드디어 4주차!!
이번 수업은 다양한 subquery이다.
subquery란?
쿼리 안의 쿼리라는 뜻으로 하위쿼리를 만들어 상위쿼리에 사용함으로써 쿼리를 단순하게 할 수 있는 방식이다.
결론부터 말하자면 역시나 모든 수업중 가장 어려웠다.
하지만 서브쿼리를 잘 이용하면 원하는 데이터를 잘 활용할 수 있는 파워풀한 능력이 생긴다고 하니 열심히 배워보았다!!
먼저 서브쿼리 이해를 위한 간단 예시를 들어보자.
서브쿼리 예시
내가 가지고 있는 데이터에서 카카오페이로 강의를 결제한 유저 정보를 보려면 users 테이블과 oders 테이블을 조인 시켜야했다.
select u.user_id, u.name, u.email from users u
inner join orders o on u.user_id = o.user_id
where o.payment_method = 'kakaopay'하지만 위 내용을 다른방법으로 즉, join을 사용하지 않고 아래와같은 순서로 진행해 볼 수 있다.
- oders 테이블에서 kakaopay로 결제한 user_id만 보이기
select user_id from orders
where payment_method = 'kakaopay'- 내가 뽑아낸 위 데이터 안에 있는 user_id정보와 일치하는 user데이터만 user 테이블에서 가지고 오기
select u.user_id, u.name, u.email from users u
where u.user_id in (
select user_id from orders
where payment_method = 'kakaopay'
)이렇게 하면 join을 이용하지 않고도 원하는 데이터를 얻을 수 있다.
이때 where절에 들어가는 괄호 부분이 퀄이 안의 또다른 쿼리 바로 서브쿼리이다!
서브쿼리는 where절, select절, from절 어디에도 들어갈 수 있다!
그중에서도 from절에 가장 많이 사용한다고 한다.
위 예시가 바로 where절에 들어가는 서브쿼리 예시이다.
select절 서브쿼리 예시
가지고 있는 데이터를 활용해서 checkins 테이블의 course_id, userid, likes, 코스별 likes평균을 붙여보았다.
- 먼저 checkins 테이블 불러오기
select * from checkins c- checkins 테이블에서 코스별 likes 평균 구하기
select course_id, avg(c2.likes) from checkins c2
group by course_id - 서브쿼리를 이용해 보고 싶은 데이터만 추출하기
select checkin_id, course_id, user_id, likes,
(select avg(c2.likes) from checkins c2
where c.course_id = c2.course_id)
from checkins c2번에서 만든 쿼리문을 서브쿼리로 이용해서 select에 삽입하여 원하는 데이터 집단으로 추출할 수 있었다.
각 데이터를 매칭해주기 위해 where절로 조건을 주었다.
from절 서브쿼리 예시
이번에는 가지고 있는 데이터에서 수강등록정보(enrolled_id)별 전체 강의 수와 들은 강의 수를 출력해보았다.
- 전체 강의수 세기
select enrolled_id, count(*) as total_cnt from enrolleds_detail ed
group by enrolled_id 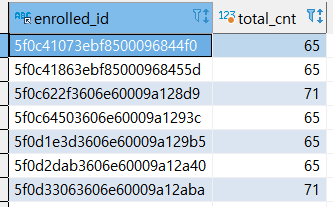
- 들은 강의 수(done=1) 세기
select enrolled_id, COUNT(*) as done_cnt from enrolleds_detail ed
where done = '1'
group by enrolled_id 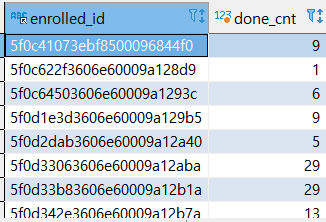
- 두개의 테이블을 innerjoin으로 합치기
select * from (
select enrolled_id, COUNT(*) as done_cnt from enrolleds_detail ed
where done = '1'
group by enrolled_id
) a inner join (
select enrolled_id, count(*) as total_cnt from enrolleds_detail ed
group by enrolled_id
) b on a.enrolled_id = b.enrolled_id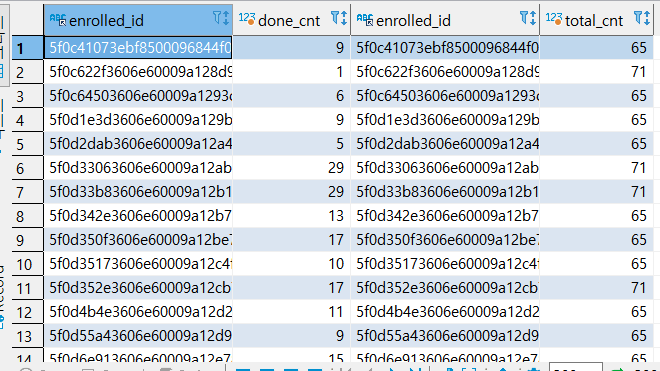
여기서 중요한점은 from절에 들어가는 각 서브퀄이에 알리아스(별칭)을 붙여주어야 한다는 점이다. 위에서는 a, b에 해당하는!
알리아스를 붙이지 않고 했을 때는 알리아스가 필요하다는 오류가 났다.
- 보고싶은 데이터만 뽑아보기
select a.enrolled_id, a.done_cnt, b.total_cnt from (
select enrolled_id, COUNT(*) as done_cnt from enrolleds_detail ed
where done = '1'
group by enrolled_id
) a inner join (
select enrolled_id, count(*) as total_cnt from enrolleds_detail ed
group by enrolled_id
) b on a.enrolled_id = b.enrolled_id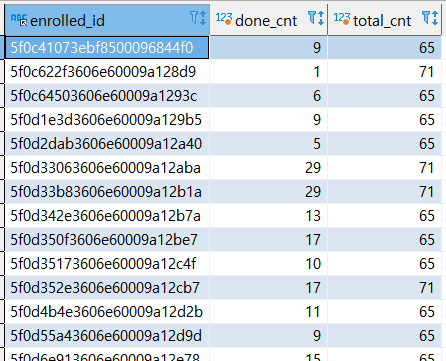
이렇게 서브쿼리를 알아보았다.
여기서 한가지 팁이 있다면, with절을 이용하면 from절의 서브쿼리를 한층 더 간편하게 만들 수 있다는 점이다.
아래는 with절을 이용해서 방금 했던 from절 서브쿼리를 더 깔끔하게 정리한 쿼리문이다.
with done_table as (
select enrolled_id, COUNT(*) as done_cnt from enrolleds_detail ed
where done = '1'
group by enrolled_id
), total_table as (
select enrolled_id, count(*) as total_cnt from enrolleds_detail ed
group by enrolled_id
)
select a.enrolled_id, a.done_cnt, b.total_cnt from done_table a
inner join total_table b on a.enrolled_id = b.enrolled_idwith절을 이용할 때 중요한점은 꼭 전체드레그를 해서 실행시켜야 한다는 점이다.
아래문단만 실행할 경우에는 with절에서 정의내린 done_table와 total_table가 없다는 에러가 발생한다.
이렇게 서브쿼리에 대해 배우고, 한걸음 더 나아가 유용하게 쓰일 수 있는 쿼리 몇가지를 더 학습했다.
추가1) case문법
case문법은 특정 조건에 따라 데이터를 구분해서 정리하는 방법이다.
point를 5000 이상, 10000이상으로 구분하여 정리하고 싶을 때 아래와 같이 case문법을 사용할 수 있다.
select pu.point_user_id, pu.point,
case
when pu.point > 10000 then '1만 이상'
when pu.point > 5000 then '5천 이상'
else '5천 미만'
END as lv
from point_users pu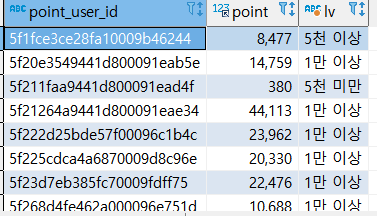
이렇게 정리한 내용을 활용한다면 아래와 같이 통계를 내어볼 수 있다.
select lv, count(*) as cnt from (
select pu.point_user_id, pu.point,
case
when pu.point > 10000 then '1만 이상'
when pu.point > 5000 then '5천 이상'
else '5천 미만'
END as lv
from point_users pu
) a
group by lv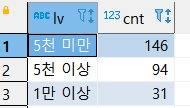
위에 활용했던 with절을 이용하면 아래와같이 더 깔끔하게 표현할 수 있다.
with point_cnt as (
select pu.point_user_id, pu.point,
CASE
when pu.point > 10000 then '1만 이상'
when pu.point > 5000 then '5천 이상'
else '5천 미만'
end as lv
from point_users pu
)
select lv, count(*) as cnt from point_cnt
group by lv추가2) 문자열 자르기
- email에서 @를 기준으로 앞에만 가져오기(아이디)
select SUBSTRING_INDEX(email, '@', 1) from users- email에서 @를 기준으로 뒤에만 가져오기(도메인)
select SUBSTRING_INDEX(email, '@', -1) from users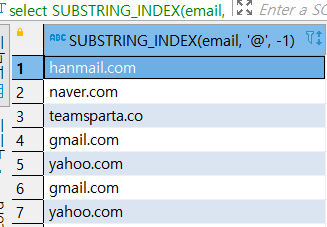
1이면 구분자 앞에 내용만, -1이면 구분자 뒤에 내용만 가지고온다.
- 문자열 일부만 가지고오기
select order_no, created_at, substring(created_at,1,10) as date
from orders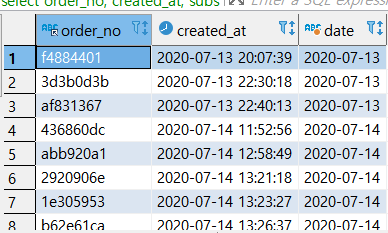
created_at에서 1번부터 10번까지 문자만 가지고 와서 날짜만으로 구성되게 만든 것이 date이다.
이렇게 SQL의 모든 강의를 완주했다!
아래는 4주차 까지 마친 스파르타 코딩 클럽에 대한 짧막한 후기!
내일배움 카드로 우연한 기회에 접하게된 스파르타코딩클럽
웹개발 종합반을 거쳐 SQL이 두번째 강의였다.
스파르타코딩클럽은 확실히 비전공자가 쉽게 코딩에 접근할 수 있도록 최대한 간단하고 이해하기 쉽도록 강의가 만들어져있다. 덕분에 다양한 과제를 직접 해볼 수 있어서 고맙게 생각한다. (너무 어려웠다면 중간에 이탈했을지도..ㅠㅠ)
특히 SQL은 이제 막 처음 접하는 시점에서 다양한 데이터를 내 손으로 만져가며 여러가지를 해볼 수 있어서 좋았다. 물론 SQL도 제대로 다루려면 꽤나 복잡해진다고 하지만, 이번 강의를 통해 그래도 내가 해볼수는 있겠다!! 라는 자신감을 얻게 되었다.
이런점에서 처음 코딩을 접하는, 코딩이 겁나는, 뭐라도 하고 싶은 문과생들에게 매우 추천하는 강의 이다. 다만, 조금 더 앞으로 나아갈 수 있는 심화된 강의가 없다는 점이 조금 아쉽다.(적어도 내일배움카드로는..?)
웹개발 종합반의 프로젝트그룹처럼 SQL 강의에서도 개인이 할 수 있는 과제 또는 프로젝트가 더 많았으면 좋겠다.
앞으로 SQL을 더 공부할지, 파이썬으로 데이터 시각화를 공부할지, 아니면 데이터가 아니라 아예 다른 개발을 공부해볼지 고민이지만, 계속해서 코딩을 놓지 않고 끌고가고자 노력할 것이다!
코딩에 재미를 갖게해주었다는 점에서 스파르타 코딩클럽에 무한 감사할 따름이다 :)
https://spartacodingclub.kr/?f_name=%EC%9D%B4%EB%8B%A8%EB%B9%84&f_uid=5f712c03affe4f0009c6ebb0
