
💻 코딩 테스트
수열의 합은 가우스 공식
위의 문제는 사실상 N * (1 ~ M) 을 구하는 문제이므로 반복문을 사용할 필요도 없이
가우스 공식으로 1 ~ N 까지의 합은 N * (1 + N ) / 2 으로 구할 수 있다.
- 그냥 for 문으로 합 구하기
using namespace std;
long long solution(int price, int money, int count)
{
long long answer = -1;
long long pay = 0;
for(int i = 1; i <= count; i++)
{
pay += price * i;
}
answer = pay - money;
if (answer <= 0)
return 0;
return answer;
}- 가우스 공식으로 합 구하기
#include <bits/stdc++.h>
using namespace std;
long long solution(int price, int money, int count)
{
long long required = 1LL * price * count * (count + 1) / 2;
return required <= money ? 0 : required - money;
}🛞 도커 / 쿠버네티스
쿠버네티스를 활용한 애플리케이션 개발 사례
쿠버네티스를 사용한 애플리케이션 개발로 관련 모범 사례를 정리해보자.
애플리케이션의 세션 처리
만약 쿠버네티스 클러스터에 백엔드 서버가 여러 개 존재하는 경우
즉, 여러 개의 (Spring) 백엔드 서버 Pod가 띄워진 상황에서는
유저의 정보의 집합인 세션을 처리하는 것은 어려울 수 있다.
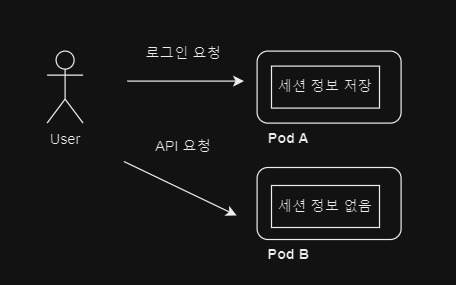
다음과 같이 API 요청이 처음 로그인을 요청한 Pod A가 아닌 Pod B 로 향할 경우
Pod B 에는 유저에 대한 세션 정보가 없기 때문에 로그인을 했음에도 올바른 동작을 수행할 수 없다.
이러한 문제를 해결하고자 쿠버네티스에는
스티키 세션 (sticky session) 을 통한 세션 어피티(session affinity) 를 사용할 수 있다.
말그대로 처음 요청한 IP 에 따라 Pod 를 지정하여 요청 경로를 고정하는 기법이다.
그러나 이 방법은 파드의 숫자가 자주 줄어들고 늘어나는 쿠버네티스의 특성으로
유연한 대응이 어려울 수 있다.
만약 부하가 늘고 줄어듬에 따라 파드가 재생성되고 없어지는 과정에서 세션 정보를 가진
Pod 가 재생성되거나 삭제되면서 세션 정보를 유지하지 못하는 경우 사용자는 로그인을 했음에도
강제 로그아웃 혹은 권한 에러를 겪게 될 수 있다.
그래서 이를 해결하고 세션 저장소를 통한 세션 처리 를 하게 된다.
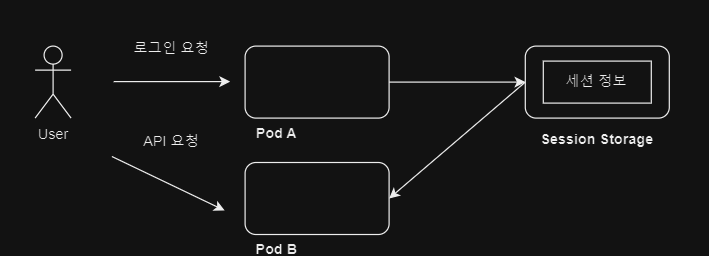
Redis 와 같은 세션 저장소를 통해 별도의 세션을 저장하는 공간으로 파드의 주기와 관계 없이
세션을 저장하고 액세스하여 세션 처리가 가능해진다.
다만, 서버의 직접 세션을 저장하는 것보다는 처리 성능이 떨어질 수는 있지만 캐시와 같은
메모리 기반의 데이터 저장소를 활용하는 등의 방법으로 성능 손실을 최소화할 수도 있다.
또한 세션 저장소에 대한 트래픽이 몰리는 경우 세션 저장소 또한 클러스터링과 복제 설정 등을
고려할 수 있다.
네임스페이스를 이용한 개발환경 구분하기
쿠버네티스의 장점 중 하나는 클러스터의 자원을 유연하게 여러 애플리케이션에 할당하며
사용할 수 있다는 점이다.
그래서 마스터 노드에서 사용되는 자원과 스케일 업에 대비해 부여한 여유 리소스를 생각한다면
하나의 클러스터에 한 개의 애플리케이션을 실행하는 것은 자원 낭비일 수 있다.
그렇다고 하나의 클러스터에 아무런 구분 없이 여러 애플리케이션을 실행시킨다면
특정 서비스에 대한 파드를 조회하거나 모니터링을 하는 등의 작업 혹은
관련 서비스의 오브젝트들을 삭제 혹은 변경하는 것에서 어려움을 겪을 수 있다.
따라서 이때는 namespace 를 사용한 서로 다른 애플리케이션을 구분할 수 있다.
namespace 구분을 통해 오브젝트를 한번에 삭제 혹은 재생성할 수 있고
리소스 할당과 애플리케이션 별 오브젝트 조회를 구별하기 쉬워진다!
