📌JPA N+1 이슈는 무엇일까?
1번 조회해야할 것을 N개 종류의 데이터 각각을 추가로 조회하게 되서 총 N+1번 DB조회를 하게 되는 문제이다. 즉, JPA의 Entity 조회시 Query 한번 내부에 존재하는 다른 연관관계에 접근할 때 또 다시 한번 쿼리가 발생하는 비효율적인 상황을 말한다.
예시를 들자면, 데이터 조회 시 1번만 조회할 것을 100만개 종류의 데이터가 있어 1,000,001번 DB조회하게 되어 많은 량의 쿼리가 발생하고 성능저하를 일으킨다.
📖1. 대상
@ManyToOne 연관관계를 가진 엔티티에서 주로 발생한다. 즉, 1:N 또는 N:1 관계를 가진 엔티티에서 발생한다.
📖2. 언제 발생?
데이터 조회할때
- 즉시 로딩으로 데이터를 가져오는 경우 ( N+1 문제가 바로 발생 )
- 지연 로딩으로 데이터를 가져온 이후에 가져온 데이터에서 하위 엔티티를 다시 조회하는 경우 ( 하위 엔티티를 조회하는 시점에 발생 )
💡 즉시 로딩 & 지연로딩
즉시 로딩
엔티티 조회시 연관관계에 있는 데이터까지 한번에 조회해오는 기능. fetch = FetchType.EAGER옵션으로 지정된다.
- 사용하지 않는 엔티티를 조회한다.
- 조인을 이용해 매핑된 Entity를 함께 조회
- N+1 문제 발생
- 연관관계에 있는 데이터도 동시에 같이 불러야 할 상황일 경우에는 지연로딩은 select쿼리가 2번 실행되어(디스크에 2번 액세스) 비효율적이기 때문에 이때는 즉시 로딩을 이용하는 것이 효율적이다.
지연 로딩
엔티티 조회시점이 아닌 엔티티 내 연관관계를 참조할 때( 즉, 요청할때만) 연관된 데이터를 조회하는 기능. fetch = FetchType.LAZY 옵션으로 지정된다.
- 연관된 데이터를 프록시로 조회
- 조회 대상이 영속성 컨텍스트에 이미 있으면 프록시 객체가 아닌 실체 객체를 사용한다.
📖3. 왜 발생하는 거지?
📚 "즉시로딩"의 경우
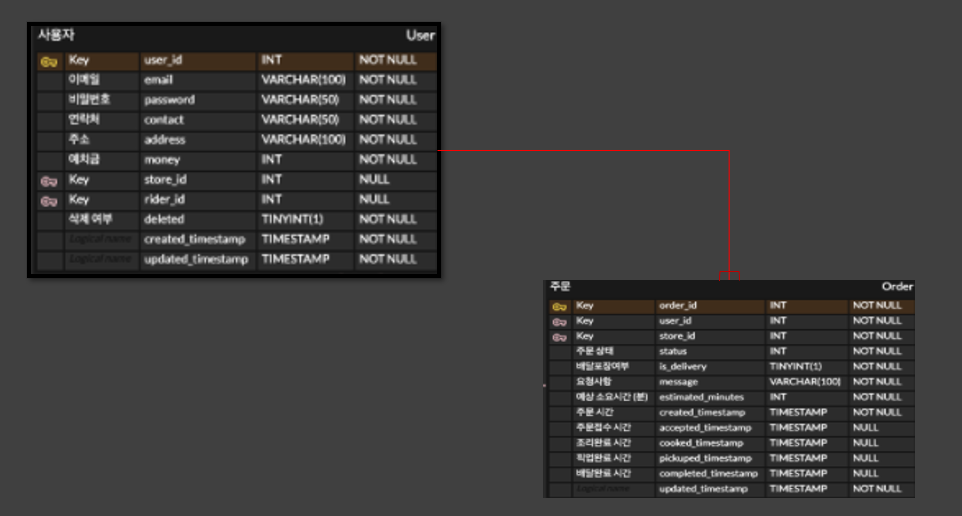
음.. 현재 진행하고 있는 프로젝트를 참고해서 예를 들자면, User(사용자)와 Order(주문)은 현재 일대다 관계로 연관관계가 존재한다. User 엔티티를 findAll()를 이용해 모든 사용자들을 조회하려고 할때, 원래는 사용자들에 관한 내용만 조회되어야 하는데 User의 연관관계 엔티티도 함께 조회되기 때문에 각 사용자마다 연관된 Order 엔티티도 조회가 함께 되는 것이다.
즉, 사용자가 5명일때, 사용자 조회에 대한 내용(1) + 각 5명의 사용자가 가지고 있는 주문 Entity에 대한 내용(5)으로 1+5 로 조회가 되어 1+N이 발생하는 것이다. 따라서, 연관관계까지 데이터를 모두 조회하는 즉시로딩일 경우 N+1 문제가 발생하는 것이다.
- findAll()을 한 순간 select u from User u이라는 JPQL 구문이 생성되고 해당 구문을 분석한 select * from user 이라는 SQL이 생성되어 실행된다.
- DB의 결과를 받아 User 엔티티의 인스턴스들을 생성한다.
- User와 연관되어 있는 Order 도 로딩을 해야 한다.
- 영속성 컨텍스트에서 연관된 User가 있는지 확인한다.
- 영속성 컨텍스트에 없다면 2에서 만들어진 User 인스턴스들 개수에 맞게 select * from order where User_id = ? 이라는 SQL 구문이 생성된다. ( N+1 발생 )
📚 "지연로딩"의 경우
필요할때만 연관데이터를 가져오기 때문에 단순히 User 엔티티를 조회할때는 N+1 문제가 발생하지 않지만, 하위 엔티티인 Order를 조회하는 경우, Order엔티티는 프록시 객체이기 때문에 User를 조회하고 나서 Order를 조회하는 쿼리가 나가기 때문에 즉시로딩과 같이 N+1문제가 발생한다.
- findAll()을 한 순간select u from User u 이라는 JPQL 구문이 생성되고 해당 구문을 분석한 select * from user 이라는 SQL이 생성되어 실행된다.
- DB의 결과를 받아 User 엔티티의 인스턴스들을 생성한다.
- 코드 중에서 User 의 Order 객체를 사용하려고 하는 시점에 영속성 컨텍스트에서 연관된 Order가 있는지 확인한다
- 영속성 컨텍스트에 없다면 2에서 만들어진 User 인스턴스들 개수에 맞게 select * from order where User_id = ? 이라는 SQL 구문이 생성된다. ( N+1 발생 )
📌해결점은 무엇일까?
📖1. Fetch Join
📚특징
1) DB에서 데이터를 가져올때 처음부터 연관된 엔티티나 컬렉션을 한번에 같이 조회하는 방법이다. 즉, User 엔티티를 조회할때 Order도 같이 조회해서 N번 Oder를 조회하는 쿼리를 나가지 않도록 하는 것이다.
@Query 어노테이션을 사용해서 join fetch 엔티티. 연관관계_엔티티”구문을 만들어준다
@Query("select u from User u join fetch u.order")
List<User> findAll();2) 조회의 주체가 되는 Entity 이외에 Fetch join이 걸린 연관 Entity도 같이 영속성 컨텍스트에서 관리해준다.
3) inner join 발생
📚Fetch Join의 문제 : 중복
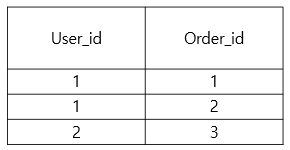
User는 여러 Order를 가질 수 있는 일대다 관계이다.
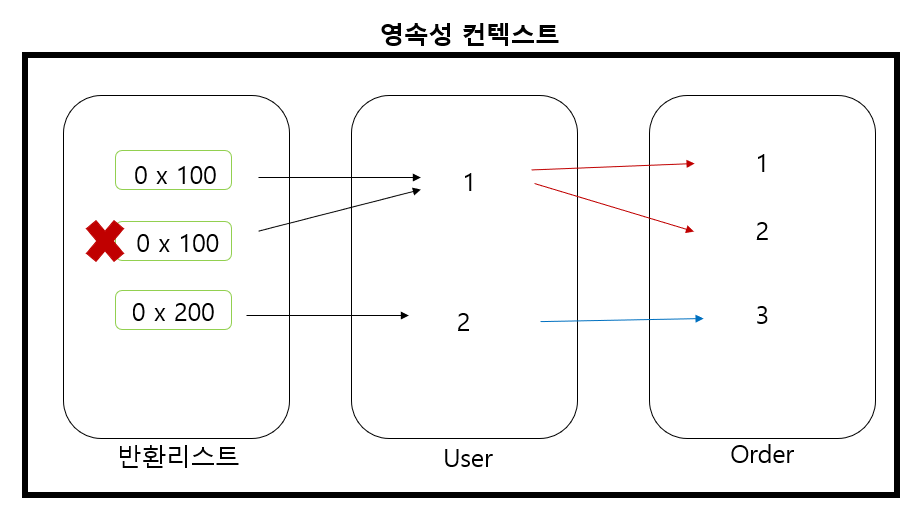
1) user 객체 1을 영속성 컨텍스트에 넣고, order 객체 1 또한 영속성 컨텍스트에 넣는다. (결과리스트 0 x100 1번째)
2) user 객체 1은 이미 넣어져 있기 때문에 참조만 하고, order객체 2를 추가한다. (결과리스트 0 x100 2번째)
3) user 객체 2를 영속성 컨텍스트에 넣고, order 객체 3도 영속성 컨텍스트에 넣는다.( 반환리스트 0 x200 )
4) 중복 데이터가 발생한다.
위의 그림에 나온것처럼, order_id를 조회할때 데이터가 중복되는 경우가 생긴다. 이러한 중복된 데이터를 제거하기 위해 DISTINCT를 사용한다. 따라서 중복방지를 위해 최종적으로 써야 할 코드에는 distinct가 들어가야 한다.
@Query("select distinct u from User u join fetch u.order")
List<User> findAll();💡 Fetch Join의 장단점.
- 장점
- 단 한번의 쿼리만 발생하도록 설계할 수 있다.
- fetch join을 이용해 특정 엔티티의 하위 엔티티의 하위 엔티티까지 가져오도록 할 수 있다.
- 단점
- 번거롭게 쿼리문을 작성해야 함
- JPA가 제공하는 Pageable 기능 사용 불가(Pageable 사용 불가) → 페이징 단위로 데이터 가져오기 불가능
- batch size로 해결 : 즉시로딩이나 지연로딩 시에 연관된 엔티티를 조회할 때 지정한 size 만큼 sql의 IN절을 사용해서 조회하는 방식
- 1 : N 관계가 2개인 엔티티를 패치 조인 사용 불가
→ MultipleBagFetchException 발생
📖2. EntityGraph 어노테이션
1) EntityGraph 상에 있는 Entity들의 연관관계 속에서 필요한 엔티티와 컬렉션을 함께 조회하려고 할때 사용한다
2) outerJoin 사용
3) attributePaths에 쿼리 수행 시 바로 가져올 필드명을 지정하면 LAZY(지연 로딩)가 아닌 Eager(즉시 로딩) 조회로 가져오게 된다.
@EntityGraph(attributePaths = {"order"})
List<User> findAllEntityGraph();💡 @EntityGraph의 장단점
- 장점
- fetch join의 매번 쿼리를 작성하고 확인하는 문제 해결
- 단점
- outerJoin을 사용하기 때문에 중복 데이터 발생함 (카테시안 곱 현상)
→ Set으로 중복 방지/distinct 적용

default_batch_fetch_size(hibernate 제공 기능)으로 n+1 을 해결하는 방법도 공부해서 적어주세요~
default_batch_fetch_size 을 사용하면 lazy 전략을 가져가면서 성능 최적화가 가능해요(개발자 개입 없이, Transaction 구조만 잘 구성해도)
그리고, 개발자 입장에서 코드만 보더라도 전체적인 DB 테이블을 알 수 있어요!
이건 실무에서 굉장히 중요하다고 생각해요.
솔직히 여러 자료를 보면서 분석하는거 힘들잖아요.
그럼 결국 업무가 바쁘면 어느 한곳에서 문서 관리를 허술하게 해버리고,
이건 후임자들에게 큰 허들을 제공할거에여.
그리고 제가 댓글은 다는 이유는
sweet_sumin 님의 글이 구글에 N+1 을 검색하면 첫번째로 나오는 글이기 때문에
한국에서 JPA를 쓰려면 무조건 Fetch Join, EntityGraph을 써야한다는 큰 오해가 생길 가능성이 농후하기 때문이에요.