- Convolutional Neural Network, 합성곱 신경망
- 인간의 시신경 구조 모방
📌 CNN 구조
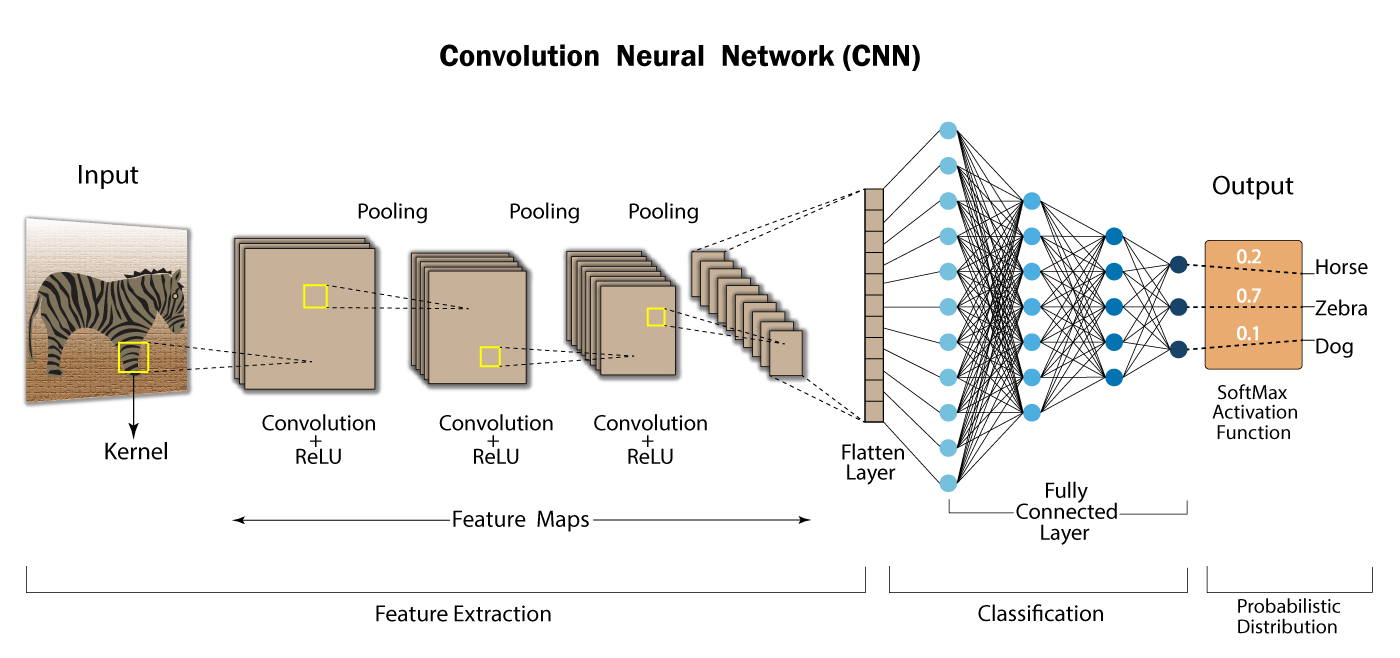
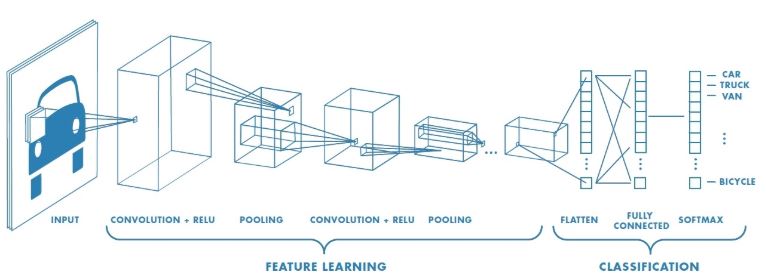
Convolutional layer: 패턴들을 쌓아가며 점차 복잡한 패턴을 인식한다.
Max pooling: 사이즈를 줄여가며, 더욱 추상화 해나간다.=> CNN: Convolution과 Pooling을 반복적으로 사용하면서 불변하는 특징을 찾고, 그 특징을 입력 데이터로 fully-connected 신경망에 보내 classification 수행
특징 추출(Feature learning/extraction) 영역, 이미지 분류(classification) 영역으로 구분됨
- 특징 추출 영역:
Convolutional layer와Pooling layer를 여러 겹 쌓는 형태로 구성- Convolutional layer: 입력 데이터에 필터를 적용 후 활성화 함수를 반영(필수 layer)
- Pooling layer: (선택 layer)
- 이미지 분류 영역:
Fully Connected Layer추가
📚 Convolutional(합성곱) layer
convolution: 특정 패턴이 있는지 박스로 훑으며 마킹
- convolution 박스로 밀고 나면, 숫자가 나온다. 그 숫자를 activation(주로 ReLU)에 넣어 나온 값으로 이미지 지도를 새로 그린다.
Color 이미지는 3D

이미지 데이터는 높이x너비x채널의 3차원 텐서(tensor)로 표현된다. 만약 이미지의 색상이 RGB 코드로 표현되었다면, 채널의 크기는 3이 되며 각각의 채널에는 R, G, B값이 저장된다.
Filter 적용
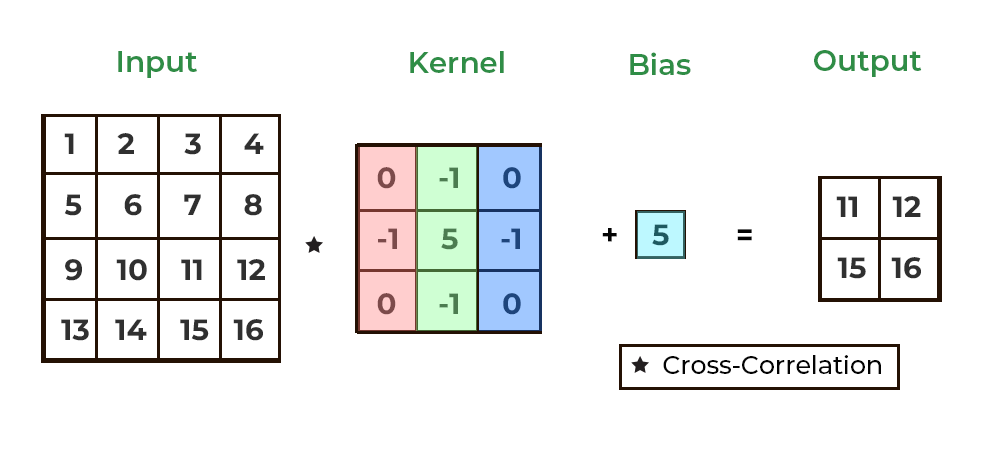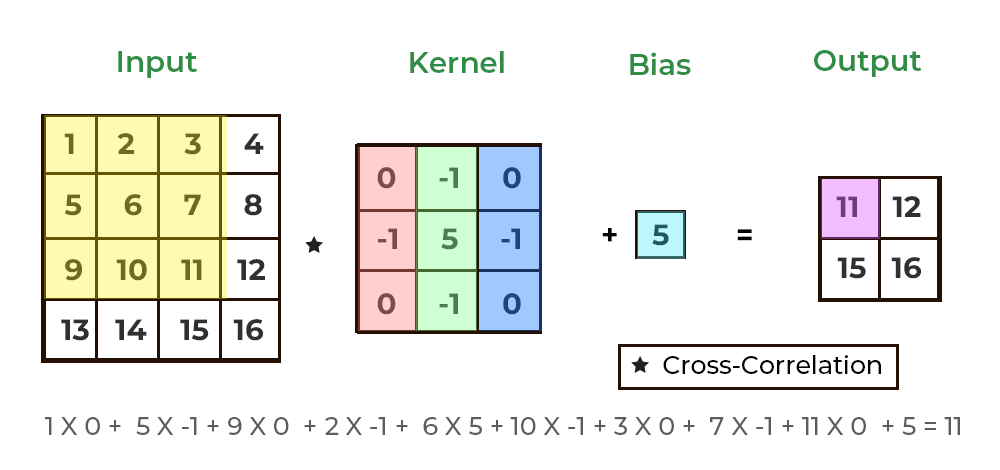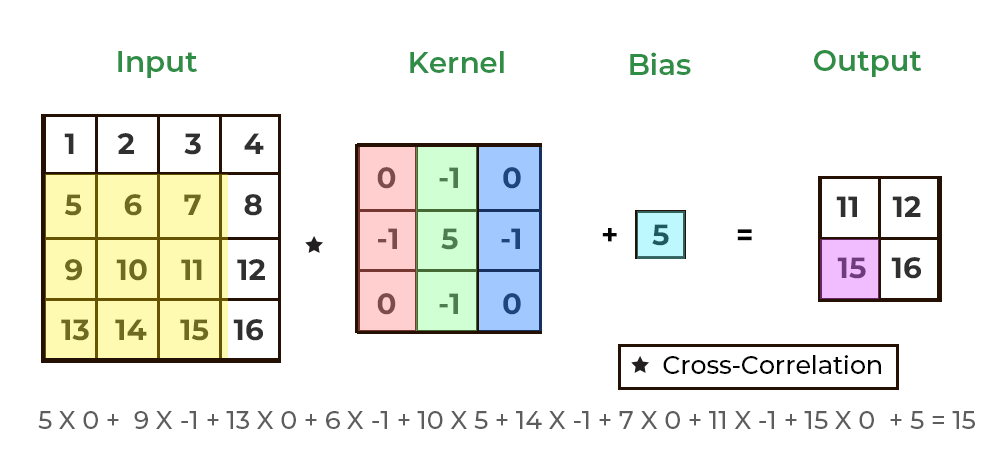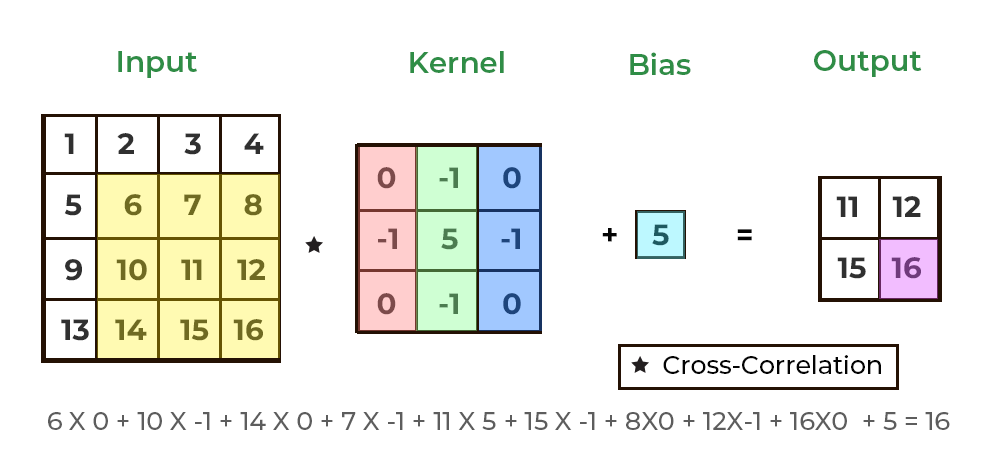
하나의 convolution layer에는 입력되는 이미지의 채널 개수만큼 필터가 존재하며, 각 채널에 할당된 필터를 적용함으로써 convolution layer의 출력 이미지가 생성된다. 예를 들어, 높이x너비x채널이 4x4x1인 텐서 형태의 입력 이미지에 대해 3x3 크기의 필터를 적용하는 convolutional layer에서는 그림과 같이 이미지와 필터에 대한 합성곱 연산을 통해 2x2x1 텐서 형태의 이미지가 생성된다. 합성곱을 통해 생성된 행렬 형태의 이미지에 bias라는 스칼라값을 동일하게 더하도록 구현되기도 한다.
Stride
필터의 이동량을 의미. CNN을 구형할 때 convolutional layer의 stride는 주로 1로 설정된다.
Padding

convolutional layer를 거치면서 이미지의 크기는 점점 작아지고, 이미지 가장자리의 픽셀 정보는 점점 사라진다. 패딩은 입력 이미지의 가장자리에 특정 값으로 설정된 픽셀들을 추가함으로써 입력 이미지와 출력 이미지의 크기를 같거나 비슷하게 만드는 역할을 수행한다. like 염색체 텔로미어
- zero-padding: 0으로 채움
📚 Pooling layer

적당히 크기를 줄이고, 특정 feature를 강조하는 layer.
처리 방법 세 가지:
- max pooling - CNN에서 주로 사용
- average pooling
- min pooling

dropout
overfitting 방지 - 학습시킬때 일부러 정보를 누락시키거나 중간중간 노드를 끔.
📚 Fully Connected Layer
2가지 종류
- Flatten layer: 데이터 타입을 fully connected 네트워크 형태로 변경. 입력 데이터의 shape 변경
- Softmax layer: classification
📌 모델 발전
모델 목표:
더 깊은 네트워크를 만들면서, 성능을 높여간다.모델 목표를 위해 중요한 것:
어떻게 학습능력을 높여서 더 깊은 네트워크를 학습했는가
학습능력을 높이는 방법:
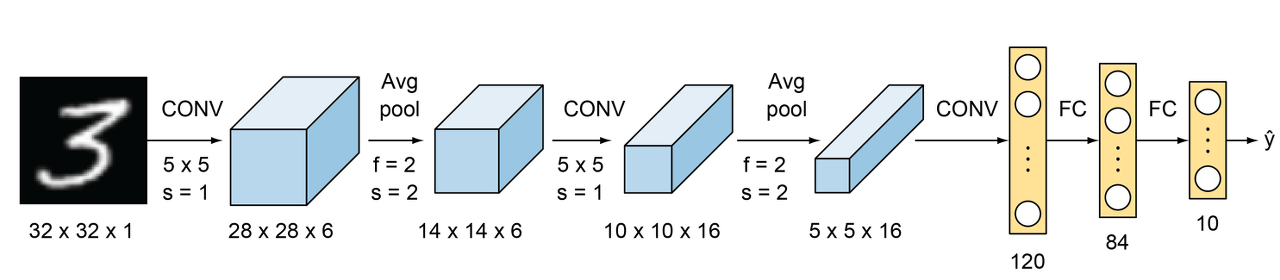
1. LeNet-5 (1998): CNN 적용하면서, 깊은 네트워크(4 layer) 학습하여 성능 상승
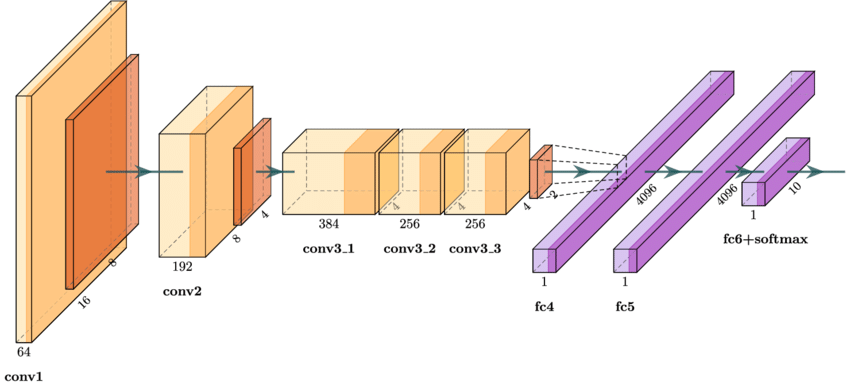
2. AlexNet (2012): GPU, ReLU함수 사용하면서, 깊은 네트워크(8 layer) 학습하여 성능 상승
3. ZFNet (2013): 하이퍼파라미터 최적화하면서, 깊은 네트워크(8 layer) 학습하여 성능 상승
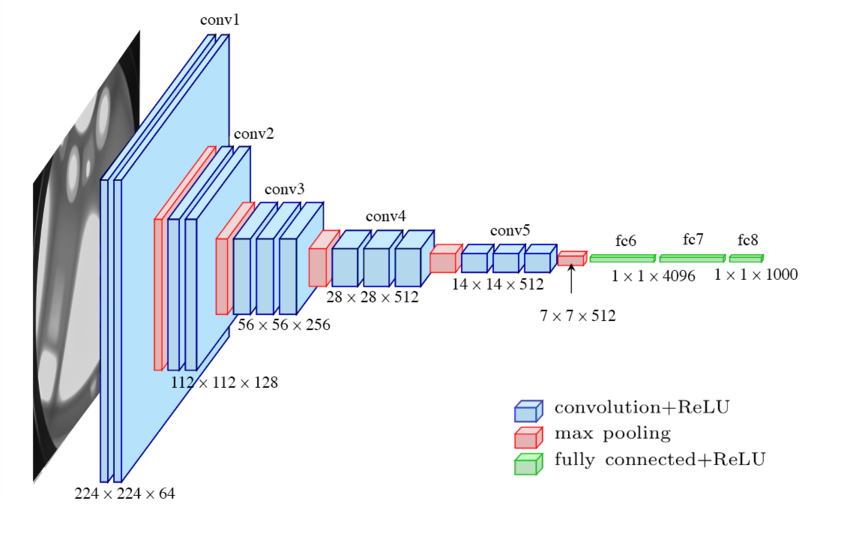
4. VGGNet (2014): 작은 필터 수(3x3) 규칙적으로 적용하면서, 깊은 네트워크(19 layer) 학습하여 성능 상승
5. GoogLeNet (2014): Inception 모듈 적용하여 효율성 높이면서, 더 깊고 넓은 네트워크(22 layer) 학습하여 성능 상승
6. ResNet (2015): Skip connection 적용하여 기울기 소실 문제 해결하면서, 매우 깊은 네트워크(152 layer) 학습하여 성능 상승
7. InceptionResNetV2 (2016): Inception 아키텍쳐와 ResNet 결합
8. DenseNet (2016): 진화된 Skip connection과 bottleneck layers을 적용하면서, 알짜배기 feature만 가진 매우 깊은 네트워크를 학습하여 성능 상승
9. Xception (2017): Inception 아키텍쳐를 발전시켜 깊이별 분리 합성곱 사용
10. MobileNetV1 (2017)
11. EfficientNet (2019)
LeNet-5
AlexNet
VGGNet
GoogLeNet (=InceptionNet)
ResNet
DenseNet
출처: 출처1, 출처2, tensor, convolutional filter
