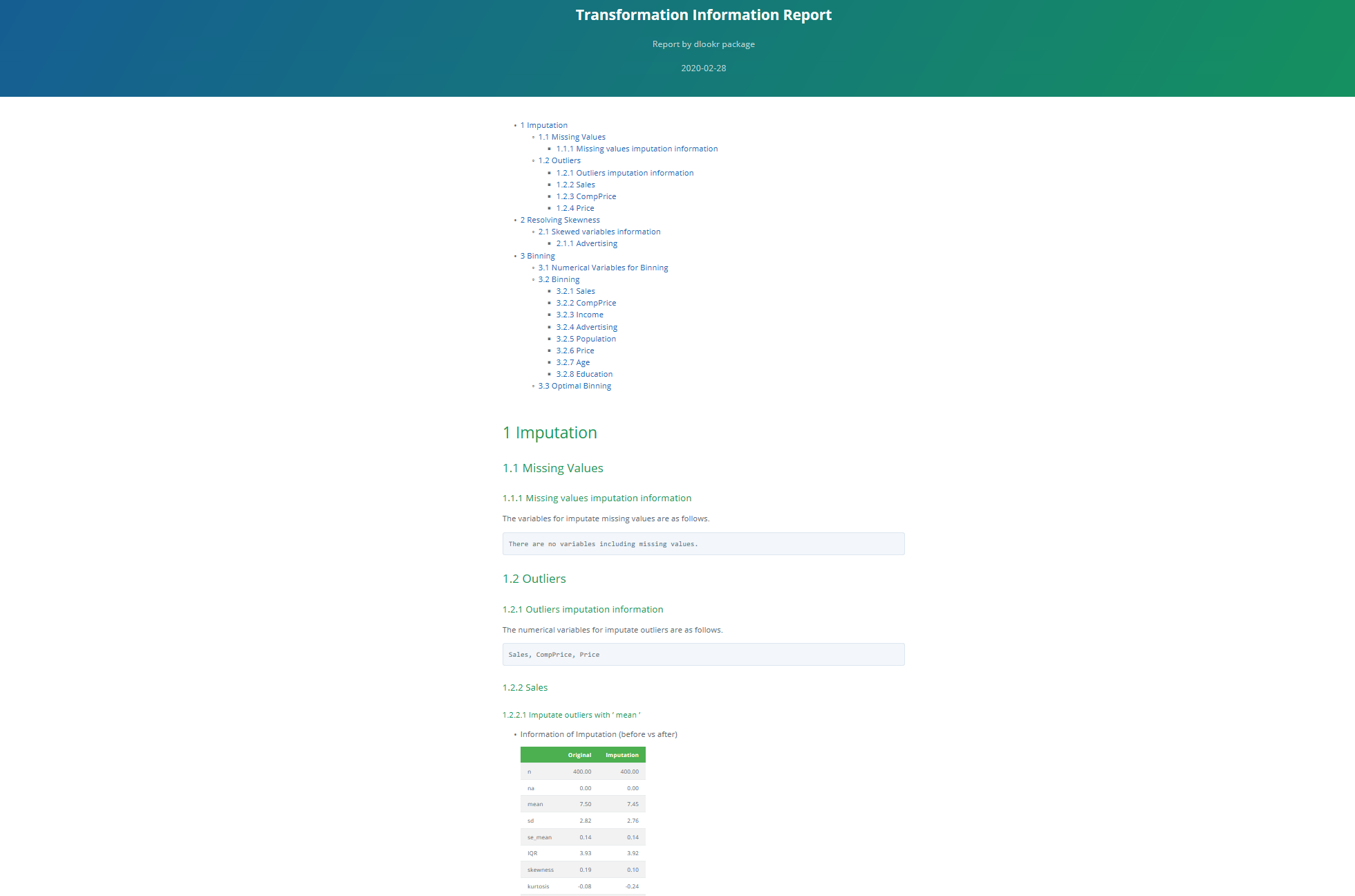
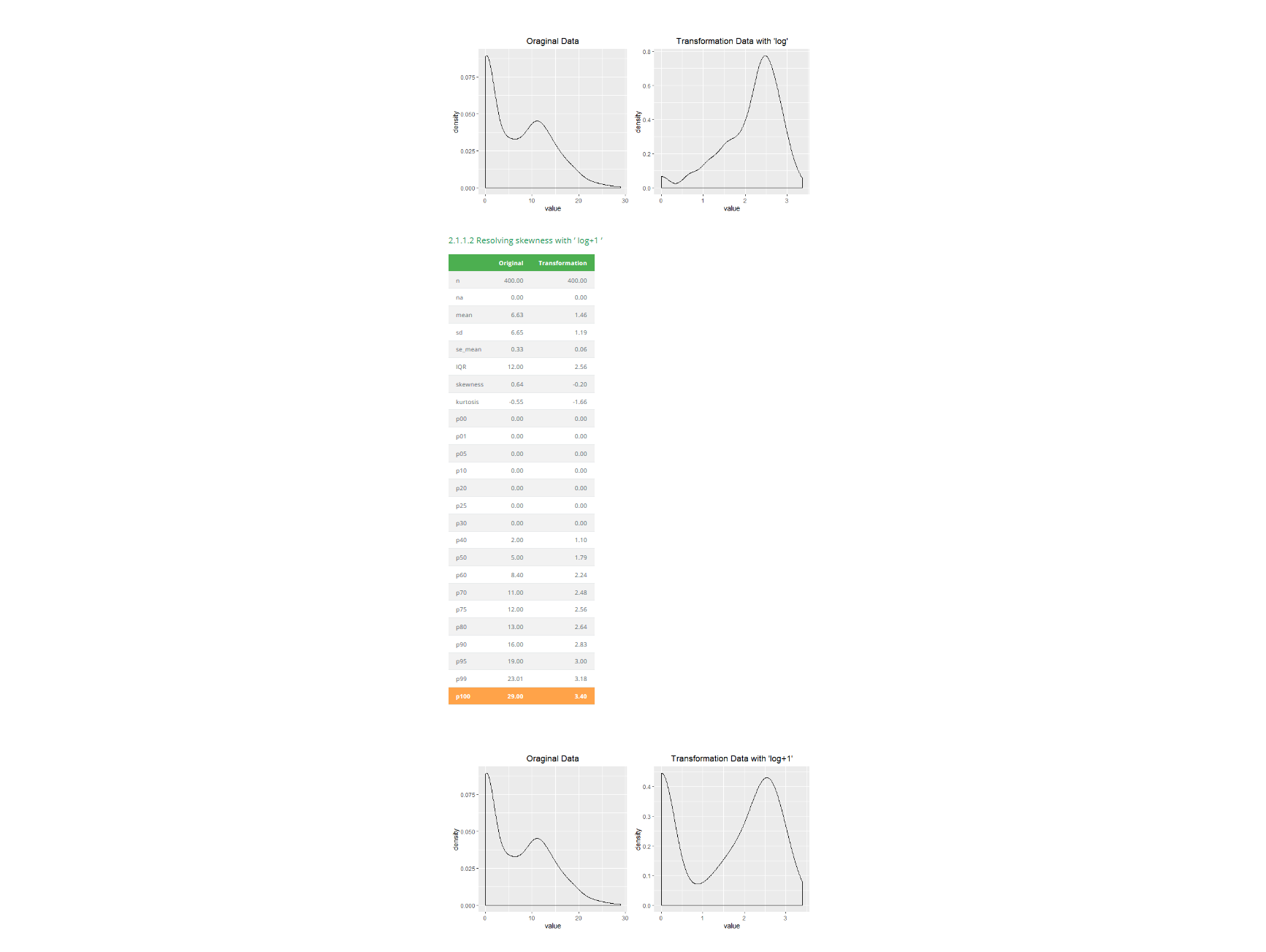
마무리
데이터에 대해 EDA 자체가 목적일 때도 있고, 혹은 그 이상의 결과물이 목적이더라도(회귀 분석, 머신러닝, 텍스트마이닝 등등) EDA는 데이터 이해를 위해 꼭 해야하는 과정입니다. 데이터 탐색 부분에서 dlookr 패키지를 처음 접하고 매우 유용하게 사용할 수 있을듯 하여 실습까지 완료해보았습니다 :-) 🌷🌼
