1. Introduction
- CNN은 비전 뿐만 아니라 semantic parsing, sentence modeling 등 NLP에서도 좋은 결과를 보임.
- 본 논문에서는 간단한 CNN 모델과 약간의 하이퍼 파라미터 튜닝 및 정적 벡터 사용을 통해 여러 벤처마킹에서 우수한 결과를 보인다고 제시하고 있음.
- Google News 1000억개의 단어를 가지고 학습을 시켜 만들어진 단어 벡터인 word2vec 사용
- 구에서 가져온 단어 벡터들에서 semantic features을 찾아 낼 수 있음 → 감정적으로 유사한 단어들은 서로 가깝게 위치
- 다양한 분류 테스크에 사용되는 pre-trained word vectors와
fine-tuning을 통해 task-specific vectors 학습시켜 향상된 결과를 얻도록 함
fine-tuning을 통해 task-specific vectors 학습시켜 향상된 결과를 얻도록 함
1️⃣ 하이퍼 파라미터 변경을 적게 했음에도 불구하고, 1개의 레이어만을 가진 간단한 CNN 모델과 word2vec와 같이 pre-trained된 단어 벡터를 사용하여 우수한 성능을 얻을 수 있었음.
2️⃣ NLP 딥러닝 분야에 있어서 결국 pre-trained된 단어 벡터가 중요한 재료인 점을 실험 결과를 통해 제시함.
참고논문 : CNN features off-the-Shelf: An astunding baseline for recognition (2014), A. Razavian et al.
2 Model
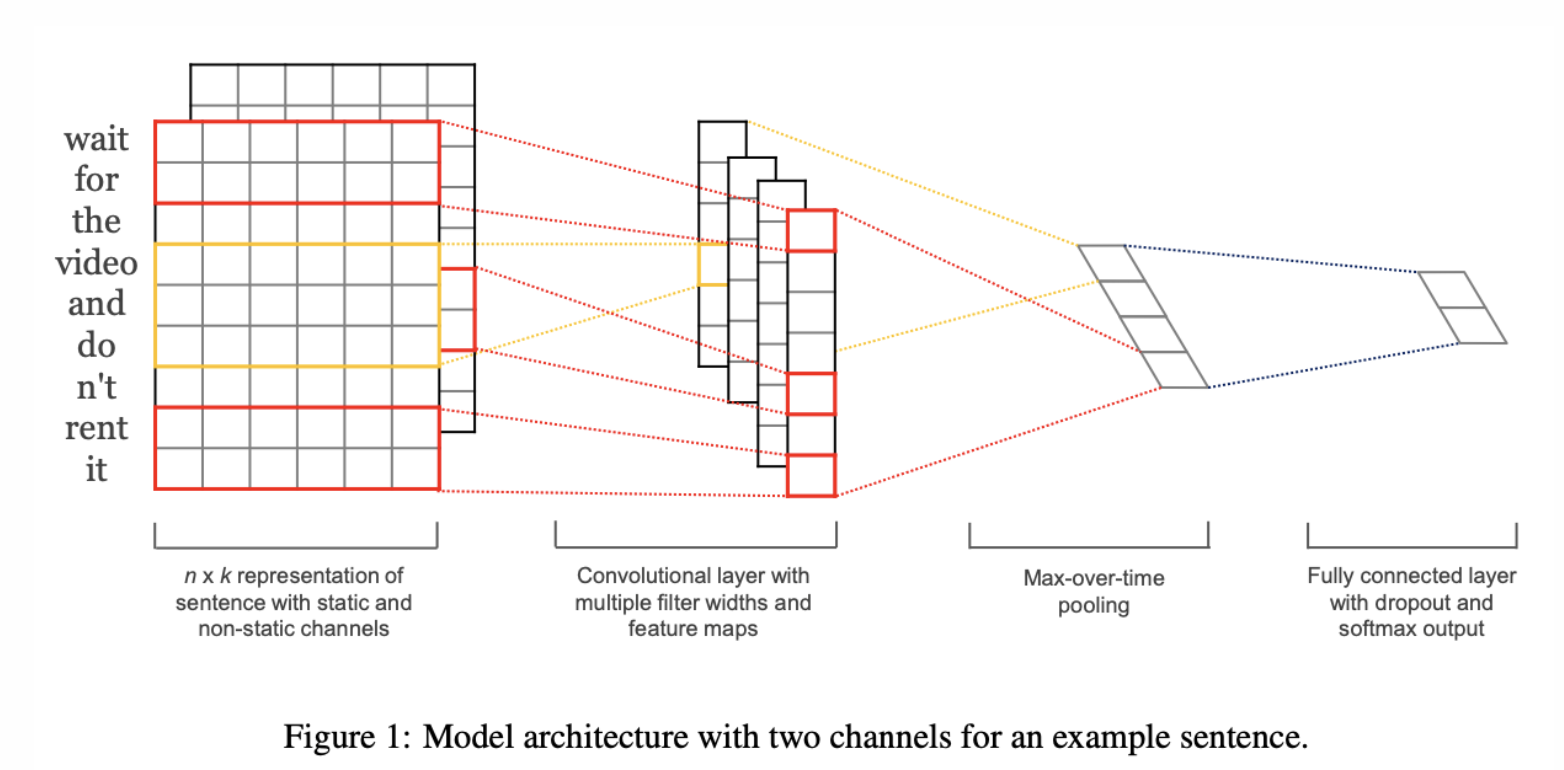
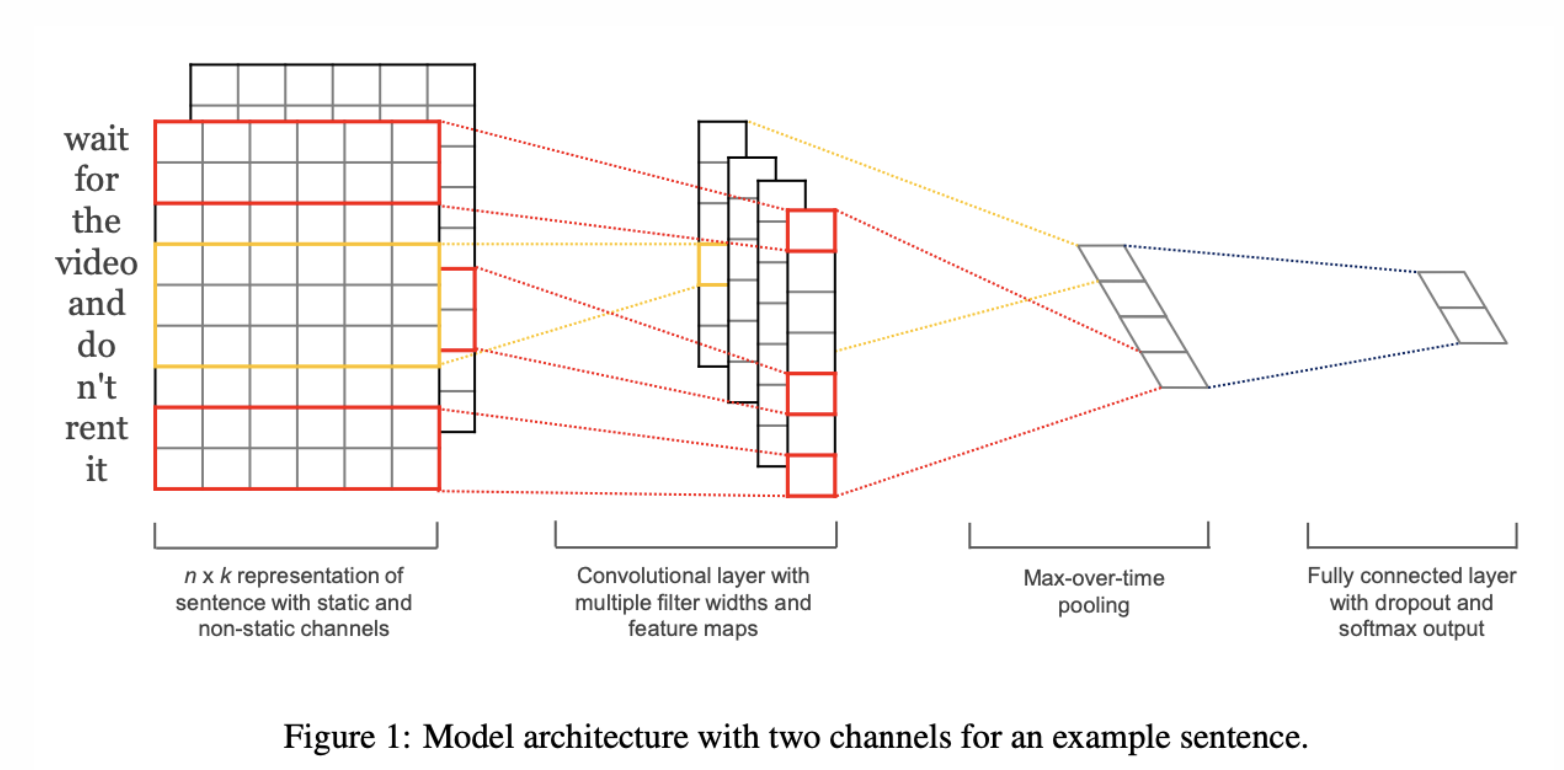
세부적으로 알아보기
- input = k-dimention의 단어 벡터
- 는 문장에서 i번째 단어의 word vector
- 문장은 n개의 단어를 concat하여 사용
- 길이가 n인 문장은 1부터 n까지의 word vector의 합(concatenation)으로 표현
- 이때, 필요하다면 padding을 추가
- 새로운 feature 만들어내기 위해 filter 사용
- CNN에는 새로운 feature를 만들어내는 filter w가 있고, 이는 h개의 단어에 대한 window
- convolution 연산을 통해 feature 생성
- : 윈도우 크기 h에 대한 의 feature
- : bias, : non linear function
-
위의 filter를 이용해 문장의 feature map c를 만듬
-
추출한 feature map에 max-over-time pooling을 적용
- 가장 중요한 feature를 추출하기 위함
효과 피쳐들을 penultimate layer를 구성하고 fully connected softmax layer로 통과되어서 라벨에 대한 확률 분포를 생성
- word vector에 대해 2개의 channel 적용
- training 동안 word vector를 static하게 유지
- backpropagation을 통해 fine tuning
➡️ 각 filter는 2개의 channe에 대해 적용이 되고, 결과는 feature 에 더해짐
2.1 Regularization
- 정규화를 위해 l2 norms를 이용한 dropout을 적용
- keep probability p=0.5라면 feature 중 반을 제거 ➡️ hidden unit들의 co-adaption 방지
- pernultimate layer
- m의 filter에서 추출한 z에 대해
- dropout을 적용한 수식으로 r은 masking vector이며, 확률 p를 이용한 random 변수
- m의 filter에서 추출한 z에 대해
- test 과정
- dropout 하지 않고, w 대신 dropout 확률을 곱하여 사용
- dropout 하지 않고, w 대신 dropout 확률을 곱하여 사용
- l2 정규화
- 가중치 벡터의 l2 norm이 s보다 클 경우 s 값을 가지도록 조정
- 가중치 벡터의 l2 norm이 s보다 클 경우 s 값을 가지도록 조정
3 Datasets and Experimental Setup
- 다양한 benchmarks에서 model test
- [Table 1] 데이터 셋의 요약 통계
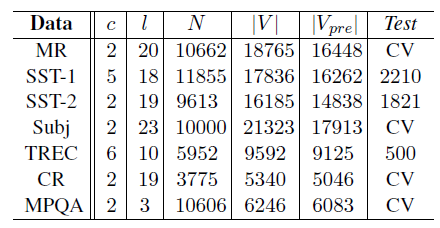
- MR : 영화 리뷰(한 문장), 긍정적-부정적 리뷰 분류
- SST-1 : Train/Dev/Test 분할 제공, 미세한 라벨(very positive, positive, neutral, negative, very negative)
- SST-2 : SST-1에서 neutral reviews 제거, binary labels 존재
- Subj : 주관적-객관적 리뷰 문장 분류 작업
- TREC : TRC 질문 데이터 셋 ➡️ 6가지 질문 유형 분류 (사람, 위치, 숫자 정보 등에 대한 질문인지 여부)
- CR : 다양한 제품(카메라, MP3 등)에 대한 고객 리뷰, 긍정적-부정적 리뷰 예측
- MPQA : MPQA 데이터 셋의 의견 양극성 탐지 하위 작업
3.1 Hyperparameters and Training
- 사용하는 모든 데이터 셋 (SST-2 Dev set의 grid search를 통한 선택)
- 정류된 linear units
- 각각 100개의 feature maps 있는 3, 4, 5의 filter windows (h)
- droupout rate (p) : 50
- 3의 l2 제약조건 (s)
- mini-batch size : 50
- Dev set : 조기 중지 이외의 조정 수행 X
- Standard Dev set 없는 경우 : Training data의 10%를 무작위로 선택
- Training : Adadelta update rule 사용 → 혼합된 mini-batches에 대한 확률적 경사 하강법
3.2 Pre-trained Word Vectors
- Initializing word vector
- unsupervised 신경 언어 모델
- large supervised training set 없는 경우의 성능 향상 방법
- word2vec 사용
- Google news의 100 billion 단어에 대해 훈련된 공개적으로 사용 가능한 vector
- dimensionality of 300
- 연속적인 bag-of-words architecture 사용하여 훈련됨
- pre-trained words set에 존재하지 않는 단어는 무작위로 초기화
3.3 Model Variation
모델의 몇 가지 변형으로 실험 진행
-
CNN-rand
- 모든 단어가 무작위로 초기화되고 training 중에 수정되는 기본 모델
-
CNN-static
- word2vec의 pre-trained vectors 존재하는 모델
- 모든 단어는 고정으로 유지
- only 모델의 다른 매개 변수만 학습됨
-
CNN-non-static
- static과 동일
- pre-trained vectors : 각 작업에 맞게 미세 조정됨
-
CNN-multichannel
- 두 개의 word vectors 존재하는 모델
- 각 vector set
- 'channel'로 취급
- 각 filter는 두 채널에 모두 적용
- gradients는 채널 중 하나를 통해서만 역전달됨
- 하나의 vector set는 고정으로 유지, 다른 하나의 vector set를 미세 조정할 수 있음
- 두 개의 channels 모두 word2vec으로 초기화됨
-
다른 무작위 요인의 영향을 분리하기 위해 각 데이터 셋 내에서 균일하게 유지
➡️ CV-fold 할당, 알 수 없는 word vector 초기화, CNN 매개 변수 초기화 등과 같은 무작위성의 다른 원천 제거
4 Results and Discussion
💡 핵심 point:
- Pre-trained 된 단어 벡터(word2vec)를 바탕으로 CNN 모델에서 약간의 hyperparameter tunning을 한 비교적 간단한 모델이지만 뛰어난 성능 관찰
- 결국은 pre-trained word vectors가 중요! NLP의 핵심 재료
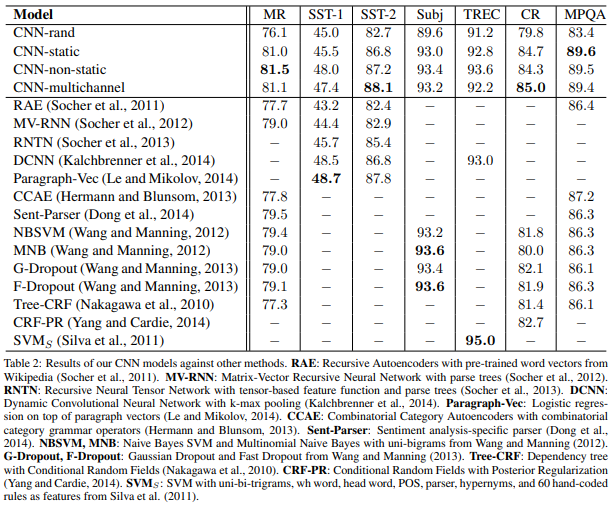
- 무작위로 초기화된 모든 단어(CNN-rand)는 좋은 성능을 보이지 않았음.
- CNN-static를 포함한 간단한 모델도 좋은 성능을 보이며, fine-tuning을 통해 더 좋은 성능을 만들 수 있다.(CNN-non-static)
- 범용 추출기(Universal Feature Extractor)로써 pre-trained word vector의 가치/중요성 발견
4.1 Multichannel vs. Single Channel Models
- 초기의 추론에는 Multichannel이 당연히 좋을 것이라고 예상(Over-fitting 문제 방지)
- 그러나, 위의 결과 표에서 볼 수 있듯 multichannel 모델이 모든 데이터셋에서 늘 좋은 성능을 보이진 않음 ➡️ 추가적으로 적절한 regularization, fine-tunning 필요하므로, 상황에 따라 적절한 접근 방법이 요구됨
4.2 Static vs. Non-static Representations
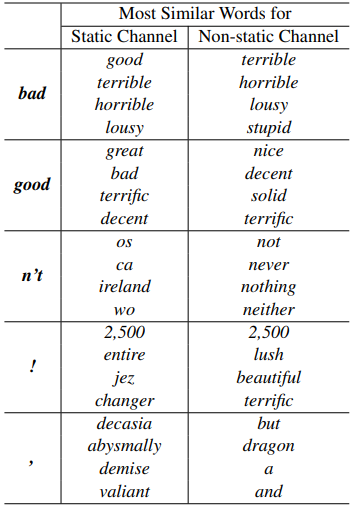
- Non-static channel을 이용하면 특정 task에 더 specific하게 fine-tuning 가능
- Static 방식 : Word2vec은 문맥적인 것을 학습하기 때문에 ‘good’와 ‘bad’가 가장 비슷한 공간에 위치
- Non-static 방식 : ‘bad’와 가장 유사한 뜻을 가지고 있는 ‘terrible’이 가장 비슷한 공간에 위치(긍정과 부정을 포함하여 vector가 학습) ⇒ fine-tuning을 진행한 쪽이 더 의미적으로 맞는 표현을 학습
-
Further Observations
-
동일한 아키텍쳐인 Max-TDNN과 비교했을 때 더 좋은 성능 ⇒ 더 많은 filter와 feature map을 사용했기 때문인 것으로 추정
-
Dropout은 좋은 regularizer → 2~4%의 성능 향상 확인
-
Pretrained word에 포함되지 않은 단어에 대해 랜덤하게 초기화할 때, pretrained vector와 동일한 분포로 초기화하면 약간의 성능 향상 확인
-
Collobert가 학습한 pretrained word vector vs. Word2Vec : w2v의 성능이 더 좋았는데, 아키텍쳐 문제인지 큰 규모의 구글 데이터셋의 영향인지 할 수 없음
-
Optimizer : Adadelta는 Adagrad와 비슷한 결과를 보였으나 adadelta 학습 속도가 미세하게 더 빠름(AdaDelta는 Adagrad, RMSprop, Momentum 모두를 합친 경사하강법)
-
5 Conclusion
- 적은 하이퍼파라미터 튜닝과 단순한 CNN 모델로도 좋은 결과
- unsupervised pre-training 워드 벡터가 NLP에서 중요한 재료임에 대한 근거 제시
