
한글 타이핑 애니메이션을 구현하고 싶었다. 타이머 함수를 이용하면 구현은 쉬웠지만, 단순히 한글자 씩 출력하는 것은 뭔가 밋밋했고, 실제로 타자를 치는듯한 애니메이션을 구현해보고 싶었다.
구현 과정
한글 타이핑 애니메이션을 구현하기 위해서는 입력받은 문자가 초성 -> 초성 + 중성 -> 초성 + 중성 + 종성 순으로 출력이 되어야 한다. "곰" 이라는 글자를 예로 들면 화면에 ㄱ -> 고 -> 곰 형태로 출력이 되어야 보기에 자연스러워진다. 이렇게 출력하기 위해선 입력받은 "곰"을 문자를 초성, 중성, 종성으로 분리하는 과정이 필요하다.
한글 문자를 분리하기 위해 가장 많이 사용되는 방법이 유니코드를 이용한 방법인데, 그러기 위해선 유니코드 상 한글의 규칙을 먼저 알아야 한다.
한글 유니코드의 규칙
다음 함수는 '가' ~ '힣'까지 모든 한글 유니코드를 출력하는 함수이다.
export function showkoreanAllUnicode() {
// 문자를 유니코드로 변환
const ga = "가".charCodeAt(0); // 가 (맨 처음 한글 문자)
const hih = "힣".charCodeAt(0); // 힣 (맨 마지막 한글 문자)
let uni = ga;
while (uni) {
const kor = String.fromCharCode(uni); // 유니코드를 문자로 변환
console.log("uniCode :", uni, "// kor : " + kor);
if (uni === hih) break;
uni++;
}
}
showkoreanAllUnicode(); // '가' ~ '힣'까지 모든 한글 unicode 출력해당 함수를 호출해보면 아래와 같이 콘솔이 출력되는데, 살펴보면 종성은 숫자 1마다, 중성은 29마다, 초성은 589마다 변하는 것을 알 수 있다.
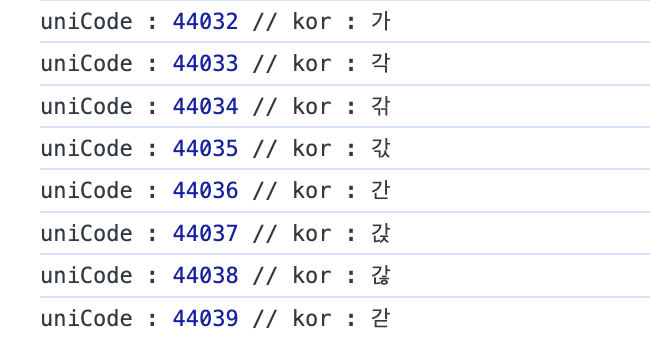
이런 규칙을 이용하여 아래처럼 문자를 분리하는 함수를 만들 수 있다.
// 초성 배열
const f = ['ㄱ', 'ㄲ', 'ㄴ', 'ㄷ', 'ㄸ', 'ㄹ', 'ㅁ',
'ㅂ', 'ㅃ', 'ㅅ', 'ㅆ', 'ㅇ', 'ㅈ', 'ㅉ',
'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ'];
// 중성 배열
const s = ['ㅏ', 'ㅐ', 'ㅑ', 'ㅒ', 'ㅓ', 'ㅔ', 'ㅕ',
'ㅖ', 'ㅗ', 'ㅘ', 'ㅙ', 'ㅚ', 'ㅛ', 'ㅜ',
'ㅝ', 'ㅞ', 'ㅟ', 'ㅠ', 'ㅡ', 'ㅢ', 'ㅣ'];
// 종성 배열(공백 포함)
const t = ['', 'ㄱ', 'ㄲ', 'ㄳ', 'ㄴ', 'ㄵ', 'ㄶ',
'ㄷ', 'ㄹ', 'ㄺ', 'ㄻ', 'ㄼ', 'ㄽ', 'ㄾ',
'ㄿ', 'ㅀ', 'ㅁ', 'ㅂ', 'ㅄ', 'ㅅ', 'ㅆ',
'ㅇ', 'ㅈ', 'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ'];
// 문자를 분해하여 초성, 중성, 종성 순으로 출력하는 함수
function disassembleKoreanChar(char: string): string[] {
const ga = "가".charCodeAt(0); // 가 (맨 처음 한글 문자)
const giyeok = "ㄱ".charCodeAt(0); // 'ㄱ' (맨 처음 한글 자음)
const uniCode = char.charCodeAt(0) - ga; // 입력받은 문자의 유니코드와 '가' 유니코드의 차
// 한글이 아닐 경우 예외처리
if (uniCode < 0 || uniCode > hih - giyeok) {
return [char, "", ""];
}
// 종성은 숫자 1마다, 중성은 29마다, 초성은 589마다 값이 변함
// 초성 배열의 인덱스
const fIdx = Math.floor(uniCode / 588);
// 중성 배열의 인덱스
const sIdx = Math.floor((uniCode - fIdx * 588) / 28);
// 종성 배열의 인덱스
const tIdx = Math.floor(uniCode % 28);
return [f[fIdx], s[sIdx], t[tIdx]];
}
const result = disassembleKoreanChar('곰');
console.log(result); // ['ㄱ', 'ㅗ', 'ㅁ']우선 uniCode 변수에 입력받은 문자의 유니코드 값에서 '가'의 유니코드를 뺀 값을 저장한다. 이 값을 기반으로 초성, 중성, 종성의 값을 구할 것이다.
fIdx는 초성 배열의 인덱스이다. 초성은 589마다 값이 바뀌는데 배열의 시작번호는 0번이므로 uni를 588로 나눠준 값을 입력한다. 소수점은 Math.floor 함수로 버려준다.
sIdx는 중성 배열의 인덱스이다. 중성은 매 29마다 값이 바뀌는데 배열의 시작번호가 0번이므로 28을 나눠주며, 초성이 바뀔때마다 다시 처음부터 반복되기 때문에 uni 값에서 초성 배열의 인덱스 값을 빼준다.
tIdx는 종성 배열의 인덱스이다. 종성은 매 1마다 값이 바뀌며, 총 28개의 배열 값을 지니고 있기 때문에 uni를 28로 나눈 나머지 값이 종성 배열의 인덱스가 된다.
위의 코드를 응용하면 아래처럼 [초성, 초성 + 중성, 초성 + 중성 + 종성] 순으로 출력하는 함수를 만들 수 있다.
// 초성 배열
const f = ['ㄱ', 'ㄲ', 'ㄴ', 'ㄷ', 'ㄸ', 'ㄹ', 'ㅁ',
'ㅂ', 'ㅃ', 'ㅅ', 'ㅆ', 'ㅇ', 'ㅈ', 'ㅉ',
'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ'];
// 중성 배열
const s = ['ㅏ', 'ㅐ', 'ㅑ', 'ㅒ', 'ㅓ', 'ㅔ', 'ㅕ',
'ㅖ', 'ㅗ', 'ㅘ', 'ㅙ', 'ㅚ', 'ㅛ', 'ㅜ',
'ㅝ', 'ㅞ', 'ㅟ', 'ㅠ', 'ㅡ', 'ㅢ', 'ㅣ'];
// 종성 배열(공백 포함)
const t = ['', 'ㄱ', 'ㄲ', 'ㄳ', 'ㄴ', 'ㄵ', 'ㄶ',
'ㄷ', 'ㄹ', 'ㄺ', 'ㄻ', 'ㄼ', 'ㄽ', 'ㄾ',
'ㄿ', 'ㅀ', 'ㅁ', 'ㅂ', 'ㅄ', 'ㅅ', 'ㅆ',
'ㅇ', 'ㅈ', 'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ'];
export function disassembleKoreanString(char: string): string[] {
const ga = "가".charCodeAt(0); // 가 (맨 처음 한글 문자)
const giyeok = "ㄱ".charCodeAt(0); // 'ㄱ' (맨 처음 한글 자음)
const uniCode = char.charCodeAt(0) - ga;
// 한글이 아닐 경우 예외처리
if (uniCode < 0 || uniCode > hih - giyeok) {
return [char, "", ""];
}
// 종성은 숫자 1마다, 중성은 29마다, 초성은 589마다 값이 변함
// 초성 인덱스
const fIdx = Math.floor(uniCode / 588);
// 중성 인덱스
const sIdx = Math.floor((uniCode - fIdx * 588) / 28);
// 종성 인덱스
const tIdx = Math.floor(uniCode % 28);
// [초성, 초성 + 중성, 초성 + 중성 + 종성] 배열을 출력
return [
f[fIdx],
String.fromCharCode(ga + fIdx * 588 + sIdx * 28),
t[tIdx] ? String.fromCharCode(ga + fIdx * 588 + sIdx * 28 + tIdx) : "",
];
}
const result = disassembleKoreanString('곰');
console.log(result); // ['ㄱ','고','곰']위 함수 안에 사용된 String.fromCharCode 함수는 유니코드 값에 해당하는 문자를 출력하는 함수이다.
여기에 인자로 '가'의 유니코드 + (초성 인덱스 x 초성 간의 간격) + (중성의 인덱스 x 중성 간의 간격) + 종성 인덱스를 넣으면 초성 + 중성 + 종성을 다 더한 문자를 구할 수 있다. 이를 응용해서 마지막에 종성 인덱스를 생략하면 초성 + 중성을 더한 문자 또한 구할 수 있다.
따라서 위의 함수는 문자를 입력받으면 해당 문자의 [초성, 초성 + 중성, 초성 + 중성 + 종성] 순으로 이루어진 배열을 출력하게 된다. 예를 들어 함수에 "곰"이라고 입력하면 ["ㄱ", "고", "곰"] 형태로 출력한다. 또한 함수 외부에서 사용하기 쉽도록, 입력받은 글자가 한글이 아닐 경우에도 배열의 길이는 3으로 동일하게 리턴하도록 만들었다.
하지만 위의 함수는 단일 문자만 처리 가능하므로, 문자열을 입력받았을때 처리가 가능하게 별도의 함수를 하나 더 만들었다.
// 입력받은 문자열을 쪼갠 결과값을 출력하는 함수
function disassembleString(line: string): string[] {
let titleArr: { a: string; b: string; c: string }[] = [];
[...line].forEach((char) => {
titleArr = titleArr.concat(disassembleKoreanString(char));
});
return titleArr;
}
const result = disassembleString('곰돌이');
console.log(result); // ['ㄱ', '고', '곰', 'ㄷ', '도', '돌', 'ㅇ', '이', '']disassembleString 함수는 입력받은 문자열의 길이만큼 disassembleKoreanString 함수를 호출하고, 그 결과 배열들을 하나로 합쳐서 리턴하는 함수이다.
예를 들어 "곰돌이"라고 입력한 경우, disassembleKoreanString 함수를 3번 호출해야 하는데 각각 ['ㄱ', '고', '곰'], ['ㄷ', '도', '돌'], ['ㅇ', '이', ''] 3개의 배열이 출력된다. 이에 반해, disassembleString 함수를 사용하면 ['ㄱ', '고', '곰', 'ㄷ', '도', '돌', 'ㅇ', '이', '']로 1개의 배열이 나오게 된다.
최종적으로 disassembleString 함수로 출력된 배열을 화면에 뿌려주는 작업 또한 필요하다. 여기서 고려해야 할 것은 한글이 아닌 문자가 입력되거나, 종성이 없는 문자가 입력되었을 경우 예외처리를 해주는 것이다.
let timerId = 0;
// 문자 배열을 입력받아 화면에 출력하는 함수
function typing(element: Element, txt: string) {
return new Promise((resolve) => {
let idx = 0;
timerId = setInterval(function () {
if (idx % 3 === 0) {
// 다음 글자로 넘어갈떄 글자 추가
element.innerHTML += txt[idx];
} else {
// 현재 글자일때 초성, 초성 + 중성, 초성 + 중성 + 종성 순으로 출력
if (txt[idx] !== "") {
// 중성, 종성이 공백일때 무시
element.innerHTML = element.innerHTML.slice(0, -1) + txt[idx];
}
}
idx++;
if (txt.length <= idx) {
clearInterval(timerId);
idx = 0;
resolve(true);
}
}, 100);
});
}
typing(titleElement, disassembleString('곰돌이')); // 화면에 곰돌이 출력typing 함수는 100ms마다, disassembleString 함수를 통하여 만들어진 문자 배열의 요소들을 화면에 출력하는 함수이다. 반복문을 한번 돌때마다 idx값이 1씩 올라가며, idx값이 3이 아닌 경우 현재까지 출력된 문자열에서 맨 마지막 문자를 현재 idx값의 문자를 치환하고, idx값이 3인 경우에는 출력된 문자열 끝에 맨 마지막 문자를 추가한다.
3을 기준으로 정한 이유는 disassembleString 함수에서 리턴되는 문자 배열의 길이가 무조건 3의 배수이기 때문이다. 실제로 함수 내부에서 console.log를 찍어보면 문자 배열의 길이가 9인 것을 알 수 있다.

또한, Promise 사용으로 typing 함수를 여러번 호출하더라도 차례대로 1줄씩 화면에 출력이 되게 설정했다.
출력 결과
typing 함수를 출력한 결과는 다음과 같다. 사진처럼 자음, 모음이 잘 분리되어 출력되며,
한글이 아닌 다른 문자를 넣어도 문자가 자연스럽게 출력되는 것을 볼 수 있다.

샘플코드
github 저장소 이동 (https://github.com/MochaChoco/korean-assemble)
참고 자료
[자바스크립트] 한글 자음 모음 분리 / 초성, 중성, 종성
한글 unicode; 초성, 중성, 종성 분리 및 합성하는 방법과 천지인 입력방식
[javascript]초성 중성 종성(자음/모음)모두 나눠 하나씩 타이핑 하는 효과
