WITH CHECK OPTION CONSTRAINT, WITH READ ONLY, SEQUENCE, SYNONYM, DATA ACCESS METHOD(Full table scan, Rowid scan), INDEX(Nonunique, Unique, Range scan, Unique scan, 조합 INDEX)
빅데이터&머신러닝 - SQL
오늘은 WITH CHECK OPTION CONSTRAINT와 WITH READ ONLY, SEQUENCE와 SYNONYM, 그리고 데이터를 처리하는 방법으로 FULL TABLE SCAN과 ROWID SCAN을 배웠고, 데이터를 보다 빠르게 추출할 수 있는 INDEX에 대해 공부했다.
WITH CHECK OPTION CONSTRAINT
: VIEW에 CHECK 제약조건을 생성할 때 쓰는 형태. WHERE 절에 있는 조건식이 CHECK 제약조건의 조건식이 된다.
기본적인 형태는 다음과 같다.
CREATE OR REPLACE VIEW 뷰이름
AS
SELECT *
FROM 소유자.테이블
WHERE 조건식
WITH CHECK OPTION CONSTRAINT 뷰이름_ck;예를 들어보자.
CREATE OR REPLACE VIEW test_view
AS
SELECT *
FROM hr.test
WHERE sal BETWEEN 1000 AND 10000
WITH CHECK OPTION CONSTRAINT test_view_ck;test_view라는 이름의 VIEW를 생성하는데, hr.test 테이블에서 test_view_ck라는 이름의 CHECK 제약조건을 생성하는데 그 조건은 연봉이 1000~10000이어야 한다는 뜻이다.
test_view라는 이름의 view의 제약조건을 조회해보자.
SELECT * FROM user_constraints WHERE table_name = 'TEST_VIEW'; -- VIEW 제약조건 확인
VIEW에 체크 제약조건을 걸었기 때문에 제약조건 타입은 V, CHECK 제약조건의 조건식(Search_condition)은 null로 나온다. 따라서 CHECK 제약조건의 조건식을 조회하려면 user_views를 이용해야 한다.
SELECT * FROM user_views WHERE view_name = 'TEST_VIEW'; -- CHECK 제약조건 조건식 확인
VIEW에 걸린 CHECK 제약조건의 조건식을 확인하려면 위의 쿼리문을 작성한 뒤, text 컬럼을 확인하도록 한다.
"SELECT "ID","NAME","SAL"
FROM hr.test
WHERE sal BETWEEN 1000 AND 10000
WITH CHECK OPTION "여기서 CHECK 제약조건의 조건식은 WHERE 절이다.
만약 hr이라는 유저에서 생성한 test_view라는 view를 insa라는 유저에서 이용하려면 어떻게 해야할까? 우선 insa 유저에게 test_view에 대해 어떤 권한이 있는지 조회를 먼저 해주어야 한다.
SELECT * FROM user_tab_privs; -- insa 계정에서 실행
insa 유저의 권한을 조회했더니 hr유저의 emp_insa라는 테이블에 대해서 SELECT 할 수 있는 권한만 있다. 우리가 insa에서 view를 사용하려면 권한을 부여해주자.
GRANT SELECT, INSERT, UPDATE, DELETE ON hr.test_view TO insa; -- hr 계정에서 실행
SELECT * FROM user_tab_privs; -- insa 계정에서 실행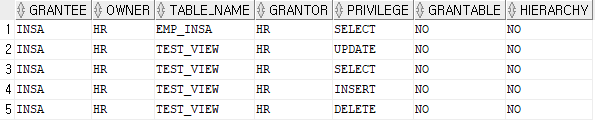
insa 유저에게 test_view에 대한 SELECT, INSERT, UPDATE, DELETE 권한이 부여되었다. 그럼 예시로 insa 계정에서 test_view라는 VIEW를 이용하여 행을 INSERT 해보자.
INSERT INTO hr.test_view(id,name,sal) VALUES(600,'이문세',10000);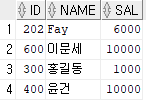
제대로 INSERT 된 것을 확인할 수 있다. 또 다른 데이터를 INSERT 해보자.
INSERT INTO hr.test_view(id,name,sal) VALUES(500,'나얼',20000);
위 예제의 경우 sal 값으로 넣어준 20000이 WHERE 절의 CHECK 제약조건(연봉 1000~10000)을 위반하였으므로 실행되지 않는다. UPDATE도 해보자.
UPDATE hr.test_view
SET sal = 30000
WHERE id = 202;
위 예제의 경우 sal 값으로 넣어준 30000이 WHERE 절의 CHECK 제약조건(연봉 1000~10000)을 위반하였으므로 실행되지 않는다. DELETE도 해보자.
DELETE FROM hr.test_view WHERE id = 202;
이렇듯 CHECK 제약조건은 INSERT, UPDATE 시에 수행된다. 같은 DML이지만 DELETE는 CHECK 제약조건에 대해 해당되지 않는다.
WITH READ ONLY
: VIEW를 통해서 DML을 불허한다. SELECT 만 가능하도록 하는 옵션. 제약조건이 될 수 있다.
기본적인 형태는 다음과 같다.
CREATE OR REPLACE VIEW 뷰이름
AS
SELECT *
FROM 소유자.테이블
WITH READ ONLY;예를 들어보자.
CREATE OR REPLACE VIEW test_view
AS
SELECT *
FROM hr.test
WITH READ ONLY;test_view라는 이름의 VIEW를 생성하는데, hr.test 테이블의 SELECT만 가능하다는 뜻이다.
test_view라는 이름의 view의 제약조건을 조회해보자.
SELECT * FROM user_constraints WHERE table_name = 'TEST_VIEW'; -- VIEW 제약조건 확인
VIEW에 WITH READ ONLY를 걸었기 때문에 제약조건 타입은 O, WITH READ ONLY의 조건식(Search_condition)은 null로 나온다. 따라서 WITH READ ONLY의 조건식을 조회하려면 user_views를 이용해야 한다.
SELECT * FROM user_views WHERE view_name = 'TEST_VIEW'; -- WITH READ ONLY 조건식 확인
VIEW에 걸린 WITH READ ONLY의 조건식을 확인하려면 위의 쿼리문을 작성한 뒤, text 컬럼을 확인하도록 한다.
"SELECT "ID","NAME","SAL"
FROM hr.test
WITH READ ONLY"WITH READ ONLY는 WITH CHECK OPTION CONSTRAINT과 마찬가지로 INSERT, UPDATE 시에 수행된다. 같은 DML이지만 DELETE는 WITH READ ONLY에 대해 해당되지 않는다.
SEQUENCE
: 자동일련번호를 생성하는 객체. SEQUENCE 객체를 생성하려면 CREATE SEQUENCE 시스템권한이 필요하다.
SELECT * FROM user_sequences WHERE sequence_name = '시퀀스이름'; -- 시퀀스 확인SEQUENCE 생성
CREATE SEQUENCE 시퀀스이름;예를 들어보자.
CREATE SEQUENCE id_seq
START WITH 1 -- 시작점. 기본값은 1
MAXVALUE 3 -- 종료점. 10 ** 27 (10의 27승)
INCREMENT BY 1 -- 기본값
NOCYCLE -- 기본값, CYCLE이면 다른 CYCLE이 시작됨.
NOCACHE -- 기본값은 CACHE SIZE 20
;
MIN_VALUE는 시작 시점, MAX_VALUE는 종료 시점, INCREMENT_BY는 얼만큼씩 증가하는지를 의미한다. 그리고 CYCLE_FLAG가 Y이면 자동일련번호가 MAX까지 갔다가 다시 사이클을 수행한다는 뜻이고, N이면 종료라는 뜻이다. CACHE_SIZE는 성능을 좋게 하기 위해 SEQUENCE 번호를 한 번에 여러 개씩 메모리에 올려놓는 것인데, 매번 일일히 SEQUENCE 번호를 생성하는 것보다 한 번에 메모리에 올려진 SEQUENCE 번호를 사용하는 것이 속도가 더 빠르다. 그리고 LAST_NUMBER는 CACHE_SIZE만큼 만들어지므로 여기서 다음 번호는 2번이다.
SEQUENCE 객체는 영구결번처럼 재사용이 불가하다. 즉, 한번 사용한 번호는 사용할 수 없으므로 SEQUENCE 번호에 대한 갭이 생긴다.
- sequence이름.nextval : 사용가능한 번호를 리턴하는 가상컬럼
- sequence이름.currval : 현재 사용한 번호를 리턴하는 가상컬럼
SEQUENCE 수정
ALTER SEQUENCE id_seq
...
;예를 들어보자.
ALTER SEQUENCE id_seq
MAXVALUE 3
INCREMENT BY 1
NOCYCLE
NOCACHE
;단, SEQUENCE 옵션 중에 START WITH 옵션은 수정할 수 없다. 만약 MAXVALUE만 바꾸겠다고 하면 아래 SQL문만 수행하면 된다.
ALTER SEQUENCE id_seq
MAXVALUE 10;SEQUENCE 삭제
DROP SEQUENCE id_seq;SYNONYM
: 긴 객체 이름을 짧은 이름으로 사용하는 객체. SYNONYM 객체를 생성하려면 CREATE SYNONYM 시스템권한이 필요하다.
SYNONYM 생성
CREATE SYNONYM ec2 FOR emp_copy_2023;
SELECT * FROM user_synonyms WHERE table_name = 'EMP_COPY_2023'; -- 동의어 조회
SELECT * FROM ec2;SYNONYM 삭제
DROP SYNONYM ec2;
SELECT * FROM user_synonyms WHERE table_name = 'EMP_COPY_2023'; -- 동의어 삭제된 것 확인PUBLIC SYNONYM
: 모든 유저들이 사용할 수 있는 SYNONYM. PUBLIC SYNONYM 객체를 생성하려면 CREATE PUBLIC SYNONYM 시스템권한이 있어야 한다. 단, 이 시스템권한은 sys 계정만 가지고 있는 고유한 권한이므로 sys 계정에서 수행해야 한다.
GRANT CREATE PUBLIC SYNONYM TO 유저; -- sys 계정에서 수행
SELECT * FROM session_privs; -- 권한 확인그리고 PUBLIC SYNONYM을 사용하려면 그 SYNONYM에 연결되어 있는 객체에 대한 권한이 있어야만 SYNONYM을 사용할 수 있다.
PUBLIC SYNONYM 생성
CREATE PUBLIC SYNONYM emp FOR hr.employees;PUBLIC SYNONYM 삭제
일반적으로 개인이 만든 SYNONYM은 DROP을 이용하여 삭제가 가능하다. 그러나 PUBLIC SYNONYM은 그냥 DROP만 해서는 삭제할 수 없다. PUBLIC SYNONYM을 삭제하려면 DROP PUBLIC SYNONYM 시스템권한이 있어야 삭제가 된다.
GRANT DROP PUBLIC SYNONYM TO 유저; -- sys 계정에서 수행
SELECT * FROM session_privs; -- 권한 확인
DROP PUBLIC SYNONYM emp; DATA ACCESS METHOD
FULL TABLE SCAN
: 첫번째 BLOCK에 있는 행부터 마지막 BLOCK의 행까지 ACCESS 하는 방식
ROWID SCAN
: 행의 물리적인 주소(ROWID, 가상컬럼)를 가지고 찾는 방식. 데이터 액세스 방법 중 가장 빠르다.
ROWID가 AAAEAbAAEAAAADNAAA인 데이터가 있다고 가정해보자.
AAAEAbAAEAAAADNAAA
AAAEAb(6자리) : DATA OBJECT ID. 이 객체의 이름이 무엇인지를 나타낸다.
SELECT * FROM user_objects WHERE object_name = 'EMPLOYEES';AAE(3자리) : FILE ID. 이 객체가 어느 파일 안에 있는지를 나타낸다. 이를 테면, 내가 가진 테이블이 10GB인데 하나의 데이터 파일이 담을 수 있는 용량이 4GB라고 하면 총 3개의 데이터 파일이 필요하기 때문에 FILE ID는 다를 수도 있다.
SELECT * FROM user_tables WHERE table_name = 'EMPLOYEES';
SELECT * FROM dba_data_files WHERE tablespace_name = 'USERS'; -- SYS 계정에서 수행AAAADN(6자리) : BLOCK ID. BLOCK의 번호를 말한다.
SELECT * FROM user_segments WHERE segment_name = 'EMPLOYEES';
SELECT * FROM user_extents WHERE segment_name = 'EMPLOYEES';
SELECT * FROM dba_segments WHERE segment_name = 'EMPLOYEES'; -- SYS 계정에서 수행. 
header block이 BLOCK의 번호이고 여기서 head block은 202번이다. 번호는 sequence하게 넘버링 된다.
AAA(3자리) : ROW SLOT ID. BLOCK 안에 행(ROW)이 있는 위치를 말한다. SLOT의 번호는 전부 다르다.
BY USER ROWID SCAN
: 유저가 직접 ROWID를 써서 스캔하는 방식.
SELECT *
FROM hr.employees
WHERE ROWID = 'AAAEAbAAEAAAADNAAA';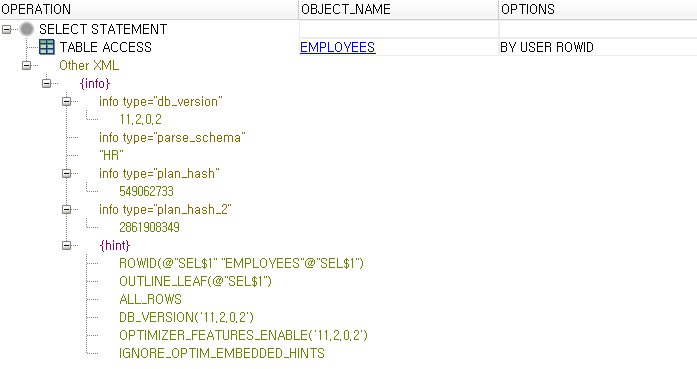
그런데 저렇게 긴 알파벳으로 나열된 ROWID를 모를 때가 많기 때문에 조건에 해당하는 ROWID를 별도로 적어둔 것이 바로 INDEX라는 개념이다.
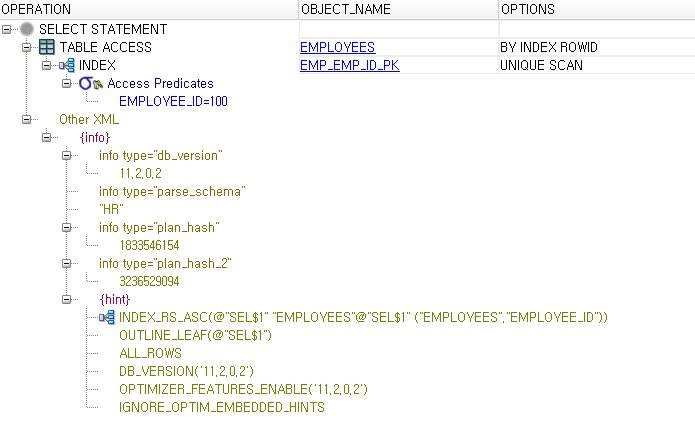
BY INDEX ROWID SCAN
: INDEX가 가지고 있는 ROWID를 가지고 스캔하는 방식
INDEX
: BY INDEX ROWID SCAN 방식을 사용해서 행의 검색 속도를 높이기 위한 객체.
INDEX를 이용해서 행을 검색하면 I/O(입력/출력)를 개선할 수 있고, INDEX는 테이블과 독립적으로 생성된다. 또한 INDEX는 자동으로 유지관리한다.
그리고 PRIMARY KEY, UNIQUE 제약조건을 생성하면 UNIQUE INDEX가 자동으로 생성된다. 그 외는 수동으로 INDEX가 생성된다.
NONUNIQUE INDEX 생성
CREATE INDEX 인덱스이름
ON 소유자.테이블(컬럼);INDEX도 객체이므로 고유한 이름을 써줘야 한다.
예를 들어보자.
CREATE INDEX emp_id_idx
ON hr.emp(employee_id);인덱스 생성 시에 내부적으로
SELECT ROWID, employee_id
FROM hr.employees
ORDER BY employee_id;가 돌아간다.
위의 CREATE 문의 경우 엄밀히 따지면 nonunique index는 아니다. PRIMARY KEY 제약조건이 걸려있는 employee_id는 고유한 값이기 때문이다. 다시 말하면 키 값이 고유한 값이면 nonunique index를 생성해야한다.
NONUNIQUE INDEX 삭제
DROP INDEX 인덱스이름;UNIQUE INDEX 생성
CREATE UNIQUE INDEX hr.emp_id_idx
ON hr.emp(employee_id);따로 UNIQUE 제약조건을 걸지 않았지만 UNIQUE INDEX가 걸려있으면 중복되는 값은 들어올 수 없다. 즉 UNIQUE INDEX 덕분에 UNIQUE 제약조건이 걸린 것과 같은 효과.
UNIQUE INDEX 삭제
DROP INDEX emp_id_idx;INDEX RANGE SCAN과 INDEX UNIQUE SCAN
INDEX RANGE SCAN
SELECT *
FROM hr.emp
WHERE employee_id = 100; -- INDEX RANGE SCAN-- 100번 사원을 찾기 위해서 emp_id_idx라는 이름으로 인덱스가 만들어졌고, 그 인덱스에서 100번에 해당하는 rowid를 찾아라. 그리고 그 rowid를 가지고 emp 테이블에 찾아가라.
-- 찾았어도 또 그 데이터가 있을 수 있기 때문에 다시 인덱스(LEAF BLOCK)로 돌아와서 검사하고 스캔하는 것을 바로 index range scan이라고 함.
-- 그래서 오름차순으로 정렬이 되어있어야 아래로 더 스캔해서 안 찾고 range scan을 종료할 수 있음
INDEX UNIQUE SCAN
SELECT *
FROM hr.emp
WHERE employee_id = 100; -- INDEX UNIQUE SCAN. RANGE SCAN과 다르게 다시 LEAF BLOCK으로 액세스 하지 않음조합 INDEX
SELECT *
FROM hr.emp
WHERE last_name = 'King' -- last_name에는 인덱스가 걸려있음
AND first_name = 'Steven'; -- first_name에는 인덱스가 없음.
-- WHERE 절에 여러 조건이 걸려있는데 그 조건들 중 일부만 인덱스가 걸려있다면, 인덱스가 걸려있지 않은 조건은 전~부 FULL TABLE SCAN 해야하기 때문에 결과적으로 성능이 떨어짐.
-- 따라서 조합인덱스를 걸어줄 필요가 있음
CREATE INDEX emp_name_idx
ON hr.emp(last_name, first_name);
-- 인덱스 생성 시에 내부적으로는 아래 쿼리문장이 수행된다.
SELECT last_name, first_name, ROWID
FROM hr.emp
ORDER BY 1, 2;
SELECT * FROM user_indexes WHERE table_name = 'EMP';
SELECT * FROM user_ind_columns WHERE table_name = 'EMP'; -- 인덱스 명이 같은데 컬럼 포지션이 다르면 조합인덱스가 걸려있다는 뜻. 컬럼 포지션 순서대로 선행됨. 선행 컬럼이 무엇인지가 중요!!!★F10을 누르면 필터 술어는 사라져있음. 즉 조합 인덱스를 썼더니 FULL TABLE SCAN 을 더이상 하지 않음.
SELECT *
FROM hr.emp
WHERE last_name = 'King'
AND first_name = 'Steven';만약 조합인덱스를 걸었는데 가장 중요한 것은 선행 컬럼이 무엇인지가 중요!!!
선행 컬럼은 혼자서도 자주 사용되는 컬럼이어야 함. 그리고 다른 컬럼들에 비해 좀 더 유니크성이 있는 컬럼이어야 훨씬 더 잘 걸러지고 성능에도 좋다.
SELECT *
FROM hr.emp
WHERE last_name = 'King';만약 조합인덱스를 걸어놓고 후행 컬럼으로 조회를 하면 UNIQUE SCAN 이 아니라 RANGE SCAN 으로 바꿔서 조회하게 됨. 효율 떨어짐.
SELECT *
FROM hr.emp
WHERE first_name = 'Steven';