
자바에서 코틀린으로 전환하면서 다양한 함수들이 있지만 제대로 활용하고 있지 않은것 같아서 어떤 함수들이 있는지 정리해보고자 한다. 존재라도 알면 쓰임을 생각해내서 활용하지 않을까? ⭐️ 표시를 통해 자주 쓰이거나, 이건 기억해두고 싶다라는 것들을 표시해두었다.
component1()
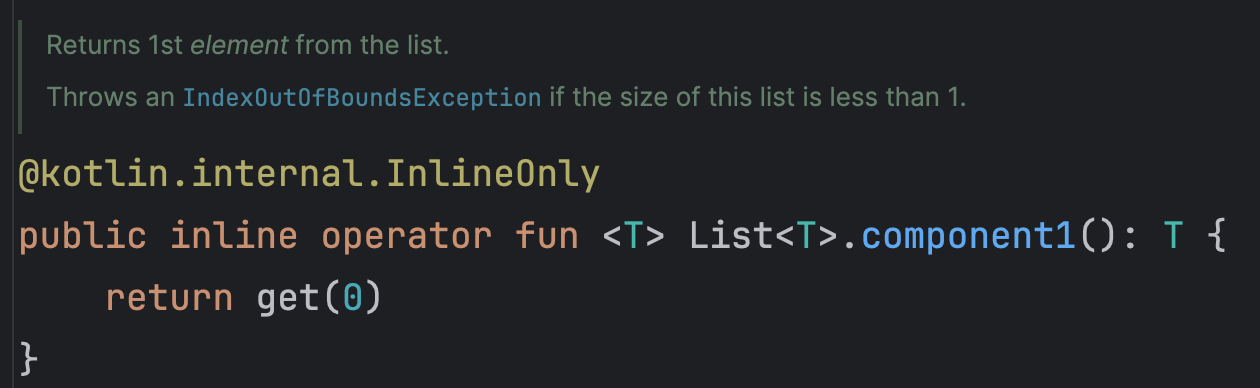
리스트의 첫번째 요소를 반환한다. 만약 리스트의 요소를 첫번째 이외에도 가져오고 싶다면 1이 아닌 다른 숫자를 적용하면 된다. 5번째까지 가능한 것 같다.
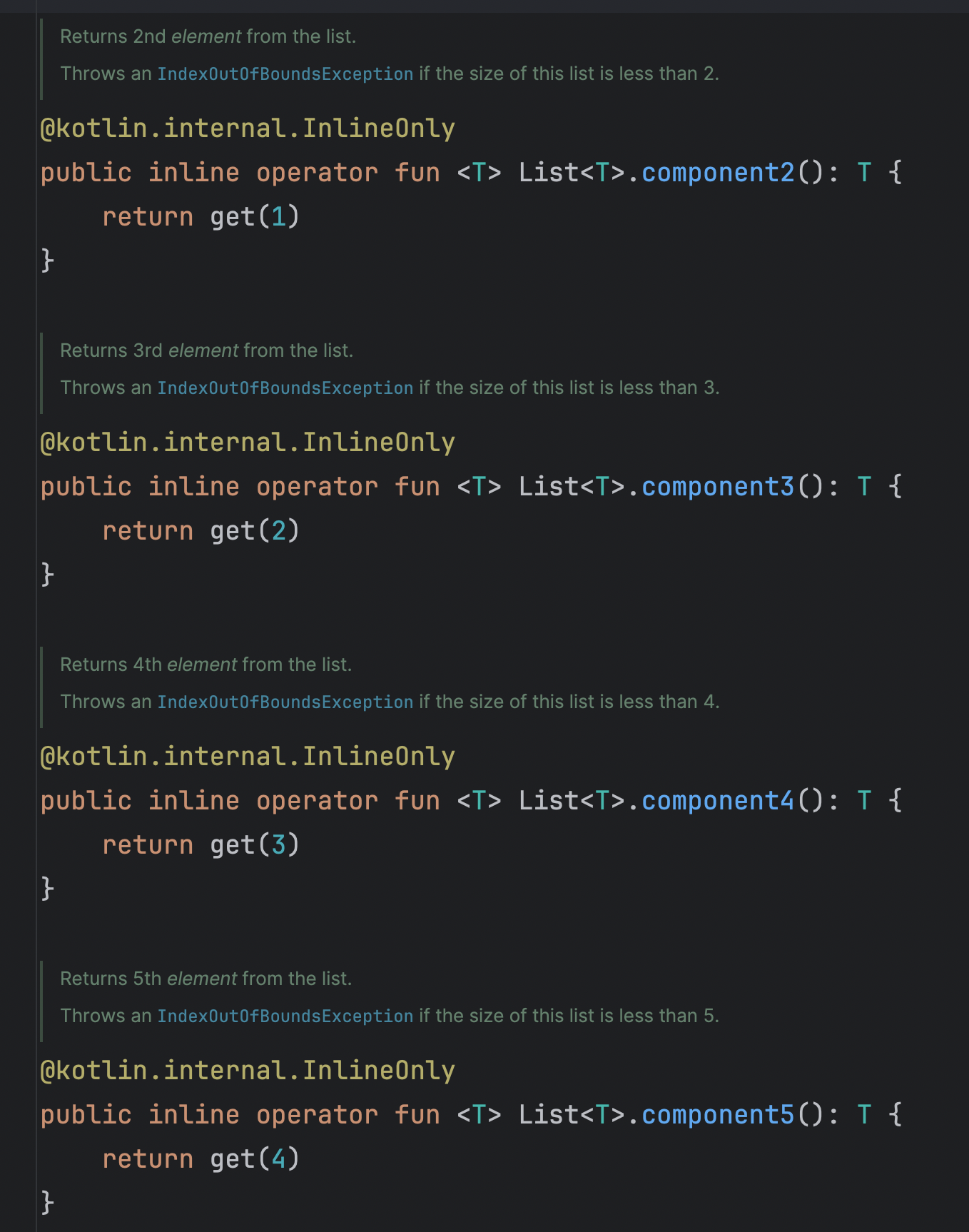
contains(), elementAt(), elementAtOrElse(), elementAtOrNull()

해당 요소가 포함되어 있는지 확인하는 용도로 쓰인다.
그렇다면 특정 위치의 element를 알고 싶다면? elementAt을 쓰면 된다.

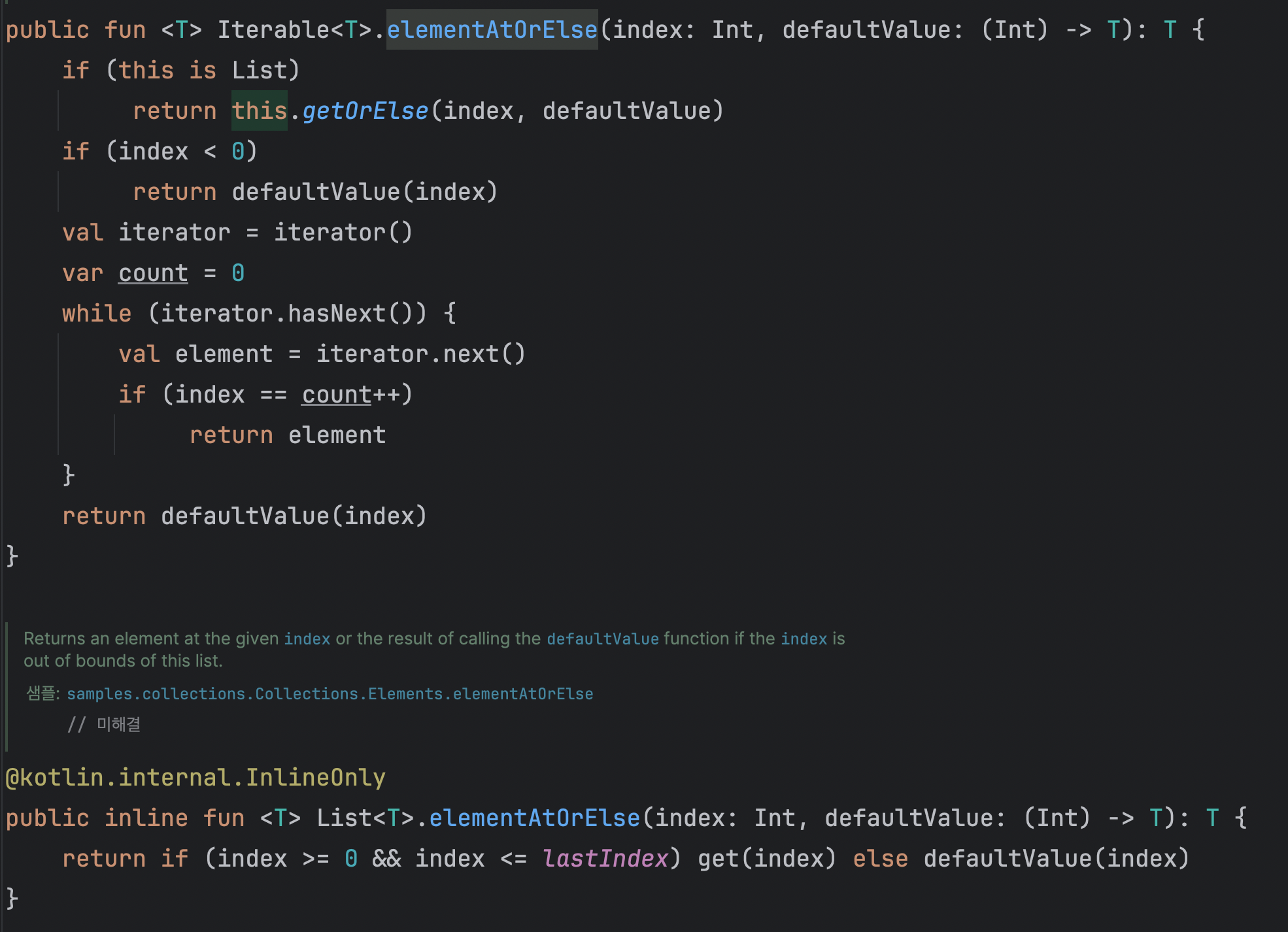
코드를 보니 elementAtOrElse 를 사용하는 것을 볼 수 있다. 특정 위치에 element가 없다면 대신 다른 것을 내보내는 역할에 쓰인다.
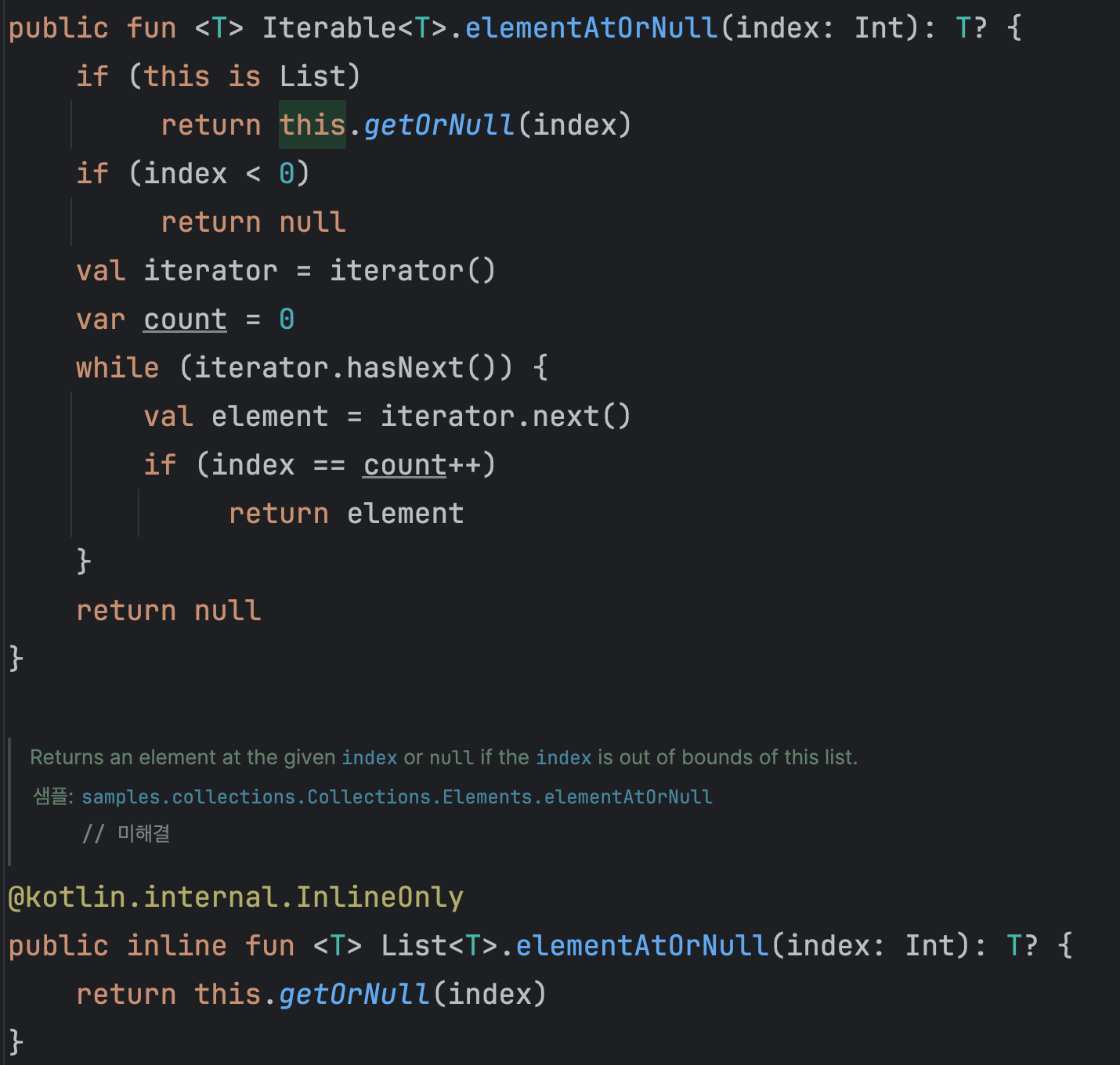
아 물론 default가 아닌 null을 내보내고 싶을때는 elementAtOrNull()를 쓰면 된다.
find ⭐️
- find : 앞에서부터 탐색하여 만족하는 요소 존재한다면 만족하는 요소의 가장 첫번째를 반환한다. 없다면 null을 반환한다.
- findLast: 뒤에서부터 탐색하여 만족하는 요소가 존재한다면 만족하는 요소 있다면 반환하고 없다면 null을 반환한다.
get
- getOrElse : 인덱스 위치에 요소가 있으면 해당 요소를 반환하고 아닌 경우, 지정한 기본값을 반환한다.
- getOrNull : 주어진 인덱스에 대해 element가 없으면 반환해주고, 없으면 null 반환한다.
index
- indexOf : 주어진 요소에 일치하는 첫 인덱스를 반환한다.
- indexOfFirst : 람다식에 일치하는 첫 요소의 인덱스를 반환한다.
- indexOfLast : 람다식에 일치하는 마지막 요소의 인덱스를 반환한다.
last, first ⭐️
-
last: 마지막 요소를 반환한다. 람다식에 일치하는 마지막 요소 반환한다.
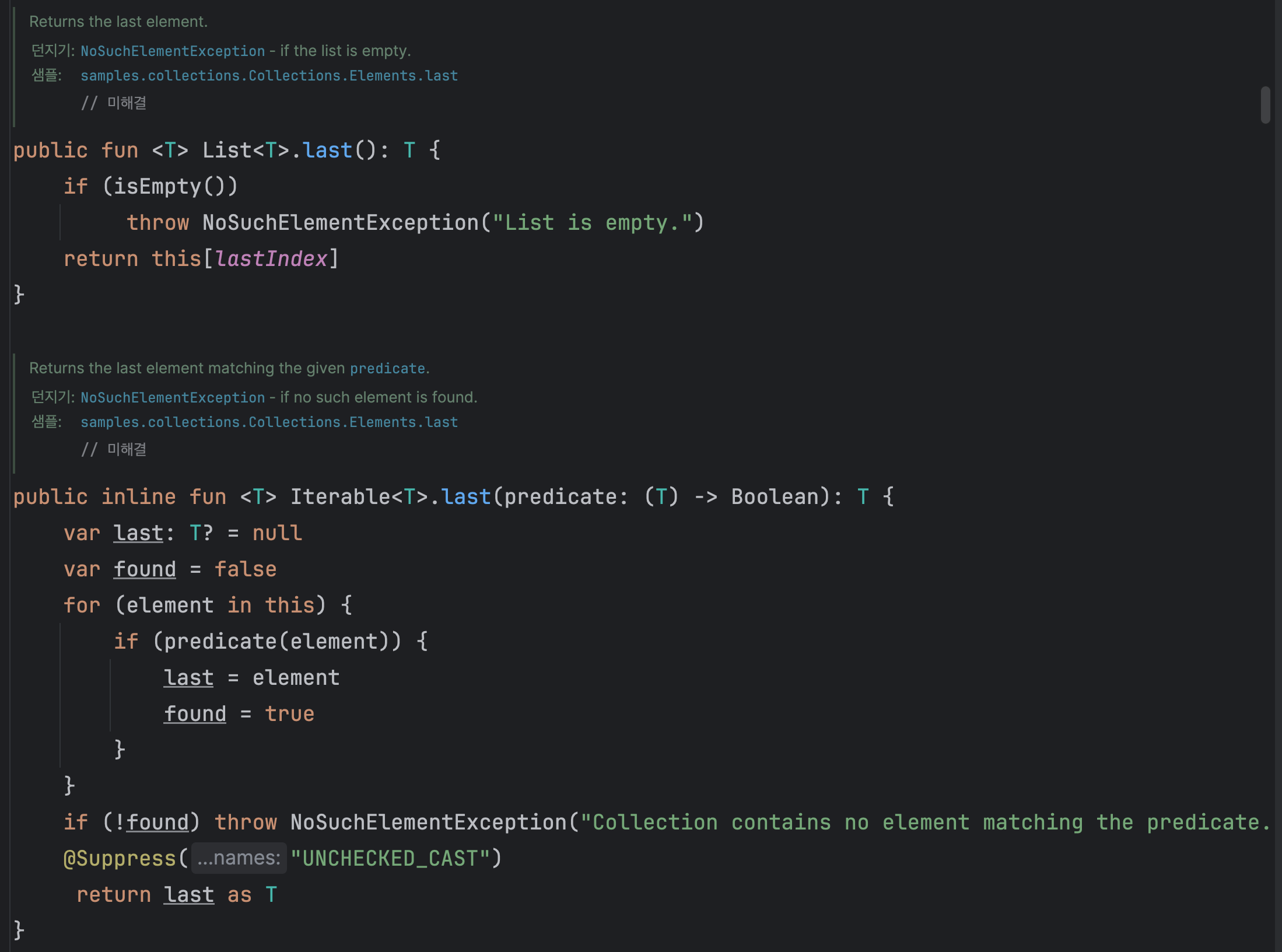
그외 :
lastIndexOf() - 마지막 인덱스 반환
lastOrNull() - 없으면 null 반환 -
first: 첫번째 요소를 반환한다. 람다식에 일치하는 첫번째 요소를 반환한다.
그외
firstNotNullOf - 주어진 람다를 적용한 결과 중 첫 번째로 null이 아닌 값을 반환
( first는 요소 자체를 반환하지만 firstNotNullOf는 요소에 변환을 적용한 후 null이 아닌 결과를 찾는다.)
firstNotNullOfOrNull - NoSuchElementException이 발생하는 상황에서 null을 반환
firstOrNull() - 없으면 null 반환
random
- random() : collection의 요소 중 하나를 랜덤으로 가져온다
- randomOrNull() : collection의 요소 중 하나를 랜덤으로 가져오거나 collection이 비어있으면 null을 반환한다.
single
- single() : 조건을 만족하는 원소가 딱 하나일 때 그 값을 반환한다. 없으면 에러낸다.
- singleOrNull() : 조건을 만족하는 원소가 딱 하나일 때 그 값을 반환한다. 없으면 null을 반환한다.
drop ⭐️
- drop(n: Int) : 리스트의 앞부분부터 지정한 개수(n)만큼의 요소를 뺀 새로운 리스트를 생성하는 메서드
- dropLast(n: Int) : 리스트의 뒤에서부터 지정한 개수(n)만큼의 요소를 뺀 새로운 리스트를 생성하는 메서드
- dropWhile(predicate: (T) -> Boolean) : 조건이 만족할 때까지 앞에서부터 버리고 나머지를 리턴한다
- dropLastWhile(predicate: (T) -> Boolean) : 조건이 만족할 때까지 뒤에서부터 버리고 나머지를 리턴한다.
filter ⭐️
-
filter : 컬렉션에서 주어진 조건을 만족하는 요소들만을 필터링하여 새로운 리스트를 반환
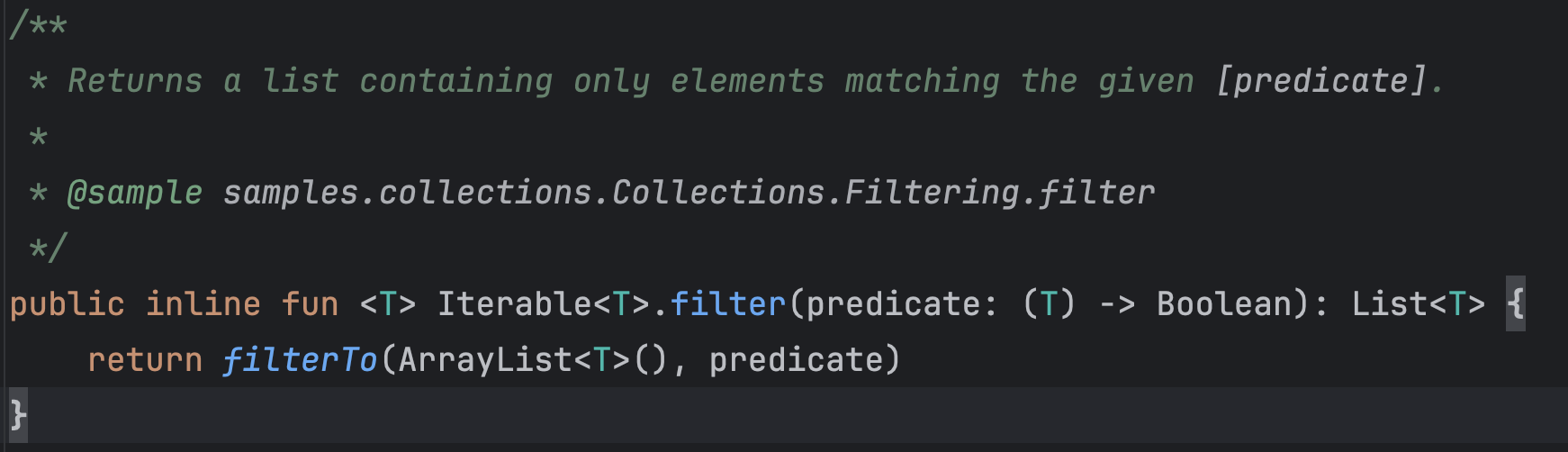

-
filterTo : 컬렉션에서 주어진 조건을 만족하는 요소들만 필터링하여, 그 결과를 주어진 컬렉션에 추가

📌 인덱스 활용
-
filterIndexed : 리스트의 각 요소와 해당 요소의 인덱스를 기반으로 조건에 맞는 요소들만을 필터링하여 새로운 리스트를 반환. 새로운 리스트가 필요할 때 사용
 -> 각 요소의 인덱스를 고려하여 조건을 만족하는 요소만 필터링하고 있음. 여기서 짝수 인덱스이면서 값이 2보다 큰 요소들만 선택됨
-> 각 요소의 인덱스를 고려하여 조건을 만족하는 요소만 필터링하고 있음. 여기서 짝수 인덱스이면서 값이 2보다 큰 요소들만 선택됨 -
filterIndexedTo : 주어진 리스트나 컬렉션에 인덱스와 값을 기준으로 필터링된 요소를 추가. 결과를 다른 컬렉션에 담아야 할 때 유용
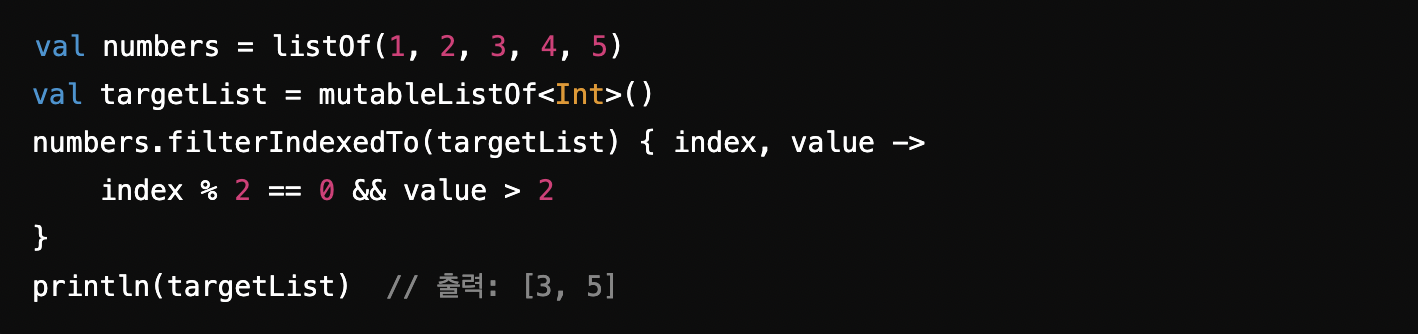 -> 필터링된 결과를 새로운 리스트에 반환하는 대신, 이미 존재하는 targetList에 추가
-> 필터링된 결과를 새로운 리스트에 반환하는 대신, 이미 존재하는 targetList에 추가
📌 특정 타입의 요소들만 필터링
-
filterIsInstance : 컬렉션에서 특정 타입의 요소들만 필터링하여 새로운 리스트로 반환. 새로운 리스트가 필요할 때 사용
 -> String 타입의 요소들만 필터링하여 새로운 리스트를 반환
-> String 타입의 요소들만 필터링하여 새로운 리스트를 반환 -
filterIsInstanceTo : 컬렉션에서 특정 타입의 요소들을 주어진 컬렉션에 필터링하여 추가. 기존 컬렉션을 이용해 결과를 추가할 때 유용
 -> 필터링된 결과를 새로운 리스트가 아닌, targetList라는 기존의 리스트에 추가
-> 필터링된 결과를 새로운 리스트가 아닌, targetList라는 기존의 리스트에 추가
📌 특정 조건에 맞지 않는 요소 또는 null이 아닌 요소를 필터링
-
filterNot : 주어진 조건을 만족하지 않는 요소들만 필터링하여 새로운 리스트를 반환

-
filterNotTo : 주어진 조건을 만족하지 않는 요소들만 필터링하여, 그 결과를 주어진 컬렉션에 추가

-
filterNotNull : 컬렉션에서 null이 아닌 요소들만 필터링

-
filterNotNullTo : 주어진 조건을 만족하지 않는 요소들만 필터링하여, 그 결과를 주어진 컬렉션에 추가

기타 ⭐️
-
slice : 컬렉션에서 주어진 인덱스 또는 범위에 해당하는 요소를 선택하여 새로운 컬렉션을 반환. 인덱스 범위를 지정하여 그에 해당하는 요소만 선택

-
partition : 컬렉션의 요소를 두 개의 리스트로 나누는 함수

-
take : 컬렉션의 처음부터 주어진 개수만큼의 요소를 선택하여 새로운 리스트를 반환

-
takeLast : 컬렉션의 끝에서부터 주어진 개수만큼의 요소를 선택하여 새로운 리스트를 반환
-
takeLastWhile : 주어진 조건을 만족하는 마지막 요소들만 선택하여 새로운 리스트를 반환합니다. 조건을 만족하지 않는 첫 번째 요소가 발견될 때까지 선택. 조건에 맞는 요소를 끝에서부터 선택
-
takeWhile : 주어진 조건을 만족하는 처음부터 요소들을 선택하여 새로운 리스트를 반환합니다. 조건을 만족하지 않는 첫 번째 요소가 발견될 때까지 선택

-
reversed : 컬렉션의 요소 순서를 반전시켜 새로운 리스트를 반환 ⭐️

-
shuffle : 컬렉션의 요소를 무작위로 섞어 새로운 리스트를 반환

sort ⭐️
-
sortBy : 오름차순으로 정렬
-
sortByDescending : 내림차순으로 정렬

-
sorted : 리스트를 오름차순으로 정렬한 새로운 리스트를 반환
-
sortedDescending : 리스트를 내림차순으로 정렬한 새로운 리스트를 반환

-
sortedBy : 주어진 기준에 따라 오름차순으로 정렬한 새로운 리스트를 반환
-
sortedByDescending : 주어진 기준에 따라 내림차순으로 정렬한 새로운 리스트를 반환

-
sortedWith : 커스텀 Comparator를 사용하여 정렬한 새로운 리스트를 반환

sortBy, sortByDescending: 원본 리스트를 기준에 따라 정렬하며, 원본이 변경됨 (MutableList 전용).
sorted, sortedBy, sortedByDescending, sortedDescending, sortedWith: 새로운 리스트를 반환하며, 원본은 변경되지 않음.
변환
컬렉션을 배열로 변환
-
toBooleanArray
-
toByteArray
-
toCharArray
-
toDoubleArray
-
toFloatArray
-
toIntArray
-
toLongArray
-
toShortArray
-
toMutableSet
-
toCollection : 컬렉션을 다른 컬렉션(타입 지정 가능)으로 변환. 주로 새 컬렉션에 기존 데이터를 넣고자 할 때 사용

-
toHashSet : 컬렉션을 HashSet으로 변환. 중복을 제거하고 순서는 보장
-
toList
-
toMutableList
-
toSet
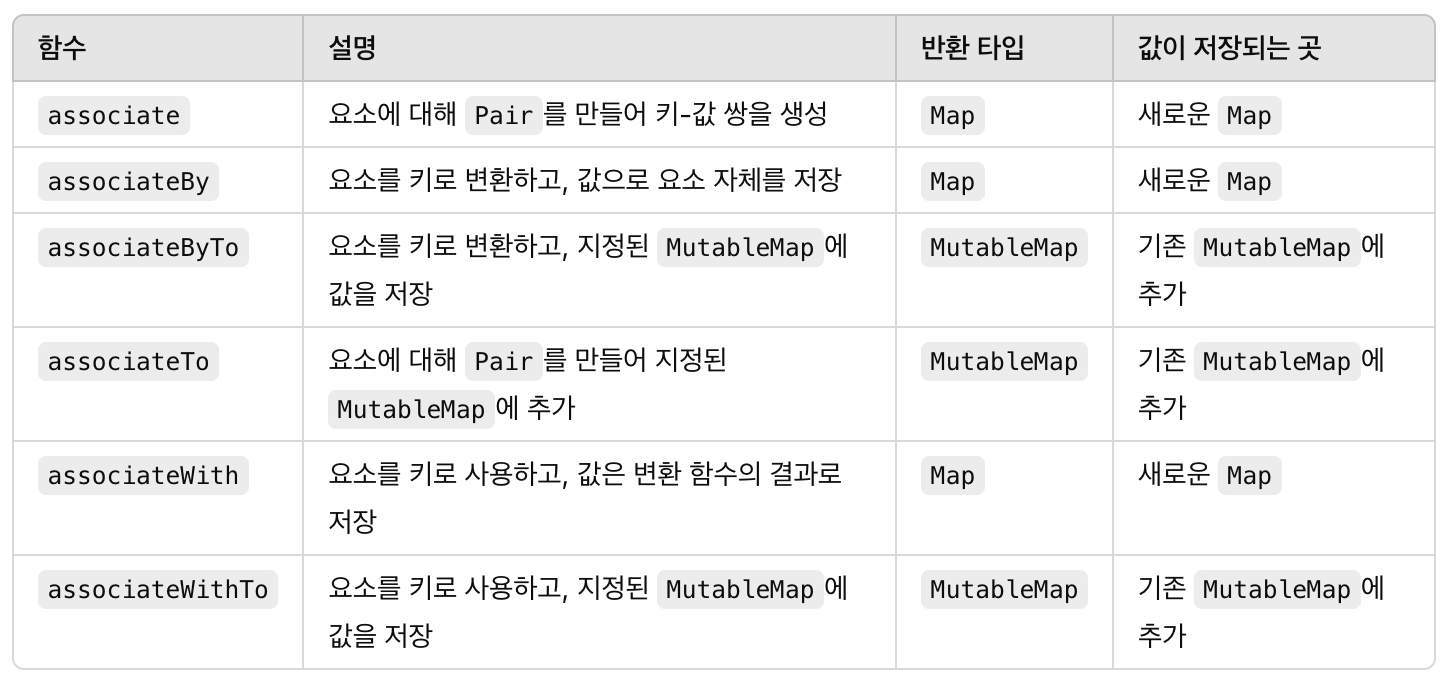
associate ⭐️
-
associate : 컬렉션의 각 요소에 대해 Pair를 생성하여, 이를 키-값 쌍으로 Map

-
associateBy : 각 요소를 키로 변환하는 함수를 제공하여, 이를 기준으로 Map을 만듦

-
associateByTo : 기존 MutableMap에 각 요소를 키로 변환한 값을 추가하여 MutableMap을 만듦. associateBy와 기능은 동일하지만, 결과를 지정한 MutableMap에 추가

-
associateTo : 각 요소에 대해 Pair를 생성하고, 이를 주어진 MutableMap에 추가. associate와 기능은 동일하지만, 결과를 지정한 MutableMap에 추가

-
associateWith : 각 요소를 키로 사용하고, 이를 값으로 변환하는 함수를 제공하여 Map을 만든다

-
associateWithTo : 각 요소를 키로 사용하고, 변환한 값을 제공된 MutableMap에 추가하여 MutableMap을 만듭니다. associateWith와 동일하지만, 결과를 지정한 MutableMap에 추가

group ⭐️
-
groupBy : 컬렉션의 요소들을 지정된 키 기준으로 그룹화하여, Map으로 반환

-
groupByTo : groupBy와 동일하지만, 그룹화 결과를 새로운 Map 대신 지정한 MutableMap에 추가

-
groupingBy : 컬렉션을 지연 그룹화하는데 사용됩니다. groupingBy는 즉시 결과를 반환하는 대신 그룹화 전략 객체를 생성. 그룹화된 데이터를 후처리하기 위한 여러 확장 함수와 함께 사용

정리
groupBy: 즉시 그룹화하여 새로운 Map 반환.
groupByTo: 결과를 기존 MutableMap에 추가.
groupingBy: 지연 그룹화 후 추가 처리 가능.
map ⭐️
- flatMap : 각 요소를 변환한 후 다중 요소로 확장하고, 이를 평탄화(flatten)하여 하나의 리스트로 만든다.

- flatMapIndexed : 각 요소와 인덱스를 사용하여 다중 요소로 변환하고, 이를 평탄화(flatten)하여 하나의 리스트로 만든다.

-
flatMapIndexedTo : 각 요소와 인덱스를 사용하여 변환한 다중 요소를 지정된 MutableCollection에 추가하고, 이를 평탄화(flatten)

-
flatMapTo : 각 요소를 다중 요소로 변환하고, 이를 지정된 MutableCollection에 평탄화(flatten)하여 추가

- map : 컬렉션의 각 요소를 변환하여 새로운 컬렉션으로 만든다.

-
mapIndexed : 각 요소와 해당 요소의 인덱스를 함께 사용하여 변환된 새로운 컬렉션을 만든다.

-
mapIndexedNotNull : 각 요소와 인덱스를 함께 사용하여 변환하되, null을 제외한 요소들만을 포함하는 새로운 컬렉션을 만든다.

- mapIndexedNotNullTo : 각 요소와 인덱스를 사용하여 변환한 결과에서 null을 제외하고, 지정된 MutableCollection에 추가

- mapIndexedTo : 각 요소와 인덱스를 함께 사용하여 변환된 결과를 지정된 MutableCollection에 추가

- mapNotNull : 각 요소를 변환하되, null이 아닌 요소들만 포함하는 새로운 컬렉션을 만든다

- mapNotNullTo : 각 요소를 변환하여 null을 제외한 결과를 지정된 MutableCollection에 추가한다.

- mapTo : 각 요소를 변환한 결과를 지정된 MutableCollection에 추가한다.

기타
-
withIndex : 컬렉션의 각 요소에 대한 인덱스와 값을 포함하는 시퀀스를 반환
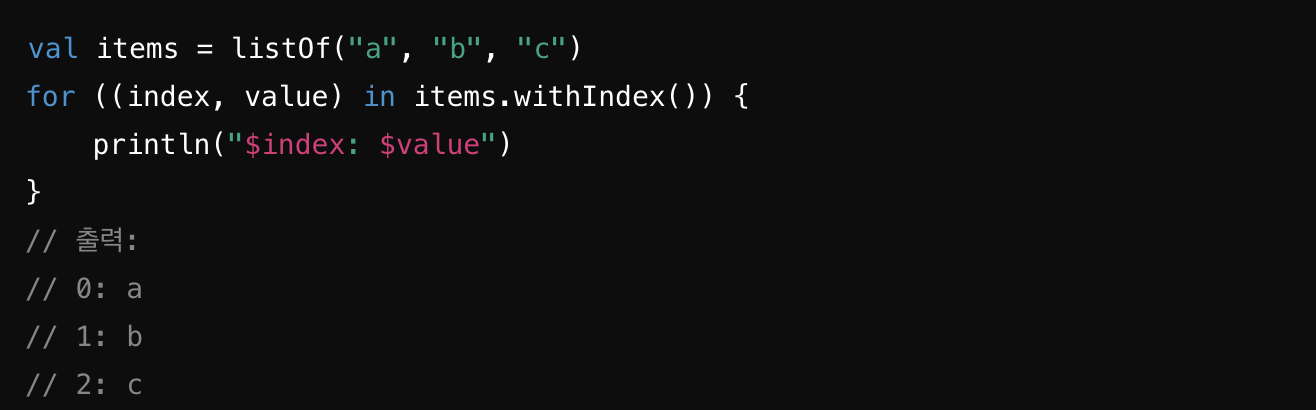
-
distinct : 컬렉션의 중복 요소를 제거하여 새로운 컬렉션을 반환 ⭐️
-
distinctBy : 주어진 조건에 따라 중복 요소를 제거

-
intersect : 두 컬렉션의 교집합을 반환

-
union : 두 컬렉션의 합집합을 반환 ⭐️
-
subtract : 컬렉션에서 다른 컬렉션의 요소를 제거하여 새로운 컬렉션을 반환

-
all : 컬렉션의 모든 요소가 주어진 조건을 만족하는지 확인 ⭐️
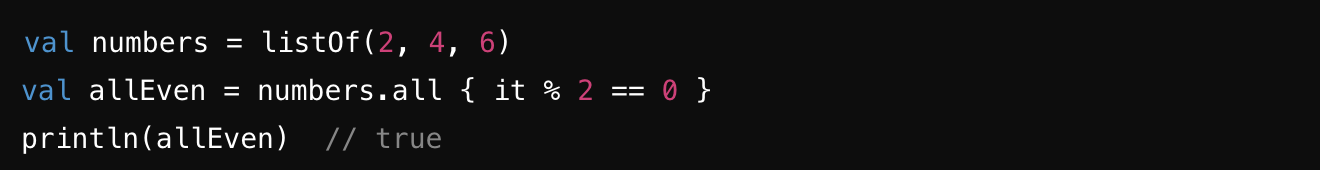
-
any : 컬렉션의 어떤 요소라도 주어진 조건을 만족하는지 확인 ⭐️
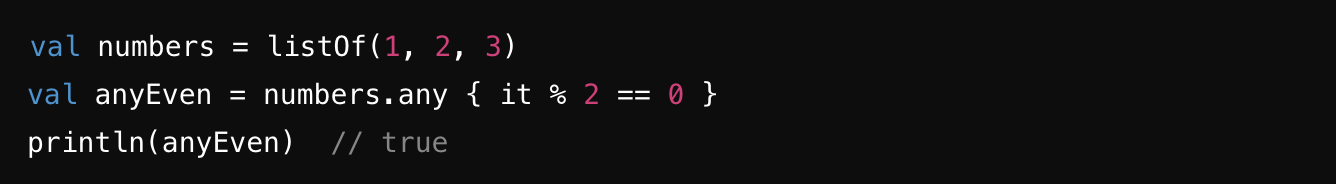
-
count : 주어진 조건을 만족하는 요소의 개수를 반환 ⭐️
-
none : 컬렉션의 모든 요소가 주어진 조건을 만족하지 않는지 확인 ⭐️
-
windowed : 컬렉션을 지정한 크기의 슬라이딩 윈도우로 나누어 리스트의 리스트를 반환 ⭐️

-
zip : 두 컬렉션의 요소를 쌍으로 묶어 새로운 리스트를 생성 ⭐️

-
zipWithNext : 컬렉션의 요소를 인접한 요소와 쌍으로 묶어 새로운 리스트를 생성

-
joinTo : 컬렉션의 모든 요소를 지정한 대상에 문자열로 추가

-
joinToString : 컬렉션의 모든 요소를 문자열로 결합하여 반환. 각 요소 사이에 지정된 구분자를 사용하고, 필요에 따라 접두사와 접미사를 추가할 수 있다 ⭐️
형식)
joinToString(
separator: String = ", ",
prefix: String = "",
postfix: String = "",
limit: Int = -1,
truncated: String = "...",
transform: ((T) -> CharSequence)? = null
): String
-
asSequence : 컬렉션을 시퀀스로 변환하여, 지연 평가를 사용할 수 있게 합니다. 이는 큰 컬렉션을 처리할 때 성능을 개선할 수 있습니다. 특징: 시퀀스는 중간 연산을 지연 실행하므로, 효율적으로 요소를 처리할 수 있다. ⭐️

-
average : 숫자형 컬렉션의 평균 값을 계산하여 반환
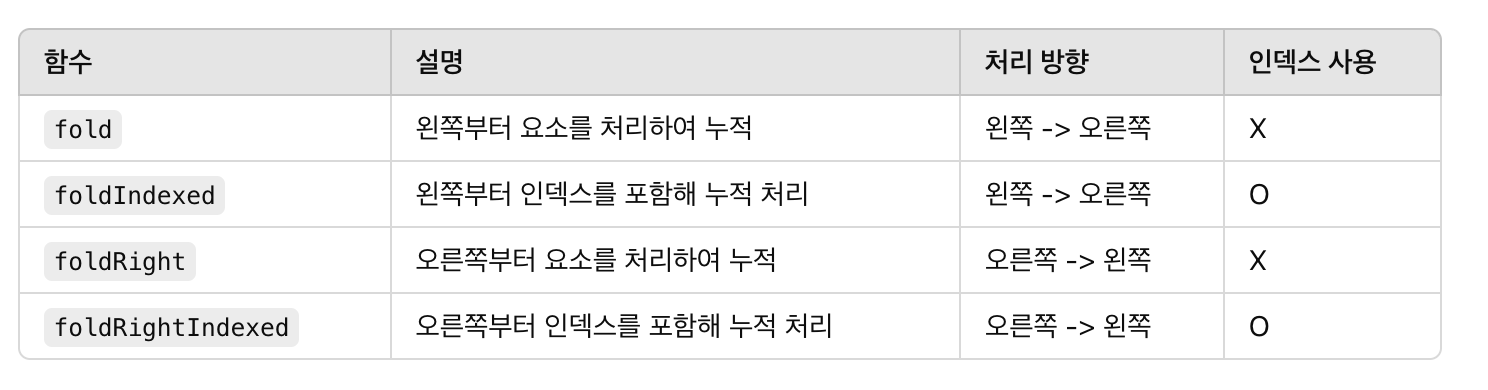
fold ⭐️
-
fold : 컬렉션의 왼쪽부터(앞에서부터) 각 요소를 누적하여 하나의 값으로 축약합니다. 초기값을 설정한다.
-- 형식: fold(initial: R, operation: (acc: R, T) -> R)

-
foldIndexed : fold와 동일하게 왼쪽부터 처리하되, 인덱스를 포함하여 요소를 처리한다.
-- 형식: foldIndexed(initial: R, operation: (index: Int, acc: R, T) -> R)

-
foldRight : 컬렉션의 오른쪽부터(뒤에서부터) 각 요소를 누적하여 하나의 값으로 축약합니다. 초기값을 설정할 수 있다.
-- 형식: foldRight(initial: R, operation: (T, acc: R) -> R)

-
foldRightIndexed
-- 형식: foldRightIndexed(initial: R, operation: (index: Int, T, acc: R) -> R)

Each ⭐️
- forEach : 컬렉션의 각 요소에 대해 주어진 작업을 수행함.
- forEachIndexed : forEach와 동일하나, 각 요소와 함께 인덱스 정보도 제공
- onEach : 컬렉션의 각 요소에 대해 주어진 작업을 수행한 후, 원래 컬렉션을 그대로 반환합니다. 보통 중간 연산으로 사용되며, 작업을 수행한 후 결과를 다시 사용
- onEachIndexed : onEach와 동일하나, 각 요소와 함께 인덱스 정보도 제공합니다. 작업 후 원래 컬렉션을 반환
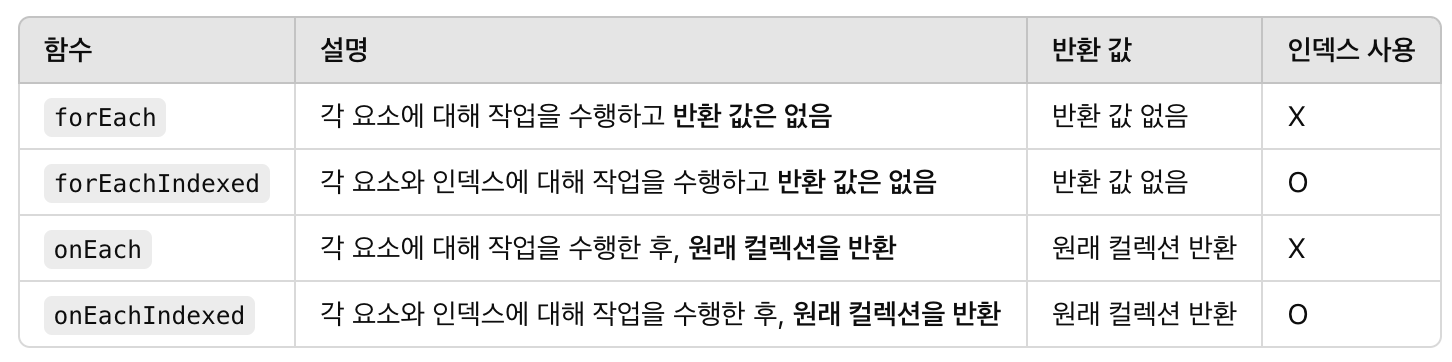
- forEach 계열은 주로 부작용을 발생시키며 결과를 반환하지 않는다.
- onEach 계열은 부작용을 발생시키면서도 원래 컬렉션을 반환하여 체이닝에 유용
max ⭐️
-
max : 컬렉션에서 최댓값을 찾기
-
maxOrNull : 컬렉션에서 최댓값을 찾으며, 비어 있는 경우 null을 반환
-
maxByOrNull : 주어진 람다식에 따라 특정 기준을 기반으로 최댓값을 찾으며, 비어 있는 경우 null을 반환
-
maxBy : 주어진 람다식에 따라 특정 기준을 기반으로 최댓값을 찾는다. 비어 있는 컬렉션이면 예외가 발생

-
maxOf : 주어진 람다식을 적용하여 최댓값을 반환합니다. 비어 있는 컬렉션이면 예외가 발생

-
maxOfOrNull : 주어진 람다식을 적용하여 최댓값을 반환하며, 비어 있는 경우 null을 반환
-
maxOfWith : 주어진 비교 기준(Comparator)을 사용하여 특정 람다식을 적용한 후 최댓값을 반환합니다. 비어 있는 컬렉션이면 예외가 발생

-
maxOfWithOrNull : 주어진 비교 기준과 람다식을 사용하여 최댓값을 찾으며, 비어 있는 경우 null을 반환
-
maxWith : 주어진 비교 기준(Comparator)을 사용하여 컬렉션에서 최댓값을 반환합니다. 비어 있는 컬렉션이면 예외

-
maxWithOrNull : 주어진 비교 기준(Comparator)을 사용하여 최댓값을 찾으며, 비어 있는 경우 null을 반환
min ⭐️
- min
- minBy
- minByOrNull
- minOf
- minOfOrNull
- minOfWith
- minOfWithOrNull
- minOrNull
- minWith
- minWithOrNull
reduce ⭐️
reduce 함수들은 컬렉션의 요소들을 누적(accumulate)하여 하나의 값으로 축약하는 연산을 수행합니다. fold와 비슷하지만, reduce는 초기값을 사용하지 않고 컬렉션의 첫 번째 요소를 누적값으로 시작합니다.
-
reduce: 컬렉션의 왼쪽부터 차례대로 요소를 누적하며 하나의 값으로 축약합니다. 첫 번째 요소를 시작점으로 사용합니다. 비어 있는 컬렉션이면 예외가 발생

초기값 없이 컬렉션의 첫 번째 요소를 누적값으로 사용 -
reduceOrNull : reduce와 동일하지만, 비어 있는 컬렉션일 경우 null을 반환
-
reduceIndexed : reduce와 동일하지만, 인덱스 정보를 함께 사용하여 요소를 누적합니다. 첫 번째 요소를 시작점으로 사용합니다. 비어 있는 컬렉션이면 예외가 발생

-
reduceIndexedOrNull : reduceIndexed와 동일하지만, 비어 있는 컬렉션일 경우 null을 반환
reduceRight 계열은 오른쪽부터 처리한다
- reduceRight
- reduceRightIndexed
- reduceRightIndexedOrNull
- reduceRightOrNull
running ⭐️
runningFold와 runningReduce 계열 함수들은 중간 결과를 포함한 연산의 누적 결과 리스트를 반환하는 함수들입니다. 기존의 fold와 reduce처럼 연산을 누적하는 방식이지만, 매 단계마다의 중간 결과를 리스트에 저장하여 최종 결과뿐만 아니라 각 단계에서의 결과를 확인할 수 있다.
-
runningFold : 주어진 초기값(initial value)에서 시작하여, 컬렉션의 각 요소마다 누적값을 적용한 중간 결과 리스트를 반환

-
runningFoldIndexed : runningFold와 동일하지만, 인덱스 정보를 함께 사용하여 각 요소마다 누적 연산을 수행하고 중간 결과 리스트를 반환
-
runningReduce : reduce와 유사하게, 초기값 없이 컬렉션의 첫 번째 요소를 누적값으로 시작하며, 각 요소마다 누적 결과 리스트를 반환

-
runningReduceIndexed : runningReduce와 동일하지만, 인덱스 정보를 함께 사용하여 각 요소마다 누적 연산을 수행하고 중간 결과 리스트를 반환
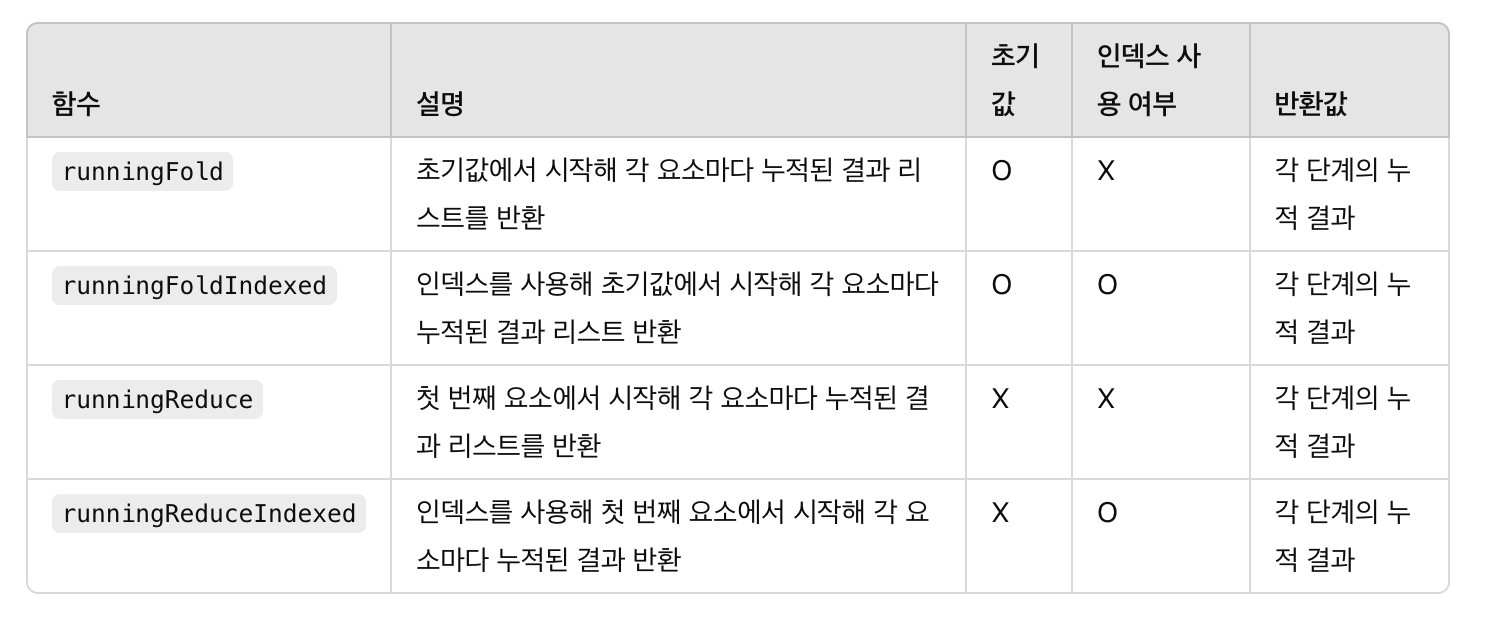
이 함수들은 각 단계별 중간 결과를 기록하는 점에서 단순한 fold 및 reduce와 차이가 있습니다.
scan ⭐️
-
scan : 컬렉션의 각 요소를 누적하여 결과 리스트를 반환합니다. 첫 번째 요소를 시작점으로 사용하고, 각 요소마다 누적 결과를 포함. 첫 번째 요소를 누적값으로 사용하며, 각 단계의 누적 결과가 리스트로 저장

-
scanIndexed : scan과 동일하지만, 인덱스 정보를 함께 사용하여 각 요소마다 누적 연산을 수행하고 결과 리스트를 반환합니다.

중간 결과를 기록하는 점에서 유용하며, 복잡한 누적 연산을 쉽게 구현할 수 있게 도와준다.
sum
-
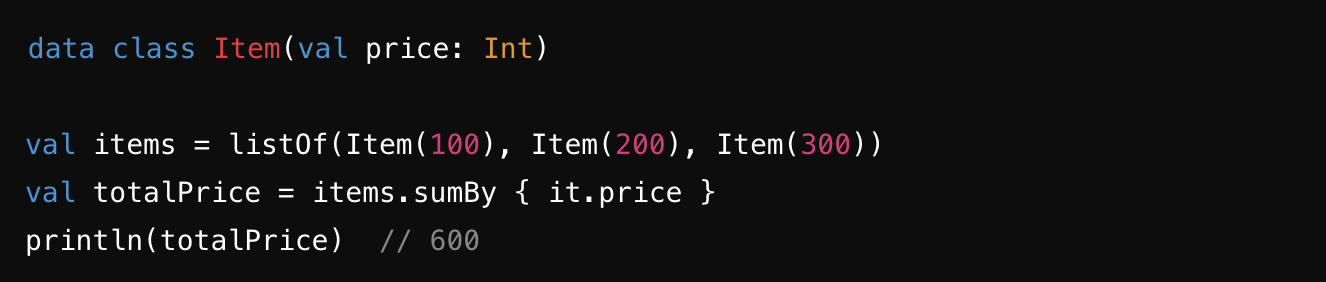
sumBy : 컬렉션의 각 요소에 대해 주어진 변환 함수를 적용하여 그 결과의 합을 계산합니다. 주로 정수 값을 반환하는 함수와 함께 사용
-
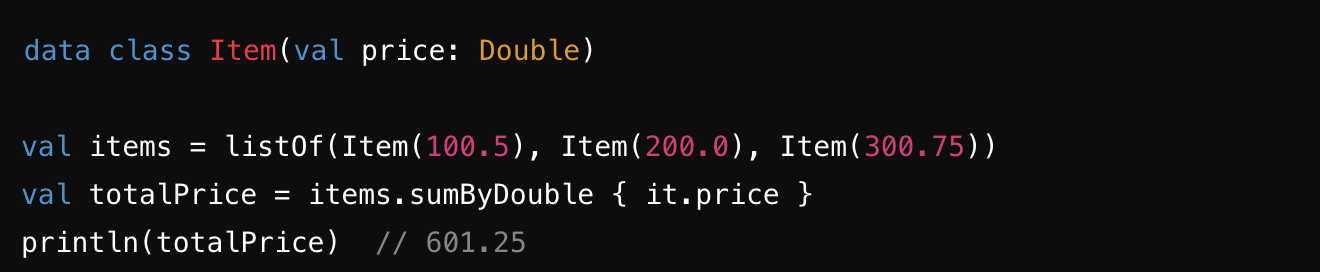
sumByDouble : 컬렉션의 각 요소에 대해 주어진 변환 함수를 적용하여 그 결과의 합을 계산합니다. 주로 Double 값을 반환하는 함수와 함께 사용합니다. 현재는 deprecated된 함수입니다.
-
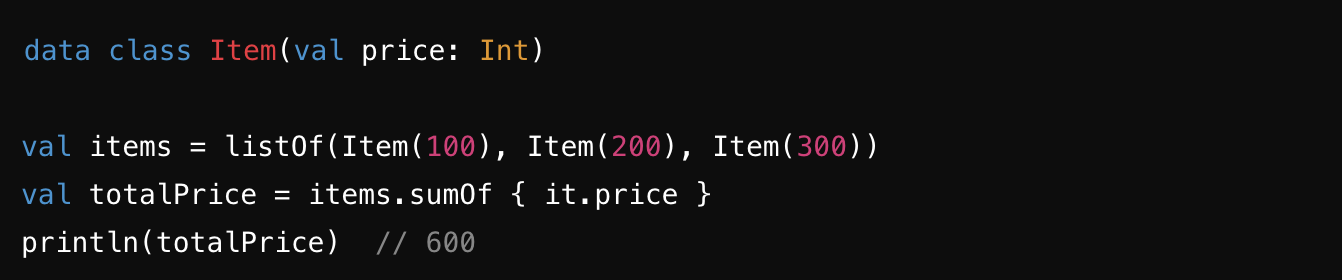
sumOf : 컬렉션의 각 요소에 대해 주어진 변환 함수를 적용하여 그 결과의 합을 계산합니다. Int, Double, Long 등 다양한 타입의 합계를 지원 ⭐️
require, chunk ⭐️
-
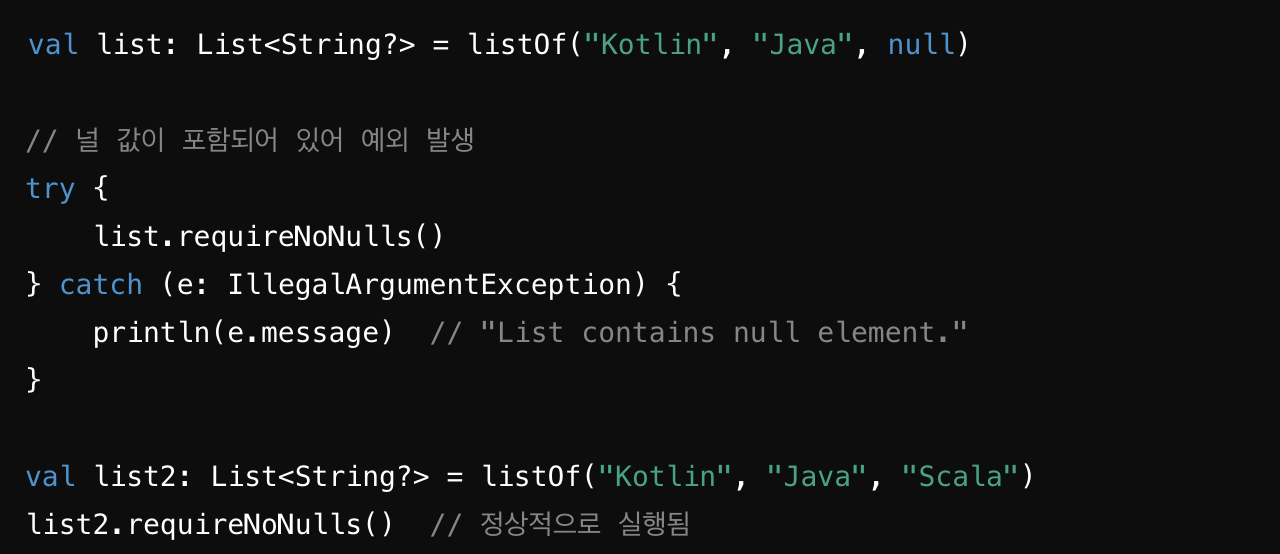
requireNoNulls : 컬렉션에 널(null) 값이 포함되어 있지 않음을 보장하는 함수입니다. 만약 컬렉션에 널 값이 포함되어 있다면, IllegalArgumentException을 발생시킵니다.
주로 널 값을 허용하지 않는 컬렉션을 필요로 하는 경우 사용합니다
-
chunked : 컬렉션을 주어진 크기(chunk size)로 나누어 작은 리스트의 리스트로 변환하는 함수. 남은 요소가 있는 경우, 마지막 청크는 주어진 크기보다 작을 수 있습니다. 이를 통해 대규모 데이터를 작은 조각으로 나누어 처리할 수 있습니다.

minus, plus
- minus
- minusElement : minus와 기능적으로 유사하지만, 명시적으로 minusElement를 사용하여 의도를 더욱 분명히 할 수 있습니다.
- plus
- plusElement : plus와 기능 같습니다

면접전이라 지식창고 시리즈 정주행하면서 많이 배웠습니다!
주제들에 대해서 엄청 고민을 많이 하신것 같아요!