Apache Kafka란?
: 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 설계된 오픈 소스 분산 이벤트 스트리밍 플랫폼(distributed event streaming platform)
이벤트 스트리밍
: 인체의 중추 신경계에 해당하는 디지털 처리 방식
-
비즈니스가 점점 더 소프트웨어화, 자동화되는 'always-on' 세상을 위한 기술 기반
-
Kafka의 이벤트 스트리밍은 Fortune 100대 기업의 60% 이상을 포함하여 수많은 산업 및 조직의 다양한 사용 사례에 적용됨
사용 사례
-
증권 거래소, 은행 및 보험과 같은 실시간으로 지불 및 금융 거래를 처리
-
물류 및 자동차 산업과 같이 자동차, 트럭, 차량 및 선적을 실시간으로 추적하고 모니터링
-
공장 및 풍력 발전 단지와 같은 IoT 장치 또는 기타 장비의 센서 데이터를 지속적으로 캡처하고 분석
-
소매, 호텔 및 여행 산업, 모바일 애플리케이션과 같은 고객 상호 작용 및 주문을 수집하고 즉시 대응
-
병원에서 치료 중인 환자를 모니터링하고 상태 변화를 예측하여 응급 상황에서 시기 적절한 치료를 보장
-
회사의 여러 부서에서 생성된 데이터를 연결, 저장 및 사용 가능하게 만듦
-
데이터 플랫폼, 이벤트 중심 아키텍처 및 마이크로서비스(MSA)의 기반 역할
이벤트 스트리밍 플랫폼
: Kafka는 세 가지 주요 기능을 결합하여 end-to-end 이벤트 스트리밍을 구현할 수 있음
주요 기능 3가지
- 이벤트 스트림을 지속적으로 발행(publish-write), 구독(subscribe-read) 합니다.
- 이벤트 스트림을 원하는 만큼 내구성 있고 안정적으로 저장(store) 합니다. (KafkaCluster(broker))
- 이벤트 스트림을 발생 시 또는 소급하여 처리(Process) 합니다.
Message Oriented Middleware:MOM
: 메시지 지향 미들웨어
- 비동기 메시지를 사용하는 각각의 응용프로그램 사이의 데이터 송수신을 의미함
- 이를 구현한 시스템을 메시지큐(Message Queue:MQ)라 합니다.
Message Queue (MQ)
: 메시지 큐
- 많이 사용하는 오픈소스 MQ로는
- RabbitMQ
- ActiveMQ
- RedisQueue
등이 있다.
Kafka와 MQ
Kafka는 이벤트 스트리밍 플랫폼으로서 여러가지 역할을 할 수 있고, MQ처럼 메시지 브로커 역할을 할 수 있도록 구현하여 사용할 수도 있으며, 기존 범용 메시지브로커들과 비교했을때 아래와 같은 특징을 가진다.
- 대용량의 실시간 로그 처리에 특화되어 TPS가 우수하다. - 고성능
- 분산 처리에 효과적으로 설계 되어 병렬처리와 확장(Scaleout), 고가용성(HA)에 용이하다 - 클러스터링
- 발행/구독(Publish-Subscribe) 모델 (Push-Pull 구조)
- 메시지를 받기를 원하는 컨슈머가 해당 토픽(topic)을 구독함으로써 메시지를 읽어 오는 구조
- 기존에 퍼블리셔나 브로커 중심적인 브로커 메시지와 달리 똑똑한 컨슈머 중심
- 브로커의 역할이 줄어들기 때문에 좋은 성능을 기대할 수 있음
- 파일 시스템에 메시지를 저장함으로써 영속성(durability)이 보장
- 장애시 데이터 유실 복구 가능
- 메시지가 많이 쌓여도 성능이 크게 저하되지 않음
- 대규모 처리를 위한 batch 작업 용이
Kafka의 주요 개념 및 용어
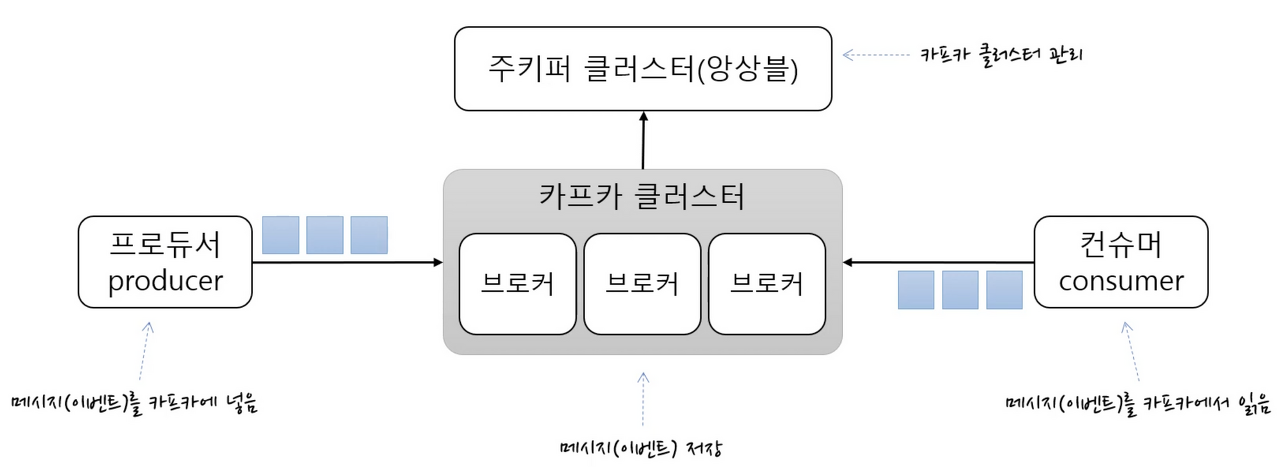
-
KafkaCluster : 카프카의 브로커들의 모임. Kafka는 확장성과 고가용성을 위하여 broker들이 클러스터를 구성
-
Broker : 각각의 카프카 서버, 동일 노드에 여러 브로커를 띄울 수 있다.
-
Zookeeper : 카프카 클러스터 정보 및 분산처리 관리 등 메타데이터 저장. 카프카를 띄우기 위해 반드시 실행되어야 함(곧 카프카 클러스터와 통합 예정)
-
Producer : 메시지(이벤트)를 발행하여 생산(Wirte) 하는 주체
-
Consumer : 메시지(이벤트)를 구독하여 소비(Read) 하는 주체
Topic, Partition, Offset
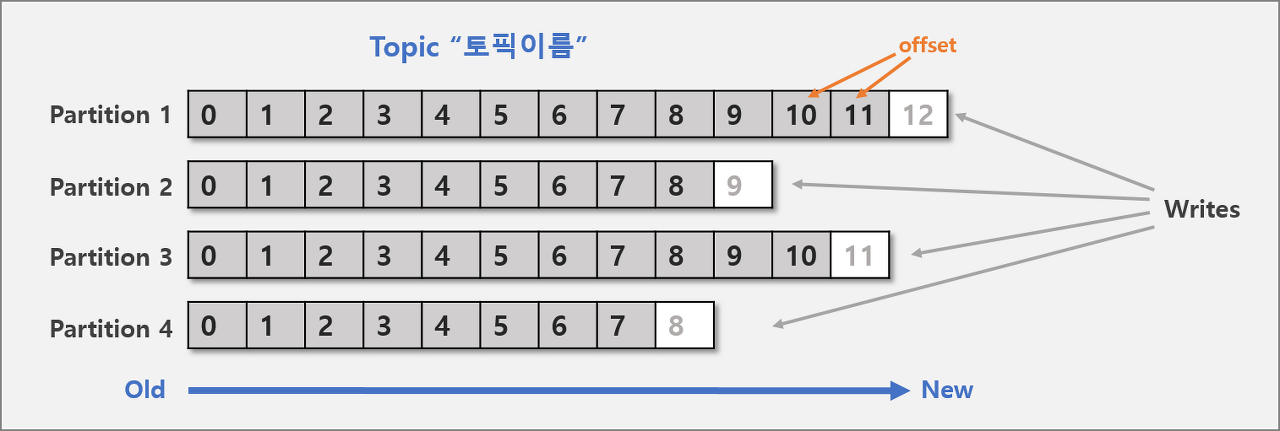
카프카에 저장되는 메시지는 topic으로 분류, topic은 여러개의 patition으로 나눠짐
-
Topic : 메시지를 구분하는 단위
- 파일시스템의 폴더, 메일함과 유사함 ex) 주문용 토픽, 결제용 토픽 등
-
Partition : 메세지를 저장하는 물리적인 파일
-
한 개의 토픽은 한 개 이상의 파티션으로 구성됨
-
파티션은 메시지 추가만 가능한 파일(append-only)
-
-
offset : 파티션내 각 메시지의 저장된 상대적 위치
-
프로듀서가 넣은 메시지는 파티션의 맨 뒤에 추가 (Queue)
-
컨슈머는 오프셋 기준으로 마지막 커밋 시점부터 메시지를 순서대로 읽어서 처리함
-
파티션의 메시지 파일은 처리 후에도 계속 저장되어 있으며, 설정에 따라 일정시간 뒤 삭제됨
-
Consumer
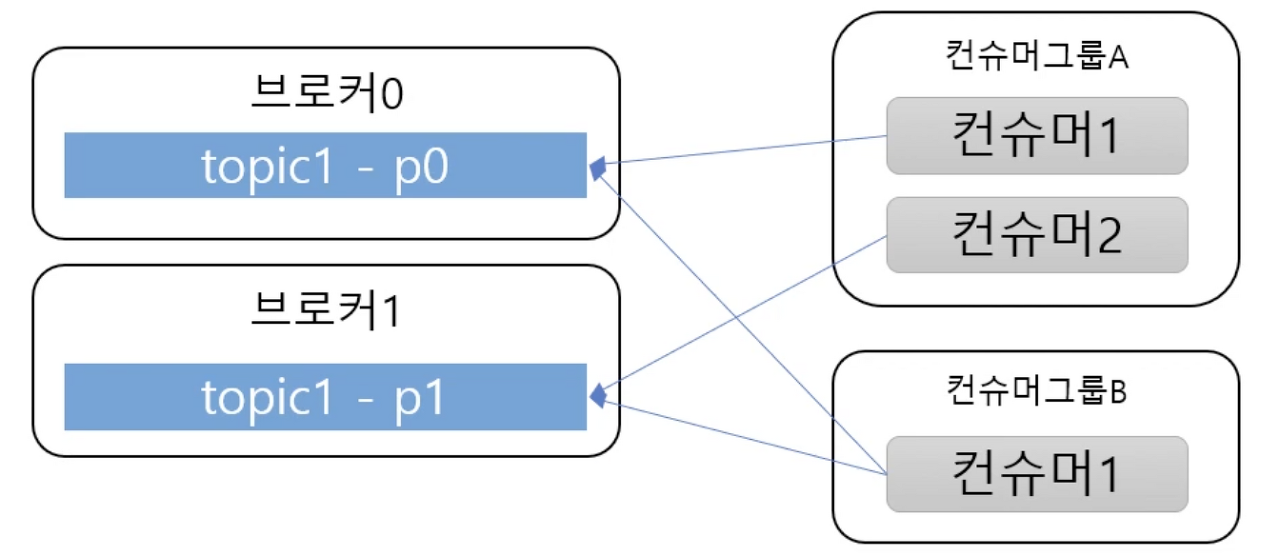
-
Consumer : 메시지(이벤트)를 구독하며 소비(Read)하는 주체
-
Consumer Group
: 메시지를 소비하는 컨슈머들의 논리적 그룹- Topic의 파티션은 컨슈머그룹과 1:N 매칭 관계로 동일 그룹내 한 개의 컨슈머만 연결가능 하다.
- 이로써 파티션의 메시지는 순서대로 처리되도록 보장
- 특정 컨슈머에 문제가 생겼을때
Fail over를 통한 리밸런싱 가능 - 보통 파티션과 컨슈머는 1:1이 best practice로 봄
Why Kafka?
고성능
-
다중 프로듀서, 다중 컨슈머가 상호 간섭없이 메시지를 쓰고 읽어서 처리
-
디스크 기반의 이벤트 보존
-
지속해서 보존 가능, 데이터 유실 위험이 적고 컨슈머가 항상 안떠있어도 됨.
-
장애 발생시 유실 복구 가능(재처리)
-
파티션 파일은 OS 페이지 캐시를 통해 IO를 메모리에서 처리하여 성능이 유리
-
Zero Copy를 통해 디스크 버퍼에서 네트워크 버퍼로 직접 데이터 복사
-
-
브로커가 하는일이 비교적 단순 - 똑똑한 컨슈머
-
브로커는 컨슈머와 파티션간 맵핑 관리만 하며 성능에 집중
-
메시지 필터, 메시지 재전송과 같은 일은 프로듀서, 컨슈머에 위임
-
-
batch 기능을 제공하여 동시 처리량 증가
-
프로듀서 : 일정 크기만큼 메시지를 모아서 전송
-
컨슈머 : 최소 크키만큼 메시지를 모아서 읽어옴
-
-
확장성(scale out) : 수평 확장이 쉽게 가능 - 브로커, 파티션, 컨슈머 추가
고가용성(HA- High Availability)
Kafka의 topic은 partition이라는 단위로 쪼개어져 클러스터의 각 서버들에 분산되어 저장되고, 고가용성을 위하여 복제(replication) 설정을 할 경우 이 또한 partition 단위로 각 서버들에 분산되어 복제되고 장애가 발생하면 partition 단위로 fail over가 수행된다.
-
Replication : 토픽내 파티션의 복제본.
replication-factor를 통해 개수를 지정할 수 있다.- 복제수(replication factor)만큼 파티션의 복제본이 각 브로커에 생김
- 토픽 생성시 복제수를 2로 하면 파티션이 2개가 각각의 브로커에 생김
-
leader와 follower로 구성
-
프로듀서&컨슈머는 리더를 통해서만 메시지 처리
-
팔로워는 리더가 속한 브로커에서 메시지를 복제함
-
리더가 속한 브록커가 장애나면 다른 팔로워가 리더가 되어서 처리
-
Change Data Capture
: 실시간 데이터 캡쳐
- CDC를 사용하기 위해서는 Kafka connect가 필요하다.
Kafka Connect
: 데이터소스와 Kafka를 연결해주는 매개체
-
Connector를 이용하여 데이터소스와 연결한다. 즉, Kafka Connector가 Producer와 Consumer 역할을한다고 보면 된다.
-
Producer 역할을 하는 Kafka Connector : Source Connector
-
Consumer 역할을 하는 Kafka Connector : Sink Connector
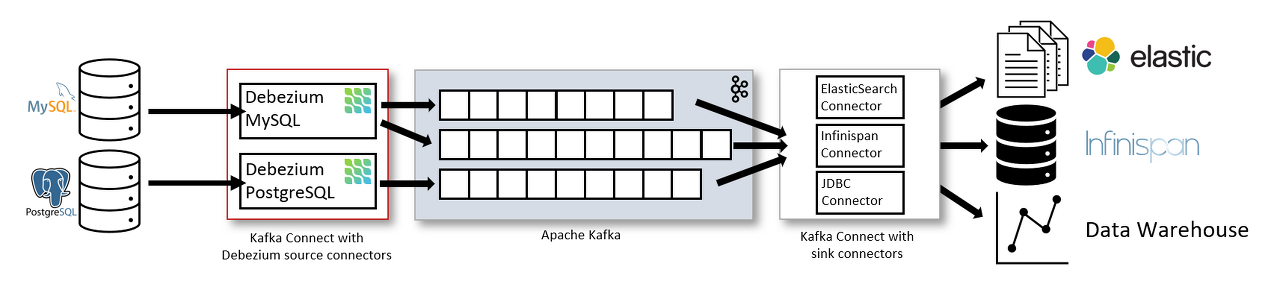
-
-
Kafka Connector가 만들어내는 메시지 구조
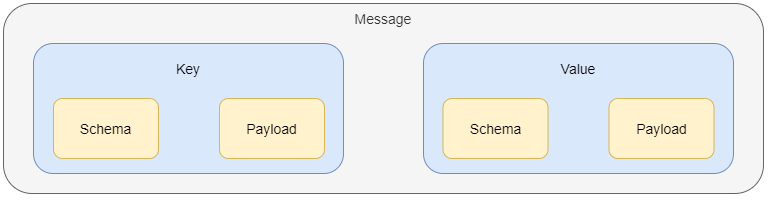
-
Message는
Key-Value로 구성되어있으며, 각 Key와 Value는Schema와Payload로 구성되어있다. -
여기서
Key는 PK와 같이 데이터를 식별할 수 있는 정보가 들어있고,Value는 데이터의 전체 값이 들어있다. -
Payload는 데이터 값이 저장이 되며, 이 데이터 값의 데이터 타입이Schema에 명시되어 있다.
-
-
동일한 메세지가 계속 들어오는 경우 Schema가 중복이 되어 불필요하게 데이터 용량을 잡아먹게 된다.
=> 이를 위해 Kafka Connect는 Schema Registry를 활용한다.
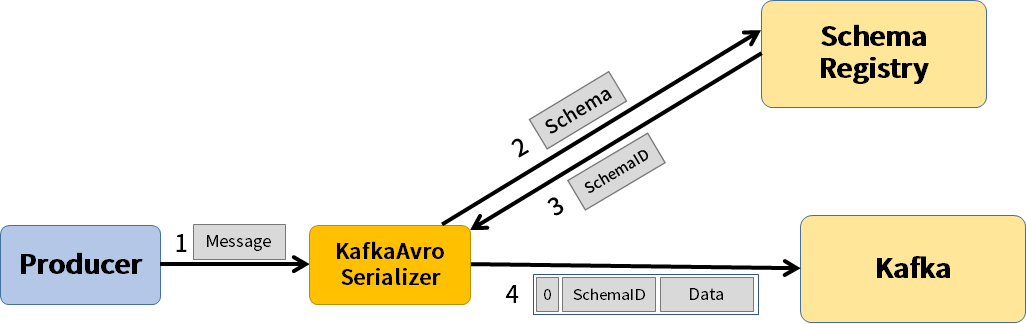
Schema Registry는 Key와 Value에 명시된 Schema를 따로 저장하며,Kafka Connector는 Schema 대신 Schema Registry의 Schema 번호를 명시하여 메세지 크기를 줄인다.
꼭 비동기를 써야 하는가?
-
API는 동기적 호출로써 세분화된 서비스간 결합도가 높아짐 → 하나의 서비스로 인해 응답속도가 심각하게 저해될 수 있음
-
이를 효율적으로 보장하기 위한 비동기 서비스를 구축하고, 비즈니스를 도출해내는 것이 MSA 아키텍처를 설계하는 주요 요건 중 하나이다.
-
비동기 처리 요건을 파악하고, 상황에 따라 CQRS 등의 Advanced Application 구조를 설계하여 MSA의 이점을 최대한 누릴수 있도록 설계해야 할 것이다.
참고자료
