Ref.
SQL SERVER 튜닝 가이드 실습편 | ep.06, 실습1
RID LOOKUP에 의한 성능 이슈
구문에 사용된 컬럼의 일부가 인덱스에 존재하지 않아 RID Lookup이 수행되면서 높은 I/O(논리적 읽기)를 사용한 사례
SELECT SEQ, CLASS_CD, MAIN_CODE
FROM TB_MAIND5
WHERE CLASS_CD = 'SE'
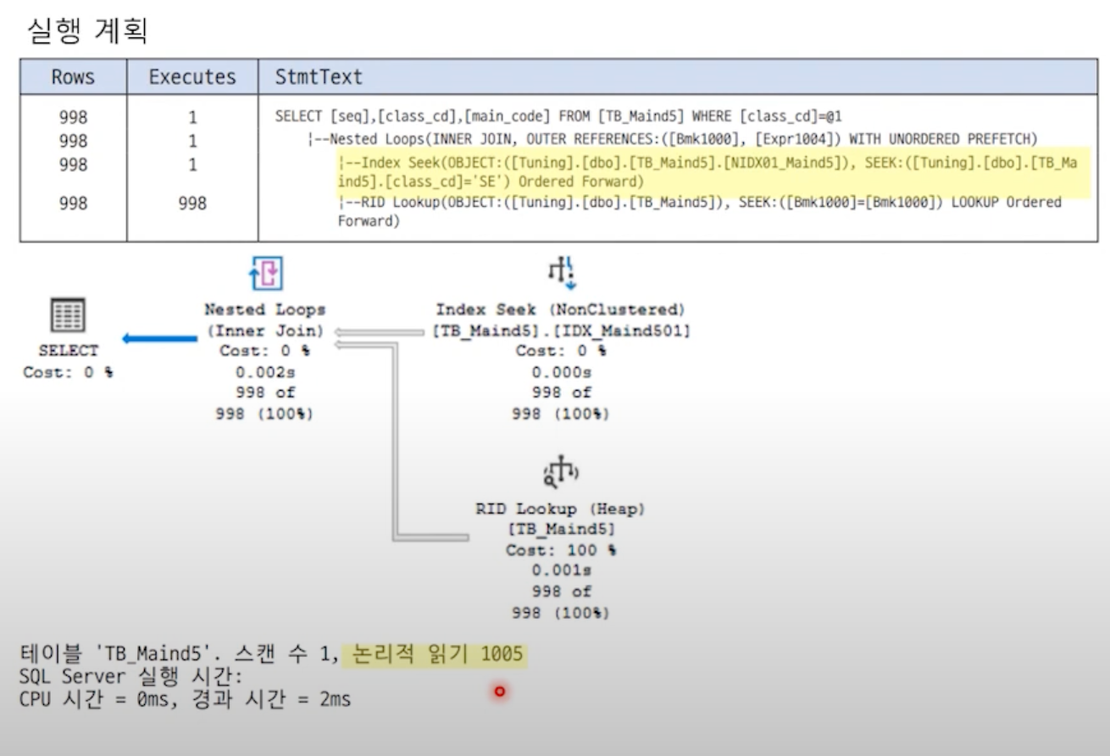
SELECT절에서 요구하는 SEQ, MAIN_CODE컬럼이 인덱스에 포함되어 있지 않아 탐색된 결과 집합 수만큼 RID Lookup이 반복 수행된다. 1005만큼의 I/O비용 발생.
RID Lookup으로 인해 NL Join이 반복 수행되면서 I/O를 유발한다.
요구되는 컬럼을 인덱스의 포괄(include) 열로 추가하면 RID Lookup의 과정이 제거되기 때문에 I/O를 감소시킬 수 있다.
개선방안
- 포괄(include) 열 인덱스 생성.
→ RID Lookup 연산이 요구되지 않고 인덱스 탐색으로만 데이터를 조회할 수 있도록 한다.
CREATE INDEX NIDX02 ON TB_MAIND5(CLASS_ID) INCLUDE (SEQ, MAIN_CODE)결과
- rid lookup 제거 및 index seek로만 탐색
KEY LOOKUP에 의한 성능 이슈
테이블 조회를 위해 인덱스로 탐색할 때 일부 컬럼이 인덱스에 포함되지 않아 Key Lookup이 발생하여 I/O가 증가되는 사례
SELECT TYPE,
NO1,
TID /* 인덱스에 포함되어 있지 않음. ↓↓↓(인덱스정보 참고) */
FROM TB_KEYUP1
WHERE NO1 = 4 AND TYPE = 'J'
SELECT 절에서 요구하는 TID컬럼이 인덱스에 포함되어 있지 않아서 탐색된 결과 집합 수만큼 key lookup이 반복 수행되면서 높은 I/O비용이 발생.
Key Lookup은 인덱스를 탐색한 뒤 부족한 컬럼을 가져오기 위해 클러스터 인덱스에 조인하는 작업이다. 인덱스에 포함되어 있지 않은 TID컬럼을 인덱스의 포괄(include) 로 추가해주면 Key Lookup의 과정이 제거된다.
개선방안
- 포괄열이 있는 인덱스 생성
→ 필요한 모든 컬럼이 인덱스에 포함되기 때문에 Key Lookup 과정 없이 인덱스 탐색으로만 수행된다. (I/O비용 감소)```sql CREATE INDEX NIDX02_KEYUP2 ON TB_KEYUP1(NO1,TYPE) INCLUDE (TID) ```
결과
- key lookup 제거 및 index seek로만 탐색
인덱스 부재로 인한 성능 이슈
인덱스 부재로 인해 테이블을 전체 스캔하면서 I/O가 발생하는 사례
SELECT SEQ,
CLASS_CD,
MAIN_CODE
FROM TB_MAIN
WHERE CLASS_CD = 'SE'
// 인덱스 없음
실행계획

조건절에 사용된 CLASS_CD 컬럼이 키로 구성된 인덱스가 존재하지 않기 때문에 데이터 전체를 스캔하면서 높은 I/O비용이 발생.
테이블 스캔은 테이블의 모든 데이터를 읽고 조건절에 일치하는 값을 추출하기 때문에 불필요한 데이터까지 모두 읽게 된다. 조건절에 있는 컬럼을 기준으로 필요한 데이터만 읽도록 인덱스를 생성하면 I/O를 감소시킬 수 있다.
개선방안
- CLASS_CD컬럼이 키로 구성된 신규 인덱스 생성
→ 조건에 해당하는 데이터만 읽도록 CLASS_CD 컬럼이 키로 구성된 인덱스를 생성한다.
CREATE INDEX NIDX_MAIN ON TB_MAIN(CLASS_CD)결과
- index seek로 탐색
인덱스 키 누락으로 인한 성능 이슈
조건절에서 사용된 컬럼의 일부가 인덱스에 포함되지 않아 스캔 범위가 많아지면서 불필요한 I/O가 발생되는 사례
SELECT A.UID,
COUNT(B.NUMBER) AS CNT
FROM TB_STORE A
INNER JOIN TB_STORELOG B
ON A.NUMBER = B.NUMBER
WHERE B.LOGTIME BETWEEN '2020-01-01' AND '2020-12-31'
GROUP BY A.UID
실행계획
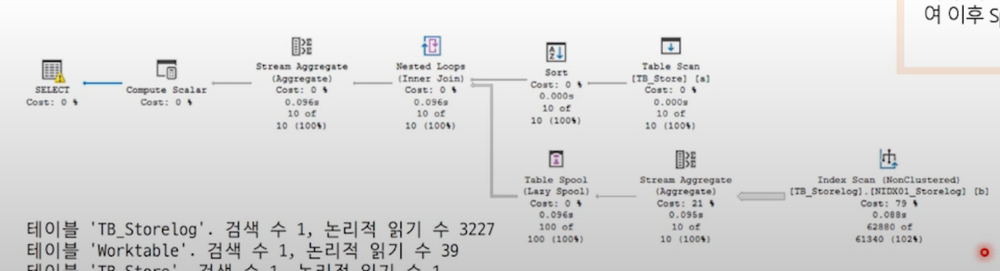
인덱스가 존재함에도 전체 데이터를 읽어내면서 (특정 인덱스만을 읽으라는 조건이 없기때문) 불필요한 I/O 사용.
만약 인덱스 탐색을 하게 되면 불필요한 데이터를 반복적으로 읽어내기 때문에 이를 대신하여 처음 조인이 시도될때 Spool에 저장하여 이후 Spool과 조인하도록 수행
조건절로 사용된 LOGTIME 컬럼이 인덱스 키에 포함되지 않아 탐색 범위가 많아지는 것이 원인.
조인 조건과 조건절이 모두 키로 구성된 인덱스를 생성하면 필요한 범위만 읽어내면서 I/O를 개선할 수 있다.
개선방안
- TB_STORELOG 테이블의 NUMBER컬럼과 LOGTIME 컬럼이 키로 구성된 신규 인덱스 생성
→ 조인이 수행될때마다 필요한 범위만 인덱스로 탐색한다.
CREATE INDEX NIDX02_STORELOG ON TB_STORELOG(NUMBER, LOGTIME)결과

인덱스 페이지 분할에 의한 성능 이슈
인덱스 키 값을 업데이트할 때 발생하는 페이지 분할로 인해 I/O가 증가되는 사례
// update 전
SELECT NUM,
CODE
FROM TB_PGSPLIT
WHERE NUM > 300
UPDATE A SET CODE = ABS(NUM-CODE) FROM TB_PGSPLIT A
// update 후
SELECT NUM,
CODE
FROM TB_PGSPLIT
WHERE NUM > 300
update 전
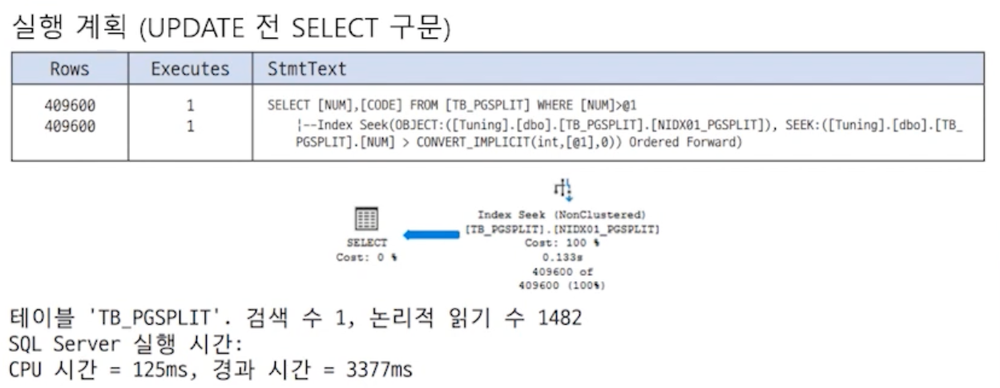
update 후
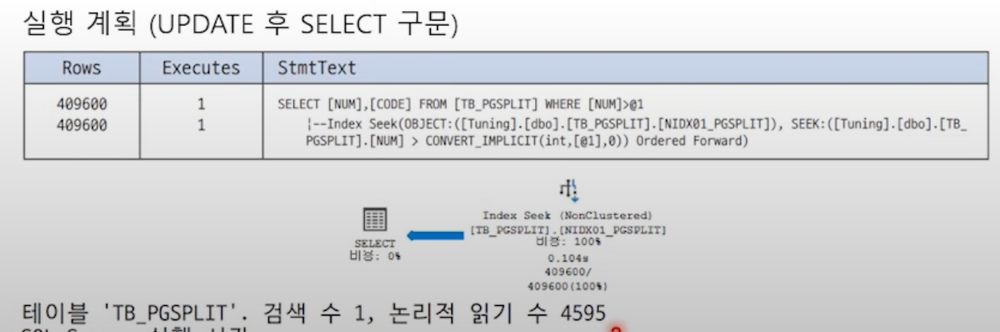
인덱스의 CODE 컬럼이 UPDATE 될 때 정렬된 값을 유지하기 위해 분할이 발생하고 이로 인해 페이지 양이 많아져 UPDATE 이후 SELECT를 수행할 때 I/O가 증가.
CODE컬럼은 SELECT구문에서 조건절이 아닌 조회용으로만 사용되기 때문에 포괄 열로 하는 인덱스 생성을 고려할 수 있다. 포괄 열은 정렬을 하지 않기 때문에 UPDATE될 때 페이지 내에 중간에 삽입될 확률이 낮아져 페이지 분할 발생이 적어진다.
개선 방안
- CODE 컬럼을 포괄 열로 하는 인덱스를 생성
→ UPDATE 시 CODE 컬럼에 정렬이 필요하지 않아 페이지 분할이 적게 발생된다.
CREATE INDEX NIDX02 ON TB_PGSPLIT(NUM) INCLUDE (CODE)결과

