
2탄으로 돌아왔다.
1탄에서 말했듯이, 비동기를 위해 Async를 적용했다.
나는 이벤트를 발행하는 곳이 이벤트를 처리하는 곳에서 결과가 나올때까지 기다리는 것이 아닌, 이벤트 처리에 대한 일은 신경쓰지 않고 각각 다른 쓰레드에서 독립적으로 각각의 작업들을 처리해나갔으면 했다. 즉, 맨 처음에 언급했던 것처럼 비동기적으로 작동하길 원한다. 따라서 @Async를 적용하였다.
관련 깃허브 PR : https://github.com/sue4869/ottsharing/pull/2
📌@Async를 적용하지 않으면?
Async를 적용하지 않고 토큰생성이벤트 발행을 100번 하도록 하였다.
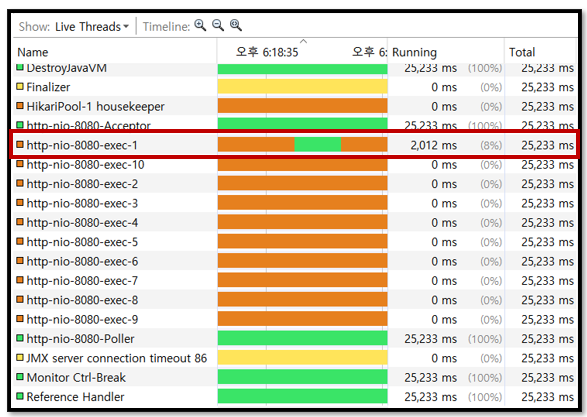
보다시피 http-nio-8080-exec-1만을 이용하는 것을 볼 수 있다. 즉, 한 쓰레드로만 100개의 요청을 다 수행하고 있는 것을 볼 수 있다. 초록색은 Running하고 있는 진행상태를 의미한다.
📌@Async
그러면 이번에는 Async를 적용해볼까?
토큰생성로직은 회원정보 로직과 비동기적으로 작동하도록 만들기 위해 @Async를 적용하였고, 이전 테스트와 같이 100번의 토큰생성이벤트를 발행하도록 하였다.
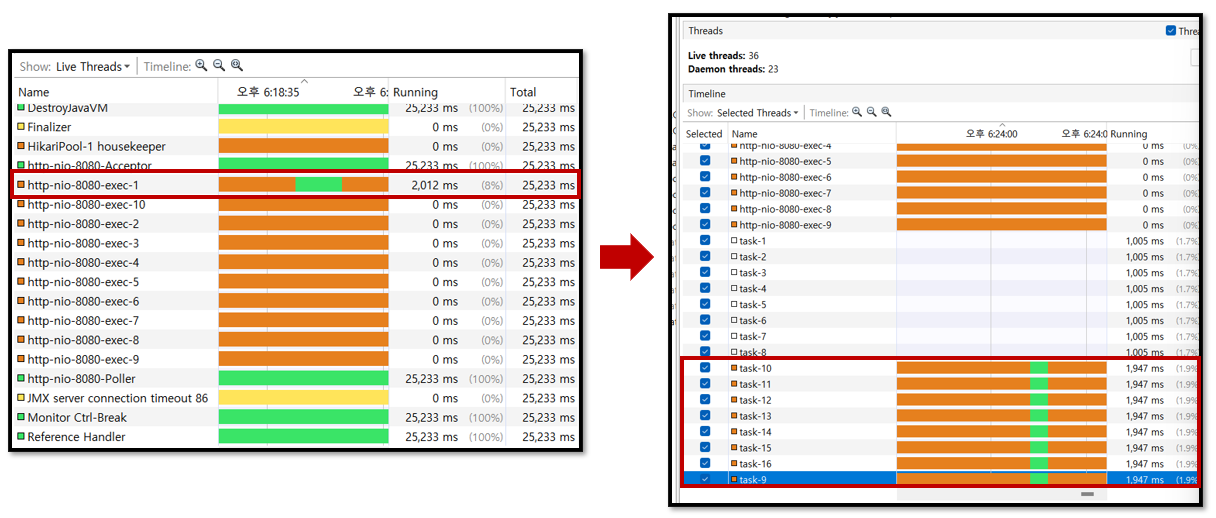
위 사진을 보면, 한 쓰레드에서 모든 요청을 처리한 이전과 달리, 'task-번호'로 된 여러 쓰레드를 이용하여 토큰 생성 이벤트 요청에 대한 처리를 하는 것을 볼 수 있다.
당연한 수치겠지만, 숫자로 보면, 100번의 요청을 동기의 경우 한 쓰레드에서 다 처리 하기 때문에 8%를 사용하고, 비동기의 경우 100번의 요청에 8개의 쓰레드로 나눠서 처리하기 때문에 각각 1.9%씩을 사용하는 것을 확인할 수 있다.
🌱@Async의 default 설정
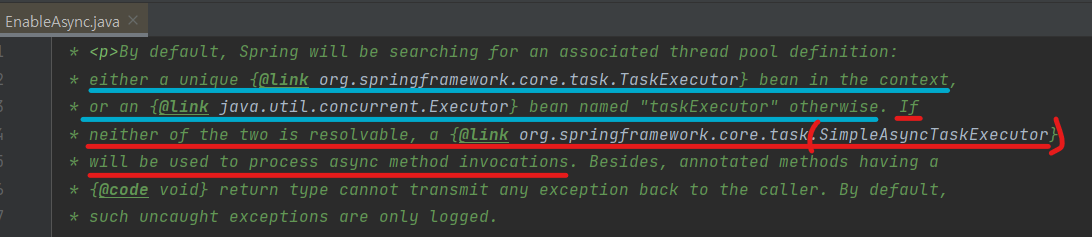
일반적으로 Async를 사용하면, EnableAsync 문서에 나와있듯이 @Async는 기본적으로 스레드를 관리할때 SimpleAsyncTaskExecutor를 이용해서 스레드를 생성한다고 말하고 있다(빨간줄). 참고로, EnableAsync는 전체 Spring 애플리케이션 컨텍스트에 대한 주석 기반 비동기 처리를 활성화하는 역할을 하기 때문에 이런 정보들이 적혀있다.
혹시 해당 내용을 알고 싶으면, spring 공식 문서에서도 볼 수 있으니 클릭해서 봐보길 바란다.
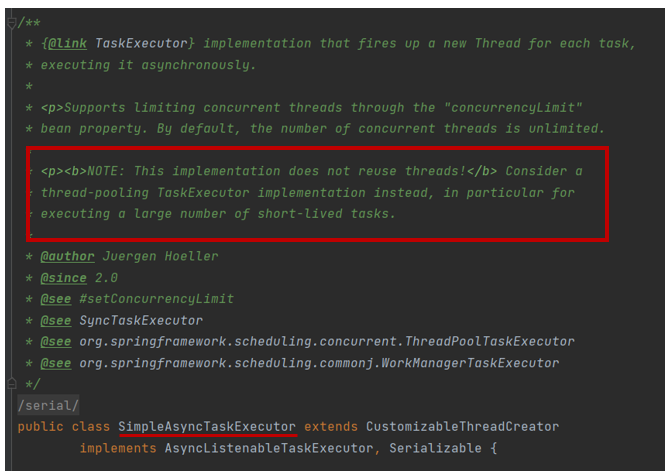
또한, Async의 기본 설정인 SimpleAsyncTaskExecutor는 쓰레드를 재활용하지 않고 요청마다 매번 쓰레드를 생성한다고 써있다. 즉, SimpleAsyncTaskExecutor는 쓰레드풀을 쓰지 않고 매번 쓰레드를 새로 생성하는 것이다.
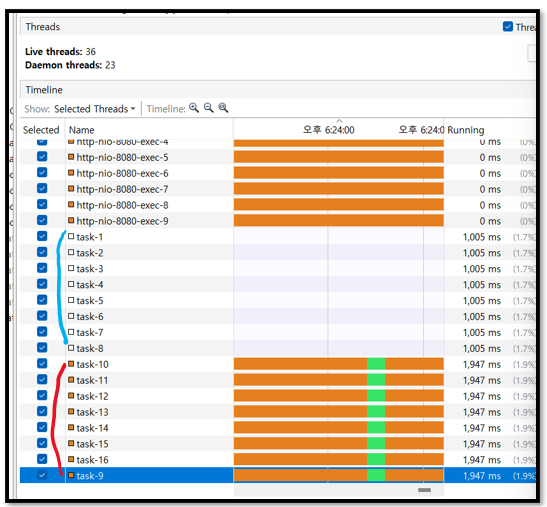
파랑색묶음의 task는 이전의 요청에 의해 생성되어 사용된 쓰레드들이고 빨간묶음은 이번 요청을 위해 새로 생성되어 사용되고 있는 쓰레드이다. 요청이 다 처리되면 해당 쓰레드들은 다 dead Thread로 만들어버리는 현상을 볼 수 있다. 이렇게 매번 쓰레드를 생성할 경우, 요청이 많으면 성능이 저하될 우려가 있다고 생각했다. 이러한 이유로 나는 매번 쓰레드를 생성하는 것보다는 ThreadPool을 사용해서 쓰레드를 재활용하여 보다 효율적으로 자원을 사용했으면 하는 바람에 AsyncTask라는 이름의 별도의 쓰레드풀을 만들어주었다.
🌱Async를 위한 별도의 쓰레드풀 만들기
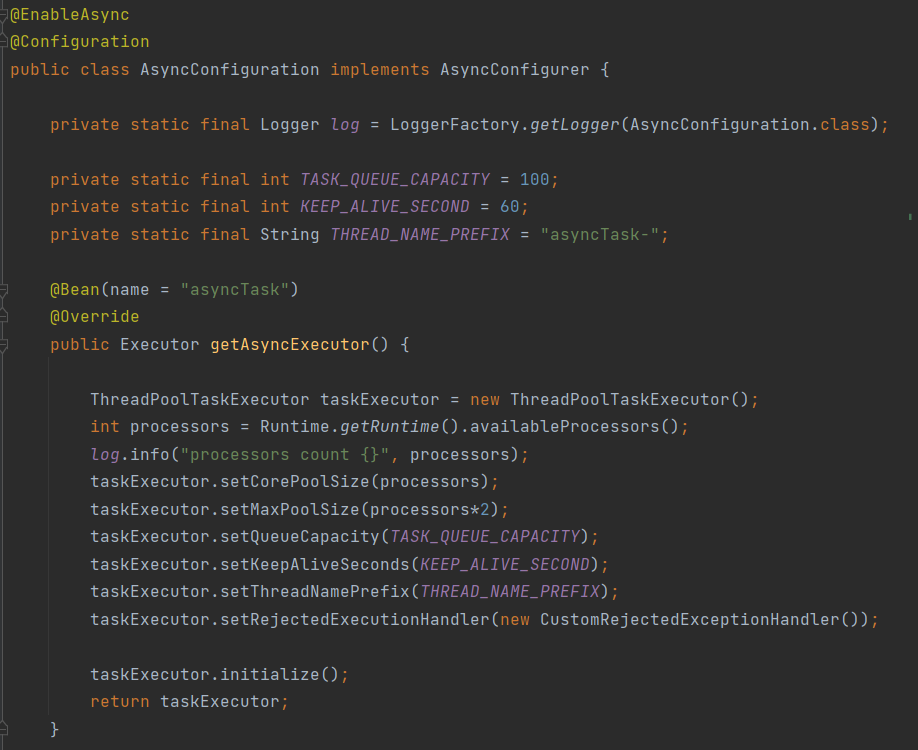
각각의 변수에 대해 설명하자면,
- TASK_CORE_POOL_SIZE : 기본적으로 실행을 대기하고 있는 스레드 수
- TASK_MAX_POOL_SIZE : 최대로 생성할 수 있는 스레드 수
- TASK_QUEUE_CAPACITY : 요청받은 작업을 저장할 최대 갯수(이 크기보다 많은 작업이 큐에 들어와야 poolSize가 증가한다.)
- THREAD_NAME_PREFIX : spring이 생성하는 스레드의 접두사
를 지칭한다.
난 일단 크지않은 프로젝트이기 때문에 최대로 100개 요청을 동시에 수용할 수 있도록 TASK_QUEUE_CAPACITY를 100으로 지정하였다. 그 다음 문제는 스레드의 개수인데, processor의 개수가 한정적인 상태에서, 쓰레드를 무한히 만든다고 해서 성능이 올라가는 것도 아니고 오히려 context switching으로 성능 저하를 일으킬 가능성이 있어 적절한 쓰레드 수를 지정하는 것이 좋다. 여기서는 몇개로 지정하는 것이 좋을 지 고민이 많았다.
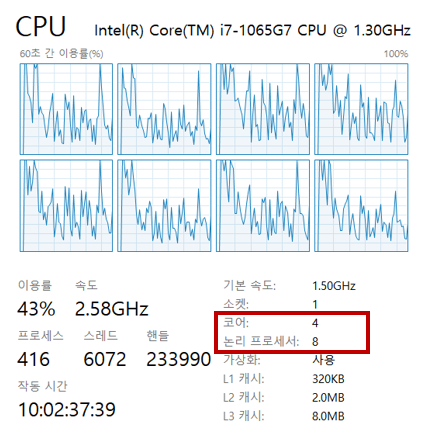
위 사진에 나온 것처럼, 현재 내 컴퓨터는 intel i7으로 4개의 코어를 가지고 있지만,물리적 코어 한개당 스레드 2개를 할당해 성능을 높이는 기술인 하이퍼스레딩이라는 기술을 지원 해주기 때문에 논리 프로세서는 8개인 것을 확인 할 수 있다. 즉, 최대로 활용가능한 쓰레드는 8라는 말이다.
따라서 난 기본적으로 실행을 대기하고 있는 스레드의 수(TASK_CORE_POOL_SIZE)를 8로 지정하였다. 그럼, 최대로 생성할 수 있는 스레드 수(TASK_MAX_POOL_SIZE)는 몇으로 해야 할까?
자, 이렇게 생각될 수 있다.
최대로 생성할 수 있는 스레드의 수를 16으로 해도 어차피 8개밖에 사용할 수 없을 것 같은데? 그러면 8을 해야 하는 것이 아닐까? 정답은 없지만, 난 최대로 생성할 수 있는 스레드 수(TASK_MAX_POOL_SIZE)로 16을 지정하였다. 한 건의 작업을 처리하는데 cpu 바운드 작업인 경우에는 사이즈를 8개로 처리하는 게 좋을 것 같지만, I/O가 많이 일어나는 작업인 경우 I/O 처리하는 동안은 다른 스레드를 할당시켜 작업을 수행하는 게 cpu를 덜 낭비하는 게 될 것이다. 본 로직은 I/O 작업이 많이 일어나는 것은 아니더라도 그 후 로직에서도 해당 쓰레드풀을 쓰게 할 것이고, 어느정도 I/O처리가 있을 수 있기 때문에 다른 쓰레드에 할당할 수 있는 여지라도 있을 수 있어야 한다고 생각했다. (혹시 이에 대한 의견이 있으면 같이 이야기 나눠보고 싶다. 개발수다떨고 싶다..ㅠㅠ)

위 사진에 나온것처럼 100번의 요청을 asyncTask-번호라는 이름의 쓰레드를 이용하는 것을 볼 수 있다.
🌱ThreadPoolTaskExecutor의 기본적인 동작원리
내가 만들어준 Async 쓰레드풀에 대한 설정은 위에서 말했으니 이제는 동작에 대해 말할 시간이다.
-
현재 점유하고 있는 쓰레드의 갯수가 corePoolSize만큼 있을 때 요청이 오면 지정된 queueCapacity의 갯수만큼 요청을 큐에 넣는다.
-
현재 점유하고 있는 쓰레드의 갯수가 corePoolSize만큼 있고 큐에 담긴 요청이 queueCapacity의 갯수만큼 있을 때 요청이 오면 maxPoolSize만큼 쓰레드를 생성한다.
-
만약 현재 점유하고 있는 쓰레드의 갯수가 maxPoolSize만큼 있고 큐에 담긴 요청이 queueCapacity의 갯수만큼 있을때 요청이 오면 RejectedExecutionException 예외가 발생된다.
지금까지는 queueCapacity를 100으로 지정하였기 때문에 동시에 100개의 요청에 대한 테스트를 진행하였다. 따라서, 따로 maxPoolSize만큼 쓰레드를 생성하지 않고 기본적인 corePoolSize만큼의 쓰레드만 생성하는 것을 볼 수 있다. 그렇다면 만약 1000개를 요청하면? maxPoolSize만큼 생성하고 RejectedExecutionException 예외가 발생할까? 눈으로 직접 확인해보자.

16개의 쓰레드들을 생성하는 것을 볼 수 있다.
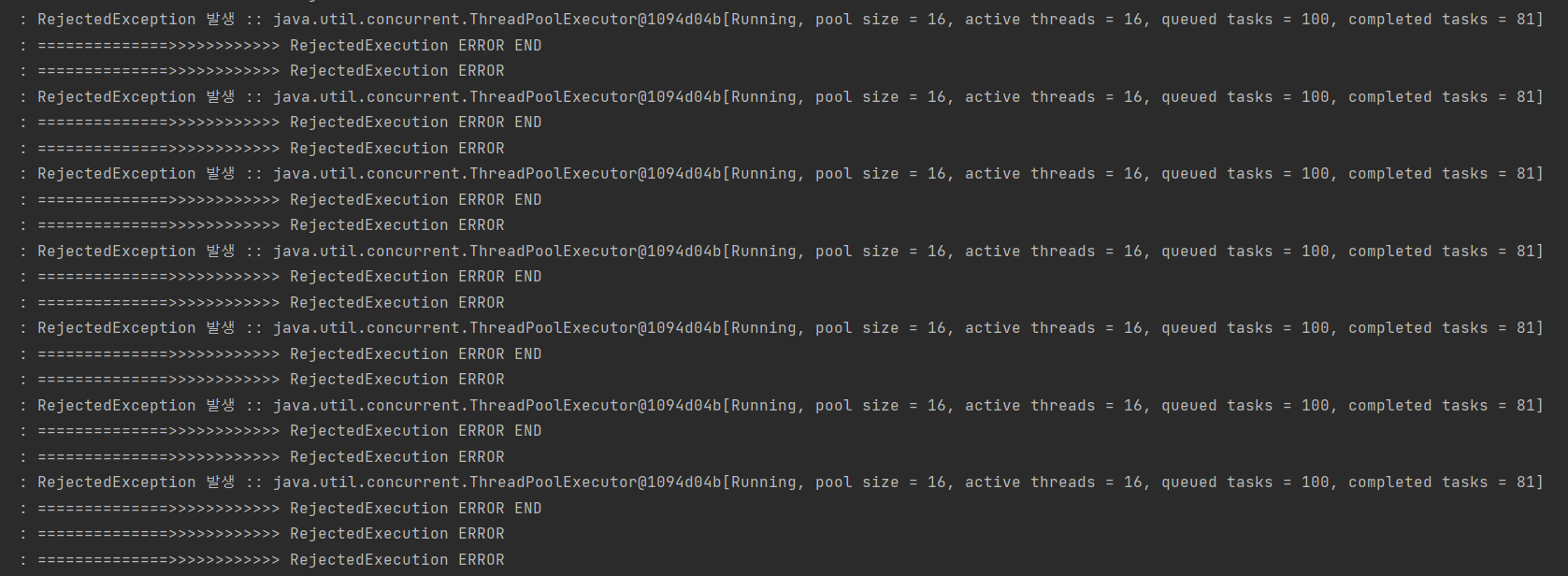
또한, RejectedExecutionException 예외가 발생하는 것도 볼 수 있다. 마지막으로 토큰생성하는 로직에서 예외가 발생하였는데, 원래라면 토큰에 대한 정보는 rollback되고 회원정보에 대한 데이터는 rollback이 안되어야 한다. DB에 회원정보에 대한 데이터가 rollback되지 않고 그대로 남아있을까? 확인해보자.
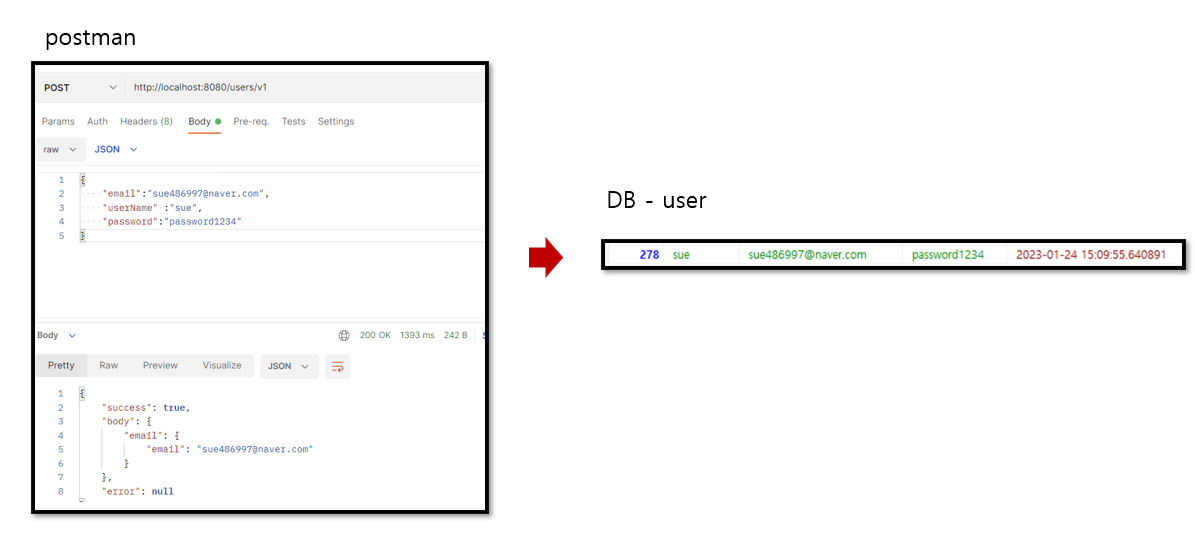
토큰에 대한 데이터는 없는 반면, 회원에 대한 정보는 그대로 존재하는 것을 볼 수 있다. (참고로, 비밀번호에 대한 암호화는 나중에 인증,인가 로직 구현시 할 것이다)
이로써, Async에 대한 설정과 이에 대한 테스트까지 해보았다. 하지만, 이게 끝이 아니다. 단순히 회원가입하고 토큰생성하는 로직을 짤 뿐인데 속에 많은 것들을 해봐야한다는 것을 요즘 새삼 많이 느낀다. 즉, 3편도 있다! 기대하길!
