
spark 설치
apache spark

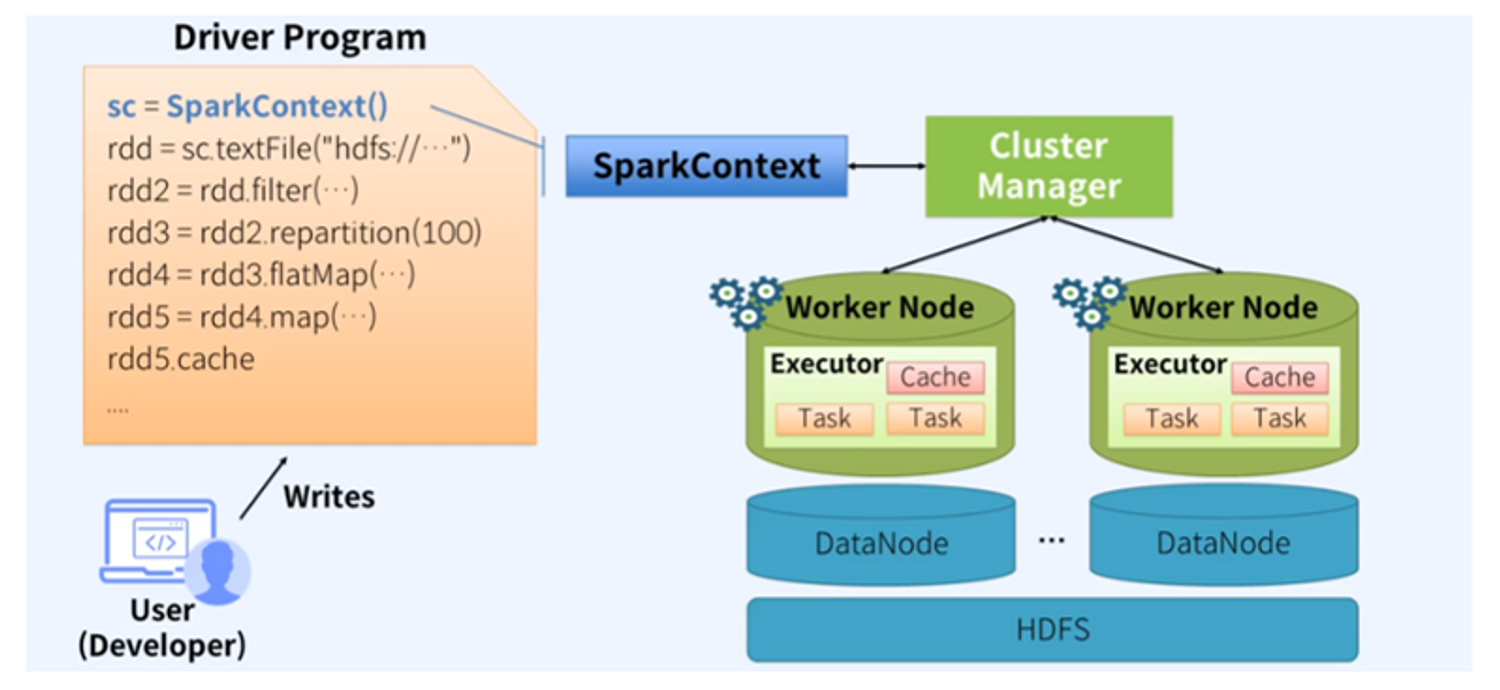
- 작동 방식
기본설치
- spark 설치 및 실행(다운 로드, 설정, shell)
- spark history server 구성(historyserver 시작/종료/테스트)
spark 설치 및 실행(다운로드, 설정, shell)
- spark local 환경 구성 및 실행(spark-master-01 서버에서 작업)
#-----------------------------------------------------------------------------
# Spark Tarball 다운로드.... (spark 3.2.1 pre-built) (on spark-master-01)
#-----------------------------------------------------------------------------
# tarball 다운로드(spark 3.2.1 pre-built)
cd /playdata
wget https://archive.apache.org/dist/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz
tar xvfz spark-3.2.1-bin-hadoop3.2.tgz
mv spark-3.2.1-bin-hadoop3.2 spark32
# JAVA_HOME 환경변수 설정(jdk8, spark-env.sh)
cd /playdata/spark32
./bin/spark-shell
# JAVA_HOME is not set -> JAVA_HOME 환경변수 설정 필요
#-----------------------------------------------------------------------------
# JAVA 다운로드 + Unzip.... (OpenJDK8) (on spark-master-01)
#-----------------------------------------------------------------------------
cd /playdata
wget https://github.com/ojdkbuild/contrib_jdk8u-ci/releases/download/jdk8u232-b09/jdk-8u232-ojdkbuild-linux-x64.zip
unzip jdk-8u232-ojdkbuild-linux-x64.zip
mv jdk-8u232-ojdkbuild-linux-x64 jdk8
rm jdk-8u232-ojdkbuild-linux-x64.zip
#----------------------------------------------------------------------------
# JAVA_HOME 환경변수 설정.... (spark-env.sh) (on spark-master-01)
#----------------------------------------------------------------------------
cd /playdata/spark32/conf
cp spark-env.sh.template spark-env.sh
nano spark-env.sh
# 다음 내용 추가
JAVA_HOME=/playdata/jdk8
#----------------------------------------------------------------------------
# spark-shell 실행.... (on spark-master-01)
#----------------------------------------------------------------------------
# 정상 실행 확인(spakr-shell) + Web UI 확인(http://spark-master-01:4040)
cd /playdata/spark32
./bin/spark-shell
scala> sc
scala> spark
scala> sc.master
scala> sc.uiWebUrl
//--프로세스 확인.... (SparkSubmit) (다른 터미널 하나 더 열어서)
$ /playdata/jdk8/bin/jps
2800 Jps
2692 SparkSubmit -> spark-shell 프로세스.... (Driver 프로세스)
//--Driver 웹UI 확인.... (on 크롬 브라우저) (필요시 방화벽 오픈)
http://공인IP:4040
//--spark-shell 나가기....
scala> (Ctrl + L) -> Console 화면 Clear....
scala> :quit 또는 :q -> 나가기....
#-----------------------------------------------------------------------------
# (옵션) PATH 설정.... (~/.profile) (on spark-master-01)
#-----------------------------------------------------------------------------
//--JPS 명령어에 대한 PATH 등록.... (/playdata/jdk8/bin)
$ vi ~/.profile
export PATH=/playdata/jdk8/bin:$PATH
$ source ~/.profile 또는 . ~/.profile
$ jps
$ java -version
$ javac -version예제로 실행해보기
- RDD
- asd- Resilient Distributed Dataset
- 클러스터에서 구동시 여러 데이터 파티션은 여러 노드에 위치할 수 있습니다. RDD를 사용하면 모든 파티션의 데이터에 접근해 Computation 및 transformation을 수행할 수 있습니다.
- scala로 실행해 보기
#--spark-shell 코드 작성 및 실행.... (Word Count)
$ cd /playdata/spark32
$ ./bin/spark-shell
scala> val rdd = sc.textFile("README.md")
scala> val rdd_word = rdd.flatMap(line => line.split(" "))
# iterable 객체의 각 요소를 한 단계 더 작은 단위로 쪼개는 기능
scala> val rdd_tuple = rdd_word.map(word => (word, 1))
scala> val rdd_wordcount = rdd_tuple.reduceByKey((v1, v2) => v1 + v2))
# reduce는 키 기반으로 합침 | ex) (a,1)(a,1) -> (a,2) & (a,1)(a,2)(a,3) -> (a,6)
scala> val arr_wordcount = rdd_wordcount.collect()
# RDD를 Scala array로 변환,RDD의 값을 보고싶을 경우 사용
scala> arr_wordcount.take(10).foreach(tuple => println(tuple))
scala> :quit (-> 종료되면 history의 .inprogress 확장자 사라짐)- pyspark으로 실행해 보기
$ cd /playdata/spark32
$ ./bin/pyspark
> rdd = sc.textFile("README.md")
rdd_word = rdd.flatMap(lambda line: line.split(" "))
rdd_tuple = rdd_word.map(lambda word: (word, 1))
rdd_wordcount = rdd_tuple.reduceByKey(lambda v1,v2: v1 + v2)
arr_wordcount = rdd_wordcount.collect()
for wc in arr_wordcount[:10]:
... print(wc)
...
> exit()spark-sql 실행.... (Word Count)
#--spark-sql 실행.... (Word Count)
$ cd /playdata/spark32
$ ./bin/spark-sql
spark-sql> select word, count(*) from (select explode(split(*, ' ')) as word from text.`README.md`) group by word limit 10;
spark-sql> exit; (-> 종료되면 history의 .inprogress 확장자 사라짐)- local 호스트 설정
- 참고 : https://extrememanual.net/28196

# 다음 내용 추가 저장
192.XXX.XXX.100 spark-master-01
192.XXX.XXX.101 spark-worker-01
192.XXX.XXX.102 spark-worker-02linux ubuntu 환경 방화벽
sudo ufw enable # 방화벽 켜기
sudo ufw disable # 방화벽 끄기
sudo ufw allow 1234/tcp # 1234 port의 tcp를 open 하여 줌
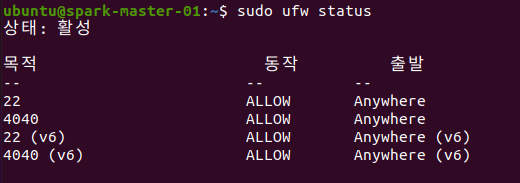
sudo ufw status # 상태 확인 하기
# 규칙 제거
sudo ufw delete allow 1234/tcp
sudo ufw delete deny 1234/tcp



👨Education Computer Engineering 🎓Expected Graduation: February 2023 📞Contact info thstjddn77@gmail.com