논문 리뷰 - CLIP(Learning Transferable Visual Models From Natural Language Supervision)
CLIP:
- 이미지와 텍스트를 같은 공간으로 보내서 multimodal representation learning을 수행하는 모델
- VL(Vision language) pretraining 분야의 새로운 패러다임
기존 기법 한계:
- 고정된 class label을 활용한 supervised learning은 이미지의 semantic 정보를 제대로 추출해내지 못함 (cf. 고정된 형태의 데이터: 특정 카테고리 내에서 간단하고 짧은 라벨 텍스트만 붙음)
- 충분히 성능 좋은 image, text encoder가 있음에도 불구하고, 필요한 정보들을 얻지 못한다는 것은 다양한 downstream tasks(Image retrieval, Image captioning, VQA 등..)에 적용하기 매우 힘듦 - 일반화 성능 부족
따라서, 이미지와 이 이미지를 설명하는 조금 더 상세한 텍스트(raw text)를 라벨로 사용한다면 기존의 컴퓨터 비전 데이터의 문제를 해결할 수 있을 것
- Large noisy web data(WIT) 구축 -> 기존의 NLP LLMs들이 주로 사용하던 대용량 데이터 셋을 활용한 representation learning 방법을 적용
- Text embedding과 Image embedding을 연결하는 새로운 방법을 제시함으로써, Crossmodality의 가능성 제시
- Zero-shot 성능 대폭 향상
Abstract & Introduction
CLIP은 위의 한계를 극복하기 위해 기존의 딱딱한 class label 기반 학습에서 벗어나, 보다 자유롭고 다양한 raw text data를 활용하고자 함
- 엄청난 크기의 dataset을 활용하는 LLMs(Large Language Models, like GPT)에서 아이디어를 차용
- 자연어처리 분야에서는 적은 양의 라벨이 붙은 고품질 데이터셋보다, 많은 양의 웹 상에서 수집된 라벨이 없는 데이터가 더 학습에 용이하게 사용됨
- 하지만, 컴퓨터 비전과 같은 분야에서는 적은 양의 라벨이 붙은 고품질 데이터셋을 이용해 학습함
- main idea: 자연어처리 분야처럼, 웹 상에서 수집된 테스트로부터 사전 학습을 하는 방식을 컴퓨터 비전 분야에 적용 -> 많은 양의 raw text data를 supervision으로 제공
- 4억개 가량의 raw (image, text) pair를 효과적으로 활용하기 위해서 Contrastive Learning 기법 사용
결과적으로 거대한 dataset으로부터 다양한 semantic 정보를 학습하고, 학습된 정보들을 서로 연결해주는 방법을 제시함으로써, gold-label을 활용한 supervised learning의 성능 뛰어넘음
2. Approach
2.1. Natural Language Supervision
자연어를 이용한 지시(Natural Language upervision)
- 이전에도 본 연구에서 사용한 방법론을 이용한 학습은 있어왔지만 각각 부르는 이름이 달랐음(unsupervised, self-supervised, weakly supervised, supervised ...)
- 자연어를 이용한 방법론의 이점
- scale을 키우기 쉬움(이전의 방법론에서는 scale을 키우기 위해서는 일일이 라벨링된 데이터를 많이 만들어야 했다.)
- 단순한 이미지 텍스트 표현이 아닌, 이미지에 대한 깊은 이해를 가능하게 함 -> 'zero-shot transfer' 가능
2.2. Creating a Sufficiently Large Dataset
충분히 큰 데이터셋 사용
- 이때까지의 연구들은 주로 세 가지 데이터셋을 사용
- MS-COCO
- Visual Genome
- YFCC100M
본 연구에서 만든 새로운 데이터셋(WebImageText, WIT):
- 약 4억개의 (image, text) 페어로 구성
- 모든 데이터는 인터넷에서 수집
- 데이터의 다양성을 얻기 위해, 5만 개의 텍스트 쿼리를 이용했으며, 하나의 쿼리에서 2만 개가 넘는 (image, text) 페어를 갖지 않도록 했다.
- 사용된 데이터셋의 총 단어 수는 GPT-2에서 사용된 WebText에서의 양과 유사하다.
2.3. Selecting an Efficient Pre-Training Method
2.4. Choosing and Scaling a Model
Image Encoder: ResNet-50, Vision Transformer
Text Encoder: Transformer
2.5. Training
CLIP은 학습 과정에서 2개의 encoder를 사용함
(1) 먼저 image, text encoder가 각 데이터를 인코딩하면 그들은 projection을 통해 같은 공간 상에 놓여진다.
(2) 그 후, 같은 공간에 놓여진 embedding vector끼리 contrastive learning을 진행한다. positive pair끼리의 코사인 유사도(cosine similarity)는 최대화하고, negative pair끼리의 유사도는 최소화
(3) 최종적으로, CE(Cross Entropy) Loss를 활용하여 Cross-modality 학습
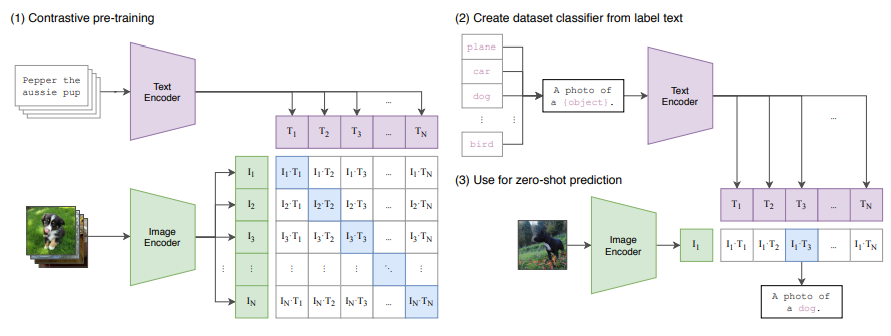

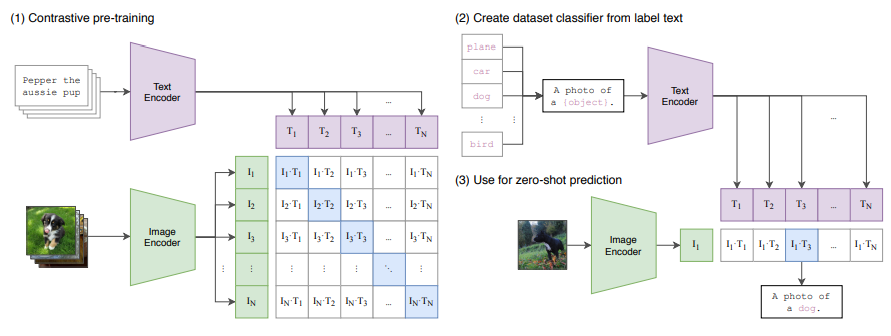
Contrastive pre-training
- 이미지 인코더와 텍스트 인코더를 사용하여 각 데이터를 벡터 공간에 매핑하는 과정
- 목적: 이미지와 그에 상응하는 텍스트 사이의 관계를 학습하여, 두 유형의 데이터가 동일한 의미를 공유하도록 하는 것
-
데이터 인코딩:
이미지 인코더는 주어진 이미지를 벡터로 변환한다. 이 벡터는 이미지의 시각적 특성을 나타낸다.
텍스트 인코더는 관련 텍스트(설명이나 라벨 등)를 벡터로 변환한다. 이 벡터는 텍스트의 언어적 특성을 나타낸다. -
벡터 공간 매핑:
인코딩된 이미지 벡터와 텍스트 벡터는 같은 벡터 공간에 배치된다. 이는 두 인코더가 출력하는 벡터들이 서로 비교가능하도록 만들기 위함이다. -
대조 학습:
긍정 쌍: 서로 관련 있는 이미지와 텍스트의 경우, 이 둘 사이의 코사인 유사도를 최대화한다. 즉, 관련 있는 쌍의 벡터 각도를 가깝게 하여 유사도를 높인다.
부정 쌍: 관련 없는 이미지와 텍스트의 경우, 이들 사이의 코사인 유사도를 최소화한다. 즉, 관련 없는 쌍의 벡터 각도를 멀어지게 하여 서로 다르게 인식되도록 한다.
3. Experiments
- 일반적으로 Image classification task의 class는 단일 라벨로 구성되어 있지만, CLIP의 text data는 짧은 문장으로 구성되어 있다.
- 단일 라벨의 경우, 충분한 semantic 정보를 포함하지 못 할 뿐만 아니라 다의성을 가질 문제도 존재하기 때문에 약간의 수정을 거쳐 text encoder에 삽입하게 된다.
- image encoder를 거쳐서 나온 feature는 text encoder의 결과들과 유사도 계산을 하게 되고, 최종적으로 가장 유사도가 높은 클래스를 정답으로 반환한다.
- 이와 같이 text prompt의 문장 형식을 조정하는 것을 'Prompt Engineering'이라고 부른다.
3.1. Zero-Shot Transfer
- zero-shot transfer: 학습 때 사용하지 않은 데이터셋에 대해 image classification을 하는 태스크
- "A photo of a {label}"과 같은 형식의 prompt를 default로 사용
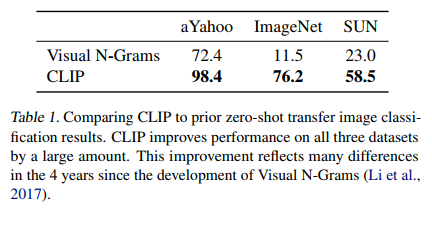 | 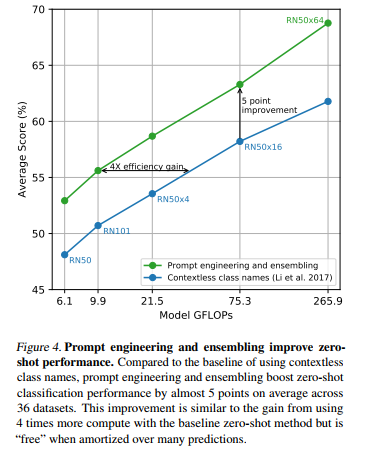 |
|---|
Image classification task에 대한 zero-shot 성능과 prompt engineering의 효과: 기존에 비해 Zero-shot 성능 향상
 |  |
|---|
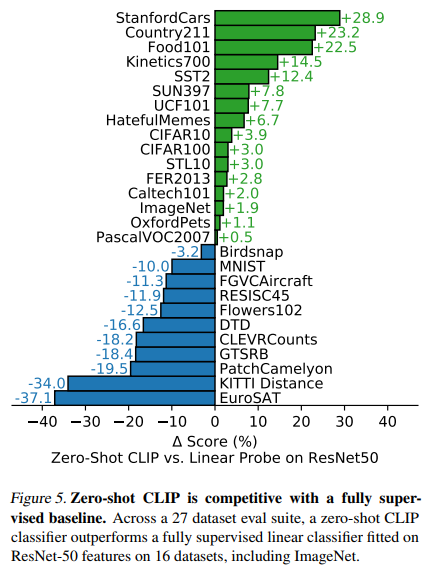
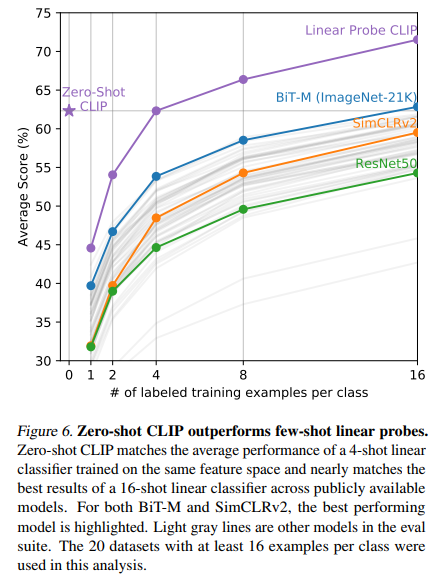
왼쪽은 Fully supervised, 오른쪽은 few-show methods와 Zero-shot CLIP을 비교한 그림
- 몇몇 데이터 셋에 대해서는, 아직 fully supervised method가 우세
- EuroSAT과 같이, fine grained detail을 잡아내는 능력이 필요한 데이터 셋에 대해서는 아직 성능이 부족한 것처럼 보임
- few-shot methods 보다는 확실히 더 좋은 성능
 |  |
|---|
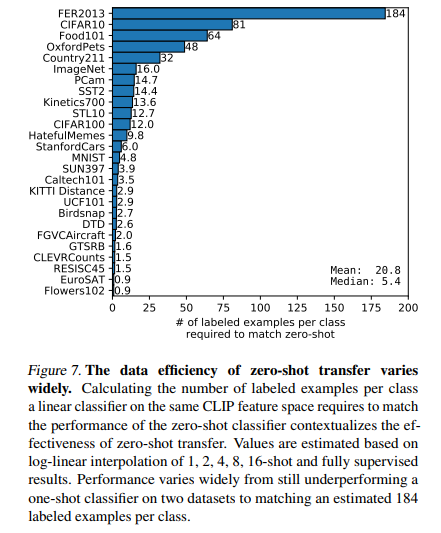
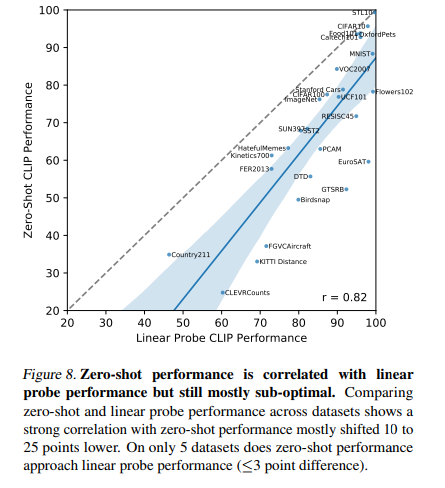
3.2 Representation Learning
Downstream tasks에 적용하기 위해서는, 결국 image feature를 잘 뽑는 것이 중요하다.
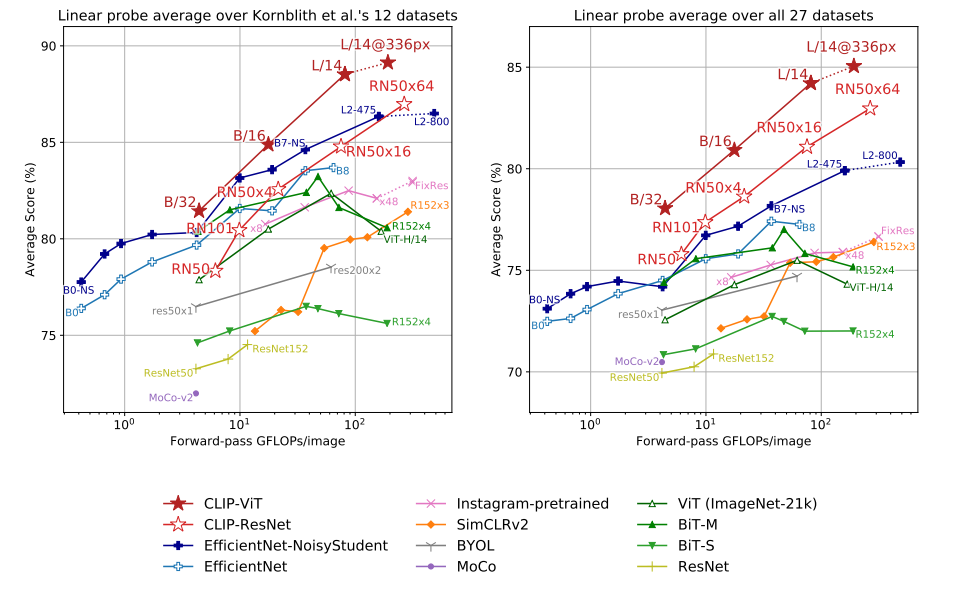
모든 크기에서 CLIP모델이 다른 모델보다 좋은 성능을 냈다.
Limitations
- 특정 태스크에서는 CLIP이 여전히 좋지 않은 성능을 보임
- 태스크가 복잡한(fine-grained classification) 경우 조금 더 성능 저하가 심했다.
- CLIP은 인터넷 상에서 가져온 (image, text) 페어를 통해 학습되었는데, 필터링이 되지 않아 social biases를 그대로 학습할 수 있다. (LLM의 근본적인 한계점인 bias 문제)
- 앞선 human performance와 비교 실험에서 살펴보았듯이, CLIP에서 zero-shot 성능을 더욱 상승시킬 수 있는 few-shot 방법에 대해 후속 연구가 필요하다.
references
[논문 리뷰] CLIP: Learning Transferable Visual Models From Natural Lanugage Supervision
[21′ PMLR] Learning Transferable Visual Models From Natural Language Supervision (CLIP)
