
안녕하세요👏👏👏 지난 포스팅(> R로 크롤링 하기)에서 크롤링 해온 코로나 19에 대한 네이버 블로그 글을 가지고 워드 크라우드를 만들어 보겠습니다.
사실 처음 만들어본거라 많이 미흡합니다🤣 (원래 사전을 만들거나 받아와야 하는데 사전도 만들지 않았고요..) 무튼 무작정 만들어 본 이번 포스팅을 계기로, 사용한 패키지들을 더 자세히 공부해봐야겠습니다.
패키지 라이브러리 🧠
본 작업을 위해 많은 패키지 라이브러리가 필요했습니다. 워드클라우드 뿐만 아니라 상위 단어에 대해 바 그래프를 만들어 보려 합니다.
> library(tidyverse) # 데이터 전처리(stringr)와 그래프(ggplot2)
> library(rJava) # 아래 NLP4kec 사용을 위해 필요
> library(NLP4kec) # 자연어 처리
> library(tm) # 말뭉치 생성, 말뭉치 전처리, DTM 생성
> library(RWeka) # N-gram 생성
> library(wordcloud2) # 워드클라우드
> library(RColorBrewer) # 그래프 색상데이터 처리 ✍
데이터 전처리
> load("Nblog.R") # 블로그 글 크롤링한 파일 불러오기
# 전처리가 필요한 내용은 무엇이 있을까?
# NA는 없음. 이미 이전에 처리해주었기 때문
> is.na(Nblog) %>% sum()
[1] 0
# 중복값 없음
> duplicated(Nblog) %>% sum()
[1] 0
# 한 블로그 콘텐츠별 글자수 최소는 531자, 최대는 18708자
> Nblog$contents %>%
+ nchar() %>%
+ range()
[1] 531 18708
# 글자수가 너무 적거나 큰 게시물은 필터링을 하기 위해 그래프로 시각화 하였다.
# 18708인 최대 글자수 게시물만 완전 위에 있었다
> Nblog$contents %>%
+ nchar() %>%
+ boxplot()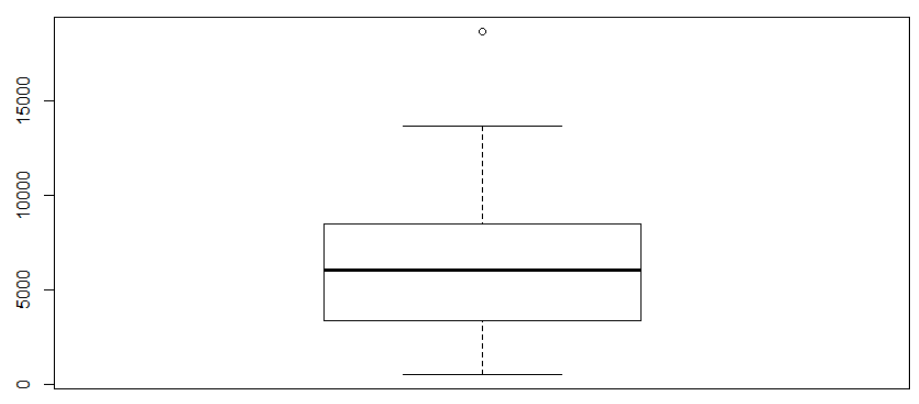
# 왠지 공식 블로그일 것 같아서, 찾아보니 진짜 안산블로그 공식 싸이트여서 삭제하기로 함
# 네이버 블로그 글에는 공식 블로그나 광고가 많아 다른 것들도 대충 보고 전처리 해주어야 하지만... 시간관계상 그러진 못했다
> dplyr::filter(Nblog, nchar(contents) > 18000) %>%
+ dplyr::select(url)
url
1 http://blog.naver.com/PostView.nhn?blogId=cityansan&logNo=221824314139
# 그럼, 데이터 전처리를 해볼까?
# 15000자 이하의 블로그 글만 남겼다. (=> 위 안산시 공식 블로그 제거)
> Nblog %>%
+ dplyr::filter(nchar(contents) < 15000) -> Nblog
# 한글을 제외한 모든 글자는 삭제처리 했다
> Nblog$contents <- Nblog$contents %>%
+ stringr::str_remove_all(pattern = "[^가-힣]")
# 한글을 제외한 모든 글자를 삭제하여, 아래와 같이 데이터가 변경되었다
Nblog$contents[1]
[1] "우한코로나확진자봉쇄령뚫고베이징이동상하이저널중국정부가코로나발원지인우한과후베이성을봉쇄하며초강력방역에나선가운데우한확진자가베이징으로이동한것으로알려져논란이일고있습니다월일후베이일보에따르면지난일부터인후통을동반한간헐적발열증세를보인황씨는거주지우한에서일새벽베이징으로이동했습니다베이징에거주하는가족이자가용으로황씨를데리고온것입니다발열이계속된황씨는결국일코로나확진판정을받았습니다베이징당국은황씨가어떤경로로검역을뚫고이동을할수있었는지철저히조사하겠다고밝혔습니다소식이알려지자누리꾼들은방역에구멍이뚫린것이아니냐며모든정보를투명하게공개해달라고요청했습니다여성코로나치료제무더기로삼켰다가목숨잃을뻔북만신시각망스스로코로나에감염됐다고판단한한중국여성이치료약물을무더기로삼키는일이발생했습니다일북만신시각망에따르면우한에살고있는이여성은스스로인터넷에서코로나치료에효과가있다고알려진약품을구입해복용했습니다이여성은하루개의약을먹은뒤정신이상증세를보여병원으로긴급이송돼치료를받고있습니다검사결과여성은코로나에감염되지않은상태였고가족역시음성판정을받았습니다지난일안후이성에서는자신이코로나에감염됐다고생각한여성이호수에뛰어들어자살하려다경찰에의해구조되기도했습니다상하이시대구경북에마스크만개기증상하이저널상하이시정부가한국의대구와경북지역에마스크만개를기증했습니다중국지방정부가한국에코로나방역물자를지원한것은이번이처음입니다일환구망에따르면일상하이시는한국주상하이총영사관에의료용마스크만개와마스크만개를전달했습니다코로나지역전파가집중적으로일어나고있는한국대구경북지역에보내기위해서입니다상하이시관계자는양국의우정을위해상하이시정부는한국대구시경상북도등지역에방역용품을긴급제공하기로결정했다고말했습니다한편이날중국주한대사관도대구시에만개의의료용마스크를지원했습니다중난산코로나월말기본적으로통제될듯인민일보웨이보중난산중국공정원원사가월말이면코로나사태가기본적으로통제될것이라는전망을내놓았습니다일광저우성언론브리핑에서중난산원사는연구팀이수학적모형에두가지요소국가차원의강력한조치와춘절이후인파유동피크를추가해얻어낸예측결과월중순이나월말에정점을찍을것으로예상한바있는데실제로월일그래프가꺾였다고말했습니다이어코로나사태가월말쯤이면기본적으로통제될것이라내다봤습니다상하이개인지하철탑승정보등록한다상하이저널상하이가대중교통을이용하는밀접접촉자추적을위해이제부터지하철을탑승하는고객들의탑승칸과휴대폰정보를수집합니다일동방망에따르면상하이지하철은일부터코드로정보등록을실시하고있습니다상하이지하철은각객실칸마다고유번호를부여해전용코드를부착해승객스스로코드스캔을통해자신의탑승정보를등록할수있도록했습니다상하이지하철은이번조치로확진자발생에따른밀접접촉자추적이용이해질것이라며승객의건강과안전한외출을위해더욱관리를강화하는차원의조치라고설명했습니다코로나방콕모바일게임시장급증중국경영보코로나로인한방콕이온라인게임사용자급증으로이어졌다고일중국경영보가보도했습니다감마데이터가발표한년월모바일게임보고서에따르면춘절기간게임상품의다운로드수는눈에띄게증가했습니다월초에비해게임다운로드수는늘었고사격게임은레이싱게임카드보드게임급증했습니다전반적으로올월모바일게임시장은지난해같은기간에비해전월대비증가했습니다코로나사태로게임라이브방송도급증하고있는추세입니다지난일왕저롱후이주최측은온라인으로대회를진행한다고발표했습니다선양모든입국자에대한코로나검사실시현대쾌보중국각공항의해외입국자에대한검역이강화되고있는가운데랴오닝성선양시에서도모든입국자에대한코로나검사를실시한다고발표했습니다일선양시신종코로나바이러스방역지휘센터는선양입국자에대한방역관련통지를통해이같이밝혔습니다해외에서선양으로입국하는사람중발열호흡기질환등의이상증상을보이면전문인력의인솔하에공항격리실에서관찰됩니다이때증상이계속될경우응급차로지정병원으로옮겨져검사및치료가진행됩니다별다른증상이없는경우에도지정구역으로옮겨져핵산검사를위한샘플을채취해야합니다이후상황에따라호텔격리자가격리기관격리등을일의격리관찰이진행됩니다글상하이저널상하이방상하이저널상하이방은중국상하이의최대한인교민지인상하이저널의웹사이트입니다"자연어 처리
# NLP4kec 패키지로 자연어처리를 해주었다
> data <- NLP4kec::r_parser_r(contentVector = Nblog$contents,
+ language = "ko")
Language : ko
Total Rows : 68
# 자연어 처리를 하면 데이터 형식은 문자형으로 되고,
> class(data)
[1] "character"
# 아래와 같이 자연어별로 단어가 분리된다
data[1]
[1] "우한 코로나 확진 봉쇄 령 뚫다 베이징 이동상 하이 저널 중국 정부 코로나 발원지 우한 후베이 봉쇄 강력 방역 나서다 가운데 우한 확진 베이징 이동 것 알리다 지다 논란 일다 있다 월일 후베이 일보 따르다 지나다 일 인후통 동반 간헐 발열 증세 보이다 황 씨 거주지 우한 새벽 베이징 이동 베이징 거주 가족 자가용 황 씨 데리다 오다 것 발열 계속 황 씨 결국 코로나 확진 판정 받다 베이징 당국 황 씨 경로 검역 뚫다 이동 하다 수 있다 조사 밝히다 소식 알리다 지다 누리 방역 구멍 뚫리다 것 정보 투명 공개 달다 요청 여성 코로나 치료제 무더기 삼키다 목숨 잃다 뻔 북만 신시 망 코로나 감염 판단 한 중국 여성 치료 약물 무더기 삼키다 일 발생 북 시각 망 따르다 우한 살다 있다 이여성 인터넷 코로나 치료 효과 있다 알리다 지다 약품 구입 복용 이여성 하루 약 먹다 뒤 정신 이상 증세 보이다 병원 긴급 이송 치료 받다 있다 검사 결과 여성 코로나 감염 않다 상태 가족 음성 판정 받다 지나다 일 안후이 자신 코로나 감염 생각 여성 호수 뛰어들다 자살 경찰 의하다 구조 하다 상하 대구경북 마스크 개기 증상 저널 상하 정부 한국 대구 경북 지역 마스크 기증 중국 지방 정부 한국 코로나 방역 물자 지원 것 이번 처음 일환 구망 따르다 일상 한국 주상 총영사관 의료 마스크 마스크 전달 코로나 지역 전파 집중 일어나다 있다 한국 대구경북 지역 보내다 위하다 상하 관계자 양국 우정 위하다 상하 정부 한국 대구시 경상북도 등 지역 방역 용품 긴급 제공 결정 말 한편 나다 중국주 대사관 대구시 의료 마스크 지원 중난산 코로나 월말 기본 통제 듯 인민일보 웨이보 중난산 중국 공정 원원 사 월말 코로나 사태 기본 통제 것 전망 내놓다 일광 저우 언론 브리핑 중난산 원사 연구 팀 수학 모형 요소 국가 차원 강력하다 조치 춘절 이후 인파 유동 피크 추가 얻다 내다 예측 결과 월 중순 월말 정점 찍다 것 예상 바 있다 월일 그래프 꺾이다 말 코로나 사태 월말 기본 통제 것 내다 보다 상하 하철 탑승 정보 등록 상하 저널 상하 이 대중교통 이용 밀접 접촉자 추적 위하다 이제 지하철 탑승 고객 탑승 칸 휴대폰 정보 수집 일동 방망 따르다 상하 지하철 일 코드 정보 등록 실시 있다 상하이 지하철 객실 칸 고유 번호 부여 전용 코드 부착 승객 코드 스캔 통하다 자신 탑승 정보 등록 수 있다 하다 상하이 지하철 이번 조치 확진 발생 따르다 밀접 접촉자 추적 용이하다 지다 것 승객 건강 안전 외출 위하다 관리 강화 차원 조치 설명 코로나 방콕 모바일게임 시장 급증 중 국경 영보 코로나 인하다 방콕 온라인 게임 사용자 급증 이어지다 일중 국경 영보 보도 감마 데이터 발표 월 모바일게임 보고서 따르다 춘절 기간 게임 상품 다운로드 수 눈 띄다 증가 월초 비하다 게임 로드 수 늘다 사격 게임 레이싱 게임 카드 보드게임 급증 전반 오다 월 모바일게임 시장 지난해 같다 기간 비하다 전월 대비 증가 코로나 사태 게임 라이브 방송 급증 있다 추세 지나다 일 왕저 롱 후 주최 측 온라인 대회 진행 발표 선양 입국 대하다 코로나 검사 실시 현대 쾌보 중국 공항 해외 입국 대하다 검역 강화 있다 가운데 랴오닝 성선 양시 입국 대하다 코로나 검사 실시 발표 일선 양시 신종 코로나 바이러스 방역 지휘 센터 선양 입국 대하다 방역 관련 통지 통하다 밝히다 해외 선양 입국 사람 중 발열 호흡기 질환 등 이상 증상 보이다 전문 인력 인솔 공항 격리실 관찰 이때 증상 계속 경우 응급차 지정 병원 옮기다 지다 검사 치료 진행 별다르다 증상 없다 경우 지정 구역 옮기다 지다 핵산 검사 위하다 샘플 채취 하다 이후 상황 따르다 호텔 격리 격리 기관 격리 등 일 격리 관찰 진행 글 상하 저널 상하이방 상하이 저널 상하이방 중국 상하이 최대한 교민 지인상 하이 저널 웹 사이트 "말뭉치 만들기와 말뭉치 전처리
말뭉치 만들기
# tm 패키지로 말뭉치로 만들어 주었다.
> data <- data %>% tm::VectorSource() %>% tm::VCorpus()
# 아래와 같이 데이터 형식이 바뀌어야 한다.
> class(data)
[1] "VCorpus" "Corpus"
> class(data[[1]])
[1] "PlainTextDocument" "TextDocument"말뭉치 전처리 👻
N gram은 1개 단어, 2개 단어, 3개 단어 로 해서 총 3개를 각각 만들 예정입니다. 이를 하나로 통합하는 사전을 만들어야 하지만, 본 작업에서는 사전을 만들지 않았기에 각각 만들었습니다.
이를 위해 아래의 것을 해주겠습니다.
- 불용어 단어 삭제 (출처 : 바로가기)
- 코로나 바이러스 관련 단어 삭제(키워드가 코로나 이므로 해당 단어가 당연히 가장 많을 것이니까)
- 혹시 필터링 되지 않았을까 해서 말뭉치도 전처리(스페이스, 숫자, ...)
참고로 불용어 삭제는 한번에 하지 않고 계속해서 빈도수가 높은 단어들을 봐가며 추가해주었습니다.. 데이터 전처리는 한번에 다 하기보다 계속해서 보충해주어야 합니다. 😢
# 다운로드 받은 한국 불용어 파일 불러오기
> dic <- read.table(file = "../data/한국어불용어100.txt",
+ sep = "\t",
+ fileEncoding = "UTF-8")
# 불러온 한국 불용어 파일에서 첫 번째 열(단어들)만 남기고 문자형으로 변환
> dic <- dic[ , 1] %>% as.character()
# 그 외 여러 용도로 제외할 문자 모음 만들기
# 위 불용어 파일에 없는 글자들을 수동으로 입력
> dic2 <- c("가지다", "걸리다", "그렇다", "나가다", "나오다", "나타나다", "늘어나다", "다녀오다", "다르다", "다양하다", "대하다", "돌보다", "드리다", "들어가다", "따르다", "떨어지다", "마시다", "못하다", "바라다", "보내다", "버리다", "밝히다", "보이다", "부탁드리다", "불가피하다", "알리다", "알아보다", "이기다", "위하다", "전하다", "지키다", "최대한", "지나다", "여러분", "인하다", "통하다", "있다", "하다", "되다", "주다", "만들다")
# N-gram => 한 단어에서만 제외할 문자
> dic3 <- c("코로나", "바이러스")
# N-gram => 두, 세 단어에서만 제외할 문자
> dic4 <- c("코로나 바이러스", "신종 코로나 바이러스")
# 위 제외할 문자를 사용하여 두 개의 말뭉치를 생성했다!
# N-gram => 한 단어에서 사용할 data1
> data1 <- tm::tm_map(data, FUN = stripWhitespace) %>%
+ tm::tm_map(FUN = removeNumbers) %>%
+ tm::tm_map(FUN = removePunctuation) %>%
+ tm::tm_map(FUN = removeWords, words = c(dic, dic2, dic3))
# N-gram => 두 단어에서 사용할 data2
> data2 <- tm::tm_map(data, FUN = stripWhitespace) %>%
+ tm::tm_map(FUN = removeNumbers) %>%
+ tm::tm_map(FUN = removePunctuation) %>%
+ tm::tm_map(FUN = removeWords, words = c(dic, dic2, dic4))N Gram 생성과 데이터 형식 변환
이 부분은 아래 블로그를 참고하였습니다. :)
블로그 바로가기 : 클릭
# 이후 TDM 생성에서 활용할 N-Gram-Tokenizer를 만들어 주었다
> NGramTokenizer2 <- function(x) unlist(lapply(NLP::ngrams(words(x), 2), paste, collapse=" "), use.names=FALSE)
> NGramTokenizer3 <- function(x) unlist(lapply(NLP::ngrams(words(x), 3), paste, collapse=" "), use.names=FALSE)
# 위 N-Gram-Tokenizer를 활용하여 TDM을 만들어 준다
# 이 TDM을 통해 빈도수가 높은 단어를 파악하고, 불용어가 있는지 점검해서 다시 말뭉치 전처리 과정을 반복했다
> ng1 <- tm::TermDocumentMatrix(data1)
> ng2 <- tm::TermDocumentMatrix(data2, control=list(tokenize=NGramTokenizer2))
> ng3 <- tm::TermDocumentMatrix(data2, control=list(tokenize=NGramTokenizer3))
# 단어별 빈도수 확인
#최소 빈도수는 N-Gram 단어 개수에 따라 임의로 다르게 설정해주었다
> w <- tm::findFreqTerms(ng1, lowfreq = 10)
> w2 <- tm::findFreqTerms(ng2, lowfreq = 10)
> w3 <- tm::findFreqTerms(ng3, lowfreq = 5)
# 아래와 같이 매트릭스 형태로 변경하고 내림차순 정렬을 하면
# 각 단어와 빈도수를 편하게 확인할 수 있다
> wf <- rowSums(as.matrix(ng1[w,])) %>% sort(decreasing = TRUE)
> wf
# 이 후 그래프와 워드 클라우드 생성을 위해 데이터 프레임으로 변환
> wf <- data.frame(words = names(wf), frequency = wf)
> wf
words frequency
마스크 마스크 122
진료소 진료소 50
호흡기 호흡기 45
치료제 치료제 41
보건소 보건소 40
질병관리본부 질병관리본부 40
감염병 감염병 38
빠르다 빠르다 35
근로자 근로자 33
감염증 감염증 28
면역력 면역력 28
신천지 신천지 27
온라인 온라인 27
어렵다 어렵다 26
지하철 지하철 26
홈페이지 홈페이지 26
사이트 사이트 25
의료진 의료진 25
대상자 대상자 24
... 생략...
# 글자수 2개와 3개도 동일하게 해준다
> wf2 <- rowSums(as.matrix(ng2[w2,])) %>% sort(decreasing = TRUE)
> wf2 <- data.frame(words = names(wf2), frequency = wf2)
> wf3 <- rowSums(as.matrix(ng3[w3,])) %>% sort(decreasing = TRUE)
> wf3 <- data.frame(words = names(wf3), frequency = wf3)드디어... 시각화 🐣🐥🐤
ggplot2 : 바 그래프
제가 애정하는 ggplot2 패키지로 TOP 10 바 그래프를 먼저 만들어 보겠습니다.
# 같은 코드를 반복해서 쓰는건 귀찮으니까 사용자 함수로 만들었다
> bar <- function(x){
+ x %>%
+ dplyr::slice(1:10) %>%
+ ggplot2::ggplot(mapping = aes(x = reorder(words, frequency), y = frequency)) +
+ ggplot2::geom_bar(stat = "identity", fill = "gray") +
+ ggplot2::theme_light() +
+ ggplot2::labs(x = "Words", y = "Frequency") +
+ ggplot2::coord_flip()
+ }
> bar(wf)
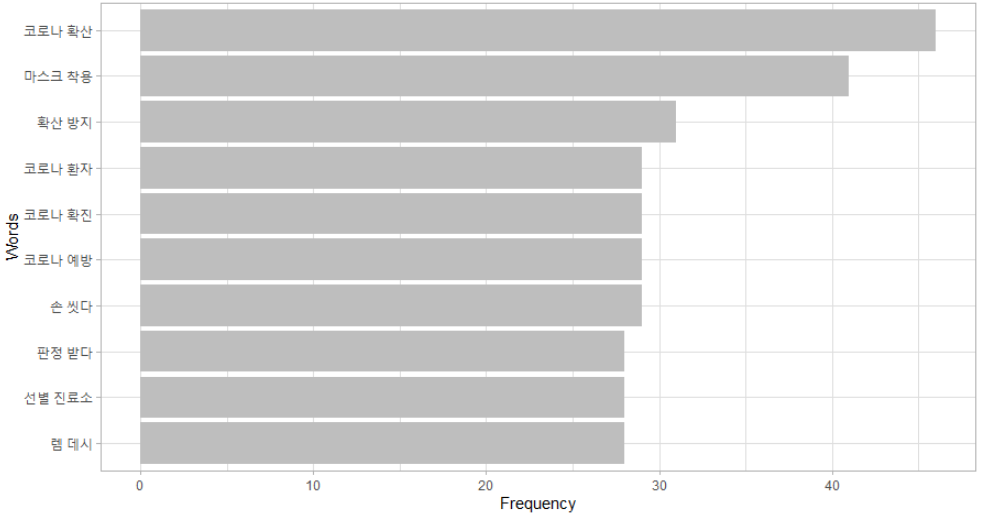
> bar(wf2)
> bar(wf3)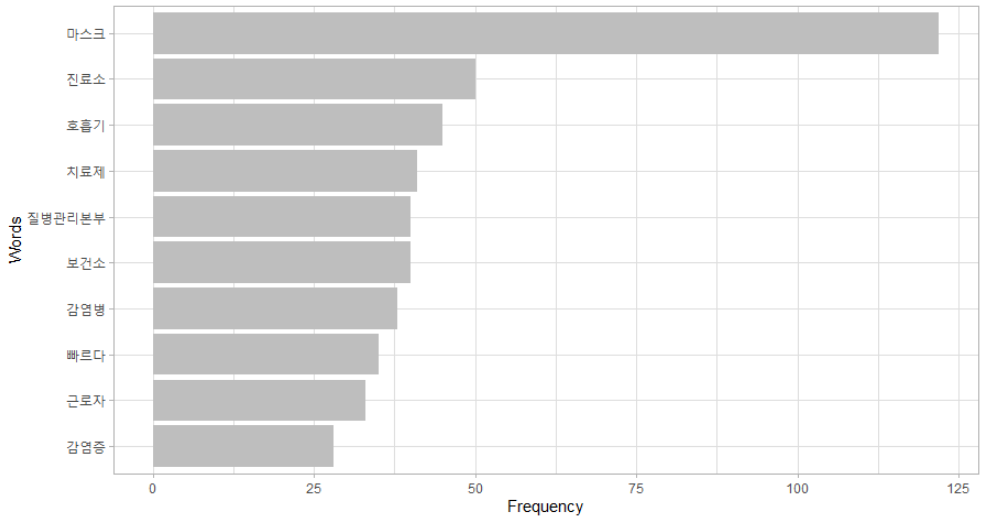
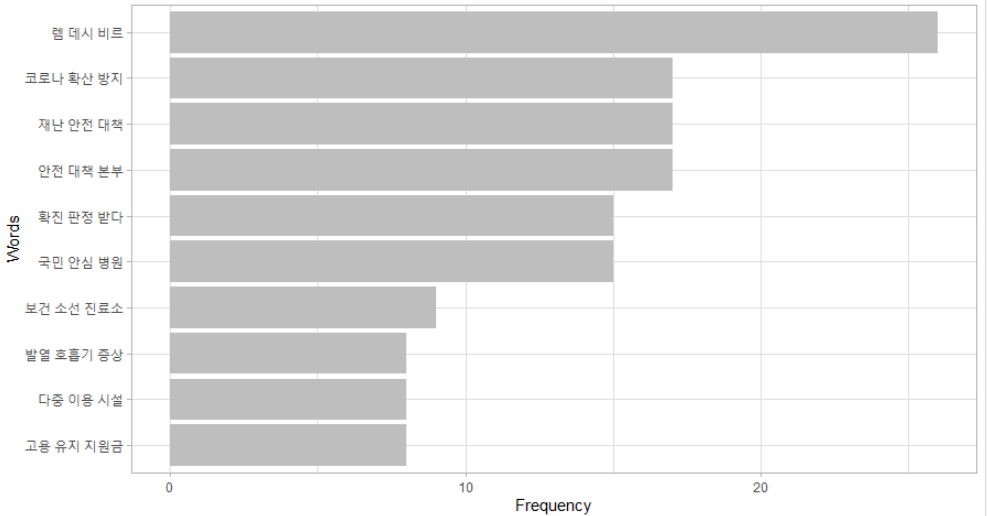
wordcloud2 : 워드클라우드
위 바 그래프를 통해 대략 어떤 키워드의 빈도수가 높은지 알 수 있었습니다. 워드 클라이드로 별도 빈도수 제한 없이(제 데이터 자체가 크기가 적게 때문에 빈도수 제한 걸지 않았습니다.) 확인해보겠습니다!
# 역시 사용자 함수를 만든 후 워드 클라우드를 생성해주었다.
> word <- function(x){
+ wordcloud2::wordcloud2(x,
+ color = "random-light",
+ fontFamily = "NanumGothic")
+ }
> word(wf)
> word(wf2)
> word(wf3)특히 두 단어 N-Gram은 사전을 만들지 않고 전치리가 부족했던게 드러니는 듯 하네요.



마무리
위 작업 중 느낀 것은, 1)사전 생성이 참 중요하다 2)전처리가 참 중요하다 3)작업 중간에도 끊임 없이 전처리 과정으로 돌아가야 한다 4)예쁘게 만들기가 어렵다 등등 🙂

잘 읽고가요 ~
:-)