논문 리뷰 - BERT: Pre-Training of Deep bidirectional Transformers for Language Understanding
NLP Evaluation Methods
- SQuAD v1.1 & 2.0 (Stanford Question Answering Dataset): 텍스트 내에서 질문에 대한 답 찾기
- GLUE (General Language Understanding Evaluation): 9개의 서로 다른 NLP 과제로 구성
- CoLA (Corpus of Linguistic Acceptability): 문장이 문법적으로 맞는지 평가.
- SST-2 (Stanford Sentiment Treebank): 텍스트의 감정을 긍정/부정으로 분류.
- MRPC (Microsoft Research Paraphrase Corpus): 두 문장이 같은 의미인지 판단.
- STS-B (Semantic Textual Similarity Benchmark): 두 문장의 의미적 유사성 평가.
- QQP (Quora Question Pairs): 두 질문이 같은 의미인지 판단.
- MNLI (Multi-Genre Natural Language Inference): 문장 간의 관계를 예측.
- QNLI (Question Natural Language Inference): 질문과 문장 간의 관계를 예측.
- RTE (Recognizing Textual Entailment): 두 문장 간의 논리적 관계를 판단.
- WNLI (Winograd NLI): 문맥상 참조 대상을 식별.
- SWAG (Situations With Adversarial Generations): 상식 추론
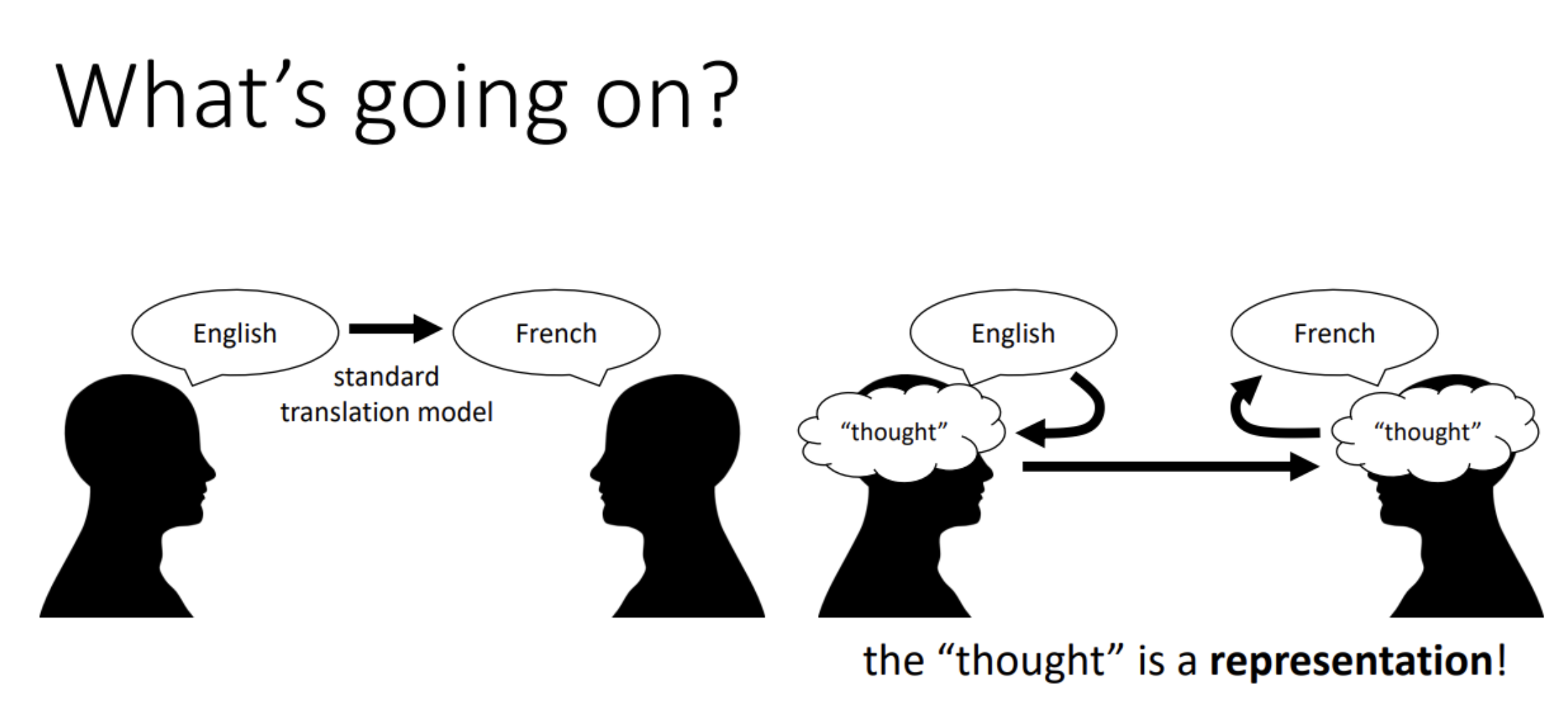
Language Representation
- 언어 데이터를 딥러닝 모델의 입력값으로 쓸 수 있도록 하는 표현
- representation: 문장의 의미를 내포한다.
- representation은 언어에 종속되지 않고(language-agnostic), 그 문장의 의미(sementic-content)만을 담고있다.
- BERT 모델은 language representation 그 자체에 목적을 두고 있다.
- 이후에 어떤 태스크나 모델과도 결합하기 좋은 representation 을 만드는 것이 목적
1 Abstract
BERT
- Bidirectional Encoder Representations from Transformers
- new language representation model
기존 모델과의 차별점: - designed to pretrain deep bidirectional representations from unlabled text by jointly conditioning on both left and right context in all layers
- pre-trained BERT model 에 하나의 output layer를 추가함으로써, 다양한 task 수행 가능 & SOTA 달성
- 11개의 NLP task 에서 SOTA 달성
- BERT 이전에는 각 task 마다 별개의 model 이 필요했다.
2 Introduction
두 가지 유형의 NLP task
1) Sentence-level task
- NLI(Natural Laguage Inference, 자연어 추론), paraphrasing(의역)
- aim to predict the relationships between by analyzing them holistically
2) Token-level task
- entity recognition(개체명 인식), question answering(질의응답)
- models are required to produce fine-grained output at the token level
기존 모델이 pre-trained language representation 을 각 task 에 적용하는 두 가지 방법
두 방식 모두 동일한 목적 함수를 사용하고, unidirectional(단방향) 언어 모델을 사용한다.
1) feature-based (ELMo 등)
- uses task-specific architectures
- 설계한 모델에서 pre-trained representation 을 하나의 feature 로 추가하여 학습시킨다.
2) fine-tuning (GPT 등)
- fine-tune al pre-trained parameters
- task-specific 한 모델을 따로 설계하지 않고,Task-specific 한 parameter 최소한으로 줄인 공통적인 모델을 사용한다.
- 해당 모델로부터 task-specific parameter들을 해당 태스크에 맞게 fine-tuning 시켜서 학습시킨다.
기존 모델의 한계(특히 fine-tuning방식)
- standard language models are unidirectional -> limits the choice of architectures that can be used during pre-training
BERT 가 제시하는 방법
- BERT: fine-tuning 방식을 베이스로 하여, bidirectional 모델 구현
- MLM(Masked Language Model)을 통해 unidirectionality constraint 극복
- MLM: randomly masks some of the tokens from the input -> predict the original vocabulary id of the masked word based only on its context (문장에서 임의의 token을 mask로 가리고, 그 단어가 무엇일지 예측)
- NSP(Next Sentence Prediction) task
BERT 가 가지는 차별점
- enable pre-trained deep bidirectional representations
- 무거운 task-specific architecture 가질 필요 없음.
- BERT는 sentence-level, token-level task 에서 모두 SOTA를 달성한 최초의 fine-tuning based representation model
3 BERT
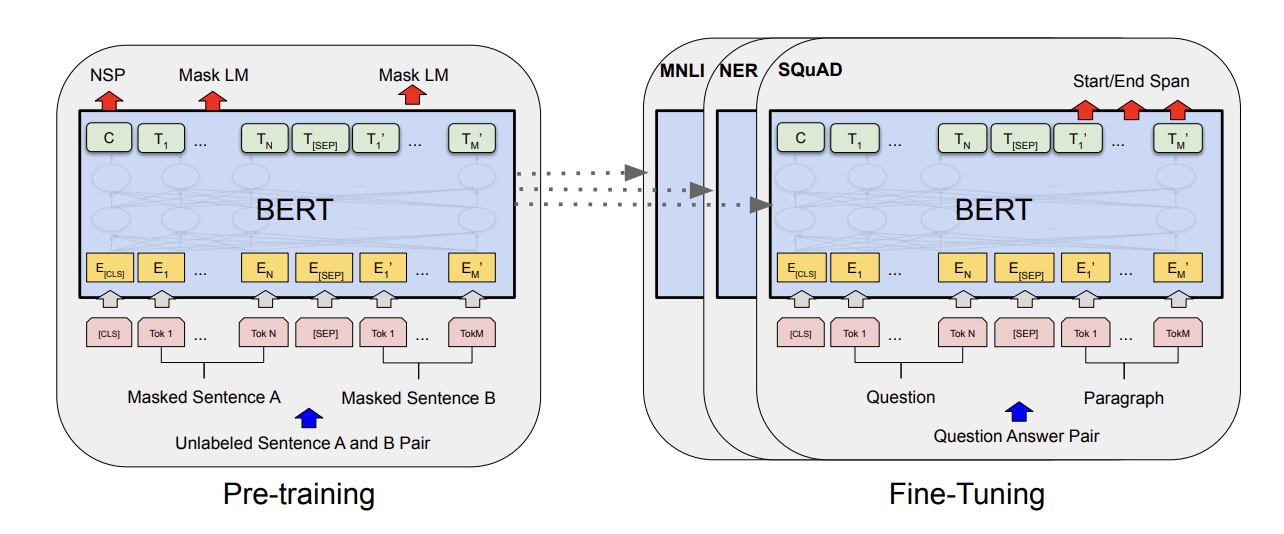
Two steps: pre-training, fine-tuning
Pre-training
- trained on unlabeled data over different pre-training tasks
Fine-tuing
- initialized with the pre-trained parameters -> all parameters are fine-tuned using labeled data from the downstream tasks
- BERT: unified architecture across different tasks
Model Architecture
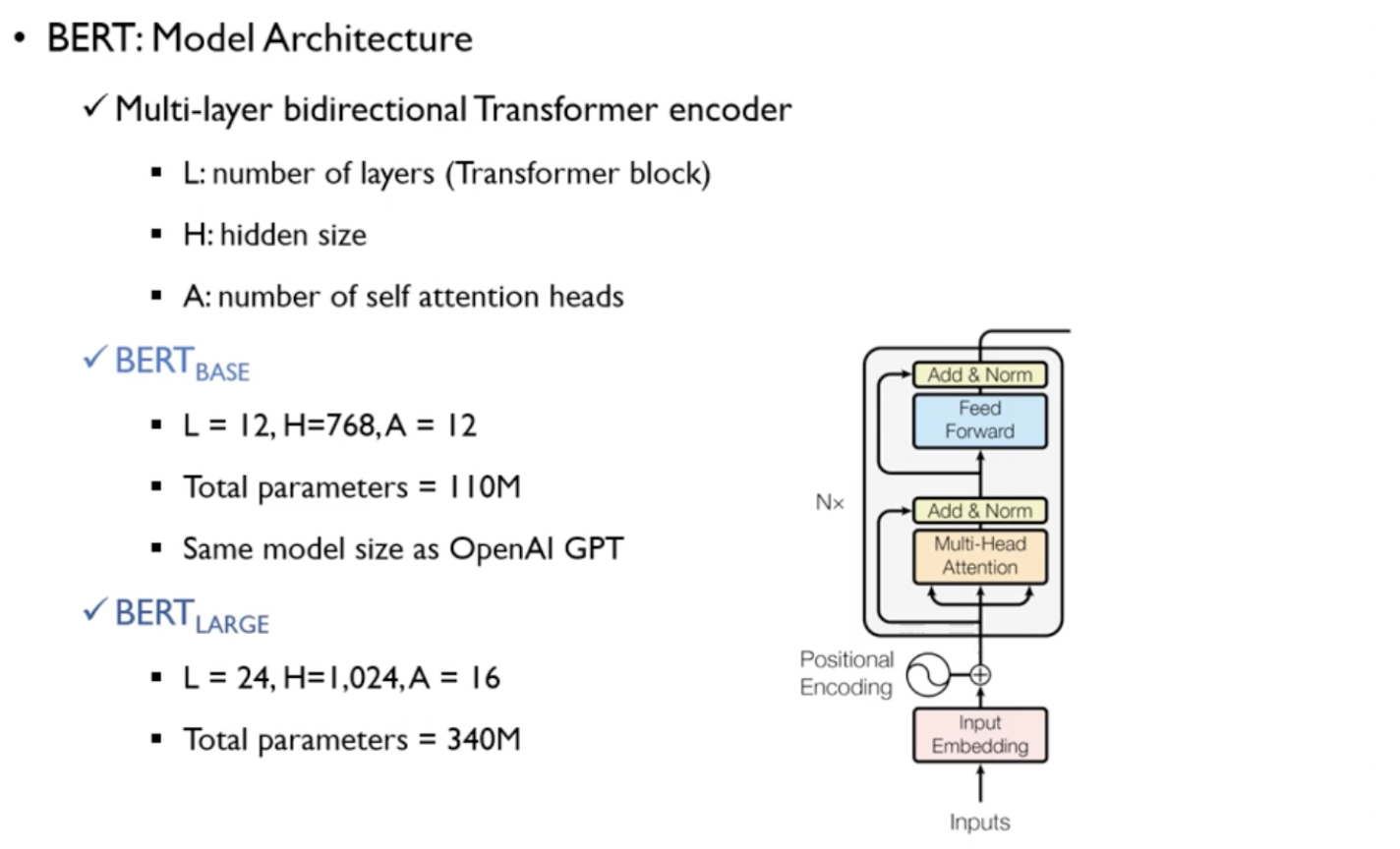
- L: number of layers(transformer blocks)
- H: hidden size
- A: number of self-attention heads
- BERT base (L=12, H=768, A=12, total parameters=110M(OpenAI GPT와 비교 위함))
- BERT large (L=24, H=1024, A=16, total parameters=340M)
- transformer에서는 activation function으로 ReLU를 사용했지만, BERT는 GELU 사용
Input/Output Representations
- sentence: 연속된 text - 언어적으로 말이 안 될 수 있음.
- sequence: BERT에 입력되는 input token sequence(한 문장이거나 두 문장) - 하나의 입력 단위
다양한 task를 수행하기 위해서, input representation 은 한 문장과 두 문장 모두 한 sequence 에 받아야 한다.
-
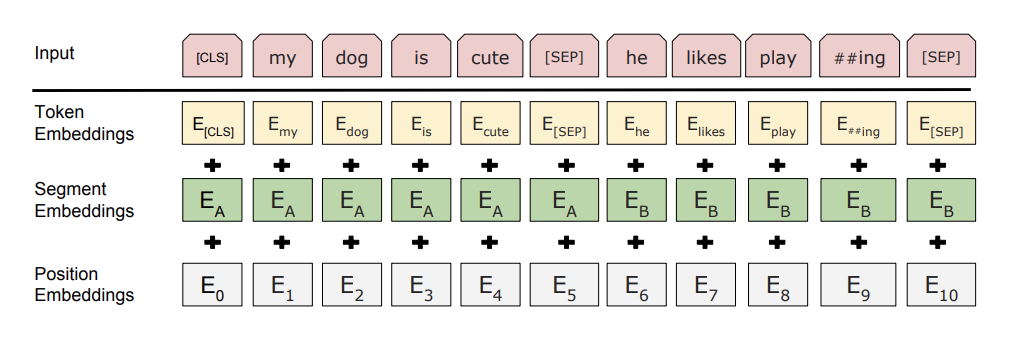
Embedding()
- token embedding: WordPiece embeddings(30,000 token vocabulary) 사용
- [CLS]: 모든 sequence의 첫 번째 token
- [SEP]: 두 문장이 input으로 들어갈 경우, 분리를 위한 token
- [CLS]: 모든 sequence의 첫 번째 token
- segment embedding: 여러 문장이 합쳐진 경우, 소속된 문장을 나타내는 embedding
- positional embedding
- (Token emgeddings + Segment Embeddings + Position Embeddings) -> sum ->
- token embedding: WordPiece embeddings(30,000 token vocabulary) 사용
-
final hidden vector(출력 representation)
- : [CLS] token에 대응하는 hidden vector
- : 나머지 i번째 입력토큰
- = 각 hidden vector들은 동일하게 H의 차원을 가지는 실수 벡터
3-1 Pre-training
MLM, NSP 두 가지 task 존재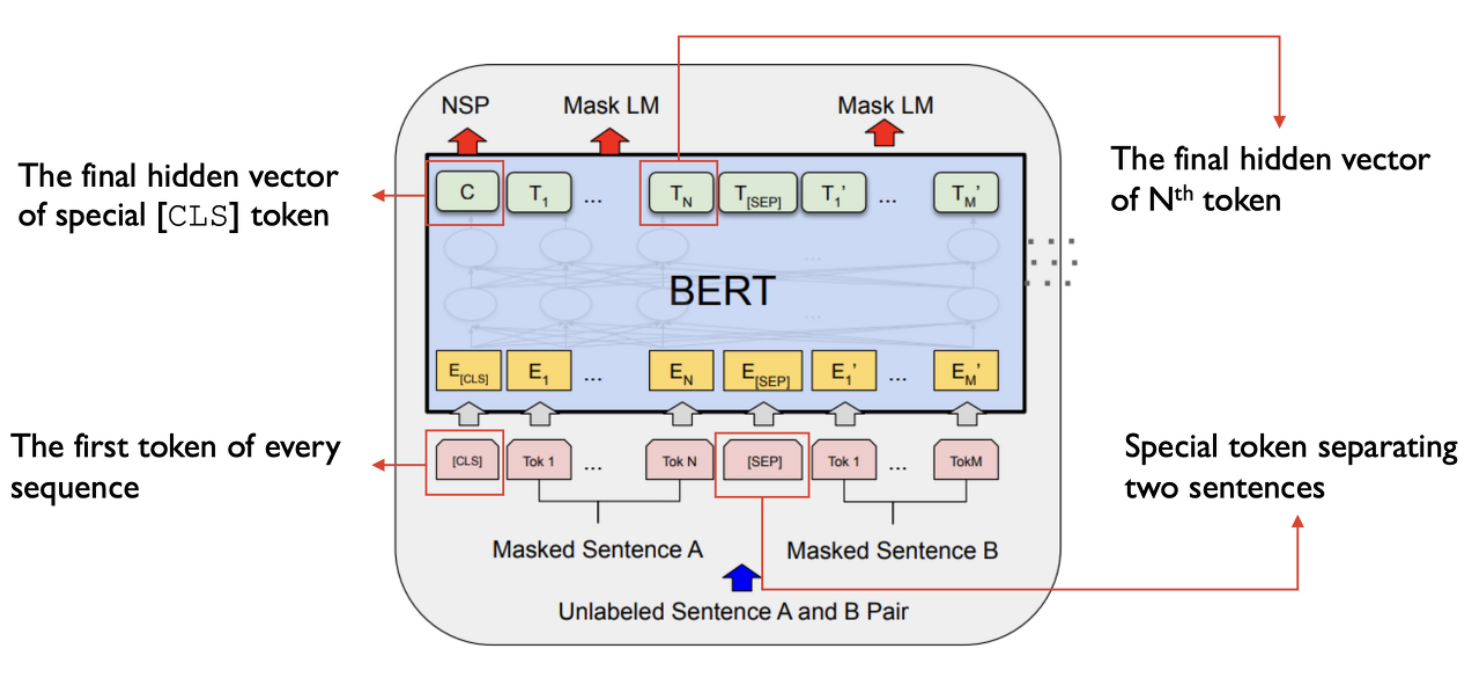
Task 1. Masked Language Modeling(MLM)
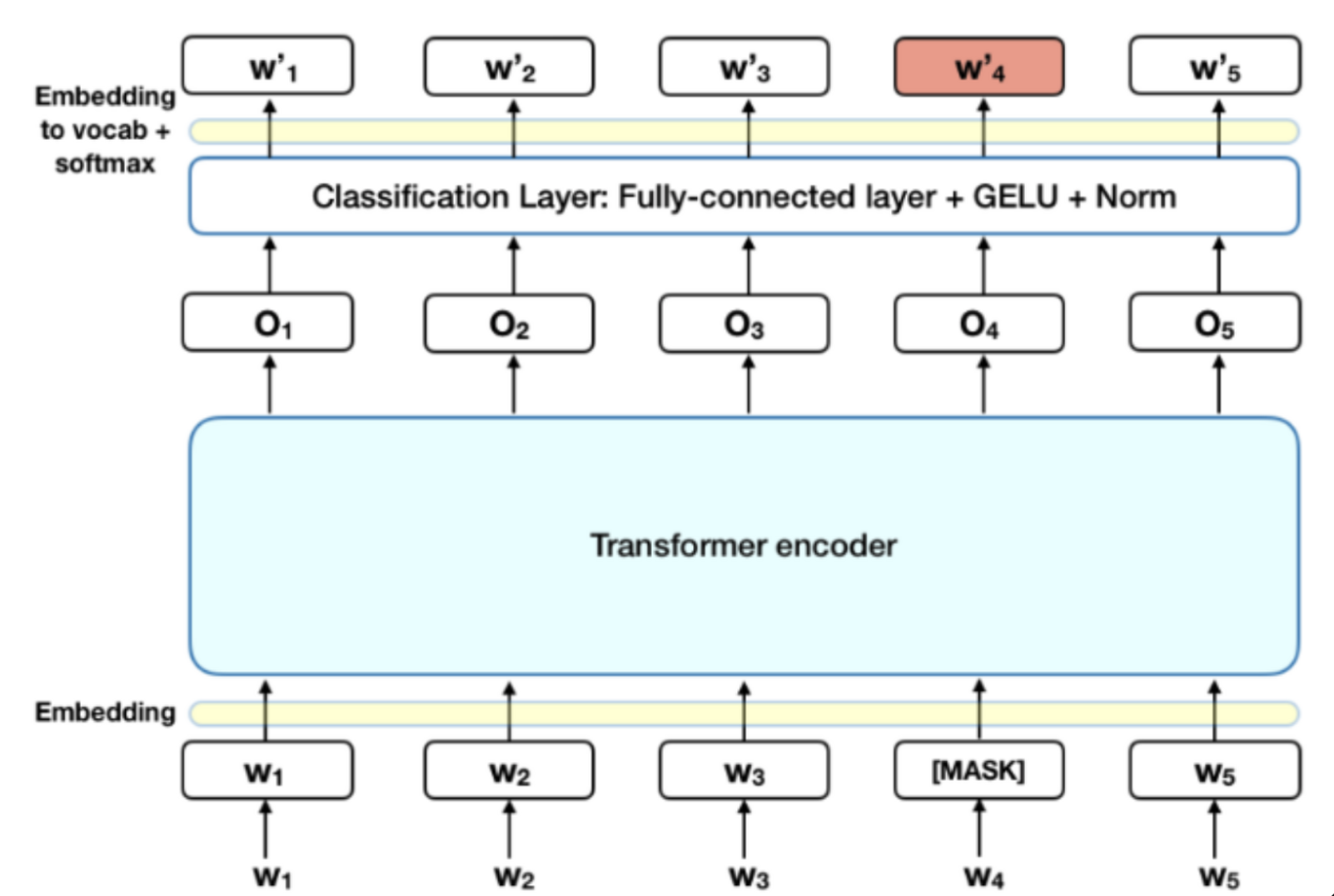 Bidirectional model이므로, 참조의 순환 문제가 발생한다. 단방향은 무조건 한쪽 방향으로만 참조가 진행되지만, 참조가 양쪽 방향으로 진행되면 결국 간접적으로 자기 자신을 참조하게 되기 때문이다. BERT는 이 문제를 MLM(Masked LM) 을 통해 해결한다.
Bidirectional model이므로, 참조의 순환 문제가 발생한다. 단방향은 무조건 한쪽 방향으로만 참조가 진행되지만, 참조가 양쪽 방향으로 진행되면 결국 간접적으로 자기 자신을 참조하게 되기 때문이다. BERT는 이 문제를 MLM(Masked LM) 을 통해 해결한다.
- MLM: input token 중 15%의 token을 가리고, 가려진 token을 예측하도록 함
w4->[MASK]->encoder layer->output->Classifiaction Layer(Fully-connected layer, GELU activation function, Normalization)->w'4
- MLM의 단점: [MASK] token은 pre-training에만 사용되고 fine-tuning 시에는 사용되지 않으므로 mismatch 발생
- 해결방안: pre-training시 i번째 token이 masking token으로 선택되면
- 그 중 80%만 실제로 masking: 모델이 masking된 단어 예측하도록 함
- 10%는 random token으로 치환: 문맥에 맞지 않는 단어 처리하는 능력 기름
- 10%는 masking하지 않음

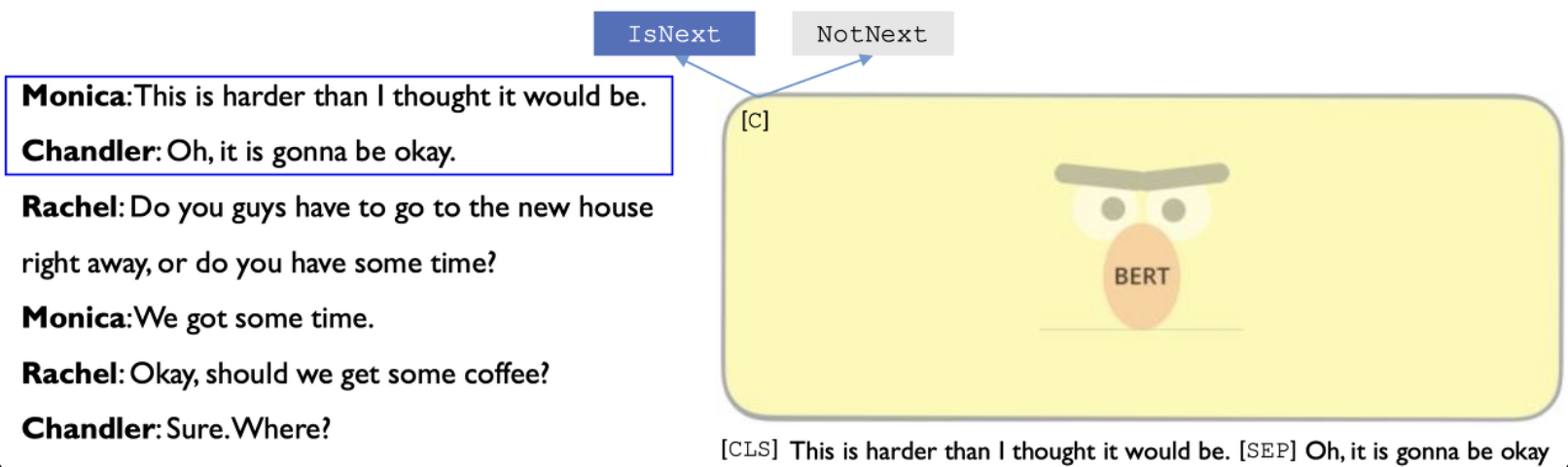
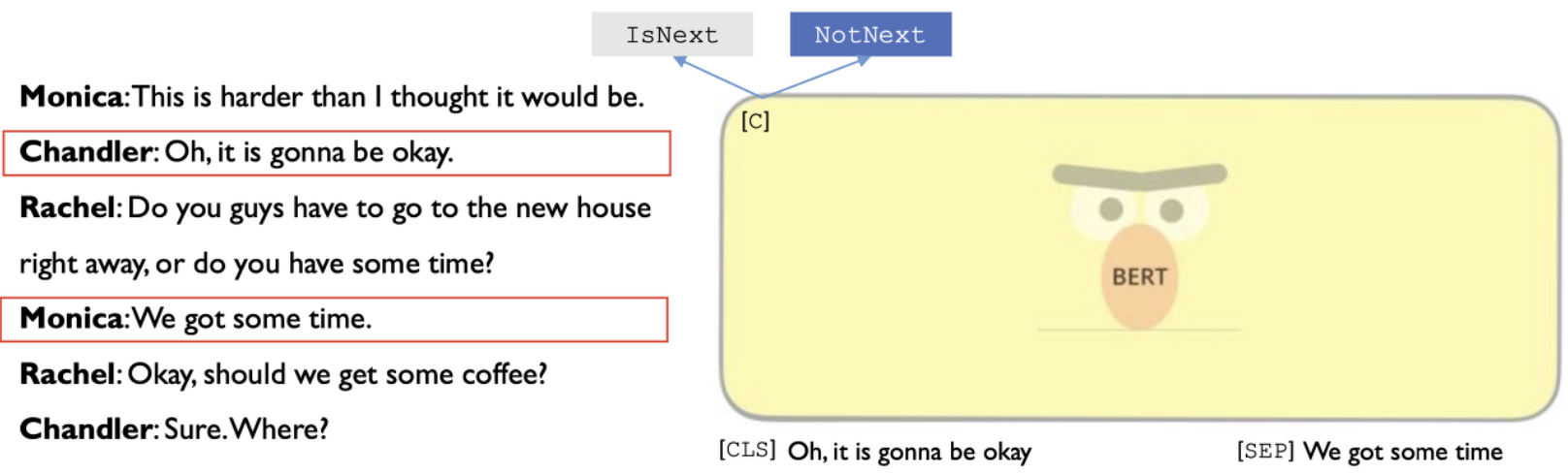
Task 2. NSP (Next Sentence Prediction)
선행 모델(ELMo, GPT)의 경우, 한 문장 단위로 학습을 했기 때문에 두 문장 사이의 관계 알아내기에는 부족하다. QA(Question Answering), NLI(Natural Language Inference) 등 많은 downstream task 들이 두 문장 사이 관계를 학습시켜야 한다. 문장 간 관계를 학습시키기 위해, pre-train시 binarized next sentence prediction task를 수행한다.
- Binarized NSP task
- 두 개의 문장이 실제로 corpus에서 연속된 문장인지 아닌지 판별하는 binary classification
- 두 문장의 관계를 알아야만 해결할 수 있는 task 에 대한 성능 높이는 데 큰 기여
 |   |
|---|
ELMo, GPT, BERT 모델 아키텍쳐 비교
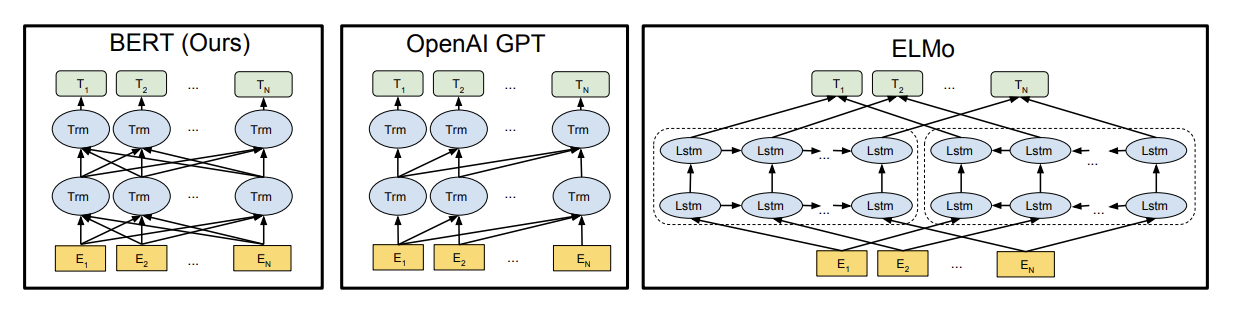
- BERT: Encoder를 이용해 양방향 학습, 일정 비율 random하게 masking
- GPT: Decoder를 이용해 한쪽 방향으로 학습
- ELMo: forward LSTM, backword LSTM 여러 단계 학습. hidden state를 전부 linear combination해서 최종 token 생성
Data(pre-training corpus)
- BookCorpus(800M), English Wikipedia(2,500M)
- 연속된 sequence를 추출하기 위해, sentence level corpus 보다 document level corpus 를 사용하는 것이 중요하다.
3-2 Fine-tuning
- 기존 모델이 두 문장 입력 처리시 사용한 방법: 각 문장을 독립적으로 encoding하고, 두 문장 사이 bidirectional cross attention 수행
- BERT에서는 이를 한 번에 처리 - 두 문장 입력을 하나의 sequence로 처리
- encoding a concatenated text pair with self-attention effectively includes bidirectional cross attention between two sentences
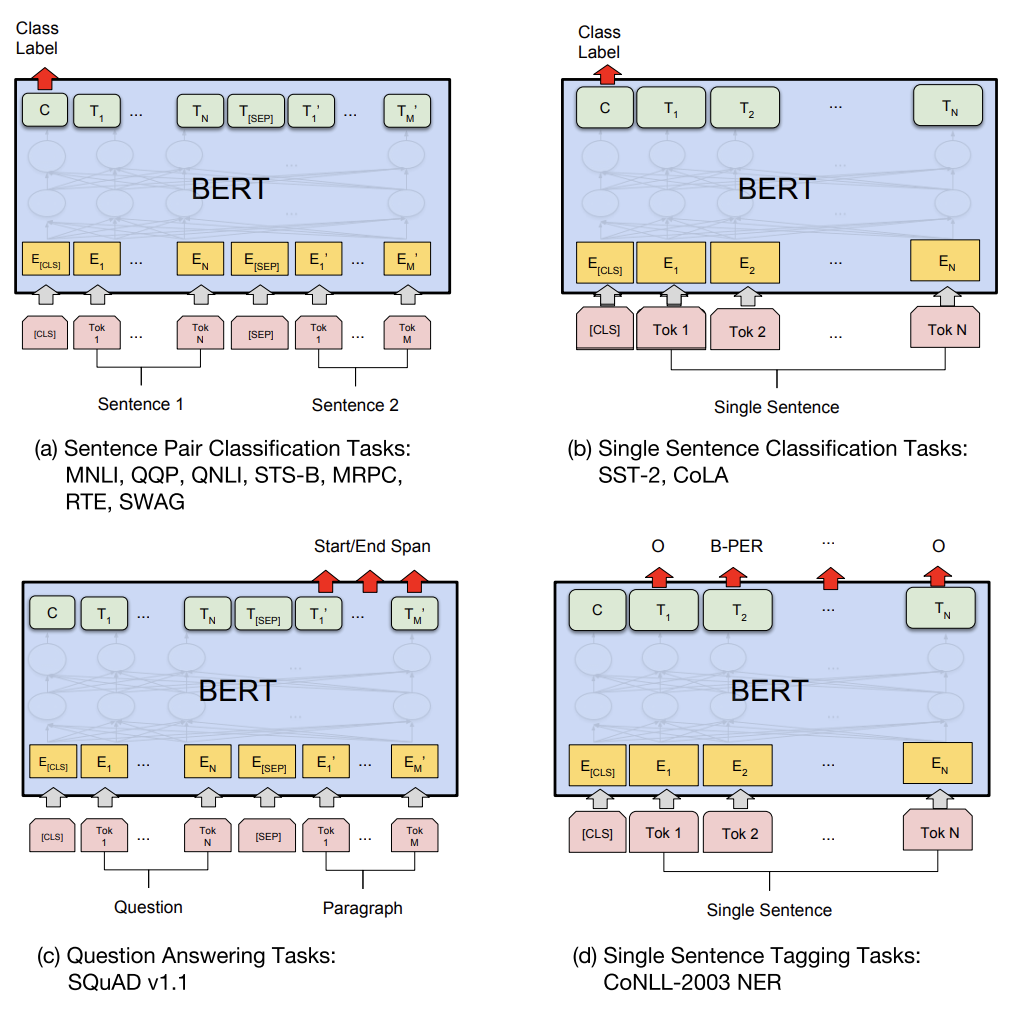 (a), (c): 입력으로 두 문장 받음.
(a), (c): 입력으로 두 문장 받음.
(b), (d): 입력으로 한 문장 받음.
(a), (b): 단순 classification
(c): 새로운 문장 생성
(d): 문장 tagging
- plug in the task-specific inputs and outputs into BERT -> fine tune all the parameters end-to-end
- pre-trained model 윗 단에 하나의 layer를 쌓는 것으로 fine-tuning 구현 가능
- Input: pre-training 단계의 문장 A, B -> Paraphrasing, Entailment 에서의 전제 - 가설, Question Answering에서의 질문 - 구절 등
- Output: token representation -> token-level task에 대한 output layer, [CLS] -> classification task 에 대한 output layer
4 Experiments
각 NLP task(GLUE, SQuAD, SWAG)를 위해 적용한 fine-tuning 방법 설명, SOTA 달성
5 Ablation Studies
일정 부분을 제거하면서 그 결과를 통해 해당 부분이 어떤 역할을 하는 지를 파악하는 실험
NSP vs No NSP
- vs No NSP 모델 (즉, MLM만 적용한 BERT 모델): BERT 모델이 결과가 좋음
- vs No NSP + LTR(Left To Right) 모델 (즉, MLM, NSP 둘 다 적용하지 않은 BERT모델): BERT 모델이 결과가 좋음 + 위 No NSP 모델보다 결과가 더 나쁨
따라서 MLM과 상관없이 NSP 학습이 효율적이라는 것을 증명할 수 있다.
MLM
- No NSP의 경우에는 위에서와 같이 MLM 적용한 모델이 더 효과적이었다.
- vs LTR BERT (NSP 만 적용한 BERT): 초기 수렴은 LTR BERT가 더 좋았지만, pre-training steps가 증가할수록 MLM이 LTR보다 더 좋은 결과를 얻음.
Model Size, Feature-based approach
- BERT-Large가 BERT-Base 보다 우수한 성능
- feature extraction 보다 fine-tuning 방법에서 우수한 성능 보임
BERT 등장의 의의
- Pre-training 을 통해 다양한 문제 해결에 좋은 결과를 냈다는 것이다.
- 다시 말해서, 대부분의 NLP 문제를 풀 때, 꼭 그 문제에 맞는 데이터로 훈련시키는 것이 아니라 일반적인 NLP 데이터로 사전학습을 시키고 이를 모델에 적용해도 좋은 결과를 낼 수 있다는 뜻
- BERT의 등장으로, 많은 논문들이 이 Pre-trained 모델을 활용해서 다양한 문제를 풀어냈다. 또한, 문제에 맞는 많은 데이터를 수집하기가 쉽지 않은데 BERT가 이런 데이터 부족 문제를 어느정도 해결해 줄 수 있다.
references
[CS182] Lecture 1: Introduction (Representation과 Deep Learning이란)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT 개념 쉽게 이해하기
