
💻 코딩 테스트
c++ 람다 캡쳐
C++ 의 람다식에서는 기본적으로 람다 외부 변수를 사용할 수 없으므로 캡쳐 를 통해
외부 변수를 선언해주어야 한다.
int ext_index = str_to_index(ext);
int sort_by_index = str_to_index(sort_by);
for(vector<int> vec : data)
{
if (vec[ext_index] < val_ext)
answer.push_back(vec);
}
sort(answer.begin(), answer.end(),
[sort_by_index](vector<int> a, vector<int> b) {
return a[sort_by_index] < b[sort_by_index];
}
);정렬을 위해서는 람다식의 변수가 필요했으므로 sort_by_index 라는 변수를 캡쳐를 통해
가져와 사용하였다.
🌿 자바 / Spring
생성자 주입 방식
- 주입 받아야 하는 객체의 변수를 final 로 작성
- 생성자를 이용해서 해당 변수를 생성자의 파라미터로 지정한다.
생성자 주입 방식은 객체를 생성할 때 문제가 발생하는지를 미리 확인할 수 있기 때문에
필드 주입이나 Setter 주입 보다 선호되는 방식이다.
Lombok 을 통해 간단히 작성 가능
@Service
@RequiredArgsConstructor
public class SampleService {
private final sampleDAO sampleDAO;
}간단히 얘기하자면
필드 주입 은 한번 정하게 되면 수정 불가,
수정자 주입 은 public 으로 노출 가능
생성자 주입 은 객체 생성 시 1회만 호출 가능하며,
순수 자바만을 통한 테스트 코드 작성등의 이점을 가지게 된다.
- 주입 받아야 하는 객체의 변수를
final로 작성 - 생성자를 이용해서 해당 변수를 생성자의 파라미터로 지정한다.
생성자 주입 방식은 객체를 생성할 때 문제가 발생하는지를 미리 확인할 수 있기 때문에
필드 주입이나 Setter 주입 보다 선호되는 방식이다.
Lombok 을 통해 간단히 작성 가능하며 그 방법은 다음과 같다.
@Service
@RequiredArgsConstructor
public class SampleService {
private final sampleDAO sampleDAO;
}인터페이스를 이용한 느슨한 결합
@Service
@RequiredArgsConstructor
public class SampleService {
private final sampleDAO sampleDAO;
}위의 상황에서 sampleDAO 를 다른 객체로 변경하게 되면 SampleService 또한 수정되어야 한다.
그러나 이는 추상화된 타입을 이용해 수정할 수 있다.
public interface SampleDAO {
}@Repository
public class SampleDAOImpl implements SampleDAO {
}SampleService 입장에서는 인터페이스만 바라보고 있기 때문에 실제 객체가 SampleDAOImpl
의 인스턴스인지 알 수 없으며 SampleDAOAA 로 바뀐다고 해도 아무런 문제가 없다.
이처럼 객체와 객체의 의존 관계의 실체 객체를 몰라도 가능하게 하는 방식을 느슨한 결합이라고 한다.
그러나 객체가 만약 SampleDAOImpl 와 EventSampleDAOImpl 와 같이 같은 인터페이스에 대한
구현체를 2개로 생성할 경우 SampleService (스프링의) 입장에서는 어떤 것을 주입해야 할지
알 수 없기 때문에 @Primary 와 @Qualifier 와 같은 어노테이션을 사용한다.
🛞 도커 / 쿠버네티스
쿠버네티스 네트워크 연결
파드 내부 컨테이너끼리 통신
하나의 파드 내부에서 통신을 하는 일은 사이드카 패턴을 제외하고는 드물게 사용된다.
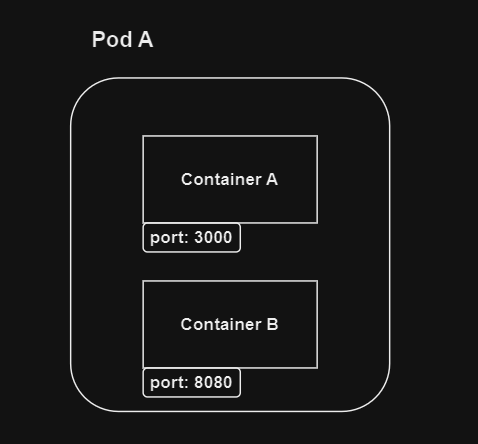
파드는 쿠버네티스의 가장 작은 단위의 오브젝트이므로 같은 파드에 속해있는 컨테이너는
모든 저장공간가 네트워크 인터페이스를 공유하게 되므로 별다른 네트워크 설정없이
port 를 통한 통신이 가능하다.
파드와 파드 사이의 통신
파드가 재생성되는 일은 쿠버네티스 사용에 있어 흔하게 발생되는 일이며
이때 파드에 부여되는 이름과 IP 는 매번 달라질 수 있으며
어떠한 Pod A-SDFW1와 Pod B-DE123B 통신이 필요할 때 Pod A 와 Pod B 의 계속 바뀌는 이름과 IP, 포트를 파악하여 애플리케이션에 이를 계속 바뀔 때 명시해주는 것은 어려운 일이다.
따라서 이때 사용되는 것이 Service 이다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: backend # 배치된 파드 중 셀렉터가 app: backeend 인 파드를 서비스 대상으로 포함
ports:
- protocol: TCP
port: 8080 # 이 서비스가 8080번 포드로 클러스터에 노출한다.
targetPort: 8080 # 이 서비스를 대상 파드의 8080 포트에 연결한다.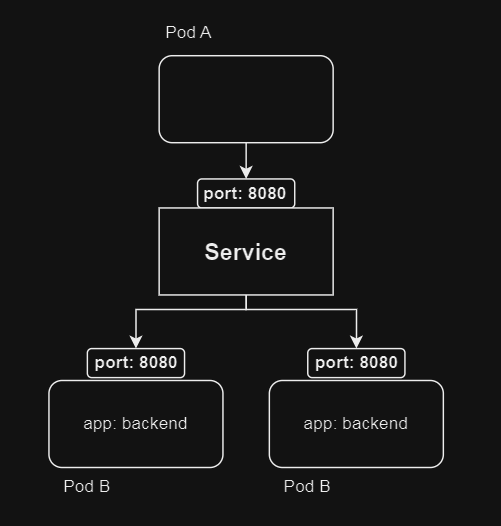
selector 를 통해 명시한 대상과 일치하는 파드를 묶게 되고 Service 를 통해
Pod 간의 통신이 가능해진다.
그럼 Pod 를 고르는 기준은?
기본적으로 서비스는 RR (라운드 로빈) 방식을 사용하고 이와 다른 방법을
사용하고 싶다면 Istio 나 다른 서비스를 이용해야 한다. (추후 다룰 수 있다면 다뤄보기)
클러스터 외부에서 파드를 호출하는 방법
Service
쿠버네티스가 서비스를 생성하게 되면 기본적으로 ClusterIP 를 가지게 되므로
서비스는 클러스터 내부 IP 주소를 부여 받게 되는 것이다.
그러나 이는 내부 주소 이기 때문에 외부에서 해당 서비스에 접근해서
파드의 (파드의 애플리케이션에) 접근하는 것은 불가능하다.
따라서 이때 사용할 수 있는 방법은 Service 타입을 NodePort 로 설정하는 것이다.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app: this-is-my-app
ports:
- protocol: TCP
port: 8080
targetPort: 8080
nodePort: 32500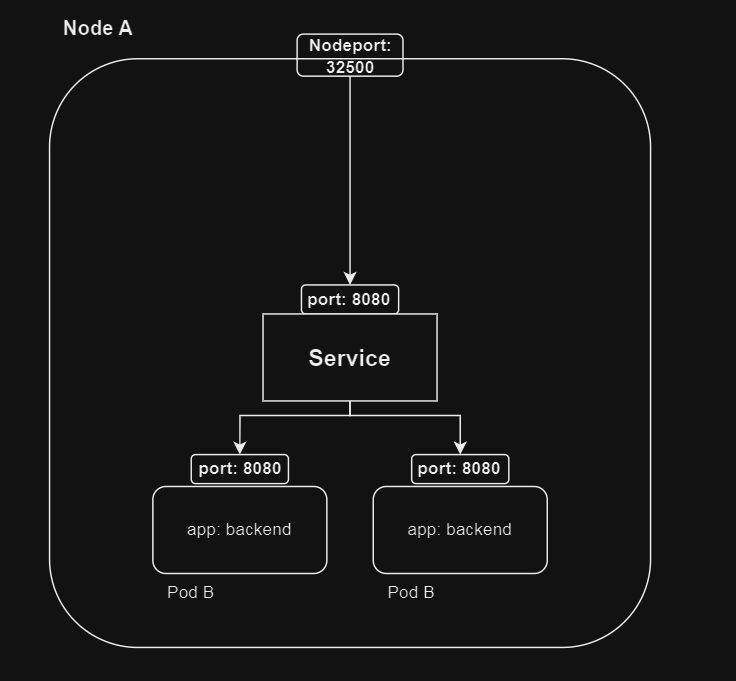
이를 통해 만약 Node A 의 서비스에 접근하고자 한다면
curl localhost:32500/api/healthcheck으로 외부에서 접근이 가능하게 된다.
그러나 이는 서비스를 생성할 때마다 매번 NodePort 번호를 적고 명시해줘야 하는 번거로움이
있으므로 공인 IP 나 도메인 주소, 쿠버네티스 자체 Load Balancer 를 활용하거나 클라우드
서비스의 로드 밸런서를 사용하는 방법이 있다. (AWS NLB, ALB 등등)
Ingress
클러스터 외부에서 오는 트래픽은 경로 (Path) 혹은 호스트 (Host) 에 따라 다른 서비스로
트래픽을 전달해준다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
spec:
ingressClassName: nginx
rules:
- host: "myapp.mydomain.com"
http:
paths:
- path: /users
pathType: Prefix
backend:
service:
name: Service-A
port:
number: 3000
- path: /
pathType: Prefix
backend:
service:
name: Service-B
port:
number: 3000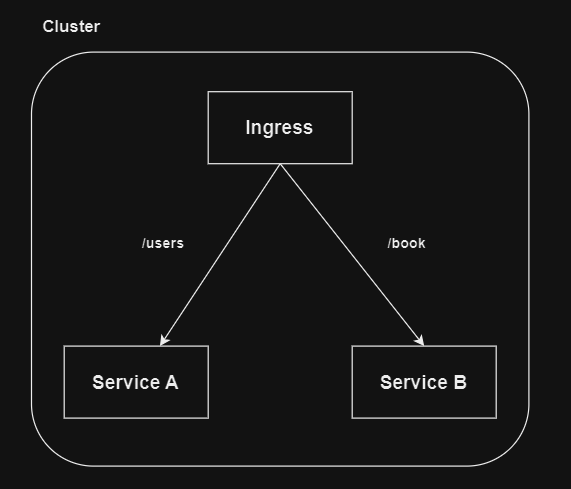
Ingress 는 NodePort나 LoadBalancer 와 같은 서비스와 달리 경로나 호스트 기반의 HTTP 요청을 세밀하게 제어할 수 있다. (Ingress 는 Service 에 포함되지 않는 독립적인 오브젝트이다.)
주로 MSA 나 요청이 주로 HTTP 로 이루어진다면 Ingress 를 통한 네트워크 구현이 적절할 수 있다.
🍚 누룽지
공부할 주제를 정했으면 공부하기 위한 것들은 우선 집히는 것부터!
프로젝트가 끝나고 이제 취준을 하는 동안 다시 스스로 공부해야되는 상황이므로
위의 적은 주제들을 위주로 공부해야 될텐데 이걸 공부하기로 했으면 어떻게 공부할지를 고민하기보다는 빠르게 일단 손에 가장 빨리 잡히는 걸로 시작하는게 좋은 것 같다!
책이나 강의나 인터넷 자료를 고르던 결국 내가 알고있는 건 쓰윽 보면서 넘어가면 되는 거고
모르는 건 상황에 맞게 찾아가면 되는거니께 🫡
