Vector DB
-
ChatGPT 등 LLM 등장 이후 중요성 대두
-
hallucination 방지, 검색 기능 강화
- 기존의 키워드 기반 검색에서 의미론적 유사성을 기반으로 한 검색 기능 제공
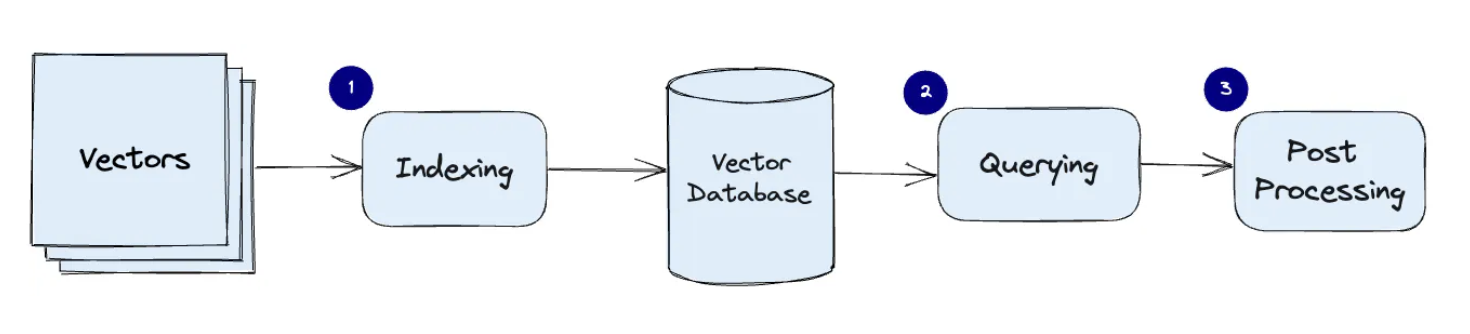
작동 원리
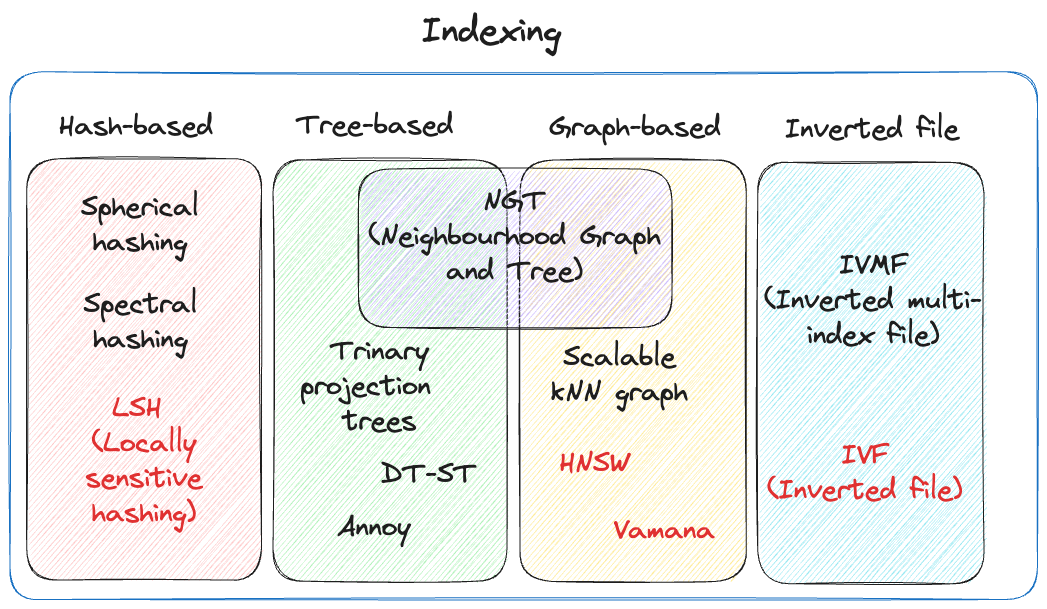
1. Indexing: PQ(Product Quantization), LSH(Locality-Sensitive Hashing), HNSW(Hierachical Navigable Small World) 와 같은 알고리즘을 사용하여 벡터 인덱싱
2. Querying: query 벡터를 indexing 된 데이터셋의 벡터들과 비교하여 최근접 이웃을 찾는다. 이 과정에서 특정 유사도 측정 방식이 사용되며, 이 유사도 측정은 해당 인덱스에 의해 정의된 방식을 따른다.
3. Post Processing: (일부) 최종 결과를 반환하기 전에 후처리 작업 수행
Embedding
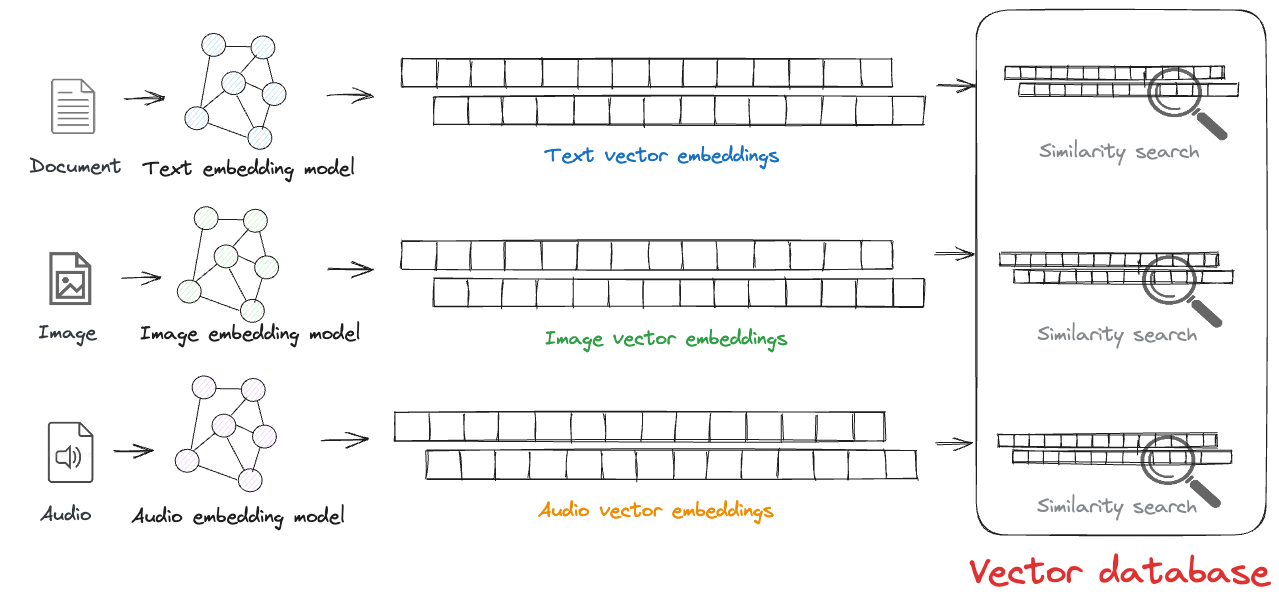 벡터 db는 원본 데이터와 임베딩 벡터를 저장한다. 텍스트, 이미지, 오디오 등 비정형 데이터로 임베딩을 생성하고 저장, 유사도 검색을 실행할 수 있다.
벡터 db는 원본 데이터와 임베딩 벡터를 저장한다. 텍스트, 이미지, 오디오 등 비정형 데이터로 임베딩을 생성하고 저장, 유사도 검색을 실행할 수 있다.
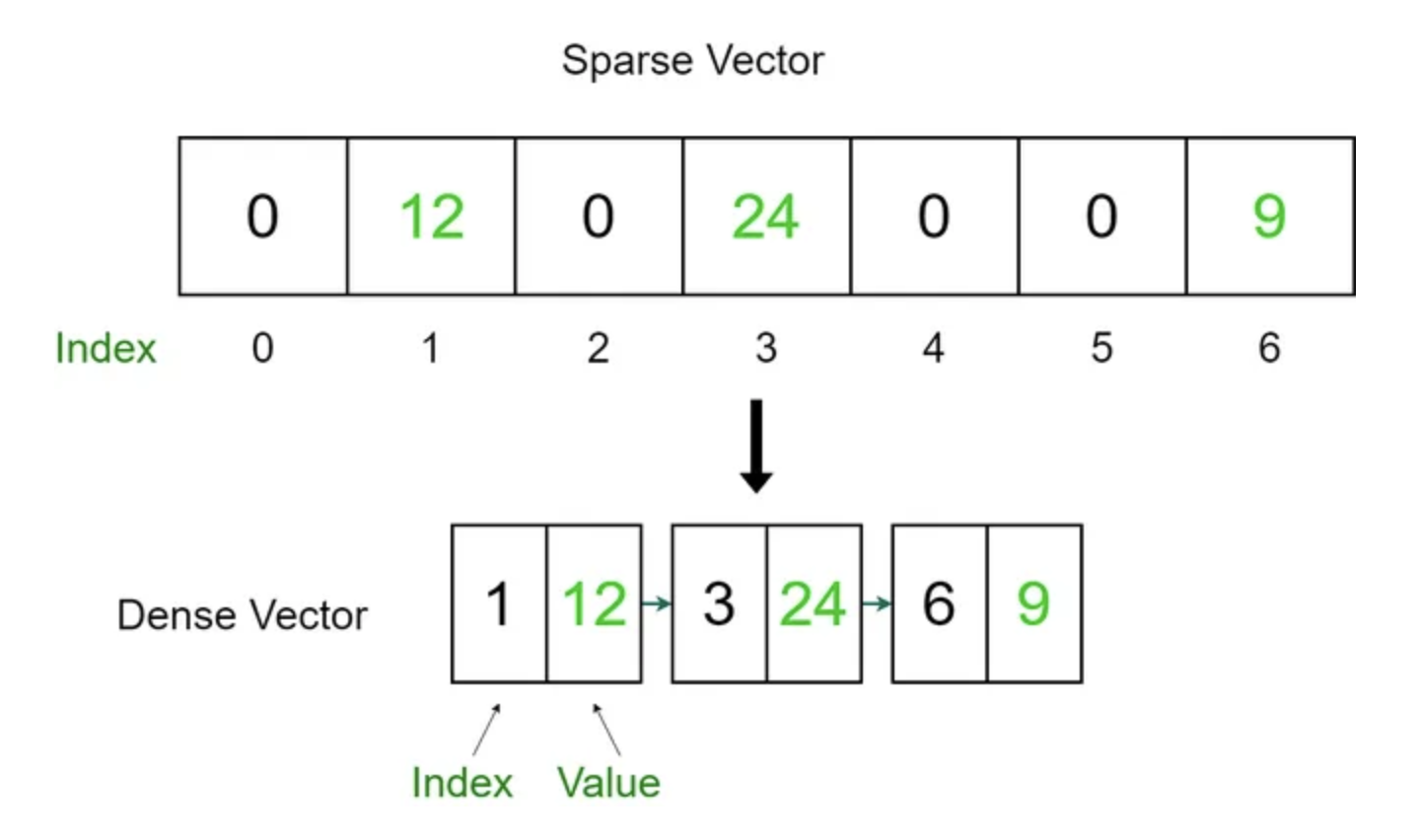
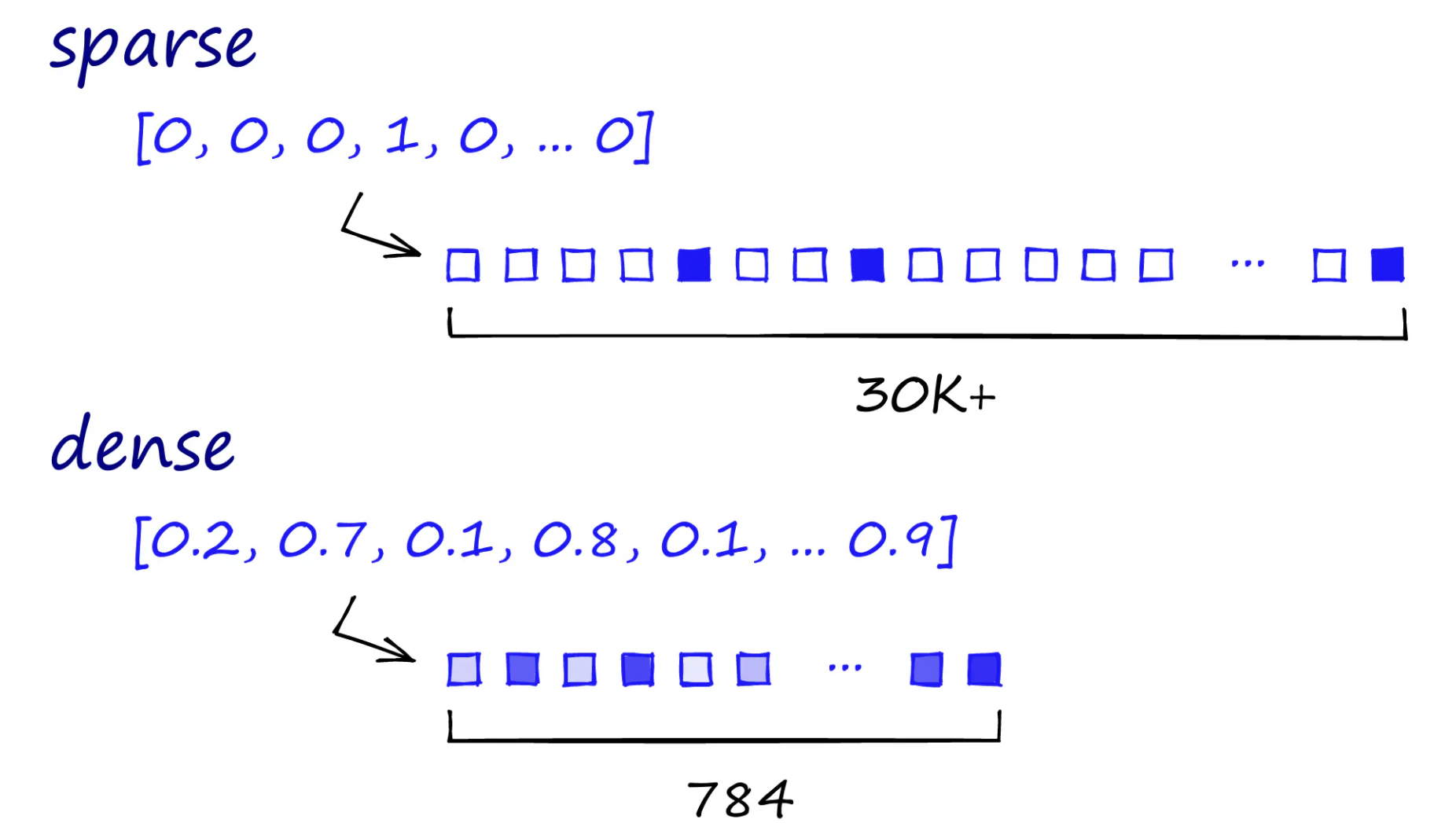
Sparse vs Dense
 |  |  |
|---|
Sparse embedding
- Bag of Words 접근법: 텍스트의 구조나 순서를 무시하고, 단어의 출현 빈도만을 고려한다.
- 전체 어휘 크기에 해당하는 벡터가 생성된다. 예를 들어, 어휘가 10,000개 단어로 구성되어 있다면, 각 문서는 10,000차원의 벡터로 표현된다.
- 대부분의 문서가 전체 어휘의 작은 부분만을 사용하기 때문에, 일반적으로 90% 이상의 요소가 0인 sparse matrix가 된다.
- 검색 시 단어 간의 의미적 유사성을 고려하지 않고, 단어가 정확히 일치해야만 관련성이 있다고 판단한다.
- TF-IDF
Dense embedding
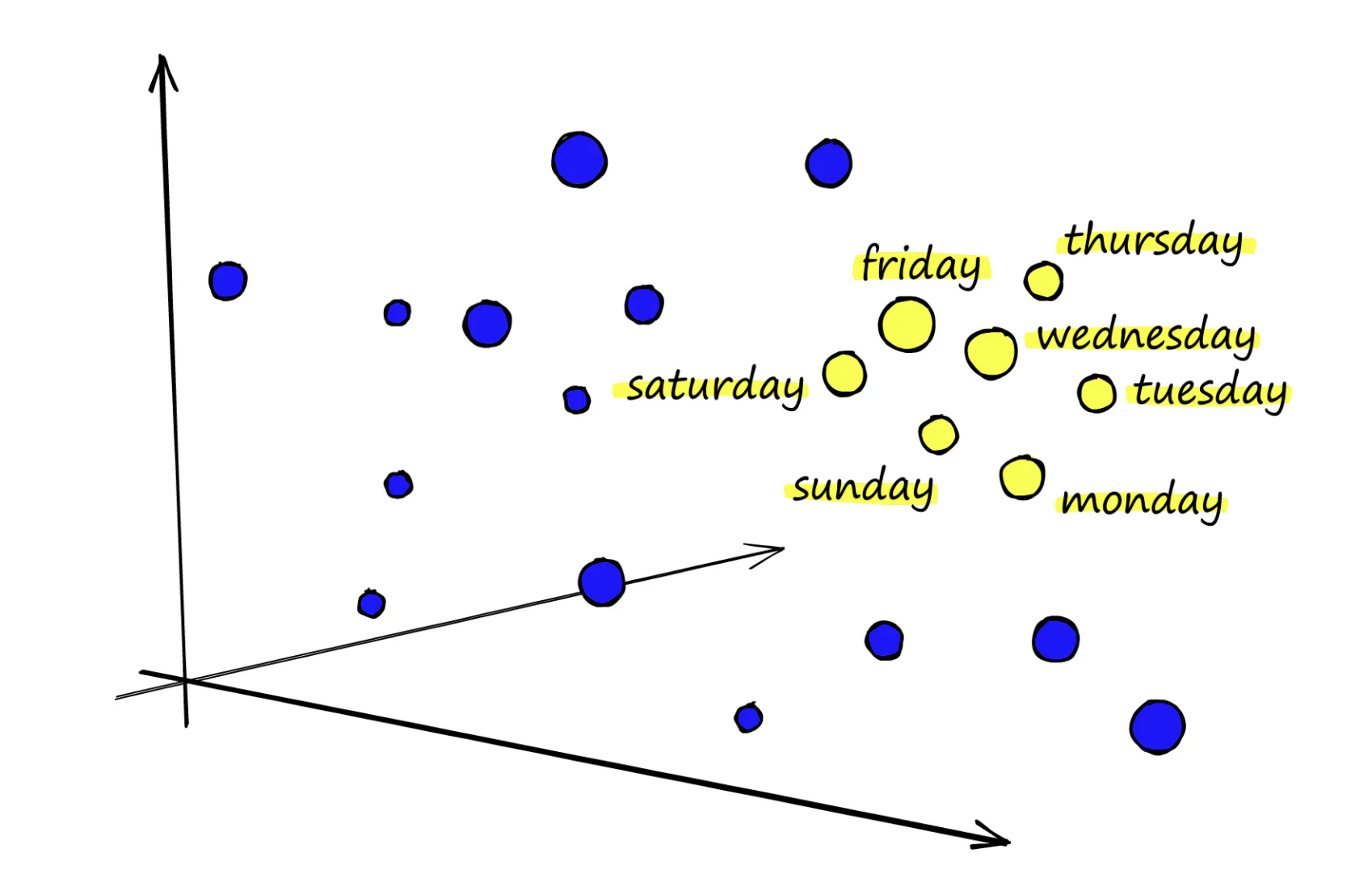
- ex. Hugging Face sentence-transformers, OpenAI Embedding API, Cohere Embedding API
- 유사한 의미를 가진 단어들이 벡터 공간에서 클러스터 형성
- 검색시 단어의 유사성이나 맥락 파악 가능
- 벡터의 차원이 낮을수록 임베딩 공간에서의 표현이 더 간결해진다. 높은 차원은 세밀한 특징 구분을 가능하게 하지만, 계산 복잡도가 증가하고 저장 공간이 많이 필요하다. (trade-off)
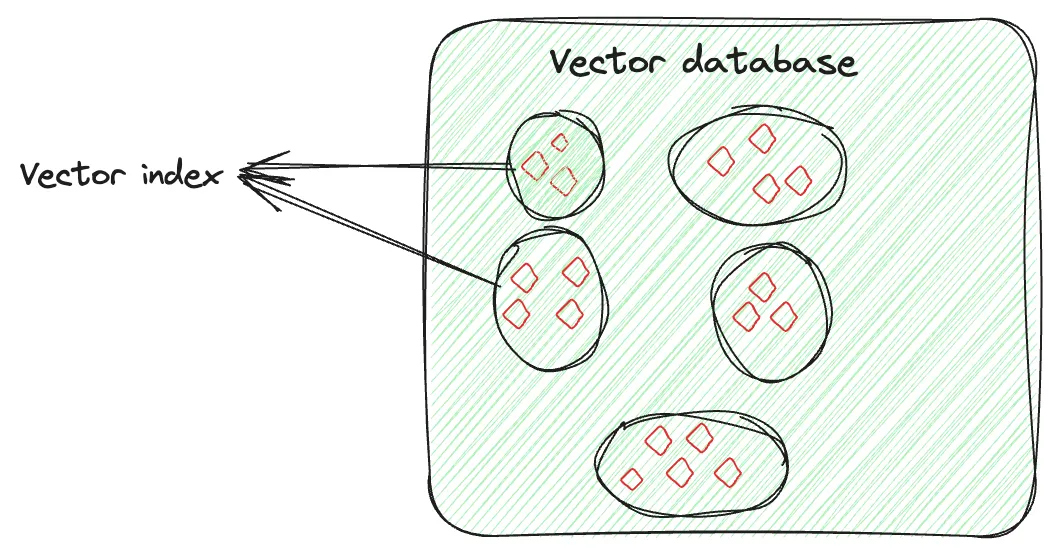
Indexing
ANN(Approximate nearest neighbours)
- 대규모 고차원 데이터셋에서 정확한 최근접 이웃을 찾는 대신(kNN, brute-force search), 근사치의 최근접 이웃을 빠르게 찾는 방법 (검색 속도와 정확도 사이의 trade-off)
- 다양한 Indexing 방법을 통해 ANN을 구현한다.
 |  |
|---|
Vector indexing intelligently orginizes the vector embeddings to optimize the retrieval process.
Hash-based index
- ex. LSH(Locally Sensitive Hashing)
- 해시 함수를 사용하여 벡터를 버킷에 매핑
Tree-based index
- ex. KD-Tree, Annoy
- 데이터를 계층적 트리 구조로 구성
- 저차원에서 효과적, 고차원에서는 성능 저하
Graph-based index -> search process through the multi-layer structure of an HNSW graph
-> search process through the multi-layer structure of an HNSW graph
- ex. HNSW
- 데이터 포인트를 노드로, 유사성을 엣지로 표현하는 그래프 구성
- 고차원 데이터에 효과적, 빠른 검색 속도
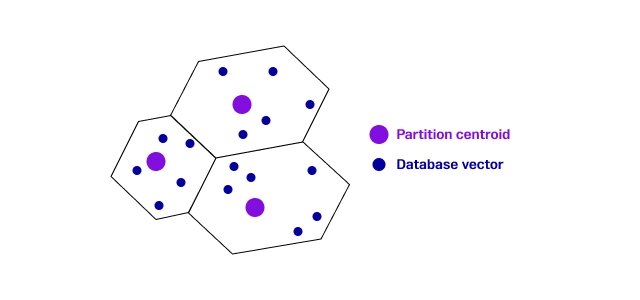
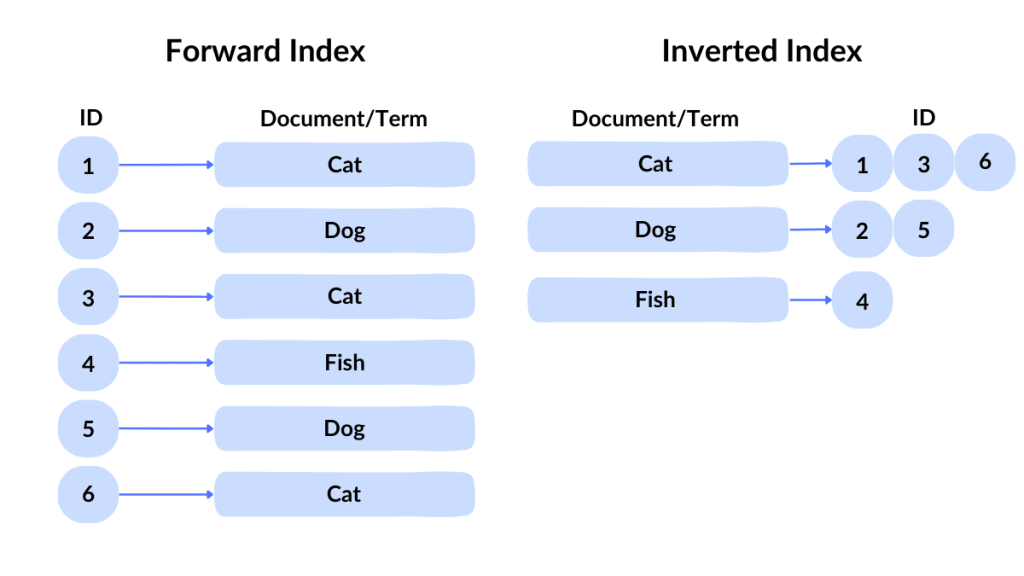
Inverted file index
 |  |
|---|
- ex. IVF(Inverted File)
- 데이터를 여러 클러스터로 나누어 각 클러스터에 대한 작은 인덱스를 생성하고, 이를 통해 검색 범위를 좁혀 성능을 향상시킴
- 메모리 효율적, 대규모 데이터셋에 적합
Compression
Flat vs Quantized
참고
Vector databases (3): Not all indexes are created equal
What is a Vector Database & How Does it Work? Use Cases + Examples
Hybrid Search Revamped
Dense Vectors in Natural Language Processing
Dense Vectors: Capturing Meaning with Code
Intro to NLP Part II: Word Embedding
Passage Retrieval - Dense Embedding
Vector Indexes in Postgres using pgvector: IVFFlat vs HNSW
How To Implement Inverted Indexing - Top 10 Tools & Future Trends
Scaling up with FAISS(Scailing Up)
Understanding Vector Indexing: A Comprehensive Guide
