데이터베이스 튜닝
Ref.
[웨비나] SQL SERVER 튜닝 가이드 | INDEX
[웨비나] SQL SERVER 튜닝 가이드 | 격리수준
[웨비나] SQL SERVER 튜닝 가이드 | 실행계획(Execution Plan)
- 인덱스
- 조인
- 통계
- 격리수준
- 실행계획
인덱스
B-tree 구조를 따른다.
종류
클러스터인덱스
- 인덱스의 Leaf Node에 실제 데이터를 가진다
- 인덱스 키 값을 기준으로 데이터를 정렬
- 테이블 당 1개만 생성 가능
비클러스터 인덱스
- 데이터 테이블(Heap Table)과 독립적으로 생성
- 테이블 당 여러개 생성가능(최대 999개)
- Leaf Node에서 해당 키가 위치하는 행
- Leaf노드는 RID로 HeapTable에 접근한다.
클러스터 + 비클러스터 인덱스
- 인덱스의 RID 대신 Clustered 인덱스 키 값을 가지고 탐색
- 클러스터 인덱스의 Root Node부터 탐색
스캔 방식
Table Scan
- 조건에 맞는 데이터를 색인하는 것보다 모든 데이터를 읽는 것이 더 효율적일 때 사용되는 방식
- Clustered Index가 존재하면 Clustered Index Scan으로 변경된다.
Clustered Index Scan
- Clustered Index의 Leaf 페이지를 모두 탐색하는 방식
- Leaf 페이지 = 데이터가 들어있는 페이지
- 인덱스 컬럼을 가공하거나 선두 컬럼에 대한 검색조건이 없을때 주로 발생
- 컬럼을 가공한다는 것은 WHERE ID = ‘B02’ + ‘ABC’ 이런식으로 더 추가적으로 형태를 변경하는 것을 의미한다.
Clustered Index Seek
- 인덱스의 Root부터 Leaf까지 필요한 페이지만 수직적으로 탐색하는 방식
- 조건에 제시된 열이 Clustered Index에 포함되는 경우 Clustered Index Seek 발생
Non-Clustered Index Scan
- Non-Clustered Index의 Leaf 페이지를 모두 탐색하는 방식
- 인덱스 컬럼을 가공하거나 선두 컬럼에 대한 검색조건이 없을 때 주로 발생
Non-Clustered Index Seek
- 인덱스의 Root부터 Leaf까지 필요한 페이지만 수직적으로 탐색하는 방식
- Non-Clustered Index에 포함된 열만 조회할 경우 Index Seek 발생
RID Lookup : Non-Clustered Index + Heap Table
- 열 데이터가 부족하여 조인을 통해 열을 가져오는 과정
- Non-Clustered Index + Heap일 경우 RID Lookup 발생
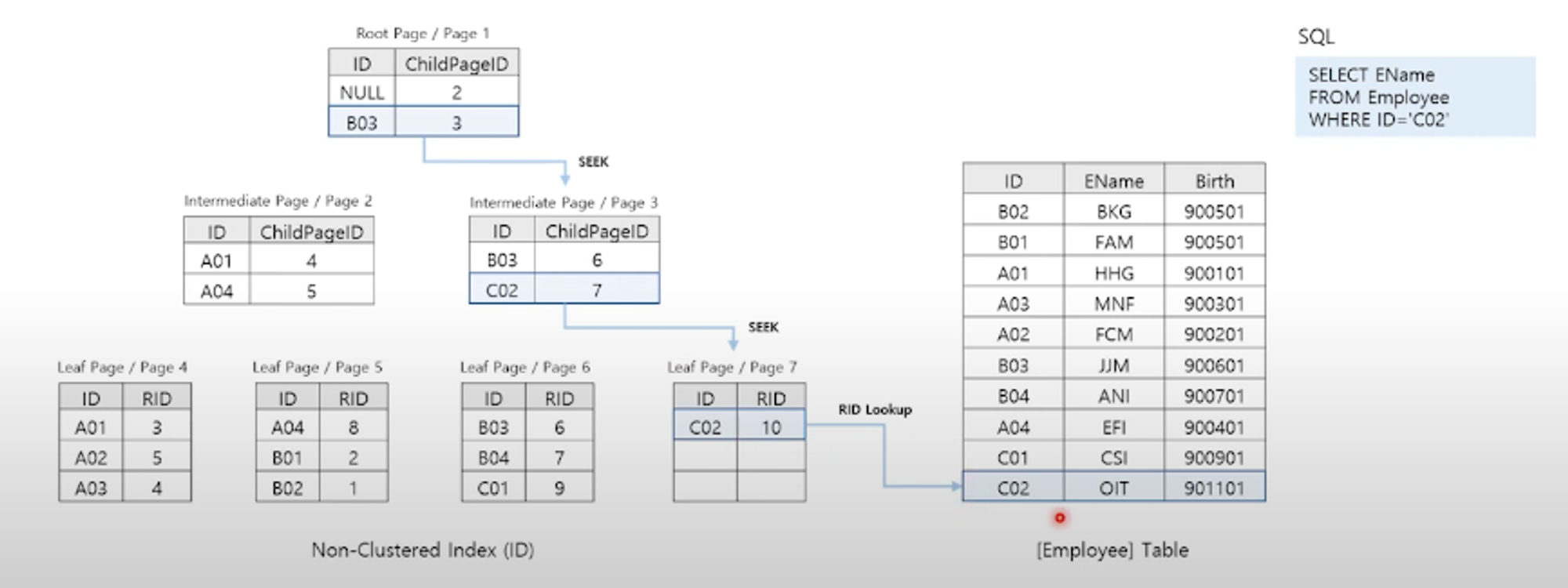
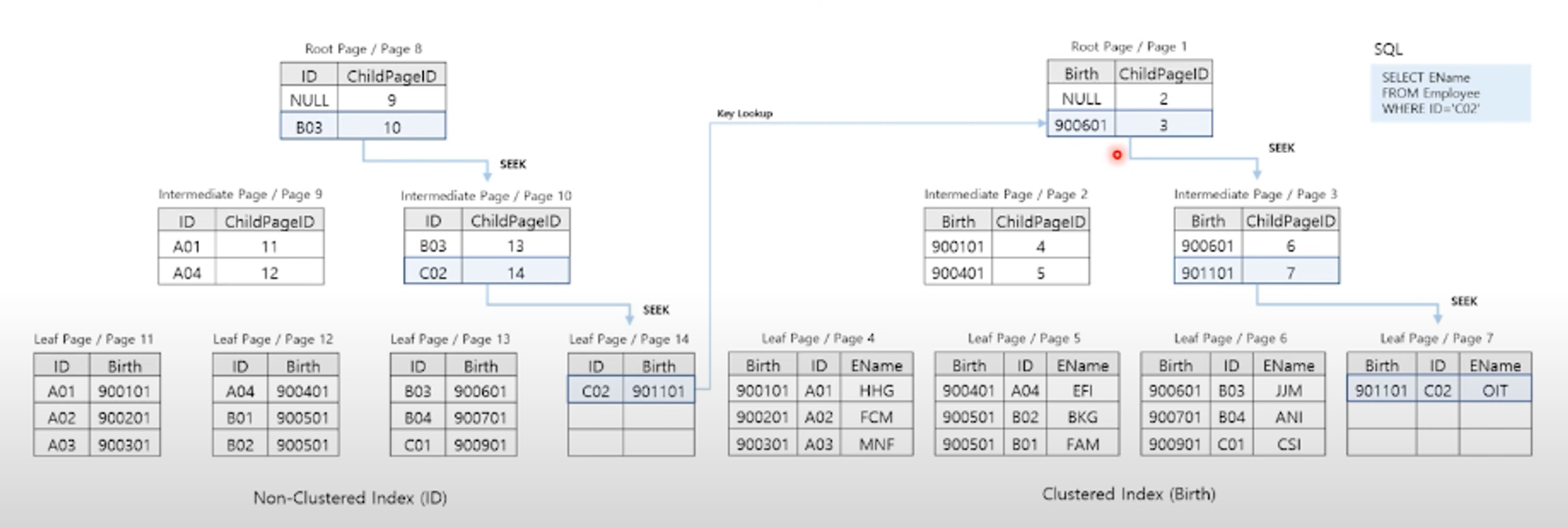
Key Lookup : Non-Clustered Index + Clustered Index
- 열 데이터가 부족하여 조인을 통해 열을 가져오는 과정으로 RID Lookup과 동일
- Non-Clustered Index에 포함된 열 이외의 데이터까지 조회하는 경우 발생
궁금
인덱스가 있기만 하면 무조건 인덱스 스캔인건가? 왜냐면 인덱스 지정된 컬럼을 조건으로 주면 인덱스 seek 이기 때문이고 그렇지 않은 경우는 인덱스 스캔으로 되기 때문… 직접 해보자
결론 : 무조건 index seek, index scan이 아니다.!!
인덱스 선택도(Selectivity): 인덱스 선택도는 인덱스의 유일성을 나타내는 지표로, 쿼리가 선택하는 데이터와 인덱스가 선택하는 데이터의 비율을 의미한다. 인덱스 선택도가 높을수록 해당 인덱스가 더 유용하게 사용될 가능성이 높다. (옵티마이저가 판단)
쿼리의 성능 향상 여부: 인덱스를 사용하더라도 데이터가 많고 선택도가 낮은 경우에는 Table Scan이 더 효율적일 수 있다.
인덱스와 테이블의 크기: 데이터베이스 엔진은 인덱스와 테이블의 크기를 고려하여 실행 계획을 결정하기 때문에인덱스가 작고 쿼리가 선택하는 데이터가 적은 경우에는 Index Seek이나 Index Scan이 더 효율적이다.
인덱스와 테이블의 변경 빈도: 인덱스와 테이블의 변경 빈도도 고려되며 인덱스와 테이블의 변경이 자주 일어나는 경우에는 인덱스를 사용하여 쿼리를 실행하는 것은 성능을 저하시킬 수 있다.
인덱스 조각화
정의
- 키 값을 기반으로 정렬된 인덱스 페이지의 논리적 순서와 물리적 순서가 일치하지 않는 것을 의미
- 페이지 분할로 인해 발생될 수 있다.
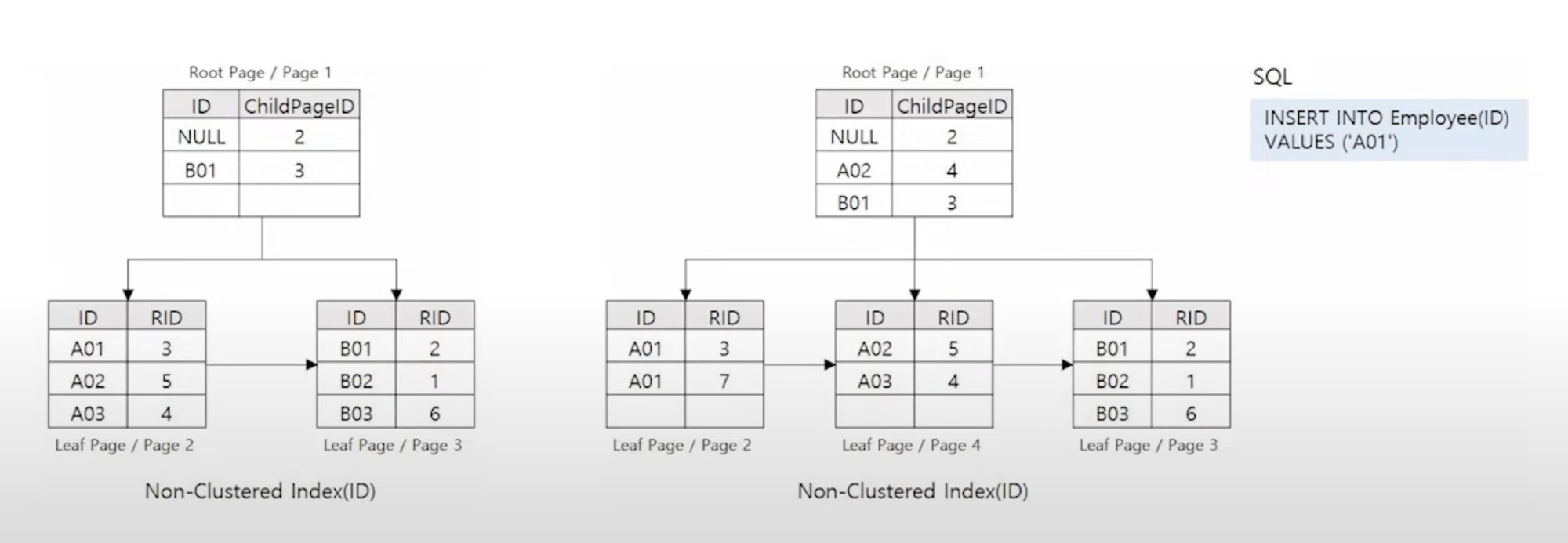
페이지 분할에 의한 성능 이슈
- 페이지 분할은 읽어내야 하는 페이지가 많아지는 것을 의미한다. (성능이 저하됨을 의미)
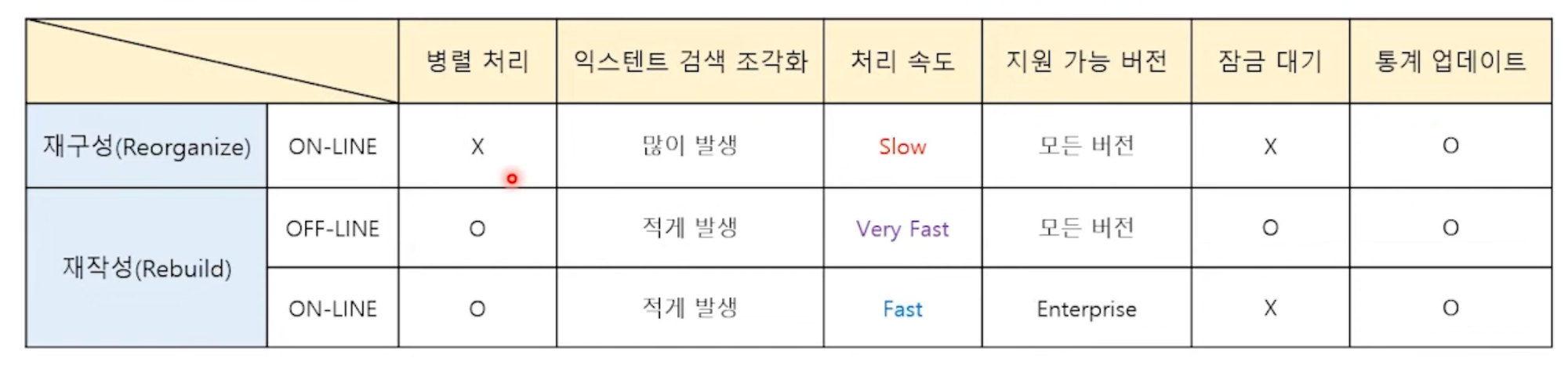
분할된 페이지 정리
- 인덱스 재구성 : 조각난 인덱스의 페이지를 읽어내면서 물리적으로 재 정렬한 후 비워진 페이지를 반환
- ALTER INDEX [인덱스명] on [TABLE명] REORGANIZE
- 인덱스 재작성 : 기존 인덱스를 삭제하고 새로운 페이지를 할당받아 재 생성
- 재구성과 재작성 비교
통계 (STATISTICS)
정의
- 테이블의 데이터 분포를 기반으로 계산된 정보
- 테이블이나 인덱싱된 뷰에서 하나 이상의 열에 있는 값의 분포에 대한 통계 정보를 포함하는 BLOB개체
- 통계의 상세정보, 열들에 대한 밀도 벡터, 단일 열( 또는 인덱스의 선두 키 )의 데이터 분포를 나타내는 히스토그램을 포함한다
필요성
- 해당 정보로 조회 대상 데이터의 예상되는 행 수를 산정
- 예상 행 수는 처리비용을 계산하기 위해 사용됨
- 이 비용을 바탕으로 최적화된 실행계획을 선택한다.
통계의 유무에 따라 수행되는 실행계획의 차이
SELECT A.PRODUCTNUMBER,
B.MODIFIEDDATE
FROM TB_STATISTICS A
INNER JOIN TB_STATISTICS B
ON A.PRODUCTNUMBER = B.PRODUCTNUMBER
WHERE A.PRODUCTNUMBER > 4500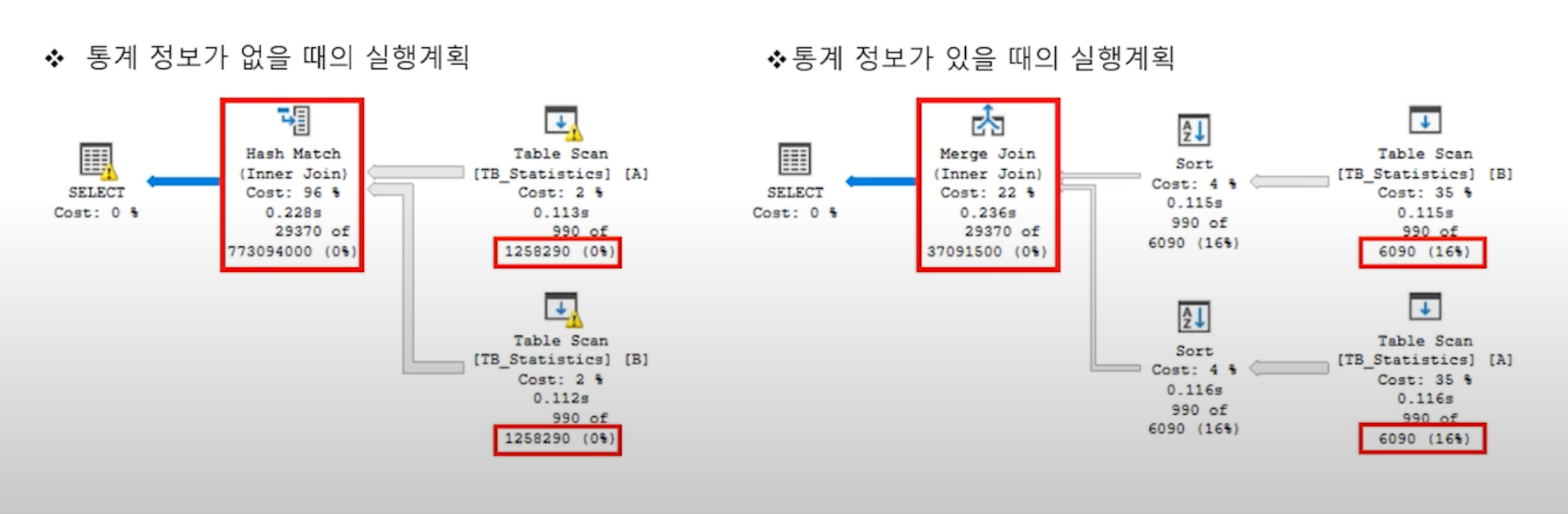
- 통계정보 없을때 : 120만건 이상으로 판단하여 Hash Join을 실행한다
- 통계정보가 있을때 : 6090건으로 판단하여 Merge Join을 실행한다
구성요소
-
통계헤더(stat header)

- Name : 통계의 이름을 나타낸다
- Updated : 해당 통계의 마지막 업데이트 시간을 나타낸다
- Rows : 통계의 마지막 업데이트 시간을 기준으로 전체 행 수를 나타낸다.
- Rows Sampled : 통계 정보가 업데이트될 때 참고했던 행의 수
- Steps : 히스토그램의 단계 수를 나타낸다. (최대 200단계)
- Density : 히스토그램 경계 값을 제외하고 모든 값에 대한 1/(고유 값)을 나타낸다. (잘 안씀)
- Average key length : 전체 열의 데이터들이 가지는 평균 바이트 수
- String Index : 문자열 요약 통계가 별도로 저장되어 있음을 표기
- Filter Expression : 필터링된 인덱스를 사용할 경우에 필터 조건자를 나타낸다.
- Unfiltered Rows : 필터 조건에 의해 필터 되지 않은 행의 수
-
밀도벡터(Density Vector)
- 정의 : 단일컬럼과 결합 컬럼들의 밀도와 평균 길이를 표기한다.

- 정의 : 단일컬럼과 결합 컬럼들의 밀도와 평균 길이를 표기한다.
-
히스토그램(Histogram)
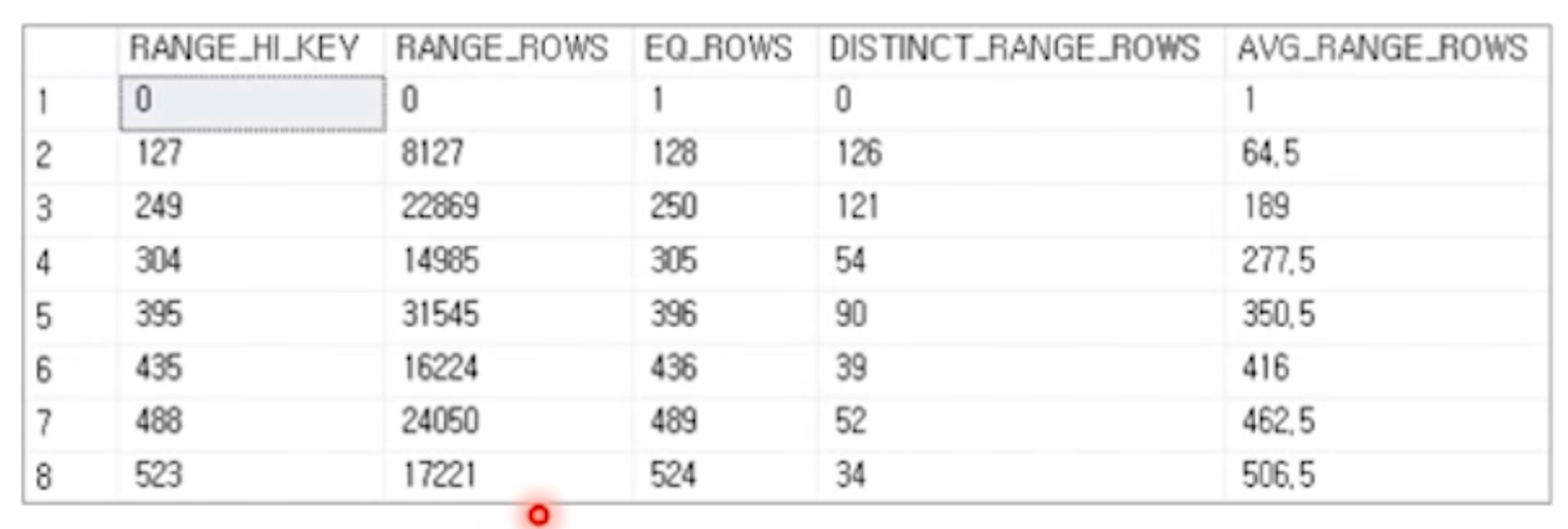
- RANGE_HI_KEY : 히스토그램 단계로 지정된 값을 상한 값을 나타낸다
- RANGE_ROWS : 현재 단계와 이전 단계 사이에서 상한 값을 제외한 값들의 행 수를 나타낸다
- EQ_ROWS : 각 단계에서 상한 값과 같은 값을 가진 행의 수를 나타낸다
- DISTINCT_RANGE_ROWS : 상한 값을 제외한 값들의 중복 제거한 데이터 수를 의미한다
- AVG_RAGNE_ROWS :
RANGE_ROWS를DISTINCT_RANGE_ROWS로 나눈 값 - 해석 (예시)
- 8행을 기준으로 7행의 RAGNE_HI_KEY가 488이기 때문에 489 ~ 523까지의 구간을 나타내는 것.
- RAGNE_HI_KEY는 523이다.
- RANGE_HI_KEY를 제외한 489 ~ 522까지의 데이터는 17221행이 존재한다.
- 523은 (EQ_ROWS)524행이 존재한다.
- 489~522까지에서 중복을 제거하면 34개 이다.
- 489~522까지의 각 데이터들은 평균적으로 506.5행이 존재한다.
변수를 사용하여 바인드한 구문은 밀도벡터를 그렇지않으면 히스토그램을 참조한다.
→ Dart언어의 const와 비슷한 원리인듯 하다. (쿼리를 실행하기전에는 변수의 값을 알 수가 없다.)
히스토그램을 참조하여 실행계획을 세우면 예상 행 수와 실제 행수가 일치한다.
통계정보 확인을 위한 기본명령어
DBCC SHOW_STATISTICS ([테이블명], [인덱스명]) [WITH 옵션]
옵션 없으면 3개 다 조회
// 옵션 종류
STAT_HEADER -> 통계헤더
DENSITY_VECTOR -> 밀도 벡터
HISTOGRAM -> 히스토그램격리 수준(ISOLATION)
정의
- 트랜잭션이 수행될때 다른 트랜잭션으로부터 영향을 받지 않게 고립성을 유지시키는 트랜잭션 특성
- 다양한 격리수준으로 잠금의 유형을 정의함
- 명시적으로 격리 수준을 변경하기 전까지 기본 격리 수준(READ COMMITTED)가 유지된다.
격리 수준 옵션을 지정하는 구문
SET TRANSACTION ISOLATION LEVEL
// 옵션 선택
READ UNCOMMITTED
READ COMMITTED
REPEATABLE READ
SNAPSHOT
SERIALIZABLE필요성
- 현재 트랜잭션이 다른 트랜잭션으로부터 영향을 받지 않도록 하기 위해 잠금으로 이를 보장한다.
- 격리 수준을 높이면 동시성은 낮아지고, 반대로 격리 수준을 낮추면 동시성은 높아진다.
- 동시성 제어를 하기 위해 다양한 격리 수준이 필요하며 상황에 따라 적합한 수준을 사용해야 한다.
격리 수준에서 허용되는 동시성의 문제점
- Dirty Read : 트랜잭션에서 데이터를 읽을 때 아직 COMMIT 되지 않은 데이터를 읽는 현상
- Non-Repeatable Read : 트랜잭션에서 읽은 데이터가 해당 트랜잭션이 종료되기 전에 다른 트랜잭션에서 변경, 삭제되어 다시 읽었을 때 읽었던 데이터의 결과 값이 다른 현상
- Phantom Read : 트랜잭션에서 읽은 데이터가 해당 트랜잭션이 종료되기 전에 다른 트랜잭션에서 데이터를 삽입하여 다시 읽었을 때 결과 집합이 다른 현상
종류
- READ UNCOMMITTED
- 데이터가 수정되었지만 아직 COMMIT되지 않은 데이터를 읽을 수 있도록 지정하는 격리 수준
- 데이터 조회 시 Key에 공유잠금(S)을 요청하지 않는다.
- COMMIT되지 않은 데이터도 읽을 수 있는 격리 수준
- (NOLOCK)
- READ COMMITTED
- 데이터가 변경되었지만 COMMIT되지 않으면 읽을 수 없도록 지정하는 격리 수준
- SQL Server의 기본 격리수준
- 데이터 조회 시 공유 잠금을 획득하며 조회가 끝나면 반환한다
- Dirty Read를 방지할 수 있고, Non-Repeated Read, Phantom Read는 발생할 수 있다.
ALTER DATABASE [db명] SET READ_COMMITTED_SNAPSHOT ON WITH ROLLBACK IMMEDIATE- 이 옵션이 ON으로 설정되어 있으면 데이터베이스 엔진은 행 버전 관리를 사용하여 데이터 일관성을 제공한다.
- 트랜잭션에서 조회할때 키에 공유 잠금 요청없이 COMMIT된 데이터를 읽을 수 있다. → COMMIT 될때까지 기다리지 않는다는 의미. (실제로 commit된게 아니기 때문에 commit되기 전 데이터를 불러온다)
- REPEATABLE READ
- COMMIT된 데이터만 읽도록 하며 현재 트랜잭션이 조회하는 데이터를 다른 트랜잭션에서 수정, 삭제할 수 없도록 지정한다
- 데이터 조회 시 공유 잠금(LOCK)을 획득하고 트랜잭션이 완료되기 전까지 반환하지 않는다.
- 범위 조건 검색 시 해당하는 데이터를 수정, 삭제는 불가능하지만 삽입은 가능하기 때문에 Phantom Read가 발생할 수 있다.
ex)
1.
BEGIN TRAN
SELECT * FROM TESTTABLE FROM WHERE NO > 2
2.
BEGIN TRAN
UPDATE TESTTABLE SET GRADE = 'A'
FROM TESTTABLE WHERE NO = 5
// TESTTABLE을 조회시 트랜잭션을 생성하였고 (shared lock)
// 같은 테이블 TESTTABLE을 다른 트랜잭션을 생성하여 update하려 했으나 선행된
// 조회 트랜잭션이 종료되기 전에는 후행된 update 트랜잭션을 수행할 수 없다.- SNAPSHOT
- ALLOW_SNAPSHOT_ISOLATION 기능을 활성화 하면 데이터베이스 수준에서 스냅샷 옵션을 사용하도록 설정한다
- 트랜잭션에서 스냅샷 격리를 사용하지 않는 경우에도 DML 문에서 행 버전을 생성하기 시작하며 트랜잭션에서 스냅샷 격리 수준을 지정할 수 있다.
- 스냅샷 트랜잭션이 아닌 다른 트랜잭션에서 데이터가 수정되면 행 버전을 생성하고 스냅샷 트랜잭션에서 수정하려는 행의 버전을 확인하여 수정된 버전이 있다면 업데이트 충돌 오류가 발생한다.
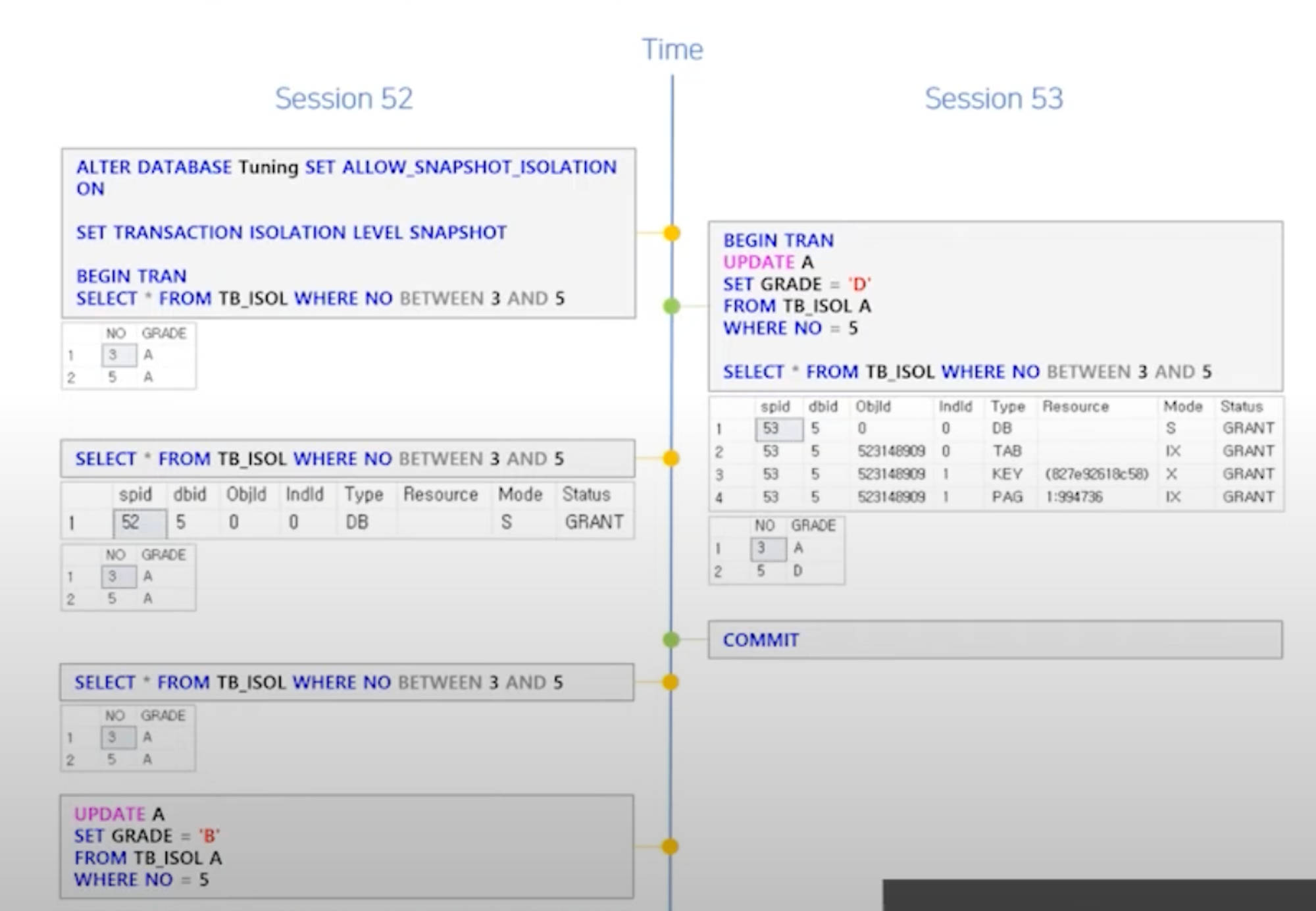
- SERIALIZABLE
- REPEATABLE READ와 유사한 특성을 가지지만, 이 수준은 범위 조건 검색 시 해당 범위에 데이터 삽입도 불가능하다.
- 데이터 조회 시 키 단위로 공유 잠금을 하지 않고 키 범위로 공유 잠금을 한다.
- 동시성은 매우 낮지만 데이터 정합성이 중요한 경우 선택안이 될 수 있고, Dirty Read, Non-Repeatable Read, Phontom Read 모두 방지된다.

조인(JOIN)
정의
- 관계가 있는 두 개 이상의 테이블을 주어진 조건으로 결합하여 하나의 결과 집합으로 출력하는 기능
종류
- 논리적 조인 : 결과 집합의 데이터를 결정하는 방식
- INNER JOIN : 조인 조건을 만족하는 데이터만 결과로 출력
- OUTER JOIN : 조인조건을 만족하는 데이터와 기준이 되는 테이블의 조인 실패 행까지 출력 ( LEFT, RIGHT, FULL )
- CROSS JOIN : 조인 조건 없이 두 테이블에 대한 모든 행을 조인하여 출력
- 물리적 조인 : 조인을 처리하기 위한 방법 NL, HASH, Sort MERGE
- Nested Loop Join : 중첩된 반복조인
- Merge Join : 테이블의 처리 범위 내에서 조인 키 기준으로 정렬한 다음 병합하는 과정으로 조인
- Hash Join : 테이블을 한번 스캔하거나 계산한 후 해시함수를 적용하여 조인
Nested Loop Join (NL Join)
- 중첩된 반복 조인
- 선행 테이블의 결과 집합을 한 건씩 후행 테이블에 조인하고 이를 반복하여 최종 결과 집합을 만들어낸다
- 선행 테이블의 결과 집합 건수만큼 조인이 반복되기 때문에 결과 집합의 크기에 따라 조인의 전체 일 량이 결정된다
NL Join 처리 과정
ex) 예시
SELECT EMP.ENAME,
EMP.SAL,
DEPT.DNAME
FROM DEPT
INNER LOOP JOIN EMP
ON DEPT.DEPTNO = EMP.DEPTNO
WHERE DEPT.DEPTNO = 20 AND EMP.SAL > 2000Dept테이블의DEPTNO = 20조건에 만족하는 데이터를IX_DEPTNO인덱스로 범위 탐색한다.IX_DEPTNO인덱스로부터 탐색한 행의 RID 값으로 DEPT 테이블에 RID LookUp을 수행한다- 조인 조건인
DEPTNO열을 기준으로EMP테이블의IX_EMP인덱스와 조인한다 - 조인된 결과에서
IX_EMP의 RID값으로EMP테이블에 RID LookUp을 수행한다 - 조인된 결과 집합에서
EMP테이블의 조건인Sal>2000을 만족하는 데이터만 운반 단위에 전달한다 - 1번에서 탐색한 행 수만큼 2번~5번 과정을 반복하여 최종결과 집합을 출력한다
Merge Join (Sorted Merge Join)
- 두 테이블의 처리 범위 내에서 조인 키 기준으로 정렬한 다음 병합하는 과정으로 조인한다
- 조인할 때 정렬을 선행으로 하게 되는데, 이때 인덱스를 통해 미리 정렬된 데이터로 조인한다면 이 과정은 생략할 수 있다.
Merge Join 처리 과정
SELECT EMP.ENAME,
EMP.SAL,
DEPT.DNAME
FROM DEPT
INNER MERGE JOIN EMP
ON DEPT.DEPTNO = EMP.DEPTNO
WHERE DEPT.DEPTNO > 20 AND
EMP.SAL > 2000DEPT테이블에서DEPTNO > 20조건에 만족하는 데이터를 찾고 조인 조건인DEPTNO열로 정렬을 수행한다EMP테이블에서도Sal > 2000조건에 만족하는 데이터를 찾고DEPTNO열을 기준으로 정렬을 수행한다DEPTNO로 정렬된 데이터를 기준으로 마지막 값을 만날 때까지 스캔하면서 최종 결과 집합을 출력한다
Hash Join
- 해시함수를 적용하여 조인하는 방식이다
- 조인할 때 선행으로 읽어내는 테이블을 빌드 입력(Build Input), 후행으로 읽는 테이블을 프로브 입력(Probe Input)이라고 한다
- 빌드 입력은 해시함수를 적용하여 해시테이블을 생성하고 프로브 입력의 값을 해시함수로 적용하면서 해시테이블에 조인한다
- 해시테이블을 생성할 때 메모리를 사용하게 되는데 메모리만 사용하여 처리할 경우에는 인메모리 해시 조인, 메모리 부족으로 디스크 영역까지 사용하게 되면 유예 해시조인이라고 한다
- 실제 사용사례 : (링크된)오라클서버의 테이블과 mssql서버의 테이블을 서로 Join할때 사용.
- 중간에 Hash테이블을 두고 조인을 처리하기 때문에 가능.
Hash Join 처리 과정
SELECT EMP.ENAME,
EMP.SAL,
DEPT.DNAME
FROM DEPT
INNER HASH JOIN EMP
ON DEPT.DEPTNO = EMP.DEPTNO
WHERE DEPT.DEPTNO > 20 AND
EMP.SAL > 2000DEPT테이블의DEPTNO > 20조건에 해당하는 행을IX_DEPTNO인덱스로 탐색한 후 해시함수를 적용하여 해시테이블을 생성한다EMP테이블에서SAL > 2000조건에 해당하는 행을 해시함수를 적용하면서 해시테이블에 조인한다- 조인에 성공한 행은 최종 결과 집합에 포함하며
EMP테이블의 행이 모두 비교될때까지 2번을 반복한다
암시적으로 조인이 사용되는 구문
스칼라 반환 함수
- 외부로부터 단일 값을 입력 받고 내부 구문을 수행하여 결과를 단일 값으로 반환한다
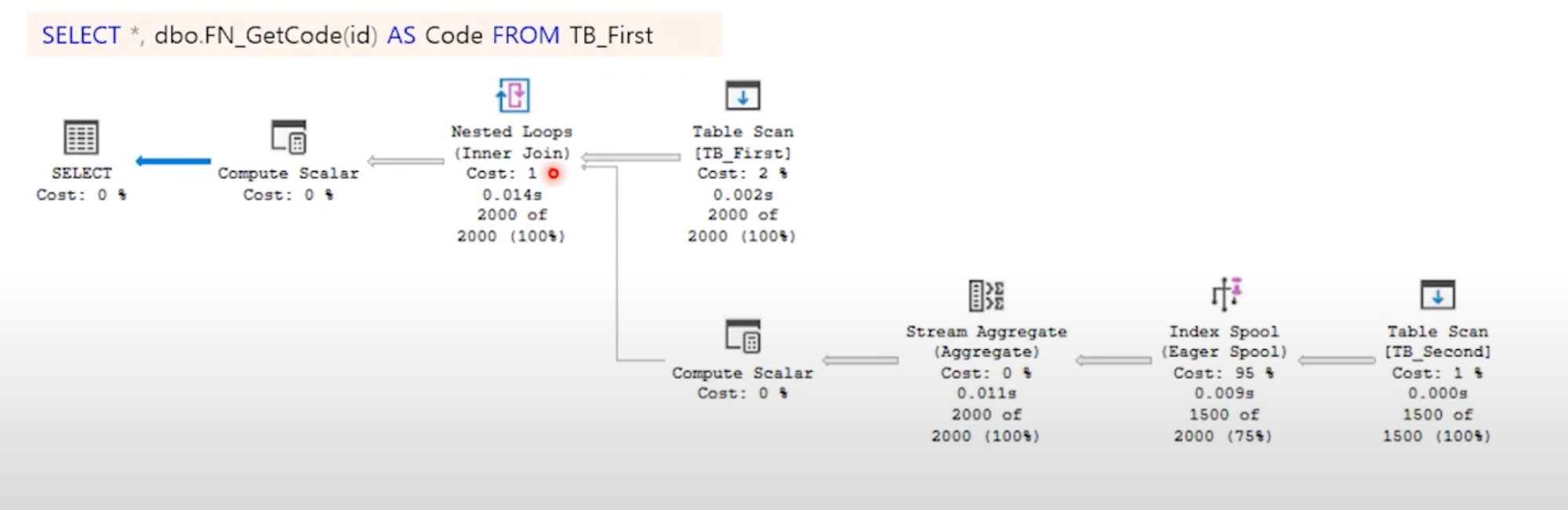
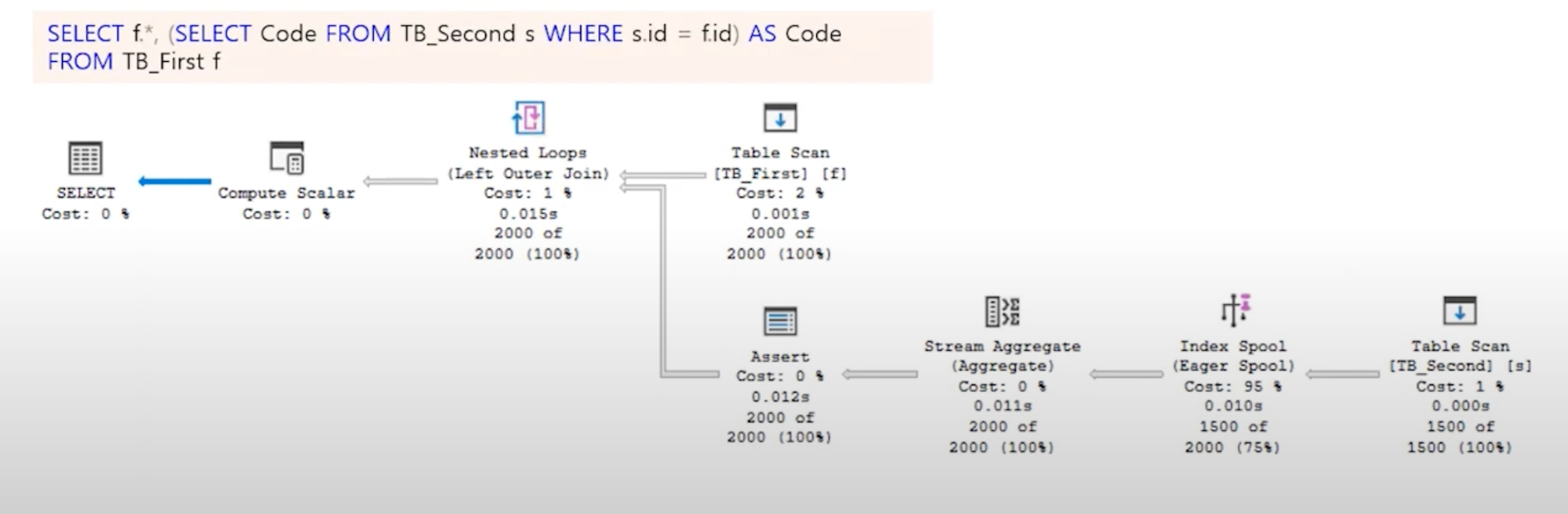
스칼라 서브 쿼리
- 서브 쿼리는 SQL 구문안에 존재하는 SQL 구문을 의미한다
- FROM 절에 정의되는 SQL을 제외하고 SELECT절이나 WHERE절 등에 작성될 수 있으며 단일 값의 결과만 반환할 수 있다.
- 스칼라 함수와의 차이점 : 메인 쿼리와 조인조건을 기준으로 OUTER JOIN된다는 것이다.
조인의 힌트
- Loop : Nested Loop Join으로 수행 방식을 고정한다
- Merge : Merge Join으로 고정
- Hash : Hash Join으로 고정
Join Hint
SELECT *
FROM DEPT
INNER LOOP JOIN EMP
ON DEPT.DEPTNO = EMP.DEPTNOQuery Hint
SELECT *
FROM DEPT
INNER JOIN EMP
ON DEPT.DEPTNO = EMP.DEPTNO
OPTION(LOOP JOIN)실행 계획
정의
- 실행계획은 SQL 구문을 처리하기 위해 사용되는 연산 방법이나 오브젝트를 읽어내는 순서 등이 조합된 일련의 처리 절차이다.
특징
- SQL 구문을 처리하는 실행 계획은 많은 경우의 수로 생길 수 있지만, 비용을 계산하여 가장 최적이라 판단되는 계획이 선택된다.
- 하지만 SQL의 작성방법(힌트고정, 연산자 사용)이나 혹은 사용자가 설정한 옵션 등의 다양한 이유로 죄적의 실행 계획은 아닐 수 있다
- SQL을 처리하는데 있어서 리소스 사용 비율을 파악할 수 있다.
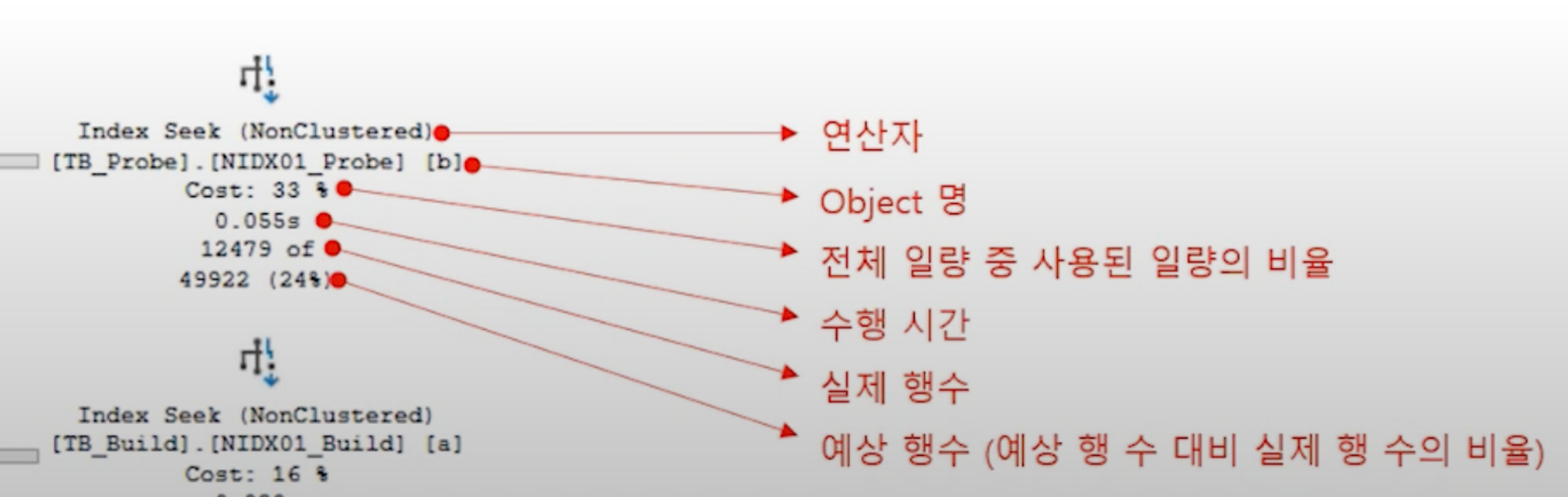
실행계획 확인 방법
- 예상실행계획 : 각 연산자의 속성 정보를 통해 SQL이 수행되기전에 미리 계획을 확인할 수 있다. (실제와 차이가 있을수 있다)
- 실제 실행계획 : SQL이 실제로 수행된 정보를 출력하며 리소스 사용량 메트릭 및 런타임 정보가 포함된다.
텍스트 예상 실행계획
SET SHOWPLAN_ALL ON/OFF명령을 통해 활성화
텍스트 실제 실행계획
SET STATISTICS PROFILE ON/OFF명령을 통해 활성화
