MySQL에서 텍스트 문자열 검색 시 like나 instr 연산자를 사용하여 원하는 텍스트를 필터링하여 조회할 수 있다.
SELECT * FROM USER WHERE NAME LIKE '%홍길동%';그러나, 텍스트를 검색하여 찾아야 할 데이터가 방대한 양일 경우 성능이 떨어지게 된다. (과부하 발생 및 응답시간 증가)
이에 대한 해결책이 전체 텍스트 검색 기능(Full Text Search)이다.
MySQL의 B-Tree Index
-
일반적인 인덱스
-
인덱스란? 데이터의 주소값을 저장하는 별도의 특별한 자료구조
-
한 Column 안에서 비슷한 형식의 데이터 중 원하는 데이터를 찾는 경우 사용하는 것이 일반적임
Full Text Search
: 첫 글자 뿐 아니라 중간의 단어나 문장으로도 인덱스를 생성해줌
- 입력한 keyword가 포함된 내용을 출력해줄 뿐만 아니라, 다양한 규칙을 적용시켜 개발자가 원하는 값만 출력이 가능하도록 하는 기능
-
긴 텍스트 데이터를 빠르게 검색하기 위한 MySQL의 부가적인 기능
-
즉, 전체 텍스트도 결국 인덱스의 종류 중 한 가지임
Full Text Index
: 텍스트로 이루어진 문자열 데이터의 내용으로 생성한 특수한 인덱스의 종류
- 내용이 긴 텍스트를 따로 인덱싱하여 관리할 수 있다.
특징 (일반 Index와의 차이)
-
긴 문장 전체를 대상으로 인덱싱을 하며, InnoDB와 MyISAM 테이블만 지원함
-
char, varchar, text 타입 문자만 인덱싱이 가능함
-
여러 개의 열에 Full Text Index 지정 가능
-
사용자가 쓰기 나름인 데이터를 토큰 단위로 쪼개서 검색에 용이하도록 해줌
Full Text Search 활용하기
1. Full Text 검색어 길이 조정
-
보통 MySQL의 Full Text 검색어 최소 길이는 4로 설정되어 있음
-
그러나 한국어 검색 특성상 보통은 2글자 이상부터 검색이 일반적임 → 수정 필요
- 현재 설정 길이 확인
-- 길이 확인 SHOW VARIABLES LIKE '%FT_MIN%'; - MySQL Server 폴더의
ini파일에 아래 내용을 추가
ini파일 찾기가 어렵다면 아래 코드로 찾기SHOW VARIABLES WHERE VARIABLE_NAME LIKE "%DIR"
-
MySQL 재시작 (작업 관리자에서 다시 시작)
-
Full-text 인덱스를 이미 설정해뒀다면 지우고 다시 추가, 혹은
REPAIR TABLE MEETING QUICK;을 사용하여 REPAIR하기 (SCHEMA 지우고 다시 만들어 설정하는 것을 추천)
2. Full-text key 설정하기
- 테이블 설정 변경하기
ALTER TABLE 테이블명 ADD FULLTEXT KEY (컬럼명1ㅡ 컬럼명2, ...);3. Repository 사용 예시
@Query(value="SELECT * FROM MEETING M WHERE MATCH(M.TITLE, M.CONTENT,"
+ "M.TAGS, M.AREA, M.AREA2) AGAINST('KEYWORDS' IN BOOLEAN MODE) ORDER BY M.MEETING_ID DESC", NATIVEQUERY=TRUE) 주의!
-
FULLTEXT를 사용해서 출력하는 하나의 ROW 문자열은 CHARACTER SET이 모두 동일해야 한다.
-
EX: TITLE은 UTF8이고, CONTENT는 UTF8MB4이면 일관성에 오류가 발생
-
문자열 타입의 CHARACTER SET을 일치시켜줘야 함
ALTER TABLE MEETING MODIFY COLUMN PHONE_NUMBER VARCHAR(255) CHARACTER SET UTF8MB4;Full-text Index의 데이터 인덱싱
다음 두 종류의 parser을 이용하여 인덱스를 구축한다.
1) Built-in parser 또는 Stop-word parser
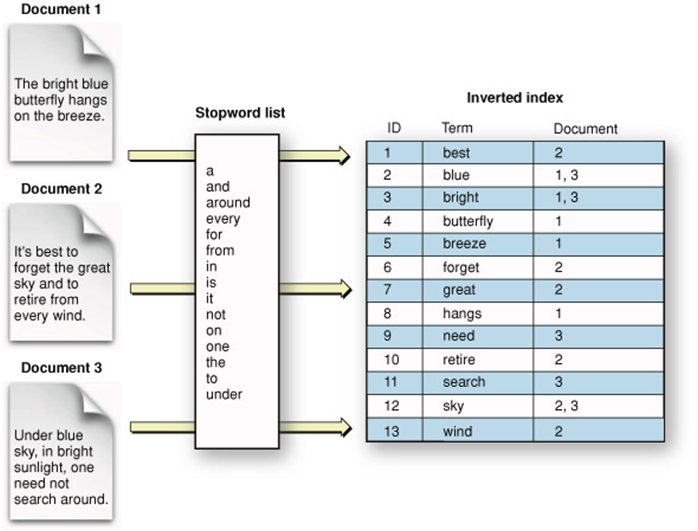
-
Stop-word 기법을 사용하는 기본 내장 파서(built-in parser) 이용
-
stop-word : 토큰을 나눌 때 해당하는 Stop-word가 나타났을 때를 기준으로 토큰을 나눔
-
Input :
“나는 김치찌개가 좋습니다.” -
Stop-word :
" "(공백) (default = 공백) -
Token : 나는 | 김치찌개가 | 좋습니다. => 공백을 기준으로 4개의 토큰 인덱싱됨
2) N-gram parser
-
n-gram 기법을 사용하여 할당한 토큰의 크기 n만큼씩 데이터를 인덱스로 파싱해두었다가 사용하는 파서
예시 1
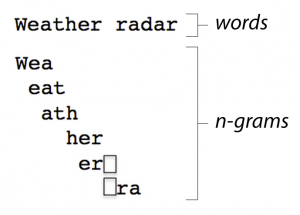
input: weather radarn-gram: 3
👉🏻 위 그림 예시에서 Token 2가 아닌er과ra는 n-gram parsing은 되었지만 인덱싱 되지 않는다.
예시 2
-
Input:“나는 김치찌개가 좋습니다.” -
N-gram:n = 2 -
Token:나는 | 는 | 김 | 김치 | 치찌 | 찌개 | 개가 | 개 | 좋 | 좋습 | 습니 | 니다 | 다.=> 중에서 Token 2가 아닌 “는 “,” 김”, “개 “, “ 좋” 은 제거됨 -
결과 :
나는 | 김치 | 치찌 | 찌개 | 개가 | 좋습 | 습니 | 니다 | 다.
