그룹함수
여러 행 당 하나의 결과를 반환하는 함수. 입력값이 숫자형만 가능한 그룹함수는 sum, avg, median, variance, stddev, max, min, count이고 모든 타입이 다 가능한 그룹함수는 max, min, count이다. 그룹함수는 null을 포함하지 않지만 count(*)는 null을 포함한 행 수를 셀 수 있다. 대표값은 자료의 특징을 대표하는 값으로 avg, median, count가 있다.
count
: 행의 수를 구하는 함수
SELECT count(*)
FROM employees
WHERE department_id = 50; -- WHERE 절로 조건을 제한하고 데이터 갯수를 셀 수 있음
SELECT count(commission_pct) -- null 값은 포함하지 않음
FROM employeessum
: 합
SELECT sum(salary) -- sum은 숫자 타입만 가능
FROM employeesavg
: 평균
SELECT round(avg(salary)) -- 일의 자리까지 반올림한 연봉의 평균값
FROM employees;그룹함수는 null을 포함하지 않는다! 예를 들면,
1.
자료 : 10, 20, 0
sum : 10 + 20 + 0
avg : (10 + 20 + 0) / 3
-- 1번 예제는 일반적으로 생각할 수 있는 계산의 형태이다.
2.
자료 : 10, 20, null
sum : 10 + 20
avg : (10 + 20) / 2
-- 2번 예제는 자료값에 null이 포함되어 있을 경우이다. 그룹함수는 null을 포함하지 않기 때문에
평균을 구할 때는 전체 합계에서 null을 제외한 갯수만큼으로 나누어 주어야 한다.
전체 데이터 갯수로 나누는 것이 절대 아님!만약, null을 포함한 평균을 구하고 싶을 때 쓰는 함수가 있다. 바로 nvl 함수. null 값을 실제값으로 바꾸는 함수가 nvl 함수다. null을 포함한 평균을 구할 땐 nvl 함수를 활용하여 null값 대신 0이라는 실제값을 넣어서 계산하면 된다.
SELECT avg(nvl(commission_pct, 0))
FROM employees;median ★
: 중앙값
중앙값을 구하는 방법은 자료의 갯수가 홀수 또는 짝수인 경우, 이렇게 크게 두 가지로 분류할 수 있다.
1. 홀수일 때,
자료 : 20, 30, 10, 50, 40
1) 크기순(오름차순)으로 나열한 후 가운데 값을 중앙값이라고 한다.
10, 20, 30, 40, 50
2) 자료가 홀수면,
(관측값수 + 1) / 2 = 3 <- 중앙값의 위치
2. 짝수일 때,
자료 : 20, 30, 10, 50, 40, 60
1) 크기순(오름차순)으로 나열한 후 가운데 값을 중앙값이라고 한다.
10, 20, 30, 40, 50, 60
2) 자료가 홀수면,
(관측값수) / 2 = 3 <- 위치
(관측값수) / 2 + 1 = 4 <- 위치
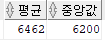
SELECT (30 + 40) / 2
FROM dual; -- 결과는 35평균과 중앙값은 차이가 있다.
variance ★★
: 분산. 내가 가진 자료(데이터)가 평균값을 중심으로 퍼져있는 평균적인 거리
1) 평균
2) 편차 제곱 합의 평균
(관측값 - 관측값 평균)² + (관측값 - 관측값 평균)²
---------------------------------------------
관측값의 수 - 1 (자유도)
SELECT variance(salary)
FROM employees;stddev
: 표준편차. 분산의 제곱근을 수행한 값
SELECT
avg(salary), -- 평균
variance(salary), -- 분산
sqrt(variance(salary)), -- 분산의 제곱근(=표준편차)
stddev(salary) -- 표준편차
FROM employees;max
: 최대값. 문자는 알파벳 or 가나다 순에서 가장 끝 값, 날짜는 가장 최근 날짜를 말한다.
min
: 최소값. 문자는 알파벳 or 가나다 순에서 가장 처음 값, 날짜는 가장 오래된 날짜를 말한다.
SELECT
max(salary), -- max or min
max(last_name),
max(hire_date),
max(salary) - min(salary) "range" -- 범위는 최대값 - 최소값
FROM employees;GROUP BY
: 테이블의 행을 작은 그룹(군집)으로 나눌 수 있는 절
SELECT sum(salary)
FROM employees
WHERE department_id = 10;
...
SELECT sum(salary)
FROM employees
WHERE department_id = 110;
SELECT sum(salary)
FROM employees
WHERE department_id IS NULL;라는 쿼리문이 있다고 하자. WHERE 절로 행을 제한해서 그룹을 만드는데 만약 컬럼 이름이 예제처럼 엄청 많다면? 이럴 때 일일히 WHERE 절로 제한하기 힘드니까 이런 문제를 해결하기 위해 나온 것이 바로 GROUP BY이다.
SELECT sum(salary)
FROM employees
GROUP BY department_id;옛날에 오라클 9i R1 버전까지는 GROUP BY가 SORT GROUP BY로 수행되었다. 그래서 ORDER BY를 하지 않고 GROUP BY 만으로도 GROUP BY 절에 명시된 컬럼을 기준으로 (오름차순) 정렬된 결과로 출력이 됐다. 그러나 대용량 데이터를 다룰 때 SORT보다는 HASH 알고리즘을 이용하는 것이 훨씬 효율이 좋기 때문에 9i R2 버전부터는 HASH로 알고리즘이 변경되었고, GROUP BY는 HASH GROUP BY를 수행하게 된다. 따라서 이전과 달리 GROUP BY 절에 명시된 컬럼을 기준으로 정렬되지 않는다.
이런 그룹함수들을 사용할 때 주의해야할 것들이 있다. 여러 번 강조하는 내용인데, 그룹함수는 count(*)을 제외하고 null을 포함하지 않는다. 그리고 SELECT 절에 그룹함수에 포함되지 않은 개별 컬럼은 하나도 빠짐없이 GROUP BY 절에 명시해야 한다. 예를 들면,
SELECT
department_id,
job_id,
sum(salary)
FROM employees
GROUP BY department_id, job_id;SELECT 절에 그룹함수로 묶인 sum을 제외한 개별 컬럼은 department_id와 job_id이다. 이 컬럼들의 이름은 빠짐없이 GROUP BY 절에 명시해야 한다는 뜻이다.
SELECT
department_id dept_id,
job_id,
sum(salary)
FROM employees
GROUP BY dept_id, job_id;위 예제에서는 SELECT 절에서 department_id를 dept_id라는 이름으로 열 별칭을 만들었다. 하지만 이런 열 별칭은 GROUP BY 절에서 사용할 수 없다. 왜냐하면 위의 예제에서는 FROM -> GROUP BY -> SELECT 순으로 쿼리문이 진행되는데 별칭이 쓰여있는 GROUP BY 절은 가장 마지막에 수행되는 SELECT 절에서 명시한 열 별칭이 무엇인지 알 수 없기 때문이다. 위치표기법 또한 마찬가지로 GROUP BY 절에 쓰일 수 없다.
그리고 단일행 함수는 연속해서 중첩이 가능하지만 그룹함수는 "두 번까지만" 중첩할 수 있다. 예시는 아래와 같다.
SELECT max(avg(salary))
FROM employees
GROUP BY department_id;또한, 아래의 예제를 보면 department_id라는 개별 컬럼과 max(avg(salary))라고 두 번 중첩된 그룹함수가 있다. 그러나 그룹함수를 두 번 중첩하면 개별 컬럼과 함께 사용할 수 없다.(아직 배우지 않았지만 이런 경우엔 '서브쿼리'를 이용하여 해결할 수 있다.)
SELECT
department_id,
max(avg(salary)) -- 오류 발생
FROM employees
GROUP BY department_id;그리고 중요한 건!!! WHERE 절로는 그룹함수의 결과를 제한할 수 없다!!! 아래에 예를 들어보자.
SELECT
department_id,
sum(salary)
FROM employees
WHERE sum(salary) >= 10000 -- 오류 발생!
GROUP BY department_id;employees 테이블에서(FROM) 연봉의 합계가 10000 이상인 데이터를(WHERE) 부서 별로 분류하고(GROUP BY) 부서명과 연봉의 합계를 출력(SELECT)하라는 의미 같아 보인다. 그러나 이 쿼리문은 잘못된 쿼리문이다. 왜냐하면 GROUP BY보다 WHERE 절이 선행되기 때문에 연봉의 합계가 어떤 부서의 것인지 알 수 없다. 이렇게 WHERE 절로 제한할 수 없던 그룹함수의 한계를 보완하기 위해 나온 것이 바로 HAVING 절이다.
HAVING
: 그룹함수의 결과를 제한하는 절. 통상적으로 HAVING은 GROUP BY 아래에 써준다.
/
※ 일반적인 쿼리문 순서
SELECT
FROM
WHERE
GROUP BY
HAVING
START WITH
CONNECT BY
ORDER BY
/
HAVING을 활용한 여러 가지 예제들을 살펴보자.
SELECT
department_id,
count(*),
sum(salary)
FROM employees
GROUP BY department_id
HAVING count(*) >= 5;employees 테이블에서(FROM) 부서 별 군집을 구하고(GROUP BY) 인원수가 5명 이상인(HAVING) 부서명, 부서별 인원수, 연봉합계를 구하라(SELECT)는 뜻이다. HAVING 절에는 SELECT 절에 나열된 컬럼 or 함수의 내용만 써줘야 하는 것은 아니다. 내가 알맞게 조건을 걸어주면 된다. 또 다른 예제를 살펴보자.
SELECT
department_id,
sum(salary)
FROM employees
WHERE last_name LIKE '%i%'
GROUP BY department_id
HAVING sum(salary) >= 10000
ORDER BY 1;employees 테이블에서(FROM) last_name 중간에 i가 들어가는 데이터로 행을 제한하고(WHERE) 부서 별 군집을 구하고(GROUP BY) 연봉 합계가 10000 이상인(HAVING) 부서명, 연봉합계를 구하고(SELECT) 1번 컬럼을 오름차순으로 정렬하라(ORDER BY)는 뜻이다. 또 다른 예제를 살펴보자.
SELECT
department_id,
sum(salary),
count(*)
FROM employees
GROUP BY department_id
HAVING last_name LIKE '%i%' -- 오류 발생!
AND count(*) >= 5
ORDER BY 1;여기서 주의해야할 점이 있다!!! 행을 제한할 때는 WHERE, 그룹함수를 제한할 때는 HAVING을 사용해야 한다. 위의 예제처럼 HAVING을 이용하여 LIKE가 들어가는 단일행 제한을 한다거나 IN 연산자를 쓴다거나 하는 쿼리문을 작성하지 않도록 꼭!! 주의해야 한다. 또한 반대로 WHERE 절에 그룹함수를 제한하지도 않아야 한다.
hire_date 컬럼은 날짜 타입의 컬럼이기 때문에 아래와 같은 쿼리문을 짜면 성능 상에 문제가 발생할 수 있다!!!
SELECT
job_id,
count(*)
FROM employees
-- WHERE to_char(hire_date, 'yyyy') = '2008'
-- WHERE substr(hire_date,1,2) = '08'
-- WHERE hire_date LIKE '08%'
GROUP BY job_id
ORDER BY 2 desc;DATE 타입 컬럼이 to_char, substr, LIKE를 사용하면 내부적으로 to_char 형변환 함수가 수행되다보니 성능 상에 문제가 발생한다. 이와 비슷한 맥락으로 숫자 타입은 to_number, 날짜 타입은 to_date 등으로 변환하는 것을 습관화하여 형변환에 주의하며 쿼리문을 짜도록 하자!
예제를 한 번 풀어보자. ★★★ 년도별 입사 인원수를 아래 화면과 같이 출력해주세요. ★★★

일반적으로 군집을 만들어서 정렬할 때는 세로로 정렬되기 마련이다. 세로일 땐 간단히 GROUP BY를 이용해서 풀면 된다. 그런데 문제에선 군집을 가로로 정렬시킨 모양이다. 이럴 땐 보통 조건제어문을 사용하는데 SQL에서는 조건제어문을 사용할 수 없다. 때문에 DECODE 함수나 CASE 표현식을 응용해서 풀 수 있다.
DECODE 함수로 풀면,
SELECT
count(*) total,
count(DECODE(to_char(hire_date,'yyyy'),'2001','X')) "2001년",
count(DECODE(to_char(hire_date,'yyyy'),'2002','X')) "2002년",
count(DECODE(to_char(hire_date,'yyyy'),'2003','X')) "2003년"
FROM employees;입사날짜를 'yyyy'와 같은 문자형으로 형변환 하고 DECODE 함수를 이용해 기준값(입사날짜)이 비교값('2001')일 때 참값('X')을 리턴하고 그 데이터의 갯수를 세준다는 뜻이다. count가 아니라 sum 함수를 이용해 갯수를 세줄 수도 있다.
SELECT
count(*) total,
sum(DECODE(to_char(hire_date,'yyyy'),'2001',1)) "2001년",
sum(DECODE(to_char(hire_date,'yyyy'),'2002',1)) "2002년",
sum(DECODE(to_char(hire_date,'yyyy'),'2003',1)) "2003년"
FROM employees;단, sum은 숫자형을 취급하는 그룹함수이므로 인수값을 숫자형(1)으로 적어주어야 하고 누적 계산으로 갯수를 세기 때문에 무조건 숫자 1을 써주도록 한다.
CASE 표현식으로 풀면,
SELECT
count(*) total,
count(CASE WHEN to_char(hire_date, 'yyyy')='2001' THEN 'X' END) "2001년",
count(CASE WHEN to_char(hire_date, 'yyyy')='2002' THEN 'X' END) "2002년",
count(CASE WHEN to_char(hire_date, 'yyyy')='2003' THEN 'X' END) "2003년"
FROM employees;입사날짜를 'yyyy'와 같은 문자형으로 형변환 하고 만약 그 값이 '2001'이면 THEN을 받아서 'X'로 리턴하고 그 데이터의 갯수를 세준다는 뜻이다. 이 또한 마찬가지로 sum을 이용해 갯수를 세줄 수 있다.
Join
두 개 이상의 테이블에서 내가 원하는 데이터를 가져오는 방법이다. 각 테이블마다 중복되는 컬럼 이름이 있을 수도 있고 중복되는 컬럼이지만 테이블 여러개로 나눠놓은 경우도 있다. 왜 테이블이 여러 갈래로 나누어져 있을까? 왜냐하면 중복되는 데이터를 거르고, 데이터가 너무 많으면 추후 유지보수 비용이 크게 발생하기 때문이다. 따라서 여러 갈래로 분산시켜 놓은 것이다.
Cartesian product
: 카티시안 곱. join 조건이 생략되었거나 잘못 만들었을 때, 첫번째 테이블의 행 수와 두번째 테이블의 행 수가 곱해진다.
Equi join(Inner join, Simple join, 등가 join)
: join 키 값이 일치하는 데이터만 추출하는 join. null 값은 제외되므로 누락되는 데이터가 있을 수 있다.
SELECT
employees.employee_id,
employees.last_name,
departments.department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id;
M쪽 집합(107건) 1쪽 집합(27건) = M쪽 집합(107건 이하)1쪽 집합은 중복성이 없는 집합, M쪽 집합은 중복이 있는 집합을 말한다. 조인 건수는 M쪽 집합의 행의 수 보다 작거나 같게 나와야 한다. 1쪽 집합과 1쪽 집합끼리 조인할 수도 있다.
SELECT
e.employee_id,
e.last_name,
d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id;테이블에 별칭을 붙일 땐 FROM 절에서 스펠링 맨 앞글자만 따서 테이블명 한 칸 띄고 바로 뒤에 붙인다. 테이블의 별칭을 사용하여 join을 수행하면 코드가 심플해지므로 메모리 사용을 줄일 수 있다. 단, 테이블에 별칭을 사용한 뒤에는 무조건 그 쿼리문 내에서는 별칭만 쓰도록 한다.
SELECT
e.employee_id,
e.last_name,
l.city
FROM employees e, departments d, locations l
WHERE e.department_id = d.department_id -- 조인 조건 술어
AND d.location_id = l.location_id; -- 조인 조건 술어Join 수행할 테이블이 n개면 조인 조건 술어는 n-1개 기술해야 한다. 예제에서는 테이블이 employees, departments, location 이렇게 3개이므로 조인 조건 술어는 3-1=2개여야 한다. 그리고 employees 테이블과 locations 테이블처럼, 컬럼이 서로 연관이 없는 테이블들을 직접 연결해야할 때 매개체로 다른 테이블(departments)을 엮어주어야 한다.
