SAX (Symbolic Aggregate ApproXimation)
- SAX : 시계열 데이터의 문자 표현을 위한 알고리즘 , 낮은 컴퓨팅 복잡도 -> 인 네트워킹 프로세싱 기술로 사용 가능.
간단하고 , 계산 복잡도가 낮음.
SAX: 길이가 n인 시계열 데이터 X를 a(<<n)길이의 문자열로 바꾸는것
STEP 1
- 원본 시계열 데이터를 PAA(PieceWise Aggregate Approximation)표현으로 바꿈
PPA: n 차원(길이)의 시계열 데이터를 w차원으로 축소
예를 들어, 길이가 10인 데이터를 5로 축소한다고 하면.
2개씩 묶어서 평균을 낸 데이터로 바꾸는 것이다.
시계열 데이터는 PAA를 적용하기전에 Z-Normalized 해야한다. 평균을 0으로 표준편차를 1로 바꿈.
Step 2
- PAA 표현을 string으로 전환.
예를 들어 우리가 4개의 알파벳 a,b,c,d가 있을 때.
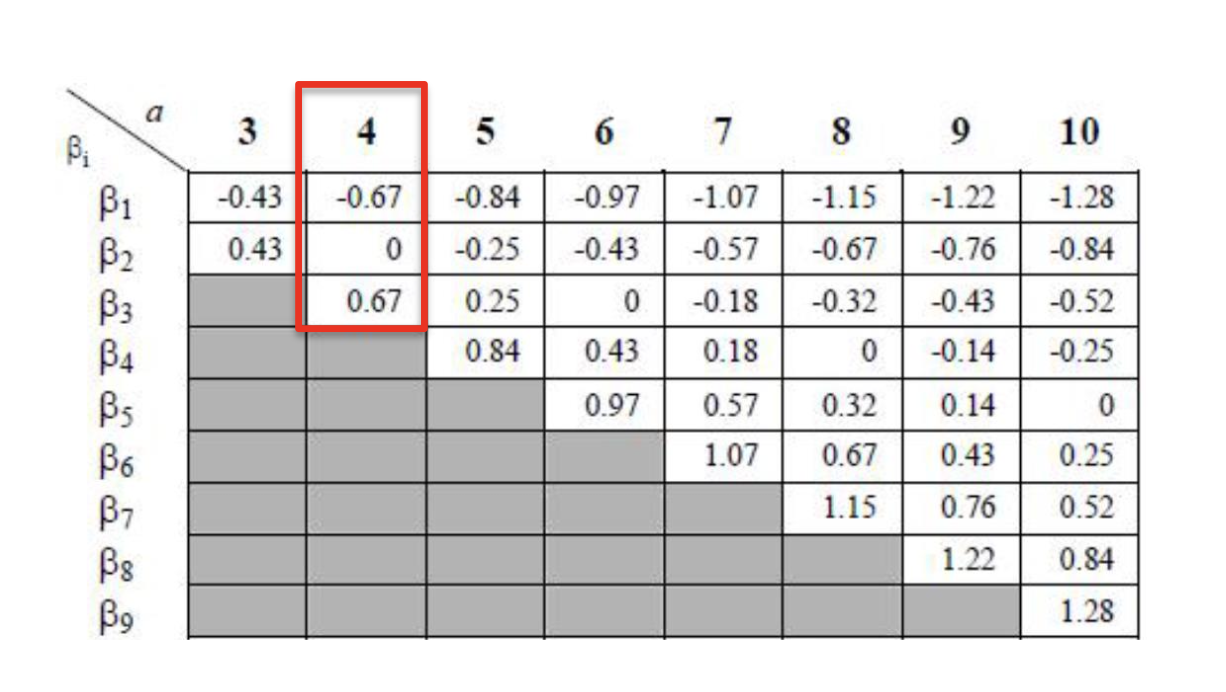
구간은 베타1,베타2,베타3로 나눌 수 있고
Time Series C : 2,3,4.5,7.6,4,2,2,2,3,1 로 10개인 것을
PAA(W=5) 처리하면 : -0.33,1.63,-0.06,-0.6,-0.6 이다.
첫 번째 요소인 -0.33은 베타1인 -0.67보단 크고 0보단 작으니 b가 할당
두 번째 요소 1.63은 베타3인 0.67보다 크니 d가 할당
세 번째 요소 -0.06은 베타1보단 크니까 b
네 번째 요소 -0.6도 b
다섯 번째로 b를 할당한다.
결과: bdbbb
코드
import numpy as np
from scipy.stats import norm
def paa_transform(series, w):
"""
PAA (Piecewise Aggregate Approximation) 변환
- series: 시계열 데이터 (numpy array or list)
- w: 구간 개수
반환: 길이 w인 PAA 시계열
"""
series = np.array(series)
n = len(series)
if n % w != 0:
raise ValueError("시계열 길이는 w로 나누어 떨어져야 함")
segment_size = n // w
paa = [np.mean(series[i * segment_size: (i + 1) * segment_size]) for i in range(w)]
return np.array(paa)
def sax_transform(paa, alphabet_size):
"""
SAX 변환
- paa: PAA로 요약된 시계열 (z-normalized 상태)
- alphabet_size: 사용할 심볼 개수 (예: 5 → a~e)
반환: SAX symbol list
"""
breakpoints = norm.ppf([i / alphabet_size for i in range(1, alphabet_size)])
symbols = [chr(i) for i in range(97, 97 + alphabet_size)] # 'a', 'b', ...
sax = []
for val in paa:
for i, bp in enumerate(breakpoints):
if val < bp:
sax.append(symbols[i])
break
else:
sax.append(symbols[-1])
return sax
paa = paa_transform(np.random.rand(100), 10)
sax_transform = sax_transform(paa, 10)
print("PAA:", paa)
print("SAX:", sax_transform)
가슴에 별을 간직한 사람은 어둠 속에서 길을 잃지 않는다
이름이 특이하네요