1주차에서는 환경 설정,
2주차에서는 기본 코딩,
3주차에서는 numpy,
4주차는 드디어 데이터를 시각화하는 seaborn에 대해 배웠다.
역시.. 날이 갈수록 난이도는 높아져만 간다 ㅠㅠ
3주차에서 pandas를 배우며 데이터프레임을 만드는 방법을 배웠고,
데이터프레임을 바탕으로 seaborn을 통해 다양한 plot을 이용 데이터를 시각화 해보았다.
우선, seaborn이란?
파이썬으로 활용할 수 있는 데이터 시각화 라이브러리이다.
가장 대표적인 라이브러리가 matplotlib라면, seaborn은 matplotlib에 기본을 두고 있으면서도 활용이 쉽고 시각적으로 더 예쁘게 데이터를 가공할 수 있다.(matplotlib에 비해 그릴 수 있는 그래프 종류가 적다고는 하지만, 초보자인 나에게는 전혀 문제가 안되고, 쉽고 예쁘다는 부분에서 훨씬 활용도가 높을 것이라 생각한다.)
아 그리고, pandas dataframe과 호환이 잘 된다는 것도 큰 장점이다.
강사님이 설명해준 seaborn 활용법으로 가장 강조하신 부분은
seaborn을 활용해서 어떻게 데이터를 그릴 수 있는지 찾아보라는 것이었다.
아래는 seaborn에서 제공하는 그래프 종류를 보여주는 사이트 화면!
이렇게 다양한 데이터 그래프를 그릴 수 있는데,
내가 가지고 있는 데이터를 어떤 그래프로 그렸을 때 용이하게 정보를 나타낼 수 있는지 고민하고, 어떤 모양의 데이터가 있는지 살펴보면서 공부하는 것이 큰 도움이 된다고 한다!
(하지만 아직 그래프만 봐도 눈이 돌아간다 ..ㄷㄷ)
오늘은 학습했던 대표적인 그래프 몇개만 정리해보고자 한다!
0. seaborn 라이브러리 설치
import seaborn as sns
sns.set_theme(style='whitegrid')
penguins = sns.load_dataset("penguins")
penguins라이브러리를 설치하고,
대표적인 penguins 데이터프레임을 불러왔다.
1. Histplot
- 가장 기본적으로 사용되는 plot이면서 히스토그램을 출력해주는 그래프이다.
- 전체 데이터에서 특정 구간별 정보를 확인할 때 용이하게 사용할 수 있다.
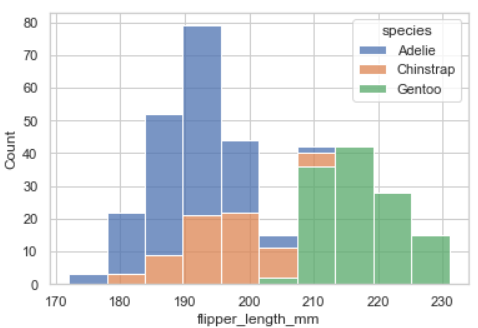
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple = 'stack')괄호 안의 x, y는 x, y축을 의미하며
hue는 색깔 구분 하는 기준데이터를 의미하고
multiple은 정보가 위로 겹쳐져서 나오게끔 stack 값을 매겨 준 것이다.
stack 값을 준 경우
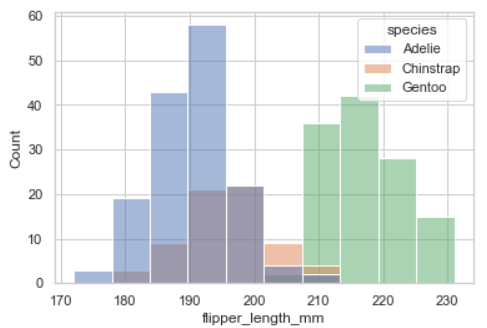
stack값을 안 준 경우
2. Barplot
- 막대그래프와 유사! 어떤 데이터 값의 크기를 막대로 표현한다.
- 가로/세로 두 가지 모두 출려 가능(x, y 축 값을 바꿔가며 변환)
- 히스토그램과 유사하게 생겼지만 다른 그래프다!
sns.barplot(data=penguins, x="flipper_length_mm", y="species", hue='species')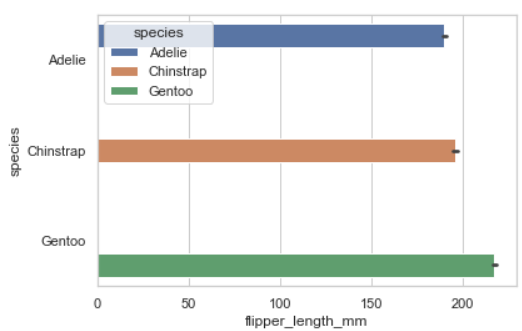
자동으로 평균 값을 구해서 막대그래프가 그려진다.
여기서 x, y 값을 바꾸면 아래처럼 세로그래프가 된다.
sns.barplot(data=penguins, x="species", y="body_mass_g", hue='species')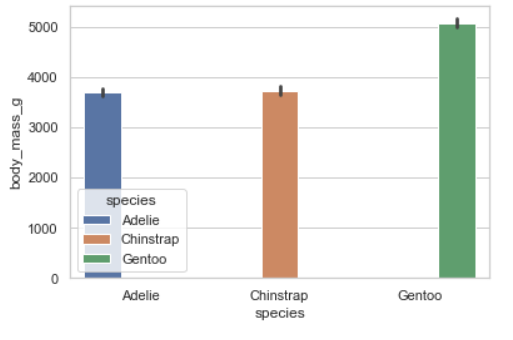
3. Countplot
- 말 그대로 갯수를 세어주는 그래프
- 종류별로 count를 세어서 보여줄 때 유용하다
- x, y중 한쪽만 지정하면 나머지 한축은 자연스럽게 갯수를 출력한다.
sns.countplot(data=penguins, x='species', hue='sex')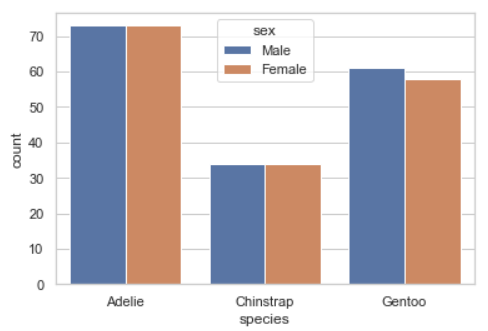
4. Boxplot
- 분포 정보를 보기 좋고, 분포에서 평균 근처 데이터를 보기 좋다.
- 데이터의 각 종류별로 사분위수(평균 기준 25~75%)를 box안에 표시하는 plot이다
- box와 전체 range의 그림을 통해 outlier(너무 튀는 데이터)를 찾기 용이하다. 평균을 심하게 벗어나는 데이터를 점찍어서 보여준다.
sns.boxplot(data=penguins, x="flipper_length_mm", y="species", hue="species")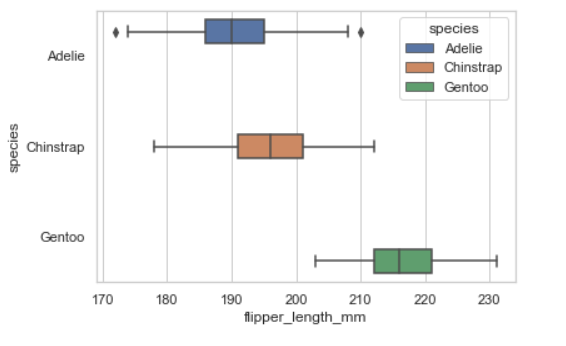
5. Violinplot
- 데이터에 대한 분포 자체를 보여주는 그래프(인구구조를 나타내는 항아리그래프가 외국에서는 viloinplot으로 불리는 것 같다)
- boxplot은 box로 중간을 보여준다면, vilolinplot은 전체적인 분포 모양을 나타낸다.
- 평균이 어느정도이고, 평균 근처에 어떤 데이터가 얼마나 있는지 확인 가능하다.
sns.violinplot(data=penguins, y='flipper_length_mm', x='species', hue='species')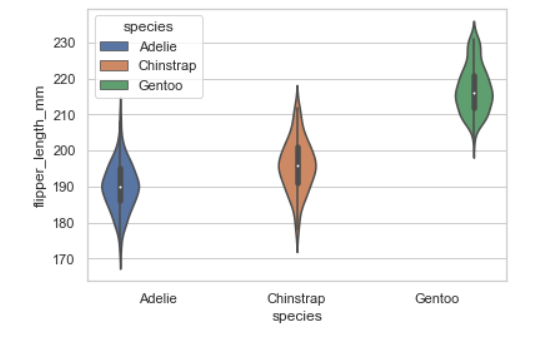
6. Lineplot
- 특정 데이터를 x, y로 표시하여 관계를 확인할 수 있는 선그래프
- 수치형 지표들 간의 경향(정비례, 반비례 등)을 파악할 때 사용 가능하다
sns.lineplot(data=penguins, x="body_mass_g", y="flipper_length_mm", hue="species")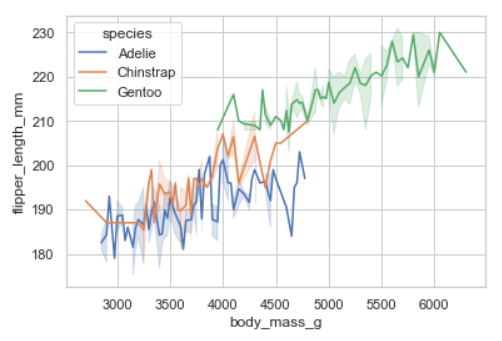
7. Pointplot
- 특정 수치를 error bar와 함께 출력해주는 plot
- 포인트 간의 차이를 나타내서 얼마나 차이가 나는지 확인이 용이하다.
- 데이터와 error bar를 한번에 보여주기 때문에, 확인하고 싶은 특정 지표만 사용하는 것을 추천한다.
sns.pointplot(data=penguins, y="flipper_length_mm", x="sex", hue="species")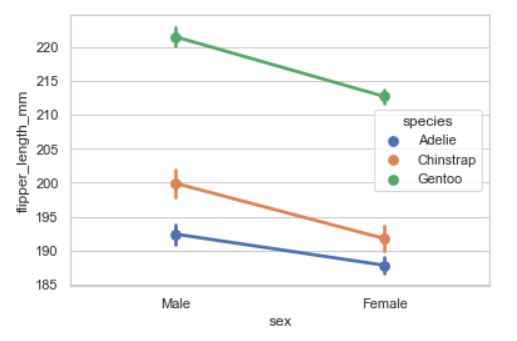
8. Scatterplot
- lineplot과 비슷하게 x, y에 대한 분포를 보여주는데 점으로 보여준다.
- lineplot이 경향성이 초첨을 둔다면, scatterplot은 퍼져있는 모양 자체에 초점을 둔다.
- 산포도, 산점도라고 생각하면 이해가 빠를 듯!
sns.scatterplot(data=penguins, x="body_mass_g", y="flipper_length_mm", hue="species")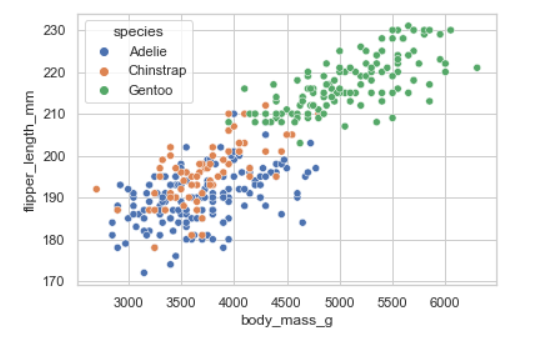
9. Pairplot
- 주어진 데이터의 각 feature들 사이의 관계를 표시하는 plot
- scatterplot, facetgrid, kdeplot을 이용하여 feature간의 관계를 다양한 그래프로 보여준다.
- 모든 feature간의 관계를 보여주기 때문에 feature가 많으면 용량소모도 많고 보기도 힘든 단점이 있다.(ex. 200개의 feature가 있다면 그래프는 40000개가 나온다)
- pair이기때문에 x, y를 따로 지정해주지 않아도 짝지어 나온다.(물론 지정해도 된다!)
sns.pairplot(data=penguins, hue="species")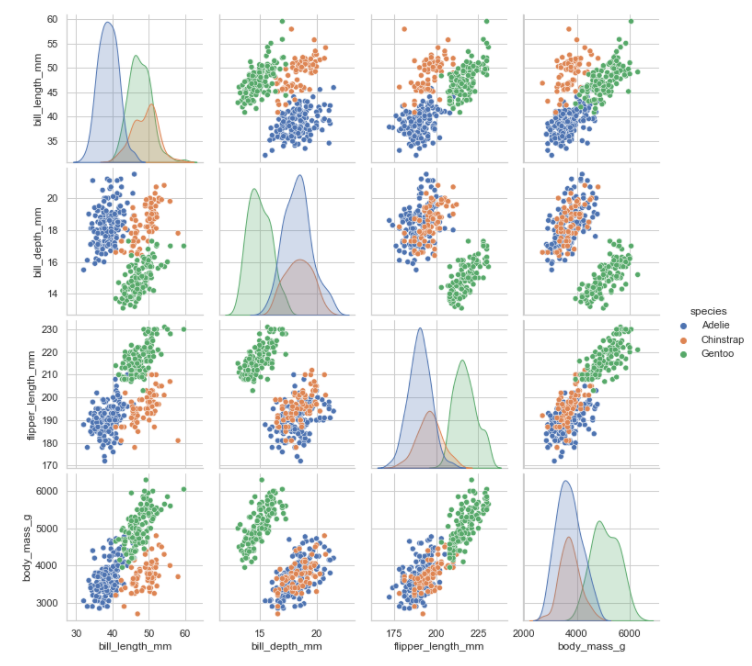
내가 활용한 데이터프레임에는 4개의 feature가 있었기 때문에 총 16개 그래프가 나왔다.
10. Heatmap
- 정사각형 그림에 데이터에 대한 정도 차이를 색으로 보여주는 plot(열화상 카메라와 유사)
- pairplot과 유사하게 feature간의 관계를 확인할 때 주로 쓰인다.
- feature간의 관계를 파악하기 위해 상관계수(Correlation matrix)를 먼저 만들어주고, 그 데이터를 바탕으로 그래프를 그린다.
corr = penguins.corr()
sns.heatmap(data=corr)pandas의 corr 함수를 이용해 상관계수로 만든다음 그래프를 그렸다.
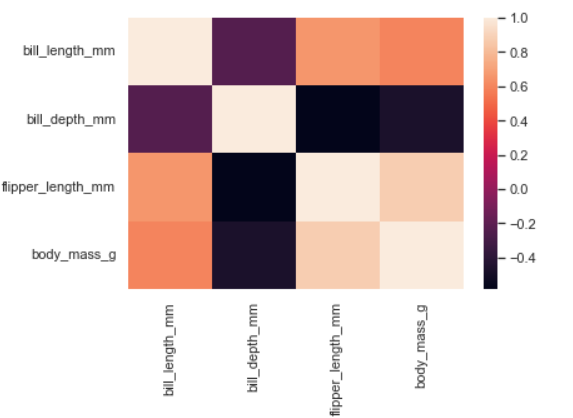
음으로 갈수록 부의 관계(반비례), 양으로 커질 수록 정의 관계(정비례)로 파악해볼 수 있다.
다양한 그래프를 배웠는데, 첫번째 histplot과 마지막 heatmap이 가장 어렵고 이해가 안되었다. 다음 수업부터는 실제 데이터 분석인데, 다양한 데이터로 시각화해보면서 연습해보아야 할 것 같다 :)
