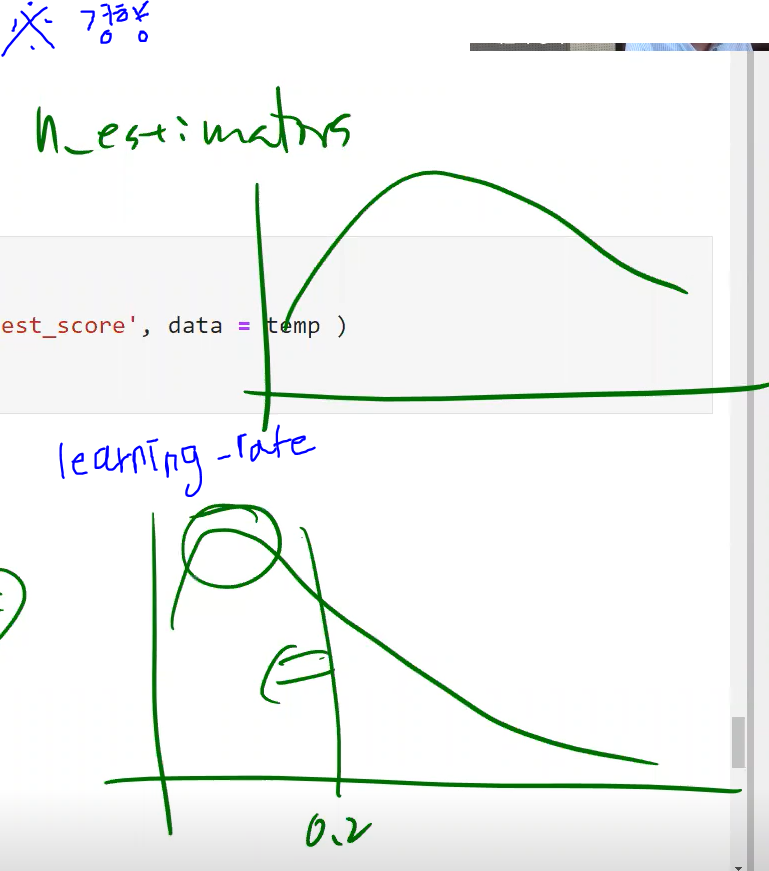
learning_rate
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=2 , n_estimators=3, learning_rate=1.0)
gbrt.fit(x,y): 각 트리의 기여 정도를 조절. 0.1처럼 낮게 설정하면 앙상블을 train set에 학습시키기 위해 많은 트리가 필요하지만, 예측의 성능은 좋아짐
-
learning_rate은 0< ≤1
-
learning_rate을 낮추고 n_estimators를 높이면 '조금씩 많이' 가기
learning_rate을 높이고 n_estimators를 낮추면 '보폭을 넓게 해서 듬성듬성' 가기
- 참고
<핸즈 온 머신러닝> 263-264p.
에이블 | 머신러닝 - 13과 Boosting, 교안 146p
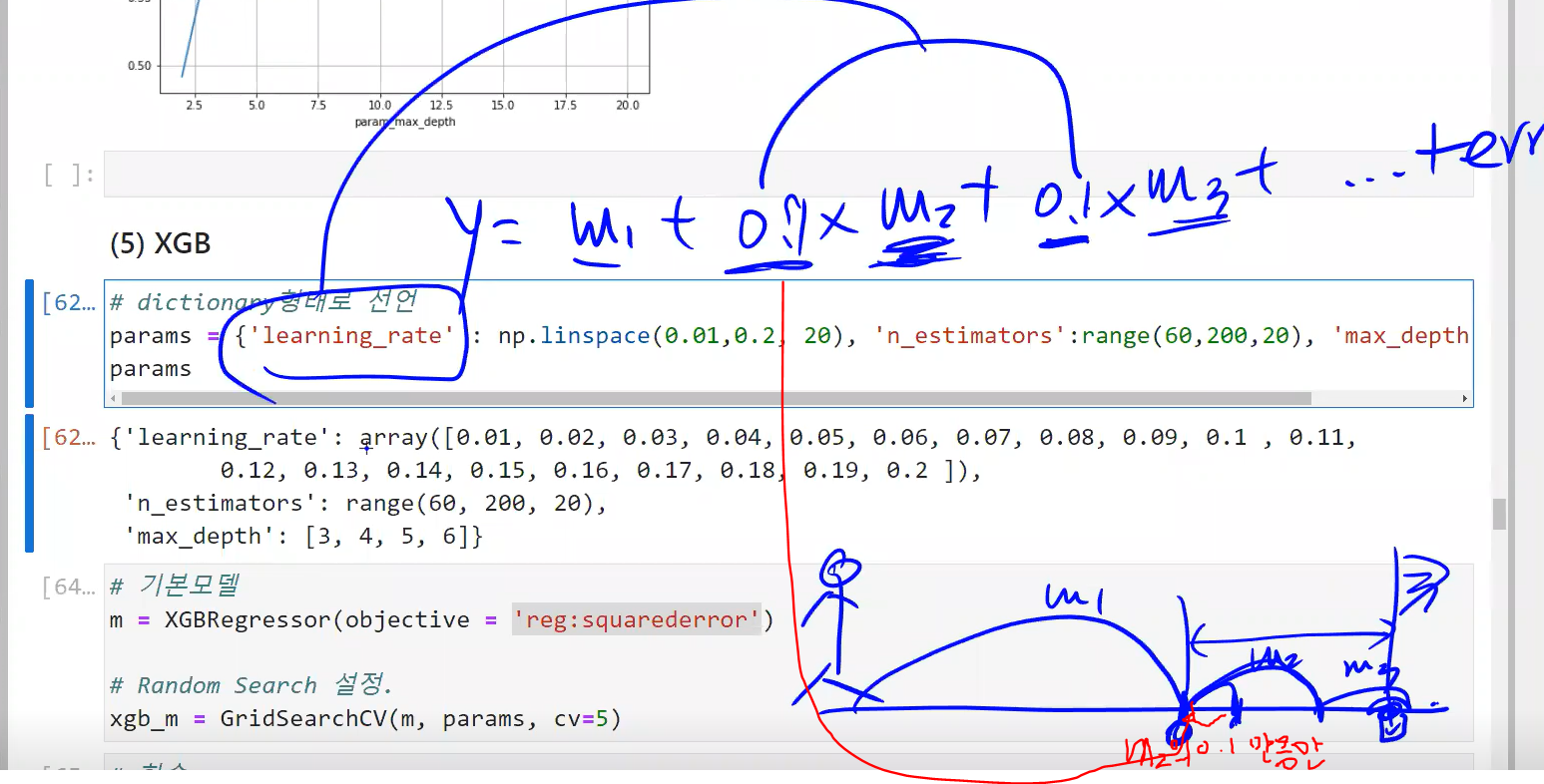
13과 (5)XGB
OLS
: 선형회귀의 회귀계수를 찾는 약자
model = OLS(y_train, add_constant(x_tr)).fit(disp=False)disp=False
: 모델 학습시 로그 기록이 안남도록 해줌
model = OLS(y_train, add_constant(x_tr)).fit(disp=False) objective=
: .fit을 하게 되면 오차를 최소화하는 모델을 찾는데, 여기서 오차를 계산하는 함수가 logs function. 즉, logs function을 = 이하의 함수로 지정하라는 의미
# 기본모델
m = XGBRegressor(objective = 'reg:squarederror') - 참고
에이블 | 머신러닝 교안 151쪽 필기, 실습 14과 (5) XGB
