왜 정규식을 쓰는걸까?
개발을 하다보면 꽤나 많이 데이터를 가공해서 저장을 하게 되는데, 그럴때 유용한게 바로 regular expression(정규식)이다. 예를들어, 어떤 기업에서는 전화번호를 010-xxxx-xxxx식으로 저장할것이고, 어떤 기업에서는 +82 10-xxxx-xxxx식으로 저장되어 있을것이다.
하지만 자사의 DB는 이미 11자리 숫자(예:010xxxxxxxx)로 저장이 되어있고, 이걸 통합해야할 경우, 유용한게 정규식이다.
또, 유저로부터 정보를 받아올때 이메일만 입력받고 싶은 경우, 주민번호 유효성을 검사할때 등 미리 알아두면
function replace(string) {
const withOutDash = string.replace("-","")
const withOutContryNumber = withOutDash.replace("+82 ", "")
return withOutCountryNumber
}같은 무한 replace를 안써도 된다.
쓰는 방법
Anchors : ^ and $
^The The로 시작하는 모든 문자열을 매칭
end$ end로 끝나는 문자열과 매칭
abc abc가 들어있는 모든 문자열과 매칭Quantifiers : *+?and{}
abc* ab 그리고 0개 이상의 c 를 포핳한 문자열과 매칭
abc+ ab 그리고 1개 이상의 c 를 포함한 문자열과 매칭
abc? ab 그리고 0개 또는 1개의 c를 포함한 문자열과 매칭
abc{2} ab 그리고 2개의 c를 포함한 문자열과 매칭
abc{2,5} ab 그리고 2개 이상 5개 이하의 c를 포함한 문자열과 매칭
a(bc)* a 그리고 0개 이상의 bc를 포함한 문자열과 매칭
a(bc){2,5} a 그리고 2개 이상 5개 이하의 bc를 포함한 문자열과 매칭OR operator : | or []
a(b|c) a 그리고 b 또는 c를 포함한 문자열과 매칭
a[bc] 위와 동일Character classes : \d \w \s
\d 숫자 하나와 매칭
\w 문자 하나와 매칭
\s 공백문자 하나와 매칭
. 모든 문자 하나와 매칭
Grouping and Captureing : ()
a(bc) 소괄호는 캡쳐 그룹을 생성Bracket Exppression : []
[abc] a 또는 b 또는 c를 포함하는 문자열과 매칭
[a-c] 위와 동일
[a-zA-Z0-9] 영문과 숫자 하나와 매칭하고, 대소문자를 구분하지 않음많이 사용하게 되는 예제
핸드폰 정규식
const regExp = /^\d{3}-\d{3,4}-\d{4}$/;
일반번호 정규식
const regExp = /^\d{2,3}-\d{3,4}-\d{4}$/;
이메일 정규식
const regExp = /^[0-9a-zA-Z]([-_.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_.]?[0-9a-zA-Z])*.[a-zA-Z]{2,3}$/i;
비밀번호 정규식 (특수문자 / 문자 / 숫자 포함 형태의 8~15자리 이내의 암호)
const regex = /^.*(?=^.{8,15}$)(?=.*\d)(?=.*[a-zA-Z])(?=.*[!@#$%^&+=]).*$/;
비밀번호 정규식 (숫자와 문자 포함 형태의 6~12자리 이내의 암호)
const regex = /^[A-Za-z0-9]{6,12}$/;
한글만 정규식 (ㄱ,ㄴ,ㄷ,ㄹ,ㅁ 이런건 제외)
const regex = /^[가-힣]+$/
모든 한글 정규식 (ㄱ,ㄴ,ㄷ,ㄹ 가능)
const regex = /[ㄱ-ㅎ|ㅏ-ㅣ|가-힣]/;
영어만 정규식
const regex = /^[a-zA-Z]+$/
URL 정규식
const regex = /https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{2,256}\.[a-z]{2,6}\b([-a-zA-Z0-9@:%_\+.~#()?&//=]*)/
숫자만 정규식
const regExp = /[0-9]/g;
특수문자 정규식
const regExp = /[\{\}\[\]\/?.,;:|\)*~`!^\-_+<>@\#$%&\\\=\(\'\"]/g;
모든 공백 체크 정규식
const regExp = /\s/g;
해석을 통한 예제
핸드폰 정규식
const regExp = /^\d{3}-\d{3,4}-\d{4}$/;
^: 시작하는
\d: 숫자로
{3}: 3개의
"-": -가 들어가고
\d: 숫자를 포함한
{3,4}: 3~4개의
"-": -가 들어가고
\d : 숫자
{4} : 4자리
$ : 로 끝나는
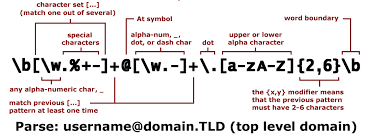
해당 조건을 충족하는 문자열을 반환하는 정규식이메일 정규식
const regExp = /^[0-9a-zA-Z]([-_.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_.]?[0-9a-zA-Z])*.[a-zA-Z]{2,3}$/i;
^[0-9a-zA-Z] : 숫자나 대소문자를 포함한 문자열과
( : 문자열 시작
[-_.]? : 0개나 1개의 -,_을 포함한
[0-9a-zA-Z] : 숫자나 대소문자를 포함한 문자열
) : 문자열 끝
* : 0개 이상의 문자열
"@" : @를 포함
이게 두번 반복되고,
[a-zA-Z]{2,3} : 대소문자 2 ~ 3개를 포함
해당 조건을 충족하는 정규식
정리하자면,
당연하겠지만, 이미 자주 쓰는 정규식은 웹 서치를 통해서 쉽게 찾을 수 있다. 하지만 웹 스크래핑을 할 경우, 데이터가 내가 원하는대로 가공되어 있는 경우는 찾기가 거의 힘들다. 그럴때마다 내가 원하는 형식의 데이터로 저장을 하고 싶은 경우 굉장히 유용한게 정규식이다.

공유하고 나누는걸 좋아하는 개발자